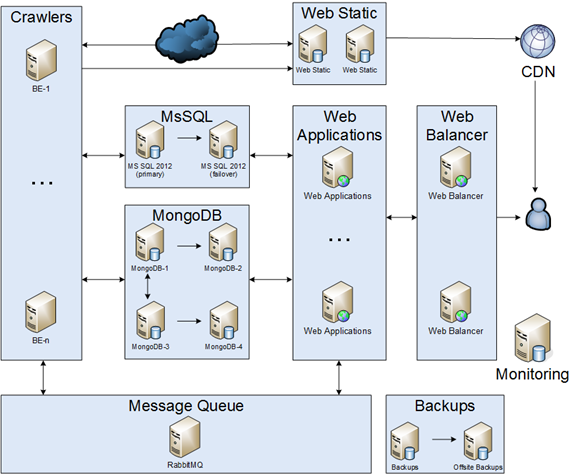
I'd like to share my story about migration monolith application into microservices. Please, keep in mind that it was during 2012 — 2014. It is transcription of my presentation at dotnetconf(RU). I'm going to share a story about changing every part of the infrastructure.
Project description

The main project idea was to crawl articles from the internet, analyze it, save & create user feed. On one hand, our infrastructure had to be reliable, but on the other hand, we were on a budget. As a result, we agreed that:
- System performance degradation is allowed.
- Some parts of our infrastructure might be down for 30 min.
- In case of disaster, downtime might be some days.
Crawlers
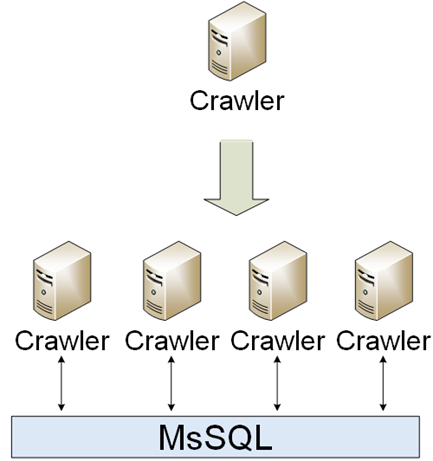
It was a simple part of the infrastructure. Crawlers should download, analyze & save. The first one implementation was a single crawler, however, the world was changing & a lot of different crawlers appeared. Crawlers were communicating with each other by MsSQL.
Downtime wasn't a problem for crawlers, so it was really easy to scale them:
- Automate provision.
- Add business metrics.
- Collect errors.
MsSQL
Our database was about 1TB.
MsSQL cluster
There were different ways how to create a cluster:
- SQL mirroring.
- Windows failover cluster — it wasn't a case because there was no san/Nas.
- AlwaysOn — it was completely new for us and there was no expertise in it, so, it wasn't a case for us.
As a result, we decided to use the 1st. I'd like to notice that we didn't use witness because of async mode, so we created scripts for auto switch master -> slave & manual slave -> master.
MsSQL perfomance

The clock was ticking, a performance was degrading, we were searching bottlenecks. Sometimes, it wasn't easy, i.e. were optimizing SQL queries by disk io, when, we found that the performance was low because of lack of RAM. However it was not enough, as a temporary solution, we migrated from HDD to SSD. On one hand, it increased the performance dramatically, but on the other hand, it wasn't a long-term solution.
Message Queue
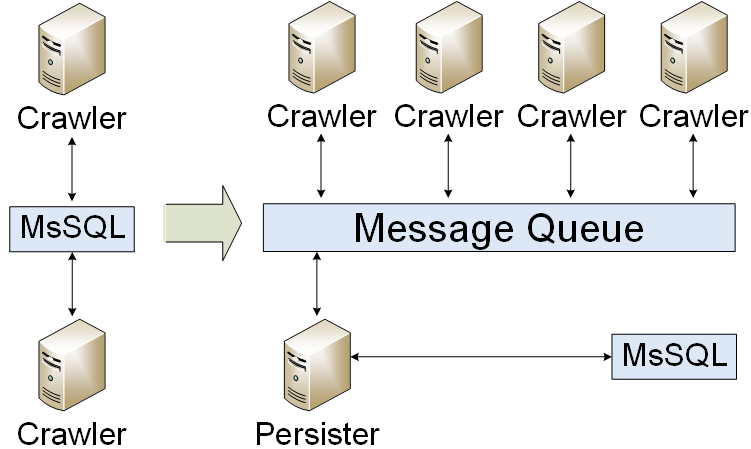
Our application had been migrated to a message queue. We were writing only results in the database. As a result, we reduced database load. But we faced a problem: how to organize a message queue cluster? At the first, we created a cold standby.
WEB

A web part consisted of two parts: static content & user dynamic content.
WEB static

WEB static part of the infrastructure was about 2TB, it had to:
- Store images.
- Convert images.
- Crawl origin image & crop if needed.

There were 2 major issues: how to sync files & how to create a web cluster. There were some ways how to sync files: buy a storage, use DFS & save files at each server. It was tough decision, however, we decided to choose the 3rd way. For the web cluster, we decided to use NLB & CDN.
WEB Balancer

It's not a really good idea to use a single server for a high-load project, you have to balance traffic somehow. There were 4 ways in our case:
- Hardware balancer — it was too expensive for us.
- IIS & ARR — it was too complicated to support.
- Nginx — it was good enough, however, we faced some issues with health checks.
- Haproxy — it was a solution with one the smallest overhead.
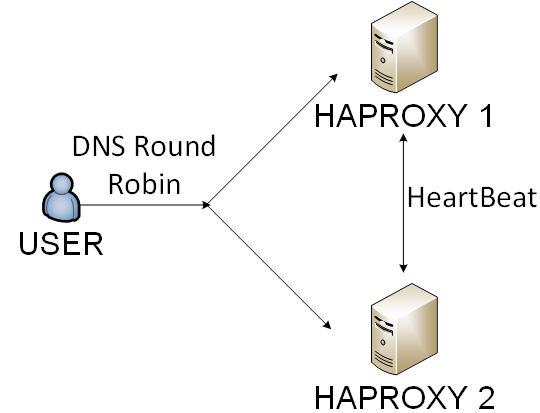
We chose the 4th way. We were balancing haproxy by DNS round robin & users by cookie.
MongoDB

A few months later, we faced that SQL performance was not good enough again. It was a sophisticated issue, however, after long conversations we decided to choose Availability & Partition tolerance from CAP theorem. As a result, we implemented a MongoDB cluster(sharding & replica). There was an interesting experience: how to create MongoDB backup, how to upgrade & a lot of MongoDB bugs.
Backups & monitoring
We implemented the 3-2-1 rule:
- At least 3 copy.
- At least 2 different storage types.
- At least 1 copy must be stored somewhere outside.
Also, we created & tested disaster recovery plan. You can read about monitoring here.
Applications updates
As you can see, the infrastructure wasn't as easy as pie. We had to update it somehow. Casual update looked like:
- Do some preparation.
- Ran migration.
- Update web applications.
- Update backend applications.
All logical steps were identical for staging/preprod/productions environments, however, it was slightly different at details. So, we created PowerShell scripts with OOP magic. It was a continuous process of improving our CI/CD infrastructure.
Conclusion
| 2012 | 2014 | |
|---|---|---|
| Servers | 3 | 60 |
| RAM GB | 72 | 800 |
| SSD GB | 200 | 10000 |
| MsSQL GB | 150 | 700 |
| MongoDB GB | 0 | 700 |
| Articles per day | 10000 | 150000 |
It was an amazing story about moving 3 desktop PC into reliable infrastructure. Be patient & do plans.








