С момента своего анонса технология WebAssembly сразу привлекла внимание разработчиков фронтенда. Веб-сообщество с энтузиазмом восприняло идею запустить в браузере код, написанный на других языках, кроме JavaScript. Главное, что WebAssembly гарантирует скорость намного выше, чем JavaScript.
Наши инженеры внимательно следили за развитием стандарта. Как только поддержку WebAssembly 1.0 внедрили во всех основных браузерах, разработчики сразу захотели опробовать её.
Но тут возникла проблема. Хотя многие приложения выигрывают от WebAssembly, но область применения технологии в электронной коммерции всё ещё примитивна. Мы не смогли сразу найти правильный вариант её использования. Было несколько предложений, но во всех вариантах JavaScript подходил лучше. Когда мы в eBay оцениваем новые технологии, то первый вопрос: «Какова потенциальная выгода для наших клиентов?» Если здесь нет ясности, мы не переходим к следующему шагу. Очень легко увлечься новой модной технологией, даже если она не имеет никакого значения для клиентов и только усложняет существующий рабочий процесс. Пользовательский опыт всегда важнее опыта разработчика. Но с WebAssembly иначе. У этой технологии огромный потенциал, просто мы не могли найти правильный вариант использования. Впрочем, в итоге всё-таки нашли.
В нативных приложениях eBay на iOS и Android есть функция сканирования штрих-кодов UPC для автоматического введения в форму. Она работает только в приложениях и требует интенсивной обработки изображений на устройстве, чтобы распознать цифры штрих-кода в потоке изображений от камеры. Полученный код затем отправляется в серверную службу, которая, в свою очередь, заполняет форму. Это означает, что логика обработки изображений на устройстве должна быть очень эффективной. Для нативных приложений мы скомпилировали собственную библиотеку C++ в нативный код для iOS и Android. Он исключительно хорошо распознаёт штрих-коды. Мы постепенно переходим на нативные API в iOS и Android, но наша библиотека C++ по-прежнему надёжна.
Сканер штрих-кодов — интуитивно понятная функция для продавцов, она заметно упрощает заполнение формы. К сожалению, эта функция не работала на мобильной версии сайта, а продавцам приходилось вручную вводить UPC, что неудобно.
Мы раньше искали вариант сканирования штрих-кодов в вебе. Два года назад даже выпустили прототип на базе открытой JavaScript-библиотеки BarcodeReader. Проблема заключалась в том, что он хорошо работал только в 20% случаев. Остальные 80% времени сканер работал исключительно медленно или вообще не срабатывал. В большинстве случаев это был тайм-аут. Вполне ожидаемо: JavaScript может сравниться по скорости с нативным кодом только если находится на «горячем пути», т. е. сильно оптимизирован JIT-компиляторами. Хитрость в том, что движки JavaScript используют многочисленные эвристики для определения, является ли путь «горячим», не гарантируя результат. Это несоответствие, очевидно, привело к разочарованию пользователей, и нам пришлось отключить эту функцию. Но теперь всё иначе. С быстрым развитием веб-платформы возник вопрос: «Можно ли реализовать в вебе надёжный сканер штрих-кодов?»
Один из вариантов — подождать выхода Shape Detection API cо встроенными функциями обнаружения изображений, в том числе штрих-кодов. Но эти интерфейсы пока на очень ранней стадии разработки и далеки от кроссбраузерной совместимости. И даже в этом случае не гарантируется работа на всех платформах. Поэтому придётся рассмотреть другие варианты.
Здесь в игру вступает WebAssembly. Если сканер штрих-кодов реализован на WebAssembly, то он гарантированно будет работать. Сильная типизация и структура байт-кода WebAssembly позволяют всегда сохранять «горячий путь» выполнения. Кроме того, у нас уже есть библиотека C++ для нативных приложений. Библиотеки C++ — идеальные кандидаты для компиляции в WebAssembly. Мы думали, что проблема решена. Оказалось, не совсем.
Рабочий прототип архитектуры для сканера штрих-кодов на WebAssembly был довольно простым.
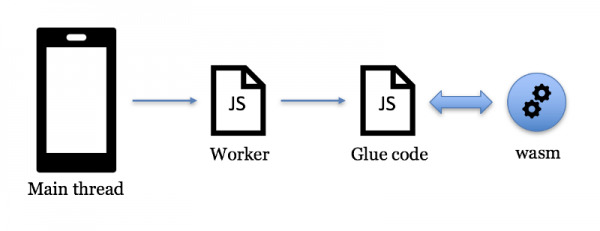
Рабочий Процесс WebAssembly
Первый шаг в любом проекте WebAssembly — определить чёткий конвейер компиляции. Emscripten стал стандартом де-факто для компиляции WebAssembly, но важно иметь согласованную среду, которая выдаёт детерминированный результат. Наш фронтенд основан на Node.js, так что нужно найти решение, совместимое с рабочим процессом npm. К счастью, примерно в то время Сурма Дас опубликовал статью «Emscripten и npm». Подход на основе Docker для компиляции WebAssembly имеет смысл, поскольку устраняет кучу накладных расходов. Как рекомендовано в статье, мы взяли докеровский образ Emscripten от trzeci. Чтобы стала возможной компиляция в WebAssembly, нативную библиотеку C++ пришлось немного подправить. В основном, мы действовали наугад, методом проб и ошибок. В конце концов удалось её скомпилировать, а также настроить аккуратный рабочий процесс WebAssembly в рамках существующего конвейера сборки.
Производительность сканера измеряется по количеству кадров, обрабатываемых Wasm API за секунду. Wasm API берёт кадр из видеопотока камеры, выполняет вычисления и возвращает ответ. Это делается на постоянной основе, пока не обнаружен штрих-код. Производительность измеряется в FPS.
Наша реализация WebAssembly при тестировании показала удивительную скорость 50 FPS. Однако срабатывала только в 60% случаев, а в остальных вылетала по тайм-ауту. Даже при таком высоком FPS они не могли быстро обнаружить штрих-код для оставшихся 40% сканирований, выдавая в конце предупреждающее сообщение. Для сравнения, прежняя реализация на JavaScript обычно работала на скорости 1 FPS. Да, WebAssembly намного быстрее (в 50 раз), но почему-то не срабатывает почти в половине случаев. Следует также отметить, что в некоторых ситуациях JavaScript работал очень хорошо и сразу находил штрих-код. Одним из очевидных вариантов было увеличить тайм-аут, но это лишь увеличит разочарование пользователей, и так мы не решаем настоящую проблему. Поэтому мы отказались от этой идеи.
Сначала мы не могли понять, почему нативная библиотека C++, которая отлично работала в нативных приложениях, не показала такой же результат в вебе. После длительного тестирования и отладки мы обнаружили, что скорость распознавания зависит от угла фокусировки объекта и фоновой тени. Но как же тогда всё работает в нативных приложениях? Дело в том, что в нативных приложениях мы используем встроенные API для автофокусировки и предоставляем пользователю возможность сфокусироваться вручную, указав пальцем на штрих-код. Поэтому нативные приложения всегда предоставляют библиотеке высококачественные чёткие изображения.
Осознав суть происходящего, мы решили попробовать другую нативную библиотеку: довольно популярный и стабильный сканер штрих-кодов ZBar с открытым исходным кодом. Что ещё более важно, он хорошо работает с размытыми и зернистыми изображениями. Почему бы не попробовать? Поскольку у нас уже был рабочий процесс WebAssembly, компиляция и деплой ZBar в WebAssembly прошли без проблем. Производительность оказалась приличной, около 15 FPS, хотя и не такая хорошая, как у нашей собственной библиотеки C++. Зато показатель успеха оказался близок к 80% для того же тайм-аута. Явное улучшение по сравнению с нашей библиотекой C++, но всё равно не 100%.
Результат нас ещё не удовлетворял, но мы заметили нечто неожиданное. Там, где Zbar вылетал по тайм-ауту, наша собственная библиотека C++ выполняла работу очень быстро. Это был приятный сюрприз. Похоже, библиотеки по-разному обрабатывали снимки разного качества. Это навело нас на идею.
Наверное, вы уже поняли. Почему бы не создать два потока воркеров: один для Zbar, а другой для нашей библиотеки C++, и не запустить их параллельно. Кто победил (кто первым пришлёт действительный штрих-код), тот отправляет результат в основной поток, и оба воркера останавливаются. Мы реализовали такой сценарий и начали сами тестировать, пытаясь сымитировать как можно больше сценариев. Такая настройка показала 95% успешных сканирований. Намного лучше, чем предыдущие результаты, но всё равно не 100%.
Одним из странных предложений было добавить в соревнование оригинальную библиотеку JavaScipt. Это будет три потока. Мы честно не думали, что это что-то изменит. Но такой тест не требовал никаких усилий, потому что мы стандартизировали рабочий интерфейс. К нашему удивлению, с тремя потоками показатель успеха действительно приблизился к 100%. Это опять было совершенно неожиданно. Как упоминалось ранее, JavaScript очень хорошо работал в некоторых ситуациях. Судя по всему, он закрыл разрыв. Так что народная мудрость права — «JavaScript всегда выигрывает». Если без шуток, на следующей иллюстрации представлен обзор окончательной архитектуры, которую мы реализовали.
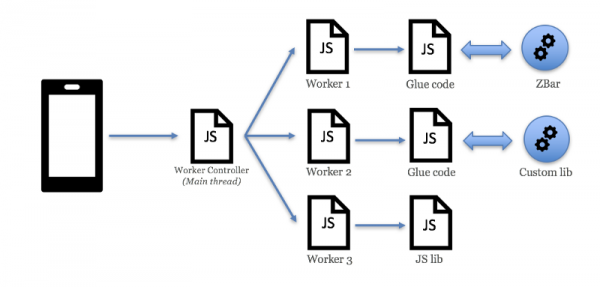
Веб-архитектура сканера штрих-кодов
На следующем рисунке показана функциональная схема высокого уровня:
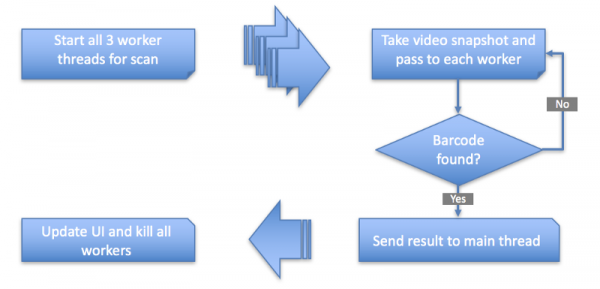
Функциональная схема сканера штрих-кодов
Ресурсы, необходимые для работы сканера, предварительно загружаются после рендеринга главной страницы. Таким образом целевая страница загружается быстро, при этом она готова к взаимодействию. Ресурсы WebAssembly (файлы wasm и скрипты связующего кода) и библиотека сканера JavaScript предварительно загружаются и кэшируются с помощью XMLHttpRequest после загрузки основной страницы. Здесь важно, что они не выполняются сразу, чтобы оставить основной поток свободным для взаимодействия пользователя со страницей. Выполнение происходит только когда пользователь нажимает на значок штрих-кода. Если пользователь нажал на значок до загрузки ресурсов, то они загружатся по требованию и немедленно выполняются. Обработчик событий сканера штрих-кодов и контроллер воркера загружаются вместе со страницей, но они очень маленькие.
После тщательного тестирования и внутреннего использования сотрудниками, мы запустили A/B-тестирование на пользователях. Тестовой группе показывалась иконка сканера (скриншот ниже), а контрольной группе — нет.

Конечный продукт
Для оценки успеха мы ввели метрику «скорость завершения черновиков» (Draft Completion Rate). Это время между началом редактирования черновика и отправкой формы. Метрика должна показать, насколько сканер штрих-кодов помогает людям в заполнении форм. Тест продолжался несколько недель, а результаты оказались очень приятными. Они полностью согласуются с нашей первоначальной гипотезой. Время завершения черновика уменьшилось на 30% для потока со сканером штрих-кодов.
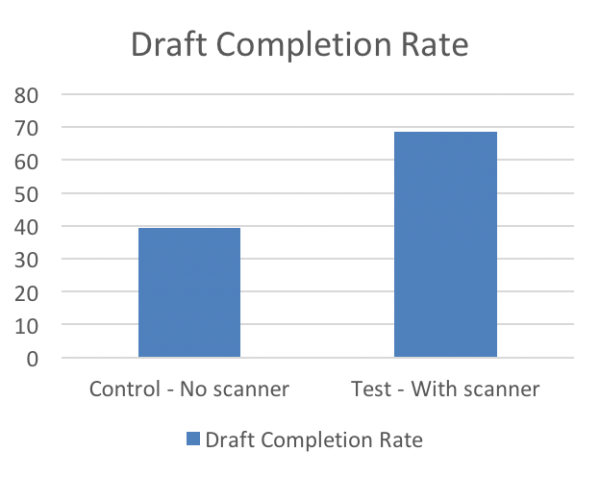
Результаты A/B-тестирования
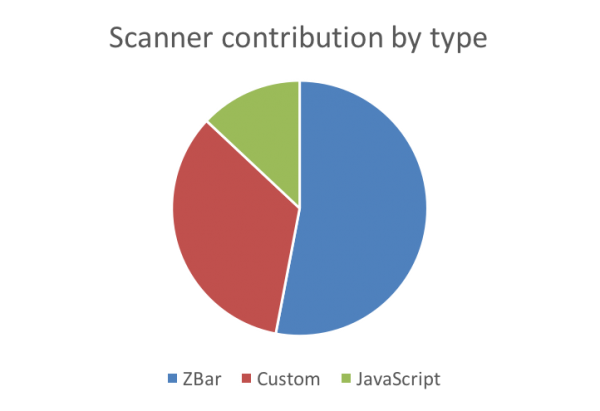
Мы также добавили профилирование, чтобы оценить эффективность всех типов сканера. Как и ожидалось, наибольший вклад внёс Zbar (53% успешных сканирований), затем наша библиотека C++ (34%) и, наконец, библиотека JavaScript с 13%.
Опыт внедрения WebAssembly стал для нас весьма познавательным. Инженеры очень радуются появлению новых технологий и сразу хотят их опробовать. Если технология ещё и полезна для клиентов, то это двойная радость. Повторим мысль, высказанную в начале статьи. Технология развивается очень быстрыми темпами. Каждый день появляется что-то новое. Но лишь немногие технологии имеют значение для клиентов, а WebAssembly — одна из них. Наш самый большой вывод из этого упражнения — говорить «нет» в 99-ти ситуациях и «да» в том единственном случае, когда это действительно важно для клиентов.
В дальнейшем мы планируем расширить использование сканера штрих-кодов и внедрить его на стороне покупателей, чтобы они могли сканировать коды товаров в офлайне для их поиска и покупки на eBay. Также рассмотрим вариант расширения функции с помощью Shape Detection API и других функций в браузере. Но мы рады, что нашли правильный вариант использования WebAssembly на eBay и успешно применили технологию в электронной коммерции.
Особая благодарность Сурме Дасу и Лин Кларк за многочисленные статьи о WebAssembly. Они действительно несколько раз помогли нам выйти из тупика.
Наши инженеры внимательно следили за развитием стандарта. Как только поддержку WebAssembly 1.0 внедрили во всех основных браузерах, разработчики сразу захотели опробовать её.
Но тут возникла проблема. Хотя многие приложения выигрывают от WebAssembly, но область применения технологии в электронной коммерции всё ещё примитивна. Мы не смогли сразу найти правильный вариант её использования. Было несколько предложений, но во всех вариантах JavaScript подходил лучше. Когда мы в eBay оцениваем новые технологии, то первый вопрос: «Какова потенциальная выгода для наших клиентов?» Если здесь нет ясности, мы не переходим к следующему шагу. Очень легко увлечься новой модной технологией, даже если она не имеет никакого значения для клиентов и только усложняет существующий рабочий процесс. Пользовательский опыт всегда важнее опыта разработчика. Но с WebAssembly иначе. У этой технологии огромный потенциал, просто мы не могли найти правильный вариант использования. Впрочем, в итоге всё-таки нашли.
Сканер штрих-кодов
В нативных приложениях eBay на iOS и Android есть функция сканирования штрих-кодов UPC для автоматического введения в форму. Она работает только в приложениях и требует интенсивной обработки изображений на устройстве, чтобы распознать цифры штрих-кода в потоке изображений от камеры. Полученный код затем отправляется в серверную службу, которая, в свою очередь, заполняет форму. Это означает, что логика обработки изображений на устройстве должна быть очень эффективной. Для нативных приложений мы скомпилировали собственную библиотеку C++ в нативный код для iOS и Android. Он исключительно хорошо распознаёт штрих-коды. Мы постепенно переходим на нативные API в iOS и Android, но наша библиотека C++ по-прежнему надёжна.
Сканер штрих-кодов — интуитивно понятная функция для продавцов, она заметно упрощает заполнение формы. К сожалению, эта функция не работала на мобильной версии сайта, а продавцам приходилось вручную вводить UPC, что неудобно.
Сканер штрих-кодов для веба
Мы раньше искали вариант сканирования штрих-кодов в вебе. Два года назад даже выпустили прототип на базе открытой JavaScript-библиотеки BarcodeReader. Проблема заключалась в том, что он хорошо работал только в 20% случаев. Остальные 80% времени сканер работал исключительно медленно или вообще не срабатывал. В большинстве случаев это был тайм-аут. Вполне ожидаемо: JavaScript может сравниться по скорости с нативным кодом только если находится на «горячем пути», т. е. сильно оптимизирован JIT-компиляторами. Хитрость в том, что движки JavaScript используют многочисленные эвристики для определения, является ли путь «горячим», не гарантируя результат. Это несоответствие, очевидно, привело к разочарованию пользователей, и нам пришлось отключить эту функцию. Но теперь всё иначе. С быстрым развитием веб-платформы возник вопрос: «Можно ли реализовать в вебе надёжный сканер штрих-кодов?»
Один из вариантов — подождать выхода Shape Detection API cо встроенными функциями обнаружения изображений, в том числе штрих-кодов. Но эти интерфейсы пока на очень ранней стадии разработки и далеки от кроссбраузерной совместимости. И даже в этом случае не гарантируется работа на всех платформах. Поэтому придётся рассмотреть другие варианты.
Здесь в игру вступает WebAssembly. Если сканер штрих-кодов реализован на WebAssembly, то он гарантированно будет работать. Сильная типизация и структура байт-кода WebAssembly позволяют всегда сохранять «горячий путь» выполнения. Кроме того, у нас уже есть библиотека C++ для нативных приложений. Библиотеки C++ — идеальные кандидаты для компиляции в WebAssembly. Мы думали, что проблема решена. Оказалось, не совсем.
Архитектура
Рабочий прототип архитектуры для сканера штрих-кодов на WebAssembly был довольно простым.
- Скомпилировать библиотеку C++ с помощью Emscripten. Она выдаст связующий код и файл .wasm.
- Выделить поток воркера из основного потока. Код JavaScript для воркера импортирует сгенерированный связующий код JavaScript, который, в свою очередь, создаст файл .wasm.
- Основной поток отправляет снимок из потока от камеры в поток воркера, а он вызовет соответствующий WASM API через связующий код. Ответ API передаётся в основной поток. Ответ может быть строкой UPC (которая передаётся бэкенду) или пустой строкой, если штрих-код не обнаружен.
- Для пустого ответа вышеуказанный шаг повторяется до тех пор, пока не будет обнаружен штрих-код. Этот цикл работает в течение указанного интервала времени в секундах. Как только порог достигнут, мы отобразим предупреждающее сообщение «Недопустимый код продукта. Попробуйте другой штрих-код или поиск по тексту». Либо пользователь не сфокусировал камеру на реальном штрих-коде, либо сканер недостаточно эффективен. Мы отслеживаем статистику по тайм-аутам как показатель качества работы сканера.

Рабочий Процесс WebAssembly
Компиляция
Первый шаг в любом проекте WebAssembly — определить чёткий конвейер компиляции. Emscripten стал стандартом де-факто для компиляции WebAssembly, но важно иметь согласованную среду, которая выдаёт детерминированный результат. Наш фронтенд основан на Node.js, так что нужно найти решение, совместимое с рабочим процессом npm. К счастью, примерно в то время Сурма Дас опубликовал статью «Emscripten и npm». Подход на основе Docker для компиляции WebAssembly имеет смысл, поскольку устраняет кучу накладных расходов. Как рекомендовано в статье, мы взяли докеровский образ Emscripten от trzeci. Чтобы стала возможной компиляция в WebAssembly, нативную библиотеку C++ пришлось немного подправить. В основном, мы действовали наугад, методом проб и ошибок. В конце концов удалось её скомпилировать, а также настроить аккуратный рабочий процесс WebAssembly в рамках существующего конвейера сборки.
Работает быстро, но…
Производительность сканера измеряется по количеству кадров, обрабатываемых Wasm API за секунду. Wasm API берёт кадр из видеопотока камеры, выполняет вычисления и возвращает ответ. Это делается на постоянной основе, пока не обнаружен штрих-код. Производительность измеряется в FPS.
Наша реализация WebAssembly при тестировании показала удивительную скорость 50 FPS. Однако срабатывала только в 60% случаев, а в остальных вылетала по тайм-ауту. Даже при таком высоком FPS они не могли быстро обнаружить штрих-код для оставшихся 40% сканирований, выдавая в конце предупреждающее сообщение. Для сравнения, прежняя реализация на JavaScript обычно работала на скорости 1 FPS. Да, WebAssembly намного быстрее (в 50 раз), но почему-то не срабатывает почти в половине случаев. Следует также отметить, что в некоторых ситуациях JavaScript работал очень хорошо и сразу находил штрих-код. Одним из очевидных вариантов было увеличить тайм-аут, но это лишь увеличит разочарование пользователей, и так мы не решаем настоящую проблему. Поэтому мы отказались от этой идеи.
Сначала мы не могли понять, почему нативная библиотека C++, которая отлично работала в нативных приложениях, не показала такой же результат в вебе. После длительного тестирования и отладки мы обнаружили, что скорость распознавания зависит от угла фокусировки объекта и фоновой тени. Но как же тогда всё работает в нативных приложениях? Дело в том, что в нативных приложениях мы используем встроенные API для автофокусировки и предоставляем пользователю возможность сфокусироваться вручную, указав пальцем на штрих-код. Поэтому нативные приложения всегда предоставляют библиотеке высококачественные чёткие изображения.
Осознав суть происходящего, мы решили попробовать другую нативную библиотеку: довольно популярный и стабильный сканер штрих-кодов ZBar с открытым исходным кодом. Что ещё более важно, он хорошо работает с размытыми и зернистыми изображениями. Почему бы не попробовать? Поскольку у нас уже был рабочий процесс WebAssembly, компиляция и деплой ZBar в WebAssembly прошли без проблем. Производительность оказалась приличной, около 15 FPS, хотя и не такая хорошая, как у нашей собственной библиотеки C++. Зато показатель успеха оказался близок к 80% для того же тайм-аута. Явное улучшение по сравнению с нашей библиотекой C++, но всё равно не 100%.
Результат нас ещё не удовлетворял, но мы заметили нечто неожиданное. Там, где Zbar вылетал по тайм-ауту, наша собственная библиотека C++ выполняла работу очень быстро. Это был приятный сюрприз. Похоже, библиотеки по-разному обрабатывали снимки разного качества. Это навело нас на идею.
Многопоточность и гонки на скорость
Наверное, вы уже поняли. Почему бы не создать два потока воркеров: один для Zbar, а другой для нашей библиотеки C++, и не запустить их параллельно. Кто победил (кто первым пришлёт действительный штрих-код), тот отправляет результат в основной поток, и оба воркера останавливаются. Мы реализовали такой сценарий и начали сами тестировать, пытаясь сымитировать как можно больше сценариев. Такая настройка показала 95% успешных сканирований. Намного лучше, чем предыдущие результаты, но всё равно не 100%.
Одним из странных предложений было добавить в соревнование оригинальную библиотеку JavaScipt. Это будет три потока. Мы честно не думали, что это что-то изменит. Но такой тест не требовал никаких усилий, потому что мы стандартизировали рабочий интерфейс. К нашему удивлению, с тремя потоками показатель успеха действительно приблизился к 100%. Это опять было совершенно неожиданно. Как упоминалось ранее, JavaScript очень хорошо работал в некоторых ситуациях. Судя по всему, он закрыл разрыв. Так что народная мудрость права — «JavaScript всегда выигрывает». Если без шуток, на следующей иллюстрации представлен обзор окончательной архитектуры, которую мы реализовали.

Веб-архитектура сканера штрих-кодов
На следующем рисунке показана функциональная схема высокого уровня:
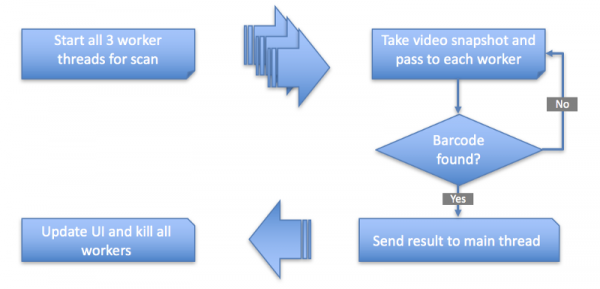
Функциональная схема сканера штрих-кодов
Примечание о загрузке ресурсов
Ресурсы, необходимые для работы сканера, предварительно загружаются после рендеринга главной страницы. Таким образом целевая страница загружается быстро, при этом она готова к взаимодействию. Ресурсы WebAssembly (файлы wasm и скрипты связующего кода) и библиотека сканера JavaScript предварительно загружаются и кэшируются с помощью XMLHttpRequest после загрузки основной страницы. Здесь важно, что они не выполняются сразу, чтобы оставить основной поток свободным для взаимодействия пользователя со страницей. Выполнение происходит только когда пользователь нажимает на значок штрих-кода. Если пользователь нажал на значок до загрузки ресурсов, то они загружатся по требованию и немедленно выполняются. Обработчик событий сканера штрих-кодов и контроллер воркера загружаются вместе со страницей, но они очень маленькие.
Результаты
После тщательного тестирования и внутреннего использования сотрудниками, мы запустили A/B-тестирование на пользователях. Тестовой группе показывалась иконка сканера (скриншот ниже), а контрольной группе — нет.

Конечный продукт
Для оценки успеха мы ввели метрику «скорость завершения черновиков» (Draft Completion Rate). Это время между началом редактирования черновика и отправкой формы. Метрика должна показать, насколько сканер штрих-кодов помогает людям в заполнении форм. Тест продолжался несколько недель, а результаты оказались очень приятными. Они полностью согласуются с нашей первоначальной гипотезой. Время завершения черновика уменьшилось на 30% для потока со сканером штрих-кодов.

Результаты A/B-тестирования
Мы также добавили профилирование, чтобы оценить эффективность всех типов сканера. Как и ожидалось, наибольший вклад внёс Zbar (53% успешных сканирований), затем наша библиотека C++ (34%) и, наконец, библиотека JavaScript с 13%.

Вывод
Опыт внедрения WebAssembly стал для нас весьма познавательным. Инженеры очень радуются появлению новых технологий и сразу хотят их опробовать. Если технология ещё и полезна для клиентов, то это двойная радость. Повторим мысль, высказанную в начале статьи. Технология развивается очень быстрыми темпами. Каждый день появляется что-то новое. Но лишь немногие технологии имеют значение для клиентов, а WebAssembly — одна из них. Наш самый большой вывод из этого упражнения — говорить «нет» в 99-ти ситуациях и «да» в том единственном случае, когда это действительно важно для клиентов.
В дальнейшем мы планируем расширить использование сканера штрих-кодов и внедрить его на стороне покупателей, чтобы они могли сканировать коды товаров в офлайне для их поиска и покупки на eBay. Также рассмотрим вариант расширения функции с помощью Shape Detection API и других функций в браузере. Но мы рады, что нашли правильный вариант использования WebAssembly на eBay и успешно применили технологию в электронной коммерции.
Особая благодарность Сурме Дасу и Лин Кларк за многочисленные статьи о WebAssembly. Они действительно несколько раз помогли нам выйти из тупика.







