Ежедневно в сервисе Pyrus работают десятки тысяч сотрудников из нескольких тысяч организаций по всему миру. Отзывчивость сервиса (скорость обработки запросов) мы считаем важным конкурентным преимуществом, так как она напрямую влияет на впечатление пользователей. Ключевой метрикой для нас является «процент медленных запросов». Изучая ее поведение, мы заметили, что раз в минуту на серверах приложений возникают паузы длиной около 1000 мс. В эти промежутки сервер не отвечает и возникает очередь из нескольких десятков запросов. О поиске причин и устранении узких мест, вызванных сборкой мусора в приложении, пойдет речь в этой статье.

Современные языки программирования можно разделить на две группы. В языках типа C/C++ или Rust используется ручное управление памятью, поэтому программисты тратят больше времени на написание кода, управление временем жизни объектов, а затем на отладку. При этом баги из-за неправильного использования памяти — одни из самых сложных в отладке, поэтому большинство современной разработки ведется на языках с автоматическим управлением памятью. К ним относятся, например, Java, C#, Python, Ruby, Go, PHP, JavaScript, и.т.д. Программисты экономят время разработки, но за это приходится платить дополнительным временем выполнения, которое программа регулярно тратит на сборку мусора — освобождение памяти, занятой объектами, на которые в программе не осталось ссылок. В небольших программах это время ничтожно, однако по мере роста числа объектов и интенсивности их создания сборка мусора начинает давать заметный вклад в общее время выполнения программы.
Веб-серверы Pyrus работают на платформе .NET, где используется автоматическое управление памятью. Большинство сборок мусора — блокирующие ('stop the world'), т.е. на время своей работы останавливают все потоки (threads) приложения. Неблокирующие (фоновые) сборки на самом деле тоже останавливают все потоки, но на очень короткий период времени. Во время блокировки потоков сервер не обрабатывает запросы, имеющиеся запросы подвисают, новые складываются в очередь. В результате напрямую замедляются запросы, которые обрабатывались в момент сборки мусора, также медленнее выполняются запросы сразу по окончании сборки мусора из-за накопившихся очередей. Это ухудшает метрику «процент медленных запросов».
Вооружившись недавно вышедшей книгой Konrad Kokosa: Pro .NET Memory Management (о том, как мы за 2 дня привезли в Россию ее первый экземпляр, можно написать отдельный пост), целиком посвященной теме управления памятью в .NET, мы начали исследование проблемы.
Для профилирования веб-сервера Pyrus мы воспользовались утилитой PerfView (https://github.com/Microsoft/perfview), заточенной под профилирование .NET приложений. Утилита основана на механизме Event Tracing for Windows (ETW) и имеет минимальное влияние на производительность профилируемого приложения, что позволяет использовать ее на боевом сервере. Кроме того, влияние на производительность зависит от того, какие виды событий и какую информацию мы собираем. Не собираем ничего — приложение работает как обычно. Также PerfView не требует ни перекомпиляции, ни перезапуска приложения.
Запустим трассировку PerfView с параметром /GCCollectOnly (время трассировки 1.5 часа). В этом режиме он собирает только события сборок мусора и оказывает минимальное влияние на производительность. Посмотрим на отчет трассировки Memory Group / GCStats, а в нем на сводку событий сборщика мусора:

Тут мы видим сразу несколько интересных показателей:
Поясним наблюдение про количество сборок мусора. Идея разделить объекты по времени их жизни основана на гипотезе о поколениях (generational hypothesis): значительная часть создаваемых объектов умирает быстро, а большинство остальных живут долго (другими словами, мало объектов, имеющих «среднее» время жизни). Именно под этот режим и заточен сборщик мусора .NET, и в этом режиме сборок второго поколения должно быть гораздо меньше, чем 0-го поколения. То есть, для оптимальной работы сборщика мусора мы должны подгонять работу нашего приложения под гипотезу о поколениях. Сформулируем правило так: объекты должны либо умирать быстро, не доживая до старшего поколения, либо доживать до него и жить там вечно. Это правило применяется и для других платформ, где используется автоматическое управление памятью с разделением по поколениям, например, таким как Java.
Интересные для нас данные можно извлечь из другой таблицы в отчете GCStats:

Здесь перечислены случаи, когда приложение пытается создать большой объект (в .NET Framework объекты размером > 85000 байт создаются в LOH — Large Object Heap), и ему приходится ждать окончания сборки 2-го поколения, которая происходит параллельно в фоне. Эти паузы аллокатора не настолько критичны, как паузы сборщика мусора, так как они влияют только на один поток. До этого мы использовали версию .NET Framework 4.6.1, а в версии 4.7.1 Microsoft доработали сборщик мусора, теперь он позволяет выделять память в Large Object Heap во время фоновой сборки 2-го поколения: https://docs.microsoft.com/ru-ru/dotnet/framework/whats-new/#common-language-runtime-clr
Поэтому мы обновились до последней на тот момент версии 4.7.2.
Почему же у нас так много сборок старшего поколения? Первое предположение — мы имеем утечку памяти. Для проверки этой гипотезы посмотрим на размер второго поколения (мы настроили в Zabbix мониторинг соответствующих счетчиков производительности). Из графиков размера 2-го поколения для 2-х серверов Pyrus видно, что его размер сначала растет (в основном из-за заполнения кэшей), но затем стабилизируется (большие провалы на графике — штатный перезапуск веб-сервиса для обновления версии):

Это означает, что нет заметных утечек памяти, то есть, большое количество сборок 2-го поколения возникает по другой причине. Следующая гипотеза — большой трафик памяти, т.е., во 2-е поколение попадает много объектов, и много объектов там умирает. Для нахождения таких объектов в PerfView имеется режим /GCOnly. Из отчетов трассировки обратим внимание на 'Gen 2 Object Deaths (Coarse Sampling) Stacks', который содержит выборку объектов, умирающих во 2-м поколении, вместе со стеками вызовов мест, где эти объекты были созданы. Тут мы видим следующие результаты:

Раскрыв строку, внутри мы видим стек вызовов тех мест в коде, которые создают объекты, доживающие до 2-го поколения. Среди них:


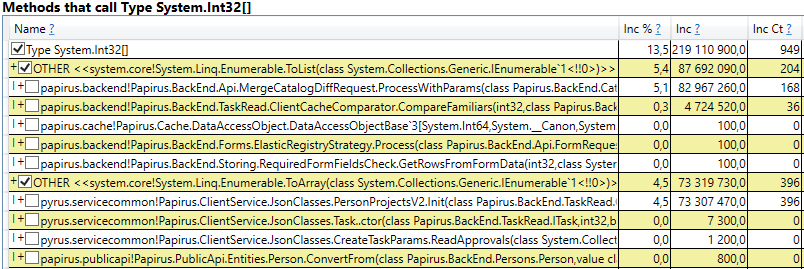
Интересно, что буферы для JSON и для вычисления клиентских кэшей — это всё временные объекты, которые живут в течение одного запроса. Почему же они доживают до 2-го поколения? Обратим внимание, что все эти объекты — массивы достаточно большого размера. А при размере > 85000 байт память под них выделяется в Large Object Heap, которая собирается только вместе со 2-ым поколением.
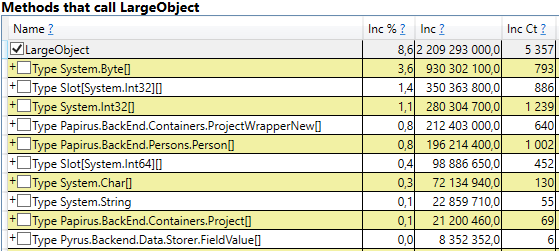
Для проверки откроем в результатах perfview /GCOnly раздел 'GC Heap Alloc Ignore Free (Coarse Sampling) stacks'. Там мы видим строку LargeObject, в которой PerfView группирует создание больших объектов, а внутри мы увидим все те же самые массивы, которые мы видели в предшествующем анализе. Мы подтверждаем основную причину проблем со сборщиком мусора: мы создаем много временных больших объектов.

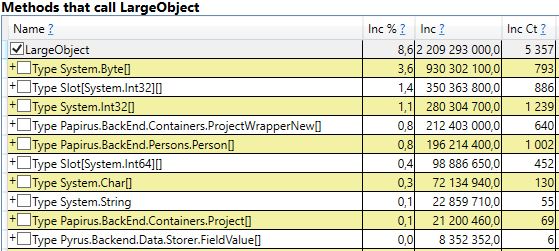
По результатам измерений мы выделили основные направления дальнейшей работы: борьба с большими объектами при вычислении клиентских кэшей и сериализации в JSON. Есть несколько вариантов решения этой проблемы:
Рассмотрим по отдельности оба случая больших объектов — вычисление клиентских кэшей и сериализацию в JSON.
Web-клиент и мобильные приложения Pyrus кэшируют данные, доступные пользователю (проекты, формы, пользователи, и т.п.) Кэширование используется для ускорения работы, также оно необходимо для работы в оффлайн-режиме. Кэши вычисляются на сервере и передаются на клиент. Они индивидуальны для каждого пользователя, так как зависят от его прав доступа, и достаточно часто обновляются, например, при изменении справочников, к которым он имеет доступ.
Таким образом, на сервере регулярно происходит много вычислений клиентских кэшей, при этом создается много временных короткоживущих объектов. Если пользователь состоит в большой организации, то он может получить доступ к многим объектам, соответственно клиентские кэши для него будут большими. Именно поэтому мы видели выделение памяти под большие временные массивы в Large Object Heap.
Проанализируем предложенные варианты избавления от создания больших объектов:
Мы решили пойти по 3-му пути иизобрести свой велосипед написать List и HashSet, не нагружающие Large Object Heap.
Наш ChunkedList<T> реализует стандартные интерфейсы, включая IList<T>, благодаря этому требуются минимальные изменения имеющегося кода. Да и используемая нами библиотека Newtonsoft.Json автоматически умеет его сериализовывать, так как он реализует IEnumerable <T>:
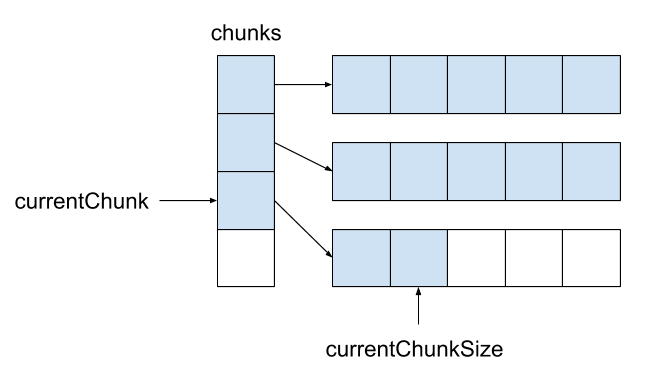
У стандартного списка List<T> имеются следующие поля: массив для элементов и количество заполненных элементов. В ChunkedList<T> имеется массив массивов элементов, количество полностью заполненных массивов, количество элементов в последнем массиве. Каждый из массивов элементов при этом которых меньше 85000 байт:
Так как ChunkedList<T> устроен довольно сложно, то на него мы написали подробные тесты. Любую операцию нужно тестировать как минимум в 2-х режимах: в «маленьком», когда весь список умещается в один кусок размером до 85000 байт, и «большом», когда он состоит более, чем из одного куска. При этом для методов, изменяющих размер (например, Add), сценариев еще больше: «маленький» -> «маленький», «маленький» -> «большой», «большой» -> «большой», «большой» -> «маленький». Тут возникает довольно много запутанных граничных случаев, с которыми хорошо справляются юнит-тесты.
Ситуация упрощается тем, что часть методов из интерфейса IList не используются, и их можно не реализовывать (такие, как Insert, Remove). Их реализация и тестирование были бы довольно накладными. Кроме того, написание юнит-тестов упрощается тем, что нам не нужно придумывать новый функционал, ChunkedList<T> должен вести себя так же, как и List<T>. То есть все тесты устроены так: создаем List<T> и ChunkedList<T>, проводим над ними одинаковые операции и сравниваем результаты.
Мы провели замер производительности с помощью библиотеки BenchmarkDotNet, чтобы убедиться, что мы не сильно замедлим наш код при переходе с List<T> на ChunkedList<T>. Протестируем, например, добавление элементов в список:
И такой же тест с использованием List<T> для сравнения. Результаты при добавлении 500 элементов (все помещается в один массив):
Результаты при добавлении 50000 элементов (разбивается на несколько массивов):
Если посмотреть на столбец 'Mean', в котором отображено среднее время выполнения теста, видно, что наша реализация медленнее стандартной всего в 2-2.5 раза. С учетом того, что в реальном коде операции со списками — лишь малая часть всех выполняемых действий, эта разница становится несущественной. Зато столбец 'Gen 2/1k op' (количество сборок 2-го поколения за 1000 выполнений теста) показывает, что мы добились цели: при большом количестве элементов ChunkedList не создает мусора во 2-м поколении, что и было нашей задачей.
Аналогично ChunkedHashSet<T> реализует интерфейс ISet<T>. При написании ChunkedHashSet<T> мы повторно использовали логику разбиения на небольшие куски, уже реализованную в ChunkedList. Для этого мы взяли готовую реализацию HashSet<T> из .NET Reference Source, доступного по лицензии MIT, и заменили в ней массивы на ChunkedList-ы.
В юнит тестах тоже воспользуемся тем же трюком, что и для списков: будем сравнивать поведение ChunkedHashSet<T> с эталонным HashSet<T>.
Наконец, тесты производительности. Основная операция, которую мы используем — объединение множеств, поэтому именно ее мы и протестируем:
И точно такой же тест для стандартного HashSet. Первый тест для небольших множеств:
Второй тест для больших множеств, которые вызывали проблему с кучей больших объектов:
Результаты схожи со списками. ChunkedHashSet медленнее в 2-2.5 раза, но при этом на больших множествах нагружает 2-е поколение на 2 порядка меньше.
Веб-сервер Pyrus предоставляет несколько API, в которых используется разная сериализация. Мы обнаружили создание больших объектов в API, используемом ботами и утилитой синхронизации (далее Public API). Заметим, что в основном API используется собственная сериализация, которая не подвержена данной проблеме. Мы об этом писали в статье https://habr.com/ru/post/227595/, в разделе «2. Вы не знаете, где узкое место вашего приложения». То есть, основной API уже работает хорошо, а проблема проявилась в Public API по мере роста количества запросов и объемов данных в ответах.
Займемся оптимизацией Public API. На примере основного API мы знаем, что можно возвращать ответ пользователю в потоковом режиме. То есть, нужно не создавать промежуточные буферы, содержащие ответ целиком, а писать сразу ответ в поток (stream).
При ближайшем рассмотрении мы выяснили, что в процессе сериализации ответа мы создаем временный буфер для промежуточного результата ('content' — массив байтов, содержащий JSON в кодировке UTF-8):
Проследим, где используется content. По историческим причинам Public API основан на WCF, для которого стандартным форматом запросов и ответов является XML. В нашем случае в XML-ответе имеется единственный элемент 'Binary', внутри которого записан JSON, закодированный в Base64:
Заметим, что временный буфер здесь не нужен. JSON можно писать сразу в буфер XmlWriter, который нам предоставляет WCF, на лету кодируя его в Base64. Таким образом, мы пойдем по первому пути, избавившись от выделения памяти:
Здесь Base64Writer — это простая обертка над XmlWriter, реализующая интерфейс Stream, которая пишет в XmlWriter в виде Base64. При этом из всего интерфейса достаточно реализовать только один метод Write, который вызывается в StreamWriter:
Попробуем разобраться с загадочными индуцированными сборками мусора. Мы 10 раз перепроверили наш код на наличие вызовов GC.Collect, но это не дало результатов. Удалось поймать эти события в PerfView, но стек вызовов не особо показателен (событие DotNETRuntime/GC/Triggered):
Есть маленькая зацепка — вызов RecycleLimitMonitor.RaiseRecycleLimitEvent перед индуцированной сборкой мусора. Проследим стек вызовов метода RaiseRecycleLimitEvent:
Названия методов вполне соответствуют их функциям:
Дальнейшее расследование показывает, обработчики IObserver<RecycleLimitInfo> добавляются в методе RecycleLimitMonitor.Subscribe(), который вызывается в методе AspNetMemoryMonitor.Subscribe(). Также в классе AspNetMemoryMonitor вешается обработчик IObserver<RecycleLimitInfo> по умолчанию (класс RecycleLimitObserver), который чистит кэши ASP.NET, и иногда запрашивает сборку мусора.
Загадка Induced GC почти разгадана. Осталось выяснить вопрос, для чего вызывается эта сборка мусора. RecycleLimitMonitor следит за использованием памяти IIS (точнее, за цифрой private bytes), и когда ее использование приближается к определенному пределу, начинает по довольно запутанному алгоритму вызывать событие RaiseRecycleLimitEvent. В качестве предела памяти используется значение AspNetMemoryMonitor.ProcessPrivateBytesLimit, а в нем в свою очередь находится следующая логика:
Вывод расследования такой: ASP.NET по использованию памяти приближается к своему пределу и начинает регулярно вызывать сборку мусора. Для 'Private Memory Limit (KB)' не было установлено значение, поэтому ASP.NET ограничивался 60% от физической памяти. Проблема маскировалась тем, что на сервере Task Manager показывал много свободной памяти и казалось, что ее хватает. Мы повысили значение 'Private Memory Limit (KB)' в настройках Application Pool в IIS до 80% от физической памяти. Это стимулирует ASP.NET использовать больше имеющейся памяти. Также мы добавили мониторинг счетчика производительности '.NET CLR Memory / # Induced GC', чтобы не пропустить, когда в следующий раз ASP.NET решит, что он приближается к пределу использования памяти.
Посмотрим, что же произошло со сборками мусора после всех этих изменений. Начнем с perfview /GCCollectOnly (время трассировки — 1 час), отчет GCStats:

Видно, что сборок 2-го поколения теперь на 2 порядка меньше, чем 0-го и 1-го. Также, время этих сборок уменьшились. Индуцированных сборок больше не наблюдается. Посмотрим на список сборок 2-го поколения:
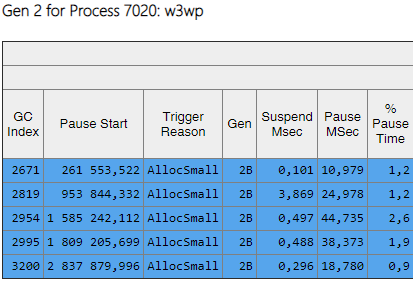
Из столбца Gen видно, что все сборки 2-го поколения стали фоновыми ('2B' означает 2-е поколение, Background). То есть, большая часть работы выполняется параллельно с выполнением приложения, а все потоки блокируются ненадолго (столбец 'Pause MSec'). Посмотрим на паузы при создании больших объектов:
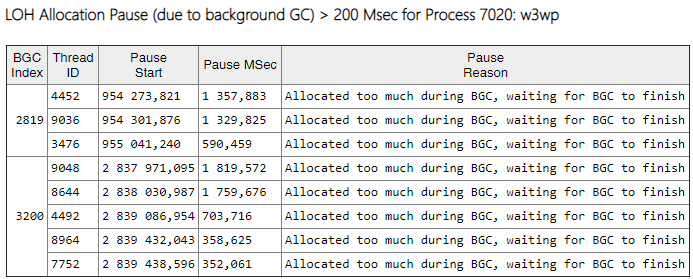
Видно, что количество таких пауз при создании больших объектов упало в разы.
Благодаря описанным в статье изменениям удалось значительно снизить количество и продолжительность сборок 2-го поколения. Удалось найти причину индуцированных сборок, и избавиться от них. Увеличилось количество сборок 0-го и 1-го поколения, но при этом уменьшилась их средняя продолжительность (с ~200 мсек до ~60 мсек). Максимальная продолжительность сборок 0-го и 1-го поколений уменьшилась, но не так заметно. Сборки 2-го поколения стали быстрее, длинные паузы до 1000мс полностью ушли.
Что касается ключевой метрики — «процент медленных запросов», она уменьшилась на 40% после всех изменений.
Благодаря проведенной работе мы поняли, какие счетчики производительности нужны для оценки ситуации с памятью и сборкой мусора, добавив их в Zabbix для постоянного мониторинга. Вот список самых важных, на которые мы обращаем внимание, и выясняем причину (например, повышенный поток запросов, большой объем передаваемых данных, баг в приложении):

Современные языки программирования можно разделить на две группы. В языках типа C/C++ или Rust используется ручное управление памятью, поэтому программисты тратят больше времени на написание кода, управление временем жизни объектов, а затем на отладку. При этом баги из-за неправильного использования памяти — одни из самых сложных в отладке, поэтому большинство современной разработки ведется на языках с автоматическим управлением памятью. К ним относятся, например, Java, C#, Python, Ruby, Go, PHP, JavaScript, и.т.д. Программисты экономят время разработки, но за это приходится платить дополнительным временем выполнения, которое программа регулярно тратит на сборку мусора — освобождение памяти, занятой объектами, на которые в программе не осталось ссылок. В небольших программах это время ничтожно, однако по мере роста числа объектов и интенсивности их создания сборка мусора начинает давать заметный вклад в общее время выполнения программы.
Веб-серверы Pyrus работают на платформе .NET, где используется автоматическое управление памятью. Большинство сборок мусора — блокирующие ('stop the world'), т.е. на время своей работы останавливают все потоки (threads) приложения. Неблокирующие (фоновые) сборки на самом деле тоже останавливают все потоки, но на очень короткий период времени. Во время блокировки потоков сервер не обрабатывает запросы, имеющиеся запросы подвисают, новые складываются в очередь. В результате напрямую замедляются запросы, которые обрабатывались в момент сборки мусора, также медленнее выполняются запросы сразу по окончании сборки мусора из-за накопившихся очередей. Это ухудшает метрику «процент медленных запросов».
Вооружившись недавно вышедшей книгой Konrad Kokosa: Pro .NET Memory Management (о том, как мы за 2 дня привезли в Россию ее первый экземпляр, можно написать отдельный пост), целиком посвященной теме управления памятью в .NET, мы начали исследование проблемы.
Измерение
Для профилирования веб-сервера Pyrus мы воспользовались утилитой PerfView (https://github.com/Microsoft/perfview), заточенной под профилирование .NET приложений. Утилита основана на механизме Event Tracing for Windows (ETW) и имеет минимальное влияние на производительность профилируемого приложения, что позволяет использовать ее на боевом сервере. Кроме того, влияние на производительность зависит от того, какие виды событий и какую информацию мы собираем. Не собираем ничего — приложение работает как обычно. Также PerfView не требует ни перекомпиляции, ни перезапуска приложения.
Запустим трассировку PerfView с параметром /GCCollectOnly (время трассировки 1.5 часа). В этом режиме он собирает только события сборок мусора и оказывает минимальное влияние на производительность. Посмотрим на отчет трассировки Memory Group / GCStats, а в нем на сводку событий сборщика мусора:
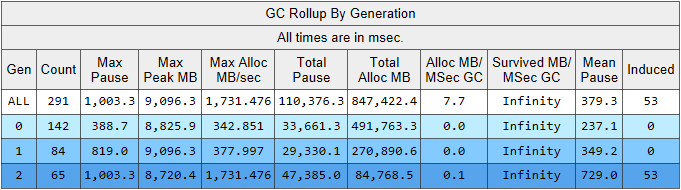
Тут мы видим сразу несколько интересных показателей:
- Среднее время паузы сборки во 2-м поколении — 700 миллисекунд, а максимальная пауза около секунды. Данная цифра показывает время, на которое останавливаются все потоки в .NET приложении, в частности во все обрабатываемые запросы добавится эта пауза.
- Количество сборок 2-го поколения сравнимо с 1-м поколением и ненамного меньше количества сборок 0-го поколения.
- В столбце Induced указано 53 сборки во 2-м поколении. Induced-сборка — это результат явного вызова GC.Collect(). В нашем коде мы не нашли ни одного вызова этого метода, значит, виновата какая-то из используемых нашим приложением библиотек.
Поясним наблюдение про количество сборок мусора. Идея разделить объекты по времени их жизни основана на гипотезе о поколениях (generational hypothesis): значительная часть создаваемых объектов умирает быстро, а большинство остальных живут долго (другими словами, мало объектов, имеющих «среднее» время жизни). Именно под этот режим и заточен сборщик мусора .NET, и в этом режиме сборок второго поколения должно быть гораздо меньше, чем 0-го поколения. То есть, для оптимальной работы сборщика мусора мы должны подгонять работу нашего приложения под гипотезу о поколениях. Сформулируем правило так: объекты должны либо умирать быстро, не доживая до старшего поколения, либо доживать до него и жить там вечно. Это правило применяется и для других платформ, где используется автоматическое управление памятью с разделением по поколениям, например, таким как Java.
Интересные для нас данные можно извлечь из другой таблицы в отчете GCStats:

Здесь перечислены случаи, когда приложение пытается создать большой объект (в .NET Framework объекты размером > 85000 байт создаются в LOH — Large Object Heap), и ему приходится ждать окончания сборки 2-го поколения, которая происходит параллельно в фоне. Эти паузы аллокатора не настолько критичны, как паузы сборщика мусора, так как они влияют только на один поток. До этого мы использовали версию .NET Framework 4.6.1, а в версии 4.7.1 Microsoft доработали сборщик мусора, теперь он позволяет выделять память в Large Object Heap во время фоновой сборки 2-го поколения: https://docs.microsoft.com/ru-ru/dotnet/framework/whats-new/#common-language-runtime-clr
Поэтому мы обновились до последней на тот момент версии 4.7.2.
Сборки 2-го поколения
Почему же у нас так много сборок старшего поколения? Первое предположение — мы имеем утечку памяти. Для проверки этой гипотезы посмотрим на размер второго поколения (мы настроили в Zabbix мониторинг соответствующих счетчиков производительности). Из графиков размера 2-го поколения для 2-х серверов Pyrus видно, что его размер сначала растет (в основном из-за заполнения кэшей), но затем стабилизируется (большие провалы на графике — штатный перезапуск веб-сервиса для обновления версии):
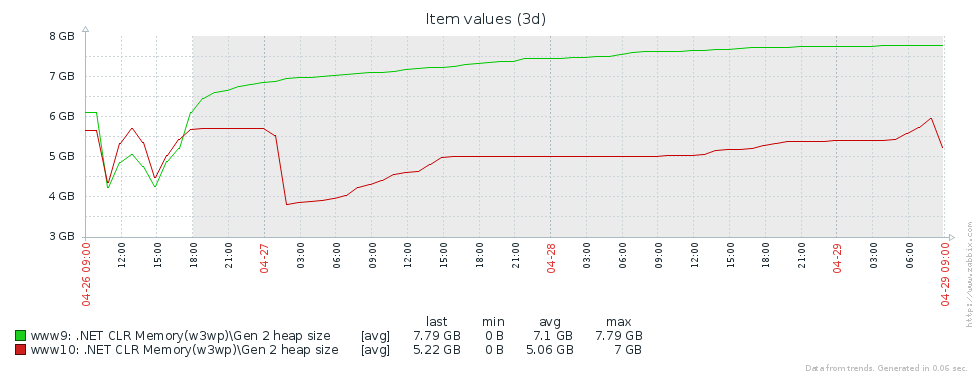
Это означает, что нет заметных утечек памяти, то есть, большое количество сборок 2-го поколения возникает по другой причине. Следующая гипотеза — большой трафик памяти, т.е., во 2-е поколение попадает много объектов, и много объектов там умирает. Для нахождения таких объектов в PerfView имеется режим /GCOnly. Из отчетов трассировки обратим внимание на 'Gen 2 Object Deaths (Coarse Sampling) Stacks', который содержит выборку объектов, умирающих во 2-м поколении, вместе со стеками вызовов мест, где эти объекты были созданы. Тут мы видим следующие результаты:
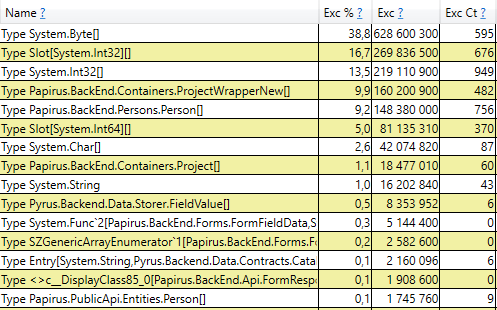
Раскрыв строку, внутри мы видим стек вызовов тех мест в коде, которые создают объекты, доживающие до 2-го поколения. Среди них:
- System.Byte[] Если заглянуть внутрь, то мы увидими, что больше половины — это буферы для сериализации в JSON:
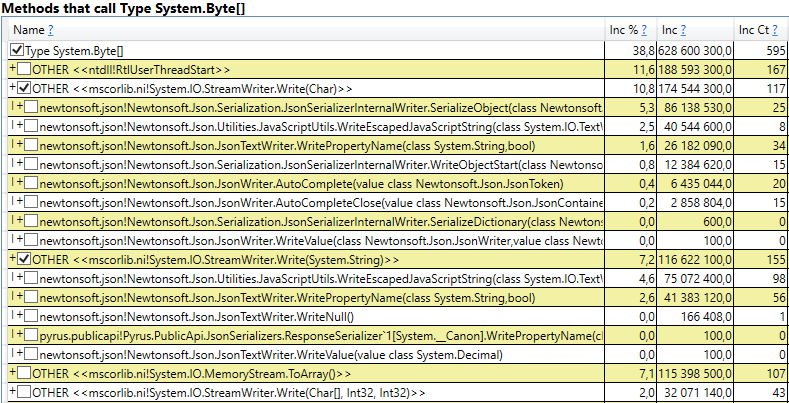
- Slot[System.Int32][] (это часть реализации HashSet), System.Int32[], и т.д. Это наш код, который вычисляет клиентские кэши — те справочники, формы, списки, друзей и т.п., которых видит данный пользователь, и которые кэшируются у него в браузере или в мобильном приложении:

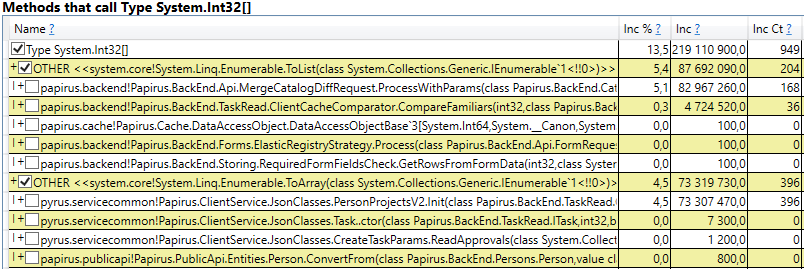
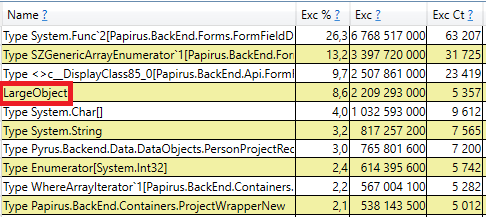
Интересно, что буферы для JSON и для вычисления клиентских кэшей — это всё временные объекты, которые живут в течение одного запроса. Почему же они доживают до 2-го поколения? Обратим внимание, что все эти объекты — массивы достаточно большого размера. А при размере > 85000 байт память под них выделяется в Large Object Heap, которая собирается только вместе со 2-ым поколением.
Для проверки откроем в результатах perfview /GCOnly раздел 'GC Heap Alloc Ignore Free (Coarse Sampling) stacks'. Там мы видим строку LargeObject, в которой PerfView группирует создание больших объектов, а внутри мы увидим все те же самые массивы, которые мы видели в предшествующем анализе. Мы подтверждаем основную причину проблем со сборщиком мусора: мы создаем много временных больших объектов.
Изменения в системе Pyrus
По результатам измерений мы выделили основные направления дальнейшей работы: борьба с большими объектами при вычислении клиентских кэшей и сериализации в JSON. Есть несколько вариантов решения этой проблемы:
- Самое простое — не создавать больших объектов. Например, если большой буфер B используется в последовательных преобразованиях данных A->B->C, то иногда эти преобразования можно объединить, превратив в A->C, и избавившись от создания объекта B. Этот вариант не всегда применим, но при этом он самый простой и эффективный.
- Пул объектов. Вместо того, чтобы постоянно создавать новые объекты и выкидывать, нагружая сборщик мусора, мы можем хранить коллекцию свободных объектов. В простейшем случае, когда нам нужен новый объект, то мы берем его из пула, или создаем новый, если пул пустой. Когда объект нам больше не нужен, мы возвращаем его в пул. Хороший пример — ArrayPool в .NET Core, который также доступен в .NET Framework в составе Nuget-пакета System.Buffers.
- Использовать вместо больших объектов маленькие.
Рассмотрим по отдельности оба случая больших объектов — вычисление клиентских кэшей и сериализацию в JSON.
Вычисление клиентских кэшей
Web-клиент и мобильные приложения Pyrus кэшируют данные, доступные пользователю (проекты, формы, пользователи, и т.п.) Кэширование используется для ускорения работы, также оно необходимо для работы в оффлайн-режиме. Кэши вычисляются на сервере и передаются на клиент. Они индивидуальны для каждого пользователя, так как зависят от его прав доступа, и достаточно часто обновляются, например, при изменении справочников, к которым он имеет доступ.
Таким образом, на сервере регулярно происходит много вычислений клиентских кэшей, при этом создается много временных короткоживущих объектов. Если пользователь состоит в большой организации, то он может получить доступ к многим объектам, соответственно клиентские кэши для него будут большими. Именно поэтому мы видели выделение памяти под большие временные массивы в Large Object Heap.
Проанализируем предложенные варианты избавления от создания больших объектов:
- Полное избавление от больших объектов. Этот подход неприменим, так как в алгоритмах подготовки данных используются среди прочего сортировка и объединение множеств, а для них требуются временные буферы.
- Использование пула объектов. У этого подхода есть сложности:
- Разнообразие используемых коллекций и типов элементов в них: используются HashSet, List и Array (2 последних можно объединить). В коллекциях хранятся Int32, Int64, а также всевозможные классы данных. Для каждого используемого типа понадобится свой пул, который к тому же будет хранить коллекции разных размеров.
- Сложное время жизни коллекций. Чтобы получить преимущества от пула, объекты в него придется возвращать после использования. Это можно сделать, если объект используется в одном методе. Но в нашем случае ситуация сложнее, так как многие большие объекты путешествуют между методами, кладутся в структуры данных, перекладываются в другие структуры, и т.д.
- Реализация. Есть ArrayPool от Microsoft, но нам нужны еще List и HashSet. Мы не нашли какой-нибудь подходящей библиотеки, поэтому классы пришлось бы реализовывать самим.
- Разнообразие используемых коллекций и типов элементов в них: используются HashSet, List и Array (2 последних можно объединить). В коллекциях хранятся Int32, Int64, а также всевозможные классы данных. Для каждого используемого типа понадобится свой пул, который к тому же будет хранить коллекции разных размеров.
- Использование маленьких объектов. Большой массив можно разбить на несколько маленьких кусочков, которые не буду нагружать Large Object Heap, а будут создаваться в 0-м поколении, а дальше идти стандартным путем в 1-е и 2-е. Мы надеемся, что они не доживут до 2-го, а будут собраны сборщиком мусора в 0-м, или в крайнем случае в 1-м поколении. Плюс этого подхода в том, что изменения имеющегося кода минимальные. Сложности:
- Реализация. Мы не нашли подходящих библиотек, поэтому классы пришлось бы писать самим. Отсутствие библиотек объяснимо, так как сценарий «коллекции, не нагружающие Large Object Heap» — это очень узкая область применения.
Мы решили пойти по 3-му пути и
Кусочный список
Наш ChunkedList<T> реализует стандартные интерфейсы, включая IList<T>, благодаря этому требуются минимальные изменения имеющегося кода. Да и используемая нами библиотека Newtonsoft.Json автоматически умеет его сериализовывать, так как он реализует IEnumerable <T>:
public sealed class ChunkedList<T> : IList<T>, ICollection<T>, IEnumerable<T>, IEnumerable, IList, ICollection, IReadOnlyList<T>, IReadOnlyCollection<T>
{У стандартного списка List<T> имеются следующие поля: массив для элементов и количество заполненных элементов. В ChunkedList<T> имеется массив массивов элементов, количество полностью заполненных массивов, количество элементов в последнем массиве. Каждый из массивов элементов при этом которых меньше 85000 байт:

private T[][] chunks;
private int currentChunk;
private int currentChunkSize;Так как ChunkedList<T> устроен довольно сложно, то на него мы написали подробные тесты. Любую операцию нужно тестировать как минимум в 2-х режимах: в «маленьком», когда весь список умещается в один кусок размером до 85000 байт, и «большом», когда он состоит более, чем из одного куска. При этом для методов, изменяющих размер (например, Add), сценариев еще больше: «маленький» -> «маленький», «маленький» -> «большой», «большой» -> «большой», «большой» -> «маленький». Тут возникает довольно много запутанных граничных случаев, с которыми хорошо справляются юнит-тесты.
Ситуация упрощается тем, что часть методов из интерфейса IList не используются, и их можно не реализовывать (такие, как Insert, Remove). Их реализация и тестирование были бы довольно накладными. Кроме того, написание юнит-тестов упрощается тем, что нам не нужно придумывать новый функционал, ChunkedList<T> должен вести себя так же, как и List<T>. То есть все тесты устроены так: создаем List<T> и ChunkedList<T>, проводим над ними одинаковые операции и сравниваем результаты.
Мы провели замер производительности с помощью библиотеки BenchmarkDotNet, чтобы убедиться, что мы не сильно замедлим наш код при переходе с List<T> на ChunkedList<T>. Протестируем, например, добавление элементов в список:
[Benchmark]
public ChunkedList<int> ChunkedList()
{
var list = new ChunkedList<int>();
for (int i = 0; i < N; i++)
list.Add(i);
return list;
}И такой же тест с использованием List<T> для сравнения. Результаты при добавлении 500 элементов (все помещается в один массив):
| Method | Mean | Error | StdDev | Gen 0/1k Op | Gen 1/1k Op | Gen 2/1k Op | Allocated Memory/Op |
| StandardList | 1.415 us | 0.0149 us | 0.0140 us | 0.6847 | 0.0095 | - | 4.21 KB |
| ChunkedList | 3.728 us | 0.0238 us | 0.0222 us | 0.6943 | 0.0076 | - | 4.28 KB |
Результаты при добавлении 50000 элементов (разбивается на несколько массивов):
| Method | Mean | Error | StdDev | Gen 0/1k Op | Gen 1/1k Op | Gen 2/1k Op | Allocated Memory/Op |
| StandardList | 146.273 us | 3.1466 us | 4.8053 us | 124.7559 | 124.7559 | 124.7559 | 513.23 KB |
| ChunkedList | 287.687 us | 1.4630 us | 1.2969 us | 41.5039 | 20.5078 | - | 256.75 KB |
Подробное описание колонок в результатах
BenchmarkDotNet=v0.11.4, OS=Windows 10.0.17763.379 (1809/October2018Update/Redstone5)
Intel Core i7-8700K CPU 3.70GHz (Coffee Lake), 1 CPU, 12 logical and 6 physical cores
[Host] : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0
DefaultJob : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0
// * Hints *
Outliers
ListAdd.StandardList: Default -> 2 outliers were removed
ListAdd.ChunkedList: Default -> 1 outlier was removed
// * Legends *
Mean : Arithmetic mean of all measurements
Error : Half of 99.9% confidence interval
StdDev : Standard deviation of all measurements
Gen 0/1k Op : GC Generation 0 collects per 1k Operations
Gen 1/1k Op : GC Generation 1 collects per 1k Operations
Gen 2/1k Op : GC Generation 2 collects per 1k Operations
Allocated Memory/Op : Allocated memory per single operation (managed only, inclusive, 1KB = 1024B)
1 us : 1 Microsecond (0.000001 sec)Если посмотреть на столбец 'Mean', в котором отображено среднее время выполнения теста, видно, что наша реализация медленнее стандартной всего в 2-2.5 раза. С учетом того, что в реальном коде операции со списками — лишь малая часть всех выполняемых действий, эта разница становится несущественной. Зато столбец 'Gen 2/1k op' (количество сборок 2-го поколения за 1000 выполнений теста) показывает, что мы добились цели: при большом количестве элементов ChunkedList не создает мусора во 2-м поколении, что и было нашей задачей.
Кусочное множество
Аналогично ChunkedHashSet<T> реализует интерфейс ISet<T>. При написании ChunkedHashSet<T> мы повторно использовали логику разбиения на небольшие куски, уже реализованную в ChunkedList. Для этого мы взяли готовую реализацию HashSet<T> из .NET Reference Source, доступного по лицензии MIT, и заменили в ней массивы на ChunkedList-ы.
В юнит тестах тоже воспользуемся тем же трюком, что и для списков: будем сравнивать поведение ChunkedHashSet<T> с эталонным HashSet<T>.
Наконец, тесты производительности. Основная операция, которую мы используем — объединение множеств, поэтому именно ее мы и протестируем:
public ChunkedHashSet<int> ChunkedHashSet(int[][] source)
{
var set = new ChunkedHashSet<int>();
foreach (var arr in source)
set.UnionWith(arr);
return set;
}И точно такой же тест для стандартного HashSet. Первый тест для небольших множеств:
var source = new int[][] {
Enumerable.Range(0, 300).ToArray(),
Enumerable.Range(100, 600).ToArray(),
Enumerable.Range(300, 1000).ToArray(),
}| Method | Mean | Error | StdDev | Gen 0/1k Op | Gen 1/1k Op | Gen 2/1k Op | Allocated Memory/Op |
| StandardHashSet | 30.16 us | 0.1046 us | 0.0979 us | 9.3079 | 1.6785 | - | 57.41 KB |
| ChunkedHashSet | 73.54 us | 0.5919 us | 0.5247 us | 9.5215 | 1.5869 | - | 58.84 KB |
Второй тест для больших множеств, которые вызывали проблему с кучей больших объектов:
var source = new int[][] {
Enumerable.Range(0, 30000).ToArray(),
Enumerable.Range(10000, 60000).ToArray(),
Enumerable.Range(30000, 100000).ToArray(),
}| Method | Mean | Error | StdDev | Gen 0/1k Op | Gen 1/1k Op | Gen 2/1k Op | Allocated Memory/Op |
| StandardHashSet | 3,031.30 us | 32.0797 us | 28.4378 us | 699.2188 | 667.9688 | 664.0625 | 4718.23 KB |
| ChunkedHashSet | 7,189.66 us | 25.6319 us | 23.9761 us | 539.0625 | 265.6250 | 7.8125 | 3280.71 KB |
Результаты схожи со списками. ChunkedHashSet медленнее в 2-2.5 раза, но при этом на больших множествах нагружает 2-е поколение на 2 порядка меньше.
Сериализация в JSON
Веб-сервер Pyrus предоставляет несколько API, в которых используется разная сериализация. Мы обнаружили создание больших объектов в API, используемом ботами и утилитой синхронизации (далее Public API). Заметим, что в основном API используется собственная сериализация, которая не подвержена данной проблеме. Мы об этом писали в статье https://habr.com/ru/post/227595/, в разделе «2. Вы не знаете, где узкое место вашего приложения». То есть, основной API уже работает хорошо, а проблема проявилась в Public API по мере роста количества запросов и объемов данных в ответах.
Займемся оптимизацией Public API. На примере основного API мы знаем, что можно возвращать ответ пользователю в потоковом режиме. То есть, нужно не создавать промежуточные буферы, содержащие ответ целиком, а писать сразу ответ в поток (stream).
При ближайшем рассмотрении мы выяснили, что в процессе сериализации ответа мы создаем временный буфер для промежуточного результата ('content' — массив байтов, содержащий JSON в кодировке UTF-8):
var serializer = Newtonsoft.Json.JsonSerializer.Create(...);
byte[] content;
var sw = new StreamWriter(new MemoryStream(), new UTF8Encoding(false));
using (var writer = new Newtonsoft.Json.JsonTextWriter(sw))
{
serializer.Serialize(writer, result);
writer.Flush();
content = ms.ToArray();
}Проследим, где используется content. По историческим причинам Public API основан на WCF, для которого стандартным форматом запросов и ответов является XML. В нашем случае в XML-ответе имеется единственный элемент 'Binary', внутри которого записан JSON, закодированный в Base64:
public class RawBodyWriter : BodyWriter
{
private readonly byte[] _content;
public RawBodyWriter(byte[] content)
: base(true)
{
_content = content;
}
protected override void OnWriteBodyContents(XmlDictionaryWriter writer)
{
writer.WriteStartElement("Binary");
writer.WriteBase64(_content, 0, _content.Length);
writer.WriteEndElement();
}
}Заметим, что временный буфер здесь не нужен. JSON можно писать сразу в буфер XmlWriter, который нам предоставляет WCF, на лету кодируя его в Base64. Таким образом, мы пойдем по первому пути, избавившись от выделения памяти:
protected override void OnWriteBodyContents(XmlDictionaryWriter writer)
{
var serializer = Newtonsoft.Json.JsonSerializer.Create(...);
writer.WriteStartElement("Binary");
Stream stream = new Base64Writer(writer);
Var sw = new StreamWriter(stream, new UTF8Encoding(false));
using (var jsonWriter = new Newtonsoft.Json.JsonTextWriter(sw))
{
serializer.Serialize(jsonWriter, _result);
jsonWriter.Flush();
}
writer.WriteEndElement();
}Здесь Base64Writer — это простая обертка над XmlWriter, реализующая интерфейс Stream, которая пишет в XmlWriter в виде Base64. При этом из всего интерфейса достаточно реализовать только один метод Write, который вызывается в StreamWriter:
public class Base64Writer : Stream
{
private readonly XmlWriter _writer;
public Base64Writer(XmlWriter writer)
{
_writer = writer;
}
public override void Write(byte[] buffer, int offset, int count)
{
_writer.WriteBase64(buffer, offset, count);
}
<...>
}Induced GC
Попробуем разобраться с загадочными индуцированными сборками мусора. Мы 10 раз перепроверили наш код на наличие вызовов GC.Collect, но это не дало результатов. Удалось поймать эти события в PerfView, но стек вызовов не особо показателен (событие DotNETRuntime/GC/Triggered):
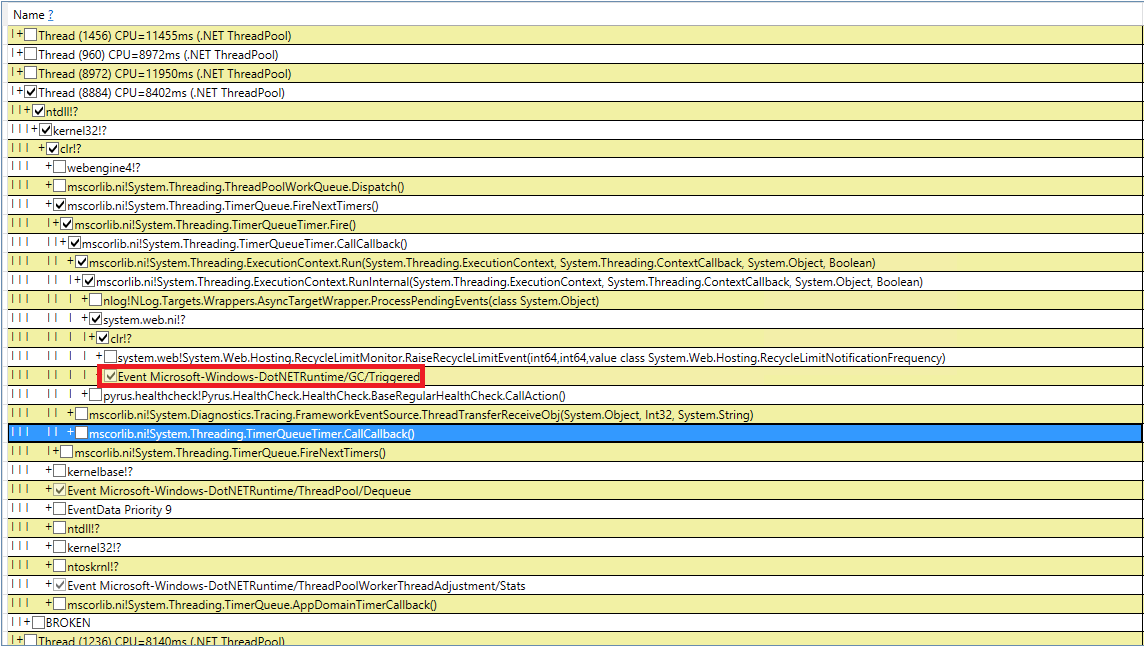
Есть маленькая зацепка — вызов RecycleLimitMonitor.RaiseRecycleLimitEvent перед индуцированной сборкой мусора. Проследим стек вызовов метода RaiseRecycleLimitEvent:
RecycleLimitMonitor.RaiseRecycleLimitEvent(...)
RecycleLimitMonitor.RecycleLimitMonitorSingleton.AlertProxyMonitors(...)
RecycleLimitMonitor.RecycleLimitMonitorSingleton.CollectInfrequently(...)
RecycleLimitMonitor.RecycleLimitMonitorSingleton.PBytesMonitorThread(...)Названия методов вполне соответствуют их функциям:
- В конструкторе RecycleLimitMonitor.RecycleLimitMonitorSingleton создается таймер, с определенным интервалом вызывающий PBytesMonitorThread.
- PBytesMonitorThread собирает статистику по использованию памяти и при каких-то условиях вызывает CollectInfrequently.
- CollectInfrequently вызывает AlertProxyMonitors, получает в результате bool, и вызывает GC.Collect(), если получает true. Также он следит за временем, прошедшим с прошлого вызова сборщика мусора, и не вызывает его слишком часто.
- AlertProxyMonitors проходит по списку запущенных IIS веб-приложений, для каждого поднимает соответствующий объект RecycleLimitMonitor, и вызывает RaiseRecycleLimitEvent.
- RaiseRecycleLimitEvent поднимает список IObserver<RecycleLimitInfo>. Обработчики получают в качестве параметра RecycleLimitInfo, в котором они могут установить флаг RequestGC, который и возвращается в CollectInfrequently, вызывая индуцированную сборку мусора.
Дальнейшее расследование показывает, обработчики IObserver<RecycleLimitInfo> добавляются в методе RecycleLimitMonitor.Subscribe(), который вызывается в методе AspNetMemoryMonitor.Subscribe(). Также в классе AspNetMemoryMonitor вешается обработчик IObserver<RecycleLimitInfo> по умолчанию (класс RecycleLimitObserver), который чистит кэши ASP.NET, и иногда запрашивает сборку мусора.
Загадка Induced GC почти разгадана. Осталось выяснить вопрос, для чего вызывается эта сборка мусора. RecycleLimitMonitor следит за использованием памяти IIS (точнее, за цифрой private bytes), и когда ее использование приближается к определенному пределу, начинает по довольно запутанному алгоритму вызывать событие RaiseRecycleLimitEvent. В качестве предела памяти используется значение AspNetMemoryMonitor.ProcessPrivateBytesLimit, а в нем в свою очередь находится следующая логика:
- Если для Application Pool в IIS настроено значение 'Private Memory Limit (KB)', то значение в килобайтах берется оттуда
- Иначе для 64-битных систем берется 60% физической памяти (для 32-битных логика сложнее).
Вывод расследования такой: ASP.NET по использованию памяти приближается к своему пределу и начинает регулярно вызывать сборку мусора. Для 'Private Memory Limit (KB)' не было установлено значение, поэтому ASP.NET ограничивался 60% от физической памяти. Проблема маскировалась тем, что на сервере Task Manager показывал много свободной памяти и казалось, что ее хватает. Мы повысили значение 'Private Memory Limit (KB)' в настройках Application Pool в IIS до 80% от физической памяти. Это стимулирует ASP.NET использовать больше имеющейся памяти. Также мы добавили мониторинг счетчика производительности '.NET CLR Memory / # Induced GC', чтобы не пропустить, когда в следующий раз ASP.NET решит, что он приближается к пределу использования памяти.
Повторные измерения
Посмотрим, что же произошло со сборками мусора после всех этих изменений. Начнем с perfview /GCCollectOnly (время трассировки — 1 час), отчет GCStats:
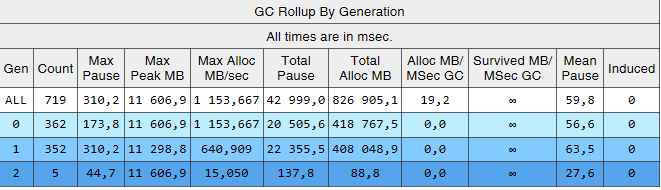
Видно, что сборок 2-го поколения теперь на 2 порядка меньше, чем 0-го и 1-го. Также, время этих сборок уменьшились. Индуцированных сборок больше не наблюдается. Посмотрим на список сборок 2-го поколения:
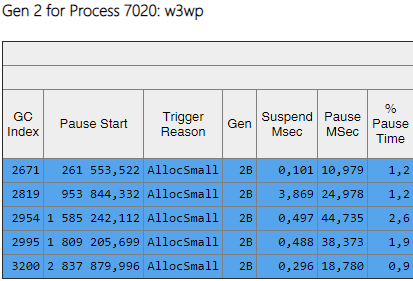
Из столбца Gen видно, что все сборки 2-го поколения стали фоновыми ('2B' означает 2-е поколение, Background). То есть, большая часть работы выполняется параллельно с выполнением приложения, а все потоки блокируются ненадолго (столбец 'Pause MSec'). Посмотрим на паузы при создании больших объектов:

Видно, что количество таких пауз при создании больших объектов упало в разы.
Итоги
Благодаря описанным в статье изменениям удалось значительно снизить количество и продолжительность сборок 2-го поколения. Удалось найти причину индуцированных сборок, и избавиться от них. Увеличилось количество сборок 0-го и 1-го поколения, но при этом уменьшилась их средняя продолжительность (с ~200 мсек до ~60 мсек). Максимальная продолжительность сборок 0-го и 1-го поколений уменьшилась, но не так заметно. Сборки 2-го поколения стали быстрее, длинные паузы до 1000мс полностью ушли.
Что касается ключевой метрики — «процент медленных запросов», она уменьшилась на 40% после всех изменений.
Благодаря проведенной работе мы поняли, какие счетчики производительности нужны для оценки ситуации с памятью и сборкой мусора, добавив их в Zabbix для постоянного мониторинга. Вот список самых важных, на которые мы обращаем внимание, и выясняем причину (например, повышенный поток запросов, большой объем передаваемых данных, баг в приложении):
| Счетчик производительности | Описание | Когда стоит обратить внимание |
| \Process(*)\Private Bytes | Количество памяти, выделенной для приложения | Значения сильно превышают порог. В качестве порога можно взять медиану за 2 недели от максимальных дневных показателей. |
| \.NET CLR Memory(*)\# Gen 2 Collections | Объем памяти в старшем поколении | |
| \.NET CLR Memory(*)\Large Object Heap size | Объем памяти для больших объектов | |
| \.NET CLR Memory(*)\% Time in GC | Процент времени, потраченный на сборку мусора | Значение больше 5%. |
| \.NET CLR Memory(*)\# Induced GC | Количество индуцированных сборок | Значение больше 0. |









