На датафесте 2 в Минске Владимир Игловиков, инженер по машинному зрению в Lyft, совершенно замечательно объяснил, что лучший способ научиться Data Science — это участвовать в соревнованиях, запускать чужие решения, комбинировать их, добиваться результата и показывать свою работу. Собственно в рамках этой парадигмы я и решил посмотреть внимательнее на соревнование по оценке кредитного риска от Home Credit и объяснить (начинающим дата саентистам и прежде всего самому себе), как правильно анализировать подобные датасеты и строить под них модели.
(картинка отсюда)
 Home Credit Group — группа банков и небанковских кредитных организаций, ведет операции в 11 странах (в том числе в России как ООО «Хоум Кредит энд Финанс Банк»). Цель соревнования — создать методику оценки кредитоспособности заемщиков, не имеющих кредитной истории. Что выглядит довольно благородно — заемщики этой категории часто не могут получить никакой кредит в банке и вынуждены обращаться к мошенникам и микрозаймам. Интересно, что заказчик не выставляет требований по прозрачности и интерпретируемости модели (как это обычно бывает в банках), можно использовать что угодно, хоть нейросети.
Home Credit Group — группа банков и небанковских кредитных организаций, ведет операции в 11 странах (в том числе в России как ООО «Хоум Кредит энд Финанс Банк»). Цель соревнования — создать методику оценки кредитоспособности заемщиков, не имеющих кредитной истории. Что выглядит довольно благородно — заемщики этой категории часто не могут получить никакой кредит в банке и вынуждены обращаться к мошенникам и микрозаймам. Интересно, что заказчик не выставляет требований по прозрачности и интерпретируемости модели (как это обычно бывает в банках), можно использовать что угодно, хоть нейросети.
Обучающая выборка состоит из 300+ тыс. записей, признаков достаточно много — 122, среди них много категориальных (не числовых). Признаки довольно подробно описывают заемщика, вплоть до материала, из которого сделаны стены его жилища. Часть данных содержатся в 6 дополнительных таблицах (данные по кредитному бюро, балансу кредитной карты и предыдущим кредитам), эти данные нужно тоже как-то обработать и подгрузить к основным.
Соревнование выглядит как стандартная задача классификации (1 в поле TARGET означает любые сложности с платежами, 0 — отсутствие сложностей). Однако следует предсказывать не 0/1, а вероятность возникновения проблем (что, впрочем, довольно легко решают методы предсказания вероятностей predict_proba, которые есть у всех сложных моделей).
На первый взгляд датасет довольно стандартной для задач машинного обучения, организаторы предложили крупный приз в $70к, в итоге в соревновании на сегодня участвует уже больше 2600 команд, а битва идет за тысячные доли процентов. Однако, с другой стороны, такая популярность означает, что датасет исследован вдоль и поперек и создано много кернелов с хорошими EDA (Exploratory Data Analisys — исследование и анализ данных в сете, в том числе графический), Feature engineering'ом (работа с признаками) и с интересными моделями. (Кернел — это пример работы с датасетом, который может выложить любой желающий, чтобы показать свою работу другим кагглерам.)
Заслуживают внимания кернелы:
Для работы с данными обычно рекомендуется следующий план, которому мы и постараемся следовать.
В данном случае нужно взять поправку на то, что данные довольно обширны и сразу их можно и не осилить, есть смысл действовать поэтапно.
Начнем с импорта библиотек, которые нам понадобятся в анализе для работы с данными в виде таблиц, построения графиков и для работы с матрицами.
Загрузим данные. Посмотрим, что у нас вообще есть. Такое расположение в каталоге "../input/", кстати, связано с требованием по размещению своих кернелов на Kaggle.
Есть 8 таблиц с данными (не считая таблицы HomeCredit_columns_description.csv, в которой содержится описание полей), которые связаны между собой следующим образом:
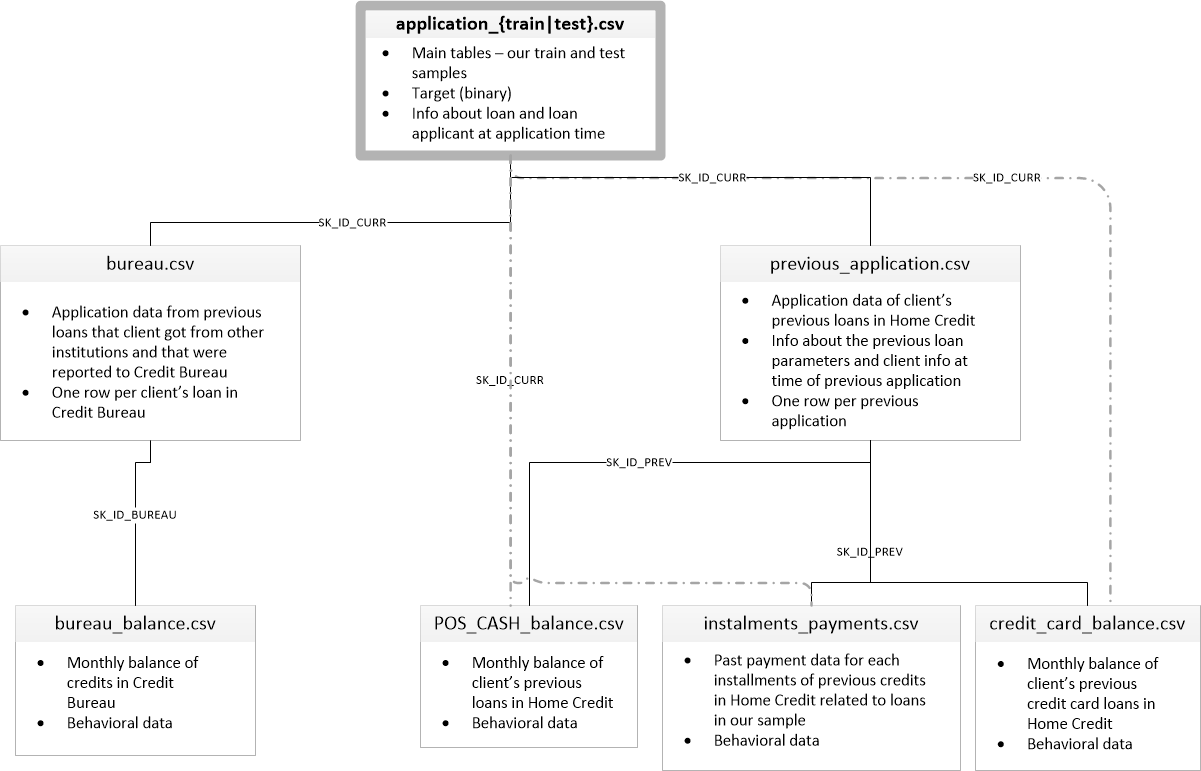
application_train/application_test: Основные данные, заемщик идентифицируется по полю SK_ID_CURR
bureau: Данные по предыдущим займам в других кредитных организациях из кредитного бюро
bureau_balance: Ежемесячные данные по предыдущим кредитам по бюро. Каждая строка — месяц испльзования кредита
previous_application: Предыдущие заявки по кредитам в Home Credit, каждая имеет уникальное поле SK_ID_PREV
POS_CASH_BALANCE: Ежемесячные данные по кредитам в Home Creditс выдачей наличными и кредитам на покупки товаров
credit_card_balance: Ежемесячные данные по балансу кредитных карт в Home Credit
installments_payment: Платежная история предыдущих займов в Home Credit.
Сосредоточимся для начала на основном источнике данных и посмотрим, какую информацию из него можно извлечь и какие модели построить. Загрузим основные данные.
Итого у нас есть 307 тысяч записей и 122 признака в обучающей выборке и 49 тысяч записей и 121 признак в тестовой. Расхождение, очевидно, вызвано тем, что целевого признака TARGET в тестовой выборке нет, его-то мы и будем предсказывать.
Посмотрим на данные внимательнее
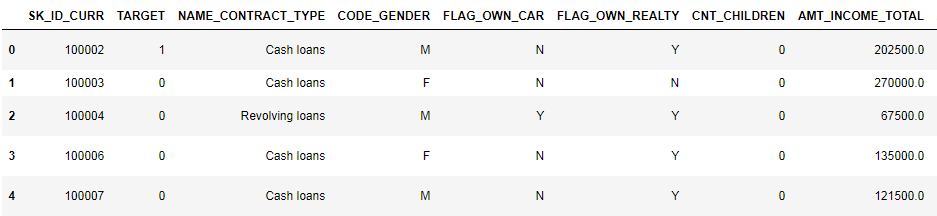
(показано первые 8 столбцов)
Довольно сложно смотреть данные в таком формате. Посмотрим на список столбцов:
Напомню, подробные аннотации по полям — в файле HomeCredit_columns_description. Как видно из info, часть данных неполная и часть — категориальная, они отображаются как object. Большинство моделей с такими данными не работают, нам придется что-то с этим делать. На этом начальный анализ можно считать законченным, перейдем непосредственно к EDA
В процессе EDA мы считаем основные статистики и рисуем графики, чтобы найти тренды, аномалии, паттерны и связи внутри данных. Цель EDA — узнать, что могут рассказать данные. Обычно анализ идет сверху вниз — от общего обзора к исследованию отдельных зон, которые привлекают внимание и могут представлять интерес. Впоследствии эти находки можно использовать в построении модели, выборе признаков для нее и в её интерпретации.
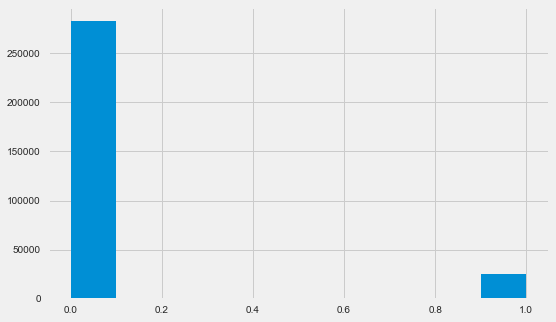
Напомню, 1 означает проблемы любого рода с возвратом, 0 — отсутствие проблем. Как видно, в основном заемщики не имеют проблем с возвратом, доля проблемных около 8%. Это значит, что классы не сбалансированы и это, возможно, нужно будет учитывать при построении модели.
Мы видели, что нехватка данных довольно существенна. Посмотрим более подробно, где и чего недостает.
В графическом формате:
На вопрос «что со всем этим делать» есть много ответов. Можно заполнить нулями, можно медианными значениями, можно просто удалить строки без нужной информации. Все зависит от модели, которую мы планируем использовать, так как некоторые совершенно отлично справляются с отсутствующими значениями. Пока запомним этот факт и оставим все как есть.
Как мы помним. часть столбцов имеет тип object, то есть имеет не числовое значение, а отражает какую-то категорию. Посмотрим на эти столбцы более внимательно.
У нас есть 16 столбцов, в каждом из которых от 2 до 58 разных вариантов значений. В основном модели машинного обучения не могут ничего сделать с таким столбцами (кроме некоторых, например LightGBM или CatBoost). Так как мы планируем опробовать разные модели на датасете, то с этим надо что-то делать. Подходов здесь в основном два:
Из популярных также стоит отметить mean target encoding (за уточнение спасибо roryorangepants).
С Label Encoding есть небольшая проблема — он присваивает числовые значения, которые не имеют ничего общего с реальностью. Например, если мы имеем дело с числовым значением, то доход заемщика в 100000 однозначно больше и лучше, чем доход в 20000. Но можно ли сказать, что, например, один город лучше другого потому, что одному присвоено значение 100, а другому — 200?
One-Hot-encoding, с другой стороны, более безопасен, но может плодить «лишние» столбцы. Например, если мы закодируем тот же пол при помощи One-Hot, у нас получится два столбца, «пол мужской» и «пол женский», хотя хватило бы и одного, «мужчина ли это».
По хорошему для данного датасета надо бы кодировать признаки с низкой вариативностью при помощи Label Encoding, а все остальное — One-Hot, но для упрощения закодируем все по One-Hot. На скорость вычисления и результат это практически не повлияет. Сам процесс кодирования pandas делает очень просто
Так как количество вариантов в столбцах выборок не равное, количество столбцов теперь не совпадает. Требуется выравнивание — нужно убрать из тренировочной выборки столбцы, которых нет в тестовой. Это делает метод align, нужно указать axis=1 (для столбцов).
Хороший метод понять данные — рассчитать коэффициенты корреляции Пирсона для данных относительно целевого признака. Это не лучший метод показать релевантность признаков, но он прост и позволяет составить представление о данных. Интерпретировать коэффициенты можно следующим образом:
Таким образом, все данные слабо коррелируют с таргетом (кроме самого таргета, который, понятно, равен сам себе). Однако из данных выделяются возраст и некие «внешние источники данных». Вероятно, это некие дополнительные данные из других кредитных организаций. Забавно, что хотя цель декларируется как независимость от подобных данных в принятии кредитного решения, на деле мы будем основываться в первую очередь на них.
Понятно, что чем старше клиент, тем выше вероятность возврата (до определенного предела, конечно). Но возраст почему-то указан в отрицательных днях до выдачи кредита, поэтому он положительно коррелирует с невозвратом (что выглядит несколько странно). Приведем его к положительному значению и посмотрим на корреляцию.
Посмотрим на переменную внимательнее. Начнем с гистограммы.
Сама по себе гистограмма распределения может сказать немного полезного, кроме того что мы не видим особых выбросов и все выглядит более-менее правдоподобно. Чтобы показать эффект влияния возраста на результат, можно построить график kernel density estimation (KDE) — распределение ядерной плотности, раскрашенный в цвета целевого признака. Он показывает распределение одной переменной и может быть истолкован как сглаженная гистограмма (рассчитывается как Гауссианское ядро по каждой точке, которое затем усредняется для сглаживания).
Как видно, доля невозвратов выше для молодых людей и снижается с ростом возраста. Это не повод отказывать молодым людям в кредите всегда, такая «рекомендация» приведет лишь к потере доходов и рынка для банка. Это повод задуматься о более тщательном отслеживании таких кредитов, оценке и, возможно, даже каком-то финансовом образовании для молодых заемщиков.
Посмотрим внимательнее на «внешние источники данных» EXT_SOURCE и их корреляцию.
Также корреляцию удобно отображать при помощи heatmap
Как видно, все источники показывают негативную корреляцию с таргетом. Посмотрим на рапсределение KDE по каждому источнику.
Картина аналогична распределению по возрасту — с ростом показателя растет вероятность возврата кредита. Третий источник наиболее силен в этом плане. Хотя в абсолютном выражении корреляция с целевой переменной все еще в категории «очень низкая», источники внешних данных и возраст будут иметь наивысшее значение в построении модели.
Для лучшего понимания взаимоотношений этих переменных можно построить парный график, в нем мы сможем увидеть взаимоотношения каждой пары и гистограмму распределения по диагонали. Выше диагонали можно показать диаграмму рассеяния, а ниже — 2d KDE.
Синим показаны возвратные кредиты, красным — невозвратные. Интерпретировать это все довольно сложно, но зато из этой картинки может выйти неплохой принт на майку или картина в музей современного искусства.
Рассмотрим более подробно другие признаки и их зависимость от целевой переменной. Так как среди них много категориальных (а мы уже успели их закодировать), нам снова понадобятся исходные данные. Назовем их немного по-другому во избежание путаницы
Также нам понадобится пара функций для красивого отображения распределений и их влияния на целевую переменную. Большое за них спасибо автору вот этого кернела
Итак, рассмотрим основные признаки колиентов
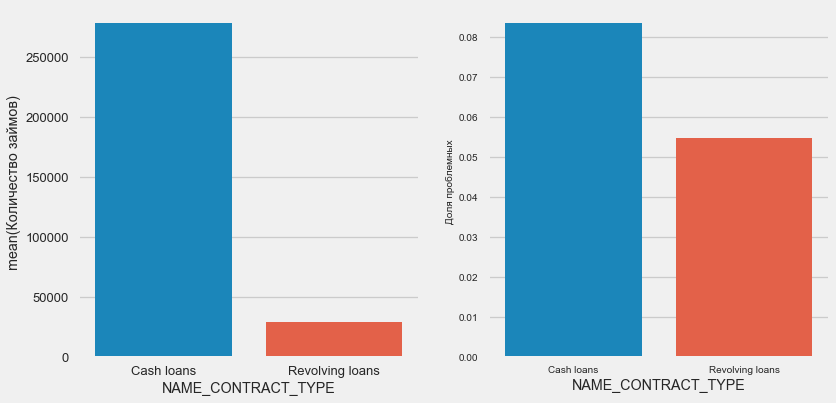
Интересно, что револьверные кредиты (вероятно, овердрафты или что-то вроде того) составляют меньше 10% от общего количества займов. В то же время процент невозврата среди них гораздо выше. Хороший повод пересмотреть методику работы с этими займами, а может быть и отказаться от них вовсе.
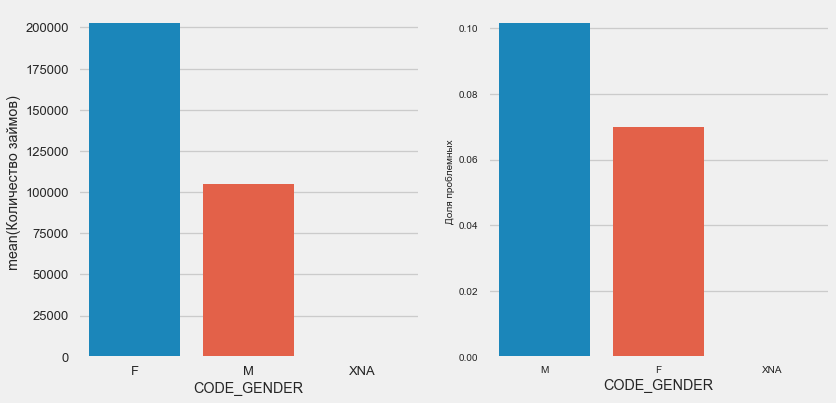
Женщин-клиентов почти вдвое больше мужчин, при этом мужчины показывают гораздо более высокий риск.
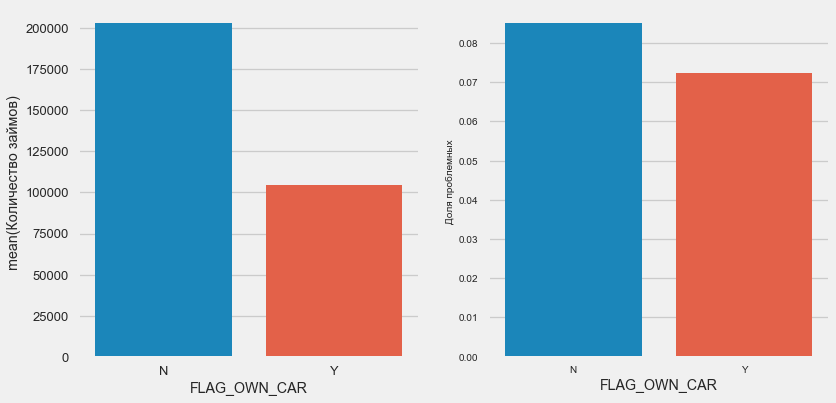
Клиентов с машиной вдвое меньше «безлошадных». Риск по ним практически одинаковый, клиенты с машиной платят чуть лучше.
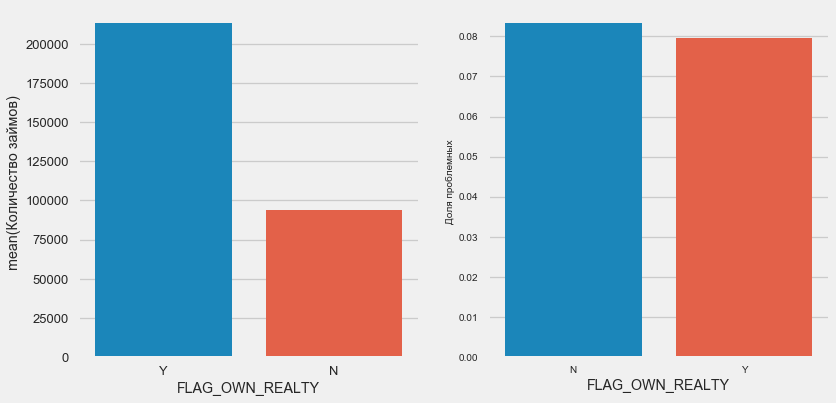
По недвижимости обратная картина — клиентов без нее вдвое меньше. Риск по владельцам недвижимости также чуть меньше.
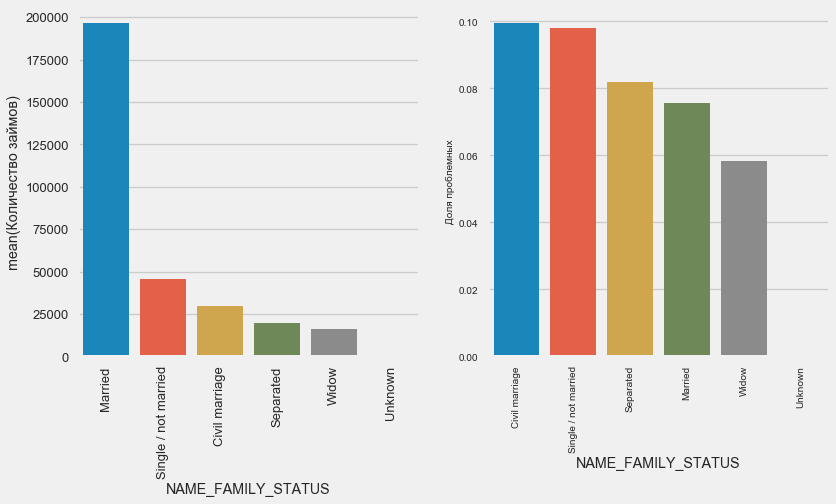
В то время как большинство клиентов состоит в браке, ниаболее рискованы клиенты в гражданском браке и одинокие. Вдовцы показывают минимальный риск.
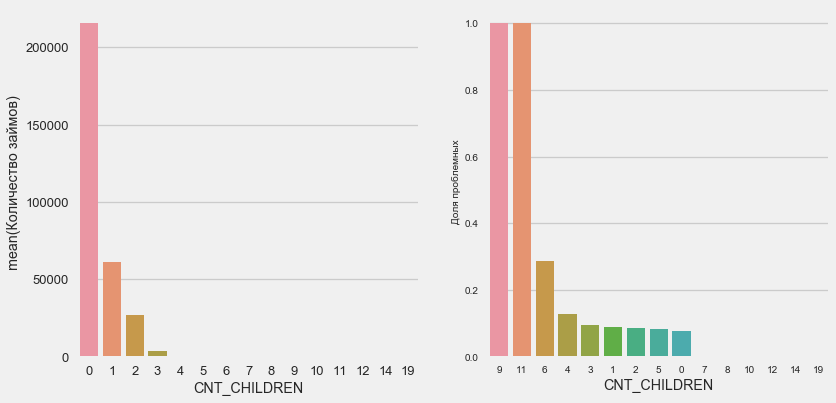
Большинство клиентов бездетны. При этом клиенты с 9 и 11 детьми показывают полный невозврат
Как показывает подсчет значений, эти данные статистически незначимы — всего по 1-2 клиента обеих категорий. Однако, все трое вышли в дефолт, равно как и половина клиентов с 6 детьми.
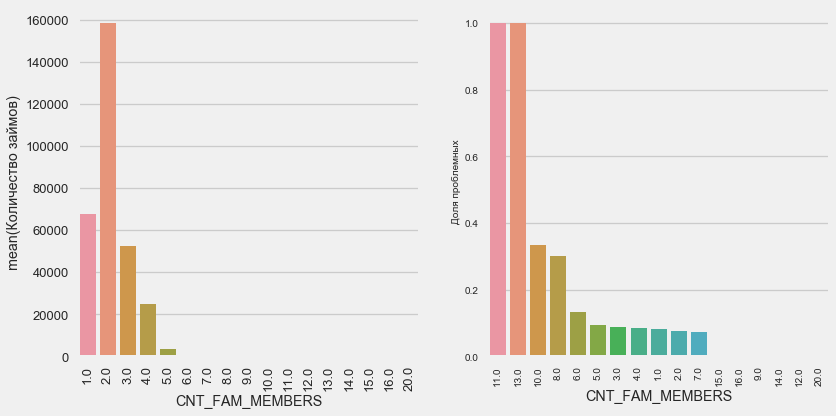
Ситауция аналогична — чем меньше ртов, тем выше возвратность.
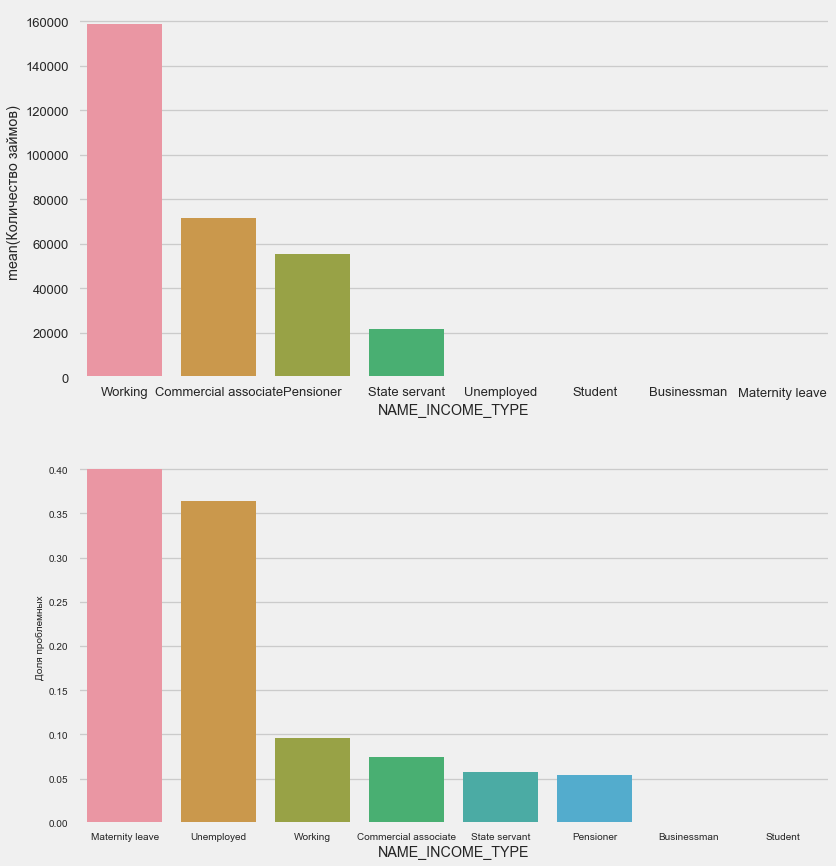
Матери-одиночки и безработные, скорее всего, уже отсекаются на этапе подачи заявки — их слишком мало в выборке. Но стабильно показывают проблемы.
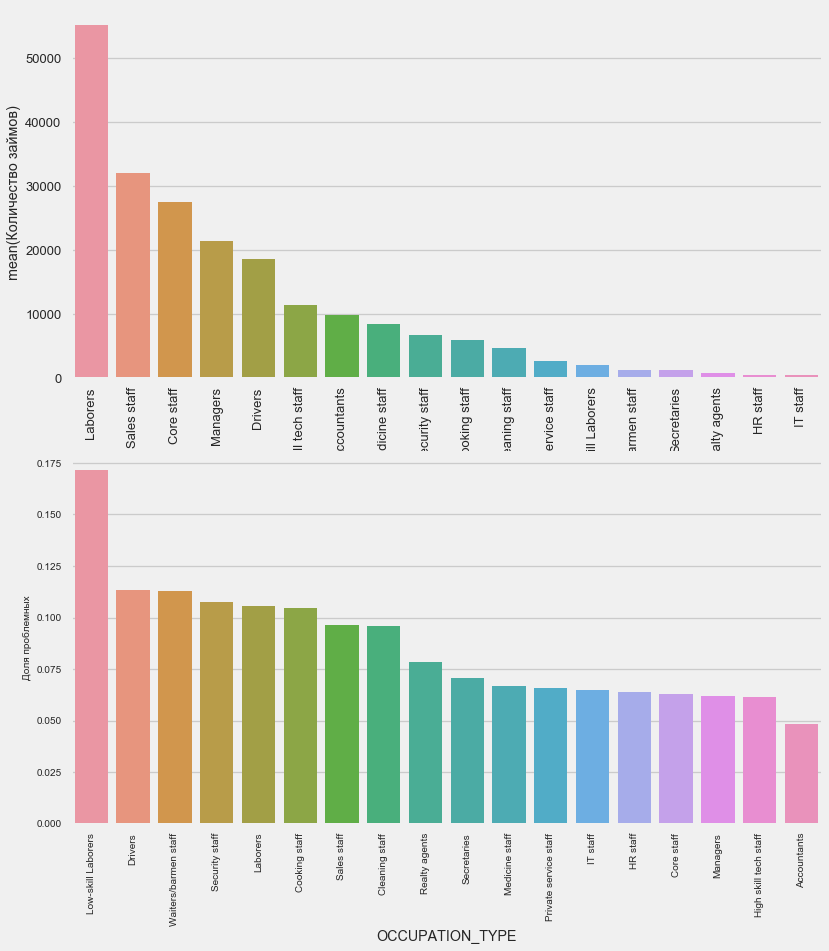
Здесь вызывают интерес водители и сотрудники безопасности, которые довольно многочисленны и выходят на проблемы чаще других категорий.
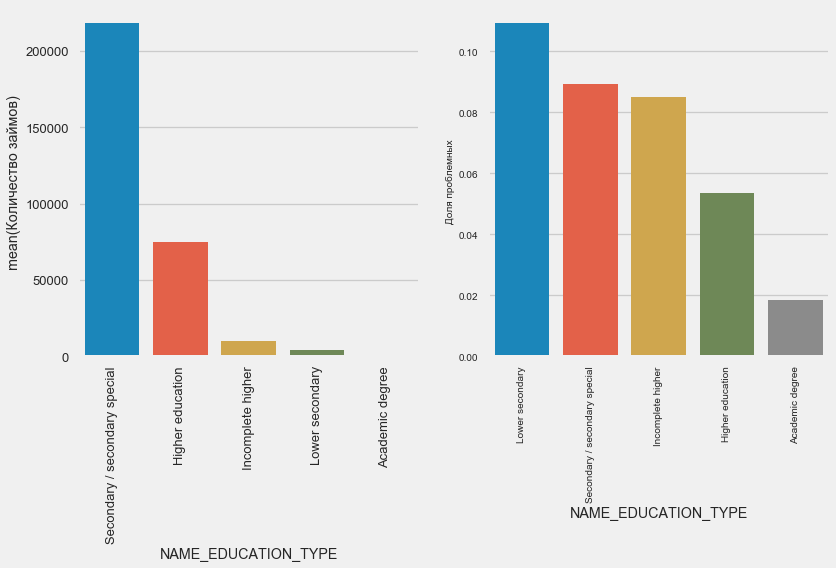
Чем выше образование, тем лучше возвратность, очевидно.
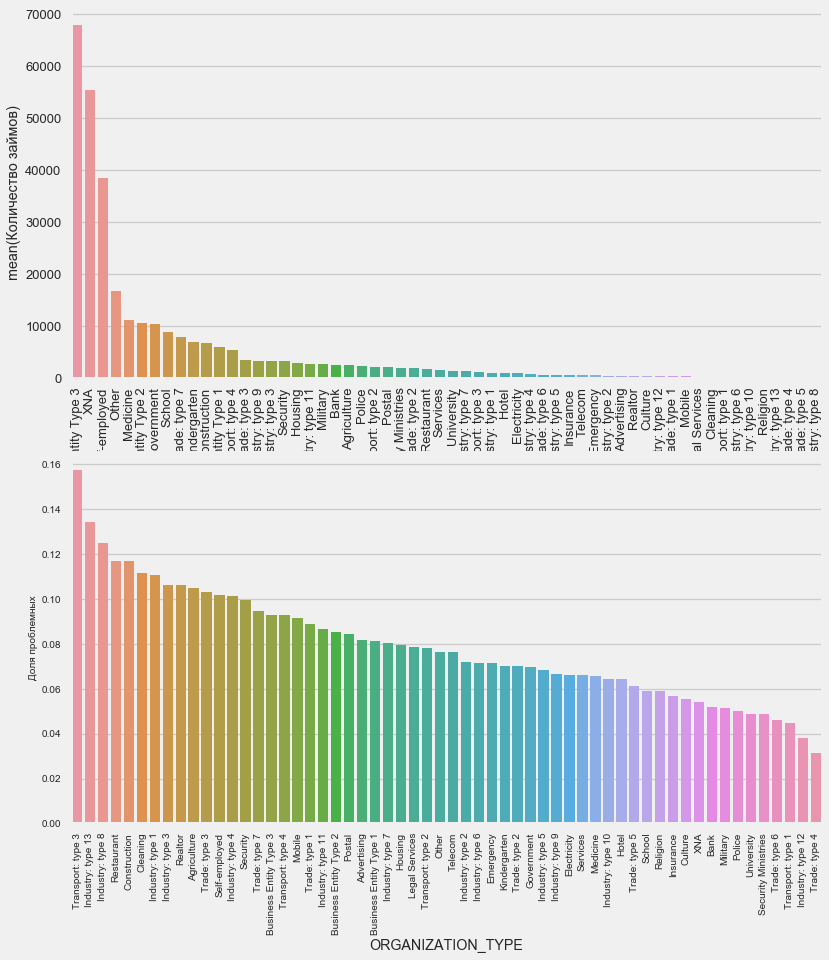
Наивысший процент невозврата наблюдается в Transport: type 3 (16%), Industry: type 13 (13.5%), Industry: type 8 (12.5%) и в Restaurant (до 12%).
Рассмотрим распределение сумм кредитов и влияние их на возвратность
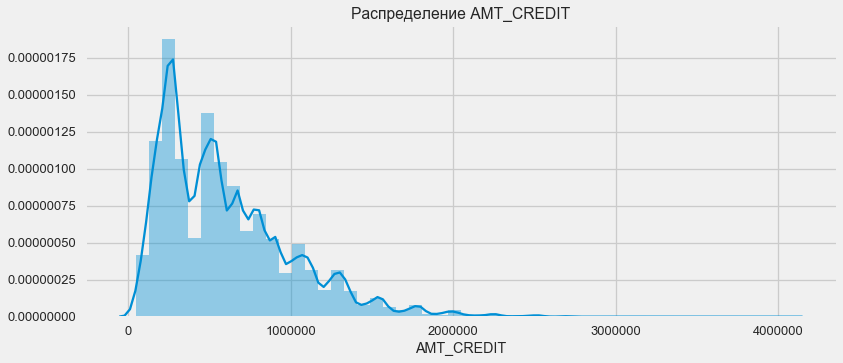
Как показывает график плотности, крепные суммы возвращаются чаще
Клиенты из более населенных регионов склонны лучше выплачивать кредит.
Таким образом, мы получили представление об основных признаках датасета и их влиянии на результат. Конкретно с перечисленными в этой статье мы ничего делать не будем, но они могут оказаться очень важными в дальнейшей работе.
Соревнования на Kaggle выигрываются преобразованием признаков — побеждает тот, кто смог создать самые полезные признаки из данных. По меньшей мере для структурированных данных выигрышные модели — это сейчас в основном разные варианты градиентного бустинга. Чаще всего эффективнее потратить время на преобразование признаков, чем на настройку гиперпараметров или подбор моделей. Модель все-таки может обучиться только по тем данным, которые ей переданы. Убедиться, что данные релевантны задаче — главная ответственность дата саентиста.
Процесс преобразования признаков может включать создание новых из имеющихся данных, выбор наиболее важных из имеющихся и т.д. Опробуем на этот раз полиномиальные признаки.
Полиномиальный метод конструирования признаков заключается в то, что мы просто создаем признаки, которые являются степенью имеющихся признаков и их произведениями. В некоторых случаях такие сконструированные признаки могут иметь более сильную корреляцию с целевой переменной, чем их «родители». Хотя такие методы часто используются в статистических моделях, в машинном обучении они встречаются значительно реже. Впрочем. ничего не мешает нам их попробовать, тем более что Scikit-Learn имеет класс специально для этих целей — PolynomialFeatures — который создает полиномиальные признаки и их произведения, нужно указать лишь сами исходные признаки и максимальную степень, в которую их нужно возводить. Используем самые мощные по силе воздействия на результат 4 признака и степень 3, чтобы не слишком сильно усложнять модель и избежать оверфиттинга (перетренированности модели — её излишней подстройки под обучающую выборку).
Итого 35 полиномиальных и производных признаков. Проверим их корреляцию с таргетом.
Итак, некоторые признаки показывают более высокую корреляцию, чем исходные. Есть смысл попробовать обучение с ними и без них (как и многое другое в машинном обучении, это можно выяснить экспериментально). Для этого создадим копию датафреймов и добавим туда новые фичи.
В расчетах нужно отталкиваться от какого-то базового уровня модели, ниже которого упасть уже нельзя. В нашем случае это могло бы быть 0,5 для всех тестовых клиентов — это показывает, что мы совершенно не представляем, вернет кредит клиент или нет. В нашем случае предварительная работа уже проведена и можно использовать более сложные модели.
Для расчета логистической регрессии нам нужно взять таблицы с закодированными категориальными признаками, заполнить недостающие данные и нормализовать их (привести к значениям от 0 до 1). Все это выполняет следующий код:
Используем логистическую регрессию из Scikit-Learn как первую модель. Возьмем дефольную модель с одной поправкой — понизим параметр регуляризации C во избежание оверфиттинга. Синтаксис обычный — создаем модель, тренируем ее и пресказываем вероятность при помощи predict_proba (нам же нужна вероятность, а не 0/1)
Теперь можно создать файл для загрузки на Kaggle. Создадим датафрейм из ID клиентов и вероятности невозврата и выгрузим его.
Итак, результат нашего титанического труда: 0.673, при лучшем результате на сегодня 0,802.
Логрег показывает себя не очень хорошо, попробуем использовать улучшенную модель — случайный лес. Это гораздо более мощная модель, которая может строить сотни деревьев и выдавать куда более точный результат. Используем 100 деревьев. Схема работы с моделью все та же, совершенно стандартная — загрузка классификатора, тренировка. предсказание.
результат случайного леса чуть лучше — 0,683
Теперь, когда мы имеем модель. которая делает хоть что-то — самое время потестить наши полиномиальные признаки. Сделаем с ними все то же самое и сравним результат.
результат случайного леса с полиномиальными признаками стал хуже — 0,633. Что сильно ставит под вопрос необходимость их использования.
Градиентный бустинг — «серьёзная модель» для машинного обучения. Практически все последние состязания «затаскиваются» именно. Построим простую модель и проверим её производительность.
Результат LightGBM — 0,735, что сильно оставляет позади все остальные модели
Самый простой метод интерпретации модели — посмотреть на важность признаков (что могут делать далеко не все модели). Так как наш классификатор обрабатывал массив, потребуется провести некоторую работу, чтобы заново поставить названия столбцов в соответствии с колонками этого массива.
Как и следовало ожидать, наиболее важны для модели все те же 4 признака. Важность признаков — не самый лучший метод интерпретации модели, но он позволяет понять основные факторы, которые модель использует для предсказаний
Теперь рассмотрим внимательно дополнительные таблицы и что с ними можно сделать. Сразу начнем готовить таблицы для дальнейшего обучения. Но для начала удалим из памяти прошлые объемные таблицы, очистим память при помощи сборщика мусора и импортируем необходимые для дальнейшего анализа библиотеки.
Импортируем данные, сразу уберем целевой столбец в отдельную колонку
Сразу же закодируем категориальные признаки. Ранее мы это уже делали, при этом мы кодировали тренировочную и тестовую выборки по отдельности, а затем выравнивали данные. Попробуем немного другой подход — найдем все эти категориальные признаки, объединим датафреймы, закодируем по списку найденных, а потом снова разделим выборки на тренировочную и тестовую.
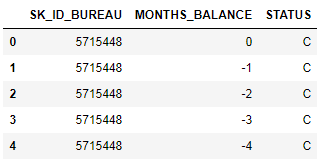
MONTHS_BALANCE — количество месяцев до даты подачи заявки на кредит. Взглянем подробнее на «статусы»
Статусы означают следующее:
С — closed, то есть погашенный кредит. X — неизвестный статус. 0 — текущий кредит, отсутствие просрочек. 1 — просрочка 1-30 дней, 2 — просрочка 31-60 дней и так далее до статуса 5 — кредит продан третьей стороне или списан.
Отсюда можно выделить например следующие признаки: buro_grouped_size — количество записей в базе buro_grouped_max — максимальный баланс по кредиту buro_grouped_min — минимальный баланс по кредиту
А также все эти статусы по кредиту можно закодировать (используем метод unstack, а затем присоединим полученные данные к таблице buro, благо что SK_ID_BUREAU там и там совпадает.

(показано первые 7 столбцов)
Довольно много данных, которые, в общем-то, можно попробовать просто закодировать One-Hot-Encoding'ом, сгруппировать по SK_ID_CURR, усреднить и, таки образом, подготовить для объединения с основной таблицей
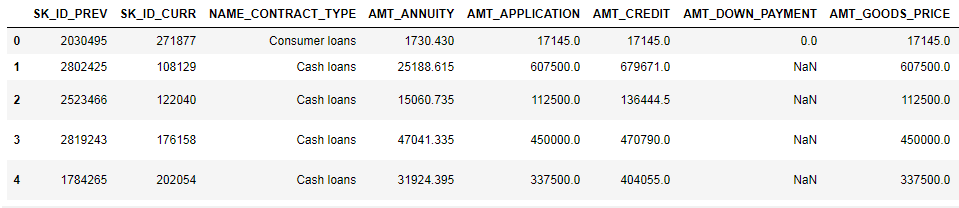
Точно также закодируем категориальные признаки, усредним и объединим по текущему ID.

Закодируем категориальные признаки и подготовим таблицу для объединения

(первые 7 столбцов)
Аналогичная работа

(показано первые 7 столбцов)
Создадим три таблицы — со средними, минимальными и максимальными значениями из этой таблицы.
И, собственно, ударим по этой выросшей в два раза таблице градиентным бустингом!
результат — 0,770.
ОК, напоследок попробуем более сложную методику с разделением на фолды, кросс-валидацией и выбором лучшей итерации.
Финальный скор на kaggle 0,783
Определенно, дальше работать с признаками. Исследовать данные, какие-то из признаков выделять, комбинировать их, по-другому присоединять дополнительные таблицы. Можно экспериментировать с гиперпараметрами можели — направлений много.
Надеюсь, это небольшая компилляция показала вам современные методы исследования данных и подготовки прогнозных моделей. Изучайте датасаенс, участвуйте в соревнованиях, будьте клевыми!
И еще раз ссылки на кернелы, которые помогли мне подготовить эту статью. Статья также размещена в виде ноутбука на Гитхабе, можно скачать её, датасет и запускать и экспериментировать.
Will Koehrsen. Start Here: A Gentle Introduction
sban. HomeCreditRisk: Extensive EDA + Baseline [0.772]
Gabriel Preda. Home Credit Default Risk Extensive EDA
Pavan Raj. Loan repayers v/s Loan defaulters — HOME CREDIT
Lem Lordje Ko. 15 lines: Just EXT_SOURCE_x
Shanth. HOME CREDIT — BUREAU DATA — FEATURE ENGINEERING
Dmitriy Kisil. Good_fun_with_LigthGBM
(картинка отсюда)
 Home Credit Group — группа банков и небанковских кредитных организаций, ведет операции в 11 странах (в том числе в России как ООО «Хоум Кредит энд Финанс Банк»). Цель соревнования — создать методику оценки кредитоспособности заемщиков, не имеющих кредитной истории. Что выглядит довольно благородно — заемщики этой категории часто не могут получить никакой кредит в банке и вынуждены обращаться к мошенникам и микрозаймам. Интересно, что заказчик не выставляет требований по прозрачности и интерпретируемости модели (как это обычно бывает в банках), можно использовать что угодно, хоть нейросети.
Home Credit Group — группа банков и небанковских кредитных организаций, ведет операции в 11 странах (в том числе в России как ООО «Хоум Кредит энд Финанс Банк»). Цель соревнования — создать методику оценки кредитоспособности заемщиков, не имеющих кредитной истории. Что выглядит довольно благородно — заемщики этой категории часто не могут получить никакой кредит в банке и вынуждены обращаться к мошенникам и микрозаймам. Интересно, что заказчик не выставляет требований по прозрачности и интерпретируемости модели (как это обычно бывает в банках), можно использовать что угодно, хоть нейросети.Обучающая выборка состоит из 300+ тыс. записей, признаков достаточно много — 122, среди них много категориальных (не числовых). Признаки довольно подробно описывают заемщика, вплоть до материала, из которого сделаны стены его жилища. Часть данных содержатся в 6 дополнительных таблицах (данные по кредитному бюро, балансу кредитной карты и предыдущим кредитам), эти данные нужно тоже как-то обработать и подгрузить к основным.
Соревнование выглядит как стандартная задача классификации (1 в поле TARGET означает любые сложности с платежами, 0 — отсутствие сложностей). Однако следует предсказывать не 0/1, а вероятность возникновения проблем (что, впрочем, довольно легко решают методы предсказания вероятностей predict_proba, которые есть у всех сложных моделей).
На первый взгляд датасет довольно стандартной для задач машинного обучения, организаторы предложили крупный приз в $70к, в итоге в соревновании на сегодня участвует уже больше 2600 команд, а битва идет за тысячные доли процентов. Однако, с другой стороны, такая популярность означает, что датасет исследован вдоль и поперек и создано много кернелов с хорошими EDA (Exploratory Data Analisys — исследование и анализ данных в сете, в том числе графический), Feature engineering'ом (работа с признаками) и с интересными моделями. (Кернел — это пример работы с датасетом, который может выложить любой желающий, чтобы показать свою работу другим кагглерам.)
Заслуживают внимания кернелы:
- EDA с подробным описанием для новичков и простые модели
- Глубокий EDA с пакетом Plotly + подгрузка данных бюро
- Хороший EDA с пакетом Seaborn
- Сравнительный анализ проблемных и дефолтных заемщиков
- 15-ти строчный LightGBM на трех признаках с итоговым скором 0,714
- Анализ признаков по данным кредитных бюро
- Обработка доп. таблиц + LightGBM
Для работы с данными обычно рекомендуется следующий план, которому мы и постараемся следовать.
- Понимание проблемы и ознакомление с данными
- Чистка данных и форматирование
- EDA
- Базовая модель
- Улучшение модели
- Интерпретация модели
В данном случае нужно взять поправку на то, что данные довольно обширны и сразу их можно и не осилить, есть смысл действовать поэтапно.
Начнем с импорта библиотек, которые нам понадобятся в анализе для работы с данными в виде таблиц, построения графиков и для работы с матрицами.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
%matplotlib inlineЗагрузим данные. Посмотрим, что у нас вообще есть. Такое расположение в каталоге "../input/", кстати, связано с требованием по размещению своих кернелов на Kaggle.
import os
PATH="../input/"
print(os.listdir(PATH))['application_test.csv', 'application_train.csv', 'bureau.csv', 'bureau_balance.csv', 'credit_card_balance.csv', 'HomeCredit_columns_description.csv', 'installments_payments.csv', 'POS_CASH_balance.csv', 'previous_application.csv']Есть 8 таблиц с данными (не считая таблицы HomeCredit_columns_description.csv, в которой содержится описание полей), которые связаны между собой следующим образом:
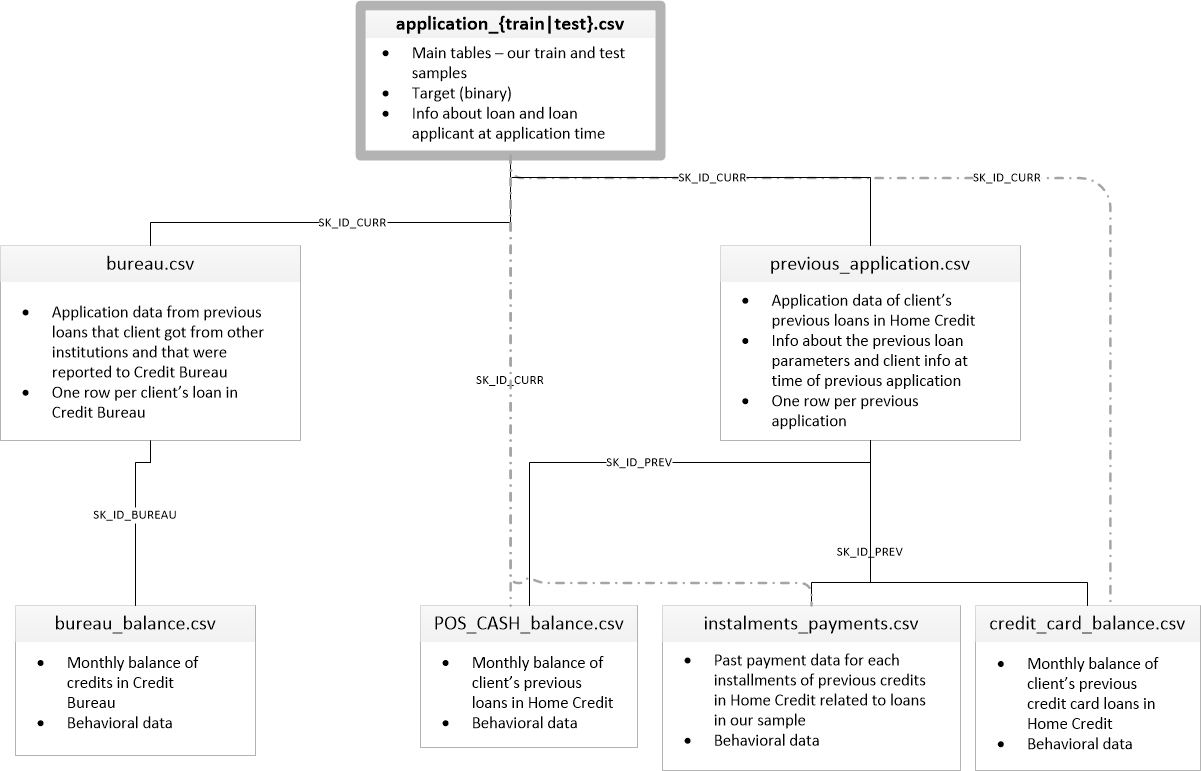
application_train/application_test: Основные данные, заемщик идентифицируется по полю SK_ID_CURR
bureau: Данные по предыдущим займам в других кредитных организациях из кредитного бюро
bureau_balance: Ежемесячные данные по предыдущим кредитам по бюро. Каждая строка — месяц испльзования кредита
previous_application: Предыдущие заявки по кредитам в Home Credit, каждая имеет уникальное поле SK_ID_PREV
POS_CASH_BALANCE: Ежемесячные данные по кредитам в Home Creditс выдачей наличными и кредитам на покупки товаров
credit_card_balance: Ежемесячные данные по балансу кредитных карт в Home Credit
installments_payment: Платежная история предыдущих займов в Home Credit.
Сосредоточимся для начала на основном источнике данных и посмотрим, какую информацию из него можно извлечь и какие модели построить. Загрузим основные данные.
- app_train = pd.read_csv(PATH + 'application_train.csv',)
- app_test = pd.read_csv(PATH + 'application_test.csv',)
- print («формат обучающей выборки:», app_train.shape)
- print («формат тестовой выборки:», app_test.shape)
- формат обучающей выборки: (307511, 122)
- формат тестовой выборки: (48744, 121)
Итого у нас есть 307 тысяч записей и 122 признака в обучающей выборке и 49 тысяч записей и 121 признак в тестовой. Расхождение, очевидно, вызвано тем, что целевого признака TARGET в тестовой выборке нет, его-то мы и будем предсказывать.
Посмотрим на данные внимательнее
pd.set_option('display.max_columns', None) # иначе pandas не покажет все столбцы
app_train.head()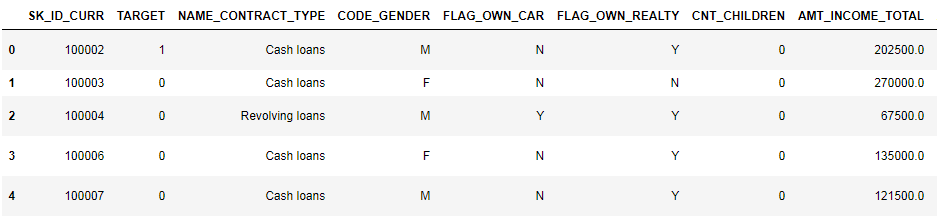
(показано первые 8 столбцов)
Довольно сложно смотреть данные в таком формате. Посмотрим на список столбцов:
app_train.info(max_cols=122)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 entries, 0 to 307510
Data columns (total 122 columns):
SK_ID_CURR 307511 non-null int64
TARGET 307511 non-null int64
NAME_CONTRACT_TYPE 307511 non-null object
CODE_GENDER 307511 non-null object
FLAG_OWN_CAR 307511 non-null object
FLAG_OWN_REALTY 307511 non-null object
CNT_CHILDREN 307511 non-null int64
AMT_INCOME_TOTAL 307511 non-null float64
AMT_CREDIT 307511 non-null float64
AMT_ANNUITY 307499 non-null float64
AMT_GOODS_PRICE 307233 non-null float64
NAME_TYPE_SUITE 306219 non-null object
NAME_INCOME_TYPE 307511 non-null object
NAME_EDUCATION_TYPE 307511 non-null object
NAME_FAMILY_STATUS 307511 non-null object
NAME_HOUSING_TYPE 307511 non-null object
REGION_POPULATION_RELATIVE 307511 non-null float64
DAYS_BIRTH 307511 non-null int64
DAYS_EMPLOYED 307511 non-null int64
DAYS_REGISTRATION 307511 non-null float64
DAYS_ID_PUBLISH 307511 non-null int64
OWN_CAR_AGE 104582 non-null float64
FLAG_MOBIL 307511 non-null int64
FLAG_EMP_PHONE 307511 non-null int64
FLAG_WORK_PHONE 307511 non-null int64
FLAG_CONT_MOBILE 307511 non-null int64
FLAG_PHONE 307511 non-null int64
FLAG_EMAIL 307511 non-null int64
OCCUPATION_TYPE 211120 non-null object
CNT_FAM_MEMBERS 307509 non-null float64
REGION_RATING_CLIENT 307511 non-null int64
REGION_RATING_CLIENT_W_CITY 307511 non-null int64
WEEKDAY_APPR_PROCESS_START 307511 non-null object
HOUR_APPR_PROCESS_START 307511 non-null int64
REG_REGION_NOT_LIVE_REGION 307511 non-null int64
REG_REGION_NOT_WORK_REGION 307511 non-null int64
LIVE_REGION_NOT_WORK_REGION 307511 non-null int64
REG_CITY_NOT_LIVE_CITY 307511 non-null int64
REG_CITY_NOT_WORK_CITY 307511 non-null int64
LIVE_CITY_NOT_WORK_CITY 307511 non-null int64
ORGANIZATION_TYPE 307511 non-null object
EXT_SOURCE_1 134133 non-null float64
EXT_SOURCE_2 306851 non-null float64
EXT_SOURCE_3 246546 non-null float64
APARTMENTS_AVG 151450 non-null float64
BASEMENTAREA_AVG 127568 non-null float64
YEARS_BEGINEXPLUATATION_AVG 157504 non-null float64
YEARS_BUILD_AVG 103023 non-null float64
COMMONAREA_AVG 92646 non-null float64
ELEVATORS_AVG 143620 non-null float64
ENTRANCES_AVG 152683 non-null float64
FLOORSMAX_AVG 154491 non-null float64
FLOORSMIN_AVG 98869 non-null float64
LANDAREA_AVG 124921 non-null float64
LIVINGAPARTMENTS_AVG 97312 non-null float64
LIVINGAREA_AVG 153161 non-null float64
NONLIVINGAPARTMENTS_AVG 93997 non-null float64
NONLIVINGAREA_AVG 137829 non-null float64
APARTMENTS_MODE 151450 non-null float64
BASEMENTAREA_MODE 127568 non-null float64
YEARS_BEGINEXPLUATATION_MODE 157504 non-null float64
YEARS_BUILD_MODE 103023 non-null float64
COMMONAREA_MODE 92646 non-null float64
ELEVATORS_MODE 143620 non-null float64
ENTRANCES_MODE 152683 non-null float64
FLOORSMAX_MODE 154491 non-null float64
FLOORSMIN_MODE 98869 non-null float64
LANDAREA_MODE 124921 non-null float64
LIVINGAPARTMENTS_MODE 97312 non-null float64
LIVINGAREA_MODE 153161 non-null float64
NONLIVINGAPARTMENTS_MODE 93997 non-null float64
NONLIVINGAREA_MODE 137829 non-null float64
APARTMENTS_MEDI 151450 non-null float64
BASEMENTAREA_MEDI 127568 non-null float64
YEARS_BEGINEXPLUATATION_MEDI 157504 non-null float64
YEARS_BUILD_MEDI 103023 non-null float64
COMMONAREA_MEDI 92646 non-null float64
ELEVATORS_MEDI 143620 non-null float64
ENTRANCES_MEDI 152683 non-null float64
FLOORSMAX_MEDI 154491 non-null float64
FLOORSMIN_MEDI 98869 non-null float64
LANDAREA_MEDI 124921 non-null float64
LIVINGAPARTMENTS_MEDI 97312 non-null float64
LIVINGAREA_MEDI 153161 non-null float64
NONLIVINGAPARTMENTS_MEDI 93997 non-null float64
NONLIVINGAREA_MEDI 137829 non-null float64
FONDKAPREMONT_MODE 97216 non-null object
HOUSETYPE_MODE 153214 non-null object
TOTALAREA_MODE 159080 non-null float64
WALLSMATERIAL_MODE 151170 non-null object
EMERGENCYSTATE_MODE 161756 non-null object
OBS_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
OBS_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DAYS_LAST_PHONE_CHANGE 307510 non-null float64
FLAG_DOCUMENT_2 307511 non-null int64
FLAG_DOCUMENT_3 307511 non-null int64
FLAG_DOCUMENT_4 307511 non-null int64
FLAG_DOCUMENT_5 307511 non-null int64
FLAG_DOCUMENT_6 307511 non-null int64
FLAG_DOCUMENT_7 307511 non-null int64
FLAG_DOCUMENT_8 307511 non-null int64
FLAG_DOCUMENT_9 307511 non-null int64
FLAG_DOCUMENT_10 307511 non-null int64
FLAG_DOCUMENT_11 307511 non-null int64
FLAG_DOCUMENT_12 307511 non-null int64
FLAG_DOCUMENT_13 307511 non-null int64
FLAG_DOCUMENT_14 307511 non-null int64
FLAG_DOCUMENT_15 307511 non-null int64
FLAG_DOCUMENT_16 307511 non-null int64
FLAG_DOCUMENT_17 307511 non-null int64
FLAG_DOCUMENT_18 307511 non-null int64
FLAG_DOCUMENT_19 307511 non-null int64
FLAG_DOCUMENT_20 307511 non-null int64
FLAG_DOCUMENT_21 307511 non-null int64
AMT_REQ_CREDIT_BUREAU_HOUR 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_DAY 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_WEEK 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_MON 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_QRT 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_YEAR 265992 non-null float64
dtypes: float64(65), int64(41), object(16)
memory usage: 286.2+ MBНапомню, подробные аннотации по полям — в файле HomeCredit_columns_description. Как видно из info, часть данных неполная и часть — категориальная, они отображаются как object. Большинство моделей с такими данными не работают, нам придется что-то с этим делать. На этом начальный анализ можно считать законченным, перейдем непосредственно к EDA
Exploratory Data Analysis или первичное исследование данных
В процессе EDA мы считаем основные статистики и рисуем графики, чтобы найти тренды, аномалии, паттерны и связи внутри данных. Цель EDA — узнать, что могут рассказать данные. Обычно анализ идет сверху вниз — от общего обзора к исследованию отдельных зон, которые привлекают внимание и могут представлять интерес. Впоследствии эти находки можно использовать в построении модели, выборе признаков для нее и в её интерпретации.
Распределение целевой переменной
app_train.TARGET.value_counts()0 282686
1 24825
Name: TARGET, dtype: int64plt.style.use('fivethirtyeight')
plt.rcParams["figure.figsize"] = [8,5]
plt.hist(app_train.TARGET)
plt.show()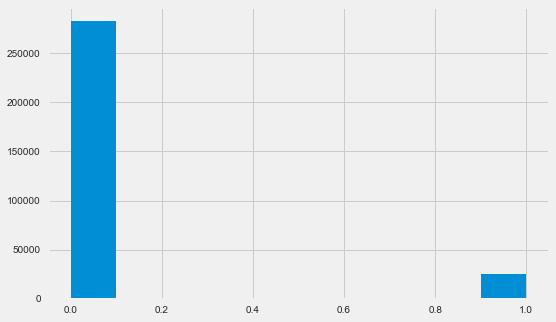
Напомню, 1 означает проблемы любого рода с возвратом, 0 — отсутствие проблем. Как видно, в основном заемщики не имеют проблем с возвратом, доля проблемных около 8%. Это значит, что классы не сбалансированы и это, возможно, нужно будет учитывать при построении модели.
Исследование недостающих данных
Мы видели, что нехватка данных довольно существенна. Посмотрим более подробно, где и чего недостает.
# Функция для подсчета недостающих столбцов
def missing_values_table(df):
# Всего недостает
mis_val = df.isnull().sum()
# Процент недостающих данных
mis_val_percent = 100 * df.isnull().sum() / len(df)
# Таблица с результатами
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)
# Переименование столбцов
mis_val_table_ren_columns = mis_val_table.rename(
columns = {0 : 'Missing Values', 1 : '% of Total Values'})
# Сортировка про процентажу
mis_val_table_ren_columns = mis_val_table_ren_columns[
mis_val_table_ren_columns.iloc[:,1] != 0].sort_values(
'% of Total Values', ascending=False).round(1)
# Инфо
print ("В выбранном датафрейме " + str(df.shape[1]) + " столбцов.\n"
"Всего " + str(mis_val_table_ren_columns.shape[0]) +
" столбцов с неполными данными.")
# Возврат таблицы с данными
return mis_val_table_ren_columns
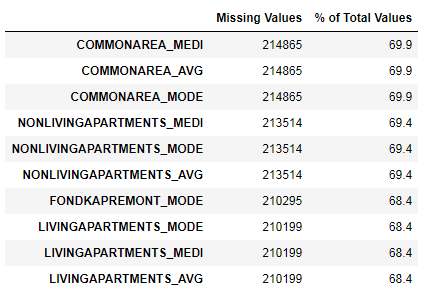
missing_values = missing_values_table(app_train)
missing_values.head(10)В выбранном датафрейме 122 столбцов.
Всего 67 столбцов с неполными данными.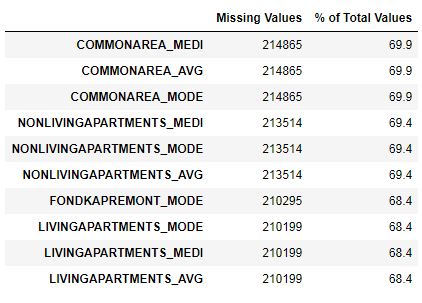
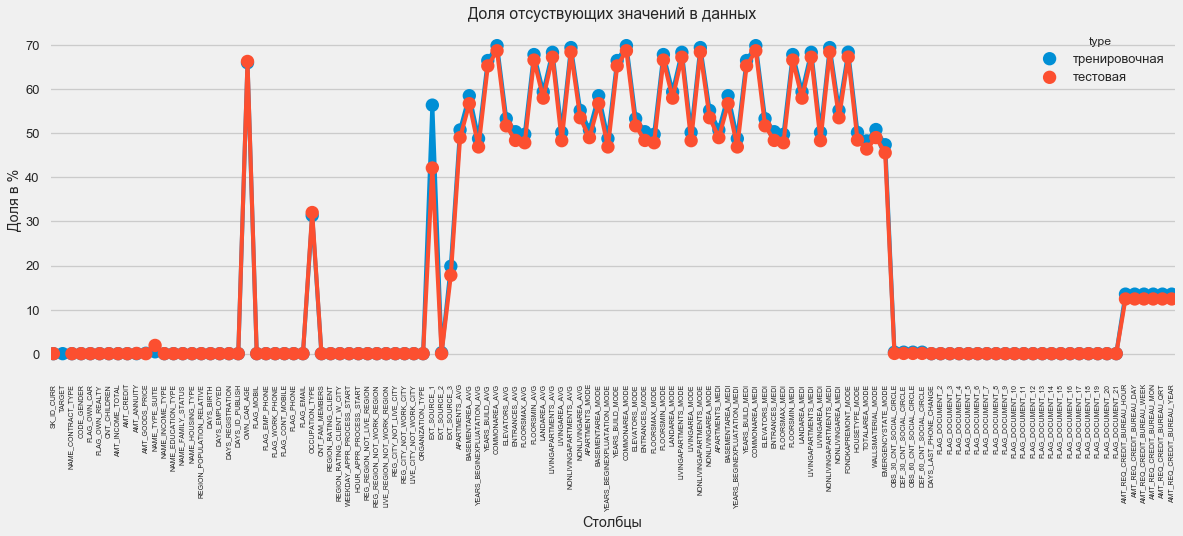
В графическом формате:
plt.style.use('seaborn-talk')
fig = plt.figure(figsize=(18,6))
miss_train = pd.DataFrame((app_train.isnull().sum())*100/app_train.shape[0]).reset_index()
miss_test = pd.DataFrame((app_test.isnull().sum())*100/app_test.shape[0]).reset_index()
miss_train["type"] = "тренировочная"
miss_test["type"] = "тестовая"
missing = pd.concat([miss_train,miss_test],axis=0)
ax = sns.pointplot("index",0,data=missing,hue="type")
plt.xticks(rotation =90,fontsize =7)
plt.title("Доля отсуствующих значений в данных")
plt.ylabel("Доля в %")
plt.xlabel("Столбцы")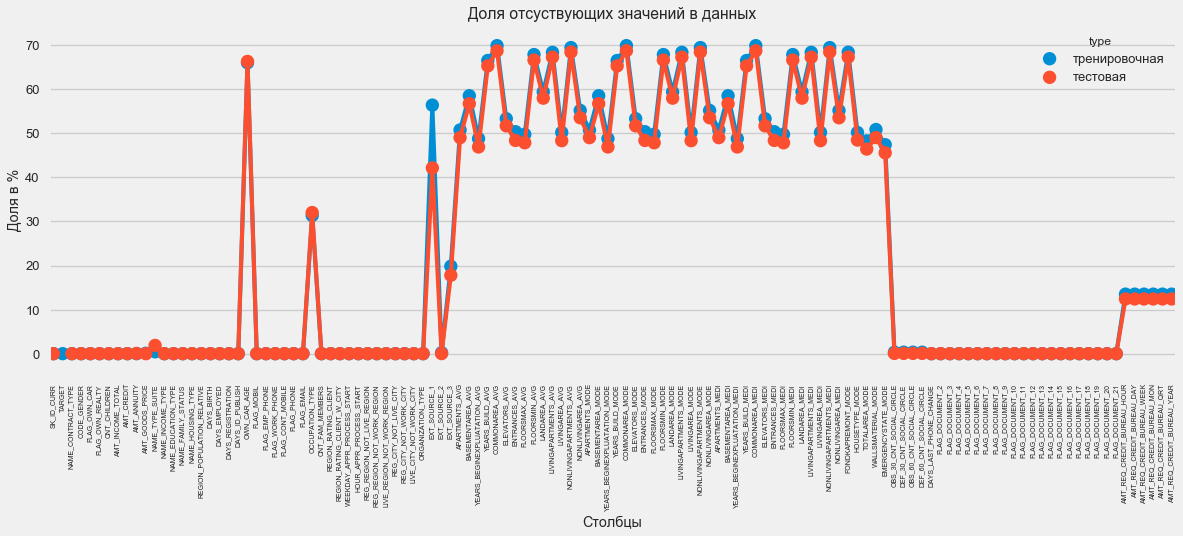
На вопрос «что со всем этим делать» есть много ответов. Можно заполнить нулями, можно медианными значениями, можно просто удалить строки без нужной информации. Все зависит от модели, которую мы планируем использовать, так как некоторые совершенно отлично справляются с отсутствующими значениями. Пока запомним этот факт и оставим все как есть.
Типы столбцов и кодирование категориальных данных
Как мы помним. часть столбцов имеет тип object, то есть имеет не числовое значение, а отражает какую-то категорию. Посмотрим на эти столбцы более внимательно.
app_train.dtypes.value_counts()float64 65
int64 41
object 16
dtype: int64app_train.select_dtypes(include=[object]).apply(pd.Series.nunique, axis = 0)NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
dtype: int64У нас есть 16 столбцов, в каждом из которых от 2 до 58 разных вариантов значений. В основном модели машинного обучения не могут ничего сделать с таким столбцами (кроме некоторых, например LightGBM или CatBoost). Так как мы планируем опробовать разные модели на датасете, то с этим надо что-то делать. Подходов здесь в основном два:
- Label Encoding — категориям присваиваются цифры 0, 1, 2 и так далее и записываются в тот же столбец
- One-Hot-encoding — один столбец раскладывается на несколько по количеству вариантов и в этих столбцах отмечается, какой вариант у данной записи.
Из популярных также стоит отметить mean target encoding (за уточнение спасибо roryorangepants).
С Label Encoding есть небольшая проблема — он присваивает числовые значения, которые не имеют ничего общего с реальностью. Например, если мы имеем дело с числовым значением, то доход заемщика в 100000 однозначно больше и лучше, чем доход в 20000. Но можно ли сказать, что, например, один город лучше другого потому, что одному присвоено значение 100, а другому — 200?
One-Hot-encoding, с другой стороны, более безопасен, но может плодить «лишние» столбцы. Например, если мы закодируем тот же пол при помощи One-Hot, у нас получится два столбца, «пол мужской» и «пол женский», хотя хватило бы и одного, «мужчина ли это».
По хорошему для данного датасета надо бы кодировать признаки с низкой вариативностью при помощи Label Encoding, а все остальное — One-Hot, но для упрощения закодируем все по One-Hot. На скорость вычисления и результат это практически не повлияет. Сам процесс кодирования pandas делает очень просто
app_train = pd.get_dummies(app_train)
app_test = pd.get_dummies(app_test)
print('Training Features shape: ', app_train.shape)
print('Testing Features shape: ', app_test.shape)Training Features shape: (307511, 246)
Testing Features shape: (48744, 242)Так как количество вариантов в столбцах выборок не равное, количество столбцов теперь не совпадает. Требуется выравнивание — нужно убрать из тренировочной выборки столбцы, которых нет в тестовой. Это делает метод align, нужно указать axis=1 (для столбцов).
#сохраним лейблы, их же нет в тестовой выборке и при выравнивании они потеряются.
train_labels = app_train['TARGET']
# Выравнивание - сохранятся только столбцы. имеющиеся в обоих датафреймах
app_train, app_test = app_train.align(app_test, join = 'inner', axis = 1)
print('Формат тренировочной выборки: ', app_train.shape)
print('Формат тестовой выборки: ', app_test.shape)
# Add target back in to the data
app_train['TARGET'] = train_labelsФормат тренировочной выборки: (307511, 242)
Формат тестовой выборки: (48744, 242)Корреляция в данных
Хороший метод понять данные — рассчитать коэффициенты корреляции Пирсона для данных относительно целевого признака. Это не лучший метод показать релевантность признаков, но он прост и позволяет составить представление о данных. Интерпретировать коэффициенты можно следующим образом:
- 00-.19 “очень слабая”
- 20-.39 “слабая”
- 40-.59 “средняя”
- 60-.79 “сильная”
- 80-1.0 “очень сильная”
# Корреляция и сортировка
correlations = app_train.corr()['TARGET'].sort_values()
# Отображение
print('Наивысшая позитивная корреляция: \n', correlations.tail(15))
print('\nНаивысшая негативная корреляция: \n', correlations.head(15))Наивысшая позитивная корреляция:
DAYS_REGISTRATION 0.041975
OCCUPATION_TYPE_Laborers 0.043019
FLAG_DOCUMENT_3 0.044346
REG_CITY_NOT_LIVE_CITY 0.044395
FLAG_EMP_PHONE 0.045982
NAME_EDUCATION_TYPE_Secondary / secondary special 0.049824
REG_CITY_NOT_WORK_CITY 0.050994
DAYS_ID_PUBLISH 0.051457
CODE_GENDER_M 0.054713
DAYS_LAST_PHONE_CHANGE 0.055218
NAME_INCOME_TYPE_Working 0.057481
REGION_RATING_CLIENT 0.058899
REGION_RATING_CLIENT_W_CITY 0.060893
DAYS_BIRTH 0.078239
TARGET 1.000000
Name: TARGET, dtype: float64
Наивысшая негативная корреляция:
EXT_SOURCE_3 -0.178919
EXT_SOURCE_2 -0.160472
EXT_SOURCE_1 -0.155317
NAME_EDUCATION_TYPE_Higher education -0.056593
CODE_GENDER_F -0.054704
NAME_INCOME_TYPE_Pensioner -0.046209
ORGANIZATION_TYPE_XNA -0.045987
DAYS_EMPLOYED -0.044932
FLOORSMAX_AVG -0.044003
FLOORSMAX_MEDI -0.043768
FLOORSMAX_MODE -0.043226
EMERGENCYSTATE_MODE_No -0.042201
HOUSETYPE_MODE_block of flats -0.040594
AMT_GOODS_PRICE -0.039645
REGION_POPULATION_RELATIVE -0.037227
Name: TARGET, dtype: float64Таким образом, все данные слабо коррелируют с таргетом (кроме самого таргета, который, понятно, равен сам себе). Однако из данных выделяются возраст и некие «внешние источники данных». Вероятно, это некие дополнительные данные из других кредитных организаций. Забавно, что хотя цель декларируется как независимость от подобных данных в принятии кредитного решения, на деле мы будем основываться в первую очередь на них.
Возраст
Понятно, что чем старше клиент, тем выше вероятность возврата (до определенного предела, конечно). Но возраст почему-то указан в отрицательных днях до выдачи кредита, поэтому он положительно коррелирует с невозвратом (что выглядит несколько странно). Приведем его к положительному значению и посмотрим на корреляцию.
app_train['DAYS_BIRTH'] = abs(app_train['DAYS_BIRTH'])
app_train['DAYS_BIRTH'].corr(app_train['TARGET'])-0.078239308309827088Посмотрим на переменную внимательнее. Начнем с гистограммы.
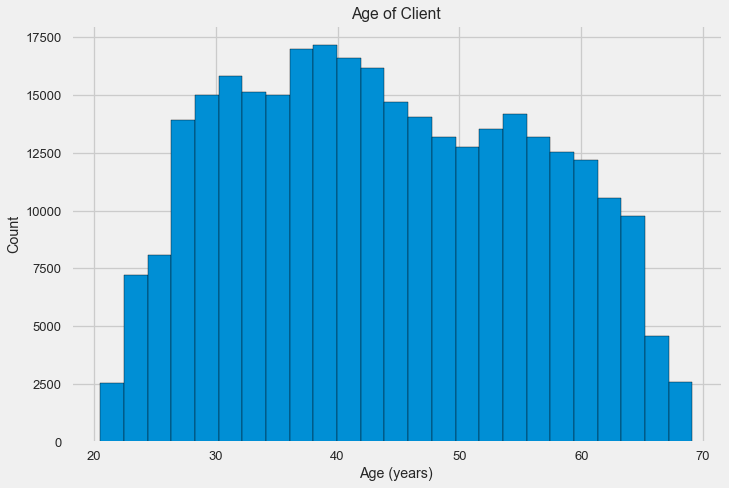
# Гистограмма распределения возраста в годах, всего 25 столбцов
plt.hist(app_train['DAYS_BIRTH'] / 365, edgecolor = 'k', bins = 25)
plt.title('Age of Client'); plt.xlabel('Age (years)'); plt.ylabel('Count');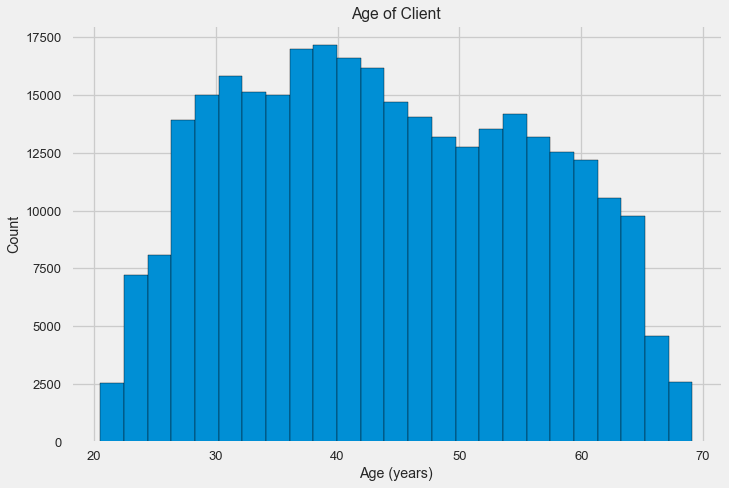
Сама по себе гистограмма распределения может сказать немного полезного, кроме того что мы не видим особых выбросов и все выглядит более-менее правдоподобно. Чтобы показать эффект влияния возраста на результат, можно построить график kernel density estimation (KDE) — распределение ядерной плотности, раскрашенный в цвета целевого признака. Он показывает распределение одной переменной и может быть истолкован как сглаженная гистограмма (рассчитывается как Гауссианское ядро по каждой точке, которое затем усредняется для сглаживания).
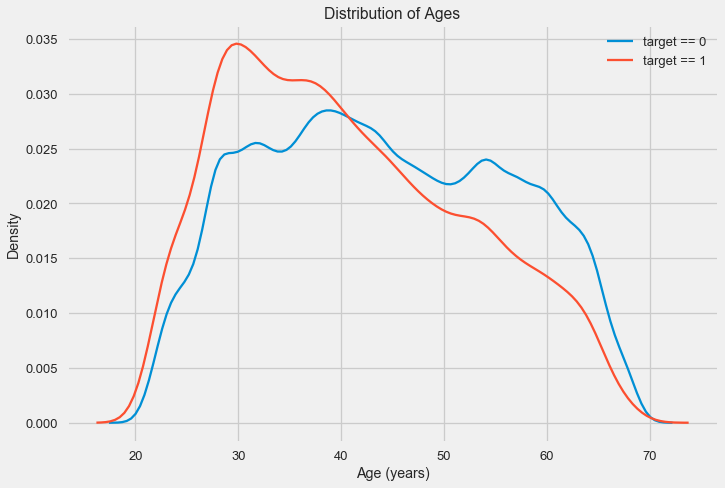
# KDE займов, выплаченных вовремя
sns.kdeplot(app_train.loc[app_train['TARGET'] == 0, 'DAYS_BIRTH'] / 365, label = 'target == 0')
# KDE проблемных займов
sns.kdeplot(app_train.loc[app_train['TARGET'] == 1, 'DAYS_BIRTH'] / 365, label = 'target == 1')
# Обозначения
plt.xlabel('Age (years)'); plt.ylabel('Density'); plt.title('Distribution of Ages');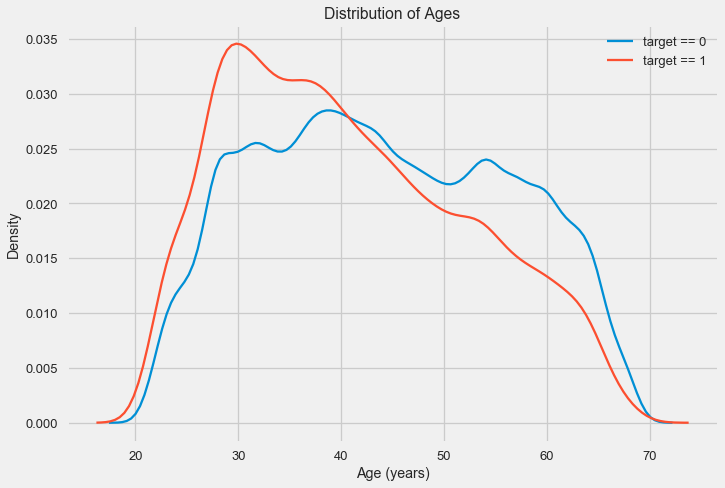
Как видно, доля невозвратов выше для молодых людей и снижается с ростом возраста. Это не повод отказывать молодым людям в кредите всегда, такая «рекомендация» приведет лишь к потере доходов и рынка для банка. Это повод задуматься о более тщательном отслеживании таких кредитов, оценке и, возможно, даже каком-то финансовом образовании для молодых заемщиков.
Внешние источники
Посмотрим внимательнее на «внешние источники данных» EXT_SOURCE и их корреляцию.
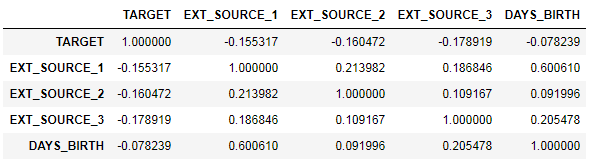
ext_data = app_train[['TARGET', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']]
ext_data_corrs = ext_data.corr()
ext_data_corrs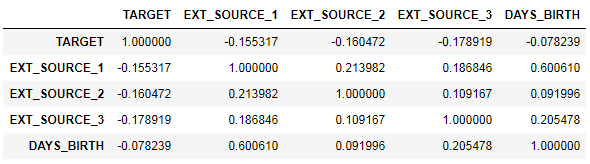
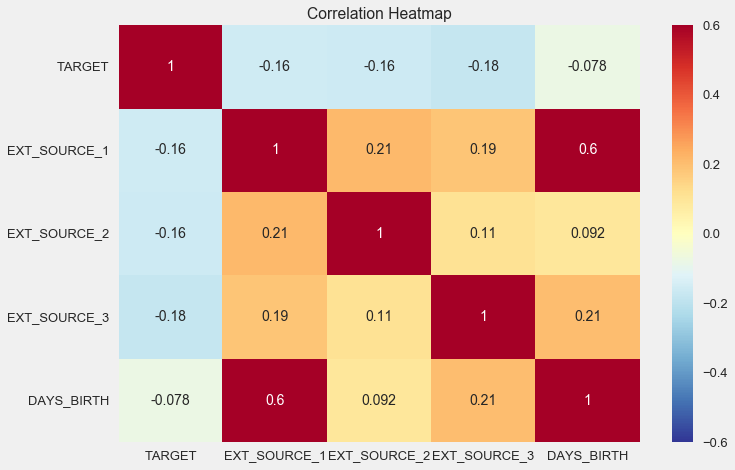
Также корреляцию удобно отображать при помощи heatmap
sns.heatmap(ext_data_corrs, cmap = plt.cm.RdYlBu_r, vmin = -0.25, annot = True, vmax = 0.6)
plt.title('Correlation Heatmap');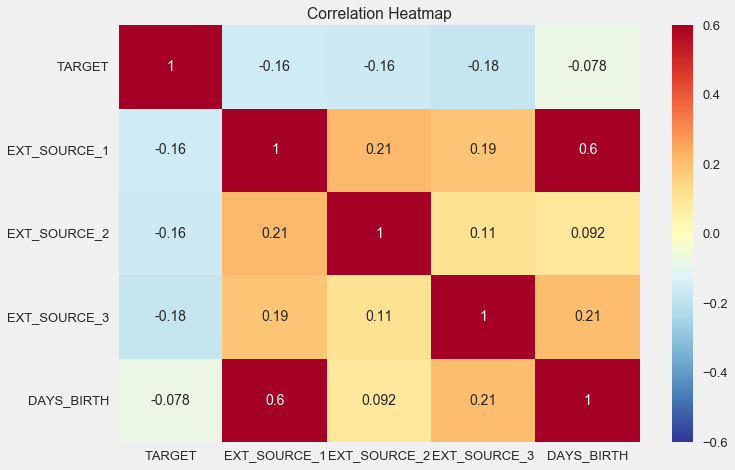
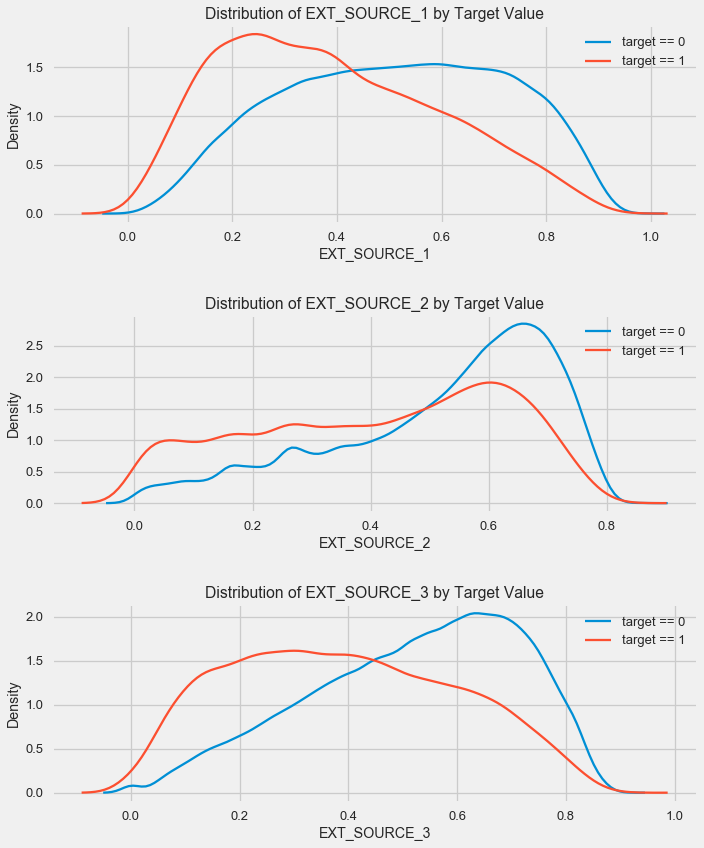
Как видно, все источники показывают негативную корреляцию с таргетом. Посмотрим на рапсределение KDE по каждому источнику.
plt.figure(figsize = (10, 12))
# итерация по источникам
for i, source in enumerate(['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']):
# сабплот
plt.subplot(3, 1, i + 1)
# отрисовка качественных займов
sns.kdeplot(app_train.loc[app_train['TARGET'] == 0, source], label = 'target == 0')
# отрисовка дефолтных займов
sns.kdeplot(app_train.loc[app_train['TARGET'] == 1, source], label = 'target == 1')
# метки
plt.title('Distribution of %s by Target Value' % source)
plt.xlabel('%s' % source); plt.ylabel('Density');
plt.tight_layout(h_pad = 2.5)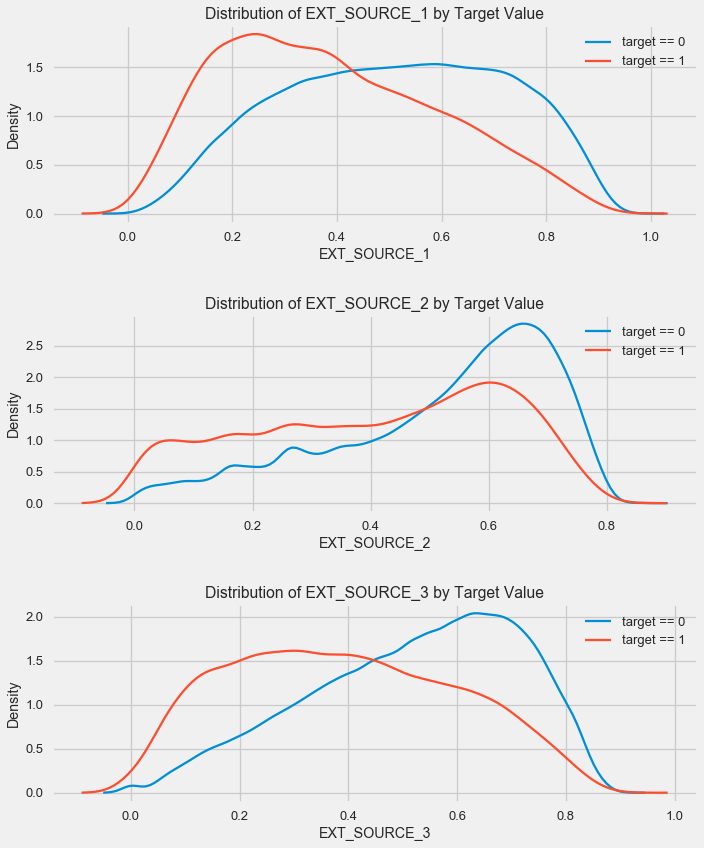
Картина аналогична распределению по возрасту — с ростом показателя растет вероятность возврата кредита. Третий источник наиболее силен в этом плане. Хотя в абсолютном выражении корреляция с целевой переменной все еще в категории «очень низкая», источники внешних данных и возраст будут иметь наивысшее значение в построении модели.
Парный график
Для лучшего понимания взаимоотношений этих переменных можно построить парный график, в нем мы сможем увидеть взаимоотношения каждой пары и гистограмму распределения по диагонали. Выше диагонали можно показать диаграмму рассеяния, а ниже — 2d KDE.
#вынесем данные по возрасту в отдельный датафрейм
age_data = app_train[['TARGET', 'DAYS_BIRTH']]
age_data['YEARS_BIRTH'] = age_data['DAYS_BIRTH'] / 365
# копирование данных для графика
plot_data = ext_data.drop(labels = ['DAYS_BIRTH'], axis=1).copy()
# Добавим возраст
plot_data['YEARS_BIRTH'] = age_data['YEARS_BIRTH']
# Уберем все незаполненнные строки и ограничим таблицу в 100 тыс. строк
plot_data = plot_data.dropna().loc[:100000, :]
# Функиця для расчет корреляции
def corr_func(x, y, **kwargs):
r = np.corrcoef(x, y)[0][1]
ax = plt.gca()
ax.annotate("r = {:.2f}".format(r),
xy=(.2, .8), xycoords=ax.transAxes,
size = 20)
# Создание объекта pairgrid object
grid = sns.PairGrid(data = plot_data, size = 3, diag_sharey=False,
hue = 'TARGET',
vars = [x for x in list(plot_data.columns) if x != 'TARGET'])
# Сверху - скаттерплот
grid.map_upper(plt.scatter, alpha = 0.2)
# Диагональ - гистограмма
grid.map_diag(sns.kdeplot)
# Внизу - распределение плотности
grid.map_lower(sns.kdeplot, cmap = plt.cm.OrRd_r);
plt.suptitle('Ext Source and Age Features Pairs Plot', size = 32, y = 1.05);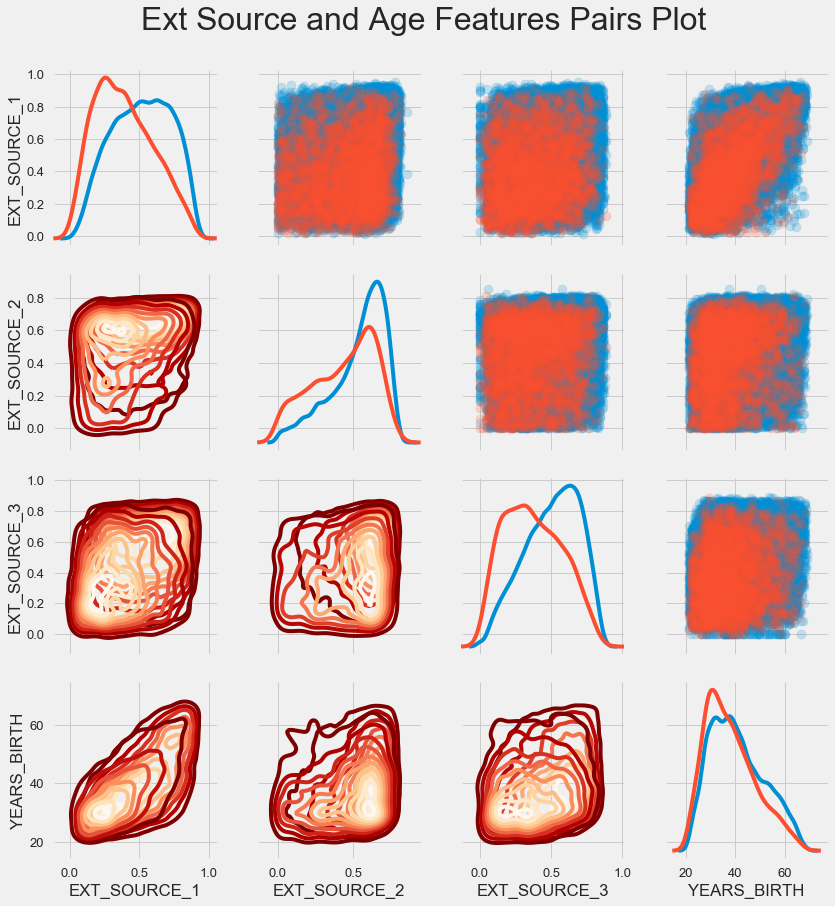
Синим показаны возвратные кредиты, красным — невозвратные. Интерпретировать это все довольно сложно, но зато из этой картинки может выйти неплохой принт на майку или картина в музей современного искусства.
Исследование прочих признаков
Рассмотрим более подробно другие признаки и их зависимость от целевой переменной. Так как среди них много категориальных (а мы уже успели их закодировать), нам снова понадобятся исходные данные. Назовем их немного по-другому во избежание путаницы
application_train = pd.read_csv(PATH+"application_train.csv")
application_test = pd.read_csv(PATH+"application_test.csv")Также нам понадобится пара функций для красивого отображения распределений и их влияния на целевую переменную. Большое за них спасибо автору вот этого кернела
def plot_stats(feature,label_rotation=False,horizontal_layout=True):
temp = application_train[feature].value_counts()
df1 = pd.DataFrame({feature: temp.index,'Количество займов': temp.values})
# Расчет доли target=1 в категории
cat_perc = application_train[[feature, 'TARGET']].groupby([feature],as_index=False).mean()
cat_perc.sort_values(by='TARGET', ascending=False, inplace=True)
if(horizontal_layout):
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12,6))
else:
fig, (ax1, ax2) = plt.subplots(nrows=2, figsize=(12,14))
sns.set_color_codes("pastel")
s = sns.barplot(ax=ax1, x = feature, y="Количество займов",data=df1)
if(label_rotation):
s.set_xticklabels(s.get_xticklabels(),rotation=90)
s = sns.barplot(ax=ax2, x = feature, y='TARGET', order=cat_perc[feature], data=cat_perc)
if(label_rotation):
s.set_xticklabels(s.get_xticklabels(),rotation=90)
plt.ylabel('Доля проблемных', fontsize=10)
plt.tick_params(axis='both', which='major', labelsize=10)
plt.show();Итак, рассмотрим основные признаки колиентов
Тип займа
plot_stats('NAME_CONTRACT_TYPE')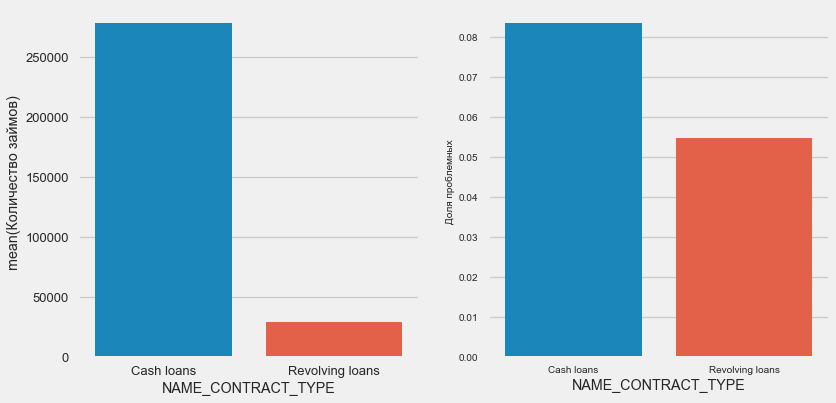
Интересно, что револьверные кредиты (вероятно, овердрафты или что-то вроде того) составляют меньше 10% от общего количества займов. В то же время процент невозврата среди них гораздо выше. Хороший повод пересмотреть методику работы с этими займами, а может быть и отказаться от них вовсе.
Пол клиента
plot_stats('CODE_GENDER')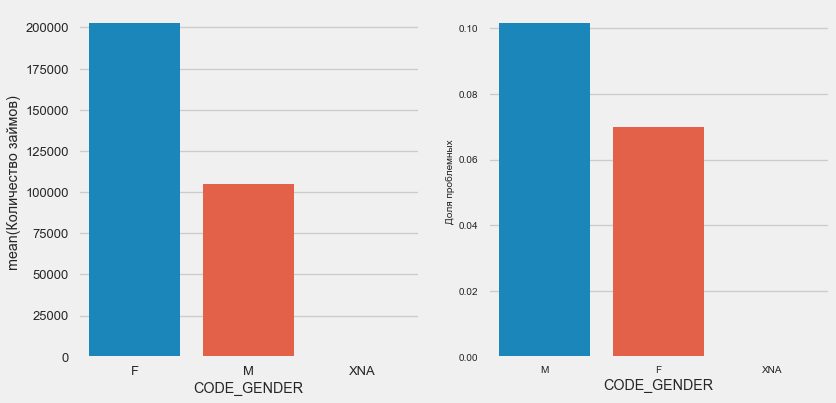
Женщин-клиентов почти вдвое больше мужчин, при этом мужчины показывают гораздо более высокий риск.
Владение машиной и недвижимостью
plot_stats('FLAG_OWN_CAR')
plot_stats('FLAG_OWN_REALTY')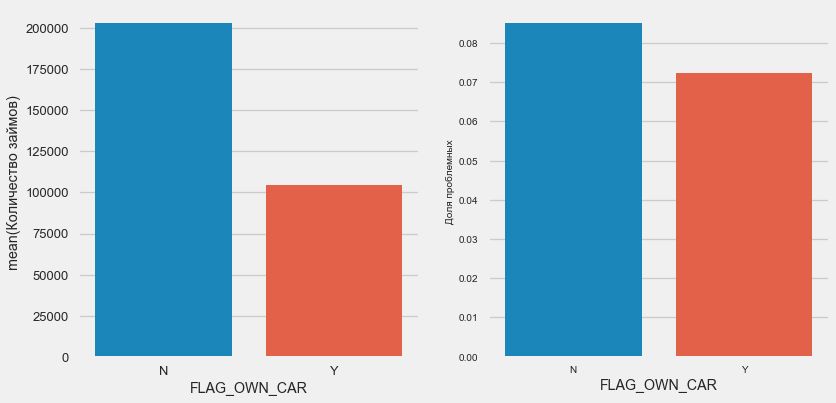
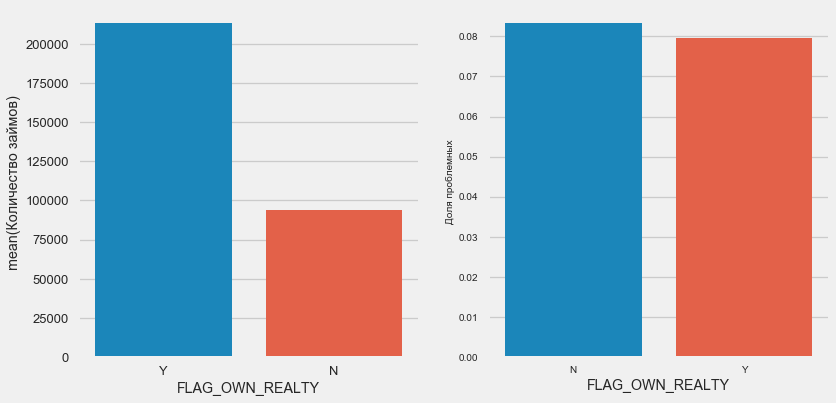
Клиентов с машиной вдвое меньше «безлошадных». Риск по ним практически одинаковый, клиенты с машиной платят чуть лучше.
По недвижимости обратная картина — клиентов без нее вдвое меньше. Риск по владельцам недвижимости также чуть меньше.
Семейный статус
plot_stats('NAME_FAMILY_STATUS',True, True)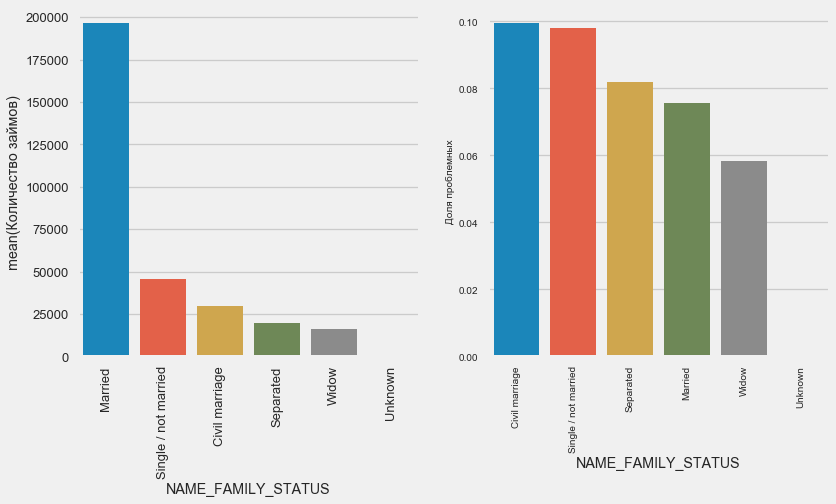
В то время как большинство клиентов состоит в браке, ниаболее рискованы клиенты в гражданском браке и одинокие. Вдовцы показывают минимальный риск.
Количество детей
plot_stats('CNT_CHILDREN')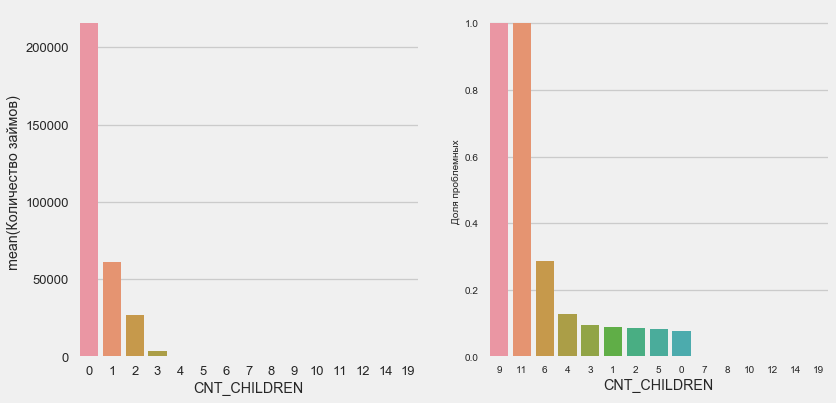
Большинство клиентов бездетны. При этом клиенты с 9 и 11 детьми показывают полный невозврат
application_train.CNT_CHILDREN.value_counts()0 215371
1 61119
2 26749
3 3717
4 429
5 84
6 21
7 7
14 3
19 2
12 2
10 2
9 2
8 2
11 1
Name: CNT_CHILDREN, dtype: int64Как показывает подсчет значений, эти данные статистически незначимы — всего по 1-2 клиента обеих категорий. Однако, все трое вышли в дефолт, равно как и половина клиентов с 6 детьми.
Количество членов семьи
plot_stats('CNT_FAM_MEMBERS',True)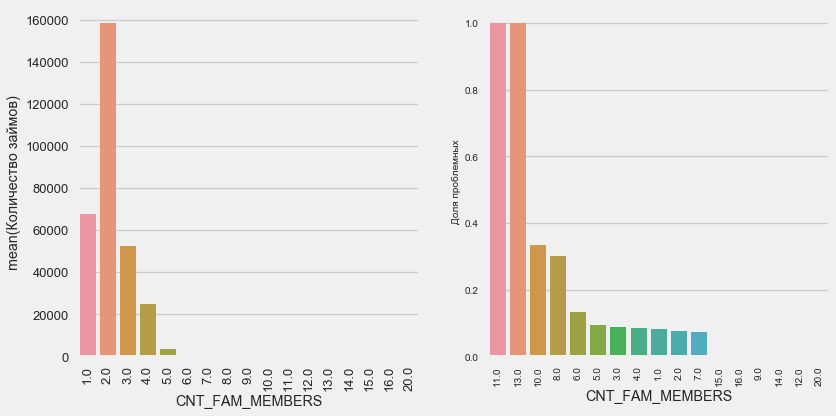
Ситауция аналогична — чем меньше ртов, тем выше возвратность.
Тип дохода
plot_stats('NAME_INCOME_TYPE',False,False)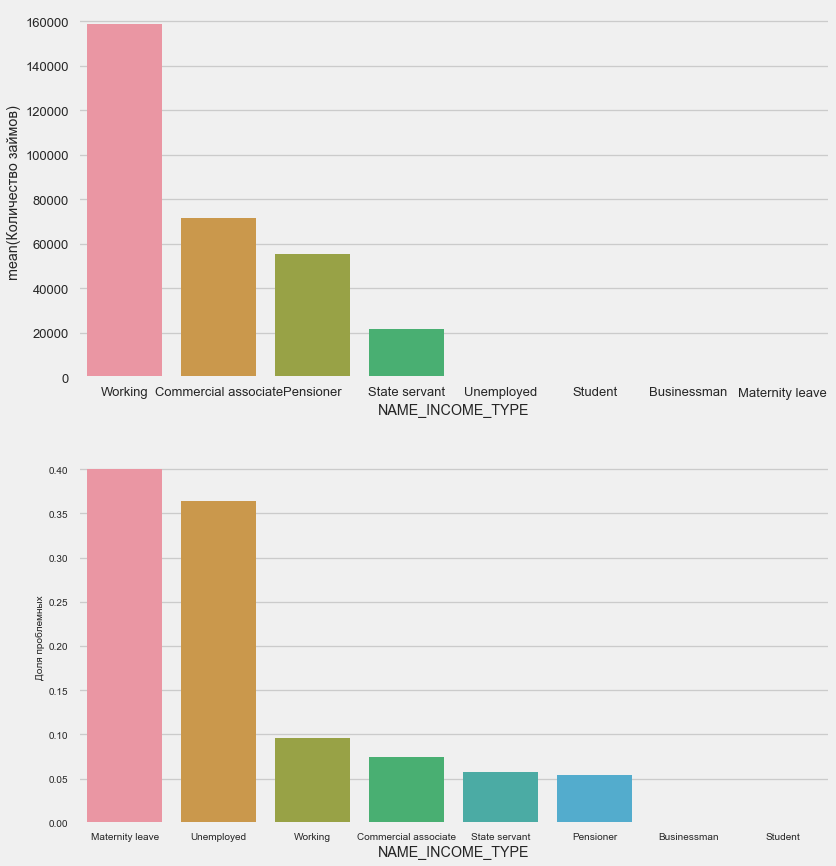
Матери-одиночки и безработные, скорее всего, уже отсекаются на этапе подачи заявки — их слишком мало в выборке. Но стабильно показывают проблемы.
Вид деятельности
plot_stats('OCCUPATION_TYPE',True, False)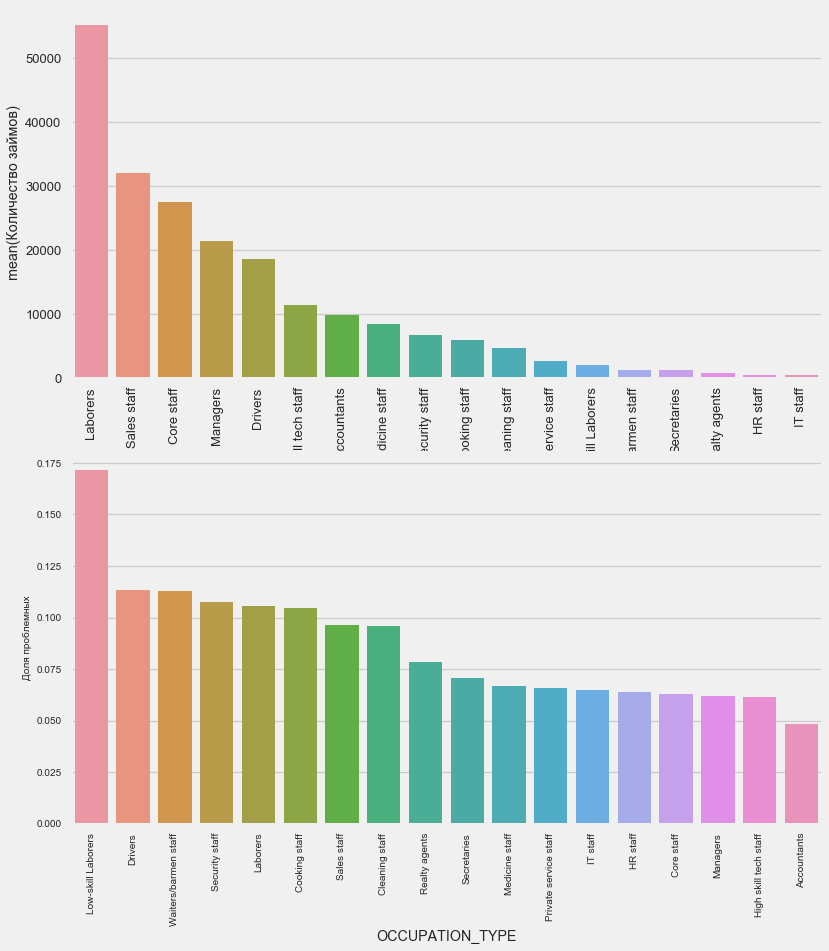
application_train.OCCUPATION_TYPE.value_counts()Laborers 55186
Sales staff 32102
Core staff 27570
Managers 21371
Drivers 18603
High skill tech staff 11380
Accountants 9813
Medicine staff 8537
Security staff 6721
Cooking staff 5946
Cleaning staff 4653
Private service staff 2652
Low-skill Laborers 2093
Waiters/barmen staff 1348
Secretaries 1305
Realty agents 751
HR staff 563
IT staff 526
Name: OCCUPATION_TYPE, dtype: int64Здесь вызывают интерес водители и сотрудники безопасности, которые довольно многочисленны и выходят на проблемы чаще других категорий.
Образование
plot_stats('NAME_EDUCATION_TYPE',True)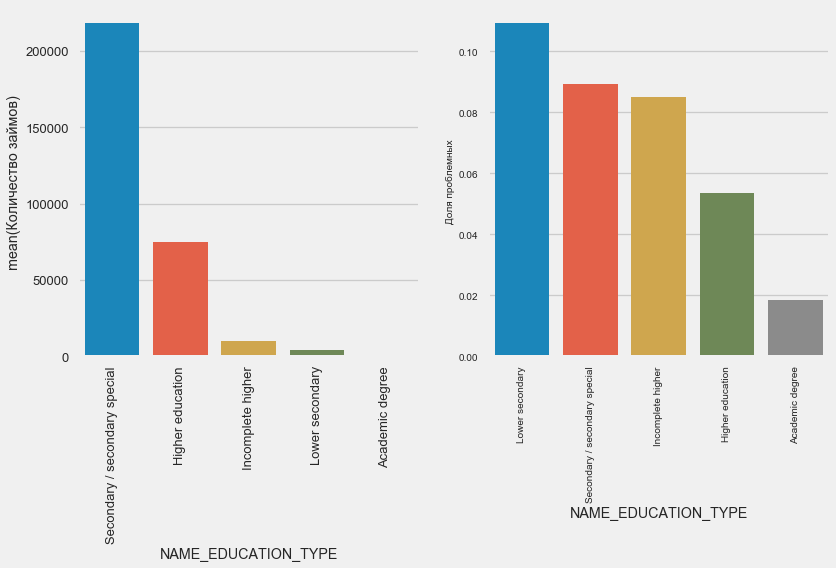
Чем выше образование, тем лучше возвратность, очевидно.
Тип организации — работодателя
plot_stats('ORGANIZATION_TYPE',True, False)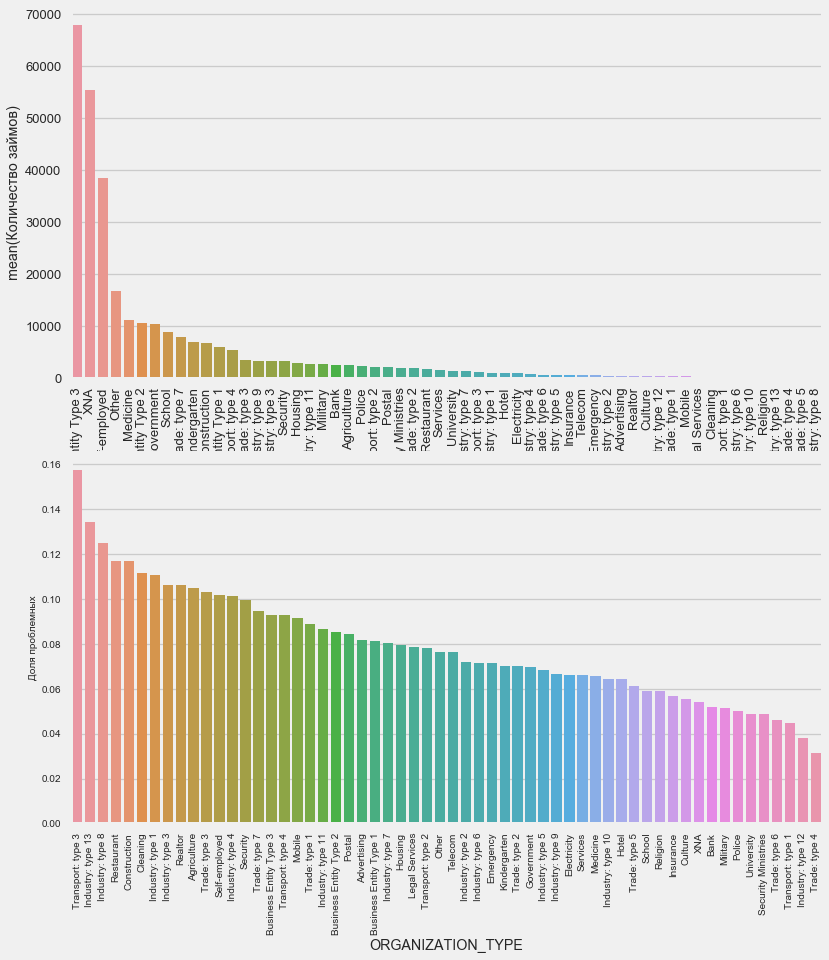
Наивысший процент невозврата наблюдается в Transport: type 3 (16%), Industry: type 13 (13.5%), Industry: type 8 (12.5%) и в Restaurant (до 12%).
Распределение суммы кредитования
Рассмотрим распределение сумм кредитов и влияние их на возвратность
plt.figure(figsize=(12,5))
plt.title("Распределение AMT_CREDIT")
ax = sns.distplot(app_train["AMT_CREDIT"])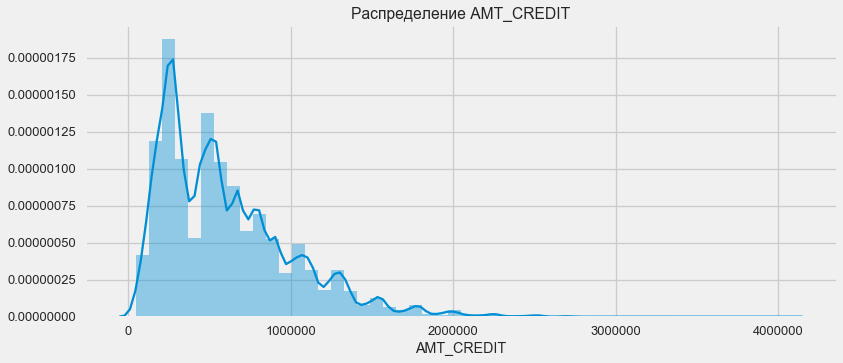
plt.figure(figsize=(12,5))
# KDE займов, выплаченных вовремя
sns.kdeplot(app_train.loc[app_train['TARGET'] == 0, 'AMT_CREDIT'], label = 'target == 0')
# KDE проблемных займов
sns.kdeplot(app_train.loc[app_train['TARGET'] == 1, 'AMT_CREDIT'], label = 'target == 1')
# Обозначения
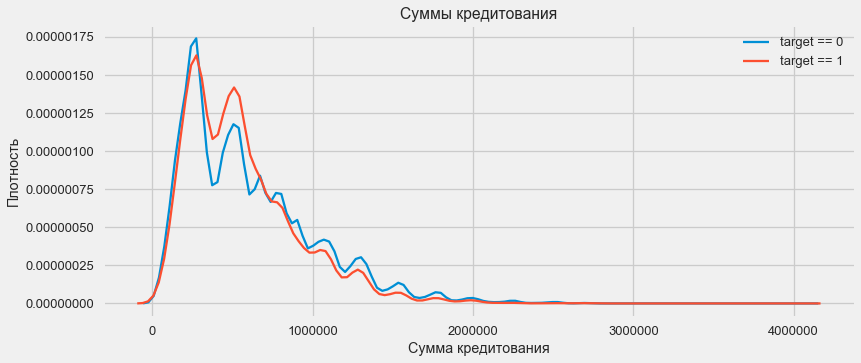
plt.xlabel('Сумма кредитования'); plt.ylabel('Плотность'); plt.title('Суммы кредитования');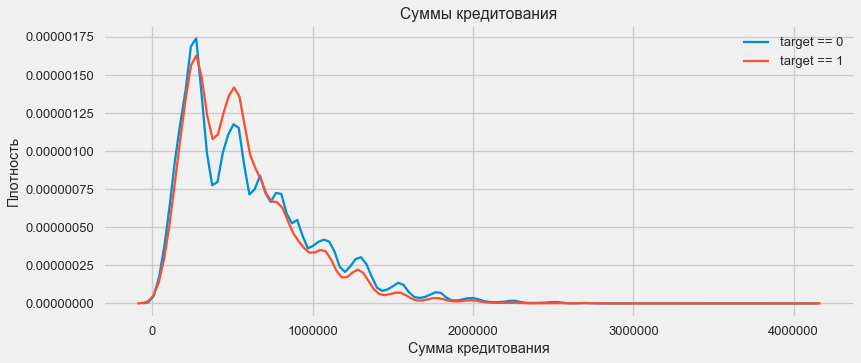
Как показывает график плотности, крепные суммы возвращаются чаще
Распределение по плотности проживания
plt.figure(figsize=(12,5))
plt.title("Распределение REGION_POPULATION_RELATIVE")
ax = sns.distplot(app_train["REGION_POPULATION_RELATIVE"])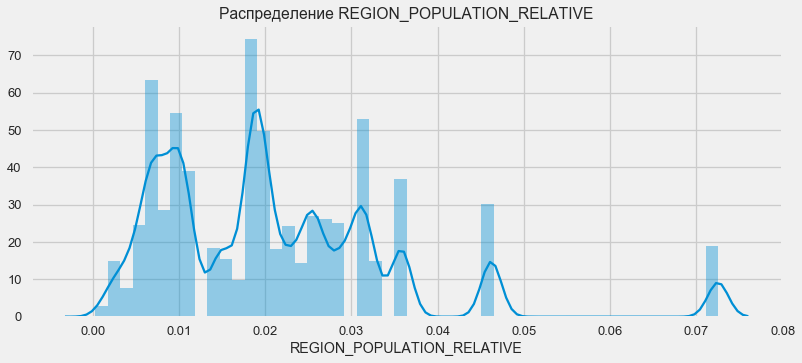
plt.figure(figsize=(12,5))
# KDE займов, выплаченных вовремя
sns.kdeplot(app_train.loc[app_train['TARGET'] == 0, 'REGION_POPULATION_RELATIVE'], label = 'target == 0')
# KDE проблемных займов
sns.kdeplot(app_train.loc[app_train['TARGET'] == 1, 'REGION_POPULATION_RELATIVE'], label = 'target == 1')
# Обозначения
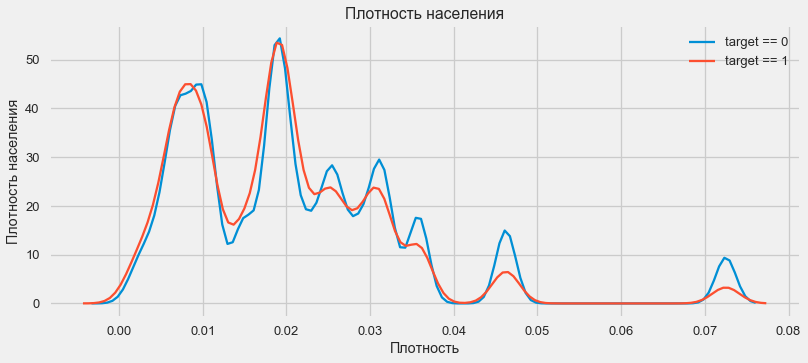
plt.xlabel('Плотность'); plt.ylabel('Плотность населения'); plt.title('Плотность населения');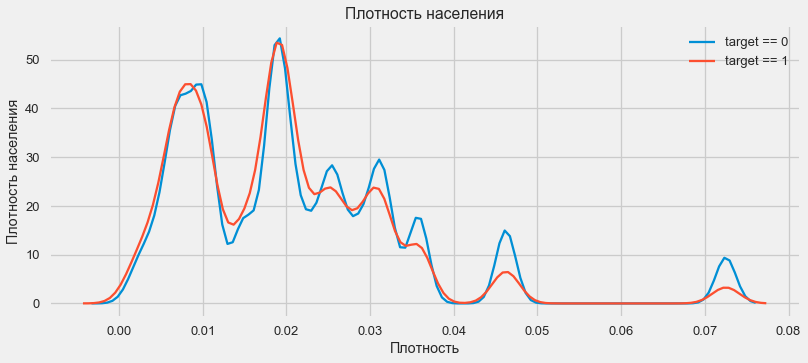
Клиенты из более населенных регионов склонны лучше выплачивать кредит.
Таким образом, мы получили представление об основных признаках датасета и их влиянии на результат. Конкретно с перечисленными в этой статье мы ничего делать не будем, но они могут оказаться очень важными в дальнейшей работе.
Feature Engineering — преобразование признаков
Соревнования на Kaggle выигрываются преобразованием признаков — побеждает тот, кто смог создать самые полезные признаки из данных. По меньшей мере для структурированных данных выигрышные модели — это сейчас в основном разные варианты градиентного бустинга. Чаще всего эффективнее потратить время на преобразование признаков, чем на настройку гиперпараметров или подбор моделей. Модель все-таки может обучиться только по тем данным, которые ей переданы. Убедиться, что данные релевантны задаче — главная ответственность дата саентиста.
Процесс преобразования признаков может включать создание новых из имеющихся данных, выбор наиболее важных из имеющихся и т.д. Опробуем на этот раз полиномиальные признаки.
Полиномиальные признаки
Полиномиальный метод конструирования признаков заключается в то, что мы просто создаем признаки, которые являются степенью имеющихся признаков и их произведениями. В некоторых случаях такие сконструированные признаки могут иметь более сильную корреляцию с целевой переменной, чем их «родители». Хотя такие методы часто используются в статистических моделях, в машинном обучении они встречаются значительно реже. Впрочем. ничего не мешает нам их попробовать, тем более что Scikit-Learn имеет класс специально для этих целей — PolynomialFeatures — который создает полиномиальные признаки и их произведения, нужно указать лишь сами исходные признаки и максимальную степень, в которую их нужно возводить. Используем самые мощные по силе воздействия на результат 4 признака и степень 3, чтобы не слишком сильно усложнять модель и избежать оверфиттинга (перетренированности модели — её излишней подстройки под обучающую выборку).
# создадим новый датафрейм для полиномиальных признаков
poly_features = app_train[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH', 'TARGET']]
poly_features_test = app_test[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']]
# обработаем отуствующие данные
from sklearn.preprocessing import Imputer
imputer = Imputer(strategy = 'median')
poly_target = poly_features['TARGET']
poly_features = poly_features.drop('TARGET', axis=1)
poly_features = imputer.fit_transform(poly_features)
poly_features_test = imputer.transform(poly_features_test)
from sklearn.preprocessing import PolynomialFeatures
# Создадим полиномиальный объект степени 3
poly_transformer = PolynomialFeatures(degree = 3)
# Тренировка полиномиальных признаков
poly_transformer.fit(poly_features)
# Трансформация признаков
poly_features = poly_transformer.transform(poly_features)
poly_features_test = poly_transformer.transform(poly_features_test)
print('Формат полиномиальных признаков: ', poly_features.shape)Формат полиномиальных признаков: (307511, 35)
Присвоить признакам имена можно при помощи метода get_feature_namespoly_transformer.get_feature_names(input_features = ['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH'])[:15]['1',
'EXT_SOURCE_1',
'EXT_SOURCE_2',
'EXT_SOURCE_3',
'DAYS_BIRTH',
'EXT_SOURCE_1^2',
'EXT_SOURCE_1 EXT_SOURCE_2',
'EXT_SOURCE_1 EXT_SOURCE_3',
'EXT_SOURCE_1 DAYS_BIRTH',
'EXT_SOURCE_2^2',
'EXT_SOURCE_2 EXT_SOURCE_3',
'EXT_SOURCE_2 DAYS_BIRTH',
'EXT_SOURCE_3^2',
'EXT_SOURCE_3 DAYS_BIRTH',
'DAYS_BIRTH^2']Итого 35 полиномиальных и производных признаков. Проверим их корреляцию с таргетом.
# Датафрейм для новых фич
poly_features = pd.DataFrame(poly_features,
columns = poly_transformer.get_feature_names(['EXT_SOURCE_1', 'EXT_SOURCE_2',
'EXT_SOURCE_3', 'DAYS_BIRTH']))
# Добавим таргет
poly_features['TARGET'] = poly_target
# рассчитаем корреляцию
poly_corrs = poly_features.corr()['TARGET'].sort_values()
# Отобразим признаки с наивысшей корреляцией
print(poly_corrs.head(10))
print(poly_corrs.tail(5))EXT_SOURCE_2 EXT_SOURCE_3 -0.193939
EXT_SOURCE_1 EXT_SOURCE_2 EXT_SOURCE_3 -0.189605
EXT_SOURCE_2 EXT_SOURCE_3 DAYS_BIRTH -0.181283
EXT_SOURCE_2^2 EXT_SOURCE_3 -0.176428
EXT_SOURCE_2 EXT_SOURCE_3^2 -0.172282
EXT_SOURCE_1 EXT_SOURCE_2 -0.166625
EXT_SOURCE_1 EXT_SOURCE_3 -0.164065
EXT_SOURCE_2 -0.160295
EXT_SOURCE_2 DAYS_BIRTH -0.156873
EXT_SOURCE_1 EXT_SOURCE_2^2 -0.156867
Name: TARGET, dtype: float64
DAYS_BIRTH -0.078239
DAYS_BIRTH^2 -0.076672
DAYS_BIRTH^3 -0.074273
TARGET 1.000000
1 NaN
Name: TARGET, dtype: float64Итак, некоторые признаки показывают более высокую корреляцию, чем исходные. Есть смысл попробовать обучение с ними и без них (как и многое другое в машинном обучении, это можно выяснить экспериментально). Для этого создадим копию датафреймов и добавим туда новые фичи.
# загрузим тестовые признаки в датафрейм
poly_features_test = pd.DataFrame(poly_features_test,
columns = poly_transformer.get_feature_names(['EXT_SOURCE_1', 'EXT_SOURCE_2',
'EXT_SOURCE_3', 'DAYS_BIRTH']))
# объединим тренировочные датафреймы
poly_features['SK_ID_CURR'] = app_train['SK_ID_CURR']
app_train_poly = app_train.merge(poly_features, on = 'SK_ID_CURR', how = 'left')
# объединим тестовые датафреймы
poly_features_test['SK_ID_CURR'] = app_test['SK_ID_CURR']
app_test_poly = app_test.merge(poly_features_test, on = 'SK_ID_CURR', how = 'left')
# Выровняем датафреймы
app_train_poly, app_test_poly = app_train_poly.align(app_test_poly, join = 'inner', axis = 1)
# Посмотрим формат
print('Тренировочная выборка с полиномиальными признаками: ', app_train_poly.shape)
print('Тестовая выборка с полиномиальными признаками: ', app_test_poly.shape)Тренировочная выборка с полиномиальными признаками: (307511, 277)
Тестовая выборка с полиномиальными признаками: (48744, 277)Тренировка модели
Базовый уровень
В расчетах нужно отталкиваться от какого-то базового уровня модели, ниже которого упасть уже нельзя. В нашем случае это могло бы быть 0,5 для всех тестовых клиентов — это показывает, что мы совершенно не представляем, вернет кредит клиент или нет. В нашем случае предварительная работа уже проведена и можно использовать более сложные модели.
Логистическая регрессия
Для расчета логистической регрессии нам нужно взять таблицы с закодированными категориальными признаками, заполнить недостающие данные и нормализовать их (привести к значениям от 0 до 1). Все это выполняет следующий код:
from sklearn.preprocessing import MinMaxScaler, Imputer
# Уберем таргет из тренировочных данных
if 'TARGET' in app_train:
train = app_train.drop(labels = ['TARGET'], axis=1)
else:
train = app_train.copy()
features = list(train.columns)
# копируем тестовые данные
test = app_test.copy()
# заполним недостающее по медиане
imputer = Imputer(strategy = 'median')
# Нормализация
scaler = MinMaxScaler(feature_range = (0, 1))
# заполнение тренировочной выборки
imputer.fit(train)
# Трансофрмация тренировочной и тестовой выборок
train = imputer.transform(train)
test = imputer.transform(app_test)
# то же самое с нормализацией
scaler.fit(train)
train = scaler.transform(train)
test = scaler.transform(test)
print('Формат тренировочной выборки: ', train.shape)
print('Формат тестовой выборки: ', test.shape)Формат тренировочной выборки: (307511, 242)
Формат тестовой выборки: (48744, 242)Используем логистическую регрессию из Scikit-Learn как первую модель. Возьмем дефольную модель с одной поправкой — понизим параметр регуляризации C во избежание оверфиттинга. Синтаксис обычный — создаем модель, тренируем ее и пресказываем вероятность при помощи predict_proba (нам же нужна вероятность, а не 0/1)
from sklearn.linear_model import LogisticRegression
# Создаем модель
log_reg = LogisticRegression(C = 0.0001)
# Тренируем модель
log_reg.fit(train, train_labels)
LogisticRegression(C=0.0001, class_weight=None, dual=False,
fit_intercept=True, intercept_scaling=1, max_iter=100,
multi_class='ovr', n_jobs=1, penalty='l2', random_state=None,
solver='liblinear', tol=0.0001, verbose=0, warm_start=False)
Теперь модель можно использовать для предсказаний. Метод prdict_proba даст на выходе массив m x 2, где m - количество наблюдений, первый столбец - вероятность 0, второй - вероятность 1. Нам нужен второй (вероятность невозврата).
log_reg_pred = log_reg.predict_proba(test)[:, 1]Теперь можно создать файл для загрузки на Kaggle. Создадим датафрейм из ID клиентов и вероятности невозврата и выгрузим его.
submit = app_test[['SK_ID_CURR']]
submit['TARGET'] = log_reg_pred
submit.head()SK_ID_CURR TARGET
0 100001 0.087954
1 100005 0.163151
2 100013 0.109923
3 100028 0.077124
4 100038 0.151694submit.to_csv('log_reg_baseline.csv', index = False)Итак, результат нашего титанического труда: 0.673, при лучшем результате на сегодня 0,802.
Улучшенная модель — случайный лес
Логрег показывает себя не очень хорошо, попробуем использовать улучшенную модель — случайный лес. Это гораздо более мощная модель, которая может строить сотни деревьев и выдавать куда более точный результат. Используем 100 деревьев. Схема работы с моделью все та же, совершенно стандартная — загрузка классификатора, тренировка. предсказание.
from sklearn.ensemble import RandomForestClassifier
# Создадим классификатор
random_forest = RandomForestClassifier(n_estimators = 100, random_state = 50)
# Тренировка на тернировочных данных
random_forest.fit(train, train_labels)
# Предсказание на тестовых данных
predictions = random_forest.predict_proba(test)[:, 1]
# Создание датафрейма для загрузки
submit = app_test[['SK_ID_CURR']]
submit['TARGET'] = predictions
# Сохранение
submit.to_csv('random_forest_baseline.csv', index = False)результат случайного леса чуть лучше — 0,683
Тренировка модели с полиномиальными признаками
Теперь, когда мы имеем модель. которая делает хоть что-то — самое время потестить наши полиномиальные признаки. Сделаем с ними все то же самое и сравним результат.
poly_features_names = list(app_train_poly.columns)
# Создание и тренировка объекта для заполнение недостающих данных
imputer = Imputer(strategy = 'median')
poly_features = imputer.fit_transform(app_train_poly)
poly_features_test = imputer.transform(app_test_poly)
# Нормализация
scaler = MinMaxScaler(feature_range = (0, 1))
poly_features = scaler.fit_transform(poly_features)
poly_features_test = scaler.transform(poly_features_test)
random_forest_poly = RandomForestClassifier(n_estimators = 100, random_state = 50)
# Тренировка на полиномиальных данных
random_forest_poly.fit(poly_features, train_labels)
# Предсказания
predictions = random_forest_poly.predict_proba(poly_features_test)[:, 1]
# Датафрейм для загрузки
submit = app_test[['SK_ID_CURR']]
submit['TARGET'] = predictions
# Сохранение датафрейма
submit.to_csv('random_forest_baseline_engineered.csv', index = False)результат случайного леса с полиномиальными признаками стал хуже — 0,633. Что сильно ставит под вопрос необходимость их использования.
Градиентный бустинг
Градиентный бустинг — «серьёзная модель» для машинного обучения. Практически все последние состязания «затаскиваются» именно. Построим простую модель и проверим её производительность.
from lightgbm import LGBMClassifier
clf = LGBMClassifier()
clf.fit(train, train_labels)
predictions = clf.predict_proba(test)[:, 1]
# Датафрейм для загрузки
submit = app_test[['SK_ID_CURR']]
submit['TARGET'] = predictions
# Сохранение датафрейма
submit.to_csv('lightgbm_baseline.csv', index = False)Результат LightGBM — 0,735, что сильно оставляет позади все остальные модели
Интерпретация модели — важность признаков
Самый простой метод интерпретации модели — посмотреть на важность признаков (что могут делать далеко не все модели). Так как наш классификатор обрабатывал массив, потребуется провести некоторую работу, чтобы заново поставить названия столбцов в соответствии с колонками этого массива.
# Функция для расчета важности признаков
def show_feature_importances(model, features):
plt.figure(figsize = (12, 8))
# Создадаим датафрейм фич и их важностей и отсортируем его
results = pd.DataFrame({'feature': features, 'importance': model.feature_importances_})
results = results.sort_values('importance', ascending = False)
# Отображение
print(results.head(10))
print('\n Признаков с важностью выше 0.01 = ', np.sum(results['importance'] > 0.01))
# График
results.head(20).plot(x = 'feature', y = 'importance', kind = 'barh',
color = 'red', edgecolor = 'k', title = 'Feature Importances');
return results
# И рассчитаем все это по модели градиентного бустинга
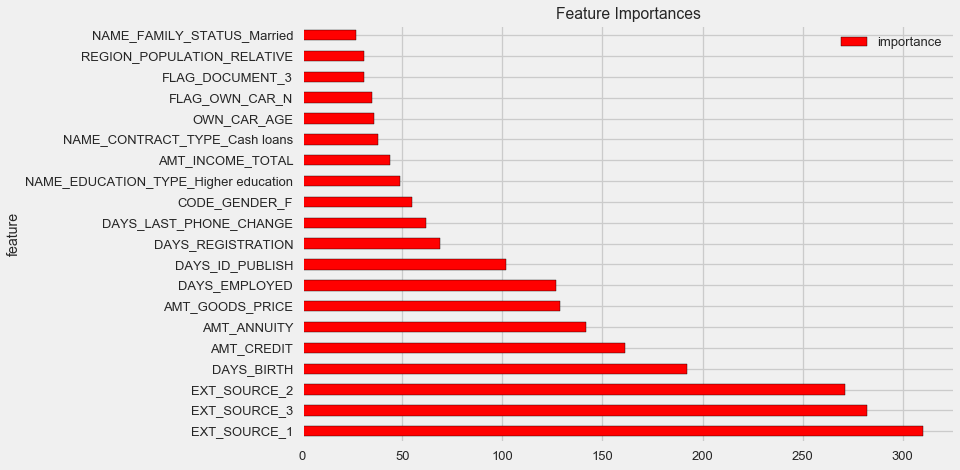
feature_importances = show_feature_importances(clf, features)
feature importance
28 EXT_SOURCE_1 310
30 EXT_SOURCE_3 282
29 EXT_SOURCE_2 271
7 DAYS_BIRTH 192
3 AMT_CREDIT 161
4 AMT_ANNUITY 142
5 AMT_GOODS_PRICE 129
8 DAYS_EMPLOYED 127
10 DAYS_ID_PUBLISH 102
9 DAYS_REGISTRATION 69
Признаков с важностью выше 0.01 = 158
Как и следовало ожидать, наиболее важны для модели все те же 4 признака. Важность признаков — не самый лучший метод интерпретации модели, но он позволяет понять основные факторы, которые модель использует для предсказаний
Добавление данных из прочих таблиц
Теперь рассмотрим внимательно дополнительные таблицы и что с ними можно сделать. Сразу начнем готовить таблицы для дальнейшего обучения. Но для начала удалим из памяти прошлые объемные таблицы, очистим память при помощи сборщика мусора и импортируем необходимые для дальнейшего анализа библиотеки.
import gc
#del app_train, app_test, train_labels, application_train, application_test, poly_features, poly_features_test
gc.collect()
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
from sklearn.model_selection import train_test_split, KFold
from sklearn.metrics import accuracy_score, roc_auc_score, confusion_matrix
from sklearn.feature_selection import VarianceThreshold
from lightgbm import LGBMClassifierИмпортируем данные, сразу уберем целевой столбец в отдельную колонку
data = pd.read_csv('../input/application_train.csv')
test = pd.read_csv('../input/application_test.csv')
prev = pd.read_csv('../input/previous_application.csv')
buro = pd.read_csv('../input/bureau.csv')
buro_balance = pd.read_csv('../input/bureau_balance.csv')
credit_card = pd.read_csv('../input/credit_card_balance.csv')
POS_CASH = pd.read_csv('../input/POS_CASH_balance.csv')
payments = pd.read_csv('../input/installments_payments.csv')
#Separate target variable
y = data['TARGET']
del data['TARGET']Сразу же закодируем категориальные признаки. Ранее мы это уже делали, при этом мы кодировали тренировочную и тестовую выборки по отдельности, а затем выравнивали данные. Попробуем немного другой подход — найдем все эти категориальные признаки, объединим датафреймы, закодируем по списку найденных, а потом снова разделим выборки на тренировочную и тестовую.
categorical_features = [col for col in data.columns if data[col].dtype == 'object']
one_hot_df = pd.concat([data,test])
one_hot_df = pd.get_dummies(one_hot_df, columns=categorical_features)
data = one_hot_df.iloc[:data.shape[0],:]
test = one_hot_df.iloc[data.shape[0]:,]
print ('Формат тренировочной выборки', data.shape)
print ('Формат тестовой выборки', test.shape)Формат тренировочной выборки (307511, 245)
Формат тестовой выборки (48744, 245)Данные кредитного бюро по ежемесячному балансу кредитов.
buro_balance.head()
MONTHS_BALANCE — количество месяцев до даты подачи заявки на кредит. Взглянем подробнее на «статусы»
buro_balance.STATUS.value_counts()C 13646993
0 7499507
X 5810482
1 242347
5 62406
2 23419
3 8924
4 5847
Name: STATUS, dtype: int64Статусы означают следующее:
С — closed, то есть погашенный кредит. X — неизвестный статус. 0 — текущий кредит, отсутствие просрочек. 1 — просрочка 1-30 дней, 2 — просрочка 31-60 дней и так далее до статуса 5 — кредит продан третьей стороне или списан.
Отсюда можно выделить например следующие признаки: buro_grouped_size — количество записей в базе buro_grouped_max — максимальный баланс по кредиту buro_grouped_min — минимальный баланс по кредиту
А также все эти статусы по кредиту можно закодировать (используем метод unstack, а затем присоединим полученные данные к таблице buro, благо что SK_ID_BUREAU там и там совпадает.
buro_grouped_size = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].size()
buro_grouped_max = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].max()
buro_grouped_min = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].min()
buro_counts = buro_balance.groupby('SK_ID_BUREAU')['STATUS'].value_counts(normalize = False)
buro_counts_unstacked = buro_counts.unstack('STATUS')
buro_counts_unstacked.columns = ['STATUS_0', 'STATUS_1','STATUS_2','STATUS_3','STATUS_4','STATUS_5','STATUS_C','STATUS_X',]
buro_counts_unstacked['MONTHS_COUNT'] = buro_grouped_size
buro_counts_unstacked['MONTHS_MIN'] = buro_grouped_min
buro_counts_unstacked['MONTHS_MAX'] = buro_grouped_max
buro = buro.join(buro_counts_unstacked, how='left', on='SK_ID_BUREAU')
del buro_balance
gc.collect()Общие данные по кредитным бюро
buro.head()
(показано первые 7 столбцов)
Довольно много данных, которые, в общем-то, можно попробовать просто закодировать One-Hot-Encoding'ом, сгруппировать по SK_ID_CURR, усреднить и, таки образом, подготовить для объединения с основной таблицей
buro_cat_features = [bcol for bcol in buro.columns if buro[bcol].dtype == 'object']
buro = pd.get_dummies(buro, columns=buro_cat_features)
avg_buro = buro.groupby('SK_ID_CURR').mean()
avg_buro['buro_count'] = buro[['SK_ID_BUREAU', 'SK_ID_CURR']].groupby('SK_ID_CURR').count()['SK_ID_BUREAU']
del avg_buro['SK_ID_BUREAU']
del buro
gc.collect()Данные по предыдущим заявкам
prev.head()
Точно также закодируем категориальные признаки, усредним и объединим по текущему ID.
prev_cat_features = [pcol for pcol in prev.columns if prev[pcol].dtype == 'object']
prev = pd.get_dummies(prev, columns=prev_cat_features)
avg_prev = prev.groupby('SK_ID_CURR').mean()
cnt_prev = prev[['SK_ID_CURR', 'SK_ID_PREV']].groupby('SK_ID_CURR').count()
avg_prev['nb_app'] = cnt_prev['SK_ID_PREV']
del avg_prev['SK_ID_PREV']
del prev
gc.collect()Баланс по кредитной карте
POS_CASH.head()
POS_CASH.NAME_CONTRACT_STATUS.value_counts()Active 9151119
Completed 744883
Signed 87260
Demand 7065
Returned to the store 5461
Approved 4917
Amortized debt 636
Canceled 15
XNA 2
Name: NAME_CONTRACT_STATUS, dtype: int64Закодируем категориальные признаки и подготовим таблицу для объединения
le = LabelEncoder()
POS_CASH['NAME_CONTRACT_STATUS'] = le.fit_transform(POS_CASH['NAME_CONTRACT_STATUS'].astype(str))
nunique_status = POS_CASH[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').nunique()
nunique_status2 = POS_CASH[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').max()
POS_CASH['NUNIQUE_STATUS'] = nunique_status['NAME_CONTRACT_STATUS']
POS_CASH['NUNIQUE_STATUS2'] = nunique_status2['NAME_CONTRACT_STATUS']
POS_CASH.drop(['SK_ID_PREV', 'NAME_CONTRACT_STATUS'], axis=1, inplace=True)Данные по картам
credit_card.head()
(первые 7 столбцов)
Аналогичная работа
credit_card['NAME_CONTRACT_STATUS'] = le.fit_transform(credit_card['NAME_CONTRACT_STATUS'].astype(str))
nunique_status = credit_card[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').nunique()
nunique_status2 = credit_card[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').max()
credit_card['NUNIQUE_STATUS'] = nunique_status['NAME_CONTRACT_STATUS']
credit_card['NUNIQUE_STATUS2'] = nunique_status2['NAME_CONTRACT_STATUS']
credit_card.drop(['SK_ID_PREV', 'NAME_CONTRACT_STATUS'], axis=1, inplace=True)Данные по платежам
payments.head()
(показано первые 7 столбцов)
Создадим три таблицы — со средними, минимальными и максимальными значениями из этой таблицы.
avg_payments = payments.groupby('SK_ID_CURR').mean()
avg_payments2 = payments.groupby('SK_ID_CURR').max()
avg_payments3 = payments.groupby('SK_ID_CURR').min()
del avg_payments['SK_ID_PREV']
del payments
gc.collect()Объединение таблиц
data = data.merge(right=avg_prev.reset_index(), how='left', on='SK_ID_CURR')
test = test.merge(right=avg_prev.reset_index(), how='left', on='SK_ID_CURR')
data = data.merge(right=avg_buro.reset_index(), how='left', on='SK_ID_CURR')
test = test.merge(right=avg_buro.reset_index(), how='left', on='SK_ID_CURR')
data = data.merge(POS_CASH.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR')
test = test.merge(POS_CASH.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR')
data = data.merge(credit_card.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR')
test = test.merge(credit_card.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR')
data = data.merge(right=avg_payments.reset_index(), how='left', on='SK_ID_CURR')
test = test.merge(right=avg_payments.reset_index(), how='left', on='SK_ID_CURR')
data = data.merge(right=avg_payments2.reset_index(), how='left', on='SK_ID_CURR')
test = test.merge(right=avg_payments2.reset_index(), how='left', on='SK_ID_CURR')
data = data.merge(right=avg_payments3.reset_index(), how='left', on='SK_ID_CURR')
test = test.merge(right=avg_payments3.reset_index(), how='left', on='SK_ID_CURR')
del avg_prev, avg_buro, POS_CASH, credit_card, avg_payments, avg_payments2, avg_payments3
gc.collect()
print ('Формат тренировочной выборки', data.shape)
print ('Формат тестовой выборки', test.shape)
print ('Формат целевого столбца', y.shape)Формат тренировочной выборки (307511, 504)
Формат тестовой выборки (48744, 504)
Формат целевого столбца (307511,)И, собственно, ударим по этой выросшей в два раза таблице градиентным бустингом!
from lightgbm import LGBMClassifier
clf2 = LGBMClassifier()
clf2.fit(data, y)
predictions = clf2.predict_proba(test)[:, 1]
# Датафрейм для загрузки
submission = test[['SK_ID_CURR']]
submission['TARGET'] = predictions
# Сохранение датафрейма
submission.to_csv('lightgbm_full.csv', index = False)результат — 0,770.
ОК, напоследок попробуем более сложную методику с разделением на фолды, кросс-валидацией и выбором лучшей итерации.
folds = KFold(n_splits=5, shuffle=True, random_state=546789)
oof_preds = np.zeros(data.shape[0])
sub_preds = np.zeros(test.shape[0])
feature_importance_df = pd.DataFrame()
feats = [f for f in data.columns if f not in ['SK_ID_CURR']]
for n_fold, (trn_idx, val_idx) in enumerate(folds.split(data)):
trn_x, trn_y = data[feats].iloc[trn_idx], y.iloc[trn_idx]
val_x, val_y = data[feats].iloc[val_idx], y.iloc[val_idx]
clf = LGBMClassifier(
n_estimators=10000,
learning_rate=0.03,
num_leaves=34,
colsample_bytree=0.9,
subsample=0.8,
max_depth=8,
reg_alpha=.1,
reg_lambda=.1,
min_split_gain=.01,
min_child_weight=375,
silent=-1,
verbose=-1,
)
clf.fit(trn_x, trn_y,
eval_set= [(trn_x, trn_y), (val_x, val_y)],
eval_metric='auc', verbose=100, early_stopping_rounds=100 #30
)
oof_preds[val_idx] = clf.predict_proba(val_x, num_iteration=clf.best_iteration_)[:, 1]
sub_preds += clf.predict_proba(test[feats], num_iteration=clf.best_iteration_)[:, 1] / folds.n_splits
fold_importance_df = pd.DataFrame()
fold_importance_df["feature"] = feats
fold_importance_df["importance"] = clf.feature_importances_
fold_importance_df["fold"] = n_fold + 1
feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0)
print('Fold %2d AUC : %.6f' % (n_fold + 1, roc_auc_score(val_y, oof_preds[val_idx])))
del clf, trn_x, trn_y, val_x, val_y
gc.collect()
print('Full AUC score %.6f' % roc_auc_score(y, oof_preds))
test['TARGET'] = sub_preds
test[['SK_ID_CURR', 'TARGET']].to_csv('submission_cross.csv', index=False)Full AUC score 0.785845Финальный скор на kaggle 0,783
Куда двигаться дальше
Определенно, дальше работать с признаками. Исследовать данные, какие-то из признаков выделять, комбинировать их, по-другому присоединять дополнительные таблицы. Можно экспериментировать с гиперпараметрами можели — направлений много.
Надеюсь, это небольшая компилляция показала вам современные методы исследования данных и подготовки прогнозных моделей. Изучайте датасаенс, участвуйте в соревнованиях, будьте клевыми!
И еще раз ссылки на кернелы, которые помогли мне подготовить эту статью. Статья также размещена в виде ноутбука на Гитхабе, можно скачать её, датасет и запускать и экспериментировать.
Will Koehrsen. Start Here: A Gentle Introduction
sban. HomeCreditRisk: Extensive EDA + Baseline [0.772]
Gabriel Preda. Home Credit Default Risk Extensive EDA
Pavan Raj. Loan repayers v/s Loan defaulters — HOME CREDIT
Lem Lordje Ko. 15 lines: Just EXT_SOURCE_x
Shanth. HOME CREDIT — BUREAU DATA — FEATURE ENGINEERING
Dmitriy Kisil. Good_fun_with_LigthGBM








