Это продолжение первой статьи о LPCNet. В первом демо мы представили архитектуру, которая сочетает обработку сигналов и глубокое обучение для повышения эффективности нейронного синтеза речи. На этот раз превратим LPCNet в нейронный речевой кодек с очень низким битрейтом (см. научную статью). Его можно использовать на текущем оборудовании и даже на телефонах.
Впервые нейронный вокодер работает в реальном времени на одном процессорном ядре телефона, а не на высокоскоростном GPU. Итоговый битрейт 1600 бит/с примерно в десять раз меньше, чем выдают обычные широкополосные кодеки. Качество намного лучше, чем у существующих вокодеров с очень низким битрейтом и сопоставимо с более традиционными кодеками, использующими более высокий битрейт.
Кодеры формы сигналов и вокодеры
Есть два больших типа речевых кодеков: кодеры формы сигналов (waveform coder) и вокодеры. Кодеры формы сигналов включают Opus, AMR/AMR-WB и все кодеки, которые могут применяться для музыки. Они пытаются обеспечить декодированную форму волны как можно ближе к оригиналу — обычно с учётом некоторых перцептивных особенностей. С другой стороны, вокодеры — это на самом деле синтезаторы. Энкодер извлекает информацию о высоте звука и форме речевого тракта, передаёт эту информацию в декодер, а тот заново синтезирует речь. Это почти как распознавание речи с последующим чтением текста в синтезаторе речи, за исключением того, что энкодер текста намного проще/быстрее, чем распознавание речи (и передаёт немного больше информации).
Вокодеры существуют с 70-х годов, но поскольку их декодеры выполняют синтез речи, они не могут быть намного лучше, чем обычные системы речевого синтеза, которые до недавнего времени звучали просто ужасно. Вот почему вокодеры обычно использовались на скоростях ниже 3 КБ/с. Кроме того, кодеры формы сигналов просто обеспечивают лучшее качество. Так продолжалось до недавнего времени, когда появились нейронные системы синтеза речи, такие как WaveNet. Внезапно синтез начал звучать намного лучше, и, конечно, появились желающие сделать вокодер из WaveNet.
Обзор LPCNet
WaveNet производит очень качественную речь, но требует сотен гигафлопс вычислительной мощности. LPCNet значительно снизил сложность вычислений. Вокодер основан на WaveRNN, которая улучшает WaveNet с помощью рекуррентной нейронной сеть (RNN) и разреженных матриц. LPCNet дополнительно улучшает WaveRNN с помощью линейного предсказания (LPC), которое хорошо себя проявило в старых вокодерах. Оно предсказывает сэмпл по линейной комбинации предыдущих сэмплов и, самое главное, делает это многократно быстрее нейронной сети. Конечно, оно не универсально (иначе вокодеры 70-х звучали бы здорово), но может серьёзно снизить нагрузку на нейросеть. Это позволяет использовать сеть меньшего размера, чем WaveRNN, без ущерба для качества.
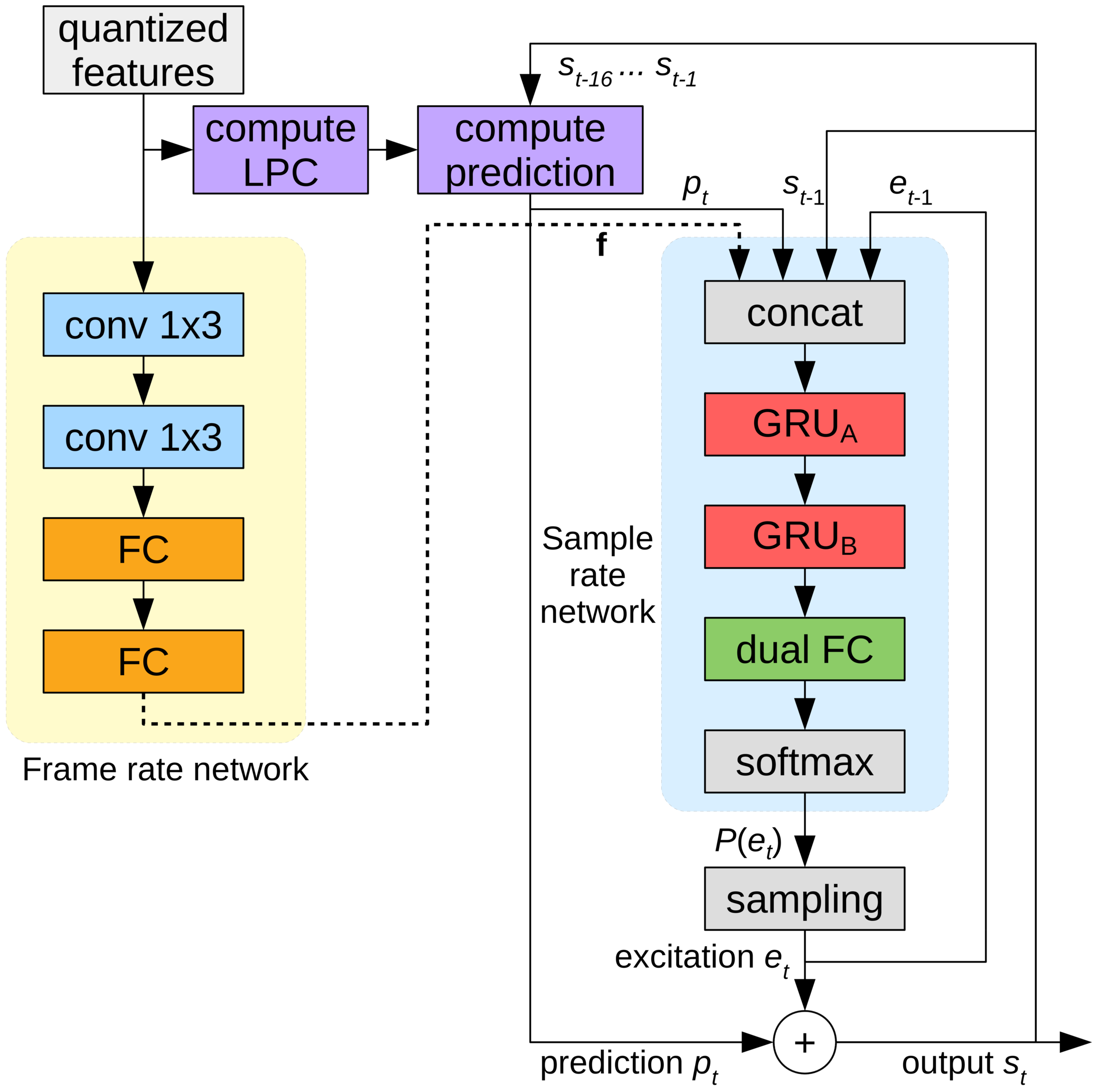
Более подробно рассмотрим LPCNet. Жёлтая часть слева вычисляется один раз на фрейм, а её выход используется для сети частоты дискретизации справа (синяя). Вычислительный блок предсказывает сэмпл в момент времени t на основе предыдущих сэмплов и коэффициентов линейного предсказания
Характеристики компрессии
LPCNet синтезирует речь из векторов по 20 признаков на каждый фрейм по 10 мс. Из них 18 признаков — это кепстральные коэффициенты, представляющие форму спектра. Два оставшихся описывают высоту: один параметр для шага высоты (pitch period), а другой для силы (насколько сигнал коррелирует с самим собой, если ввести задержку на шаг высоты). Если хранить параметры в виде значений с плавающей запятой, то вся эта информация занимает до 64 кбит/с при хранении или передаче. Это слишком много, ведь даже кодек Opus обеспечивает очень качественное кодирование речи всего на 16 кбит/с (для 16 кГц моно). Очевидно, нужно применить здесь сильную компрессию.
Высота
Все кодеки в значительной степени полагаются на высоту тона, но в отличие от кодеров формы волны, где высота «просто» помогает уменьшить избыточность, у вокодеров нет запасного варианта. Если неправильно подобрать высоту, они начнут генерировать плохо звучащую (или даже неразборчивую) речь. Не вдаваясь в подробности (см. научную статью), энкодер LPCNet изо всех сил пытается не ошибиться по высоте. Поиск начинается с поиска корреляций по времени в речевом сигнале. См. ниже, как работает типичный поиск.

Шаг высоты — это период, в течение которого сигнал шага повторяется. На анимации происходит поиск шага, который соответствует максимальной корреляции между сигналом x(n) и его копией x(n-T) с задержкой. Значение T с максимальной корреляцией является шагом высоты
Эту информацию нужно закодировать как можно меньшим количеством битов, не слишком ухудшая результат. Поскольку мы по природе воспринимаем частоту в логарифмической шкале (например, каждая музыкальная октава удваивает предыдущую частоту), есть смысл в логарифмическом кодировании. Высота речевого сигнала у большинства людей (мы не пытаемся здесь покрыть сопрано) находится между 62,5 и 500 Гц. С семью битами (128 возможных значений) мы получаем разрешение около четверти тона (разница между и до и ре — один тон).
Итак, с высотой закончили? Ну, не так быстро. Люди говорят не как роботы из фильмов 1960-х. Высота голоса может меняться даже в рамках 40-миллисекундного пакета. Нужно это учесть, оставив биты для параметра изменения высоты: 3 бита для кодирования разницы до 2,5 полутонов между началом и концом пакета. Наконец, нужно закодировать корреляцию шагов высоты, различая гласные и согласные (например, s и f). Для корреляции достаточно двух битов.
Кепстр
В то время как высота содержит внешние характеристики речи (просодия, эмоции, акцент,...), спектральная характеристика определяет, что именно было сказано (за исключением тональных языков, таких как китайский, где высота важна для смысла). Голосовые связки производят примерно одинаковый звук для любой гласной, но форма голосового тракта определяет, какой звук будет произнесён. Голосовой тракт действует как фильтр, и задача энкодера — оценить этот фильтр и передать его декодеру. Это можно эффективно сделать, если преобразовать спектр в кепстр (да, это «спектр» с изменённым порядком букв, вот такие мы весёлые ребята в цифровой обработке сигналов).
Для входного сигнала на 16 кГц кепстр в основном представляет вектор из 18 чисел каждые 10 мс, которые нужно сжать как можно сильнее. Поскольку у нас в пакете на 40 мс четыре таких вектора и они обычно похожи друг на друга, мы хотим максимально устранить избыточность. Это можно сделать, используя соседние векторы в качестве предикторов и передавая только разницу между предсказанием и реальным значением. В то же время мы не хотим слишком зависеть от предыдущих пакетов, если один из них пропадёт. Похоже, проблема уже решена…
Если у вас есть только молоток, всё выглядит как гвоздь — Абрахам Маслоу.
Если вы много работали с видеокодеками, то наверняка встречались с понятием B-фреймов. В отличие от видеокодеков, которые разделяют кадр на множество пакетов, у нас, наоборот, много фреймов в одном пакете. Начинаем с кодирования ключевого фрейма, т. е. независимого вектора, и конца пакета. Этот вектор кодируется без предсказания, занимая 37 бит: 7 для общей энергии (первый кепстральный коэффициент) и 30 бит для остальных параметров, используя векторное квантование (VQ). Затем идут (иерархические) B-фреймы. Из двух ключевиков (один из текущего пакета и один из предыдущего) прогнозируется кепстр между ними. В качестве предиктора для кодирования разницы между реальным значением и предсказанием можно выбрать любой из двух ключевых кадров или их среднее значение. Мы снова применяем VQ и кодируем этот вектор, используя в общей сложности 13 бит, включая выбор предиктора. Теперь у нас остаётся только два вектора и очень мало бит. Используем последние 3 бита, чтобы просто выбрать предиктор для оставшихся векторов. Конечно, всё это гораздо легче понять на рисунке:

Предсказание и квантование кепстра для пакета k. Зелёные векторы квантуются независимо, синие — с предсказанием, а красные используют предсказание без остаточного квантования. Предсказание показано стрелками
Собираем всё вместе
Сложив всё перечисленное, получаем 64 бита на 40-миллисекундный пакет или 1600 бит в секунду. Если хочется посчитать коэффициент сжатия, то несжатая широкополосная речь — это 256 кбит/с (16 кГц по 16 бит на сэмпл), что означает степень сжатия в 160 раз! Конечно, всегда можно поиграть с квантователями и получить более низкий или высокий битрейт (с соответствующим влиянием на качество), но нужно же с чего-то начать. Вот табличка с раскладом, куда уходят эти биты.
| Распределение битов | |
| Параметр | Бит |
| Шаг высоты | 6 |
| Модуляция высоты | 3 |
| Корреляция высоты | 2 |
| Энергия | 7 |
| Независимый кепстр VQ (40 мс) | 30 |
| Предсказанный кепстр VQ (20 мс) | 13 |
| Интерполяция кепстра (10 мс) | 3 |
| Всего | 64 |
По 64 бита на пакет 40 мс, при 25 пакетах в секунду получается 1600 бит/с.
Реализация
Исходный код LPCNet доступен под лицензией BSD. Он включает библиотеку, которая упрощает использование кодека. Обратите внимание, что разработка не закончена: и формат, и API обязательно изменятся. В репозитории также есть демонстрационное приложение
lpcnet_demo, в котором легко протестировать кодек из командной строки. Полные инструкции см. в файле README.md.Кто хочет копнуть глубже, есть вариант обучить новые модели и/или использовать LPCNet в качестве строительного блока для других приложений, таких как синтез речи (LPCNet — это только один компонент синтезатора, он не осуществляет синтез сам по себе).
Производительность
Нейронный синтез речи требует много ресурсов. На прошлогодней конференции ICASSP Бастиан Клейн с коллегами из Google/DeepMind представили кодек на 2400 бит/с на основе WaveNet, получающий битовый поток от codec2. Хотя это звучит потрясающе, вычислительная сложность в сотни гигафлопс означает, что его невозможно запустить в реальном времени без дорогого GPU и серьёзных усилий.
Напротив, наш кодек на 1600 бит/с производит всего 3 гигафлопса и предназначен для работы в режиме реального времени на гораздо более доступном оборудовании. Фактически, его можно прямо сегодня применять в реальных приложениях. Оптимизация потребовала написать немного кода для наборов инструкций AVX2/FMA и Neon (только встроенный код, без ассемблера). Благодаря этому мы теперь можем кодировать (и особенно декодировать) речь в режиме реального времени не только на ПК, но и на более-менее современных телефонах. Ниже приведена производительность на процессорах x86 и ARM.
| Производительность | |||
| CPU | Частота | % одного ядра | К реальному времени |
| AMD 2990WX (Threadripper) | 3,0 ГГц* | 14% | 7,0x |
| Intel Xeon E5-2640 v4 (Broadwell) | 2,4 ГГц* | 20% | 5.0x |
| Snapdragon 855 (Cortex-A76 на Galaxy S10) | 2,82 ГГц | 31% | 3.2x |
| Snapdragon 845 (Cortex-A75 на Pixel 3) | 2,5 ГГц | 68% | 1,47x |
| AMD A1100 (Cortex-A57) | 1,7 ГГц | 102% | 0,98x |
| BCM2837 (Cortex-A53 на Raspberry Pi 3) | 1,2 ГГц | 310% | 0,32x |
| * турбо-режим | |||
Цифры довольно интересные. Хотя показаны только Broadwell и Threadripper, на платформе x86 у процессоров Haswell и Skylake похожая производительность (с учётом тактовой частоты). Однако процессоры ARM заметно отличаются друг от друга. Даже с учётом разницы в частоте A76 в пять-шесть раз быстрее A53: вполне ожидаемо, поскольку A53 в основном используется для энергоэффективности (например, в системах big.LITTLE). Тем не менее, LPCNet вполне может работать в режиме реального времени на современном телефоне, используя только одно ядро. Хотя было бы неплохо запустить его в реальном времени и на Raspberry Pi 3. Сейчас до этого далеко, но нет ничего невозможного.
На x86 по прежнему остаётся загадкой причина ограничения производительности в пять раз от теоретического максимума. Как известно, операции умножения матрицы на вектор менее эффективны, чем матрицы на матрицу, потому что там больше загрузок за операцию — конкретно, одна загрузку с матрицы для каждой операции FMA. С одной стороны, производительность связана с кэшем L2, который предоставляет только 16 бит на цикл. С другой стороны, Intel утверждает, что L2 может дать до 32 бит на цикл на Broadwell и 64 бит на цикл на Skylake.
Результаты
Мы провели аудиотесты по образцу MUSHRA, чтобы сравнить качество кодирования. Условия тестирования:
- Образец: оригинал (если у вас результат получается лучше, чем в оригинале, с вашем тестом явно что-то не так)
- LPCNet на 1600 бит/с: наше демо
- Несжатая LPNet: «LPNet со 122 эквивалентными единицами» из первой статьи
- Opus на 9000 бит/с wideband: самый низкий битрейт, при котором Opus 1.3 кодирует широкополосный звук
- MELP на 2400 бит/с: известный вокодер с низким битрейтом (похожий по качеству на codec2)
- Speex 4000 бит/с: этот широкополосный вокодер никогда не следует использовать, но это хороший ориентир для дна
В первом тесте (набор 1) у нас восемь речевых фрагментов высказываний от двух мужчин и двух женщин. Файлы в первом наборе относятся к той же базе данных (т. е. к тем же условиям записи), которая использовалась для обучения, но эти конкретные люди были исключены из обучающего набора. Во втором тесте (набор 2) мы использовали некоторые файлы из теста Opus (несжатые), записывая звук в разных условиях, чтобы убедиться, что LPCNet выходит на некое обобщение. В обоих тестах по 100 участников, так что погрешности довольно малы. См. результаты ниже.

Субъективное качество (MUSHRA) в двух тестах
В целом, LPCNet на 1600 бит/с выглядит неплохо — гораздо лучше, чем MELP на 2400 бит/с, и не сильно отставая от Opus на 9000 бит/с. В то же время несжатая LPCNet немного лучше по качеству, чем Opus на 9000 бит/с. Это значит, что возможно обеспечить лучшее качестве, чем у Opus, на битрейтах в диапазоне 2000−6000 бит/с.
Послушайте сами
Вот образцы из аудиотеста:
Женщина (набор 1)
Мужчина (набор 1)
Смешанный (набор 2)
Где это можно использовать?
Мы считаем, что это крутая технология сама по себе, но у неё есть и практическое применение. Вот лишь некоторые варианты.
VoIP в странах с плохой связью
Не у всех постоянно есть в наличии высокоскоростное соединение. В некоторых странах связь очень медленная и ненадёжная. Речевой кодек на 1600 бит/с нормально работает в таких условиях, даже передавая пакеты несколько раз для надёжности. Конечно, из-за накладных расходов на заголовки пакетов (40 байт для IP+UDP+RTP) лучше делать пакеты побольше: 40, 80 или 120 мс.
Любительское/HF радио
Вот уже десять лет Дэвид Роу работает над кодированием речи для радиосвязи. Он разработал Codec2, который передаёт голос на скорости от 700 до 3200 бит/с. В течение прошлого года мы с Дэвидом обсуждали, как улучшить Codec2 с помощью нейронного синтеза, и вот теперь наконец-то это сделали. В своём блоге Дэвид написал о собственной реализации кодека на базе LPCNet для интеграции с FreeDV.
Повышение надёжности при потере пакетов
Возможность кодировать битовый поток приличного качества в небольшом количестве бит полезна для обеспечения избыточности на ненадёжном канале. В Opus есть механизм прямой коррекции ошибок (FEC), известный как LBRR, который кодирует предыдущий фрейм с пониженным битрейтом и отправляет его в текущем фрейме. Он хорошо работает, но добавляет значительные накладные расходы. Дублирование потока на 1600 бит/с намного эффективнее.
Планы
Предстоит изучить ещё много возможностей применения LPCNet. Например, улучшение существующих кодеков (того же Opus). Как и в других кодеках, качество Opus довольно быстро деградирует на очень низких битрейтах (ниже 8000 бит/с), потому что кодеку формы сигнала не хватает бит для соответствия оригиналу. Но переданной информации линейного предсказания достаточно для LPCNet, чтобы синтезировать прилично звучащую речь — лучше, чем Opus может сделать на этом битрейте. Кроме того, остальная информация, передаваемая Opus (остаточный прогноз), помогает LPCNet синтезировать ещё лучший результат. В некотором смысле LPCNet можно применить в качестве причудливого постфильтра для улучшения качества Opus (или любого другого кодека) без изменения битового потока (т. е. с сохранением полной совместимости).
Дополнительные ресурсы
- Ж.-М.Валин, Я.Скоглунд, Широкополосный нейронный вокодер на 1,6 Кбит/с с использованием LPCNet, Отправлено в Interspeech 2019, arXiv:1903.12087.
- Ж.-М.Валин, Я.Скоглунд, LPCNet: улучшенный нейронный синтез речи через линейное предсказание, Proc. ICASSP, 2019, arXiv:1810.11846.
- A.ван ден Оорд, С.Дилеман, Х.Зен, К.Симонян, O.Виньялс, A.Грейвс, Н.Калхбреннер, Э.Сеньор, K.Кавукуглу, WaveNet: генеративная модель для необработанного звука, 2016.
- Н. Карлхбреннер, Э.Эльсен, К.Симонян, С.Ноури, Н.Касагранде, Э.Локхарт, Ф.Стимберг, A.ван ден Оорд, С.Дилеман, K.Кавукуглу, Эффективный нейронный синтез звука, 2018.
- В.Б.Клейн, Ф.С.К.Лим, А.Любс, Я.Скоглунд, Ф.Стимберг, К.Ванг, Т.С.Уолтерс, Кодирование речи с низким битрейтом на основе Wavenet, 2018
- Исходный код LPCNet.
- Кодек для FreeDV на базе LPCNet Дэвида Роу.
- Присоединяйтесь к обсуждению разработки на #opus at irc.freenode.net (→веб-интерфейс)







