Комментарии 129
Можно потратить всю жизнь на изучение языков и понимать их немного лучше чем GT, а можно просто открыть на смартфоне GT.
-А Вы?
(с) Я, Робот.
человеку умение видеть контекст так же не даруется на генном уровне, а приходит с жизненным опытом, а точнее в процессе обучения. А умение красиво и грамотно излагать мысли даже на родном языке так вообще даётся далеко не всем. Но как учить детей — мы примерно представляем, как обучить GT до уровня среднего человека — пока вопрос, и скорее всего вопрос времени. Всё будет… просто надо отдавать себе отчёт на каком этапе мы находимся на сегодняшний день.
И с каждым днём GT будет становиться продвинутее и полезнее для всё более требовательных групп людей.
Более того, я считаю, что у разработчиков GT даже не стояло задачи сразу выпустить идеальный продукт. Как обычно, сначала стоит выпустить продукт, удовлетворяющий 90% нужд населения, а затем, проведя анализ, выбрав эффективный путь, углубляться в дебри, дабы уменьшить вероятность попадания в тупиковые варианты развития.
С моим upper-intermediate в английском я часто пользуюсь GT в качестве начального грязного перевода
Гонять текст через переводчик удобно когда маленький словарный запас. Когда слов в голове становится больше — проще прочитать самому. Ну да — можно напутать со временами иногда, но постепенно исправляешься.
P.S. Вы это детям докажите… Они книги читать не умеют, а информацию получают из ютуб каналов… Жесть...
[для интереса добавим и русский язык / прим. перев.]
Отличный пример искусства перевода. Спасибо!
Перевод — это, все-таки, передача содержания материала на другом языке.
Когда вы заменяете основной материал статьи другим (пусть и релевантным) — это уже не перевод, а что-то другое.
Поэтому, например, перевод всевозможной поэзии правильнее назвать переложением.
Прогресс слишком медленный и не всегда очевидный, а ярых фанатов отрицателей — нет. Неинтересно такую табличку делать.
Если переиначить «90% людей считают себя умнее среднего», то «все со знанием английского выше Advanced наверняка считают себя хорошими переводчиками»… а по факту имеем?
94.177.190.72/dune/1.html
читать снизу вверх :) с «Дюна» «Трудности перевода 1»
анализ в ключе:
balances are correct; Bene Gesserit; Shaddam
A beginning is the time for taking the most delicate care that the balances are correct. This every sister of the Bene Gesserit knows. To begin your study of the life of Muad'Dib, then, take care that you first place him in his time: born in the 57th year of the Padishah Emperor, Shaddam IV.
Соколов:
Начиная любое дело, следует точнейшим образом определить известные факты. Это знает любая из Дочерей Гессера. Чтобы понять Myад'Диба, следует сперва точно определить время его жизни — он родился на 57-ом году правления падишах-императора Шаддама IV
Новый:
Начало любого дела — это тот этап, когда вы должны с особой тщательностью уравновесить свои весы. Об этом знает каждая сестра из школы Бен-Джессерит. Сейчас вы начинаете изучать жизнь Муад-Диба. Пожалуйста, прежде всего попытайтесь представить, когда он родился: пятьдесят седьмой год правления Падишаха-Императора Саддама IV.
Вязников:
Начало есть время, когда следует позаботиться о том, чтобы все было отмерено и уравновешено. Это знает каждая сестра Бене Гессерит. Итак, приступая к изучению жизни Муад'Диба, прежде всего правильно представьте время его: рожден в пятьдесят седьмой год правления Падишах-Императора Шаддама IV.
Мой комментарий:
Что тут означает “balances are correct”? «Весы» будет “balance” – в единственном числе. В бухгалтерских и банковских делах можно иногда встретить “balances are correct” в смысле правильности остатков по счетам. Перевод Соколова тут хоть и не точен, но удачен. Во всей книге много мутноватых выражений, которые точно на другой язык перевести просто невозможно.
Bene Gesserit (Бинэ Гессерит) – см. пункт 70.
На иврите (Hebrew) Shaddai означает «Всемогущий, Бог», а Shaddam звучит примерно как “shut damn”, что можно перевести как «заткнись, чёрт побери». В общем лёгкий юмор и ирония начинается уже с самого начала – имя императора не Shaddai, а Shaddam. И на русский правильно переводить конечно же «Шаддам». Новый скорее всего перевёл как «Саддам» для аналогии с Саддамом Хусейном. Встречается мнение, что Дюна – аналогия ближнего востока, а спайс (специя, меланж) – аналогия нефти. Очевидно, что хотя аналогия уместна, но очень несовершенна. Множество арабизмов в тексте и соответствующий ландшафт – это вероятно намеренный ход по улучшению шансов на популярность романа в арабском мире. И как показало время, там роман тоже стал очень популярным. Когда Герберт в своей статье 1980 года «Генезис Дюны» говорит “CHOAM is OPEC”, т.е. «КООАМ это ОПЕК», он намеренно упрощает этот аспект. «Спайс» – это то, что люди потребляют непосредственно и нефть тут ни при чём. Скорее, правильнее сказать, что из-за большой популярности романа и существующих определённых ассоциаций с богатым нефтью арабским миром, теперь иногда в сленговой семантике «нефть» может обозначать «спайс», а вернее нечто с ним непосредственно связанное – см. пункт 5 и многие др.
Хотя, насколько мне моего ин.яза хватает, выводы автора статьи совершенно закономерные. Возможно Херберт на наркотиках каких сидел (дело было в 60-е).
Оригинал:
Alexander Pushkin’s sparkling novel in verse
Перевод в статье:
блестящей новеллы Александра Пушкина
Гуглоперевод:
Сверкающий роман Александра Пушкина в стихах
Тот неловкий момент, когда гуглоперевод оказался правильней, т.к. не выкинул «ненужные» слова.
В основном использую Google Translate как словарик. К сожалению, как переводчик он всё ещё довольно слаб; особенно часто буксует на различных идиоматических выражениях (их он почти совсем не знает). Для знающих английский и желающих прочитать текст на каком-то третьем языке лучше использовать перевод на английский, он как правило качественней и понятней перевода на русский.
«Площадь трапеции» -> "אזור טרפזיום" («район кости-трапеции»), потому что «trapezium area». Какого контекста ему не хватает в этот раз?
Google translate отлично переводит научную литературу и позволяет в большинстве случаев правильно понять смысл обычных текстов.
А делать художественный перевод сможет лишь с появлением настоящего ии, ибо понимания культурного контекста иначе не добиться.
И как сервис проживет, я считаю, достаточно недолго, лишь в период адаптации. Дальше у ИИ как у вида будет абсолютное преимущество, что вытеснит человека в его текущей форме (и я в этом не вижу ничего страшного, просто следующая ступень эволюции). А дальше необходимость во множестве языков отпадет :)
Так что как ни парадоксально, но сейчас мы уже практически на пике развития переводчика как софта.
Google translate отлично переводит научную литературу и позволяет в большинстве случаев правильно понять смысл обычных текстов.
Прикол в том, что в меньшинстве случаев он искажает смысл текста на противоположный (как в приведённом примере, «руководил аспирантами» превратилось в «был аспирантом»), и если вы результат перевода не просто читаете для удовольствия как худлитературу, а полагаетесь на него как на научный текст — то он вас может очень неудачно подвести.
Когда сможет переводить технические тексты, тогда поговорим.
Когда сможет переводить художественную литературу, тогда поговорим.
Когда сможет переводить стихи, тогда поговорим.
…
— Эй, хватит пичкать меня этими скучными текстами, давай лучше поговорим! :)
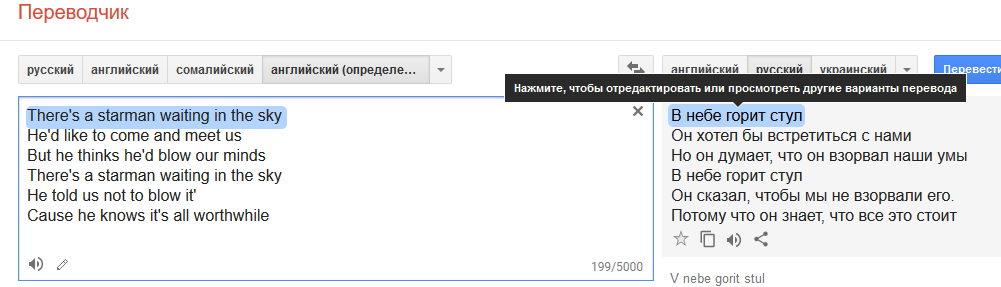 habrastorage.org/webt/hx/cx/j_/hxcxj_rtijg4tfbyp_xd4l5meme.png
habrastorage.org/webt/hx/cx/j_/hxcxj_rtijg4tfbyp_xd4l5meme.pngСледует учитывать еще один момент, кроме эволюции ИИ компьютерных переводчиков идет и сильная паралельная эволюция человеческих языков в основном в сторону уменьшения их витеватости и неоднозначности.
С ускорением жизни и желанием быстро передать информацию, люди начинают общаться более простыми и четкими фразами, а привыкая к такому стилю в собственном общении они ожидают такой же стиль и в читаемых текстах. Посмотрите, например, каким витиеватым языком писали классики лет 200 назад и как пишется современная литература.
Так что, с учетом этих двух идущих на встречу процессов у компьютерных переводчиков светлое будущее для массового применения, а сонеты Шекспира не каждый человек-переводчик адекватно переведет, это узкая ниша по которой нет смысла равнятся.
Ага, вот пример уменьшения витиеватости и неоднозначности: "На инсте гейта минусовый хуррик, в бубле, в агре".
А в чем тут витиеватость?
Тут просто специфический сленговый словарь используется, после добавления слов которого в базу будет вполне адекватно переводится.
А без знания значения сленговых слов тут и человек не поймет, я вот только очень приблизительно понял общий смысл.
Так вот в живой речи всегда используется специфический словарь.
Так а в чем принципиальная разница этого словаря со словарем используемым скажем в газетах? Что мешает расширять словарь?
А вот теперь сравните пример из Достоевского с обычными словами:
"Разумихин, сконфуженный окончательно падением столика и разбившимся стаканом, мрачно поглядел на осколки, плюнул и круто повернул к окну, где и стал спиной к публике, с страшно нахмуренным лицом, смотря в окно и ничего не видя. "
Сколько тут граматических моментов должен компьютер проанализировать чтобы правильно согласовать разные части предложения и не получить в итоге кашу?
Razumikhin, embarrassed finally by the fall of the table and a broken glass, gloomily looked at the fragments, spat and turned sharply to the window, where he turned his back on the audience, with a terribly frowning face, looking out the window and not seeing anything.
Не сказать что перевод хорош, но единственный, пожалуй, смысловой косяк в нём — это «embarrassed finally».
Так а в чем принципиальная разница этого словаря со словарем используемым скажем в газетах?В газетах минимальный словарь и простые речевые обороты. Там же не будут использоваться длинные сложноподчиненные предложения, с пространными описаниями старинными словами, когда основная задача — доносить информацию. На примере иероглифов — в газетах используются несколько тысяч, когда всего их в разы больше.
Сколько тут граматических моментов должен компьютер проанализировать чтобы правильно согласовать разные части предложения и не получить в итоге кашу?Всё в рамках школьной программы русского языка — определить части речи и члены предложения, подлежащее и сказуемое перевести как есть, остальное подогнать по смыслу (вот только тот же GT нацеливают не на обработку по правилам языка, а на использование шаблонов перевода, которые не всегда корректны).
Он гонит всё через придуманный им самим язык, а не через английский
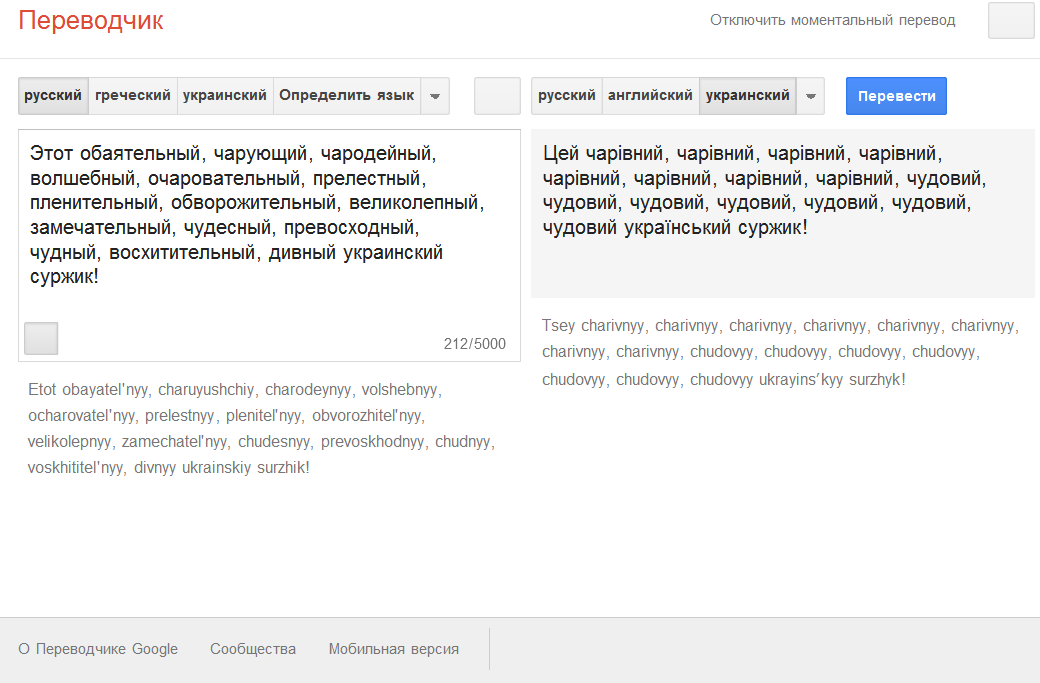
Близкие грамматически языки типа русского и украинского, вполне возможно, объединяет.
Так?
Посмотрите, например, каким витиеватым языком писали классики лет 200 назад и как пишется современная литература.
Это особенность конкретно литературного стиля, который поменялся.
Посмотрите реплики героев Шекспира — ничего в них витьеватого нету.
Самое запомнившееся: «оставленная вершина» (в чертёжной программе при выборе точки привязки) — в оригинале Top Left.
Но да, даже адекватный перевод слух таки режет иногда — хотя для меня в других случаях («полный экран» нормально воспринимаю, а вот Обозреватель вместо Explorer — тут я солидарен).
Недавно я столкнулся с необходимостью перевода с японского, так гугловый выдал несогласованный набор слов (даже при выборе английского целевым, не говоря уже о русском), а этот — относительно связный текст, не без косяков, но по нему хотя бы удалось восстановить смысл.
Вот, только что нашел "образец" перевода: Что такое вариант установки основных серверных компонентов в Windows Server?
Лично я в этом тексте понимаю только отдельные слова, вместе они никак не складываются...
К примеру, по-моему мнению, translate.ru лучше GT справляется с it-текстами.
В некоторых случаях другие переводчики бывают неплохи. Например яндексовский получше формулирует текст на русском.
Бинг переводит более упрощенными текстами, не всегда дотягивает до GT. Babylon обычно слабый перевод, мало направлений перевода, размер текста для перевода меньше других. Промт/babylon иногда бывают удобны в качестве словаря.
GT явно не понял смысла фразы — просто выдал кучу бычьего дерьма.
Редактор GT переводит не лучше автоматического GT. Английское слово bullshit означает просто «чепуха».
Но всё это появится только когда машины наполнятся идеями, эмоциями и опытом, как люди.
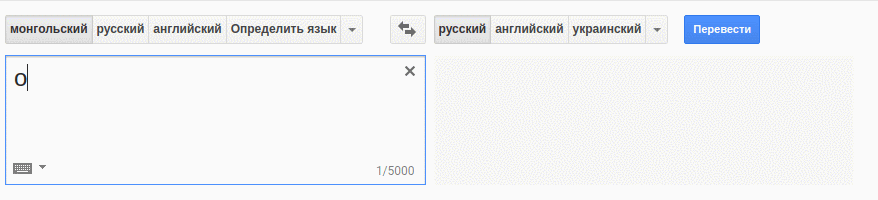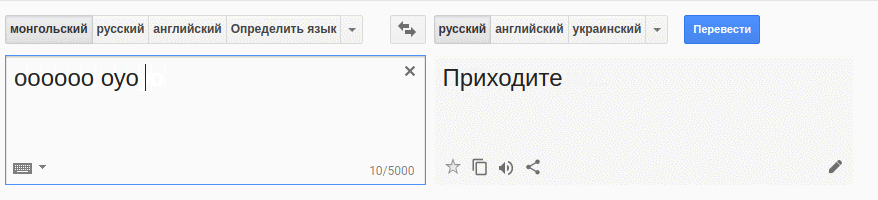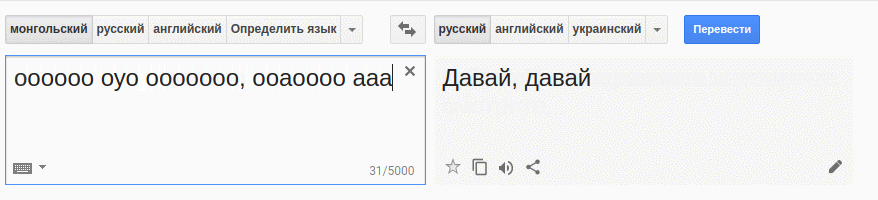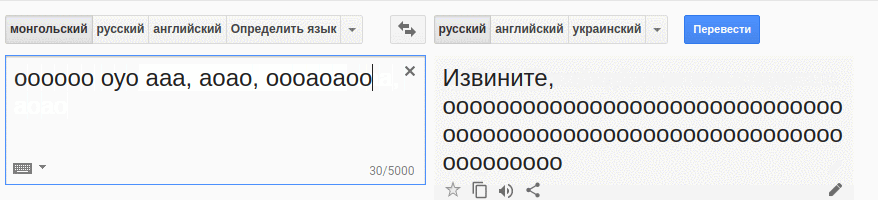
Что это, друзья, дебюты, и в чем смысл друзей? Дебюты и товарищи — «Quasi una fantasia». Что это значит для друзей? Идея состоит в том, что муж — логичный шахматист.
На монгольский туда и обратно. Вот примерно так машины идеями и наполнятся :)
Ааа, еще один прогон :)
В чем смысл друзей, дебютов и друзей? Дебюты и товарищи — «Quasi una fantasia». Что это значит для друзей? Ее муж — логичный шахматист.
Признавая правоту автора и презирая "гуглопереводы", я все же не могу не вспомнить, когда в начале 90-х в страну попали тонны западной литературы (фантастики), а машинных переводчиков, результатом которых можно было бы воспользоваться — тогда точно не было, и можно было утверждать, что все переводы сделаны людьми — и тогда было немало мест в книгах, для понимания которых было необходимо сообразить, как это выглядело в оригинале и тогда уж только понять.

Рассуждения о его и её полотенцах и связанных культурных фактах, о которых машина не имеет представления, напомнили старый пример простого диалога, смысл которого машине вряд ли будет понятен в ближайшие десятилетия:
Она: Я ухожу.
Он: Кто он?
У меня кум технический переводчик с техническим же образованием. Так вот он говорит, что технические тексты люди без образования переводить не могут. Знания терминов мало, нужно иметь хорошее представление об области знаний в целом и понимать принципы работы конкретных устройств. Поэтому такие люди как он на вес золота, если надо переводить документацию к, например, электронике, потому что он в ней хорошо разбирается. А выпускники факультетов лингвистики выдают на-гора такой текст, что надо каждое второе слово править.
Так чего же ожидать от машины, которой предложили перевести кусок фразы, не предложив контекста?
Речь как раз о том, что на данный момент мы имеем достаточно примитивный, механический подход к т.н. машинному переводу, который сравним с переводом «слово в слово» и не распознает простейших языковых отличий, таких как рода слов, не говоря уже о историческом и территориальном контексте.
Помню в свое время покупал на taobao одежду и общался об этом с китайцами через QQ.
Написал им «Мне нравиться, ваш ассортимент обуви», через Google Translate
Делаю обратный перевод — «Я любил вас во всех позах в обуви».
Хорошо, что не отправил. Поэтому на форумах жаловались, что не всегда могут найти язык с китайцами))
С тех пор, всегда пишу только простыми предложениями типа «цена товара?» и т.д. И всегда делаю обратный перевод.
Был случай, когда гугл мне из списка стран то ли убрал одну страну Баларусь, то ли заменил ее на другую совсем типа «Гундурас» (точно не помню). Долго чесал репу, пытаясь понять как это. перепроверял много раз тогда. Беларусь отдельно нормально переводил, а вот в списке тех стран то ли вычеркивал то ли заменял на другую.
«Мне нравиться, ваш ассортимент обуви»
Делаю обратный перевод — «Я любил вас во всех позах в обуви».
Это была месть Google Translate за вытекшие
Сейчас гугл транслайт нормально переводит эту фразу (проверял сегодня). Кстати с ошибками тоже хорошо справляется. Но форс-мажоры с переводом все равно бывают часто.
Смысл моего комментария был в том, что порой он переводит текст не отдельно словами, а целыми выражениями (нейронка ?). И иногда эти выражения имеют совсем другой смысл. Как это было с пропаданием «Беларусь» в списке стран. При этом, сокращая список стран, в какой-то момент Беларусь появилась в переводе.
«И Боромир, превозмогая смерть, улыбнулся.»
Перевод В. Муравьева, А. Кистяковского.
«Тень улыбки промелькнула на бледном, без кровинки, лице Боромира.»
Перевод Н. Григорьевой, В. Грушецкого.
«Уста Боромира тронула слабая улыбка.»
Перевод М. Каменкович, В. Каррика.
«Boromir smiled.»
Оригинал.
Отсюда
Так что иногда ГТ переводит лучше :)
Он тут .
Приведенная фраза описывает последнее действие Боромира перед смертью. Английский текст самой фразы не позволяет понять интонацию улыбки, но диалог перед ней — позволяет. Если кратко — Боромир призывает Арагорна идти в Минас Тирит и спасти его народ. Арагорн говорит, что Боромиру не о чем жалеть и он может быть спокоен, город будет спасен. То есть Боромир, умирает с улыбкой в которой читается сожаление и облегчение. Сожаление от того, что он не смог сам (он говорит об этом) и облегчение от обещания Арагорна. Таков контекст.
[Boromir] Farewell, Aragorn! Go to Minas Tirith and save my people! I have failed.'
'No!' said Aragorn, taking his hand and kissing his brow. 'You have conquered. Few have gained such a victory. Be at peace! Minas Tirith shall not fall!'”. Boromir smiled.
Давайте теперь посмотрим переводы:
1. Прощай, Арагорн! Иди в Минас Тирит, спаси мой народ! Я проиграл сражение.
– Нет! – с жаром возразил Арагорн, схватив руку гондорца и касаясь губами его лба. – Нет, Боромир! Ты выиграл! Немногим доводилось одержать такую победу. Усни с миром! Минас Тирит выстоит!
Уста Боромира тронула слабая улыбка.
2. Прощай, Арагорн! Иди в Минас-Тирит, спасай наших людей. А я… Меня победили.
— Нет! — воскликнул Арагорн, взяв его за руку и целуя холодеющий лоб. — Ты победил. И велика твоя победа. Покойся с миром! Минас-Тирит выстоит.
И Боромир, превозмогая смерть, улыбнулся.
3. Прощай Арагорн. Иди в Минас Тирит, защищай мой народ. Я побежден.
-Нет, — горячо ответил Следопыт, взяв воина за руки и поцеловав его в лоб, ты победил. Немногим выпала на долю такая победа. Будь спокоен. Минас Тирит не покорится врагу.
Тень улыбки промелькнула на бледном, без кровинки, лице Боромира.
И конечно же GT:
Прощай, Арагорн! Идите в Минас Тирит и спасите моих людей! Мне не удалось.'
«Нет!» — сказал Арагорн, беря его за руку и целуя его лоб. «Вы победили. Немногие получили такую победу. Быть в мире! Минас Тирит не упадет! ». Боромир улыбнулся.
Вы серъезно считаете перевод гугла лучшим? При всех огрехах переводчиков, любой из переводов лучше отражает картину происходящего. И этого не говоря о том, что половина из переведенного машиной — вообще не русский язык.
Вся статья о том, что перевод — это осознанный и переработаный текст с учетом языковых особенностей, а не тупой перевод слово в слово.
Вычислительные мощности. Их просто не хватит на всех.
Даже простые предложения порой переводит с косяками.
Думаю если отойти от словарного запаса уровень GT чуть выше чем A2.
И если я что-то перевожу то сразу 2-3 переводчиками.
GT и Microsoft Translator и яндекс переводчик.
Говорят у Microsoft Translator тоже уже нейронки работают.
А нельзя научить мощную сетку переводить как обучали играть в ГО?
на максимально доступном количестве примеров. Ведь литературы очень много.
Составить миллиарды пар фраз — перевод. С разными словами.
Просто думаю на текущем уровне качество можно поднять раза в 2 а то и в 4.
Да я согласен ждать хоть 1 минуту на страницу. Но пусть это будет более хороший перевод.
Предлагаю в качестве заглавной КДПВ свой скриншот работы GT, сделанный около года назад:

А если серьёзно, то я полностью поддерживаю идею о том, что полноценный перевод по плечу только сильному ИИ, и он обязательно будет вариативным и неоднозначным, т.е. таким же, каким выходит сегодня из-под пера хороших живых переводчиков.
И шансов добиться успехов на этом пути больше у Compreno (про который что-то давно не было новостей), чем у Гугла с его GNMT, который до сих пор в предложении "Den som vet att det blir kvarskatt på över 30 000 kronor kan göra en extra inbetalning" кроны переводит на английский как доллары (а если убрать последние пять слов — валюта чудесным образом исправляется...).
И, напоследок, не могу удержаться от ставшего уже классическим переводческого примера про "Эти типы стали есть в прокатном цехе".
В том варианте, что я слышал, речь шла о проводнике в шине (bus).
Какое «правильное слово» имелось в виду в случае двора и стены — я что-то не догадываюсь.
PS двор и стена переведены правильно, там никаких хитрых слов не имелось в виду. Почему двор мне нравится больше стены — так потому что люди по стенам не бегают, подвох слишком очевиден.
Если речь шла про некий оголённый (неизолированный) электрический проводник — то причём тут двор? Стена выглядит логичнее, проводка по стенам делается. И иногда даже таки неизолированная.
Надо сказать, с шиной тоже исходный контекст не очень понятен — зачем было подчеркивать неизолированность.
Сейчас погуглил — по инету ходит куча разных вариантов, и похоже, первоисточник вот:
— Он перелистал несколько страниц и ткнул пальцем в одну из фраз: — Переведи вот это, например.Е. Войскунский, И. Лукодьянов. Экипаж «Меконга».
— «Naked conductor runs under the carriage», — прочла Валя и тут же перевела: — «Голый кондуктор бежит под вагоном...» Неприлично и глупо!
Инженеры так и покатились со смеху.
— Послушай, как нужно правильно, — сказал Юра, отсмеявшись: — «Неизолированный провод проходит под тележкой крана». Американский технический язык — это тебе, Валечка, не английский литературный. Здесь навык нужен...
Год издания — 1962.
Остальное — «испорченный телефон». А вариант с шиной до меня дошёл через профессиональный круг общения (электроника, электрика).
Если речь шла про некий оголённый (неизолированный) электрический проводник — то причём тут двор?
Я так понимаю, что в этой версии байки обыгрывается двузначность слова «yard» — «двор» и «сортировочная станция».
Сколько мнений…
Слова и обьединения слов есть набор звуков описывающих совершенно конкретные вещи и ситуации. Вполне логично что в разных языках эти вещи и ситуации были разные. Из за массы нюансов, места жительства, приоритетных занятий и прочего… например у эскимосов куча слов описывает снег.
То есть для адекватного перевода нужно прочитать, представить ситуацию и описать эту ситуацию звуками другого языка.
Технически это реализуемо в рамках доступных технологий. По сути это задача множеств и их отношений.
И нейросети со своим статистическим анализом не решают задачу.
ссылке —
Eskimo–Aleut languages have about the same number of distinct word roots referring to snow as English does, but the structure of these languages tends to allow more variety as to how those roots can be modified in forming a single word.
the idea that a language's grammar shapes its speakers' view of the world.
Там даны примеры текста на английском языке, и перевод, сделанный на ЭВМ 50х годов.
Я взял часть текстов на английском языке из этой книги и перевел их с помощью Переводчика гугл.
Результаты просто обескураживающие: за 60 лет качество перевода заметно лучше не стало, а в некоторых текстах — получилось хуже, чем было 60 лет назад.
Сомневающиеся могут проверить сами.
«Перед учеными всех стран стоит огромная задача ознакомления с научной литературой, написанной на других языках, и вот эту задачу, безусловно, можно надеяться разрешить при помощи автоматического перевода. Первые шаги в этом направлении сделаны, и можно ожидать серьезного прогресса в данной области уже в ближайшие годы» (с) 1958
Вот была у меня книга в двух экземплярах: один — английский оригинал, и один — перевод от издательства «Эксмо» 2009го года, где указан вполне себе заслуженный переводчик-профессионал Владимир Симонов. И перевод просто ужасающий. Встретилась одна достаточно сложная фраза. И я вижу что на русском она вообще в сюжет никак не вписывается. Читая оригинал, я примерно понимаю на английском она означает, но переводчик-человек ее переводит с полным искажением смысла. Забив фразу в GT получаю практически идеальный перевод, главное — с правильным смыслом. И в этой книге такое — не единичный случай.
Так что, да, гениальный труд машина может пока что заменить не может. А вот уровень халтурщиков их российских изданий уже, похоже, переплюнула.
с облегчением увидев, что мы ещё не подошли близко к тому, чтобы заменить переводчиков машинамиЭто серьёзно? Не, ну для некоторых очень похожих языков, я полагаю, машина может адекватно перевести. Но для некоторых языков даже через 100 лет человек не научится переводить, потому что это в принципе невозможно (если мы говорим о более-менее адекватном переводе), а что уж говорить про машину.
Ну возьмём, к примеру, фразу, которую невозможно перевести с одного языка на другой. Как машина переведёт её? (имеется ввиду без добавления десятистраничного комментария)
Когда упоминается машинный перевод, нужно сразу вводить оговорки, что это даже теоретически возможно только для некоторых языков и не для всех фраз (либо зависит от типа текста).
Вся беспомощность машинного перевода уже не мешает переводческим агентствам давать переводчикам машиннопереведенные тексты на отчитку вместо оригинала на перевод (за меньший прайс, разумеется). А то и просто без обиняков нанимать «редакторов машинного перевода».
Машинный перевод неплохо работает на простых задачах — например, когда вам нужно перевести ассортимент магазина с тысячами товаров на десяток языков, и при этом цена казуса мала. Хотя мне вот каждый раз приходится переводить Aliexpress на английский, чтобы понять, что имел в виду автор… В художественной и научной литературе его не будет ещё очень много лет хотя из-за безумного багажа контекста, который существует только в головах у людей.
— версия гугл перводчика 1.0 — отстой
— версия 2.0 гул переводчика отстой
…
— версия 5.0 гулгл переводчика отсстой, потому что я лучше перевел строчку из Онегина чем он
— вы находитесь здесь
— версия гугл переводчика 6.0 отстой потому что я страдательный залог 3-го лица в 25-ом абзаце на таджикском перевел более лучше (как мне кажется)
— версия гугл 7.0 отстой потому что in Ukraine переводит «в Украине», а я упорно пишу «на», как научили великий дедушка ленин и маленький дедушка путин
По теме статьи в целом — синхронных переводчиков и переводчиков художественной литературы Google Translate (пока) не заменит, да. Но для рынка технического перевода, нишу платных переводов GT однозначно подпортил весьма сильно. Это еще одна копилка к тому, что роботы когда-нибудь заберут до 70% работы…
У Дугласа природный талант, солидная научная база и многолетний опыт нахождения контрпримеров, способных сломать вроде бы стройные системы знаний, причём он точно знает что такой приводящий к противоречию пример можно найти всегда.
PS: От Хофштадтера и его отца происходит фамилия Леонарда из «Теории Большого Взрыва» — автор статьи крайне неглупый человек.
Статья переведена с помощью ГТ бадумтсс
Слай конечно молодец, по опечаткам видно, что переводит вручную, но он афаик давно живёт "там", и статью, написанную в американском стиле изложения, оставляет в этом же стиле. Ему — нормально, а мне, думающему на другом родном языке, подобные конструкции совершенно неудобно читать. И ГТ этому тоже сейчас никак не поможет.
По-моему, перевод — невероятно утончённое искусство, постоянно требующее многих лет опыта и творческого воображение. Если в один «прекрасный» день люди-переводчики станут реликвиями прошлого, моё уважение к человеческому разуму будет поколеблено, и этот шок оставит меня в невероятном смятении и грусти.
Очень несогласен. Когда компьютеры смогут переводить текст семантически правильно и читаемо человеком, это будет как раз показ того, насколько человеческий ум продвинулся и решил такую сложную проблему.
Байязычная машина ничего не читает — не в человеческом смысле глагола «читать». Она обрабатывает текст. Обрабатываемые символы не связаны с мирским опытом. У неё нет ни памяти, из которой можно что-либо черпать, ни воображения, ни понимания, ни смысла, скрывающегося за словами, которыми она так быстро оперирует.
Это не верно. Огромная отрасль в научной областе работает над тем, чтобы научить машину «читать» в полном смысле этого слово, и у них есть успехи.
Перевод текста по сути включает в себя две большие проблемы, которые до сих пор не решены — парсинг языка и генерация языка. Гугл это решает с помощью нейронной сети, которая мапит предложения из исходного языка в нужный. Но этот способ далеко не на острие науки. Это один из наименее ресурсоёмких и быстрых способов перевода, и поэтому гугл его использует. На самом же деле существуют и другие способы, которые завязаны на «понимание» смысла текста.
Компьютеры обязательно смогут в будущем переводить текст красиво, вопрос только — когда. Многие учёные уже достигли вполне неплохих результатов в генерации. Через несколько лет вероятно эти способы будут использованы в переводе.
В простой речи более менее адекватно можно перевести порядка половины фраз. Если ты профессиональный переводчик со значительным опытом перевода с японского, либо же у тебя есть время думать несколько часов над каждой фразой, то из оставшейся половины получится перевести ещё половину, т. е. суммарно порядка 75% фраз. Как итог, если перевод не под силу даже человеку, то думать, что это когда-либо удастся машине — глупо.
Сложностей перевода много:
— Большое количество слов, которых просто нет в русском языке.
— В каждой фразе говорится какой-то факт, а также вкладываются какие-то чувства. Но когда мы переводим этот факт на другой язык, во фразу уже могут быть вложены вообще противоположные чувства, и такой перевод будет абсолютно неверным. Исправить это обычно невозможно, разве что слегка сгладить.
— Полностью отличается грамматика, из-за чего сказать тоже самое на русском зачастую невозможно.
— В японском много всяких оттенков, частиц и гоби, влияющих на выражение эмоций, оттенков и т. д., что переводить вообще нереально.
— Много инфы берётся из контекста, но на русском мы обязаны указать в предложении и подлежащее, и сказуемое, и дополнение и всё остальное. Но что, если они неизвестны и не упомянуты в оригинале? (для японского это вполне стандартная ситуация)
— И много других проблем, влияющих на возможность перевода.
Но научные или энциклопедические статьи, инструкции, документацию и т. д. переводить конечно намного легче:
— Там достаточно перевести только факты.
— Там не вложены никакие чувства, а если и вложены, то перевести их легко.
— Там допустимо объяснять значение слов, отсутствующих в русском языке.
— Там допустима сколь угодно большая разница в длине предложений.
— Там не требуется перевод никаких оттенков.
— Там отсутствуют культуро-зависимые моменты.
Недалёкость Google Translate