В статье приведён код по формированию регулярных отчётов по состоянию дисков СХД EMC VNX с альтернативными подходами и историей создания.
Старался писать код с максимально подробными комментариями и одним файлом. Только пароли свои подставить. Формат исходных данных также указан, так что буду рад, если кто-то попробует применить у себя.
Предыстория
Можно пропустить, если не интересно, откуда "ноги растут".
Есть у нас ЦОД. Там не очень свежие СХД. СХД много, отказов дисков тоже. Несколько раз в неделю в ЦОД ездят люди и меняют диски в СХД. Решение о замене дисков принимается после аварийного сообщения от системы "Recommended disk replacement".
Ничего необычного.

Но последнее время отдельные LUN, собранные на этих СХД и презентованные Виртульной среде стали серьёзно деградировать. После общения с техподдержкой вендора стало понятно, что диски уже надо менять не только при появлении вышеописанного аварийного сообщения, но и при появлении большого количества других сообщений, которые система не считает critical ошибками.
Мониторинг по SNMP этими СХД не поддерживается. Нужно использовать или дорогой проприетарный софт (его у нас нет), либо консольную утилиту NaviSECCli, которой нужно подключаться к каждому контроллеру (их два) каждой СХД, а этого не очень хотелось.
Было принято решение автоматизировать сбор логов и поиск в них ошибок. А решение о замене дисков оставлять на ответственных инженеров по результатам анализа отчёта.
Первые шаги
Изначально один из коллег написал код на PowerShell, который делал следующее:
- Брал на вход таблицу, которая содержала ip адреса контроллеров СХД;
- циклом шёл по ip адресам контроллеров А, затем по ip адресам контроллеров В;
- в процессе дополнительно опрашивал их на предмет серийных номеров дисков;
- обрабатывал все строчки логов и фильтровал на предмет содержания искомых сообщений;
- создавал объект PowerShell и в его свойства парсил необходимые данные из полученных выше строчек;
- объединял все получившиеся объекты в таблицу, которую выдавал в виде csv.
Код приведён ниже. Сразу оговорюсь, что он рабочий, но мы внедрили альтернативное решение.
cd 'd:\Navisphere CLI\'
$csv = "D:\VNX-IP.csv"
$Filter1 = "name1"
$Filter2 = "name2"
$Filter3 = "name3"
$Data = import-csv $csv -Delimiter ';' | Where {$_.cl -EQ $Filter1 -Or $_.cl -EQ $Filter2 -Or $_.cl -EQ $Filter3} | Sort-Object -Property @{Expression={$_.cl}; Ascending=$true}, @{Expression={$_.Name} ;Ascending=$true}
#$Filter1 = "nameOfcl"
#$Data = import-csv $csv -Delimiter ';' | Where {$_.Name -EQ $Filter1}
$Data | select Name,IP,cl
$yStart = (Get-Date).AddDays(-30).ToString('yyyy')
$yEnd = (Get-Date).ToString('yyyy')
$mStart = (Get-Date).AddDays(-30).ToString('MM')
$mEnd = (Get-Date).ToString('MM')
$dStart = (Get-Date).AddDays(-30).ToString('dd')
$dEnd = (Get-Date).ToString('dd')
#$start = (Get-Date).AddDays(-3).ToString('MM\/dd\/yy')
#$end = (Get-Date).ToString('MM\/dd\/yy')
$i = 1
$table = ForEach ($row in $Data) {
Write-Host $row.Name -ForegroundColor "Yellow"
Write-Host "SP A"
Write-Host (Get-Date).ToString('HH:mm:ss')
$txt = .\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getlog -date $mStart/$dStart/$yStart $mEnd/$dEnd/$yEnd | Select-String -Pattern "\(820\)","\(803\)","\(801\)","\(920\)","\(901\)"
ForEach ($n in $txt) {
$x = $n -Split(' ')
$disk = $x[3] + "_" + $x[5] + "_" + $x[7].Split("(")[0]
$sn = (.\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getdisk $disk -serial)[1] | %{$_ -replace "Serial Number: ",""} | %{$_ -replace "State: ",""} | %{$_ -replace " ",""}
New-Object PSObject -Property @{
i = $i
cl = $row.cl
Storage = $row.Name
SP = "A"
Date = $x[0]
Time = $x[1]
Disk = $disk
Error = (($n -Split('\['))[0] -Split('\)'))[1].Trim()
eCode = (($n -Split('\('))[1] -Split('\)'))[0]
SN = $sn
}
$i = $i + 1
}
Write-Host "SP B"
Write-Host (Get-Date).ToString('HH:mm:ss')
$txt = .\NaviSECCli.exe -scope 0 -h $row.newB -user myusername -password mypassword getlog -date $mStart/$dStart/$yStart $mEnd/$dEnd/$yEnd | Select-String -Pattern "\(820\)","\(803\)","\(801\)","\(920\)","\(901\)"
ForEach ($n in $txt) {
$x = $n -Split(' ')
$disk = $x[3] + "_" + $x[5] + "_" + $x[7].Split("(")[0]
$sn = (.\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getdisk $disk -serial)[1] | %{$_ -replace "Serial Number: ",""} | %{$_ -replace "State: ",""} | %{$_ -replace " ",""}
New-Object PSObject -Property @{
i = $i
cl = $row.cl
Storage = $row.Name
SP = "B"
Date = $x[0]
Time = $x[1]
Disk = $disk
Error = (($n -Split('\['))[0] -Split('\)'))[1].Trim()
eCode = (($n -Split('\('))[1] -Split('\)'))[0]
SN = $sn
}
$i = $i + 1
}
Write-Host " "
}
$table | select i,cl,Storage,SP,Date,Time,Disk,Error,eCode,SN | Export-Csv -Path 'd:\VNX-Errors.csv' -NoTypeInformation -UseCulture -Encoding UTF8
Всё было хорошо, оставалось только добавить "лоска" в виде автоматической отправки письма заинтересованным коллегам и минимального форматирования получившегося csv. Но (!) отрабатывала вся эта беда очень долго. Данные за месяц, например, собирались порядка 45 минут, что не очень подходило, потому что помимо регулярных отчётов хотелось сделать анализ за текущий год, а это было бы совсем долго. Но "отвергая — предлагай". Стали думать.

Очевидно, что нужно оптимизировать код и подключать параллельные вычисления. В PowerShell больше 5 одновременных потоков с помощью workflow у нас не получилось, а альтернативные методы мы пока не "раскурили". Так что было решено попробовать переложить логику скрипта на R. В исходном коде опрос СХД делает утилита NaviSECCli, которую вполне можно запускать из под R, так что решение вполне себе годное.
Сказано — попрокрастинировано пару дней — сделано!
Решили, что на выходе хочется получить ежедневную рассылку, содержащую в тексте письма общее количество ошибок, какой-то график по количеству аварий (чтобы было что показать руководству), а также вложение в виде xlsx таблицы. Определили, что в таблице хочется иметь 3 вкладки:
- Данные по авариям за 3 дня с разбивкой по дискам и типам аварий
- Аналогичную вкладку, но за 30 дней
- Сырые данные (если кто-то хочет сам погонять их в Excel)
Алгоритм скрипта
1. Загружаем из csv имеющиеся данные по контроллерам;
2. запускаем через параллельные вычисления цикл по всем контроллерам с поиском записей о требуемых аварийных сообщениях;
3. результаты объединяем в data frame;
4. делаем обработку и преобразование данных;
5. формируем xlsx документ;
6. формируем график, который сохраняем в png;
7. формируем письмо, содержащее собранные данные;
8. отправляем письмо.
Пройдём по пунктам алгоритма
1. Загружаем из csv имеющиеся данные по контроллерам
# A tibble: 83 x 9
Name IP cl type newA newB oldA oldB cntIP
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 XXX 10.***.**~ XclNam~ 5300-1 10.201.1~ 10.201.1~ 10.***.*~ 10.***.*~ 10.***.*~
2 XXX 10.***.**~ XclNam~ 5300-1 10.201.1~ 10.201.1~ 10.***.*~ 10.***.*~ 10.***.*~
3 XXX 10.***.**~ XclNam~ 5300-1 10.201.1~ 10.201.1~ 10.***.*~ 10.***.*~ 10.***.*~
4 XXX 10.***.**~ XclNam~ 5300-1 10.201.1~ 10.201.1~ 10.***.*~ 10.***.*~ 10.***.*~
5 XXX 10.***.**~ XclNam~ 5300-1 10.201.1~ 10.201.1~ 10.***.*~ 10.***.*~ 10.***.*~
6 XXX 10.***.**~ XclNam~ 5300-1 10.201.1~ 10.201.1~ 10.***.*~ 10.***.*~ 10.***.*~
7 XXX 10.***.**~ XclNam~ 5300-1 10.201.1~ 10.201.1~ 10.***.*~ 10.***.*~ 10.***.*~
8 XXX 10.***.**~ XclNam~ 5300-1 10.201.1~ 10.201.1~ 10.***.*~ 10.***.*~ 10.***.*~
9 XXX 10.***.**~ XclNam~ 5300-1 10.201.1~ 10.201.1~ 10.***.*~ 10.***.*~ 10.***.*~
10 XXX 10.***.**~ XclNam~ 5300-1 10.201.1~ 10.201.1~ 10.***.*~ 10.***.*~ 10.***.*~
# ... with 73 more rowsДля сбора аварийной информации нужно подключиться последовательно к обоим контроллерам (столбцы newA и newB) с помощью специализированного ПО от ЕМС — NaviCLI с определёнными ключами.
Для удобства переформатируем получившуюся после загрузки таблицу таким образом, чтобы ip адреса обоих контроллеров были в одной колонке, чтобы можно было один цикл сделать по всему списку, а не два последовательных. Делаем это с помощью функции gather. Вопросы работы с "вертикальным" или "горизонтальным" форматами данных очень хорошо описаны в официальной документации библиотеки tidyverse. Можно почитать тут.
Читаем данные с помощью функции read_csv2, также вручную определяем типы колонок через дополнительный параметр col_types. Это хорошая практика, т.к. сильно ускоряет загрузку. В нашем случае это не так важно, т.к. исходный csv содержит меньше 100 строк, но привыкаем писать правильно.
# Файл с IP VNX.
# Фильтруем по требуемым кластерам и сразу немного переформатируем его,
# чтобы все ip контроллеров А и В были в одной колонке.
VNX_ip <- vnxIPfilePath %>% read_csv2(
col_types = cols(
Name = col_character(),
IP = col_character(),
cl = col_character(),
type = col_character(),
newA = col_character(),
newB = col_character(),
oldA = col_character(),
oldB = col_character()
)
) %>%
filter(cl %in% productCls) %>%
gather(key = "cntName",
value = "cntIP",
5:6)На выходе получаем вот такой data frame (новые колонки — cntName и cntIP):
# A tibble: 30 x 8
Name IP cl type oldA oldB cntName cntIP
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 XXX 10.***.***.*~ XclNameX 5300~ 10.***.***.~ 10.***.***.~ newA 10.***.***.~
2 XXX 10.***.***.*~ XclNameX 5300~ 10.***.***.~ 10.***.***.~ newA 10.***.***.~
3 XXX 10.***.***.*~ XclNameX 5300~ 10.***.***.~ 10.***.***.~ newA 10.***.***.~
4 XXX 10.***.***.*~ XclNameX 5300~ 10.***.***.~ 10.***.***.~ newA 10.***.***.~
5 XXX 10.***.***.*~ XclNameX 5300~ 10.***.***.~ 10.***.***.~ newA 10.***.***.~
6 XXX 10.***.***.*~ XclNameX 5300~ 10.***.***.~ 10.***.***.~ newA 10.***.***.~
7 XXX 10.***.***.*~ XclNameX 5300~ 10.***.***.~ 10.***.***.~ newA 10.***.***.~
8 XXX 10.***.***.*~ XclNameX 5300~ 10.***.***.~ 10.***.***.~ newA 10.***.***.~
9 XXX 10.***.***.*~ XclNameX 5300~ 10.***.***.~ 10.***.***.~ newA 10.***.***.~
10 XXX 10.***.***.*~ XclNameX 5300~ 10.***.***.~ 10.***.***.~ newA 10.***.***.~
# ... with 20 more rows2-3. Запускаем через параллельные вычисления цикл по всем контроллерам с поиском записей о требуемых аварийных сообщениях. Результаты объединяем в data-frame
Далее — самое интересное. Параллельные вычисления.
В R несколько (скорее даже много) вариантов параллельных вычислений. Больше приглянулась связка из библиотек foreach и doParallel. Про них и другие варианты параллельных вычислений в R можно почитать тут.
Если коротко, то мы делаем всего 3 шага:
Шаг 1. Регистрируем ядрачистыйизумруд CPU для работы в параллельных вычислениях через registerDoParallel (в нашем случае мы сначала детектируем количество ядер на случай)
numCores <- detectCores()
registerDoParallel(numCores)Шаг 2. Запускаем цикл через foreach (не забываем указать оператор %dopar%, чтобы цикл шёл параллельно и указываем, через параметр .combine способ, которым будем собирать результат). В нашем случае .combine = rbind, потому что на выходе каждого цикла мы будем иметь data frame.
# Для каждой записи из списка VNX мы выдёргиваем ip и опрашиваем его.
# Если ошибок по отдельной записи нет, то больше ничего не делаем
# Если ошибки есть, то проделываем манипуляции по формированию dataframe
# Благодаря %dopar% запросы идут параллельно.
# Можно убедиться в этом, раскомментив вызов system.time и замерить так,
# а затем заменить %dopar% на %do%. Разница должна быть раза в 4-5.
# system.time({
errors_df <- foreach(i = 1:nrow(VNX_ip),
.combine = rbind,
.packages = "tidyverse") %dopar% {
errors_raw <- system(
paste(
"NaviSECCli.exe -scope 0 -h",
VNX_ip$cntIP[i],
"-user myusername -password mypassword getlog -date",
bigPeriodForm,
currDateForm
),
intern = TRUE
) %>%
str_subset(pattern = regex(paste0(errorNumbers, collapse = "|")))
# Если на контроллере искомых ошибок нет, то и остальные манипуляции не нужны
if (length(errors_raw) > 0) {
# Получаем текст описания ошибки
# Вырезаем текст по скобке круглой и квадратной,
# убираем кучу пробелов в конце,
# меняем пробелы между словами на нижние подчёркивания.
errorsDescr <- errors_raw %>%
gsub("(.*\\) )(.*)(\\s+\\[.*)",
"\\2",
x = .) %>%
trimws() %>%
gsub('([[:punct:]])|\\s+',
'_',
.)
# Переводим текст в таблицу и формируем из неё имена дисков
errors <- errors_raw %>%
str_split(pattern = "\\s+", simplify = T) %>%
as_tibble() %>%
mutate(Disk = paste0(V4, "_", V6, "_", V8) %>%
gsub(
pattern = "\\([0-9]{3}\\)",
replacement = "",
x = .)
)
# Формируем dataframe с необходимыми полями
data_frame(cl = VNX_ip$cl[i],
Storage = VNX_ip$Name[i],
Date = errors$V1 %>% as.Date(format = "%m/%d/%Y"),
Time = errors$V2,
Disk = errors$Disk,
Error = errorsDescr,
eCode = errors$V8 %>%
str_extract(paste0(errorNumbers, collapse = "|")) %>%
str_extract("[0-9]+")) %>%
mutate(DateTime = as.POSIXct(paste(Date, Time), format =
"%Y-%m-%d %H:%M:%S"))
}
}
# })Шаг 3. Очищаем созданный кластер параллелизма через stopImplicitCluster()
Чуть подробнее по получении читаемой таблицы из raw текста ошибок
В текстовом виде ошибки выглядят следующим образом:
head(errors_raw)
[1] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841d1080 10006 "
[2] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841e1a00 10006 "
[3] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 8420b600 10006 "
[4] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 84206900 10006 "
[5] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841fc900 10006 "
[6] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841fc000 10006Тут у нас значения, разделённые пробелом, которые, на первый взгляд, даже в csv нормально вставятся. Но всё не так просто. Сложность парсинга тут в том, что:
- дата и время также разделены пробелом (наименьшее из зол);
- текст ошибок состоит из "слов", т.е. тоже разделён пробелом;
- между номером диска и кодом ошибки (который в скобках) пробела почему-то нет.
В общем, рай для любителя регулярных выражений :)

Подробно на парсинге останавливаться не буду, потому что это дело вкуса, но уточню, что текст ошибки пришлось выдирать отдельно, как значения, расположенные между закрывающей круглой скобкой номера ошибки и открывающей квадратной скобкой какого-то другого значения. В цикле это переменная errors.
Также интересный момент, что для удобства формирования конечного data frame, мы, желая сделать цикл по ip адресам контроллеров, задаём последовательность не через колонку с ip адресами контроллеров (т.е. i = VNX_ip$cntIP), а через номер строки (т.е. i = 1:nrow(VNX_ip)). Это позволяет нам при формировании data frame с уже распарсенными ошибками добавить номер кластера и имя СХД через вызовы VNX_ip$cl[i] и VNX_ip$Name[i] соответственно. Без этого пришлось бы делать джойны, что было бы медленнее и хуже читалось бы в коде.
В конечном итоге получаем data frame (а если честно, то tibble, но разница выходит за рамки статьи), который содержит все нужные нам данные. Т.е. на какой СХД, на каком диске, когда возникла какая ошибка.
> errors_df
# A tibble: 2,705 x 8
cl Storage Date Time Disk Error eCode DateTime
<chr> <chr> <date> <chr> <chr> <chr> <chr> <dttm>
1 XclNam~ XStorageN~ 2019-07-18 12:09:~ 0_1_3 Soft_SCSI_~ 801 2019-07-18 12:09:55
2 XclNam~ XStorageN~ 2019-07-18 15:09:~ 0_1_3 Soft_SCSI_~ 801 2019-07-18 15:09:56
3 XclNam~ XStorageN~ 2019-07-18 16:28:~ 0_1_3 Soft_SCSI_~ 801 2019-07-18 16:28:50
4 XclNam~ XStorageN~ 2019-07-19 06:36:~ 0_1_6 Soft_SCSI_~ 801 2019-07-19 06:36:39
5 XclNam~ XStorageN~ 2019-07-19 20:57:~ 0_1_6 Soft_Media~ 820 2019-07-19 20:57:35
6 XclNam~ XStorageN~ 2019-07-22 11:00:~ 0_2_~ Soft_SCSI_~ 801 2019-07-22 11:00:43
7 XclNam~ XStorageN~ 2019-07-22 11:00:~ 0_2_~ Soft_SCSI_~ 801 2019-07-22 11:00:44
8 XclNam~ XStorageN~ 2019-07-22 12:02:~ 0_2_~ Soft_SCSI_~ 801 2019-07-22 12:02:31
9 XclNam~ XStorageN~ 2019-07-23 23:29:~ 0_3_8 Soft_SCSI_~ 801 2019-07-23 23:29:49
10 XclNam~ XStorageN~ 2019-07-13 00:01:~ 0_3_9 Soft_SCSI_~ 801 2019-07-13 00:01:46
# ... with 2,695 more rowsСамое шикарное, что весь цикл по параллельному опросу всех СХД занимает не 45 минут, а 30 секунд.
Слава богу, что это не тот случай, когда 30 секунд — это слишком быстро.

Стоит уточнить, что код на PowerShell также в цикле собирал серийные номера дисков со всех СХД, а на момент переписывания кода на R эти данные оказались лишними. Так что сравнение времени выполнения не совсем честное, но всё равно впечатляющее.
4-5. Обработка и преобразование данных. Формирование xlsx документа
Преобразование данных для xlsx документов свелось к фильтрации исходной таблицы по 3 последним дням, а также по последнему месяцу и преобразовании колонок с именами ошибок в "горизонтальный" формат, чтобы каждый тип ошибок был в отдельной колонке. Для этого была написана отдельная функция (чтобы 2 раза не дублировать одни и те же шаги)
myErrorStats <- function(data, period, orderColname = quo(Soft_Media_Error)) {
data %>%
filter(Date > period) %>%
group_by(cl, Storage, Disk, Error) %>%
summarise(count = n()) %>%
spread(Error, count, fill = 0) %>%
arrange(desc(!!orderColname))
}Для отображения типов ошибок в отдельной колонке была применена функция spread с дополнительным ключом fill = 0, с помощью которого недостающие значения были заполнены 0. Без этого ключа, если бы в какой-то день не было какого-то типа ошибок — в соответствующей колонке были бы значения NA.
Также в функции хотелось сохранить возможность передать имя колонки для сортировки в виде переменной, но при этом иметь для этой переменной значения по умолчанию. Для этого используется своебразный синтаксис dplyr, про который подробнее можно почитать тут.
В нашем случае, при определении параметров функции, мы задаём одному из них значение по умолчанию и квотируем его (orderColname = quo(Soft_Media_Error)), а затем, при вызове, ставим перед ним символы !!, чтобы получилось arrange(desc(!!orderColname)).
> errorsBigPeriod
# A tibble: 77 x 7
cl Storage Disk Hard_SCSI_Bus_E~ Recommend_Disk_~ Soft_Media_Error
<chr> <chr> <chr> <dbl> <dbl> <dbl>
1 XclN~ XStora~ 1_1_~ 0 1 64
2 XclN~ XStora~ 0_2_5 0 0 29
3 XclN~ XStora~ 1_1_~ 0 1 29
4 XclN~ XStora~ 0_3_2 0 0 27
5 XclN~ XStora~ 0_3_~ 1 0 25
6 XclN~ XStora~ 1_3_5 0 1 23
7 XclN~ XStora~ 0_2_9 0 0 21
8 XclN~ XStora~ 0_3_4 0 0 14
9 XclN~ XStora~ 0_1_~ 0 0 14
10 XclN~ XStora~ 1_0_1 0 0 12
# ... with 67 more rows, and 1 more variable: Soft_SCSI_Bus_Error <dbl>Формирование xlsx документа я разбирал в статье по отчётам о состоянии ВМ, поэтому подробно останавливаться не буду. Весь код приведён в конце статьи.

Тут важные особенности, которые повышают читаемость отчёта:
- Подписанные вкладки (по умолчанию открыта наиболее интересная);
- выделенные имена колонок;
- автоформатирование всех колонок, чтобы весь текст был читаем без необходимости раздвигать колонки.
6. формируем график, который сохраняем в png
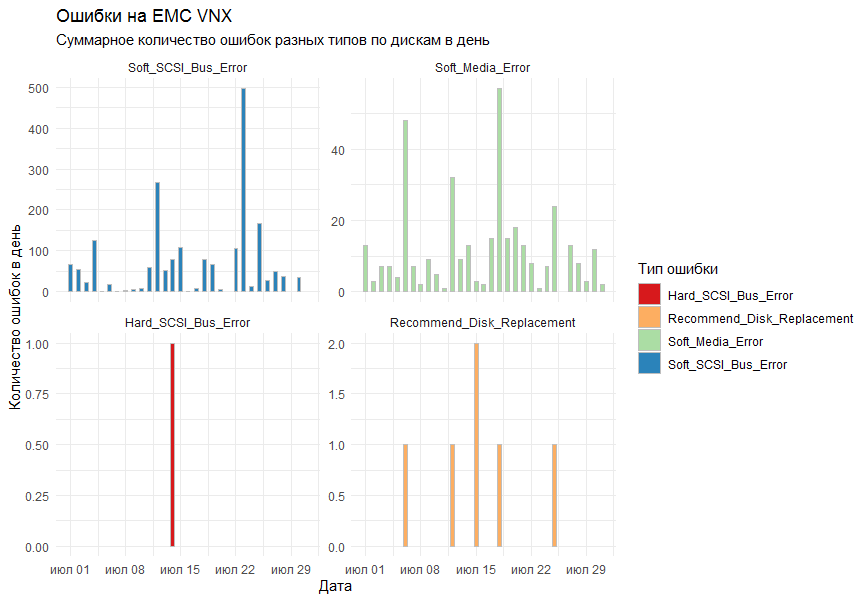
На графике хотелось получить суммарное по всем СХД количество ошибок в день с разбивкой по типам. В качестве средства рисования было решено использовать стандартную библиотеку ggplot2.
Первый вариант графика показывал все ошибки на одном графике и выглядел вот так:

Коллеги сказали, что получилось нечитаемо.
Что бы они понимали?!!!!
Замечания были учтены и к стандартном столбикам (geom_bar) была добавлена функция facet_grid для разделения результата на отдельные графики по типам ошибок.
Итоговый результат всех устроил.

#### Формируем графики ####
# Смотрим ошибки по типам по дням
errorsTotal <- errors_df %>%
group_by(Date, Error) %>%
summarise(count = n()) %>%
# spread(Error, count, fill = 0) %>%
arrange(desc(Date))
# Рисуем график событий по дням и по типам.
# Названия ошибок передаём в виде отсортированного фактора, чтобы порядок был.
plot <-
errorsTotal %>% ggplot(aes(x = Date, y = count, fill = Error)) +
geom_bar(stat = "identity",
width = 0.5,
color = "grey") +
theme_minimal() +
# theme(legend.position="top") +
scale_color_grey() +
labs(title = "Ошибки на EMC VNX",
subtitle = "Суммарное количество ошибок разных типов по дискам в день",
fill = "Тип ошибки") +
xlab("Дата") +
ylab("Количество ошибок в день") +
scale_fill_brewer(palette = "Spectral") +
facet_grid(rows = vars(factor(
Error,
levels = c(
"Soft_SCSI_Bus_Error",
"Soft_Media_Error",
"Hard_SCSI_Bus_Error",
"Recommend_Disk_Replacement"
)
)))
# # Выводим график
# plot
# Путь к png, который будет содержать график
plot_filePath <- file.path("results", "plot.png")
# Сохраняем график в png для вставки в почту
ggsave(filename = plot_filePath, plot = plot)Из интересного в формировании графика.
Хотелось, чтобы графики были в определённом порядке. Для этого параметр формирования рядов в facet_grid пришлось передавать в виде фактора (factor), а точнее даже упорядоченного фактора (ordered factor). Factor — это такой хитрый формат данных в R, который представляет из себя набор значений (в нашем случае строк, т.е. character-ов), причём набор этих значений строго определён (называется уровнями фактора), да ещё эти уровни и отсортированы. Звучит сложно, но всё встаёт на свои места, если сказать, что названия месяцев — это отличный пример упорядоченного фактора. Т.е. мы знаем, какие названия могут быть у месяцев, а также знаем (ну я надеюсь), что сначала идёт Январь, потом Февраль, потом Март и т.д. Вот по этому же принципу мы и создаём фактор.
7-8. Формируем письмо, содержащее собранные данные. Отправляем письмо
Формирование и отправка письма, а также формирование задания в Windows scheduller также была рассмотрена в статье по отчётам по состоянию ВМ. Просто выносим в текст несколько переменных и более-менее понятно форматируем. Не забываем вложения.

Выводы
R в очередной раз показал себя, как универсальный инструмент для выполнения повседневных задач и визуального представления их результатов. А с подключением параллельных вычислений этот инструмент становится ещё и быстрым.
Также практика показала, что PowerShell показывает себя крайне медленно на задачах по парсингу логов и переводу их в читаемый формат.
Большое спасибо всем, кто дочитал до конца столь большое количество букв.
Полностью код приложения
#### ENV ####
# Это нужно для корректной работы из под шедуллера (он считает домашней дирректорией system32)
setwd("C:\\Scripts\\VNX_disks_check/")
# Подгружаем библиотеки
library(tidyverse)
library(lubridate)
library(zoo)
library(stringi)
library(xlsx)
library(mailR)
library(foreach)
library(doParallel)
#### CONST ####
# Определяем пути к исходным и конечным файлам и другие постоянные переменные
vnxIPfilePath <- file.path("data", "VNX-IP.csv")
# Большой период поиска проблем
bigPeriod <- Sys.Date() - 30
# Маленький период поиска проблем
smallPeriod <- Sys.Date() - 3
# Список продуктивных контроллеров
productCls <- c("name1", "name2", "name3")
# Файл с IP VNX.
# Фильтруем по требуемым кластерам и сразу немного переформатируем его,
# чтобы все ip контроллеров А и В были в одной колонке.
VNX_ip <- vnxIPfilePath %>% read_csv2(
col_types = cols(
Name = col_character(),
IP = col_character(),
cl = col_character(),
type = col_character(),
newA = col_character(),
newB = col_character(),
oldA = col_character(),
oldB = col_character()
)
) %>%
filter(cl %in% productCls) %>%
gather(key = "cntName",
value = "cntIP",
5:6)
#### Запрашиваем ошибки с VNX ####
# В общем виде вызов команды выглядит вот так (да пароль в тексте в окрытом виде)
# NaviSECCli.exe -scope 0 -h 10.201.16.15 -user root -password Secrt4yo getlog -date 07/16/2019 07/17/2019
# Формируем список ошибок, которые хотим выцепить.
# Сразу добавляем скобки и экранируем их, чтобы можно было использовать в регулярках
errorNumbers <- c("\\(820\\)", "\\(803\\)", "\\(801\\)", "\\(920\\)", "\\(901\\)")
## Пробуем запараллелить ##
# Определяем количество ядер и регистрируем их для паралелизма
numCores <- detectCores()
registerDoParallel(numCores)
# Переводим даты в формат, который понимает NaviCLI
# Добавляем 1 день к текущей дате, чтобы смотреть аварии по "завтрашний" день,
# т.е. по текущий момент, а не на полночь сегодняшеного дня, как будет без этой хитрости.
bigPeriodForm <- bigPeriod %>% format(format = "%m/%d/%Y")
currDateForm <- (Sys.Date() + 1) %>% format(format = "%m/%d/%Y")
# Запускаем наш сложный процесс.
# Для каждой записи из списка VNX мы выдёргиваем ip и опрашиваем его.
# Если ошибок по отдельной записи нет, то больше ничего не делаем
# Если ошибки есть, то проделываем манипуляции по формированию dataframe
# Благодаря %dopar% запросы идут параллельно.
# Можно убедиться в этом, раскомментив вызов system.time и замерить так,
# а затем заменить %dopar% на %do%. Разница должна быть раза в 4-5.
# system.time({
errors_df <- foreach(i = 1:nrow(VNX_ip),
.combine = rbind,
.packages = "tidyverse") %dopar% {
errors_raw <- system(
paste(
"NaviSECCli.exe -scope 0 -h",
VNX_ip$cntIP[i],
"-user myusername -password mypassword getlog -date",
bigPeriodForm,
currDateForm
),
intern = TRUE
) %>%
str_subset(pattern = regex(paste0(errorNumbers, collapse = "|")))
# Если на контроллере искомых ошибок нет, то и остальные манипуляции не нужны
if (length(errors_raw) > 0) {
# Вырезаем текст по скобке круглой и квадратной,
# убираем кучу пробелов в конце,
# меняем пробелы между словами на нижние подчёркивания.
errorsDescr <- errors_raw %>%
gsub("(.*\\) )(.*)(\\s+\\[.*)",
"\\2",
x = .) %>%
trimws() %>%
gsub('([[:punct:]])|\\s+',
'_',
.)
# Переводим текст в таблицу и формируем из неё имена дисков
errors <- errors_raw %>%
str_split(pattern = "\\s+", simplify = T) %>%
as_tibble() %>%
mutate(Disk = paste0(V4, "_", V6, "_", V8) %>%
gsub(
pattern = "\\([0-9]{3}\\)",
replacement = "",
x = .)
)
# Формируем dataframe с необходимыми полями
data_frame(cl = VNX_ip$cl[i],
Storage = VNX_ip$Name[i],
Date = errors$V1 %>% as.Date(format = "%m/%d/%Y"),
Time = errors$V2,
Disk = errors$Disk,
Error = errorsDescr,
eCode = errors$V8 %>%
str_extract(paste0(errorNumbers, collapse = "|")) %>%
str_extract("[0-9]+")) %>%
mutate(DateTime = as.POSIXct(paste(Date, Time), format =
"%Y-%m-%d %H:%M:%S"))
}
}
# })
# Очищаем от нагрузки кластер паралелизма. Не уверен в обязательности этого действия, но в примерах так.
stopImplicitCluster()
#### Обработка ####
# Функция по обработке таблиц. Хитрые формы записи нужны, чтобы передавать переменную в колонку. Ниже подробнее.
# https://dplyr.tidyverse.org/articles/programming.html
myErrorStats <- function(data, period, orderColname = quo(Soft_Media_Error)) {
data %>%
filter(Date > period) %>%
group_by(cl, Storage, Disk, Error) %>%
summarise(count = n()) %>%
spread(Error, count, fill = 0) %>%
arrange(desc(!!orderColname))
}
# Строим все ошибки за большой период и разбиваем ошибки по типам. Используем функцию.
errorsBigPeriod <- errors_df %>%
myErrorStats(bigPeriod)
# Смотрим все ошибки за маленький период и аналогично разбиваем ошибки по типам
errorsSmallPeriod <- errors_df %>%
myErrorStats(smallPeriod)
# Путь к файлу, куда хотим сохранить результаты
errors_filePath <- file.path("results", "VNX_Errors.xlsx")
#### Создание xlsx документа ####
# Создаём новую книгу
wb<-createWorkbook(type="xlsx")
# Стили для именов рядов и колонок в таблицах
TABLE_ROWNAMES_STYLE <- CellStyle(wb) + Font(wb, isBold=TRUE)
TABLE_COLNAMES_STYLE <- CellStyle(wb) + Font(wb, isBold=TRUE) +
Alignment(wrapText=TRUE, horizontal="ALIGN_CENTER") +
Border(color="black", position=c("TOP", "BOTTOM"),
pen=c("BORDER_THIN", "BORDER_THICK"))
# Создаём новыt листs
sheetSmall <- createSheet(wb, sheetName = "Последние 3 дня")
sheetBig <- createSheet(wb, sheetName = "Последний месяц")
sheetRaw <- createSheet(wb, sheetName = "Сырые данные")
## Добавляем таблицы
addDataFrame(
errorsSmallPeriod %>% as.data.frame(),
sheetSmall,
startRow = 1,
startColumn = 1,
row.names = FALSE,
byrow = FALSE,
colnamesStyle = TABLE_COLNAMES_STYLE,
rownamesStyle = TABLE_ROWNAMES_STYLE
)
addDataFrame(
errorsBigPeriod %>% as.data.frame(),
sheetBig,
startRow = 1,
startColumn = 1,
row.names = FALSE,
byrow = FALSE,
colnamesStyle = TABLE_COLNAMES_STYLE,
rownamesStyle = TABLE_ROWNAMES_STYLE
)
# В сырых данных дополнительно собираем из двух колонок колонку DateTime и сортируем по ней
addDataFrame(
errors_df %>%
as.data.frame() %>%
arrange(desc(DateTime)),
sheetRaw,
startRow = 1,
startColumn = 1,
row.names = FALSE,
byrow = FALSE,
colnamesStyle = TABLE_COLNAMES_STYLE,
rownamesStyle = TABLE_ROWNAMES_STYLE
)
# Меняем ширину, чтобы форматирование было автоматическим
autoSizeColumn(sheet = sheetSmall, colIndex=c(1:ncol(errorsSmallPeriod)))
autoSizeColumn(sheet = sheetBig, colIndex=c(1:ncol(errorsBigPeriod)))
autoSizeColumn(sheet = sheetRaw, colIndex=c(1:ncol(errors_df)))
# Проверяем есть ли такой файл. Если есть - удаляем.
if (file.exists(errors_filePath)) {file.remove(errors_filePath)}
# Сохраняем xlsx документ
saveWorkbook(wb, errors_filePath)
#### Формируем графики ####
# Смотрим ошибки по типам по дням
errorsTotal <- errors_df %>%
group_by(Date, Error) %>%
summarise(count = n()) %>%
# spread(Error, count, fill = 0) %>%
arrange(desc(Date))
# Рисуем график событий по дням и по типам
plot <-
errorsTotal %>% ggplot(aes(x = Date, y = count, fill = Error)) +
geom_bar(stat = "identity",
width = 0.5,
color = "grey") +
theme_minimal() +
# theme(legend.position="top") +
scale_color_grey() +
labs(title = "Ошибки на EMC VNX",
subtitle = "Суммарное количество ошибок разных типов по дискам в день",
fill = "Тип ошибки") +
xlab("Дата") +
ylab("Количество ошибок в день") +
scale_fill_brewer(palette = "Spectral") +
facet_grid(rows = vars(factor(
Error,
levels = c(
"Soft_SCSI_Bus_Error",
"Soft_Media_Error",
"Hard_SCSI_Bus_Error",
"Recommend_Disk_Replacement"
)
)))
# # Выводим график
# plot
# Путь к png, который будет содержать график
plot_filePath <- file.path("results", "plot.png")
# Сохраняем график в png для вставки в почту
ggsave(filename = plot_filePath, plot = plot)
#### Формируем электронное письмо ####
# Список получателей почты
emailRecepientsList <- c("sendall-tech@domain.ru")
# Параметры для отправки электронной почты
emailParams <- list(
from = "login@domain.ru",
to = emailRecepientsList,
smtpParams = list(
host.name = "10.10.10.1",
port = 25,
user.name = "login@domain.ru",
passwd = "mypassword",
ssl = FALSE
)
)
# Сумма ошибок всех типов (убираем лишние колонки и складываем).
# Делаем через вычитание первых строк, потому что в ошибок какого то типа может не быть, а мне лень писать исключения.
errorsTotal <- errorsSmallPeriod[-c(1,2,3)] %>% sum()
# Формируем тело письма
emailBody <- paste0(
'<html>
<h3>Добрый день, уважаемые коллеги.</h3>
<p>За последние 3 дня было зафиксировано <strong>', errorsTotal, '</strong> ошибок на дисках EMC VNX</p>
<p>Детальную информацию вы можете посмотреть на графике ниже, а также в файле во вложении.</p>
<p>Файл имеет 3 вкладки:
<ul>
<li>Данные за последние 3 дня. Отсортировано по <strong>Soft_Media_Error</strong>.</li>
<li>Данные за 30 дней. Отсортировано по <strong>Soft_Media_Error</strong>.</li>
<li>Сырые данные. Отсортировано по <strong>Дате</strong>.</li>
</ul>
На дисках с большим количеством ошибок велика вероятность скорого отказа. Их рекомендуется заменить.</p>
<p><img src="', plot_filePath, '"></p>
</html>'
)
#### Формируем письмо с плохоподписанными машинами ####
send.mail(from = emailParams$from,
to = emailParams$to,
subject = "Сводка по ошибкам на дисках EMC VNX",
body = emailBody,
encoding = "utf-8",
html = TRUE,
inline = TRUE,
smtp = emailParams$smtpParams,
authenticate = TRUE,
send = TRUE,
attach.files = c(errors_filePath),
debug = FALSE)Параметры окружения и версии используемого ПО
- Модели СХД: EMC VNX 5300
- Версия ПО для опроса СХД: NaviCLI-Win-32-x86-en_US-7.31.25.1.29-1
- Параметры виртуальной машины, с которой запускается скрипт: 4*2 CPU, 8 Gb RAM
> sessionInfo()
R version 3.5.3 (2019-03-11)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows Server 2012 R2 x64 (build 9600)
Matrix products: default
locale:
[1] LC_COLLATE=Russian_Russia.1251 LC_CTYPE=Russian_Russia.1251 LC_MONETARY=Russian_Russia.1251
[4] LC_NUMERIC=C LC_TIME=Russian_Russia.1251
attached base packages:
[1] parallel stats graphics grDevices utils datasets methods base
other attached packages:
[1] taskscheduleR_1.4 pander_0.6.3 doParallel_1.0.14 iterators_1.0.10 foreach_1.4.4 mailR_0.4.1
[7] xlsx_0.6.1 stringi_1.4.3 zoo_1.8-6 lubridate_1.7.4 wesanderson_0.3.6 forcats_0.4.0
[13] stringr_1.4.0 dplyr_0.8.3 purrr_0.3.2 readr_1.3.1 tidyr_0.8.3 tibble_2.1.3
[19] ggplot2_3.2.0 tidyverse_1.2.1
loaded via a namespace (and not attached):
[1] tidyselect_0.2.5 reshape2_1.4.3 rJava_0.9-11 haven_2.1.1 lattice_0.20-38 colorspace_1.4-1
[7] vctrs_0.2.0 generics_0.0.2 utf8_1.1.4 rlang_0.4.0 R.oo_1.22.0 pillar_1.4.2
[13] glue_1.3.1 withr_2.1.2 R.utils_2.9.0 RColorBrewer_1.1-2 modelr_0.1.4 readxl_1.3.1
[19] plyr_1.8.4 munsell_0.5.0 gtable_0.3.0 cellranger_1.1.0 rvest_0.3.4 R.methodsS3_1.7.1
[25] codetools_0.2-16 labeling_0.3 fansi_0.4.0 xlsxjars_0.6.1 broom_0.5.2 Rcpp_1.0.1
[31] scales_1.0.0 backports_1.1.4 jsonlite_1.6 digest_0.6.20 hms_0.5.0 grid_3.5.3
[37] cli_1.1.0 tools_3.5.3 magrittr_1.5 lazyeval_0.2.2 crayon_1.3.4 pkgconfig_2.0.2
[43] zeallot_0.1.0 data.table_1.12.2 xml2_1.2.0 assertthat_0.2.1 httr_1.4.0 rstudioapi_0.10
[49] R6_2.4.0 nlme_3.1-137 compiler_3.5.3






