Комментарии 25
Предварительно создать папки C:\1\test и C:\1\test-out
Уж пару строк-то в скрипт можно было бы добавить, чтобы он создавал…
Распознавание капчи длится 28 сек на компьютере средней мощности. 2 сек можно выиграть благодаря применению в скрипте многопоточности, но это, как говорится, что мертвому припарка.
Распознавание 30 сек??? Капчи??? Вроде нынче автомобильные номера в реалтайме распознаются, а у вас капча 30 секунд?
питон же :) да и без gpu, но всё равно как-то вяло.
Скорее всего, основное время занимает инициализация TF, при первом запуске библиотека всегда долго раскочегаривается.
В горячем режиме, с загруженной моделью, результат выдается моментально.
В горячем режиме, с загруженной моделью, результат выдается моментально.

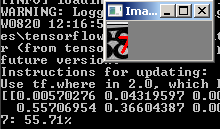
Пока это лучший результат с «прогретым» TF на слабом железе без CUDA. Опять же надо учитывать, что по факту распознается 5-ть разных цифр отдельно, т.е. на 1 цифру приходится по 3,52 сек.
def prescript(file):
cmdCommand = "python predict-captcha.py --image "+ file +" --model simple_nn.model --label-bin simple_nn_lb.pickle --flatten 1"
process = subprocess.Popen(cmdCommand.split(), stdout=subprocess.PIPE)
output, error = process.communicate()
print (str(output)[2])
1. Тут скорее дело в том, что вы для распознавания каждой картинки вызываете скрипт predict-captcha.py и таким образом каждый раз заново загружаете модель, хотя достаточно это сделать один раз.
2. Не понятно зачем вообще вызывать это как скрипт, когда можно оформить как модуль и импортировать.
3. Предыдущий пункт заодно позволит не сохранять картинки на диск, а использовать питоновские file-like объекты.
4. Не понятно почему не использовалась сверточная архитектура, хотя она лучше подходит для распознавания изображений.
5. И даже ваш подход можно попробовать улучшить если использовать transfer learning.
1,2.Да это колхоз, через subprocess, именно он все тормозит. Временная «изолента».
3. Вы про pickle.dumps?
4.Вы правы. Но интерес был выжать из простой сети максимум.
5.Каким образом это реализуется?
3. Вы про pickle.dumps?
4.Вы правы. Но интерес был выжать из простой сети максимум.
5.Каким образом это реализуется?
Про file-like я например про BytesIO.
Про transfer learning — мелькнула мысль, что если предварительно обучить на MNIST, а потом заморозить нижние слои, кроме предпоследнего и обучить уже на капчах. Вот, например, тут правда CNN.
А колхоз убрать не долго и тогда смысл в замерах хоть какой-то появится.
Про transfer learning — мелькнула мысль, что если предварительно обучить на MNIST, а потом заморозить нижние слои, кроме предпоследнего и обучить уже на капчах. Вот, например, тут правда CNN.
А колхоз убрать не долго и тогда смысл в замерах хоть какой-то появится.
Одну грыжу вправил с subprocessами:


C BytesIO скорее всего не выйдет, т.к. изображение необходимо сначала открыть в rb режиме. В коде капча считывается в стандартном режиме, иначе ее потом не нарезать.
Такой вариант дает ошибку:
f = open(«img1», «rb»)
Такой вариант дает ошибку:
f = open(«img1», «rb»)
Сохраняем в буффер:
Передаем в функцию и читаем из буффера:
Только проще сразу img1 передать))
import io
from PIL import Image
img = Image.open('capcha.jpg')
area1=(27,0,51,37)
img1 = img.crop(area1)
buffered_img1 = io.BytesIO()
img1.save(buffered_img1)
Передаем в функцию и читаем из буффера:
import cv2
import numpy as np
img1 = cv2.imdecode(np.fromstring(buffered_img1.read(), np.uint8), 1)
Только проще сразу img1 передать))
Баловался подобной задачкой, на компе средней мощности (без GPU) почти мгновенно сетка распознавала, за секунды, или может доли секунд, даже не замечал лага особо никогда. Причем капча была посложнее, с шумами/дисторсией/поворотами. Сеть имела десятки слоев чтобы уверенно распознавать, архитектура типа resnet.
Может дело в том что в моей версии tensorflow-cpu использовались AVX-инструкции?
Может дело в том что в моей версии tensorflow-cpu использовались AVX-инструкции?
Have you heard about github?
М-м-м. Мне кажется, что большей точности можно было бы добиться, заменив простейший "нож" по геометрическим координатам на хоть какой-то классификатор, который позволил бы избежать проблемы как тут:
Когда на одной картинке две половины двух разных цифр.
НЛО прилетело и опубликовало эту надпись здесь
Можно заморозить получившийся граф, выгрузив его из keras'а и использовать tensorflow-serving: github.com/tensorflow/serving
Через serving должно побыстрее заработать.
Через serving должно побыстрее заработать.
.
Какая знакомая капча из онлайн-сервиса Росреестра ;))
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Как обойти капчу: нейросеть на Tensorflow,Keras,python v числовая зашумленная капча