 Когда я представляюсь и говорю, чем занимается наш стартап, у собеседника сразу возникает вопрос: вы раньше работали в Facebook, или ваша разработка создана под влиянием Facebook? Многие знают об усилиях Facebook по обслуживанию своего социального графа, потому что компания опубликовала несколько статей об инфраструктуре этого графа, который она тщательно выстроила.
Когда я представляюсь и говорю, чем занимается наш стартап, у собеседника сразу возникает вопрос: вы раньше работали в Facebook, или ваша разработка создана под влиянием Facebook? Многие знают об усилиях Facebook по обслуживанию своего социального графа, потому что компания опубликовала несколько статей об инфраструктуре этого графа, который она тщательно выстроила.Google рассказывала о своём графе знаний, но ничего о внутренней инфраструктуре. Однако в компании тоже есть для него специализированные подсистемы. На самом деле сейчас графу знаний уделяется большое внимание. Лично я поставил на эту лошадку минимум два своих повышения по службе — и начал работу над новым графом ещё в 2010 году.
Google было необходимо построить инфраструктуру не только для обслуживания сложных взаимосвязей в Knowledge Graph, но и для поддержки всех тематических блоков OneBox в поисковой выдаче, которые имеют доступ к структурированным данным. Инфраструктура необходима для 1) качественного обхода фактов с 2) достаточно высокой пропускной способностью и 3) достаточно низкой задержкой, чтобы успеть попасть в хорошую долю поисковых запросов в вебе. Оказалось, что ни одна доступная система или БД не может выполнить все три действия.
Теперь, когда я рассказал, зачем нужна инфраструктура, в остальной части статьи расскажу о своём опыте построения таких систем, в том числе для Knowledge Graph и OneBox.
Откуда я это знаю?
Вкратце представлюсь. Я работал в Google с 2006 по 2013 год. Сначала в качестве стажёра, затем инженера-программиста в инфраструктуре веб-поиска. В 2010 году Google приобрела Metaweb, а моя команда только что запустила Caffeine. Я хотел заняться чем-то другим — и начал работать с ребятами из Metaweb (в Сан-Франциско), тратя время на поездки между Сан-Франциско и Маунтин-Вью. Я хотел выяснить, как использовать граф знаний для улучшения веб-поиска.
В Google и до меня были такие проекты. Примечательно, что проект под названием Squared создан в нью-йоркском офисе, и ходили некоторые разговоры о Knowledge Cards. Потом были спорадические усилия отдельных лиц/небольших команд, но в то время не существовало установленной командной цепочки, что в конечном итоге заставило меня покинуть Google. Но к этому вернёмся позже…
История Metaweb
Как уже упоминалось, Google приобрела Metaweb в 2010 году. Metaweb построил высококачественный граф знаний, используя несколько методов, включая краулинг и парсинг Википедии, а также краудсорсинговую систему редактирования в вики-стиле с использованием Freebase. Всё это работало на базе данных графов собственной разработки Graphd — демоне графов (теперь опубликован на GitHub).
Graphd обладал некоторыми довольно типичными свойствами. Как демон, он работал на одном сервере, все данные хранил в памяти и мог выдавать целый сайт Freebase. После покупки Google ставила одной из задач продолжить работу с Freebase.
Google построила империю на стандартном железе и распределённом софте. Одна серверная СУБД никогда бы не смогла обслуживать и краулинг, и индексирование, и поисковую выдачу. Сначала создали SSTable, затем Bigtable, который горизонтально масштабируется до сотен или тысяч машин, которые совместно обслуживают петабайты данных. Машины выделяет Borg (отсюда появились K8), они общаются по Stubby (отсюда появился gRPC) с резолвингом IP-адресов через нейм-сервис Borg (BNC внутри K8) и хранят данные в Google File System (GFS, можно сказать Hadoop FS). Процессы могут погибнуть, машины могут сломаться, но система в целом неубиваема и продолжит гудеть.
В такое окружение попал Graphd. Идея БД, обслуживающей целый веб-сайт на одном сервере, чужда Google (включая меня). В частности, для работы Graphd требовалось 64 ГБ или больше памяти. Если вам кажется, что это немного, вспомните: это 2010 год. Большинство серверов Google максимум оснащались 32 ГБ. Фактически, Google пришлось закупать специальные машины с достаточным объёмом оперативной памяти, чтобы обслуживать Graphd в его тогдашнем виде.
Замена Graphd
Начался мозговой штурм, как переместить данные Graphd или переписать систему для работы распределённым способом. Но, видите ли, графы сложны. Это вам не базы данных ключ-значение, где можно просто взять кусок данных, переместить его на другой сервер и выдать их при запросе ключа. Графы выполняют эффективные объединения и обходы, которые требуют, чтобы программное обеспечение работало определённым образом.
Одна из идей заключалась в использовании проекта под названием MindMeld (IIRC). Предполагалась, что память с другого сервера станет доступна гораздо быстрее через сетевое оборудование. Должно было работать быстрее, чем обычные RPC, достаточно быстро, чтобы псевдо-реплицировать прямой доступ к памяти, требуемый базой данных в памяти. Но идея не зашла слишком далеко.
Другая идея, которая фактически стала проектом, заключалась в создании действительно распределённой системы обслуживания графов. Что-то, что может не только заменить Graphd для Freebase, но и реально работать в продакшне. Её назвали Dgraph — распределённый граф, перевёрнуто от Graphd (граф-демон).
Если вам интересно, то да. Мой стартап Dgraph Labs, компания и проект с открытым исходным кодом Dgraph названы в честь того проекта в Google (примечание: Dgraph является торговой маркой Dgraph Labs; насколько мне известно, Google не выпускает наружу проекты с названиями, которые совпадают с внутренними).
Почти во всём дальнейшем тексте, когда я упоминаю Dgraph, то имею в виду внутренний проект Google, а не созданными нами проект с открытым исходным кодом. Но об этом позже.
История Cerebro: движок знаний
Создание ненароком инфраструктуры для графов
Хотя я в целом знал о попытках Dgraph заменить Graphd, моей целью было создать что-то для улучшения веб-поиска. В Metaweb я познакомился с инженером-исследователем DH, который создал Cubed.
Как я уже упоминал, разношёрстный группа инженеров из нью-йоркского подразделения разработала Google Squared. Но система от DH была гораздо лучше. Я начал думать, как бы внедрить её в Google. У Google были кусочки головоломки, которые я мог легко использовать.
Первая часть головоломки — поисковая система. Это способ с высокой степенью точности определить, какие слова связаны друг с другом. Например, когда вы видите фразу вроде [tom hanks movies], она может сказать вам, что [tom] и [hanks] связаны друг с другом. Точно так же из [san francisco weather] мы видим связь [san] и [francisco]. Это очевидные вещи для людей, но не столь очевидные для машин.
Вторая часть головоломки — понимание грамматики. Когда в запросе [books by french authors], машина может интерпретировать это как [books] от [french authors], т. е. книги тех авторов, которые являются французскими. Но она также может интерпретировать это как [french books] от [authors], т. е. книги на французском языке любого автора. Я применил теггер Part-Of-Speech (POS) из Стенфордского университета, чтобы лучше разобрать грамматику и построить дерево.
Третья часть головоломки — понимание сущностей. [french] может означать многое. Это может быть страна (регион), национальность (относящаяся к французскому народу), кухня (относящаяся к еде) или язык. Тут я применил другую систему, чтобы получить список сущностей, которым может соответствовать слово или фраза.
Четвёртая часть головоломки заключалась в понимании отношений между сущностями. Когда известно, как связать слова в фразы, в каком порядке фразы должны быть выполнены, то есть их грамматика, и каким сущностям они могут соответствовать, нужно найти отношения между этими сущностями, чтобы создать машинные интерпретации. Например, запускаем запрос [books by french authors], а POS говорит, что это [books] от [french authors]. У нас есть несколько сущностей для [french] и несколько для [authors]: алгоритм должен определить, как они связаны. Например, они могут быть связаны по месту рождения, то есть авторы, которые родились во Франции (хотя могут писать на английском языке). Или это могут быть авторы, которые являются французскими гражданами. Или авторы, которые могут говорить или писать по-французски (но могут не иметь отношения к Франции как к стране), или авторы, которые просто любят блюда французской кухни.
Система графов на поисковом индексе
Чтобы определить, есть ли связь между объектами и как они связаны, нужна система графов. Graphd никогда не собирался масштабироваться до уровня Google, но можно было использовать сам поиск. Данные Knowledge Graph хранятся в формате троек Triples, то есть каждый факт представлен тремя частями: субъектом (сущностью), предикатом (отношением) и объектом (другой сущностью). Запросы идут как
[S P] → [O] или [P O] → [S], а иногда [S O] → [P].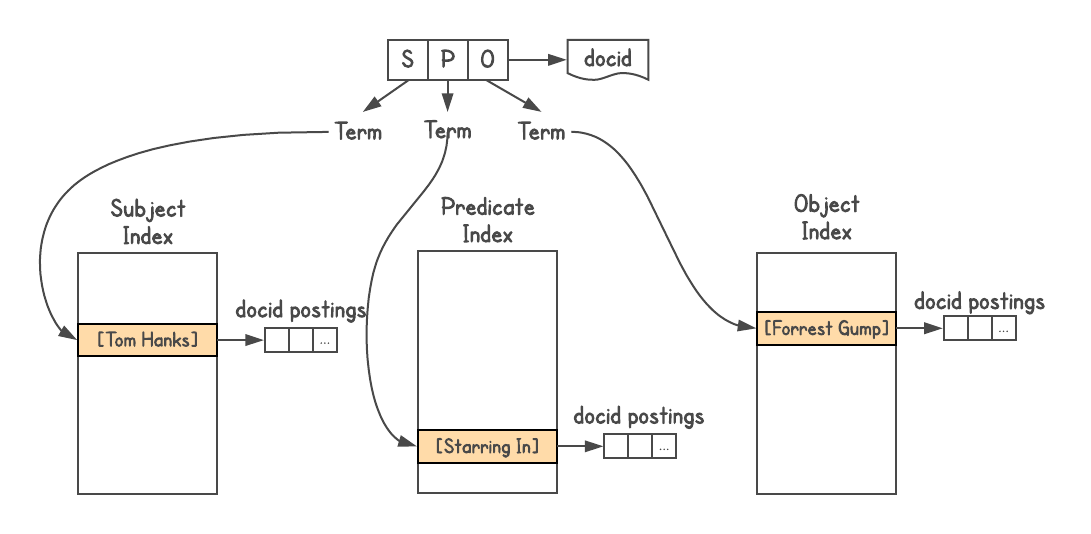
Я использовал поисковый индекс Google, назначил docid каждой тройке и построил три индекса, по одному для S, P и O. Кроме того, индекс допускает вложения, поэтому я добавил информацию о типе каждой сущности (т. е. актёр, книга, человек и т. д.).
Я сделал такую систему, хотя видел проблему с глубиной объединений (что объясняется ниже) и она не подходит для сложных запросов. Реально, когда кто-то из команды Metaweb попросил меня опубликовать систему для коллег, я отказался.
Для определения отношений можно посмотреть, сколько результатов даёт каждый запрос. Например, сколько результатов дают [french] и [author]? Берём эти результаты и смотрим, как они связаны с [books] и т. д. Так появилось множество машинных интерпретаций запроса. Например, запрос [tom hanks movies] генерирует разнообразные интерпретации, такие как [movies directed by tom hanks], [movies starring tom hanks], [movies produced by tom hanks], но автоматически отвергает интерпретации вроде [movies named tom hanks].
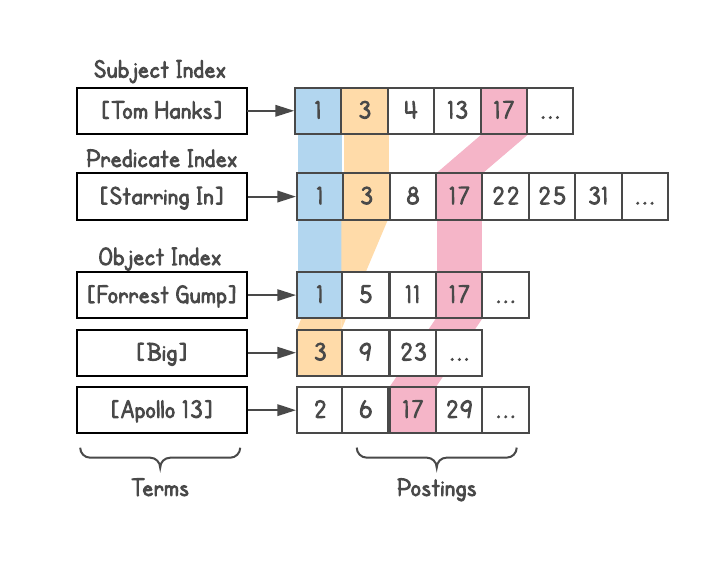
Каждая интерпретация генерирует список результатов — допустимых сущностей на графике — а также возвращает их типы (присутствующие во вложениях). Это оказалось чрезвычайно мощной функцией, потому что понимание типа результатов открыло такие возможности, как фильтрация, сортировка или дальнейшее расширение. Выдачу с фильмами вы можете отсортировать по году выпуска, длине фильма (короткий, длинный), языку, полученным наградам и т. д.
Проект казался настолько интеллектуальным, что мы (DH тоже частично был вовлечён как эксперт по графу знаний) назвали его Cerebro, в честь одноимённого устройства из фильма «Люди Икс».
Cerebro часто раскрывала очень интересные факты, которых изначально не было в поисковом запросе. Например, по запросу [US presidents], Cerebro поймёт, что президенты — это люди, а у людей есть рост. Это позволяет отсортировать президентов по росту и показать, что Авраам Линкольн — самый высокий президент США. Кроме того, людей можно отфильтровать по национальности. В этом случае в списке появляются Америка и Великобритания, потому что у США был один британский президент, а именно Джордж Вашингтон. (Отказ от ответственности: результаты основаны на состоянии графа знаний на момент проведения экспериментов; не могу ручаться за их правильность).
Синие ссылки против знаний
Cerebro удалось действительно понять запросы пользователей. Получив данные по всему графу, мы могли бы генерировать машинные интерпретации запроса, генерировать список результатов и многое понять из этих результатов для дальнейшего исследования графа. Выше объяснялось: как только система понимает, что имеет дело с фильмами, людьми или книгами и т. д., можно активировать определённые фильтры и сортировки. Можно сделать ещё обход узлов и показать связанные сведения: от [US presidents] к [schools they went to] или [children they fathered]. Вот некоторые другие запросы, которые система сгенерировала сама: [female african american politicians], [bollywood actors married to politicians], [children of us presidents], [movies starring tom hanks released in the 90s]
Такую возможность перейти от одного списка к другому DH продемонстрировал в другом проекте под названием Parallax.
Cerebro показала очень впечатляющий результат, и руководство Metaweb её поддержало. Даже в части инфраструктуры она оказалась работоспособной и функциональной. Я называл её движком знаний (подобно поисковому движку). Но в Google этой темой никто не руководил конкретно. Моего менеджера она мало интересовала, мне советовали поговорить то с одним человеком, то с другим, и в итоге я получил шанс продемонстрировать систему одному очень высокому топ-менеджеру по поиску.
Ответ оказался не тем, на который я надеялся. При демонстрации результатов движка знаний по запросу [books by french authors] он запустил поиск Google, показал десять строчек с синими ссылками и сказал, что Google может делать то же самое. Кроме того, они не хотят забирать трафик с сайтов, потому что те разозлятся.
Если вы считаете, что он прав, подумайте вот о чём: когда Google делает поиск в интернете, то действительно не понимает запрос. Система ищет правильные слова в нужном положении, с учётом веса страницы и так далее. Это очень сложная система, но она не понимает ни запроса, ни результатов. Пользователь сам выполняет всю работу: чтение, анализ, извлечение необходимой информации из результатов и дальнейшие поиски, сложение вместе полного списка результатов и т. д.
Например, для [books by french authors] человек сначала попытается найти исчерпывающий список, хотя одной страницы с таким списком может не найтись. Затем отсортировать эти книги по годам издания или отфильтровать по издательствам и так далее — всё это требует от человека обработки большого объёма информации, многочисленных поисков и обработки результатов. Cerebro в состоянии сократить эти усилия и сделать взаимодействие с пользователем простым и безупречным.
Но тогда не было полного понимания важности графа знаний. Руководство не было уверено в его полезности или в том, как его связать с поиском. Этот новый подход к знаниям нелегко усвоить организации, которая добилась столь значительного успеха, предоставляя пользователям ссылки на веб-страницы.
В течение года я боролся с непониманием менеджеров, и в конце концов сдался. Менеджер из шанхайского офиса обратился ко мне, и я передал ему проект в июне 2011 года. Он поставил на него команду из 15 инженеров. Я провёл неделю в Шанхае, передавая инженерам все, что я создал и чему научился. DH также был вовлечён в это дело, и он долгое время руководил той командой.
Проблема глубины объединения (join-depth)
В системе работы с графами Cerebro была проблема глубины объединения. Объединение (join) выполняется, когда результат раннего запроса необходим для выполнения более позднего. Типичное объединение включает некоторый
SELECT, т. е. фильтр в определённых результатах из универсального набора данных, а затем эти результаты используются для фильтрации по другой части набора данных. Объясню на примере.Скажем, вы хотите знать [people in SF who eat sushi]. Всем людям присвоены некоторые данные, в том числе о том, кто живёт в каком городе и какую пищу ест.
Приведённый выше запрос является одноуровневым объединением (single-level join). Если приложение обратится к БД, то сделает один запрос для первого шага. Затем несколько запросов (по одному запросу на каждый результат), чтобы выяснить, что ест каждый человек, выбирая только тех, кто ест суши.
Второй шаг страдает от проблемы веерного развёртывания (fan-out). Если первый шаг даёт миллион результатов (население Сан-Франциско), то второй шаг должен выдать по запросу на каждого, запрашивая их привычки к еде, а затем применив фильтр.

Инженеры распределённых систем обычно решают эту проблему путём броадкаста, то есть повсеместной рассылки. Они накапливают соответствующие результаты, делая по одному запросу к каждому серверу в кластере. Это обеспечивает объединение (join), но вызывает проблемы с задержкой запроса.
В распределённой системе броадкаст плохо работает. Эту проблему лучше всего объясняет Джефф Дин из Google в своём выступлении «Достижение быстрого отклика в крупных онлайновых сервисах» (видео, слайды). Общая задержка всегда больше, чем задержка самого медленного компонента. Небольшие блики на отдельных компьютерах вызывают задержки, а включение в запрос многих компьютеров резко увеличивает вероятность задержек.
Рассмотрим сервер, у которого в 50% случаев задержка более 1 мс, а в 1% случаев — более 1 с. Если запрос идёт только к одному такому серверу, только 1% ответов превышает секунду. Но если запрос идёт к сотне таких серверов, то 63% ответов превышают секунду.
Таким образом, броадкаст одного запроса сильно увеличивает задержку. Теперь подумайте, а если нужно два, три или более объединения? Это слишком медленно для выполнения в реальном времени.
Проблема веерного развёртывания при броадкасте запроса свойственна большинству ненативных БД графов, включая граф Janus, Twitter FlockDB и Facebook TAO.
Распределённые объединения — сложная проблема. Нативные базы данных графов позволяют избежать этой проблемы, сохраняя универсальный набор данных в рамках одного сервера (автономная БД) и выполняя все объединения, не обращаясь к другим серверам. Например, так делает Neo4j.
Dgraph: объединения с произвольной глубиной
Завершив работу над Cerebro и имея опыт построения системы обслуживания графов, я принял участие в проекте Dgraph, став одним из трёх технических руководителей проекта. Мы применили инновационные концепции, которые решили проблему глубины объединения.
В частности, Dgraph так разделяет данные графа, что каждое объединение может полностью выполнить одна машина. Возвращаясь к объекту
subject-predicate-object (SPO), каждый инстанс Dgraph содержит все субъекты и объекты, соответствующие каждому предикату в этом экземпляре. В экземпляре хранится несколько предикатов, причём каждый хранится полностью.Это позволило выполнять запросы с произвольной глубиной объединений, устранив проблему веерного развёртывания при броадкасте. Например, запрос [people in SF who eat sushi] сгенерирует максимум два сетевых вызова в БД независимо от размера кластера. Первый вызов найдёт всех людей, которые живут в Сан-Франциско. Второй запрос отправит этот список на пересечение (intersect) со всеми людьми, кто ест суши. Затем можно добавить дополнительные ограничения или расширения, каждый шаг по-прежнему предусматривает не более одного сетевого вызова.

Это создаёт проблему очень больших предикатов на одном сервере, но её можно решить дальнейшим разделением предикатов между двумя или более инстансами по мере увеличения размера. В худшем случае один предикат разделится по всему кластеру. Но такое произойдёт только в фантастической ситуации, когда все данные соответствуют только одному предикату. В остальных случаях такой подход позволяет гораздо уменьшить задержку запросов в реальных системах.
Шардинг стал не единственным нововведением в Dgraph. Всем объектам были присвоены целочисленные идентификаторы, их отсортировали и сохранили в виде списка (posting list) для быстрого пересечения таких списков впоследствии. Это позволяет быстро фильтровать во время объединения, находить общие ссылки и т. д. Тут также пригодились идеи из поисковых подсистем Google.
Объединяем все блоки OneBox через Plasma
Dgraph в Google не был базой данных. Это была одна из подсистем, к тому же реагирующая на обновления. Таким образом, она нуждалось в индексации. У меня был большой опыт работы с системами инкрементальной индексации в реальном времени, работающих под Caffeine.
Я начал проект по объединению всех OneBox в рамках этой системы индексирования графов, включая погоду, расписание авиарейсов, события и так далее. Может вы не знаете термин OneBox, но вы определённо его видели — это отдельное окно, которое отображается при выполнении определённых типов запросов, где Google возвращаtn более богатую информацию. Чтобы увидеть OneBox в действии, попробуйте [weather in sf].
Ранее каждый OneBox работал на автономном бэкенде и поддерживался разными группами разработчиков. Имелся богатый набор структурированных данных, но блоки OneBox не обменивались данными друг с другом. Во-первых, разные бэкенды многократно увеличивали трудозатраты. Во-вторых, отсутствие обмена информации ограничивало спектр запросов, на которые Google мог реагировать.
Например, [events in SF] могли показать события, а [weather in SF] — погоду. Но если бы [events in SF] понимали, что сейчас дождливая погода, то могли бы отфильтровать или отсортировать события по типу «в закрытом помещении» или «на открытом воздухе» (возможно, в сильный ливень лучше пойти в кино, а не на футбол).
С помощью команды Metaweb мы начали конвертировать все эти данные в формат SPO и индексировать одной системой. Я назвал её Plasma, движок индексирования графов в реальном времени для обслуживания Dgraph.
Чехарда менеджмента
Как и Cerebro, проект Plasma получал мало ресурсов, но продолжал набирать обороты. В конце концов, когда руководство осознало, что блоки OneBox неминуемо входят в наш проект, то сразу решило поставить «правильных людей» для управления системой графов. В разгар политической игры сменилось три руководителя, у каждого из которых был нулевой опыт работы с графами.
Во время этой чехарды Dgraph менеджеры проекта Spanner назвали Dgraph слишком сложной системой. Для справки, Spanner — это распределённая по всему миру SQL-база данных, которой нужны собственные GPS-часы для обеспечения глобальной согласованности. Ирония этого до сих пор сносит мне крышу.
Dgraph отменили, Plasma выжила. И во главе проекта поставили новую команду с новым руководителем, с чёткой иерархией и отчётностью перед CEO. Новая команда — со слабым пониманием графов и соответствующих проблем — решила сделать инфраструктурную подсистему на основе существующего поискового индекса Google (как я сделал для Cerebro). Я предложил использовать систему, которую уже сделал для Cerebro, но её отклонили. Я изменил Plasma для краулинга и расширения каждого узла знаний на несколько уровней, чтобы система могла рассматривать его как веб-документ. Они назвали эту систему TS (аббревиатура).
Это означало, что новая подсистема не сможет выполнять глубоких объединений. Опять это проклятие, которое я вижу во многих компаниях, потому что инженеры начинают с неправильной идеи, что «графы — это простая проблема, которую можно решить, просто построив слой поверх другой системы».
Через несколько месяцев в мае 2013 года я покинул Google, проработав над Dgraph/Plasma около двух лет.
Послесловие
- Несколько лет спустя подразделение «Инфраструктура поиска в интернете» переименовали в «Инфраструктуру поиска в интернете и Граф знаний», а тот руководитель, которому я в своё время показывал Cerebro, возглавил направление «Граф знаний», рассказывая о том, как они намерены заменить простые синие ссылки Знаниями, чтобы как можно чаще напрямую отвечать на вопросы пользователей.
- Когда команда в Шанхае, работающая над Cerebro, была близка к тому, чтобы запустить её в производство, проект у них забрали и отдали в нью-йоркское подразделение. В конце концов, его запустили как Knowledge Strip. Если вы ищете [tom hanks movies], то увидите его наверху. Он немного улучшился с момента первого запуска, но всё ещё не поддерживает уровень фильтрации и сортировки, который закладывался в Cerebro.
- Все три технических руководителя, кто работал над Dgraph (в том числе я), в итоге покинули Google. Насколько мне известно, остальные сейчас работают в Microsoft и LinkedIn.
- Мне удалось получить два повышения в Google и я должен был получить третье, когда оставил компанию в должности ведущего инженера-программиста (Senior Software Engineer).
- Судя по некоторым обрывочным слухам, текущая версия TS на самом деле очень близка к дизайну графовой системы Cerebro, причём у каждого субъекта, предиката и объекта есть индекс. Поэтому она по-прежнему страдает от проблемы глубины объединения.
- С тех пор Plasma переписали и переименовали, но она продолжает работать как система индексирования графов в реальном времени для TS. Вместе они продолжают размещать и обрабатывать все структурированные данные в Google, включая Knowledge Graph.
- Неспособность Google делать глубокие объединения видна во многих местах. Например, мы до сих пор не видим обмена данными между блоками OneBox: [cities by most rain in asia] не выдаёт список городов, хотя все данные есть в графе знаний (вместо этого в поисковой выдаче цитируется веб-страница); [events in SF] нельзя фильтровать по погоде; результаты выдачи [US presidents] не сортируются, не фильтруются и не расширяются по другим фактам: их детям или школам, где они учились. Полагаю, это стало одной из причин прекращения поддержки Freebase.
Dgraph: птица Феникс
Через два года после ухода из Google я решил разработать Dgraph. В других компаниях я вижу ту же нерешительность в отношении графов, что и в Google. В графовом пространстве было много недоработанных решений, в частности, много пользовательских решений, поспешно собранных поверх реляционных или NoSQL баз данных, или как одна из многих особенностей многомодельных баз данных. Если существовало нативное решение, то оно страдало от проблем масштабируемости.
Ничто из того, что я видел, не имело связной истории с производительным, масштабируемым дизайном. Построение горизонтально масштабируемой графовой БД с низкой задержкой и объединениями произвольной глубины является чрезвычайно сложной задачей, и я хотел убедиться, что мы построили Dgraph правильно.
Команда Dgraph провела последние три года не только изучая мой собственный опыт, но и вкладывая много собственных усилий в проектирование — создание базы данных графов, не имеющей аналогов на рынке. Таким образом, у компаний есть возможность использования надёжного, масштабируемого и производительного решения вместо ещё одного наполовину готового.







