Заголовок этой статьи может показаться немного странным. И вправду: если вы работаете в сфере Data Science в 2019, вы уже востребованы. Спрос на специалистов в этой области неуклонно растет: на момент написания этой статьи, на LinkedIn размещено 144,527 вакансий с ключевым словом «Data Science».
Тем не менее, следить за последними новостями и трендами в индустрии однозначно стоит. Чтобы помочь вам в этом, мы с командой CV Compiler проанализировали несколько сотен вакансий в сфере Data Science за июнь 2019 и определили, какие навыки ожидают от кандидатов работодатели чаще всего.
Этот график показывает навыки, которые работодатели чаще всего упоминают в вакансиях в сфере Data Science в 2019:
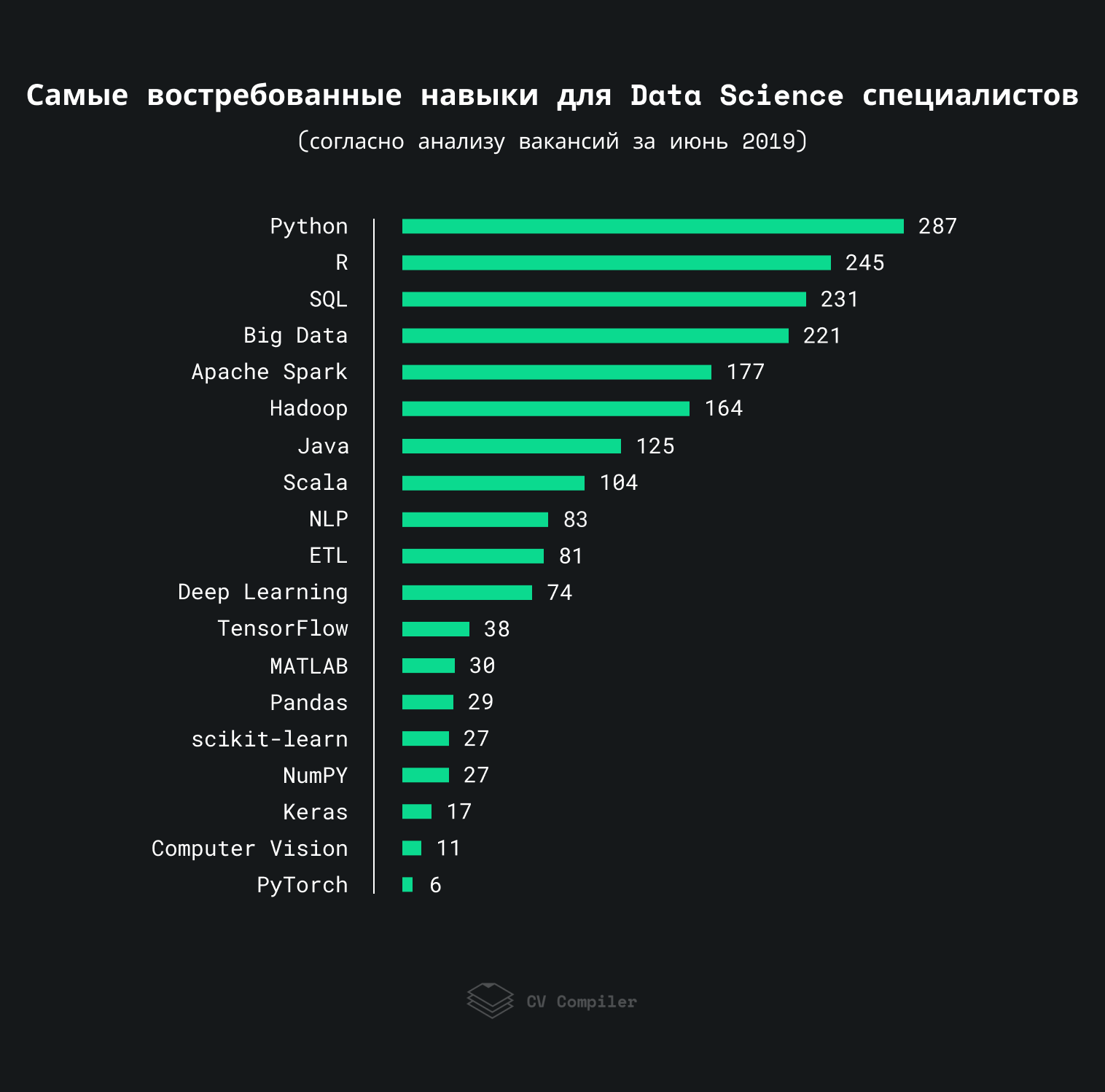
Мы проанализировали примерно 300 вакансий со StackOverflow, AngelList, и похожих ресурсов. Некоторые термины могли повторяться более одного раза в пределах одной вакансии.
Важно: Этот рейтинг демонстрирует скорее предпочтения работодателей, чем самих специалистов в сфере Data Science.
Очевидно, что Data Science — это в первую очередь не фреймворки и библиотеки, а фундаментальные знания. Тем не менее, некоторые тенденции и технологии все же стоит упомянуть.
Согласно исследованиям рынка Big Data в 2018 году, применение Big Data на предприятиях возросло с 17% в 2015 до 59% в 2018. Соответственно, возросла и популярность инструментов для работы с большими данными. Если не учитывать Apache Spark и Hadoop (о последнем мы еще поговорим подробнее), самыми популярными инструментами являются MapReduce (36) и Redshift (29).
Несмотря на популярность Spark и облачных хранилищ, «эра» Hadoop еще не окончена. Поэтому некоторые компании ожидают от кандидатов знания Apache Pig (30), HBase (32), и похожих технологий. HDFS (20) также еще встречается в некоторых вакансиях.
Учитывая повсеместное использование различных датчиков и мобильных устройств, а также популярность IoT (18), компании пытаются научиться обрабатывать данные в режиме реального времени. Поэтому платформы обработки потоков, такие как Apache Flink (21), популярны среди работодателей.
Подготовка данных и выбор параметров модели — важная часть работы любого специалиста в сфере Data Science. Поэтому термин Data Mining (128) довольно популярен среди работодателей. Некоторые компании также уделяют внимание Hyperparameter Tuning (21) (о таком термине как Feature Engineering тоже забывать не стоит). Подбор оптимальных параметров для модели — это важно, ведь от успеха этой операции зависит работоспособность модели в целом.
Умение правильно обработать данные и выводить необходимые закономерности — это важно. Тем не менее, визуализация данных (55) является не менее важным навыком. Необходимо уметь представить результаты своей работы в формате, понятном любому члену команды или клиенту. Что касается инструментов для визуализации данных, работодатели предпочитают Tableau (54).
В вакансиях нам также встречались такие термины как AWS (86), Docker (36), а также Kubernetes (24). Можно сделать вывод, что общие тренды из сферы разработки ПО потихоньку перекочевали в сферу Data Science.
Карла Гентри,
Data Scientist, владелец Analytical Solution
LinkedIn | Twitter
Андрей Бурков,
Director of Machine Learning в Gartner,
автор Hundred-Page Machine Learning Book.
LinkedIn
Ганапати Пулипака,
Chief Data Scientist в Accenture,
обладатель премии Top 50 Tech Leader.
LinkedIn | Twitter
Лон Ризберг,
Основатель/куратор Data Elixir,
ex-NASA.
Twitter | LinkedIn
Data Science — это быстро развивающаяся и сложная сфера, в которой фундаментальные знания важны настолько же, насколько и опыт работы с определенными инструментами. Надеемся, эта статья поможет вам определить, какие навыки необходимы, чтобы стать более востребованным специалистом в сфере Data Science в 2019. Удачи!
Эта статья была подготовлена командой CV Compiler — инструмента для улучшения резюме для специалистов в сфере Data Science и других отраслях IT.
Тем не менее, следить за последними новостями и трендами в индустрии однозначно стоит. Чтобы помочь вам в этом, мы с командой CV Compiler проанализировали несколько сотен вакансий в сфере Data Science за июнь 2019 и определили, какие навыки ожидают от кандидатов работодатели чаще всего.
Самые востребованные навыки в сфере Data Science в 2019
Этот график показывает навыки, которые работодатели чаще всего упоминают в вакансиях в сфере Data Science в 2019:
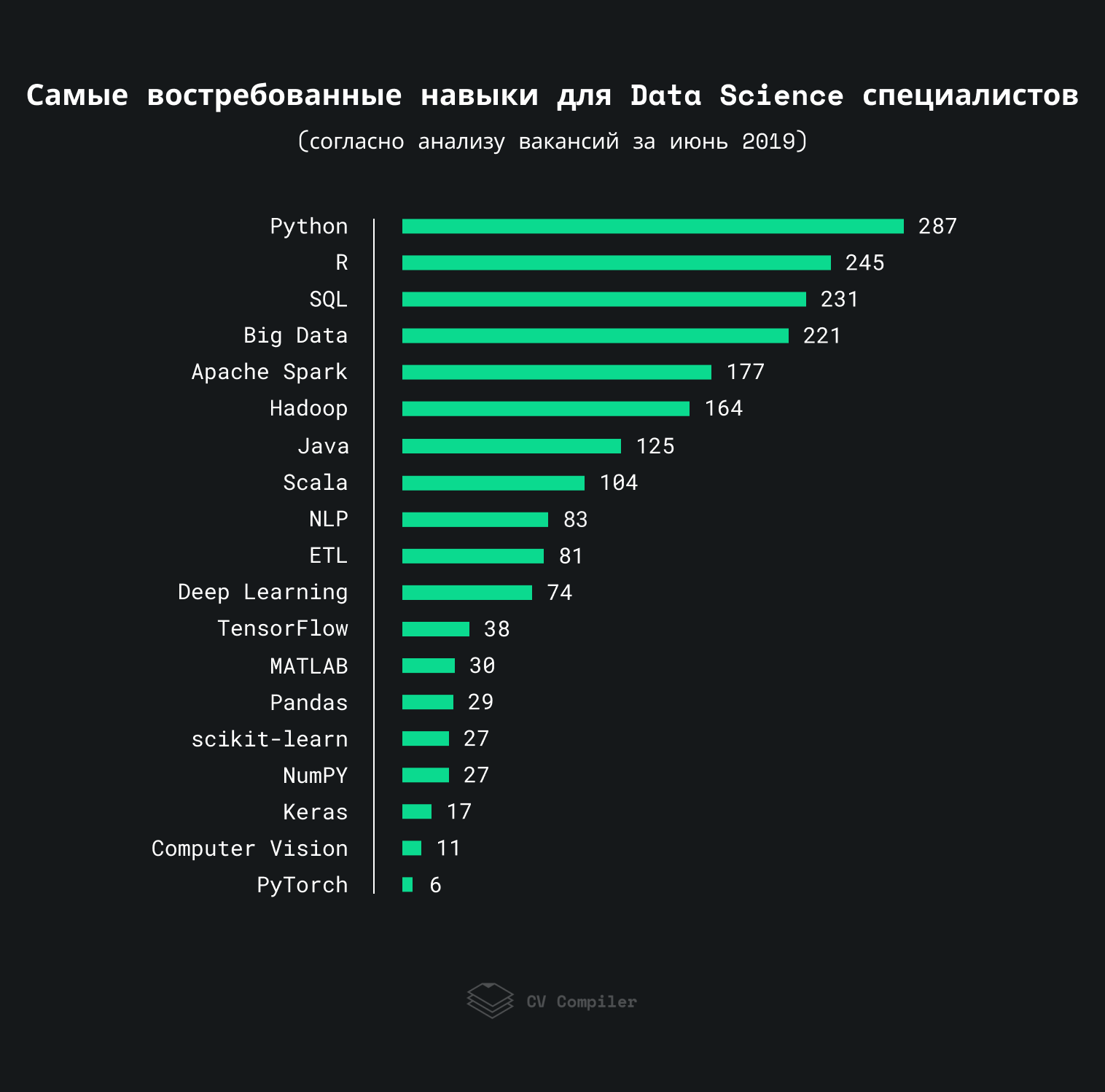
Мы проанализировали примерно 300 вакансий со StackOverflow, AngelList, и похожих ресурсов. Некоторые термины могли повторяться более одного раза в пределах одной вакансии.
Важно: Этот рейтинг демонстрирует скорее предпочтения работодателей, чем самих специалистов в сфере Data Science.
Основные тренды в сфере Data Science
Очевидно, что Data Science — это в первую очередь не фреймворки и библиотеки, а фундаментальные знания. Тем не менее, некоторые тенденции и технологии все же стоит упомянуть.
Big Data
Согласно исследованиям рынка Big Data в 2018 году, применение Big Data на предприятиях возросло с 17% в 2015 до 59% в 2018. Соответственно, возросла и популярность инструментов для работы с большими данными. Если не учитывать Apache Spark и Hadoop (о последнем мы еще поговорим подробнее), самыми популярными инструментами являются MapReduce (36) и Redshift (29).
Hadoop
Несмотря на популярность Spark и облачных хранилищ, «эра» Hadoop еще не окончена. Поэтому некоторые компании ожидают от кандидатов знания Apache Pig (30), HBase (32), и похожих технологий. HDFS (20) также еще встречается в некоторых вакансиях.
Обработка данных в режиме реального времени
Учитывая повсеместное использование различных датчиков и мобильных устройств, а также популярность IoT (18), компании пытаются научиться обрабатывать данные в режиме реального времени. Поэтому платформы обработки потоков, такие как Apache Flink (21), популярны среди работодателей.
Feature Engineering и Hyperparameter Tuning
Подготовка данных и выбор параметров модели — важная часть работы любого специалиста в сфере Data Science. Поэтому термин Data Mining (128) довольно популярен среди работодателей. Некоторые компании также уделяют внимание Hyperparameter Tuning (21) (о таком термине как Feature Engineering тоже забывать не стоит). Подбор оптимальных параметров для модели — это важно, ведь от успеха этой операции зависит работоспособность модели в целом.
Визуализация данных
Умение правильно обработать данные и выводить необходимые закономерности — это важно. Тем не менее, визуализация данных (55) является не менее важным навыком. Необходимо уметь представить результаты своей работы в формате, понятном любому члену команды или клиенту. Что касается инструментов для визуализации данных, работодатели предпочитают Tableau (54).
Общие тренды
В вакансиях нам также встречались такие термины как AWS (86), Docker (36), а также Kubernetes (24). Можно сделать вывод, что общие тренды из сферы разработки ПО потихоньку перекочевали в сферу Data Science.
Мнение экспертов
Этот список технологий действительно отображает реальное положение вещей в мире Data Science. Тем не менее, есть вещи не менее важные, чем написание кода. Это способность правильно интерпретировать результаты своей работы, а также визуализировать и представлять их в понятной форме. Все зависит от аудитории — если вы рассказываете о своих достижениях кандидатам наук, говорите на их языке, но если вы представляете результаты заказчику, его не будет волновать код — только результат, которого вы достигли.
Карла Гентри,
Data Scientist, владелец Analytical Solution
LinkedIn | Twitter
Этот график показывает текущие тренды в области Data Science, но предсказать будущее, основываясь на него, довольно сложно. Я склонен считать, что популярность R будет снижаться (как и популярность MATLAB), в то время как популярность Python будет только расти. Hadoop и Big Data также оказались в списке по инерции: Hadoop вскоре исчезнет (никто больше не инвестирует в эту технологию всерьез), а Big Data перестало быть нарастающим трендом. Будущее Scala не совсем ясно: Google официально поддерживает Kotlin, который гораздо более прост для изучения. Я также скептически отношусь к будущему TensorFlow: научное сообщество предпочитает PyTorch, а влияние научного сообщества в сфере Data Science куда выше, чем во всех остальных сферах. (Это мое личное мнение, которое может не совпадать с мнением Gartner).
Андрей Бурков,
Director of Machine Learning в Gartner,
автор Hundred-Page Machine Learning Book.
PyTorch — это движущая сила обучения с подкреплением, а также сильный фреймворк для параллельного выполнения кода на нескольких графических процессорах (чего не скажешь о TensorFlow). PyTorch также помогает строить динамические графы, которые эффективны при работе с рекуррентными нейронными сетями. TensorFlow оперирует статическими графами и более сложен для изучения, но его использует большее количество разработчиков и исследователей. Однако, PyTorch ближе к Python в плане отладки кода и библиотек для визуализации данных (matplotlib, seaborn). Большинство инструментов отладки кода на Python можно использовать для отладки кода на PyTorch. У TensorFlow же есть свой инструмент для отладки — tfdbg.
Ганапати Пулипака,
Chief Data Scientist в Accenture,
обладатель премии Top 50 Tech Leader.
LinkedIn | Twitter
По моему мнению, работа и карьера в Data Science — не одно и то же. Для работы вам понадобится вышеприведенный набор навыков, но для построения успешной карьеры в Data Science самый важный навык — это умение учиться. Data Science — непостоянная сфера, и вам придется научиться осваивать новые технологии, инструменты и подходы, чтобы шагать в ногу со временем. Постоянно ставьте перед собой новые вызовы и старайтесь не «довольствоваться малым».
Лон Ризберг,
Основатель/куратор Data Elixir,
ex-NASA.
Twitter | LinkedIn
Data Science — это быстро развивающаяся и сложная сфера, в которой фундаментальные знания важны настолько же, насколько и опыт работы с определенными инструментами. Надеемся, эта статья поможет вам определить, какие навыки необходимы, чтобы стать более востребованным специалистом в сфере Data Science в 2019. Удачи!
Эта статья была подготовлена командой CV Compiler — инструмента для улучшения резюме для специалистов в сфере Data Science и других отраслях IT.










