Комментарии 384
Я ежедневно пользуюсь rebase/marge, show/log/diff, stash, reset/checkout, cherry-pick и мне этого хватает. Но признаюсь честно, я очень часто иду спрашивать в гугла или у своих коллег по цеху.
Git имеет больше десятка полезных утилит, с своими параметрами и опциями. Я бы очень сильно хотел знать их все, а еще лучше правильно это все применять.
А программист который пришел в команду без базовых знаний, получить их в первую неделю работы. И такого человека нужно брать. Ибо если не вы то другие
Я ежедневно пользуюсь rebase/marge, show/log/diff, stash, reset/checkout, cherry-pick и мне этого хватает.
Этого более чем достаточно, Git вы наверняка знаете. Не обязательно на 100% знать возможности инструмента чтобы эффективно его использовать.
Я как-то привык к тому, что мёрдж допустим только тогда, когда конфликтов нет…
git merge X
# there are conflicts
git mergetool
# N часов разрешения конфликтов спустя
git commit# оно посыпалось в проде (так как конфликты как-то разрешили, но тестировать не тестировали)
# научились пользоваться rebase
А что, ребейз автоматически исправляет ошибки?
После мержа мастера в фичу, разрешения конфликтов, фича пушится, CI прогоняет тесты, и мержится мерж реквест.
После мержа мастера в фичу, разрешения конфликтов, фича пушится, CI прогоняет тесты, и мержится мерж реквест.Однако при этом разработчик, почти никогда, не смотрит на то, что там произошло и почему возник конфликт. Потому что у вас на всё стадию разрешения конфликтов — один шаг:
# N часов разрешения конфликтов спустя
git commit
В случае же с rebase вы вполне можете решить сделать его в несколько шагов. Или вообще интерактивно — с проверкой после каждой стдии. Контроля над процессом — на два порядка больше.
а если в вашей feature бранче из множества коммитов нужно поправить 3-й с конца — как вы делаете?
Правишь и коммитишь. Править коммит в глубине истории — очень странное использование гита.
Отличный пример — git revert: создает новый коммит, откатывающий более ранний, вместо внесения изменений в историю.
А вот для изменения истории, которая ещё не опубликована — как раз rebase и предназначен. А до него пользовали Quilt, да.
При чём тут revert? svn revert тоже как бы создает новую ревизию. Revert никогда не предназначался для исправления истории.
А для исправления коммитов в прошлом есть довольно удобный инструмент: комбинация git commit --fixup и git rebase --interactive --autosquash
почему вспомнил — ну, так кейс такой. вот сделали вы локальную feature бранчу. в ней куча атомарных коммитов. и нужно поправить третий коммит с конца.
вопрос — как это сделать без rebase?
основная идея в том, что rebase очень полезная команда =)
сильно сомнительное флоу? =) ок, а какое флоу вы считаете не сомнительным?Такое, которое позволяет эффективно делать git bisect.
А для этого требуется следующее:
1. Все коммиты обозримы и, как правило, имеют небольшие размеры (иначе смысл делать git bisect: найдёте вы коммит размером в миллион строк, меняющий несколько тысяч файлов… что дальше?).
2. Каждый коммит имеет смысл в отдельности, сам по себе (иначе, найдя него, нельзя понять что в нём пыталось сделать и зачем).
3. Каждый коммит содержит в себе образ, который можно собрать и не содержит ошибок (тут стоит, конечно, уточнить: «насколько нам известно можно собрать» и «известных ошибок, которые мы не решили сознательно не править „здесь и сейчас“»). Самое важное и, вместе с тем, самое спорное свойство — но если оно не соблюдается, то всё время будете через git bisect находить не что-то полезное, а тот мусор, который вы оставили во время разработки.
Ключевая фича Git'а — это git bisect. Он позволяет искать ошибки в крупных проектах, над которыми работают тысячи разработчиков. Однако накладывает ограничение на то, что вы кладёте в ваш репозиторий.
Но, разумеется, если ваш проект невелик, то это не особо нужно. А если вы один работаете — то и папочек с датами может быть достаточно.
Такое, которое позволяет эффективно делать git bisect.
rebase многократно увеличивает трудозатраты, которые нужно сделать для git bisect.
Каким образом [rebase многократно увеличивает трудозатраты, которые нужно сделать для git bisect]?
После того, как сделан rebase каждый коммит потенциально может быть сломан из-за того, что изменения в мастере оказались несовместимы с тем, что осталось в ветке. Например, в мастере был переименован какой-то метод. Конфликтов не возникнет, но код перестанет собираться.
Автоматический bisect в таком случае естественно скажет, что коммит сломан. Чтобы такого не было, после rebase нужно прогнать тесты на каждом коммите и потенциально поправить код в каждом коммите.
Если вы делаете rebase — то вы делаете его для того, чтобы облегчить себе задачу в будущем, а не наоборот.
Ну вот если хочется использовать bisect, то rebase очень осложняет задачу.
Если у вас нет времени на то, чтобы прогнать тесты, то rebase делать не стоит, вот и всё
Ну в общем да. Допустим в ветке работали около недели, там 100 коммитов. Тесты прогоняются, допустим, около двух минут. Для каждого коммита нужно прогнать эти тесты. Итого, примерно три с половиной часа нужно потратить на просто прогон тестов, плюс, думаю, не менее минуты на коммит для сопуствующих действий. Так что да, если жалко четырёх с половиной часов — не стоит делать rebase.
Допустим в ветке работали около недели, там 100 коммитов.
В таком случае я бы вообще не стал делать rebase уже не задумываясь ни о чём другом.
Ну да, а ветки в с какой-нибудь фичей, они в основном такие и есть.
У нас это уровень функционала на несколько месяцев работы — такое часто лучше делать частями на мастереЧасто фичу нельзя выкатывать пока она окончательно не готова. Ну, к примеру, какой-то новый режим в онлайн-игре. Скажем, турниры. Они довольно довольно крупные (Epic Story) и пока не закончены — могут не выливаться на продакшн, получая несколько пул-реквестов в отдельную ветку для эпика.
Это если сомнений в том, что фича нужна нет.
Если есть. То всё равно: если уж так приспичило их тоже нужно переносить если не на самую голову, то хотя бы близко к ней. Да, это время и силы, но если вы уже вложили в фичу месяц работы, то потратить ещё день, чтобы причесать её перед заливкой — не слишком долго.
Хотя, конечно, тут приходится мириться с тем, что фича будет не поверх прямо последней версии, а поверх версии трёхдневный давности… что всё равно лучше, чем если она поверх версии годичной давности и «merge commit» переписывает половину кода…
А почему неуозможны-то? Что может мешать?
Иногда в коде не может быть следов новой фичи до окончательного релиза, чтобы игроки не получили спойлер до того, как отдел маркетинга начнет свою работу.
А почему неуозможны-то?
Как ниже написали, а ещё в реальном мире живем — если не всё покрыто тестами, то feature toggle рискованнее ветки.
всё равно лучше, чем если она поверх версии годичной давности и «merge commit» переписывает половину кода
Для кого лучше? Мы вот в команде решили, что не лучше. Во-первых нет смысла тратить время на rebase если он никому не нужен. Во-вторых иногда куда полезнее видеть реальную историю, чем гадать, откуда что-то взялось и зачем.
А что вы используете если вашу фичу месяц не хотят принимать, если не rebase???Как-то долго, вам не кажется?
А какие проблемы с мерджем, если месяц не мерджить и если были конфликты? На Гитхабе в Пул Реквестах все норм.
Зависит от проекта. У разработчиков ядра — это суперскорость-когда-фича-позарез-нужна-очень-срочно.А что вы используете если вашу фичу месяц не хотят принимать, если не rebase???Как-то долго, вам не кажется?
А какие проблемы с мерджем, если месяц не мерджить и если были конфликты?Так за этот месяц туда будут влиты несколько тысяч коммитов и половина интерфейсов, которые вы используете, поменяется.
То есть по объёму ваш «финальный» мёрдж будет как половина от 10-20-50 компотов, вашу фичу реализующих. Ну и как это ревьюить, извините?
Ну и как это ревьюить, извините?Так же, как и ребейз.
Ваши дальнейшие действия?
На гитхабе автоматически обновился пул-реквест.
В конце-концов вы же попросили, чтобы я включил вашу фичу в новую версию — так нафига мне знать что и как вы делали у себя дома, когда эту фичу разрабатывали?
Мне интересно знать как она будет работать в моей подсистеме сегодня. Ревьюер в ядре — как правило майнтейнер соответствующей подсистемы и это ему (или ей) этот под поддерживать если вы вдруг исчезните (да даже если и нет).
А вы пользовались? Если пользовались, то должны знать, что там именно что отдельные коммиты на ревью попадают. Поэтому перед тем как делать PR очень желательно сделать rebase.
А как ему этот самый контекст получить, когда в последнем коммите — краткая подборка всех изменений из основной ветки проекта за последний месяц?
Почему вы не желаете немного помочь ему и убрать из своего PR мусорную информацию?
А как ему этот самый контекст получить, когда в последнем коммите — краткая подборка всех изменений из основной ветки проекта за последний месяц?Таки не пользовались? Чего вы привязались вообще к коммитам?
Чего вы привязались вообще к коммитам?Потому что именно на них я смотрю?
И да, каждый из них должен иметь смысл, не должен быть слишком большим (если он больше 100 строк, то его могут попросить разбить) и так далее.
В ядре есть ещё сложность что разные люди пользуются разными инструментами, так что можете посмотреть примерно как это Chromium делает. Там инструмент у всех один…
Инструменты у разработчиков ядра, Chrimium, Android, LLVM — всё разные. Но принцип один: каждый коммит ревьюится отдельно. И должен иметь смысл — отдельно.
А иначе что делать после Git Bisect.
И да, каждый из них должен иметь смысл, не должен быть слишком большимИ как по такой логике влазит месячная фича, слепленная в один коммит ребейзом?
И она-то и мешает ревью.
Ведь, собственно, почему все эти замены Foo на Bar появляются? Чтобы помочь вам вашу фичу реализовать.
То есть, к примеру: если вы хотите сериализовать какой-то объект, но есть шанс, что этот объект «под вами» менять будут — его можно попробовать изменить так, чтобы он был immutable. И проблемы синхронизации исчезнут. Но для этого — его нужно будет создавать по-другому.
А когда вы, после всего этого выкатываете на ревью версию «с костылями»… Ну это просто неуважение к ревьюерам, которые для вас, собственно, всю эту работу и проделали.
Рассказывать после такого «плевка в лицо» о «работе в команде»… Ну как-то глупо это…
И если меня коммит не устраивает — я signoff не поставлю. Вот так вот просто.
Github вообще энфорсит совсем другую модель. Leftpad-стайл, условно говоря: я беру у вас фичу и не глядя забираю себе. Кто и как при этом будет чинить отвалившуюся другую фичу — науке неведомо.
Такое в массе крупных проектов просто «не прокатывает»: если я даю «добро» на включение чего-то в проект — то это я должен быть готов править ошибку, совершённых в любом из показанных мне коммитов, если git bisect на этот коммит укажет.
Как GitHub pull-реквесты помогут мне в этом — я не понимаю.
Github вообще энфорсит совсем другую модель. Leftpad-стайл, условно говоря: я беру у вас фичу и не глядя забираю себе. Кто и как при этом будет чинить отвалившуюся другую фичу — науке неведомо.Что? Я вас не понимаю, простите.
И если меня коммит не устраивает — я signoff не поставлю. Вот так вот просто.Ну я понял. «будет или по моему или никак». Удачи в работе в команде.
Ну я понял. «будет или по моему или никак». Удачи в работе в команде.Мне-то она зачем? Я вполне нормально работаю.
Это вам удача понадобится, если вы вдруг в большой проект (ну, скажем, от 10 миллионов строк и больше) что-то закоммитить решите. Я вот не знаю ни одного, где бы играли по вашим правилам.
Вот не надо про "не глядя". Там есть все средства для проведения ревью, а дальше уже дело за мейнтейнерами проектов будут ли они эти средства использовать.
Между прочим, github автоматически подписывает все сделанные через веб-интерфейс коммиты.
Так-то можно и самостоятельно коммит слияния подготовить и запушить, если вам так важно чтобы подпись была именно ваша.
Мердж вы уже сделали, но ревьювер смотрит старый коммит…Какой дали — такой и смотрю, другого-то нет. Вы же сказали: ревью делать — как при rebase.
В целом, это показатель неоптимального рабочего процесса, кмк.
Извините, но плюсы меня не интересуют. Даже если бы заминусовали, я бы не отказался от своих слов.
Это не делает их плохими разработчиками.
Это делает их неопытными разработчиками. Что совершенно нормально для человека, который только написал диплом. Другое дело, если культура предприятия это поддерживает, тогда развитие у ваших сотрудников будет идти не так хорошо, как могло бы.
В принципе, никакой ракетной техники в git нет — я сам работал на предприятии, где использовался (и, наверное, до сих пор используется) SVN, и переучиться на git стоило, конечно, некоторых усилий, но не то, чтобы запредельных. Но такие мелочи могут накапливаться, и делать предприятие (и, соответственно, строчку в резюме ваших сотрудников) «uncool».
У меня тут на новой работе дали проект из загадчика, парни, он в source safe ещё локальном хранится, вот где Содом.
Я его через vss2git сконвертировал в git, чтобы историю хотя бы в нормальном виде смотреть...
Сказал как есть и поэтому к приёму очереди из тухлых яиц готов.
Я правильно понимаю, что вы работаете над проектами один?
Оттого ваш стиль с версионированием директории ProjectName.dd-mm-yyyy вам подходит. Если бы в команде был хотя бы +1, то вы бы уже давно сознательно переползли на систему контроля версий.
Git (либо другую систему контроля версий) можно и удобно использовать даже если разработчик один.
И вот в один прекрасный день, админ решил обновить на этом компе драйверы для видеокарты nvidia, забыв создать точку восстановления перед установкой…
Но что-то пошло не так, решил откатится — и откатился на точку восстановления, сделанную 2 недели назад…
Уже на следующий день у нас был отдельный сервер с svn.
Вот так незатейливо и началось знакомство нашей компании с системами управления версиями!
По моему, это где-то возле частого форматирования дисков вместе с критически важными дисками каждый день без бэкапов с вероятностью 1% форматнуть не тот диск.
Кто ж спорит?)
А ни до этого, ни после этого никакими системами контроля версий я никогда не пользовался, непонятны они мне, а посему неудобны.
Непонятны и неудобны потому что видимо не пользовались нормально.
Сейчас меня закидают тухлыми яйцами, но мне удобно по-старинке: добился работоспособности — «закоммитил» директорию с проектом у себя в ProjectName.dd-mm-yyyy и продолжил делать в ProjectName. Не получается — сделал «checkout» путём переноса из ProjectName.dd-mm-yyyy обратно в ProjectName.
Какой кошмар! Действительно закидают.
И нет никакой головной боли что там лучше делать merge или rebase, и не надо придумывать никакие commit messages, и не надо синхронизировать никакие ветки.
Использую Git, голова давно не болит. Все эти вещи только лучше все организуют и систематизируют.
Если моё версионирование через директории ProjectName.dd-mm-yyyy делает в принципе то же самое, только [для меня] гораздо более прозрачно и устраивает меня на 100%.
Прозрачности тут гораздо меньше — куча лишнего и дублирующегося, отсутствие истории, дифа файлов.
А вот про всякие cherry-pick, revert, tag, submodule и прочие, а ещё какие-то жуткие, нечеловеческие, сделанные явно для того чтобы в конец запутать способы указания номера коммита.
Использовать эти команды вовсе не обязательно, разбирающимся они только помогают. Что нечеловечного в хеше коммита, тэгах, дате?
Для pfemidi предложение у меня такое:
начать использовать Git, создать в директории с вашим проектом рабочую копию через git init, закоммитить все текущие файлы с коммитом «initial»
Затем при внесении изменений, вместо создания копии папочки с
ProjectName.dd-mm-yyyy
вы просто делаете git commit с текстом «ProjectName.dd-mm-yyyy».
(меня сейчас закидают тухлыми яйцами уже поклонники Git)
т.е. в вашем привычном способе разработки не изменится, но вы сможете использовать некоторые плюшки, как только захотите.
Например, посмотреть diff между версиями ;)
ну а потом уже и нормальные имена коммитов, и ветки, и все остальное само подтянется. Сабмодули, cherry-pick, для индивидуальной разработки вам вряд ли понадобятся, tag — ну многие проекты их не используют, кстати говоря, revert — если не косячить с коммитами, то и откатывать не надо.
В общем я считаю, начинать осваивать гит с одной единственной команды -реально ;)
Приучило не писать монолиты… минимальная связанность — благо «при сборке из кубиков» есть всегда @Override-аннотация и в модулях дает писать «заглушки».
Уверяю, все эти
«закоммитил» директорию с проектом у себя в ProjectName.dd-mm-yyyy и продолжил делать в ProjectName. Не получается — сделал «checkout» путём переноса из ProjectName.dd-mm-yyyy обратно в ProjectName. Получилось — «закоммитил» директорию с проектом в следующую директорию опять с указанием даты ProjectName.dd-mm-yyyy.станут выглядеть для Вас, как ССЗБ.
Попробуйте Git Extensions (Win).
Ваш стиль работы можно очень легко перенести на git или hg, и вы это, похоже, прекрасно понимаете, но не видите преимуществ. В чем профит? В том, что система контроля версий возьмет на себя прорву чисто механической работы. Например, сейчас вы делаете изменения в проекте, потом пишете в changelog «22.01.19 Реализовал фичу XYZ. Изменил aaa.cpp, bbb.cpp, ccc.cpp». А с любой СКВ и GUI-клиентом к ней вы просто набираете в окне сообщение «Реализовал фичу XYZ» и жмете Commit. Все. GUI-клиент типа TortoiseHG или Sourcetree четко показывает вам, что изменилось. Выделили коммит в списке — видите, что этот коммит изменил файлы aaa.cpp, bbb.cpp, ccc.cpp. Выделили файл aaa.cpp — сразу видите, что конкретно поменяли. То есть система ведет максимально подробный «changelog» за вас. Ориентироваться во всем этом вы сможете очень просто, причем безо всяких хитрых команд. Вам не нужен bisect, чтобы читать список изменений.
Хотите вернуться к предыдущему состоянию? Выделили коммит и сделали на нем «Update». Нужен бэкап на внешнем винте? Один раз сделали на этом винте клон вашего репозитория а потом периодически делайте туда push. Более того, с git и mercurial вы сможете завести бесплатные аккаунты на сервисах типа github, gitlab, bitbucket и бэкапить туда.
Какие еще преимущества? Навскидку, для любого файла в проекте можно посмотреть историю изменений. В большом проекте иногда натыкаешься на какой-то хитрый участок кода и начинаешь вспоминать: когда это делали и зачем. В GUI-клиенте можно парой кликов мыши вывести историю файла, вплоть до текста файла с построчной аннотацией — когда (и кем) менялась каждая строка.
Размеры репа, если не коммитить туда бинарники, очень скромные, по сравнению с сохранением полного архива ProjectName.dd-mm-yyyy на каждый коммит. Всегда можно держать полную копию истории под рукой, а не на внешнем винте.
Если вы работаете в одиночку, то, скорее всего, вы сможете обойтись без веток, и у вас не будет «головной боли что там лучше делать merge или rebase». Жуткие номера коммитов (хэши)? В mercurial можно пользоваться последовательно возрастающим порядковым номером коммита, особенно если вы работаете один. Да и при использовании GUI, в принципе, можно и не заморачиваться этими обозначениями.
Некогда все это изучать? В mercurial описанный выше функционал под GUI клиентом можно освоить за день-два. Если не любите GUI и хочется консольного кунг-фу, вероятно, понадобится чуть побольше времени, но не намного. git в целом сложнее, чем mercurial, но на таком уровне особой разницы тоже не будет.
Было время я пользовался Microsoft Visual SourceSafe, год, с 2000-го по 2001-й год когда работал в команде, там это был корпоративный стандарт. Но там было просто, мне показали что надо нажимать в начале рабочего дня чтобы скачалась последняя версия проекта и что нажимать в конце рабочего дня чтобы другие увидели что я там за день наделал, это я и нажимал.
Мне кажется, что вы упустили существенную часть — наверное, вам также сказали, что перед тем, как сделать Checkout/Checkin, нужно обязательно сделать Show Differences, чтобы вы своими изменениями вы не затерли чужие.
Но может стоит хотя бы сменить формат даты на yyyy-mm-dd? С таким форматом даты сортировка по названию будет осмысленной и он стандартизирован — ISO8601.
Тогда уж и разделителем точку используйте, а не минус.
именах файлов/директорий после точки может быть лишь расширение
Кто вам эту ересь сказал? Расширение файла это лишь абстракция. И ни одна из известных мне современных файловых систем не реализует эту абстракцию. Она уже уровнем выше реализуется, на уровне приложений. Можно дать файлу имя "big.little.boss", никто этого не запрещает.
И ни одна из известных мне современных файловых систем не реализует эту абстракцию.Ну знаете. Это уже перебор. Оригинальный FAT (который в MS-DOS), FDOS, файловые RSX-11 — они это всё очень хорошо реализуют…
Можно дать файлу имя «big.little.boss», никто этого не запрещает.Запрещает. Ещё как запрещает! В той же FDOS под имя файла отведено ровно 11 байт, 8 под имя и 3 под расширение, так ещё и от каждого байта старший бит занят под расширение. Да и даже в старой версии Minix вы такой файл не создатите (не более 14 символов в имени файла, однако).
А это уже привычка, в именах файлов/директорий после точки может быть лишь расширение.
Так что для меня всё что после точки то расширение.
Тогда извиняюсь, недопонимание вышло.
Зачем сортировки по имени в своей же файлопомойке, если есть total commander.
Работал я как-то над "специфичным проектом". На Delphi.
Небольшой модуль для обработки изображений.
Переменные были объявлены с "запасом".
Около 60 переменных объявлено, из которых использовалсь около 20. У и по классике: они назывались x1, x2, x2, ..., a1, a2...
Что бы не иметь проблем с выходом за границу, массивы были объявлены размером в 10 раз больше нужного.
Кусок кода размером более 1000 строк состоял из 3 процедур (не функций). Передача результата через глобальные переменные.
Естественно никакого версионирования, все по папочкам.
Читать изображения разработчик этого модуля не умел, поэтому для него был написан отдельный конвертер, который jpg в текстовом виде представлял.
Я пытался указать на ошибки, однако получит в ответ что-то вроде: "Я 30 лет программирую, у меня 600 патентов, больше 100 реализованных проектов. Я к.ф.-м.н. Да тебе лет меньше, чем я в отрасли". На чем мои попытки благополучно закончились.
по классике: они назывались x1, x2, x2, ..., a1, a2...
Человеческий детёныш, воспитанный диким Fortran-ом ;)
Знакомо.
Таблицы у нас именовались незатейливо: m1,m2,..m199… (сотни их было)
Поля в таблицах — по аналогичной схеме: R01,R02…
3 разработчика, никакого VCS.
Теперь то я понял, что это был своеобразный developer lock.
Сокращенное представление
1. Определенная дата в рассматриваемом столетии
Основной формат
YYMMDD
Расширенный формат
YY-MM-DD
Просто банальные git commit, git diff, git log и отдельно git branch, git merge
Потом внезапно еще освоите git clone/git pull/git push и сможете легко работать с любой машины, а не только с одной.
По этому Changelog.txt в случае чего необходимую директорию ProjectName.dd-mm-yyyy найти не просто, а очень просто и без всяких bisect
Бисект (бинарный поиск по коммитам) нужен, когда вы не знаете, в каком коммите ошибка. Не знаете, в какой день она допущена, и при изменении какого куска кода.
Так-то я никогда не сталкивался с проектами, которые можно годами «пилить» одному. В моей практике как-то так получалось что либо проект «взлетает» и над ним работают 3-5-10-100 человек (в зависимости от того, как хорошо он «взлетел»), либо падает — а тогда там ни одного разработчика не нужно.
Про уникальный проект, где можно годами работать одному можно, видимо поэму написать — это ж редкость невероятная.
Работа над проектом в одиночку уже считается подвигом? Что за проект то хотя бы?
А что за проект — мне тоже интересно узнать…
Java (+ Hibernate, Maven, WebDriver, Jersey, OAuth2)
PHP (+ Smarty, Composer, SafeMySQL)
JS (+ NPM, Webpack, Babel, Vue)
SCSS-препроцессинг (для веб-интерфейса), микросервисы, динамическое распределение нагрузки (самописный балансир).
В марте будет как 6 лет работы «в одного».
А если у вас магазин, то вам нужно либо расширяться, либо, если это не удастся, вас сожрут. Представить себе интернет-магазин, который 10 лет остаётся на том же уровне продаж мне довольно сложно, потому и возникает интерес: что за магазин, зачем ему новые технологии (если он продаёт что-то уникальное на что в природе тысяча покупателей ежемесячно и больше — нет и не будет, то зачем ему редизайн?) и так далее.
Просто уж очень необычный случай, вот и всё.
Вы, как человек, который знает половину дизайнеров и строительных компаний в этой самой Андалусии, без заказов точно не останетесь, а если делаете свою работу хорошо, так и подавно.
Ну а теперь, возвращаясь к вашему вопросу, вы — это тот самый владелец магазина, о котором я писал, а программист одиночка — мой знакомый. Живёт в той самой Андалусии и работает уже больше 10 лет над одним проектом.
Может быть вам стоит посмотреть вот этот интерактивный учебник: https://learngitbranching.js.org/. Поверьте, Git — это мощный и удобный инструмент, который не потребует от вас каких-то специфических знаний. Если вам сложно в консоли с ним работать — есть отличные инструменты встроенные в VisuaStudio, Intelij IDEA и прочие IDE, так же есть GUI инструменты для работы с ветками и коммитами — https://git-scm.com/download/gui/linux, некоторые из них позволяют разрешать конфликты слияний прямо внутри себя.
Так же, могу вам посоветовать Git Flow, когда вы будете готовы к приятному и понятному распараллеливанию процессов изменения вашего кода.
Надеюсь вам станет немного комфортнее в работе, потому что у меня мурашки пробежали по спине от вашего комментария — я когда-то уже терял многие изменения кода и было досадно от того, что приходилось делать двойную работу
2) Я не начал огрызаться, я просто сказал как я делаю, а в последующих комментариях я просто повторил как я делаю специально для тех, кто с первого раза не понял и начал меня учить чтобы я попробовал то, попробовал сё, изменил свой подход и т.д.
Так что для меня всё равно тайна за семью печатями почему исходный комментарий заплюсовали, а последующие, в которых речь шла абсолютно о том же самом что и в исходном, были заминусованы. Но я за эти минусы ни на кого не обижаюсь, каждый волен выбирать то, что ему нравится и высказывать своё мнение пусть не словами, а минусами.
Так что для меня всё равно тайна за семью печатями почему исходный комментарий заплюсовали, а последующие, в которых речь шла абсолютно о том же самом что и в исходном, были заминусованы.
Исходный комментарий заплюсовали (и я в том числе) потому, что он біл ответом на некорректное утверждение что кто не знает гит — не профессионал. Остальные заминусовали потому, что дальнейшие попытки доказать, что гит не нужен вообще, выглядят странно для тех, кто гит знает. Можете пробовать гит, можете не пробовать, дело Ваше.

А вижу я его именно как средство для искусственного усложнения того, чего можно сделать (и я делаю) гораздо проще.
Простите, но как
git commitможет быть сложнее
rar a file_with_new_version_name.rar /myproject/dirТем более, что по времени выполнения и занимаемому месту git будет однозначно быстрее. Вдобавок я просто не представляю сколько времени вы тратите на то, чтобы сделать сравнение версий.
Недавно я столкнулся с проблемой, которую решить пока не сумел. Хороший знакомый, всплывший из длительного необщения, сотворил систему работы с данными, как ему удобнее.
Я, собственно, не столько критиковать, сколько поделиться. Есть чертова уйма офисных файлов и (кажется) ПДФок. С большим количеством значимого текста.
Помимо этого есть куча папок, в которых лежат ярлыки — ссылки на нужные фрагменты нужных файлов. Папки тематические, они тоже связаны уймой перекрестных ссылок, реализованных тоже ярлыками. На каждый файл могут быть сотни таких ярлыков в разных папках, указывающие на разные места файла. Вся организация информации реализована на этих, мать их, ярлыках.
Ему так удобнее. Это цитата, да.
Файлов много, он реально работающий биолог. То есть, тысячи, может быть первые десятки тысяч. Библиотека на жестком диске, плюс его собственные данные. Творил он это все лет десять, и после перехода с XP на семерку вся эта радость работать перестала.
Совсем.
И что с этим адочком делать, я в душе не чаю. Зато ему было удобнее, долго было…
И что с этим адочком делать, я в душе не чаю. Зато ему было удобнее, долго было…
Ставить XP в виртуальной машине, думаю.
Что-то ему не занравилось в возможных способах обмена файлами гостевой и хостовой систем. Пробовали XP Mode, пробовали VmWare: неудобно.
В итоге он все же засел за пересмотр своих воззрений. Жду, к чему пересмотр приведет.
Общий смысл в том, что какой-то привычный для него способ не работал. То ли нельзя было ярлык из гостевой на хост вытащить мышкой, то ли что в этом роде. Человек очень умный, но очень специфический. К сожалению, это довольно часто связанные характеристики.
В Subversion можно любую папку на компьютере превратить в «локальный репозиторий». После этого вы с ним работаете как с обычным репозиторием любым удобным способом и используете все бонусы управления версиями. Саму папку-репозиторий периодически бэкапите привычным вам способом.
Для разработчиков-ретроградов это простейший способ приобщиться к «современной» методологии управления кодом, проектами и ресурсами:
- все ваши цифровые «ценности» концентрируются в одном месте, за которым проще ухаживать
- вы можете работать оффлайн как привыкли и не завязаны на внешние интернет-сервисы
P.S. На самом деле, конечно, это только абстракция. «Большие дяди» хранят часто Git-репозитории не просто как папки в файловой сетеме, а используют специализированную базу данных. Но с точки зрения Git-клиента этого не видно: он по-прежнему считает, что общается с точно таким же клиентом, у которого есть точно такая же папка… только на сервер и побольше…
В Git эта идея доведена до апофигея.
Нет, в гите описанное сделать достаточно сложно. В svn можно выкачать любую директорию из тех, что есть в репозитории и комитить туда, не скачивая ничего другого вообще.
Что-то выкачать из SVN и потом туда коммитить локально, без подключения к серверу, нельзя вообще — никак. Хоть папка, хоть дедка.
Надо только svn сервер себе поставить для этого. Комитьте туда сколько хотите а потом можно смержить результат наверх. Или можно сделать rebase если мержить не всё сразу, а по одному коммиту (хотя из коробки в один клик такого кажется в svn клиентах нету, но это лишь вопрос пользовательского интерфейса).
Не надо это записывать в минусы по сравнению с гитом: просто в гите этот функционал всегда идёт в комплекте, вне зависимости от его реальной надобности.
Можно конечно.
Надо только svn сервер себе поставить для этого. Комитьте туда сколько хотите а потом можно смержить результат наверх.
Поставить svn сервер, сделать локальный репозиторий, потом скопировать туда директорию, выкачанную из удалённого репозитория, закомитить её, потом сделать дополнительные коммиты в локальный репозиторий, потом скопировать содержимое в удалённый репозиторий и закомитить. Работать в общем-то так можно, но вместо локального svn репозитория советую локальный гит репозиторий, проблем гораздо меньше, в git всё это хорошо автоматизировано при работе в связке с svn.
Или можно сделать rebase если мержить не всё сразу, а по одному коммиту
Вот тут точно, если удалённый репозиторий — svn, локально надо ставить git, иначе будет очень тяжело.
хотя из коробки в один клик такого кажется в svn клиентах нету
А в git при работе с удалённым сервером svn такое из коробки есть.
но это лишь вопрос пользовательского интерфейса
Описанный вами воркфлоу легче реализовать отдельной локалькой копией для каждого коммита в связке с утилитой patch, чем с помощью локального svn, это не вопрос интерфейса, это вопрос отсутствующих фич.
Поставить svn сервер, сделать локальный репозиторий, потом скопировать туда директорию, выкачанную из удалённого репозитория, закомитить её, потом сделать дополнительные коммиты в локальный репозиторий, потом скопировать содержимое в удалённый репозиторий и закомитить
Ну, выглядит сложно да, но на деле проще чем кажется. "Поставить svn сервер" и "создать репозиторий" это разовые действия при настройке рабочего компа.
Скачать-скопировать-закоммитить(на самом деле импортировать) это рутина которая легко автоматизируется.
Копировать назад в удалённый вроде не надо — гуи свн клиенты умеют мержить коммиты между репами вроде.
Насчёт того, что с локальным гитом это удобнее — может и так (сам не пробовал это ни с гитом ни с свн).
А вот это
легче реализовать отдельной локалькой копией для каждого коммита в связке с утилитой patch, чем с помощью локального svn, это не вопрос интерфейса, это вопрос отсутствующих фич.
точно нет. Всё же хранить "локальные копии коммитов" в vcs всяко удобнее чем вне её. И функционал "утилиты patch" там тоже есть встроенный.
Насчёт того, что с локальным гитом это удобнее — может и так (сам не пробовал это ни с гитом ни с свн).
Что не пробовали, заметно. Я пробовал, гитом легче.
точно нет [точно не легче реализовать воркфлоу с ребейс отдельной локалькой копией для каждого коммита в связке с утилитой patch, чем с помощью локального svn ] .
А вот тут точно да. Попробуйте накатить свои локальные коммиты на транк, в котором изменение из-за которого нужно поправить все ваши локальные коммиты и вы легко в этом убедитесь.
Всё же хранить "локальные копии коммитов" в vcs всяко удобнее чем вне её.
Хранить да, удобнее. Встраивать их в описанный вами воркфлоу с rebase — вот это ад.
Что-то выкачать из SVN и потом туда коммитить локально, без подключения к серверу, нельзя вообще — никак. Хоть папка, хоть дедка.
Подождите, здесь нужны дополнительные ограничения, иначе рассуждеия идут слишком «в общем».
Выше говорилось о локальных репозиториях — мы же можем выкачать удаленный тем или иным способом, создать копию в локальном и работать с ним без доступа к серверу. Нет?
Что-то выкачать из SVN и потом туда коммитить локально, без подключения к серверу, нельзя вообще — никак. Хоть папка, хоть дедка.
Секундочку, сервер не обязателен.
в SVN также как и в гит поддерживается локальный file протокол.
Я бы сказал что то, что вы описываете есть вещь совершенно не связанная с возможностью превращения любой папки в «локальный репозиторий».
Не связанная. Судя по всему, я не правильно понял о какой фиче говорил metaboloid. Перечитал внимательно его комментарий и полностью поддерживаю комментарий, который вы написали в ответ.
ЧЯДНТ?
Интервью Кузнецова было на opennet(это тот мужик, который написал сетевой стек Linux) — он там про гит и Линуса рассказывал, говорил что при всех недостатках, Торвальдс умеет видеть далеко вперёд, и там где многие разработчики видели навоз (так он называл bitkeeper), Линус смог разглядеть бриллиант и сделать на этих идеях git.
Линус смог разглядеть бриллиант и сделать на этих идеях git.Или сделал замечательный штангенциркуль, который теперь все используют как гаечный ключ.
(Где-то ещё было сравнение git с навороченным гоночным мотоциклом, на котором легко убиться, но можно и безопасно ездить вокруг гаража.)
Вспомните, ведь даже версия под Windows появилась много лет спустя.
Модель работы многим понравилась и её масштабировали на весь мир OpenSource (Mercurial тоже не забываем). А в коммерческую разработку ворваться Git в немалой степени помог Github.
А так, если копнуть глубоко, то вместо архивации всей папки с проектом, вполне можно пользоваться и svn и CVS и более старыми системами, тот же SCCS более продвинутый по возможностям, чем CVS, а появился гораздо раньше.
Как мне организовать работу в git над текстом, если некоторые соавторы не хотят и не будут?
Обычный текст без форматирования или какие-нибудь word-файлы?
P.S. Для совместной работы над текстами лучше подойдёт какая-нибудь wiki.
А что, если вам попробовать GitBook? Там поддерживаются версии, можно разрешать конфликты слияний интерактивно, история изменений и самое главное — можно создавать приватные проекты и работать в них, имеетcя интеграция с Github.
Могу ещё посоветовать Confluence от Atlassian
Текст? Word — рецензирование, объединение версий. Сравнивает не хуже Гита.
Идеология subversion на мой взгляд намного лучше подходит для таких случаев, а git просто модный и распиаренный всякими гитхабами. В сожалению, из-за распиаренности иногда некоторые инструменты ориентируются эксклюзивно на него, что даёт ему дополнительные преимущества, но это не заслуга самого гита а лишь следствие его модности.
поподробнее о том, что умеет svn и не умеет git?
sarcasm mode on
Наверное полностью парализовать работу команды при падении центрального хранилища
sarcasm mode off
Git — децентрализованная система контроля версий, это её главное преимущество
А ещё git позволяет делать промежуточные коммиты для сохранения промежуточного состояния, когда выкладывать свой код я еще не готов, а сохранить куда-нибудь его уже не помешает. Что, в свою очередь, позволяет забыть про проблемы с «дикими» инструментами вроде Telerik Reports Designer, которые «славятся» тем что регулярно необратимо портят редактируемые файлы.
Так что если вам какие-то возможности git показались ненужными — это еще не значит, что эти «замороченности» и правда никому не нужны. Я вот именно из-за них даже с svn-репозиториями через git работаю.
Промежуточные коммиты? Но они же все равно потом пойдут в общий репозиторий, если это коммиты, а не сташи.
Существует же rebase --interactive.
Извините, но у меня представление такое, если не работает сервер, то это в 99% случаях не работает сеть. Никакой нормальной работы сегодня или даже 5 лет назад без сети не представить.
От проекта зависит.
А если рухнет svn-сервер, но упадёт не только командная работа, но и вообще любая работа. В этом и заключается основная разница между git и svn.За почти 20 лет разработки сталкивался с таким пару раз, это всегда было следствием пренебрежения отказоустойчивостью на уровне «совсем», ну т.е. накопитель без raid и нет бэкапов. Работа восстанавливалась быстро, но история терялась, да.
Ни одного преимущества Git так и не прозвучало.
Надеждость централизованной системы давно и легко обеспечивается бэкапами и распределенными с серверами.
Ну так расскажите, как вы будете делать распределенный svn. И как собираетесь бороться бэкапами с сетевыми проблемами…
Perforce используют организации с десятками тысяч пользователей. Неужели вы думаете, что в гугле не сумели организовать надежность централизованного сервера?
Я не помню что бы за годы работы в RIM я хоть раз терял данные в P4.
Этот сказал тут хабрапользователь, который начал эту ветку обсуждения:
Идеология subversion на мой взгляд намного лучше подходит для таких случаев, а git просто модный и распиаренный всякими гитхабами.
Тут сравнивается именно svn и git, а не Perforce и git, и даже не hg и git.
Только на линуксе. Под виндами какая-то непонятная фигня с окончаниями строк получается, каждый раз когда я пытался — коммиты приходили битыми.
Возможно, его и можно как-то правильно настроить для работы по почте — но точно не в ситуации когда центральный сервер внезапно рухнул. Проще новый сервер поднять.
Git — децентрализованная система контроля версий, это её главное преимуществоКогда это полезно, для чего?
Наверное, в случае децентрализованной же разработки, когда человек сидит с ноутом под пальмой без доступа к сети, но имеет доступ к локальному срезу репозитория, может потом в отдельные моменты времени синхронизироваться. Наверное, характерно для open-source разработки, где всё это родилось.
А в контексте организации зачем держать у каждого весь репозиторий? Рухнет сервер? Это вообще не проблема VCS, отказоустойчивость нужно повышать другими методами.
В git действительно нет управления доступом внутри репозитория. Или всё, или ничего.
А вот невозможность «бесплатно» закрыть кому-то доступ обозначает, что такая операция получает вполне себе ненулевую цену, которую можно процитировать менеджерам и, особенно, лигалам когда они порождают очередные безумные идеи в попытке «прикрыть свою задницу».
Это — очень полезно, как показывает практика: если-таки закрыть действительно нужно — то это делается (через submodules, repo и разными другими способами), но вот обоснования «как бы чего не вышло» — уже не прокатывает… нужно реальное обоснование.
С Gerrit у меня как-то не сложилось… В нём можно при git clone получить только разрешённую часть репозитория (и истории соотв.)?
Простите, можно поподробнее о том, что умеет svn и не умеет git?Возможно, вам покажется небезынтересным, почему мы (FreeBSD) таки выбрали Subversion, а не Git.
Простите, можно поподробнее о том, что умеет svn и не умеет git?
Lock же.
Ни одна децентрализованная система его не поддерживает, по крайней мере без костылей. В .Net, допустим, есть Entity Framework 6 и EDMX-модели, которые нереально мержить, это огромный XML с описанием иногда тысяч сущностей в базе данных и их взаимосвязей, он редактируется только с помощью специального визуального редактора. Когда один разработчик вносит изменения в схему БД, в SVN или TFS он делает Lock этого файла и другие разработчики не могут его изменить, а если он использует Git, он делает коммит, попадает на конфликт и идет выяснять в честном поединке, кто будет коммитить первым.
Когда я работал с edmx, я периодически мержил edmx-модели. Ничего сложного, там довольно простой формат.
Самое противное — когда новая версия визуального дизайнера решает упорядочить сущности в новом порядке. Но это решается одинаковой версией студии у всей команды.
Вот что действительно сложно мержить — так это миграции БД. Но там и лок повесить просто не на что...
но при этом не умеющая из коробки такие действительно нужные вещи как нормальное управление доступом и его логирование.Это не баг, а фича. Причём одна из самых полезных.
Я тоже пришёл в git с P4, где есть права доступа и вот это вот всё… и после нескольких лет понял, что при переходе на git одно из самых важных вещей, которые пришлось сделать — это поделить проект на компоненты. При этом можно быть уверенным, что если вы что-то внутри компонента меняете, то вы гарантированно видите все последствия — чего не было с P4.
Ну а между компонентами — да, приходится налаживать взаимодествие. И невозможность быстрого «забивания костыля» с закрытием доступа к файлу config.cpp в котором пароль-к-важной-базе лежит заставляет делать «человеческие» решения.
Так что невозможность ограничить чтение — это, скорее, достоинство.
Ограничения же на то, куда кто может писать… легко делаются через Commit Queue — что, опять-таки, энфорсит правильный подход: CQ-бот не даст вам возможность залить код, который тесты не прошёл (ну или даст, но отправит сразу же репорт «кому надо»), что тоже очень полезно.
Я тоже пришёл в git с P4, где есть права доступа и вот это вот всё…Как вы без time-lapse view живёте? За одну эту фичу перфорсу можно многое простить, кроме цены.
и после нескольких лет понял, что при переходе на git одно из самых важных вещей, которые пришлось сделать — это поделить проект на компоненты.Не понял, какая связь между делением на компоненты и VCS? Что такого позволяет видеть Git, чего не давал P4?
При этом можно быть уверенным, что если вы что-то внутри компонента меняете, то вы гарантированно видите все последствия — чего не было с P4.
Собственно, одна из целей деления на компоненты, это инкапсуляция деталей реализации, как раз сокрытие внутренностей.
То есть, если кто-то вообще смог подключиться к репозиторию (и смог/не смог тут решает не гит), то ему сразу всё доступно. Ограничения могут возникнуть только в случае если нижестоящий слой хранилища (файловая система) тупо не даст модифицировать файлы репозитория с теми правами, с которыми запустился процесс гит-клиента.
При этом сам гит вообще не имеет никакого понятия о том, что к нему подключился кто-то конкретный — для него все юзеры по сути анонимны.
Все способы устранить эту проблему неизбежно приводят к использованию какого-то доп. софта, и я не знаю даже, есть ли способ прикрутить его к гиту не традиционно-костыльным способом и не патча сам гит на сервере.
> одно из самых важных вещей, которые пришлось сделать — это поделить проект на компоненты
Смотрится так, как будто руководитель разработки такой дурак, сам не знает что ему надо, а умный гит его заставил сделать правильно. Решение организационных проблем техническими методами? По-моему инструмент должен реализовывать запросы его использующего, вне зависимости от их разумности, а не вынуждать его менять их.
Тут все почему-то решили что «нормальное управление доступом» это разграничение доступа по файлам внутри репозитория.Разумеется.
То есть, если кто-то вообще смог подключиться к репозиторию (и смог/не смог тут решает не гит), то ему сразу всё доступно.Но что тут нелогичного? Репозиторий — это, я извиняюсь, каталог с определённого вида данными. Если мы не хотим устраивать систему прав «внутри» этих данных, то какие проблемы с тем, чтобы использовать подсистему, которая, собственно, и предназначена для того, чтобы ограничать доступ к файлам и каталогам?
Все способы устранить эту проблему неизбежно приводят к использованию какого-то доп. софта, и я не знаю даже, есть ли способ прикрутить его к гиту не традиционно-костыльным способом и не патча сам гит на сервере.Вы так и не сказали почему это, собственно, проблема.
По-моему инструмент должен реализовывать запросы его использующего, вне зависимости от их разумности, а не вынуждать его менять их.Нет. Оно так не работает. Если есть техническая возможность что-то сделать через… одно место — то этим непременно кто-то воспользуется. Рано или поздно. Если есть техническая возможность запретить что-то делать неправильно — то лучше это сделать на уровне техники.
В конце-концов вы же, почему-то, не считаете проблему прав доступа решаемой с помощью бумажки, вывешенной в коридоре, где написано — куда может писать Петя, а куда Вася… так почему в данном случае вы считаете, что ограничение «руководителя разработки» с помощью «технического средства» — это плохо?
Репозиторий — это, я извиняюсь, каталог с определённого вида данными.
Ну, с таким подходом всё встаёт на свои места. Если преподносить гит как движок базы данных для системы контроля версий — то всё так и есть. Действительно, он знает как проводить нужные операции над данными, а остальное его волновать не должно.
Ну и
Вы так и не сказали почему это, собственно, проблема.
для встраиваемой библиотеки движка базы это и правда не проблема.
Но он почему-то везде преподносится как готовый standalone продукт. (у движка базы в первую очередь должно продвигаться и документироваться низкоуровневое api для обращения к нему из приложений, а вовсе не утилиты для командной строки).
А к готовому продукту требования уже (у меня по крайней мере, но думаю это разумно) совсем другие.
Например, от любой коллективно используемой ИТ-системы (не важно, vcs это или нет) я ожидаю наличие логов важных действий — с указанием, кто (логин, возможно адрес), когда и что (в данном случае список запушенных коммитов) сделал. И не прикрученных какими-то костылями, а реализованных монолитно с остальным исходным кодом приложения.
Если есть техническая возможность запретить что-то делать неправильно — то лучше это сделать на уровне техники.
Да, но издавать запреты это прерогатива начальства того сотрудника, которого эти запреты касаются, а вовсе не авторов инструментов. А если начальства нет и проект свой собственный — то вообще непонятно с чего бы кто-то решил мне запрещать его вести так как мне нравится, пусть даже и по чьему-то мнению я делаю это неправильно.
Собственно, я не против ситуации, в которой начальство, отчаявшись заставить своих сотрудников делить проект на компоненты, заставляет их пользоваться гитом с которым по-другому не получится. (хотя неудача в мирном решении данной проблемы наводит на мысли о некомпетентности этого начальства) А вот ситуация "указа не было, по пришлось из-за особенностей инструмента" уже мне совсем не нравится.
Но он почему-то везде преподносится как готовый standalone продукт.Ну, эта… а к первоисточникам обратиться не пробовали? Вот прям от Линуса: In many ways you can just see git as a filesystem — it's content-addressable, and it has a notion of versioning, but I really really designed it coming at the problem from the viewpoint of a filesystem person (hey, kernels is what I do), and I actually have absolutely zero interest in creating a traditional SCM system.
Git изначально создавался как база для других Scm… но потом выяснилось, что того, что есть — в принципе и так достаточно.
И не прикрученных какими-то костылями, а реализованных монолитно с остальным исходным кодом приложения.Ну это уже вкусовщина. В UNIX ситуация, когда программа общается с другими программами вызывая их и передавая параметры в командной строке не считается чем-то странным и необычным. И Git был под этот сценарий заточен…
А вот ситуация «указа не было, по пришлось из-за особенностей инструмента» уже мне совсем не нравится.Тем не менее эта ситуация гораздо чаще встречается, чем все остальные…
Наша компания переехала с SVN на git (одно время был и git и mercurial). Всё что мы использовали в SVN нашли и в git c обвесом.
Если пилить одному один кусок кода то svn вполне хватает, но как только один файл начинает использовать много народу, так начинаются проблемы.
Хорошая статья и диаграммы наглядные. Кажется я впервые (с 10 примерно по счету прочитанной обзорной статьи) понял, зачем мне мог бы понадобиться гит и как с ним работать. Сейчас команда, с которой работаю, использует TFS и SVN, с ними вообще очевидно всё (то, что ожидаешь от СКВ): правишь у себя; сливаешь с общим репозиторием; видишь всю историю изменений; есть возможность откатиться на любую версию. С глобальным репозиторием видимо удобнее такое вот дополнительное "кеширование", как в гите, хотя я его и так у себя настроил давно с SVN: коммичу в локальный репозиторий на своем ПК каждое изменение; сливаю с общим сетевым по завершению какого-то логического этапа разработки (компилирующийся и протестированный код).
Он в интерактивном режиме спрашивает разработчика, что он хочет получить-изменить и подсказывает необходимые git команды.
— в нашем суперпродукте есть 300 новых перделок и 800 новых свистелок, отсутствующих в продуктах конкурентов
— простите а как мне выполнить последовательность 1-2-3-4?
— выучите все наши сакральные «перделки» и кошерные «свистелки», тогда вы сможите даже 1-2-3-4!
PS: Ни каких намеков… это всего лишь сравнение MS Оffice 97 и 2019.)))
Лично мне учить гит ради гита не интересно, сколько ни пытался – всегда бросал. Тем не менее жизни без гита, а тем более версионирования представить не могу.
Например, вот так: https://pijul.com/
Нет уж, спасибо.
Ребейз оттого и называется ребейзом, что он перемещает «точку прикрепления» ваших локальных изменений к удалённому репозиторию.
Если надо в картинках, гляньте туториалы по гиту у atlassian, у них картинки очень хорошие:
www.atlassian.com/git/tutorials/rewriting-history/git-rebase
www.atlassian.com/git/tutorials/using-branches/git-merge
habr.com/ru/post/437000/#comment_19643372
Он неюзабелен — нельзя достоверно ответить на вопрос "откуда это взялось" без пары часов изучения такого графа.
Вот когда вы смерджите через пару недель самую нижнюю ветку в самую верхнюю, то я хочу посмотреть, как вы будете искать откуда взялся коммит из средней (коричневой) ветки, который заехал и туда и сюда. Плюс к этому коммит, заехавший в обе ветки с вероятностью 100% вызовет позднее конфликт, который вы будете решать на этапе позднего merge. Как показывает мой опыт как раз вот такие хаотические слияния вызывают наростающий ком конфликтов. При каждом merge при примерно полугоде разработки вы начинаете с конфликтов. При этом применяя rebase количество конфликтов сводится к минимуму, потому что сама суть rebase состоит в том, что вы приводите ветку к состоянию fast-forward, то есть ГАРАНТИРОВАННОМУ отсутствию конфликтов.
Если вы работаете в более-менее взрослом проекте, то у вас уже как минимум будет две параллельные ветки: master и develop. А если еще и gitflow применяется, так вообще еще hotfix и release добавляется.
Но даже с маленькими ветками возникает проблема: что делать, если в мастере появился новый коммит? Если вы будете мерджить ветку в мастер с решением конфликтов на месте, то у вас появляется новый неоттестированный коммит и состояние мастера автоматически становится непредсказуемым, даже если на самом деле ничего страшного не произошло.
С мержами иногда визу по 5 мержей на пару реальных коммитов. Rebase позволит не оставлять мусор в истории. Вообще все отличия сводятся к чуть более понятной и читаемой истории, и часто вижу холивар, стоит ли оно того.
Это разные задачи. rebase нужен для приведения дочерней ветки в соответствие с родительской, а merge — для вливания изменений из дочерней ветки в родительскую. Разные отношения между ветками — вот и разные инструменты. Можно применять для всего merge, но тогда рано или поздно в более-менее активном проекте получаем merge hell
Нет, не равны. С родительской веткой работает вся команда, а с фиче-веткой — только ее часть. Потому изменения родительсткой ветки затронут большее кол-во людей и именно поэтому нужно иметь фиче-ветки как можно более готовыми к мерджу.
разве не все конфликты уйдут ровно с тем же уровнем проблем, что и при ребейзе?
Конфликты уйдут, но зато добавится +1 коммит (и он не будет пустым, как при обычном merge --no-fast-forward), а потом еще +1 коммит. Если у вас мастер достаточно часто меняется, то просто за время работы над фичей в пару дней у вас может накопиться солидный ком из таких коммитов, которые по своей сути являются мусором
Разница появляется, если имеются конфликты. Интерактивный ребейз позволяет вам от них избавиться и ревьюерам на них больше не нужно будет смотреть.
Но он меняет историю, потому делать его в уже опубликованной ветке — нельзя.
Реальный пример №2 (самый часто используемый сценарий использования rebase, наверное): вы снова работаете над фичей в своей ветке. Пока вы работаете, другие тоже работают, и master уходит вперед. Работа вам еще предстоит долгая, мерджится в master пока рано, но и сильно рассинхронизироваться вам не хочется. Можно было бы смерджится локально (т.е. влить master в свою ветку), но опять-таки, когда работа над фичей будет закончена, у вас в истории останутся «узелки» на всех тех местах, где вы синхронизировались. Чтобы «узелков» не было, вместо этого вы делаете rebase своей ветки относительно обновившегося master, и для стороннего наблюдателя ваш вклад будет выглядеть как линейная последовательность коммитов.
Вообще если вы считате, что «это ж история — её нужно сохранить», тогда вам лучше на Mercurial переключиться.
Подходы Git и Mecurial — строго противоположны. То есть базовая посылка одна, да, но выводы противоположны:
1. Mercurial: «история — вещь черезвычайно важная, нам нужно её не потерять — и мы сделаем всё, чтобы её сохранить».
2. Git: «история — вещь черезвычайно важная, мы не можем оставить её порождение воле случая… нам важно её грамотно написать — и для этого у нас есть инструменты!».
Так вот rebase — это один из этих инструментов. С помощью которого вы «пишите» красивую историю у вас в репозитории.
Разумеется когда история опубликована и на неё ссылаются — то менять её уже нельзя… тут Git и Mecurial сходятся во мнениях. Но вот отношение к приватной истории — разное до противоположности.
По второй части — выбран git как мейнстрим, hg коллега пробовал, я — нет, сразу с svn на git.
Зачем вливать свои незаконченые и неработающие разработки в мастер?Ээээ
Пулить (фактически мержите) себе из мастера новый интерфейс.Я надеюсь вы понимаете, что с точки зрения Git'а это — та же самая операция?
У Git а ветки — не часть истории. Это временные метки, помогающие вам с историей проекта работать, не более того.
По второй части — выбран git как мейнстрим, hg коллега пробовал, я — нет, сразу с svn на git.Тем не менее говорите вы как пришелец с Hg. Там, действительно, ветки являются частью репозитория и важно откуда куда вы сливаете. В случае же с Git'ом слияние — штука симметричная, а ветки, существующие в вашем локальном репозитории никак не отражаются на глобальном.
Я надеюсь вы понимаете, что с точки зрения Git'а это — та же самая операция?
У Git а ветки — не часть истории. Это временные метки, помогающие вам с историей проекта работать, не более того.
А зачем и почему я должен это понимать? Незнание внутреннего устройства машины не запрещает большинству вполне успешно ездить по дорогам.
Тем не менее говорите вы как пришелец с Hg. Там, действительно, ветки являются частью репозитория и важно откуда куда вы сливаете. В случае же с Git'ом слияние — штука симметричная, а ветки, существующие в вашем локальном репозитории никак не отражаются на глобальном.
Я пришелец не с Hg, а с svn, которым успешно пользовался бы и дальше, если бы не загнулся assembla, точнее резко поднял цены на свой эксклюзив. Насчет веток локальный и глобальных уже догадался =)) методом наступания на грабли… зы и кстати полное копирование репозитария в git редко где описано, в большинстве источников совсем неправильно написано…
ЗЫ Подитожу так, большинство рук-в по гиту написаны явно для гиков… и как бы однобоко…
Незнание внутреннего устройства машины не запрещает большинству вполне успешно ездить по дорогам.Однако мешает её чинить. А VCS (любая) — это не про «езду по дорогам». Это про «починку».
Если вы не пользуетесь своим репозиторием, чтобы исправлять баги — то вам и система контроля версий не нужна. Храните бекапы на случае, если жёсткий диск умрёт — и будет вам щастя.
ЗЫ Подитожу так, большинство рук-в по гиту написаны явно для гиков… и как бы однобоко…Не знаю. У меня есть скорее подохзрение, что они как раз написаны для «нормальных людей, которые не очень хотят знать что там внутри».
Потому что так-то можно уменьшить размер описаний раз в 10 без особой потери качества: просто описать логическую модель — всё остальное из неё автоматом следует.
Но тут вопрос не что «лучше», а что «хуже» — а просто в понимании принципа. Похоже далеко не все пользователи Git'а вообще осознают что такое «ветка» и для чего они нужны.
В смысле что я хочу, чтобы телефон запоминал что я там искал на Google Play, когда настраивал для своей сестры телефон и показывал этот список кому-то ещё. Или сохранял где-нибудь в логах информацию о всех моих входах и выходах из системы. И так далее.я вообще параноик и страдаю, когда от моей работы остаются «следы» в операционке
в смысле?
В современных OS мне неуютно, так как они всегда норовят запомнить обо мне больше, чем я им разрешил и ограничить их — очень тяжело.
Потому мне гораздо больше по душе Git, где я всегда контролирую — что увидят в центральном репозитории и знаю что мои способы именования веток никому не видны.
А в том, что считается, что я, по умолчанию, хочу, чтобы информация о том, что я делаю, была бы сохранена и куда-то там записана.
В Git я сам решаю какой информацией я делюсь с другими и когда. Без моих явных запросов — этого не происходит.
Как я уже сказал: разница в подходе.
P.S. Вообще я понимаю, что я — скорее исключение, чем правило. Иначе ни одна соцальная сеть бы не «взлетела». Но при этом «взлетел» почему-то Git, а не Mercurial… что немного удивляет.
Ещё один пример — вы сделали задачу в своем бранче сделанном не того бранча и надо перенести на другой. Можно без cherry-pick обойтись.
Очень условно:
Мердж берет все изменения с вливаемой ветки или веток, склеивает из в огромный патч и применяет его поверх текущего состояния.
Ребейз берет вашего общего родителями и от него проигрывает патчи из вливаемой ветки по одному, будто ветки не было и вы коммитили сразу туда, на что делаете ребейз.
Нет универсального ответа. Сколько разработчиков, столько и мнений.
Вот мое.
Для синхронизации своей ветки с мастером использую rebase. Это позволяет избавиться от промежуточных мержкоммитов.
При вливании готовой ветки (предварительно заребейзеной) в master использую merge --no-ff. Это позволяет сохранить историю и отношения коммитов.
Если ветка из одного коммита, то лучше влить ее с помощью fast forward merge.
rebase на самом деле инструмент более мощный. О позволяет не только синхронизировать ветки, но и перенести диапазон коммитов из одной ветки в другую (onto rebase), провести редактирование, удаление, переупорядочивание, слияние или разбиение коммитов (interactive rebase).
Это очень удобно, т.к. позволяет вам писать любой говнокод и не думать о коммит-сообщениях какое-то время. А затем уже можно причесать внешний вид ветки, убрать отладочные сообщения, пароли и все прочее из кода, что бы это не попало на сервер.
Раньше предпочитал ребейз, до одного случая...
Разработка объемной задачи была в отдельной ветки(назовем его foo), туда сливались отдельные маленькие таски, при выполнение каждой задачи сделали ребейз с основной веткой, через неделю уже сложно было
это сделать.
Проблема была в том, что в ветки foo несколько раз поменяли одны и те же файлы, а когда из основной ветки прилетал конфликты, то пришлось разрешить конфликты для каждого коммита.
В первых коммитах в ветки foo, как правило немного устаревшие версии файлов, поэтому странно разрешить конфликты с ними, когда можно сделать просто мерж и посмотреть на актуальную версию.
На счет красивой истории, если не ошибаюсь, этого можно добиться используя squash commit при принятии PR.
В общем преимущество ребейс для меня сомнительна, мерж обычно справляется на отлично, мерж коммиты не мешает — их легко фильтровать.
Ребейс можно применить, например в таких случаях:
- По невнимательности коммитили не то, и после этого коммита есть ещё другие коммиты.
- Начали задачу с не той веткой.
- Если по любой другой причины, нужно менять локальную историю.
merge нужен для слияния долгоживущих веток.
rebase нужен для подготовки к слиянию короткоживущей ветки в долгоживущую. Подготовка нужна, чтобы убрать мусорные изменения, упростить чтение истории — ну и для разрешения конфликтов тоже.
Ещё rebase в интерактивном режиме может использоваться как инструмент для редактирования истории.
{kind=link}
Я отвечал на вопрос, в чем проблема мержей без рибейзов. И это — нечитаемая история.
А рибейз — единственный способ решения данной проблемы.
Git-flow, к сожалению, ее не решает, а только усугубляет:
www.endoflineblog.com/gitflow-considered-harmful
Каждый сам выбирает, что для него важней. Плюс git-а в том, что он дает возможность выбора.
Кстати, у нас в одном проекте использовался git flow (не утилита, а концепция), но при этом никто не мешал нам делать рибейзы перед мержем.
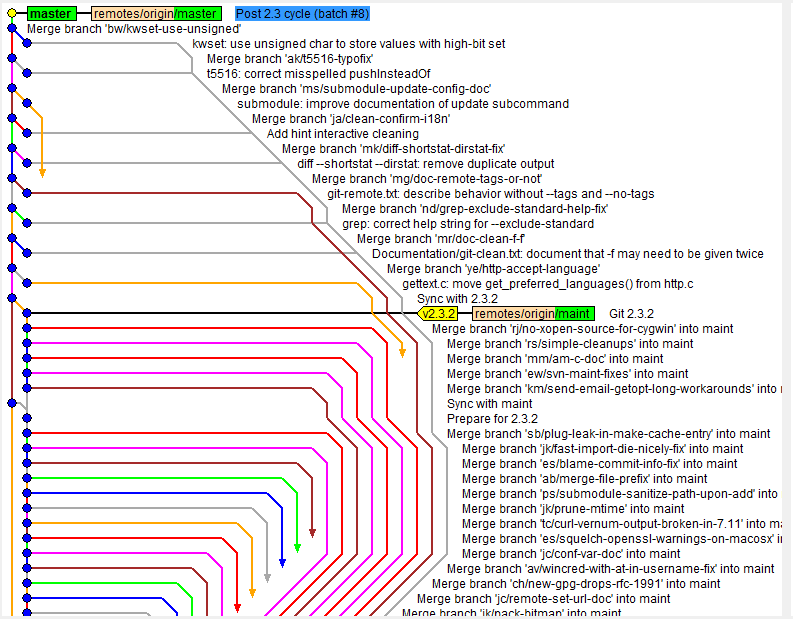
Кстати говоря, это скриншот истории разработки самого git. Джунио вполне норм такая история, как видим.
Ну и ещё то, что частично checkout репозитория не сделать, только целиком.
Неправильная позиция. merge нужен для вливания дочерней ветки в родительскую. Иначе получаем такой же бардак, только с другой стороны, потому что родительская ветка будет постоянно в состоянии diverged
Rebase — инструмент для переписывания истории коммитов, после него получается красивая линейная история изменений. Merge сливает две ветки в одну, притом обе остаются в истории. Рабочая директория в обоих случаях получается одинаковая, а лог — разный.
В котором описать необходимые команды, их результат и основные сценарии ошибок. Отдельно описать best practice для вашего проекта, например почему hard reset на мастер делать не нужно, или нужно ли делать рибейз перед мержем в общую ветку.
Без опыта и четких инструкций команда новичков (особенно с доступом в мастер) может запороть мастер и подкинуть работы на пару дней более опытным товарищам.
Коммент был скорее о том, что документация git не описывает как в данном проекте он должен быть использован. Поэтому нужно до всех донести стратегию создания и мержа веток для фич, хотфиксов и т.п.
А для особо одаренных — детально описать все пошагово.
По опыту, далеко не все сразу понимают парадигму работы с несколькими форками после SVN.
Еще одна проблема git — в нем можно одно и то же сделать по-разному. И в команде все начинают делать по-своему, что при отсутствии опыта часто приводит к проблемам.
>если в команде новичков есть доступ в master, то у них по определению не было более опытных товарищей.
В git нельзя ограничить доступ на одну ветку. Поэтому, если в проекте не используются личные форки и ограниченный доступ в основной репозиторий (что делает основные процессы намного сложней и используется далеко не везде), такой доступ будет у всех, включая новичков.
технология не готова к массовому использованию
git это же про программистов? С трудом представляю программиста, который способен в C++, но не способен запомнить десяток манипуляций с git.
А выучить можно что угодно. Можно, например, выучить, как отрегулировать карюбратор и перебрать подвеску в жигулях, только вот зачем, когда за те же деньги продаётся автомобиль, на котором можно просто ездить?
А рассказы про автомобиль никак не меняют того факта, что сегодня, сейчас — вы можете либо знать Git и работать, либо не знать — и рассказывать работодателям, почему вы решить задачу не можете… Второе, почему-то, встречает у HR меньше понимания…
std::map<std::string, std::function<bool(std::string)>>::iteratorА HRы, точнее бизнесы, знают, что задача, требущая на С++ 10 часов работы, обычно решается на Java за пять, а на Python за два часа. Программиста на каком языке они по-вашему наймут, если это не разработка драйверов?
Там же половина ответов неправильные...
Как научить людей использовать Git