Если использовать БД временных рядов (timeseries db, wiki) как основное хранилище для сайта со статистикой, то вместо решения задачи можно получить много головной боли. Я работаю над проектом, где используется такая база, и иногда InfluxDB, о которой пойдет речь, преподносила вообще неожиданные сюрпризы.
Disclaimer: приведенные проблемы относятся к версии InfluxDB 1.7.4.
Почему time series?
Проект заключается в отслеживании транзакций в различных блокчейнах и отображении статистики. Конкретно — смотрим эмиссию и сжигание стэйбл-коинов (wiki). На основе этих транзакций нужно строить графики и показывать сводные таблицы.
При анализе транзакций пришла идея: использовать базу данных временных рядов InfluxDB как основное хранилище. Транзакции являются точками во времени и в модель временного ряда они хорошо вписываются.
Еще функции агрегации выглядели весьма удобно — для обработки графиков с большим периодом идеально подходят. Пользователю нужен график за год, а в базе лежит набор данных с таймфреймом в пять минут. Все сто тысяч точек ему отправлять бессмысленно — кроме долгой обработки, они и на экране не поместятся. Можно написать свою реализацию увеличения таймфрейма, либо воспользоваться встроенными в Influx функциями агрегации. С их помощью можно сгруппировать данные по дням и отправить нужные 365 точек.
Немного смущало то, что обычно такие базы используют с целью сбора метрик. Мониторинг серверов, iot-устройства, все, с чего «льются» миллионы точек вида: [<время> — <значение метрики>]. Но если база хорошо работает с большим потоком данных, то почему маленький объем должен вызывать проблемы? С этой мыслью взяли InfluxDB в работу.
Что еще удобного в InfluxDB
Кроме упомянутых функций агрегации есть еще одна замечательная вещь — continuous queries (doc). Это встроенный в БД планировщик, который может обрабатывать данные по расписанию. Например, можно каждые 24 часа группировать все записи за день, считать среднее и записывать одну новую точку в другую таблицу без написания собственных велосипедов.
Также есть retention policies (doc) — настройка удаления данных после какого-то периода. Полезно, когда например, нужно хранить нагрузку на CPU за неделю с измерениями раз в секунду, а на дистанции в пару месяцев такая точность не нужна. В такой ситуации можно сделать так:
- создать continuous query для агрегации данных в другую таблицу;
- для первой таблицы определить политику удаления метрик, которые старше той самой недели.
И Influx будет самостоятельно уменьшать размер данных и удалять ненужное.
О хранимых данных
Данных хранится не много: около 70 тысяч транзакций и еще один миллион точек с рыночной информацией. Добавление новых записей — не более 3000 точек в сутки. Также есть метрики по сайту, но там данных мало и по retention policy они хранятся не больше месяца.
Проблемы
В процессе разработки и последующего тестирования сервиса возникали все более и более критичные проблемы при эксплуатации InfluxDB.
1. Удаление данных
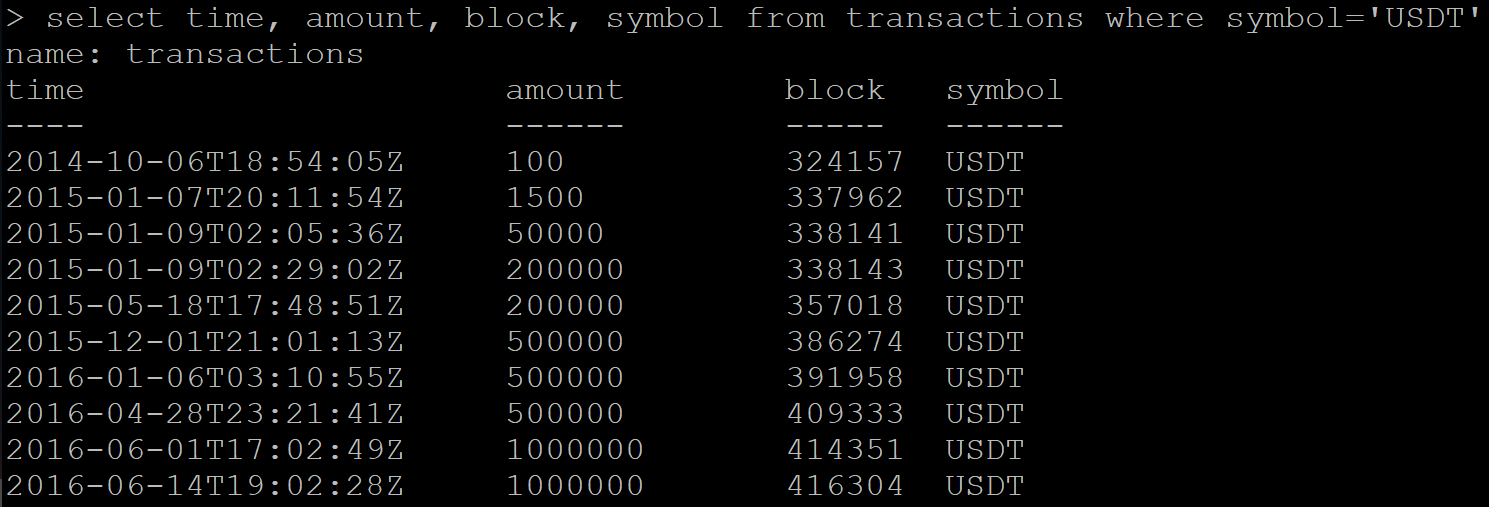
Есть серия данных с транзакциями:
SELECT time, amount, block, symbol FROM transactions WHERE symbol='USDT'Результат:
Посылаю команду на удаление данных:
DELETE FROM transactions WHERE symbol=’USDT’Далее делаю запрос на получение уже удаленных данных. И Influx вместо пустого ответа возвращает часть данных, которые должны быть удалены.
Пробую удалить таблицу целиком:
DROP MEASUREMENT transactionsПроверяю удаление таблицы:
SHOW MEASUREMENTSТаблицу в списке не наблюдаю, но новый запрос данных все еще возвращает тот же набор транзакций.
Проблема возникла у меня лишь один раз, так как кейс с удалением — единичный случай. Но такое поведение базы явно не вписывается в рамки «корректной» работы. Позже на github нашел открытый тикет почти годовой давности на эту тему.
В результате, помогло удаление и последующее восстановление всей базы.
2. Числа с плавающей точкой
Математические вычисления при использовании встроенных в InfluxDB функций дают ошибки точности. Не то, чтобы это было чем-то необычным, но неприятно.
В моем случае данные имеют финансовую составляющую и обрабатывать их хотелось бы с высокой точностью. Из-за этого в планах отказаться от continuous queries.
3. Continuous queries нельзя адаптировать к разным временным зонам
На сервисе есть таблица с дневной статистикой по транзакциям. Для каждого дня нужно сгруппировать все транзакции за эти сутки. Но день у каждого пользователя будет начинаться в разное время, следовательно и набор транзакций разный. По UTC есть 37 вариантов сдвига, для которых нужно агрегировать данные.
В InfluxDB при группировке по времени можно дополнительно указать сдвиг, например для московского времени (UTC+3):
SELECT MEAN("supply") FROM transactions GROUP BY symbol, time(1d, 3h) fill(previous)Но результат запроса будет некорректным. По какой-то причине сгруппированные по дням данные будут начинаться аж в 1677 году (InfluxDB официально поддерживает временной промежуток от этого года):
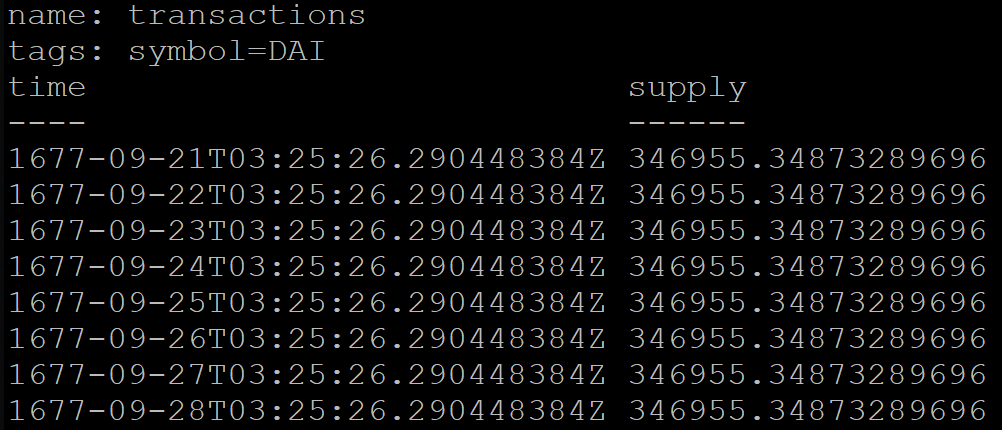
Для обхода этой проблемы временно перевели сервис на UTC+0.
4. Производительность
В интернете есть много бенчмарков со сравнениями InfluxDB и других БД. При первом ознакомлении они выглядели маркетинговыми материалами, но сейчас считаю, что доля правды в них есть.
Расскажу свой кейс.
Сервис предоставляет метод API, который возвращает статистику за последние сутки. При расчетах метод запрашивает базу трижды с такими запросами:
SELECT * FROM coins_info WHERE time <= NOW() GROUP BY symbol ORDER BY time DESC LIMIT 1SELECT * FROM dominance_info ORDER BY time DESC LIMIT 1SELECT * FROM transactions WHERE time >= NOW() - 24h ORDER BY time DESCОбъяснение:
- В первом запросе получаем последние точки для каждой монеты с данными по рынку. Восемь точек для восьми монет в моем случае.
- Второй запрос получает одну самую новую точку.
- Третий запрашивает список транзакций за последние сутки, их может быть несколько сотен.
Уточню, что в InfluxDB по тэгам и по времени автоматически строится индекс, который ускоряет запросы. В первом запросе symbol — это тэг.
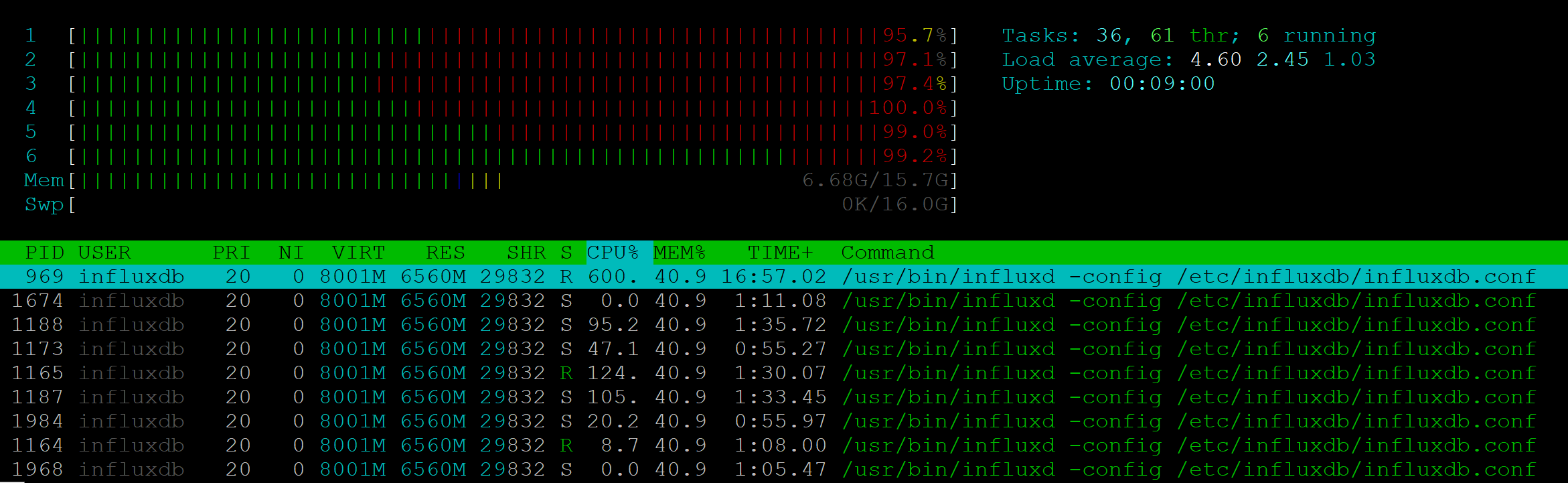
Я провел стресс-тест для этого метода API. Для 25 RPS сервер демонстрировал полную загрузку шести CPU:
При этом процесс NodeJs совсем не давал нагрузки.
Скорость выполнения деградировала уже на 7-10 RPS: если один клиент мог получить ответ за 200 мс, то 10 клиентов должны были ждать по секунде. 25 RPS — граница, с которой страдала стабильность, клиентам возвращались 500 ошибки.
С такой производительностью использовать Influx в нашем проекте невозможно. Более того: в проекте, где мониторинг нужно демонстрировать множеству клиентов — могут появиться схожие проблемы и сервер метрик будет перегружен.
Вывод
Самый главный вывод из полученного опыта — нельзя брать в проект неизвестную технологию без достаточного анализа. Простой скрининг открытых тикетов на github мог дать информацию, чтобы не брать InfluxDB в качестве основного хранилища данных.
InfluxDB должна была хорошо подойти под задачи моего проекта, но как показала практика, эта БД не отвечает потребностям и много косячит.
В репозитории проекта уже можно найти версию 2.0.0-beta, остается надеяться, что во второй версии будут значимые улучшения. А я пока пойду изучать документацию TimescaleDB.







