Пространство окружающего Мира наполнено отдельными событиями и их цепочками — эти события находят отражение в СМИ, в аккаунтах блогеров и обывателей в соцсетях. Получить картину окружающей действительности, претендующую на некую долю объективности можно, только если собрать различные точки зрения на одну и ту же проблему. Категоризатор событий — тот инструмент, который раскладывает “по полочкам” собранную информацию: версии описания событий. Далее предоставить доступ к информации о событиях пользователям через инструменты поиска, рекомендации и визуального представления временных последовательностей событий.
Сегодня мы расскажем о нашей системе, точнее о её программном ядре, под кодовым называнием «Варя» — в честь ведущего разработчика.
Само название нашего стартапа мы пока не можем упоминать, по просьбе администрации Хабрахабра, сейчас мы подали заявку на присвоение нам статуса «Стартап». Однако, о функционале и наших идеях мы можем рассказать уже сейчас. Наша система обеспечивает актуальность информации о событиях для пользователя и грамотное управление данными – в системе, каждый пользователь сам определяет, что смотреть и читать, управляет поиском и рекомендациями.
Наш проект — стартап с командой из 8 человек с компетенциями в проектировании технически и алгоритмически сложных систем, программировании, маркетинге и менеджменте.
Совместными усилиями, каждый день команда работает над проектом — уже реализованы алгоритмы категоризации, поиска и представления информации. Впереди еще внедрение алгоритмов, связанных с рекомендациями для пользователя: исходя из взаимосвязи событий, людей, и анализа пользовательской активности и интересов.
Какие задачи решаем и почему рассказываем об этом? Мы помогаем людям получать подробную информацию о событиях любого масштаба, независимо от того, где и когда они произошли.
Проект дает пользователям платформу для обсуждения событий в кругу единомышленников, позволяет поделиться комментарием или собственной версией случившегося. Социально-медийная платформа создана для тех, кто стремится знать «выше среднего» и иметь личное мнение о главных событиях прошлого, настоящего и будущего.
Пользователи сами находят и создают полезный контент в медийном пространстве и следят за его достоверностью. Мы сохраняем память о событиях их жизни.
Сейчас проект на стадии MVP, тестируем гипотезы о функционале и работе категоризатора, чтобы определиться с верным направлением дальнейшего развития. В этой статье мы расскажем о технологиях, с помощью которых решаем поставленные перед собой задачи и поделимся наработками.
Задачу машинной обработки текстов решают поисковые системы: Яндекс, Google, Bing и т.д. Идеальная система работы с потоками информации и выделения в них событий могла бы выглядеть следующим образом.
Для системы строится инфраструктура, подобная Яндексу и Гуглу, сканируется весь Интернет в реальном времени на наличие обновлений, а затем в потоке информации выделяются ядра событий, вокруг которых формируются агломерации их версий и связанного с ними контента. Программная реализация сервиса основана на нейронной сети глубокого обучения и/или решение, основанное на библиотеке Яндекса — CatBoost.
Круто? Однако у нас пока нет такого объема данных, и нет соответствующих вычислительных ресурсов для усвоения.
Классификация по темам — популярная задача, для ее решения существует множество алгоритмов: наивные байесовские классификаторы, латентное размещение Дирихле, бустинг над решающими деревьями и нейронные сети. Как, наверное, и во всех задачах машинного обучения, при использовании описанных алгоритмов возникают две проблемы:
Во-первых, где взять много данных?
Во-вторых, как их дешево и сердито разместить?
Наш продукт работает с событиями. События несколько отличаются от обычных статей.
Для преодоления «холодного старта» мы решили использовать два проекта WikiMedia: Википедию и Викиновости. Одна статья Википедии может описывать несколько событий (например, история развития компании Sun Microsystems, биография Маяковского или ход Великой Отечественной Войны).
Другие источники информации о событиях — это новостные ленты RSS. В новостях бывает по-разному: большие аналитические статьи содержат несколько событий, как и тексты Википедии, а короткие информационные сообщения из разных источников представляют одно и тоже событие.
Таким образом, статья и события образуют связи многие-ко-многим. Но на этапе MVP мы делаем допущение, что одна статья — это одно событие.
Глядя на интерфейс Гугла или Яндекса, можно подумать, что поисковые системы ищут только ключевым словам. Это так только для очень простых интернет-магазинчиков. Большинство систем поиска многокритериальны, и движок нашего проекта — не исключение. При этом далеко не все параметры, учитываемые при поиске, выводятся в пользовательском интерфейсе. У нашего проекта список параметров, которые выбирает пользователь, такой:
тематика и ключевые слова - “что?”; локация - “где?” ; дата — “когда?” ;
Те, кто пишет поисковые системы, знают, что одни только ключевые слова доставляют много проблем. Ну так остальные параметры тоже не так просты.
Тематика события — очень непростая штука. Человеческий мозг устроен так, что он любит всё категоризировать, а реальный мир с этим категорически не согласен. Поступающие статьи хотят образовать свои собственные группы тематик, и они вовсе не те, в которые мы, и наши пользователи-энтузиасты, их распределяем.
Сейчас у нас 15 основных тематик событий, и этот список несколько раз пересматривался, и, как минимум, будет расти.
Локации и даты устроены чуть более формально, но и тут есть свои подводные камни.
Итак, у нас есть набор формализованных критериев и сырые данные, которые надо на эти критерии маппить. И вот, как мы это делаем.
Задача паука — складывать поступающие статьи так, чтобы по ним можно было быстро искать. Для этого паук должен уметь приписывать статьям тему, локацию и дату, а также еще некоторые параметры, необходимые для ранжирования. Наш паук на вход получает текстовую модель статьи, построенную краулером. Текстовая модель — это список частей статьи и соответствующих им текстов. Например, почти у каждой статьи есть как минимум заголовок и основной текст. На самом деле, у нее еще есть первый абзац, набор категорий, к которому этот текст относит его источник, и список полей инфобокса (для Википедии и источников, которые имеют такие метаданные-теги). Еще есть дата публикации. Для ранжирования в поисковом движке нам будет важно знать, найдена ли, например, дата в заголовке или где-то там в конце текста. По текстовой модели строится модель темы, модель локаций и модель дат, а потом результат складывается в индекс. Про каждую из этих моделей можно написать отдельную статью, так что здесь мы лишь кратко обрисуем подходы.
Определение тематики документов — распространенная задача. Тематика может быть приписана вручную автором документа, а может быть определена автоматически. У нас, конечно, есть тематики, которые приписали нашим документам источники новостей и Википедия, но эти темы — они не про события. Часто вы встречаете в новостных лентах тему «Праздники»? Скорее вы встретите тему «Общество». У нас тоже такая была в одной из ранних редакций. Мы не смогли определить, что же к ней должно относиться, и были вынуждены ее убрать. И вдобавок, у всех источников свой набор тем.
Мы хотим управлять списком тематик, которые выводим нашим пользователям в интерфейсе, поэтому для нас задача определения темы документа — это задача нечеткой классификации. Задача классификации требует размеченных примеров, то есть список документов, которым уже приписаны наши желанные темы. Наш список похож на все подобные списки тем, но не совпадает с ними, так что размеченной выборки у нас не было. Получить ее так же можно вручную или автоматически, но если наш список тем будет меняться (а он будет!), то вручную — не вариант.
Если у вас нет размеченной выборки, вы можете использовать латентное размещение Дирихле и другие алгоритмы тематического моделирования, однако набор получаемых вами тем будет тот, какой получился, а не тот, который вы хотели.
Тут надо упомянуть еще один момент: наши статьи прилетают из разных источников. Все тематические модели строятся так или иначе на используемой лексике. У новостей и Википедии она разная, разные даже отсеиваемые высокачастотники.
Таким образом, перед нами встали две задачи:
1. Придумать способ быстро размечать наши документы в полуавтоматическом режиме.
2. Строить на основе этих документов расширяемую модель наших тем.
Чтобы решить их, мы создали гибридный алгоритм, содержащий автоматизированные и ручные стадии, представленные на рисунке.

Автоматическое определение локаций — это частный случай задачи поиска именованных сущностей. Особенности у локаций следующие:
Даты — воплощение формальности по сравнению с Темами и Локациями. Мы сделали для них расширяемый парсер на регулярных выражениях, и можем разбирать не только день-месяц-год, но и всякие более интересные штуки, типа “конец зимы 1941 года”, “в 90-е годы XIX века” и “в прошлом месяце”, с учетом эры и базовой даты документа, а также пытаемся восстановить недостающий год. Про даты надо знать, что не все они хороши. Например, в конце статьи о каком-нибудь сражении ВОВ может быть открытие мемориала сорок лет спустя, чтобы работать с такими случаями, надо резать статью на события, а мы пока этого не делаем. Так что мы рассматриваем только наиболее важные даты: из заголовка и первых абзацев.
Поисковый движок — это штуковина, которая, во-первых, ищет документы по запросу, а во-вторых, упорядочивает их по убыванию степени соответствия запросу, то есть по убыванию релевантности. Для вычисления релевантности мы используем много параметров, гораздо больше, чем просто тривентность:
Степень принадлежности документа теме.
Степень принадлежности документа локации (сколько раз и в каких частях документа встречается выбранная локация).
Степень соответствия документа дате (учитывается количество дней в пересечении интервала из запроса и дат документа, а также количество дней в пересечении минус объединение).
Длина документа. Длинные статьи должны быть выше.
Наличие картинки. Все любят картинки, их должно быть больше!
Тип статьи в Википедии. Мы умеем отделять статьи с описаниями событий, и они должны “всплывать” вверх в выборке.
Источник статьи. Новости и пользовательские статьи должны быть выше Википедии.
В качестве поискового движка мы используем Apache Lucene.
Задача краулера — собирать статьи для паука. В нашем случае сюда же мы отнесем первичную очистку текста, и построение текстовой модели документа. Краулер заслуживает отдельной статьи.
P.S. Будем рады любой обратной связи, приглашаем протестировать наш проект — для получение ссылки, пишите в личные сообщения (опубликовать здесь не можем). Свои комментарии оставляйте под статьей, или если доберетесь до нашего сервиса — прям там, через форму обратной связи.
Сегодня мы расскажем о нашей системе, точнее о её программном ядре, под кодовым называнием «Варя» — в честь ведущего разработчика.
Само название нашего стартапа мы пока не можем упоминать, по просьбе администрации Хабрахабра, сейчас мы подали заявку на присвоение нам статуса «Стартап». Однако, о функционале и наших идеях мы можем рассказать уже сейчас. Наша система обеспечивает актуальность информации о событиях для пользователя и грамотное управление данными – в системе, каждый пользователь сам определяет, что смотреть и читать, управляет поиском и рекомендациями.
Наш проект — стартап с командой из 8 человек с компетенциями в проектировании технически и алгоритмически сложных систем, программировании, маркетинге и менеджменте.
Совместными усилиями, каждый день команда работает над проектом — уже реализованы алгоритмы категоризации, поиска и представления информации. Впереди еще внедрение алгоритмов, связанных с рекомендациями для пользователя: исходя из взаимосвязи событий, людей, и анализа пользовательской активности и интересов.
Какие задачи решаем и почему рассказываем об этом? Мы помогаем людям получать подробную информацию о событиях любого масштаба, независимо от того, где и когда они произошли.
Проект дает пользователям платформу для обсуждения событий в кругу единомышленников, позволяет поделиться комментарием или собственной версией случившегося. Социально-медийная платформа создана для тех, кто стремится знать «выше среднего» и иметь личное мнение о главных событиях прошлого, настоящего и будущего.
Пользователи сами находят и создают полезный контент в медийном пространстве и следят за его достоверностью. Мы сохраняем память о событиях их жизни.
Сейчас проект на стадии MVP, тестируем гипотезы о функционале и работе категоризатора, чтобы определиться с верным направлением дальнейшего развития. В этой статье мы расскажем о технологиях, с помощью которых решаем поставленные перед собой задачи и поделимся наработками.
Задачу машинной обработки текстов решают поисковые системы: Яндекс, Google, Bing и т.д. Идеальная система работы с потоками информации и выделения в них событий могла бы выглядеть следующим образом.
Для системы строится инфраструктура, подобная Яндексу и Гуглу, сканируется весь Интернет в реальном времени на наличие обновлений, а затем в потоке информации выделяются ядра событий, вокруг которых формируются агломерации их версий и связанного с ними контента. Программная реализация сервиса основана на нейронной сети глубокого обучения и/или решение, основанное на библиотеке Яндекса — CatBoost.
Круто? Однако у нас пока нет такого объема данных, и нет соответствующих вычислительных ресурсов для усвоения.
Классификация по темам — популярная задача, для ее решения существует множество алгоритмов: наивные байесовские классификаторы, латентное размещение Дирихле, бустинг над решающими деревьями и нейронные сети. Как, наверное, и во всех задачах машинного обучения, при использовании описанных алгоритмов возникают две проблемы:
Во-первых, где взять много данных?
Во-вторых, как их дешево и сердито разместить?
Какой подход выбрали мы для событийно-основанной системы?
Наш продукт работает с событиями. События несколько отличаются от обычных статей.
Для преодоления «холодного старта» мы решили использовать два проекта WikiMedia: Википедию и Викиновости. Одна статья Википедии может описывать несколько событий (например, история развития компании Sun Microsystems, биография Маяковского или ход Великой Отечественной Войны).
Другие источники информации о событиях — это новостные ленты RSS. В новостях бывает по-разному: большие аналитические статьи содержат несколько событий, как и тексты Википедии, а короткие информационные сообщения из разных источников представляют одно и тоже событие.
Таким образом, статья и события образуют связи многие-ко-многим. Но на этапе MVP мы делаем допущение, что одна статья — это одно событие.
Глядя на интерфейс Гугла или Яндекса, можно подумать, что поисковые системы ищут только ключевым словам. Это так только для очень простых интернет-магазинчиков. Большинство систем поиска многокритериальны, и движок нашего проекта — не исключение. При этом далеко не все параметры, учитываемые при поиске, выводятся в пользовательском интерфейсе. У нашего проекта список параметров, которые выбирает пользователь, такой:
тематика и ключевые слова - “что?”; локация - “где?” ; дата — “когда?” ;
Те, кто пишет поисковые системы, знают, что одни только ключевые слова доставляют много проблем. Ну так остальные параметры тоже не так просты.
Тематика события — очень непростая штука. Человеческий мозг устроен так, что он любит всё категоризировать, а реальный мир с этим категорически не согласен. Поступающие статьи хотят образовать свои собственные группы тематик, и они вовсе не те, в которые мы, и наши пользователи-энтузиасты, их распределяем.
Сейчас у нас 15 основных тематик событий, и этот список несколько раз пересматривался, и, как минимум, будет расти.
Локации и даты устроены чуть более формально, но и тут есть свои подводные камни.
Итак, у нас есть набор формализованных критериев и сырые данные, которые надо на эти критерии маппить. И вот, как мы это делаем.
Паук
Задача паука — складывать поступающие статьи так, чтобы по ним можно было быстро искать. Для этого паук должен уметь приписывать статьям тему, локацию и дату, а также еще некоторые параметры, необходимые для ранжирования. Наш паук на вход получает текстовую модель статьи, построенную краулером. Текстовая модель — это список частей статьи и соответствующих им текстов. Например, почти у каждой статьи есть как минимум заголовок и основной текст. На самом деле, у нее еще есть первый абзац, набор категорий, к которому этот текст относит его источник, и список полей инфобокса (для Википедии и источников, которые имеют такие метаданные-теги). Еще есть дата публикации. Для ранжирования в поисковом движке нам будет важно знать, найдена ли, например, дата в заголовке или где-то там в конце текста. По текстовой модели строится модель темы, модель локаций и модель дат, а потом результат складывается в индекс. Про каждую из этих моделей можно написать отдельную статью, так что здесь мы лишь кратко обрисуем подходы.
Тематика
Определение тематики документов — распространенная задача. Тематика может быть приписана вручную автором документа, а может быть определена автоматически. У нас, конечно, есть тематики, которые приписали нашим документам источники новостей и Википедия, но эти темы — они не про события. Часто вы встречаете в новостных лентах тему «Праздники»? Скорее вы встретите тему «Общество». У нас тоже такая была в одной из ранних редакций. Мы не смогли определить, что же к ней должно относиться, и были вынуждены ее убрать. И вдобавок, у всех источников свой набор тем.
Мы хотим управлять списком тематик, которые выводим нашим пользователям в интерфейсе, поэтому для нас задача определения темы документа — это задача нечеткой классификации. Задача классификации требует размеченных примеров, то есть список документов, которым уже приписаны наши желанные темы. Наш список похож на все подобные списки тем, но не совпадает с ними, так что размеченной выборки у нас не было. Получить ее так же можно вручную или автоматически, но если наш список тем будет меняться (а он будет!), то вручную — не вариант.
Если у вас нет размеченной выборки, вы можете использовать латентное размещение Дирихле и другие алгоритмы тематического моделирования, однако набор получаемых вами тем будет тот, какой получился, а не тот, который вы хотели.
Тут надо упомянуть еще один момент: наши статьи прилетают из разных источников. Все тематические модели строятся так или иначе на используемой лексике. У новостей и Википедии она разная, разные даже отсеиваемые высокачастотники.
Таким образом, перед нами встали две задачи:
1. Придумать способ быстро размечать наши документы в полуавтоматическом режиме.
2. Строить на основе этих документов расширяемую модель наших тем.
Чтобы решить их, мы создали гибридный алгоритм, содержащий автоматизированные и ручные стадии, представленные на рисунке.
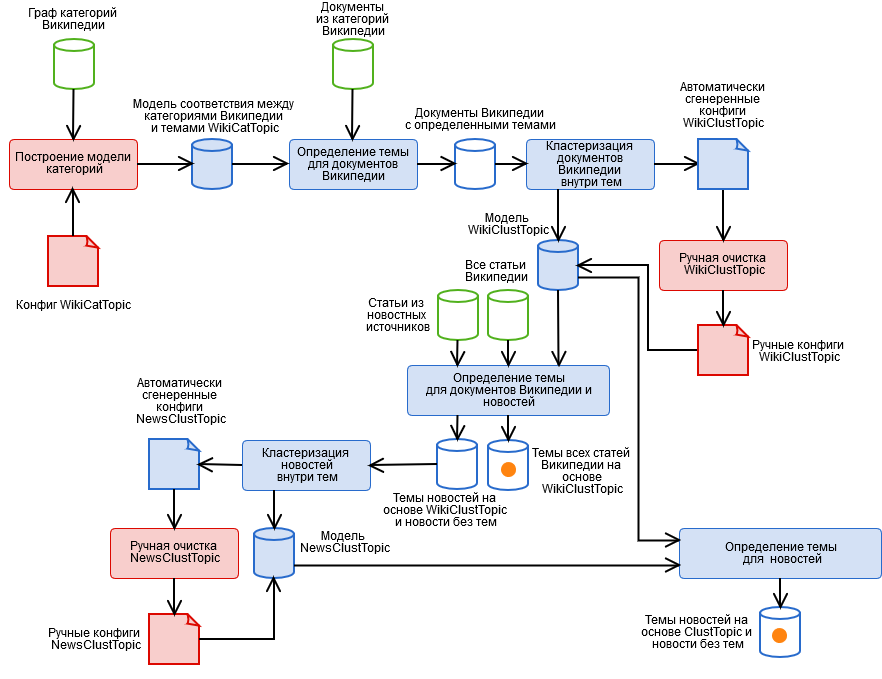
- Ручная разметка категорий Википедии и получение категориальной модели темы WikiCatTopic. На этом этапе строится конфиг, который каждой нашей теме T ставит в соответствие подграф СT категорий Википедии. Википедия является псевдо-онтологией. Это значит, что если что-то входит в категорию “Наука”, оно может быть вовсе не про науку, например, из безобидной подкатегории “Информационные технологии” на самом деле можно прийти к любой статье Википедии. О том, как с этим жить, нужна отдельная статья.
- Автоматическое определение тематики для документов Википедии на основе WikiCatTopic. Документу присваивается тема T, если он входит в одну из категорий графа СT. Заметим, что такой способ применим только для Википедийных статей. Чтобы обобщить определение тем на произвольный текст, можно было построить bag-of-words каждой тематики, и считать косинусное расстояние до тематики (и мы попробовали, ничего хорошего), но тут надо учесть три момента.
- Такие тематики содержат очень разнообразные статьи, поэтому образ тематики в пространстве слов будет не связный, а значит, “уверенность” такой модели в определении тематики очень низкая (ведь статья на одно небольшое множество статей похожа, а на остальные — нет).
- Произвольный текст, в первую очередь, новости, отличается по лексическому составу от Википедии, это тоже не добавляет модели “уверенности”. Кроме того, некоторые темы нельзя построить на основе Википедии.
- Этап 1 — очень кропотливая работенка, и всем лень ее делать.
- Кластеризация документов внутри тематик на основе результатов пункта 2 методом k-средних и получение кластерной модели темы WikiClustTopic. Довольно простой ход, который позволил нам в значительной степени решить две из трех проблем из пункта 2. Для кластеров строим bag-of-words, и принадлежность к теме определяется как максимальное из косинусных расстояний до ее кластеров. Модель описывается у нас конфигурационными файлами соответствия между кластерами и документами Википедии.
- Ручная очистка модели WikiClustTopic, включение-отключение-перенос кластеров. Тут мы также возвращались на этап 1, когда обнаруживались совсем неправильные кластеры.
- Автоматическое определение тем документов Википедии и новостей на основе WikiClustTopic.
- Кластеризация новостей внутри тем на основе результатов пункта 5 методом k-средних, а также новостей, не получивших темы, и получение кластерной модели темы NewsClustTopic. Теперь у нас есть модель темы, учитывающая специфику новостей (а также бесценная информация о качестве работы краулера).
- Ручная очистка модели NewsClustTopic.
- Переназначение тем для новостей на основе объединенной модели ClustTopic = WikiClustTopic + NewsClustTopic. На основе этой модели определяются темы новых документов.
Локации
Автоматическое определение локаций — это частный случай задачи поиска именованных сущностей. Особенности у локаций следующие:
- Все списки локаций — разные, и плохо стыкуются между собой. Мы построили свой, гибридный, который учитывает не только иерархию (Россия включает в себя Новосибирскую область), но и исторические изменения названий (например РСФСР стала Россией) на основе: Geonames, Wikidata и других открытых источников. Однако, нам всё равно пришлось писать преобразователь геометок с Google Maps :)
- Некоторые локации состоят из нескольких слов, например, Нижний Новгород, и надо уметь их собирать.
- Локации похожи на другие слова, особенно на имена тех, в честь кого названы: Киров, Жуков, Владимир. Это омонимия. Чтобы вылечить это, мы собрали статистику по статьям Википедии, описывающим населенные пункты, в каких контекстах встречаются именно названия локаций, а также постарались построить список таких омонимов с помощью словарей Open Corpora.
- Человечество не сильно напрягало воображение, и очень многие места названы одинаково. Наш любимый пример: Карасук в Казахстане и в России, под Новосибирском. Это омонимия внутри класса локаций. Мы разрешаем ее, учитывая, какие еще локации встречаются вместе с данной, и являются ли они родительскими или дочерними для одного из омонимов. Эта эвристика не универсальна, но она неплохо работает.
Даты
Даты — воплощение формальности по сравнению с Темами и Локациями. Мы сделали для них расширяемый парсер на регулярных выражениях, и можем разбирать не только день-месяц-год, но и всякие более интересные штуки, типа “конец зимы 1941 года”, “в 90-е годы XIX века” и “в прошлом месяце”, с учетом эры и базовой даты документа, а также пытаемся восстановить недостающий год. Про даты надо знать, что не все они хороши. Например, в конце статьи о каком-нибудь сражении ВОВ может быть открытие мемориала сорок лет спустя, чтобы работать с такими случаями, надо резать статью на события, а мы пока этого не делаем. Так что мы рассматриваем только наиболее важные даты: из заголовка и первых абзацев.
Поисковый движок
Поисковый движок — это штуковина, которая, во-первых, ищет документы по запросу, а во-вторых, упорядочивает их по убыванию степени соответствия запросу, то есть по убыванию релевантности. Для вычисления релевантности мы используем много параметров, гораздо больше, чем просто тривентность:
Степень принадлежности документа теме.
Степень принадлежности документа локации (сколько раз и в каких частях документа встречается выбранная локация).
Степень соответствия документа дате (учитывается количество дней в пересечении интервала из запроса и дат документа, а также количество дней в пересечении минус объединение).
Длина документа. Длинные статьи должны быть выше.
Наличие картинки. Все любят картинки, их должно быть больше!
Тип статьи в Википедии. Мы умеем отделять статьи с описаниями событий, и они должны “всплывать” вверх в выборке.
Источник статьи. Новости и пользовательские статьи должны быть выше Википедии.
В качестве поискового движка мы используем Apache Lucene.
Краулер
Задача краулера — собирать статьи для паука. В нашем случае сюда же мы отнесем первичную очистку текста, и построение текстовой модели документа. Краулер заслуживает отдельной статьи.
P.S. Будем рады любой обратной связи, приглашаем протестировать наш проект — для получение ссылки, пишите в личные сообщения (опубликовать здесь не можем). Свои комментарии оставляйте под статьей, или если доберетесь до нашего сервиса — прям там, через форму обратной связи.










