Как переводить документ в Word и не париться с форматированием? Как не переводить одно и то же? Как сохранять единообразие? Как не покупать дорогие программы? Как работать эффективно и быстро?
Если вы знакомы с Trados, MemoQ или CrowdIn, переходите сразу к инструкции по установке. Если же это новые для вас слова — добро пожаловать в прекрасный мир Computer Aided Translation.
- О переводе с помощью компьютера
- Какие бывают CAT-программы?
- Что умеет OmegaT?
- Установка
- Проверка правописания
- Как создать проект
- Что это за папки?
- Как добавить файлы
- Интерфейс
- Как переводить
- Нечёткие совпадения Fuzzy Matches
- Автоматический перевод одинаковых сегментов
- Глоссарий
- Как сохранить файлы
- Подключаем машинный перевод
- Проверяем на ошибки
- Открываем и редактируем TMX
- Создаём ТМX
- Считаем объём проекта
- Объединяем и разделяем сегменты
О переводе с помощью компьютера
Google Translate — машинный перевод, компьютер переводит за вас. CAT — принцип работы, когда компьютер только помогает в работе, автоматизируя рутинные процессы.
CAT-программы разделяют исходный текст на сегменты — строки, предложения, параграфы или абзацы. Человек переводит сегмент один за другим, а перевод сохраняется в специальную базу данных — память перевода (translation memory, TM). Если переводчику встретится похожий сегмент, программа покажет подсказку или возможный перевод. А одинаковые сегменты программа может переводить сама.
Особенно хорошо CAT помогает в переводе инструкций, юридических документов, интерфейсов программ — там, где похожие формулировки встречаются очень часто. В художественном переводе помощь будет не так очевидна, но об этом позже.
Чем больше текстов по схожей тематике вы переводите, тем больше накапливается переводов в базе данных, чаще появляются подсказки. За годы может накопиться такая база, что в новом документе половина перевода будет готова «сама по себе».
Когда перевод закончен, программа создаёт документ, идентичный оригиналу — сохраняя структуру и форматирование, но заменяя исходный текст на ваш перевод.
CAT-программы не изменяют исходный документ, поэтому необратимо испортить документ невозможно. На выходе будет полностью переведённый файл.
Какие бывают CAT-программы?
Разные. Trados, MemoQ — дорогие корпоративные комплексы, устанавливаются на компьютер. CrowdIn, Tolmach и другие — работают прямо в браузере. Как правило, всё стоит денег, либо есть ограничения по объёму проектов.
Но не всё так плохо: я уже лет восемь пользуюсь OmegaT, бесплатной программой с открытым исходным кодом, которая работает на Windows, Mac и Linux-системах и постоянно совершенствуется сообществом. Работаю в ней с китайским, английским и русским языками.
Что умеет OmegaT?
 OmegaT
OmegaTwww.omegat.org
Freeware (GPLv3), open source
Windows, macOS, Linux
Умеет всё, что описано в первой главе — помогать переводчику в работе, и разные другие мелочи.
Форматы файлов
- Microsoft Word, Excel, PowerPoint (только новые .xlsx, .docx и *.pptx, старые нужно сначала сконвертировать)
- OpenOffice .ods, .odt и прочие
- Текстовые файлы .txt, .rtf
- Текстовые файлы структуры key=value (*.ini и подобные)
- HTML
- Файлы с XML-структурой (можно настроить самому)
- И многие другие.
Языки
Любые. Практически всё, что есть в Unicode. Для редких языков может понадобиться корректировка правил сегментирования, но всё решается.
Я не буду пересказывать инструкцию. Она полная и содержательная, и ознакомиться с ней очень важно. Дальше будут лишь основные операции с программой, которые помогут начать работу.
Установка
Скачайте дистрибутив с сайта omegat.org. Я буду использовать англоязычную версию 4.1.1 ветки Latest для Windows. Для запуска требуется Java. Если не уверены, есть ли она у вас, качайте версию с пометкой JRE. Не пугайтесь надписи Beta, программа работает более чем стабильно.
Проверка правописания
После установки программа готова к работе, но по-умолчанию не хватает проверки орфографии.
- Запускаем OmegaT
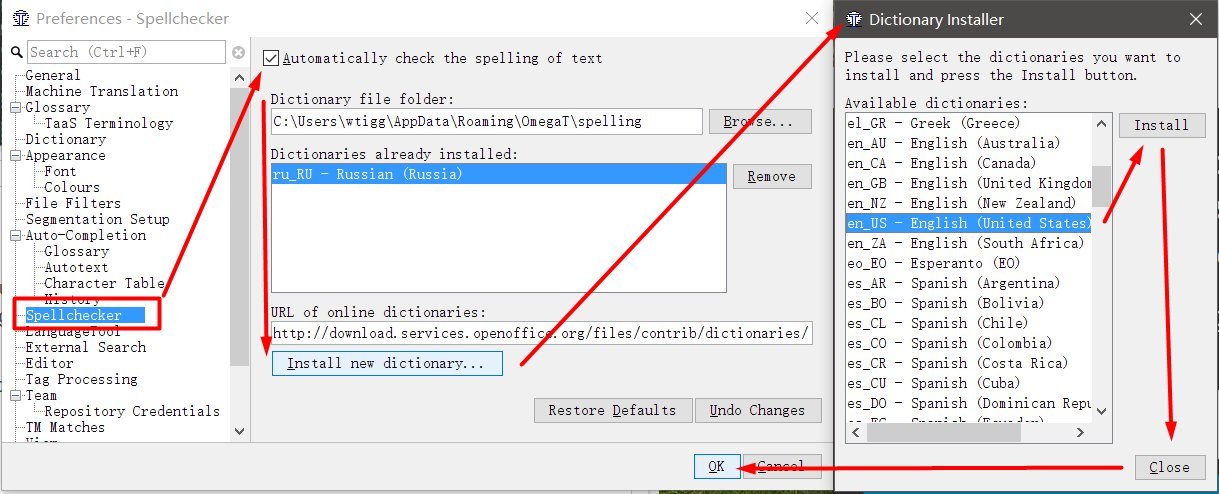
- Переходим в Options → Preferences → Spellchecker
- Ставим галку Automatically check the spelling of text
- Нажимаем Install new dictionary
- Выбираем язык (например, ru_RU для русского), нажимаем Install
- Жмём Close. В списке видим русский язык.
- Выходим из настроек.
Как создать проект
OmegaT работает не с отдельными файлами, а с «проектами». Проект — набор папок с определённой структурой. Чтобы перевести файл, нужно создать проект, а потом добавить туда файл.
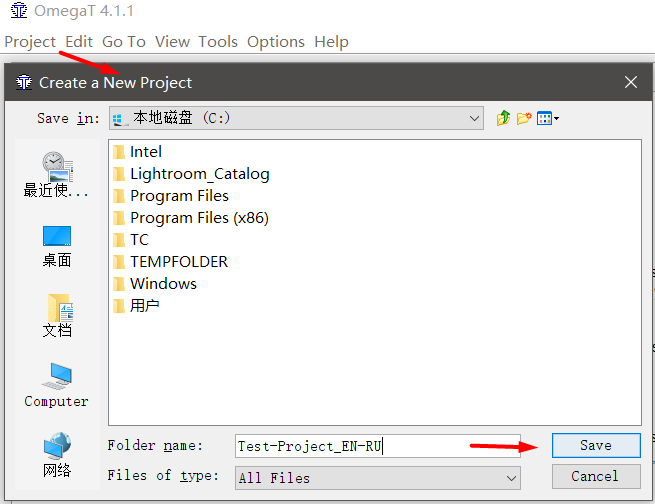
- Запускаем OmegaT
- Project → New, выбираем место для сохранения и имя проекта. Я рекомендую давать проектам осмысленные имена и указывать в них языковую пару. Например, Test-Project_EN-RU.

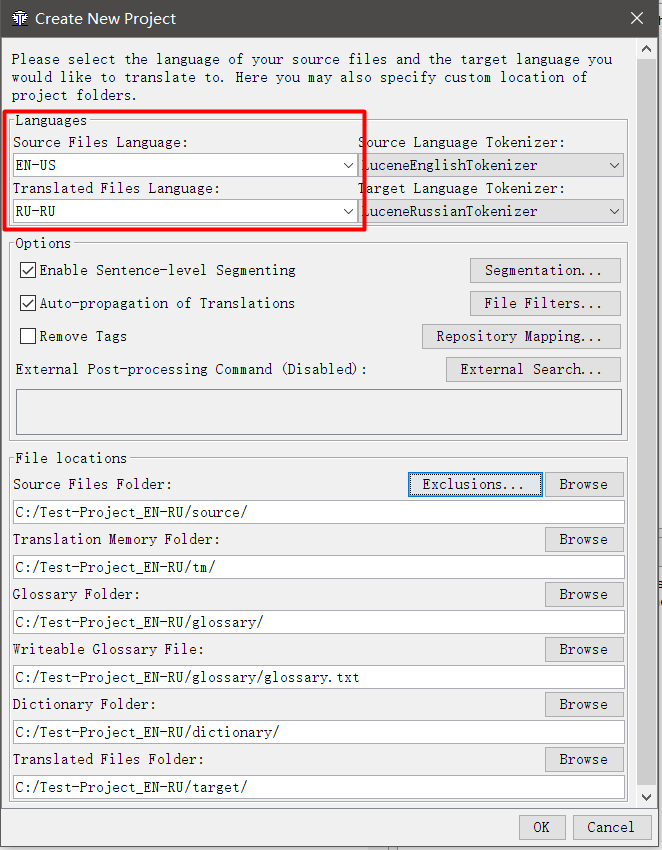
- В появившемся окне укажите языковую пару
Source Files Language — язык, с которого вы переводите; Target Files Language — язык, на который вы переводите. Указывать нужно в двух- или четырёх-буквенном коде. Например, RU — русский язык, а RU-RU и RU-BY — уточнение, что это русский из РФ и русский из Белорусии. Чтобы работала проверка правописания, код должен совпадать с кодом, указанным в настройках орфографии (если в орфографии установлен RU-RU, а в проекте будет RU, то проверка работать не будет).
- Ниже отметьте галочки Enable Sentence-level Segmenting (делить сегменты по предложениям, а не по абзацам) и Auto-propagation of Translations (подставлять переводы автоматически). Галочку Remove Tags (убирать теги) лучше снять, я объясню её работу позже.

- Нажимаем ОК.
Что это за папки?
Внутри папки проекта есть несколько под-директорий:
- dictionary — можно добавить словари в формате StarDict; функция довольно бесполезная.
- glossary — база терминов по проекту, об этом позже;
- omegat — память перевода и резервные копии проекта;
- source — папка с иходными файлами;
- target — папка, в которой будут появляться переводы;
- tm — папка для дополнительных памятей перевода, об этом позже.
А также файл omegat.project с конфигурацией текущего проекта.
Как добавить файлы
Создав проект, вы увидите такое окно:
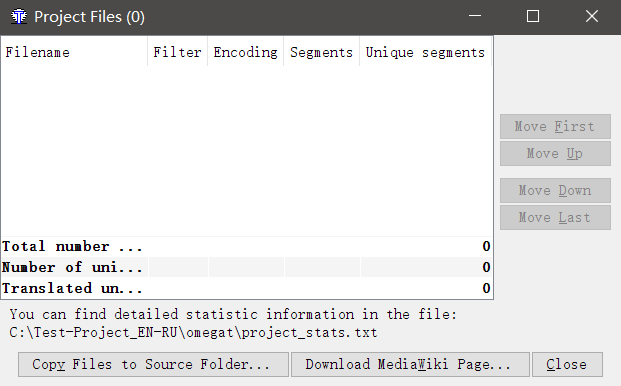
Нажмите Copy Files to Source Folder и выберите файлы, которые вы хотите перевести. Файлы будут скопированы в папку \source\ только что созданного проекта. Вы можете добавить туда файлы вручную. Просто скопируйте файлы в \source\ через проводник.
Для примера я создал два файла — Excel и Word, на которых я буду показывать работу OmegaT.
Интерфейс
OmegaT запущена, файлы добавлены. Давайте посмотрим, как они выглядят в программе.
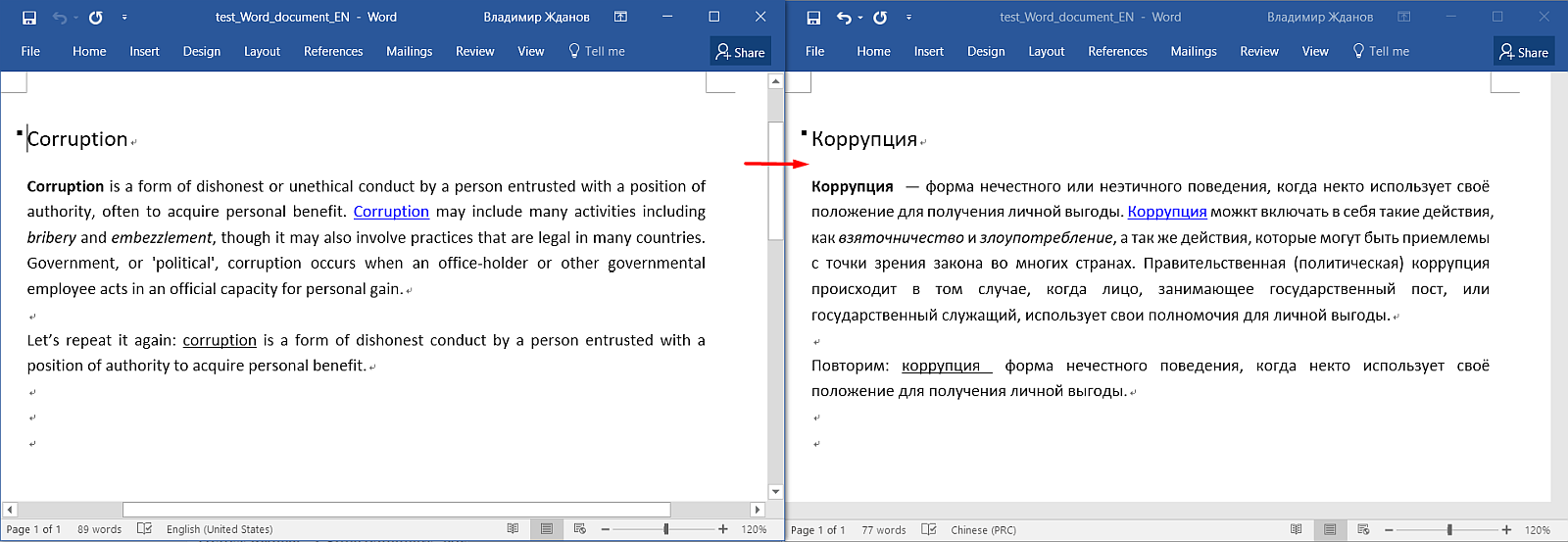
Вот исходный документ в Word. Здесь видны заголовок, абзацы, форматирование (жирный шрифт, ссылки, подчёркивания).

А вот как он выглядит в OmegaT:
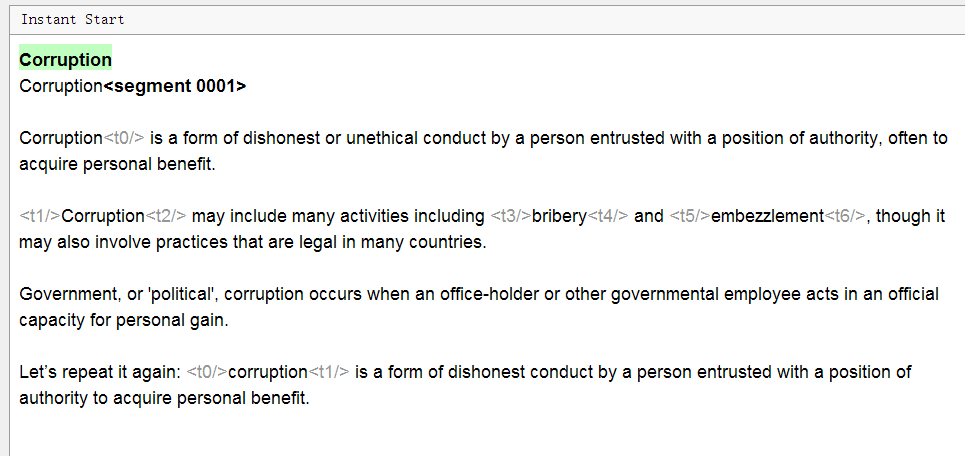
Обратите внимание: весь текст разделён на предложения, форматирования не видно, появились какие-то теги серого цвета, а заголовок заголовок дублируется. В чём дело?
- Текст разделился на сегменты
Каждое предолжение выделилось в отдельный сегмент. Правила сегментации можно настроить самостоятельно при необходимости. - Форматирование в OmegaT не видно, его заменяют теги
Они представляют собой сокращения тегов из Word, которые иначе могли выглядеть как <t>. Чтобы сохранить оригинальное форматирование, нужно оставлять эти теги как есть, вписывая перевод между тегами по той же логике, что и в оригинале.
Опция Remove tags в настройках проекта убирает теги вместе с форматированием. Не рекомендуется использовать, если важно сохранить оригинальное форматирование. - Заголовок не дублируется.
На самом деле, сверху (в зелёном цвете) всегда отображается текст на исходном языке, изменить его нельзя. Под ним находится текстовое поле, куда по-умолчанию скопирован тот же самый текст. Его нужно удалить и вписать перевод.
Кроме того, в правой части программы есть ещё два сектора: Fuzzy Matches и Glossary (словарь проекта).
Fuzzy Matches (нечёткие совпадения) — результаты поиска по базе данных проекта. Там будут отображаться подсказки по переводу, основанные на ваших предыдущих переводах.
Glossary (словарь проекта) — результат поиска по глоссарию, который вы составляете самостоятельно. В отличие от памяти перевода, это не готовый текст, а лишь подсказки по определённым терминам. Это мощный инструмент, который помогает сохранять единообразие в терминологии.
Как переводить
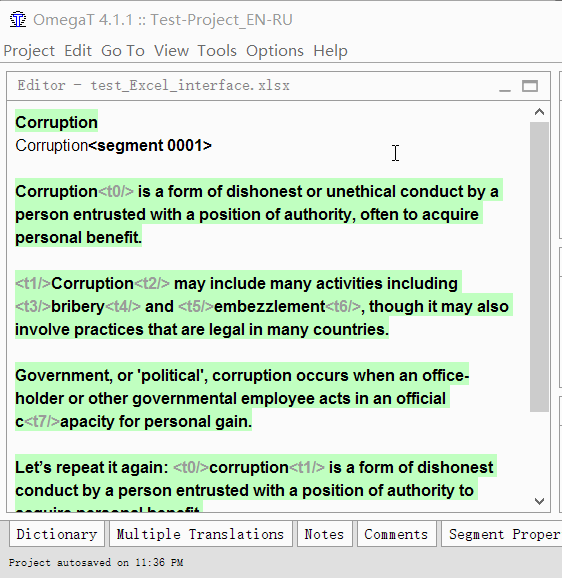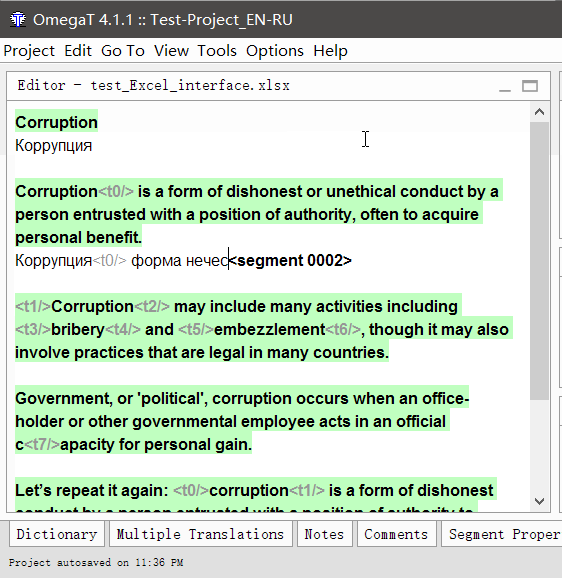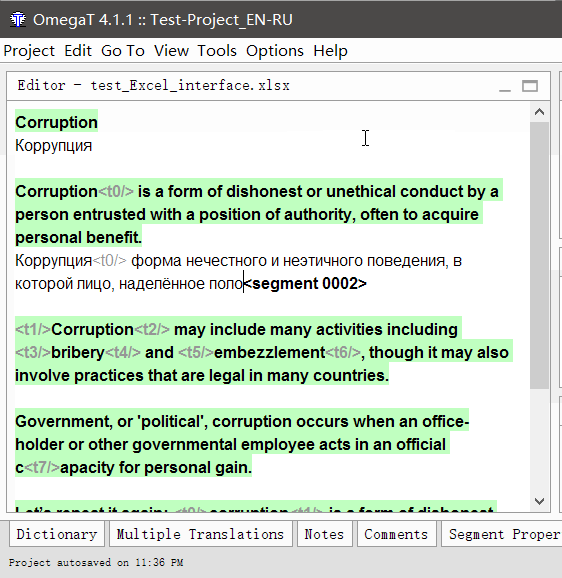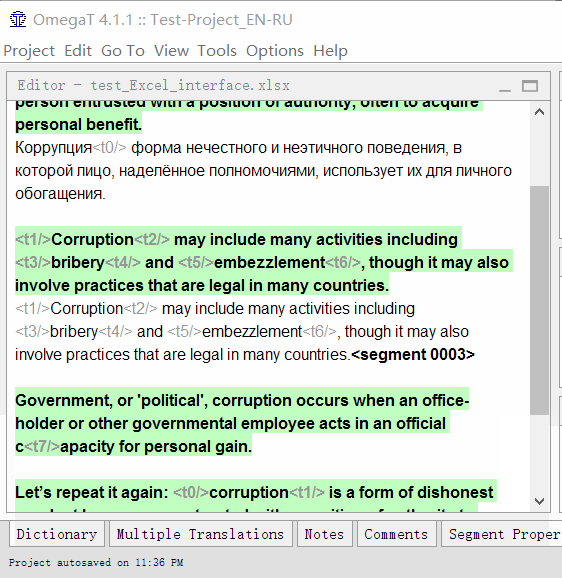
- Дважды кликните на сегмент для перевода
Под оригинальным текстом появится редактируемая текстовая строка, курсор будет в её начале, а в строке будет продублирован оригинальный текст. - Впишите свой перевод
- Нажмите Enter
При нажатии перевод сохранится, а курсор перейдёт к следующему сегменту.
Повторяйте, пока не закончите документ. В любой момент можно вернуться к предыдущему сегменту, просто дважды щёлкнув на него.
В правом нижнем углу есть удобный индикатор прогресса. Кликните на него, чтобы переключить режим просмотра.
 Текущий файл: % сегментов переведено (сегментов осталось) / Проект: % сегментов переведено (сегментов осталось), общее число сегментов.[/caption]
Текущий файл: % сегментов переведено (сегментов осталось) / Проект: % сегментов переведено (сегментов осталось), общее число сегментов.[/caption]В этой строке указано, что в текущем файле переведено 5,8% уникальных сегментов, осталось перевести ещё 1382. А суммарно в проекте переведено 63% сегментов, осталось 1756, а их общее число в проекте — 5979.
 Файл: переведено уникальных сегментов / общее число уникальных сегментов (проект: переведено уникальных сегментов / всего уникальных сегментов, всего сегментов в проекте)[/caption]
Файл: переведено уникальных сегментов / общее число уникальных сегментов (проект: переведено уникальных сегментов / всего уникальных сегментов, всего сегментов в проекте)[/caption]Во втором режиме на иллюстрации сказано, что в файле из 1592 уникальных сегментов переведено 146, а в проекте из 4748 уникальных сегментов переведено 2992. Всего сегментов (включая повторы) — 5979.
Цифры 14/14 в конце не относятся к счётчику проекта. Это — индикатор длины сегмента с которым вы работаете. Он говорит, что в оригинале было 14 символов, и в переводе их тоже 14. Эта функция полезна в тех случаях, когда нужно строго соблюдать длину строки, например при переводе интерфейса программ.
Нечёткие совпадения Fuzzy Matches
Самый главный инструмент любого CAT-приложения, ради этого они и существуют.
Объясню на примере:
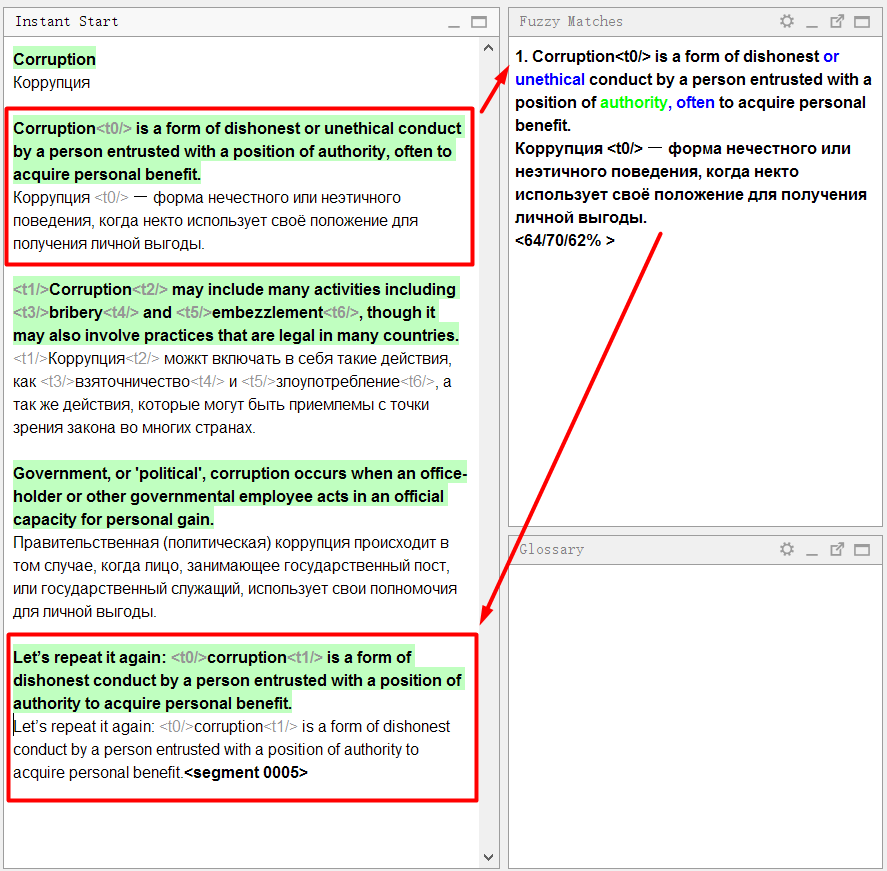
В документе-образце первое предложение очень похоже на четвёртое. Я шёл по порядку и перевёл первое предложение. Когда же я дошёл до четвёртого, программа сразу же показала нечёткое совпадение:
Посмотрите внимательно на панель совпадений:
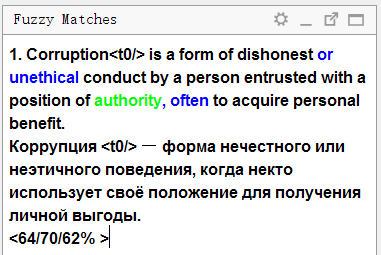
В верхней части отображается текст на исходном языке, который был сохранён в памяти перевода. Синим цветом выделны слова, которые присутствуют в памяти перевода, но отсутствуют в текущем предложении (с которым сравнивается совпадение), зелёным — слова, расположенные рядом с недостающими частями.
Ниже будет перевод, сохранённый в памяти. Если нажать Ctrl+R, то он скопируется в поле для перевода.
Ещё ниже указаны три числа в процентах. Они означают степень совпадения между предложением и памятью перевода. Подробнее о механизме вычислений можно прочитать в справке к OmegaT.
Автоматический перевод одинаковых сегментов
Конечно, если механизм Fuzzy Match найдёт 100% совпадение, он может вставить его самостоятельно. Для примера возьмём ещё один файл, на этот раз в Excel. Примерно в таком виде нередко приходит заказ на перевод интерфейса какого-нибудь сайта или программы.
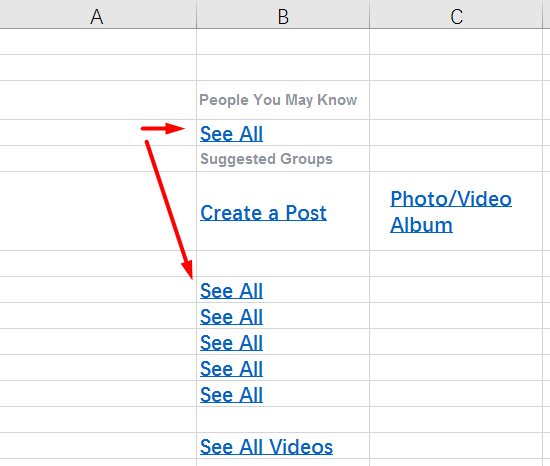
А вот как файл выглядит в OmegaT:
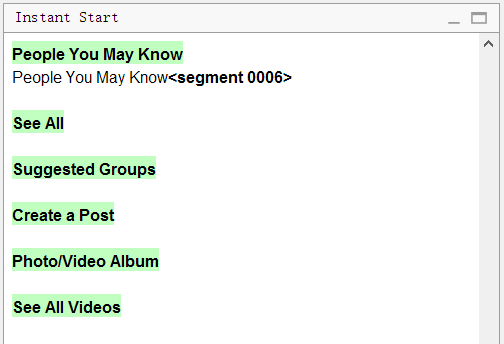
Обратите внимание, что в оригинале было шесть строчек See All. Программа убрала все дубликаты, оставив лишь одну строчку. Достаточно перевести её одну, и остальные сегменты тоже переведутся.
Глоссарий
Глоссарий работает очень просто. Сначала вы добавляете в него слова (оригинал и перевод). Теперь, когда слово встретится в тексте, в окошке Glossary сразу же отобразится подсказка.
Таким образом, когда в новом предложении появился какой-то термин, вы сразу будете знать, как именно следует его переводить. Например, если при переводе интерфейса программы всегда нужно писать «Хорошо» вместо «ОК», достаточно добавить в словарь слово «ОК» с переводом «Хорошо». Добавив несколько сотен слов в проект, вы значительно облегчите себе жизнь.
Чтобы добавить слово в глоссарий, выделите его, щёлкните правой кнопкой и выберите Add Glossary Entry.
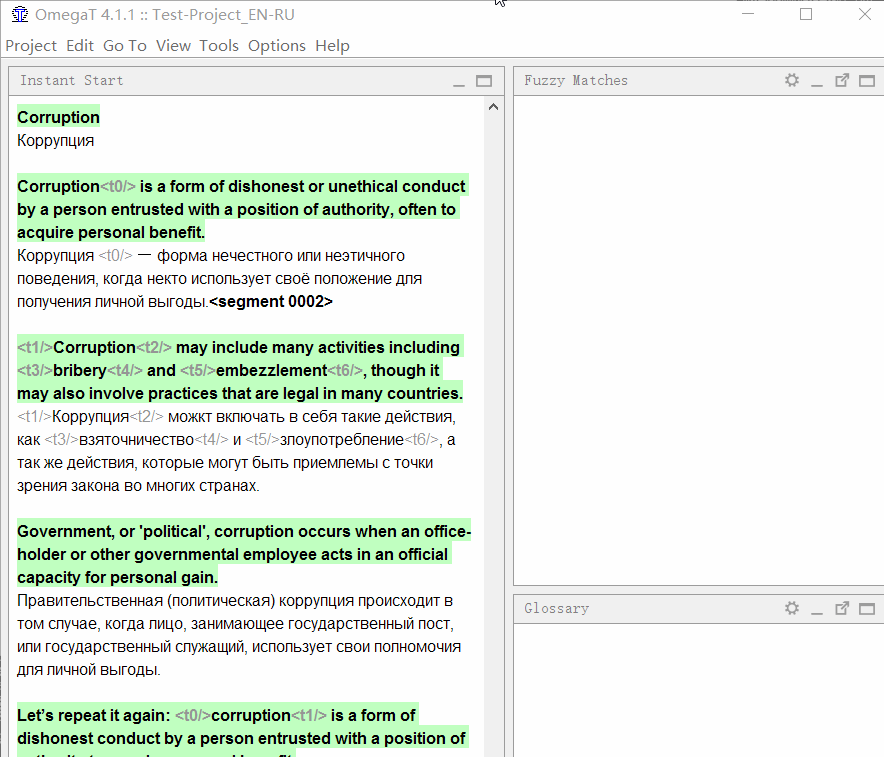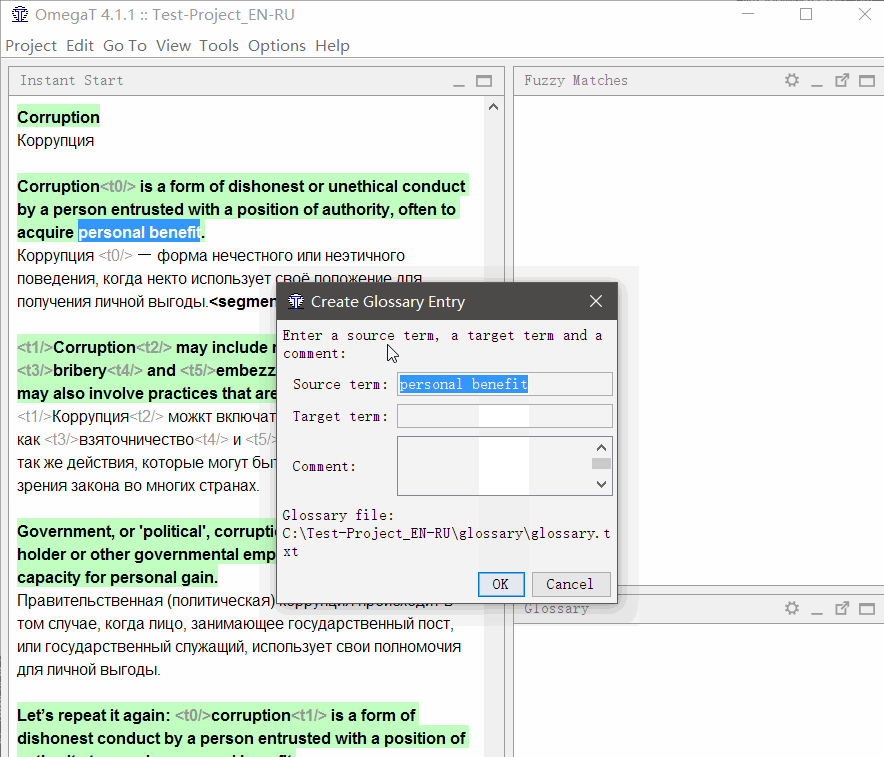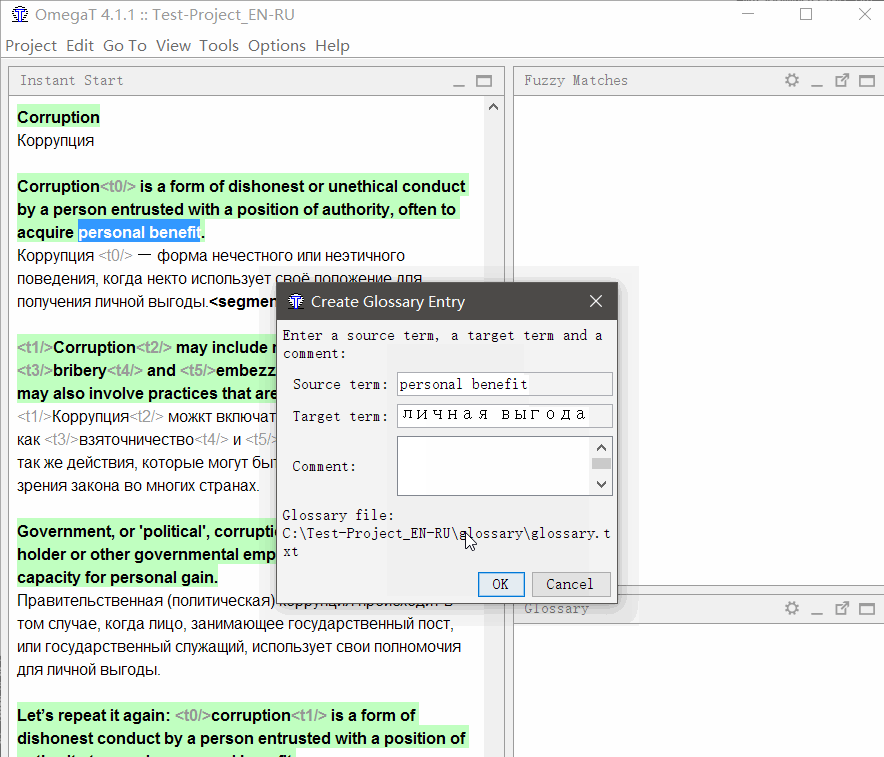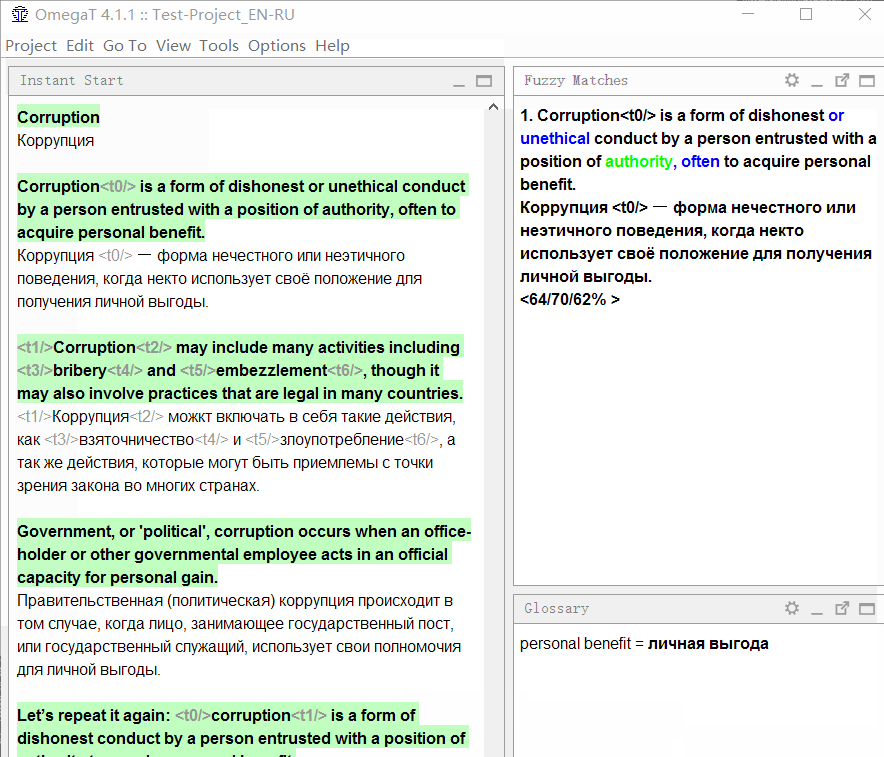
Кроме того, слова можно добавить массово в файл \glossary\glossary.txt в формате «оригинал табуляция перевод» (подойдёт таблица в Excel, сохранённая в формате tab-delimited *.csv)
Как сохранить
Пункт Project → Save означает «сохранение проекта», т.е. запись всех переводов в файл базы данных. А чтобы получить готовый файл, нужно выбрать Project → Create translated documents.
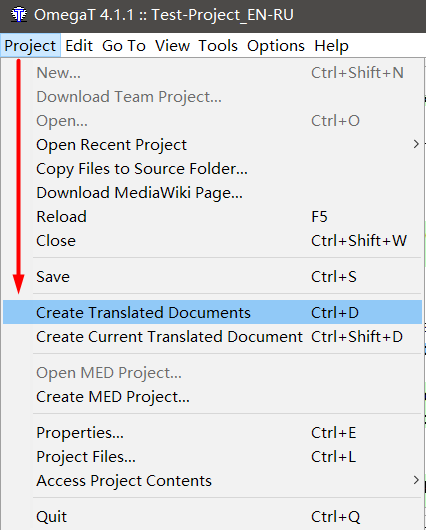
По этой команде OmegaT создаст новый файл в папке \target\ с тем же именем, что и оригинал, а весь текст поменяет на перевод. Если какие-то сегменты вы не перевели, то в файле на их месте будет оригинальный текст.
Как добавить машинный перевод
В некоторых ситуациях машинный перевод (такой, как Google Translate) может помочь переводить быстрее. OmegaT можно настроить таким образом, чтобы прямо в её интерфейсе отображался машинный перевод сегмента, который вы можете использовать напрямую или очень быстро редактировать.
В OmegaT можно подключить такие системы, как Google Translate, Microsoft Translator и Яндекс.Переводчик. За первые два придётся платить, а Яндекс.Переводчик предоставляет свои услуги бесплатно (в разумных пределах использования). Сейчас я расскажу, как это сделать.
- Зарегистрируйте аккаунт в Яндекс.
Например, заведите почту. - Перейдите на страницу разработчика в раздел «Переводчик» по этой ссылке.
- Нажмите Создать новый ключ, введите описание (для себя), нажмите Создать.
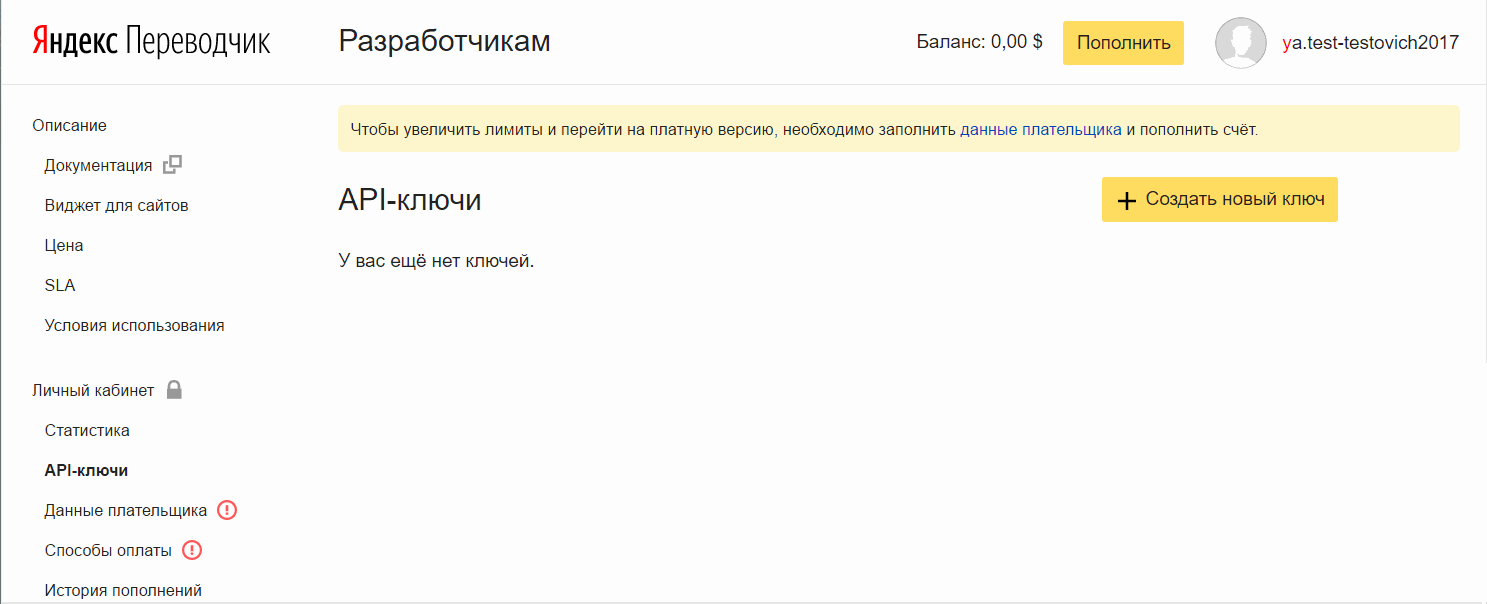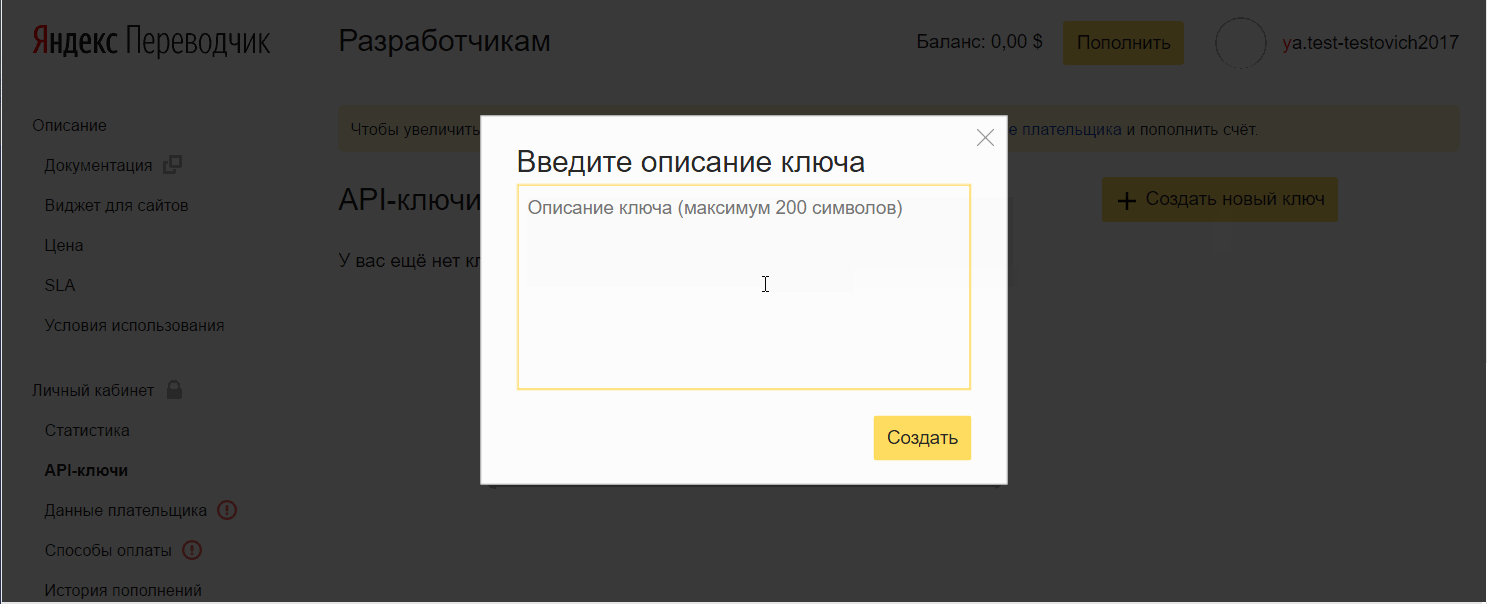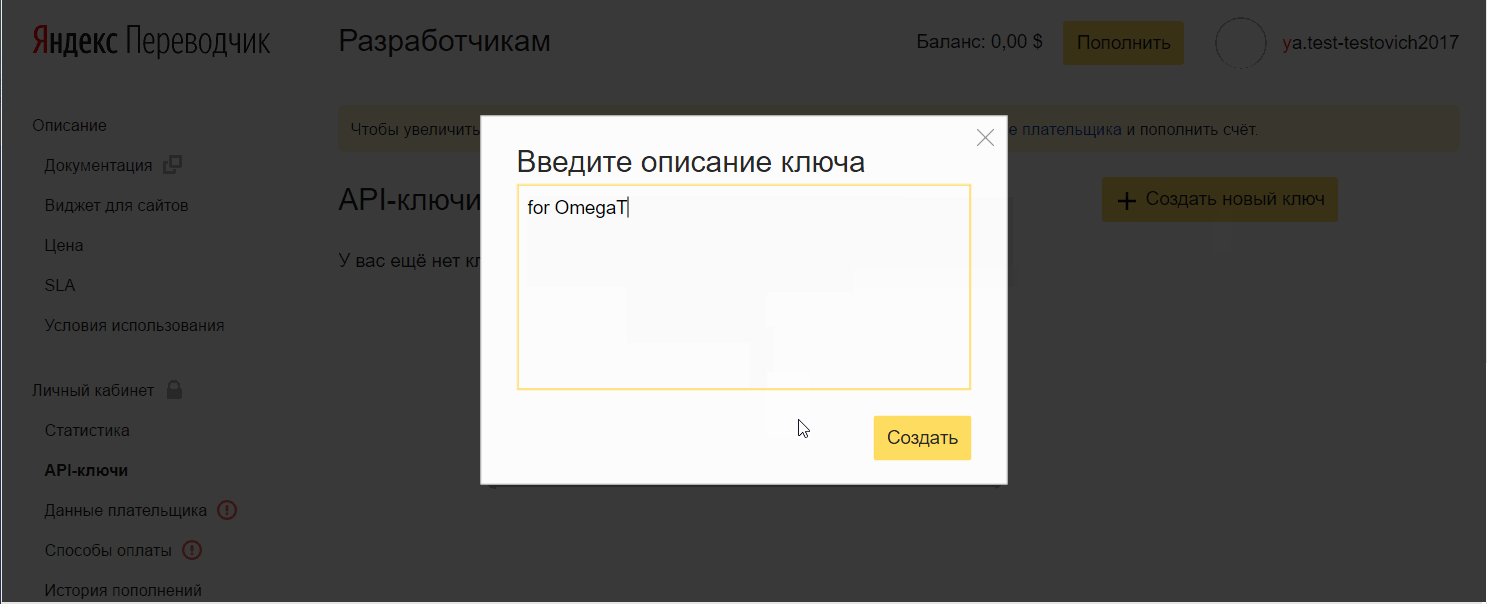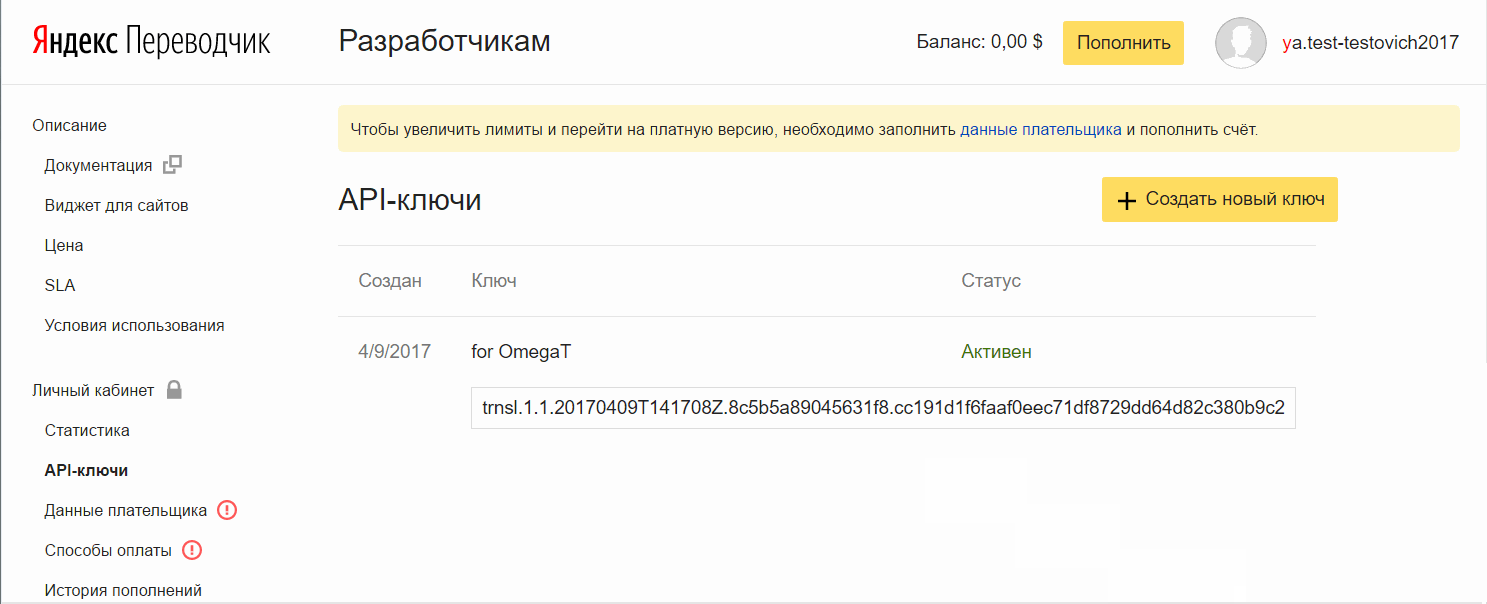
Добавим ключ в OmegaT:
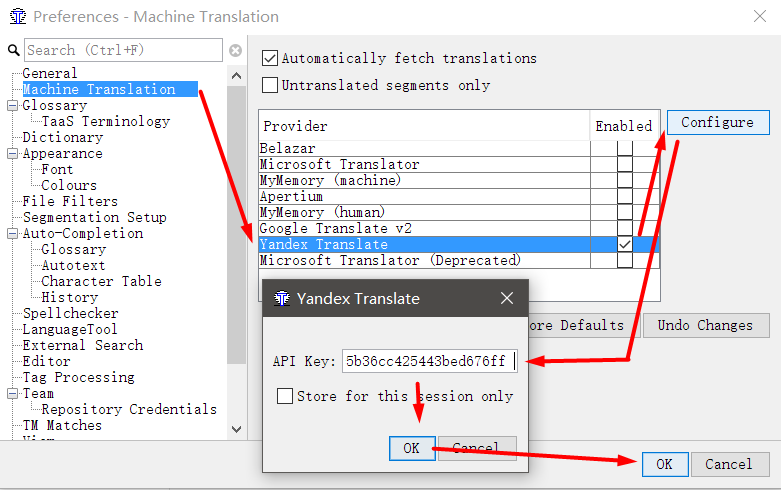
- В OmegaT перейдите в Options → Preferences → Machine Translation
- Выберите Yandex Translate, отметьте его галочкой и нажмите Configure
- Скопируйте API ключ в появившееся поле, нажмите ОК
- В появившемся окне можно задать пароль либо пропустить это действие.
Пароль нужен для того, чтобы защитить ваш API ключ. Актуально для платных переводческих систем.
Закройте настройки. Теперь в основном окне программы можно нажать на вкладку Machine Translations в нижней части окна. Чтобы окошко с машинным переводом всегда оставалось на виду, нажмите на небольшой значок с двумя окошками.
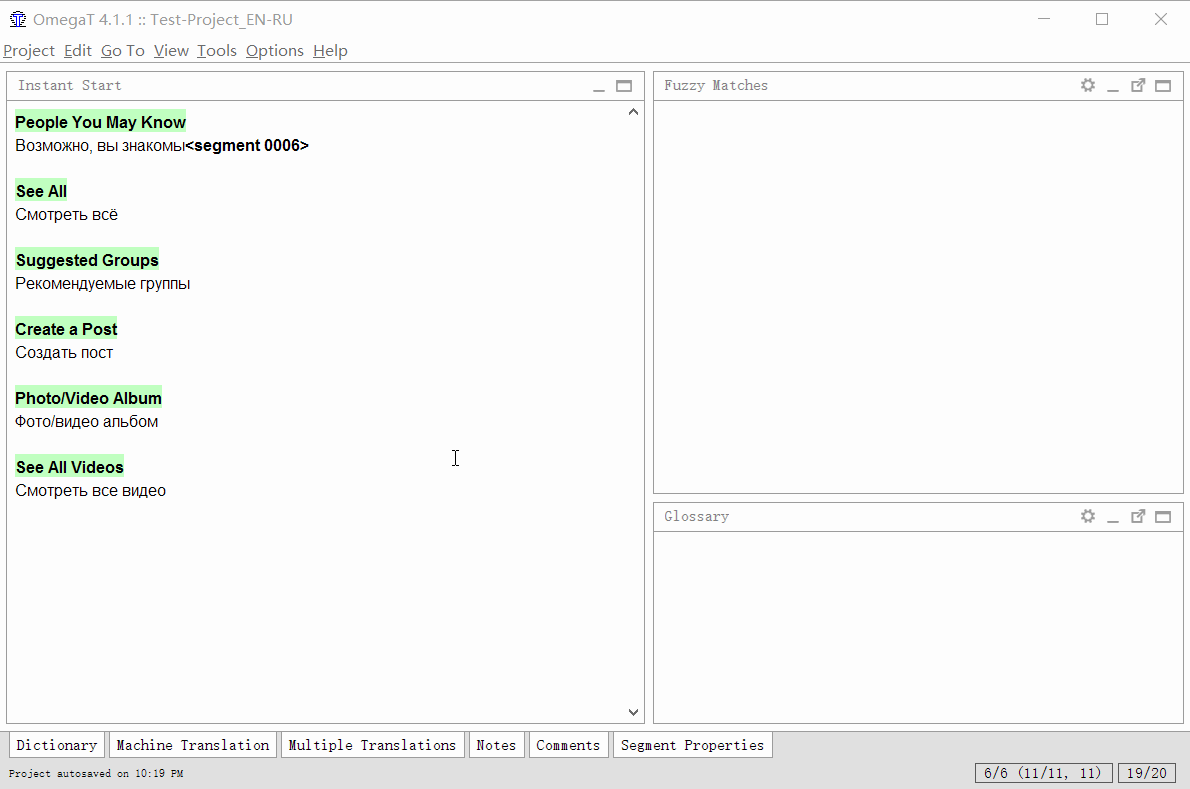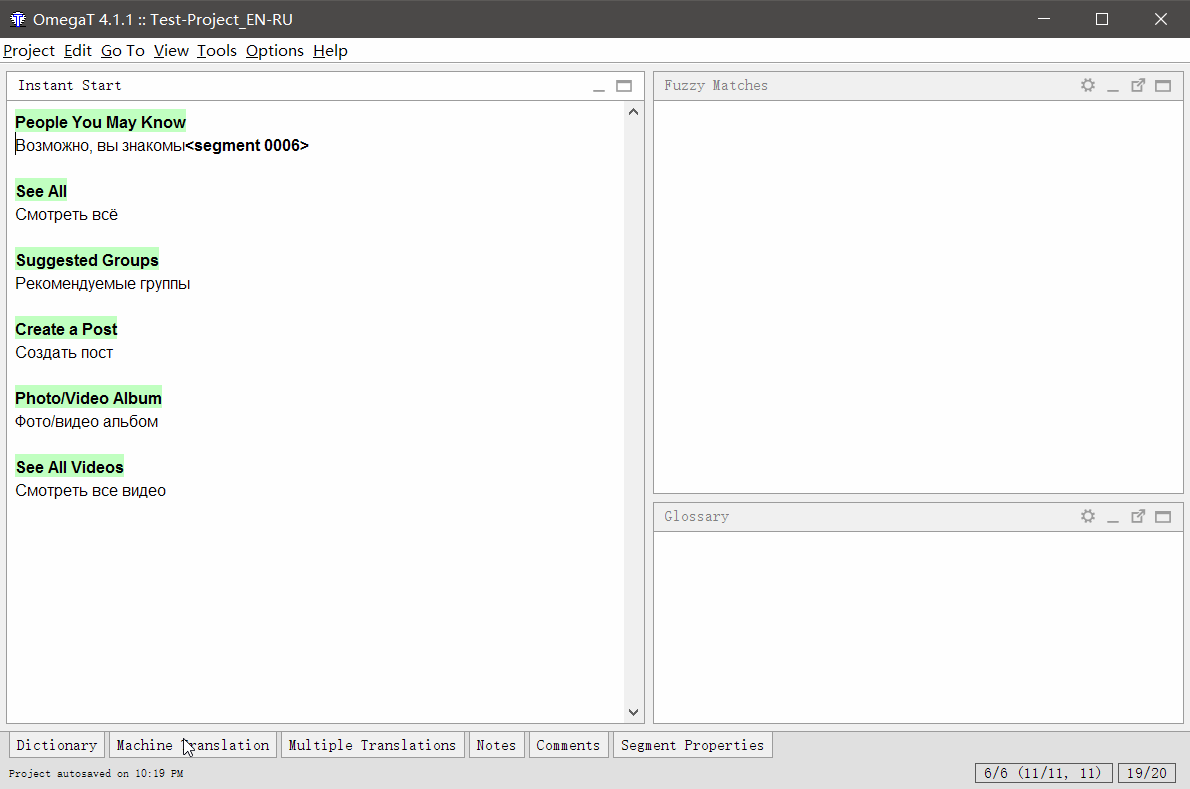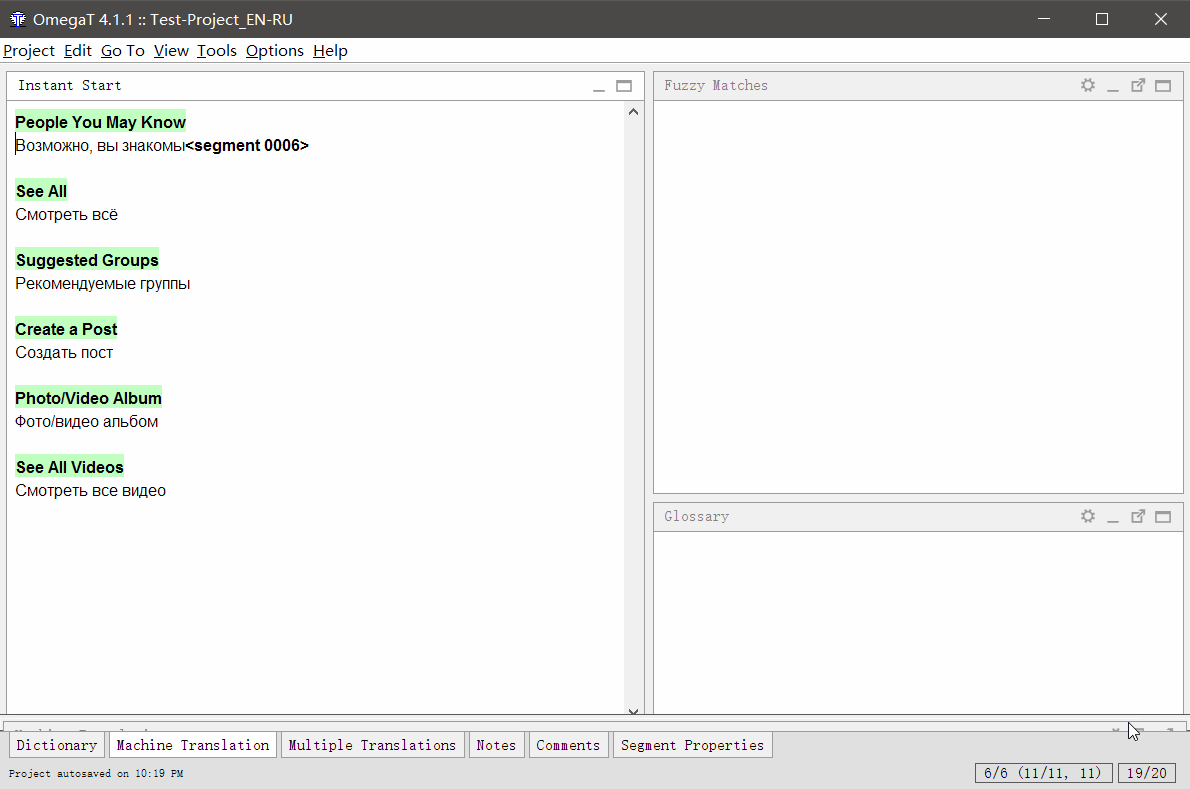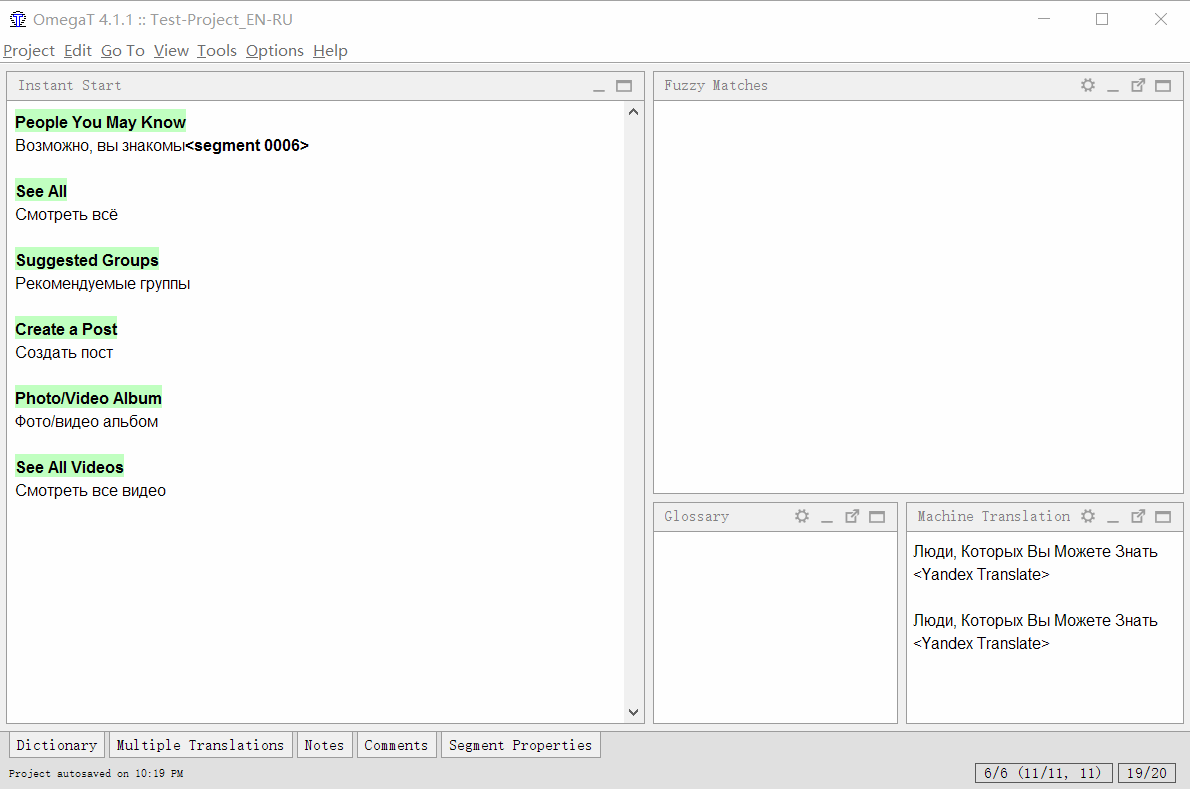
Теперь при переходе к новому сегменту программа сделает запрос к Яндекс.Переводчику, получит ответ и покажет его в окне. Горячей клавишей Ctrl+M можно вставить результат в поле перевода.
Как проверить текст на ошибки?
Кроме простой проверки орфографии, которую мы настроили ранее, можно проверить более сложные ошибки, от стилистики до пропущенных тегов. Для этого OmegaT использует открытый инструмент Language Tool. Он поставляется в комплекте с OmegaT, то можно установить отдельно, или подключиться к удалённому серверу.
- Tools → Check issues (или Ctrl+Shift+V)
- Дважды кликните на ошибке из списка, чтобы перейти к сегменту для редактирования.
По правому клику можно добавить слово в словарь, либо отключить проверку этого типа ошибок.
Слева в окне Check issues можно выбрать фильтр Tags. Он полезен в переводе документов с большим количеством тегов, сохранить которые очень важно — например, при локализации софта.
Совет: Если нужно сохранить теги любой ценой, OmegaT можно запретить создавать финальные документы при наличии ошибок в тегах. Делается это в Tools → Preferences → Tag Processing → Do not allow creating translated documents with tag issues.
Тонкая настройка Language Tool доступна через Tools → Preferences → LanguageTool. Здесь можно выбрать, использовать ли встроенный Language Tool, или подключиться к локальному/удалённому серверу. Ниже можно выбрать тип ошибок, на которые программа будет реагировать, например "Пунктуация" → "Пропущена запятая перед предлогом «И» в сложном предложении", или "Стиль" → "Разговорные слова".
Чем открыть память перевода TMX?
Бывает, что нужно посмотреть, что в файле *.tmx, или даже отредактировать его. Структура у файла довольно простая, и в крайнем случае можно обойтись блокнотом, но это не слишком удобно. OmegaT не может сама открыть TMX для редактирования: память перевода можно только добавить в проект, но не открыть её саму по себе.
Для Windows-пользователей подойдёт бесплатная утилита Olifant из пакета Okapi, скачать можно здесь.
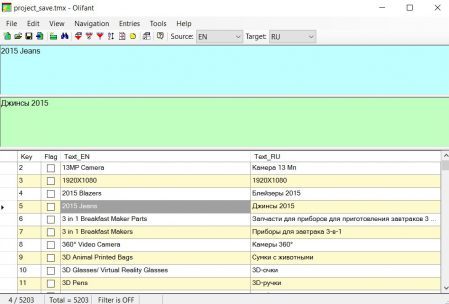
Не вижу смысла писать пошаговую инструкцию к этой программе, всё интуитивно понятно: File → Open, выбираем память перевода. В верхней части программы оригинал и перевод, в нижней — список всех сегментов.
Через File → TM Properties можно изменить свойства памяти перевода, такие как языковые пары, кодировку, и прочее.
Как создать свою ТМ?
Допустим, у вас уже есть качественный двуязычный файл, и вы хотите использовать его в проекте как справочный материал. Если файл в формате Excel, где в одном столбце оригинальный текст, а в ячейках напротив — соответствующий перевод, сделать ТМ очень просто.
Существует три способа, которыми я пользуюсь:
Olifant
Программа, о которой мы говорили в предыдущей главе, может не только открывать готовые TMX, но и создавать новые, а так же объединять несколько *.tmx в одну память.
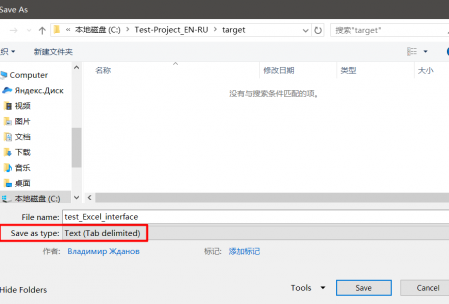
Установите и запустите Olifant, нажмите File → New и выберите язык исходника и язык перевода. Теперь добавим в новую память двуязычные сегменты: File → Import. Можно добавить файлы Wordfast, другие *.tmx или Tab-delimited files — другими словами, текстовый файл, где исходный фрагмент и его перевод разделены табуляцией.
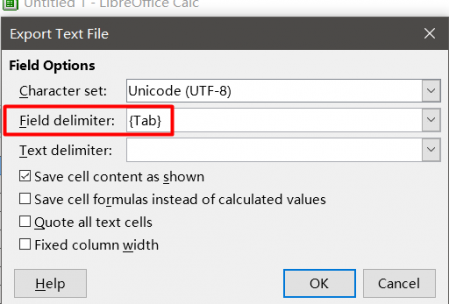
Tab-delimited файл можно создать в MS Excel или Libre Office Calc. Для этого создайте таблицу с двумя столбцами. В первом вставьте исходный текст, в ячейках напротив во втором столбце — перевод.
Сохраните файл в формате Tab-delimited text (в Microsoft Office), либо в Text CSV с параметрами Field delimiter = Tab, Character set = UTF-8 и Text delimiter = *пустой*, если вы используете Libre Office.
Когда импортируете все нужные фрагменты, просто сохраните через File → Save As в формате TMX.
OmegaT Aligner
В отличие от Olifant, источником служит не таблица с двумя столбцами, а два независимых файла с идентичной структурой, но на разных языках. Чем сложнее форматирование и чем больше отличий, тем хуже будет результат автоматического сопоставления, но его можно подправить вручную внутри Aligner.
Запустите OmegaT, откройте Tools → Align Files. Укажите языки оригинала и перевода, прикрепите файлы.
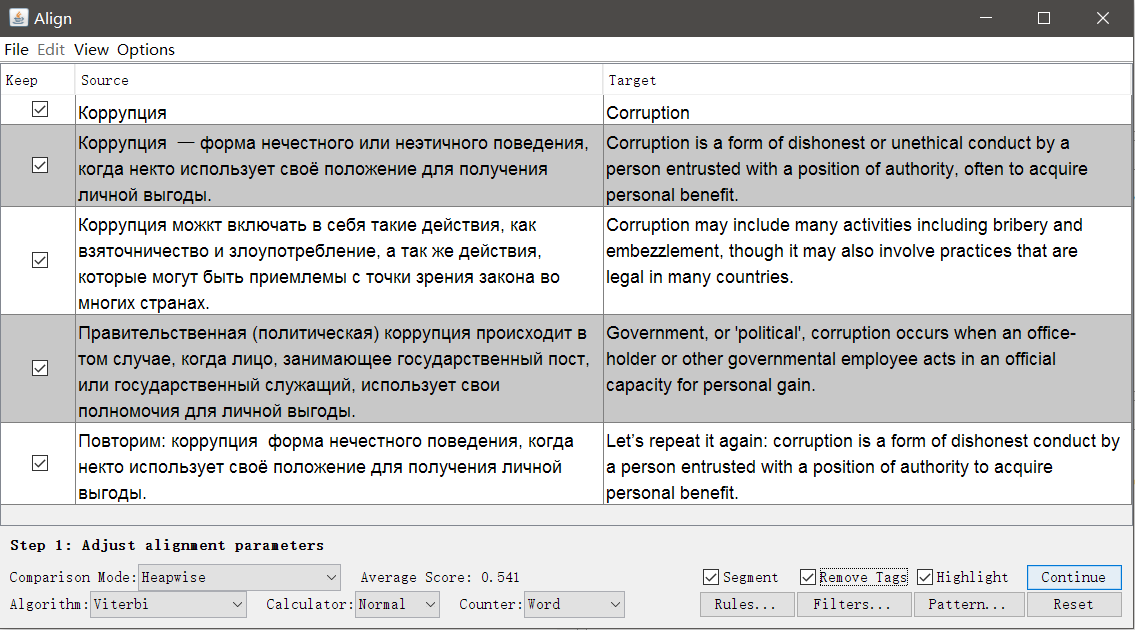
При необходимости можно убрать теги и изменить параметры сегментации. Нажмите Continue, и вы перейдёте к окну с ручной корректировкой сегментов: можно разбить, объединить или переместить сегменты вверх или вниз.
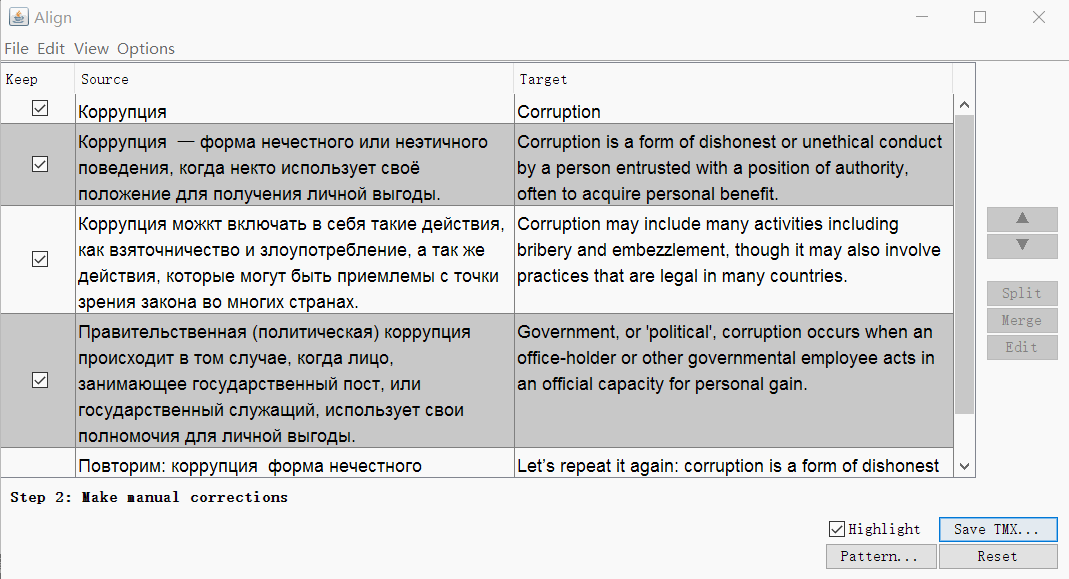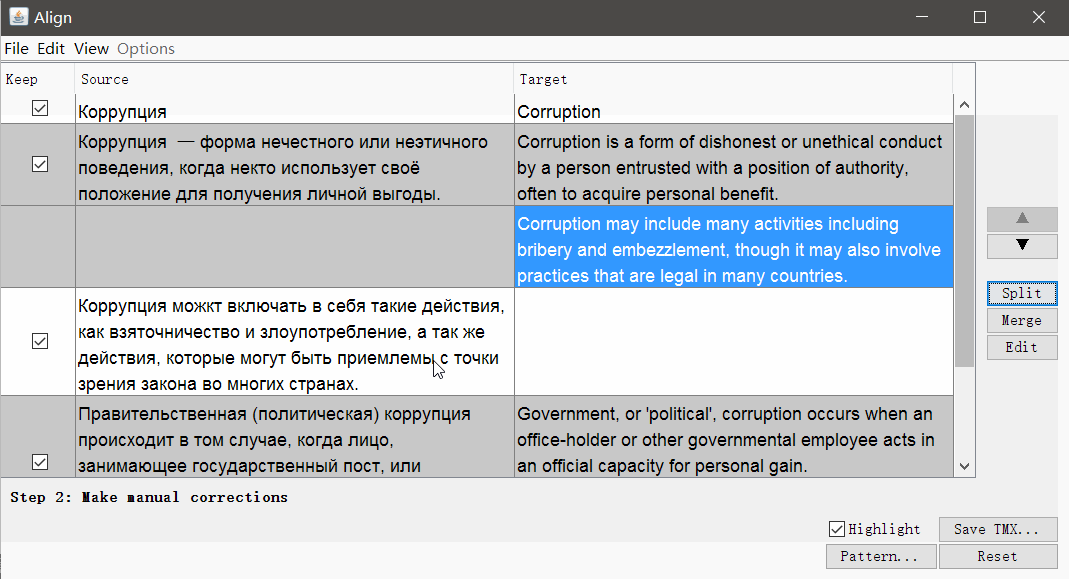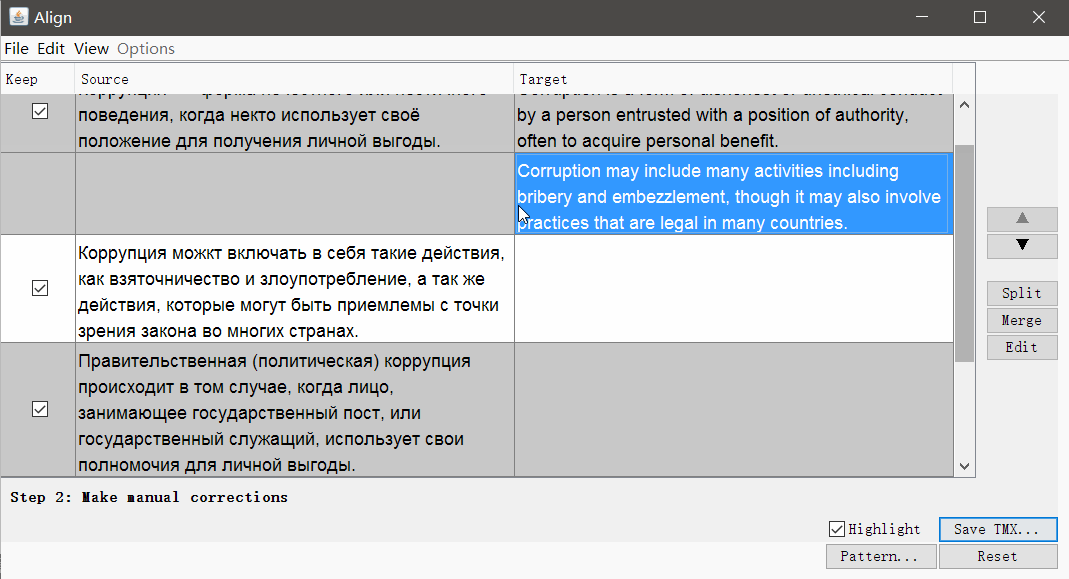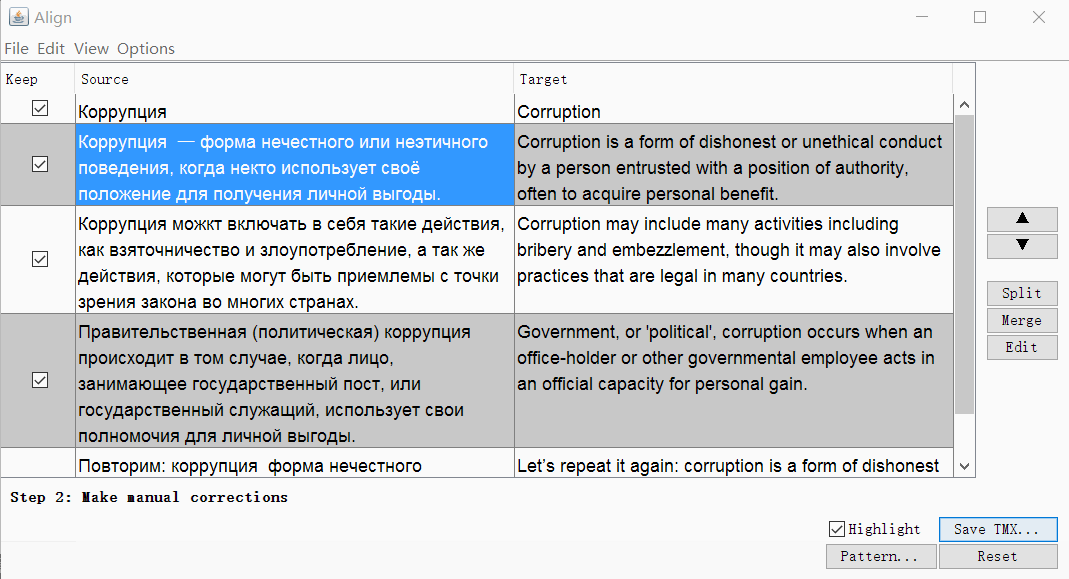
Когда всё выглядит хорошо, сохраните результат кнопкой Save TMX.
Translatum.gr
Работает аналогично Olifant, на входе нужно подать Excel-файл с двумя столбцами текста.
- Создайте новый файл Excel (обязательно *.xlsx)
- В первую колонку вставьте оригинальный текст, во вторую — перевод
Не используйте форматирование, оно не сохранится - Перейдите по ссылке конвертера
- Выберите созданный файл
- Укажите коды исходного и целевого языка
Например, если у вас англо-русский текст, это будет EN-US и RU-RU - Нажмите кнопку Submit
- Откроется страница, с которой вы сможете скачать архив с памятью перевода.
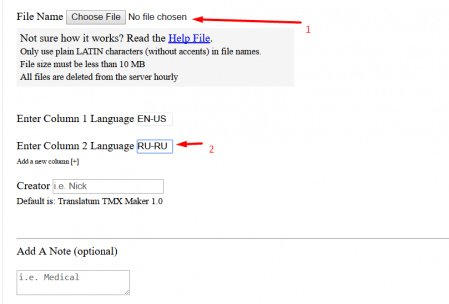
Чтобы использовать память перевода в проекте, распакуйте архив и поместите файл в папку проекта, поддиректория \tm\ (для отображения fuzzy matches) либо \tm\auto\ (для принудительного использования 100% совпадений).
Внимание!
Существует довольно неприятный баг при создании памяти перевода, где используются особые символы вроде ">", "<" и даже апострофов. TMX представляет из себя структуру XML, поэтому спец-символы, используемые в структуре документа, конвертируются в «безопасные» куски текста. Например, апостроф ' превратится в &pos; (амперсанд, pos и точка с запятой).
В некоторых ситуациях это может сильно замусорить память перевода. По правде говоря, решения этой проблемы я пока не нашёл.
Как посчитать объём проекта
Надо же сказать заказчикам, сколько вы возьмёте за перевод!
На самом деле, нет ничего проще. Откройте проект в OmegaT, перейдите в Tools → Statistics.
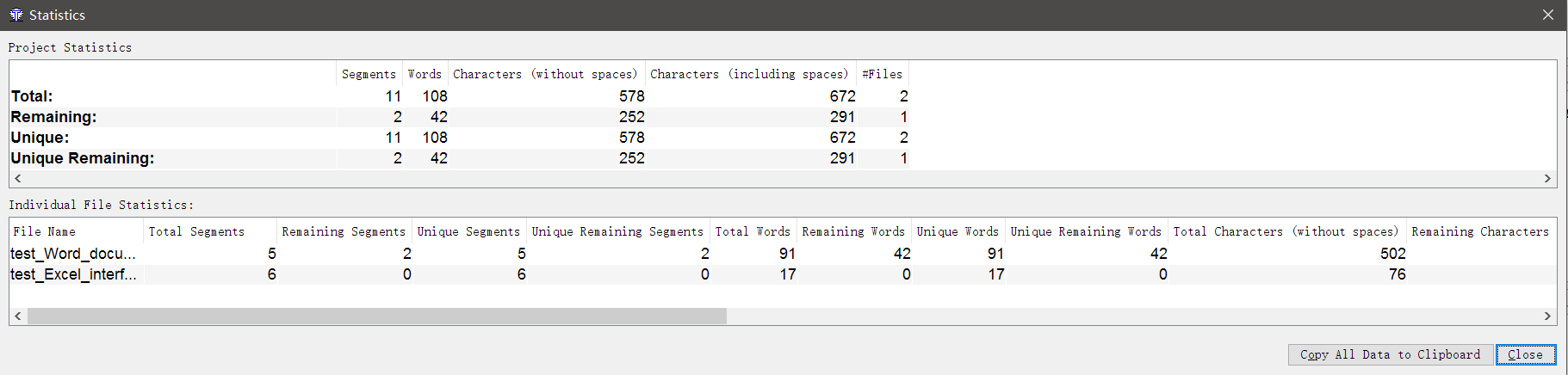
Здесь вы найдёте исчерпывающую информацию о том, сколько слов и символов в файлах, как много здесь повторов, сколько уже переведено и сколько осталось перевести, и так далее.
К сожалению, калькулятора стоимости перевода в OmegaT нет, вам придётся посчитать всё самостоятельно.
Как объединить и разделить сегменты?
Бывает, что вы хотите объединить два сегмента в один, или наоборот, заставить конкретный сегмент разделиться на две части. Если проблема встречается с большим количеством сегментов в проекте, то стоит перенастроить правила сегментации. Если же нужно точечно объединить или разделить сегменты, воспользуйтесь специальным скриптом Merge or split segments:
- Установите скрипт
Скачайте здесь, распакуйте в папку \scripts (в Windows это может быть С:\Program Files (x86)\OmegaT\scripts\) - Сделайте правила сегментации Project Specific
Project → Properties → Segmentation → отметьте галочку Make the segmentation rules project specific - Задайте скрипту кнопку
Tools → Scripting, в левой части окна найдите Merge or split segments, выделите его щелчком мыши, а затем нажмите правой кнопкой на одну из цифр в нижней части окна. Например, на единицу. И нажмите Add script.
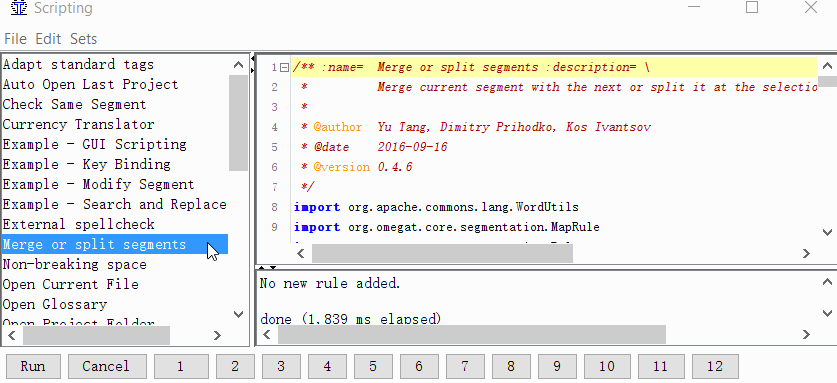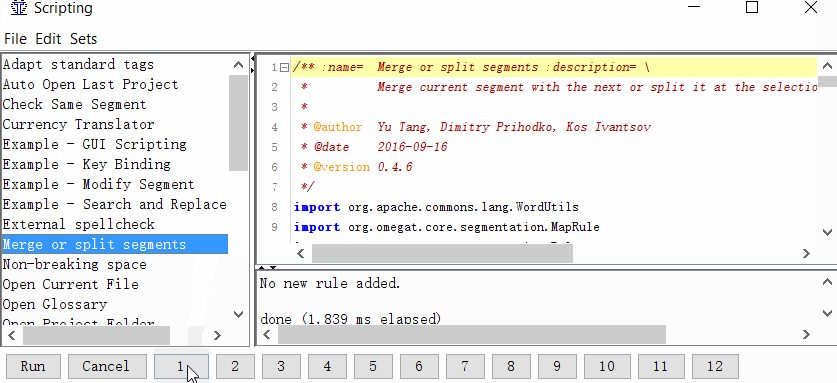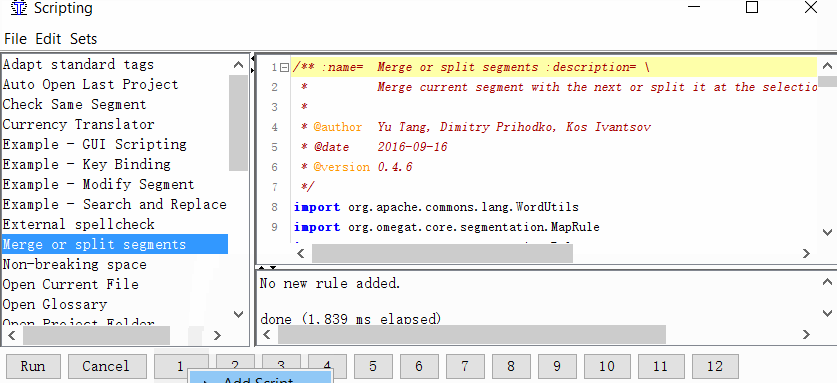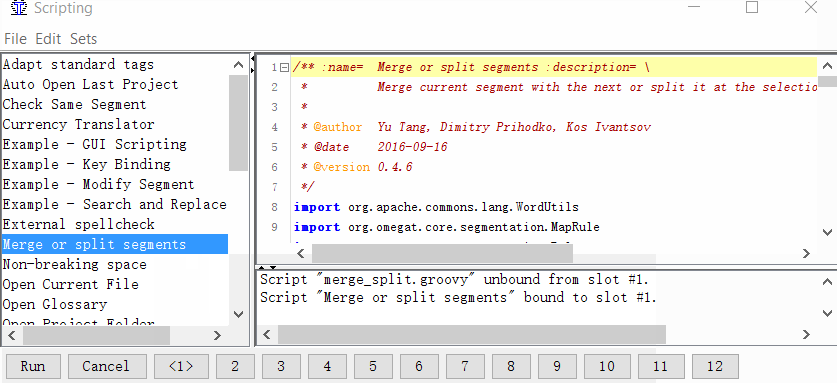
Теперь вы можете объединять или разделять сегменты.
Объединение
- Найдите два сегмента, идущих друг за другом, которые вы хотите объединить;
- Перейдите к первому сегменту;
- Нажмите Tools → 1. Merge or split segments
Программа покажет предупреждение с результатом объединения. Можете нажать ОК для объединения, или отменить действие.
Разделение
- Найдите сегмент, который вы хотите разделить;
- В исходном тексте сегмента (над переводом) выделите вторую половину текста (от середины и до самого конца), которую вы хотите сделать отдельным сегментов;
- Нажмите Tools → 1. Merge or split segments
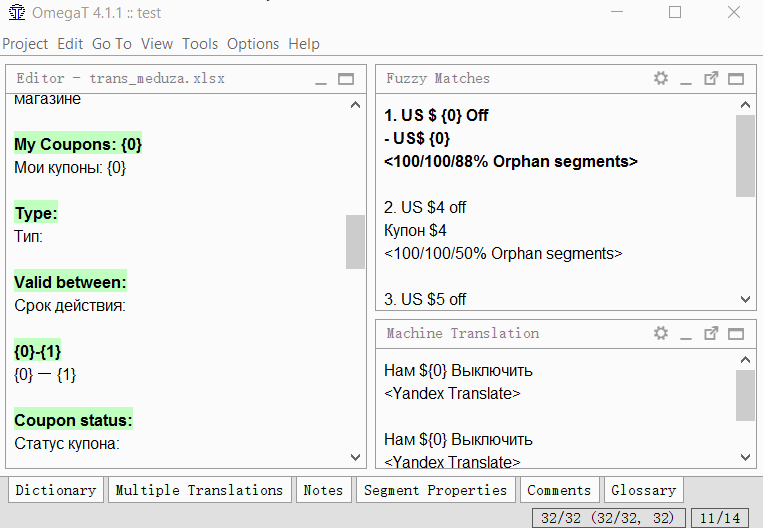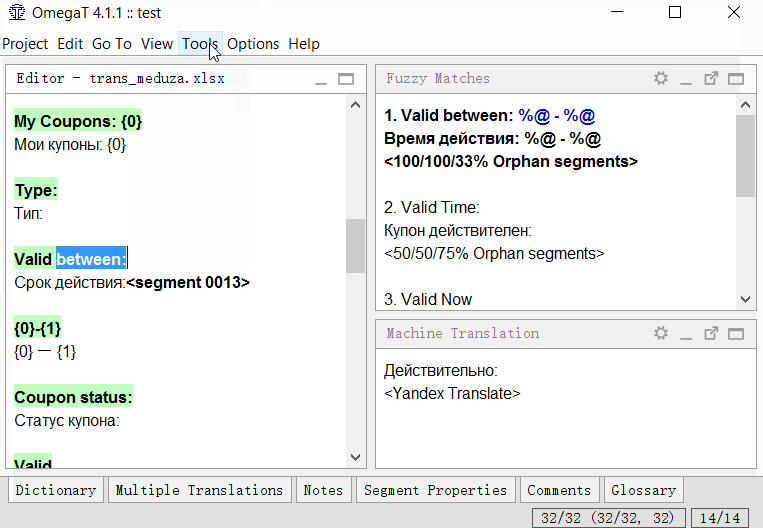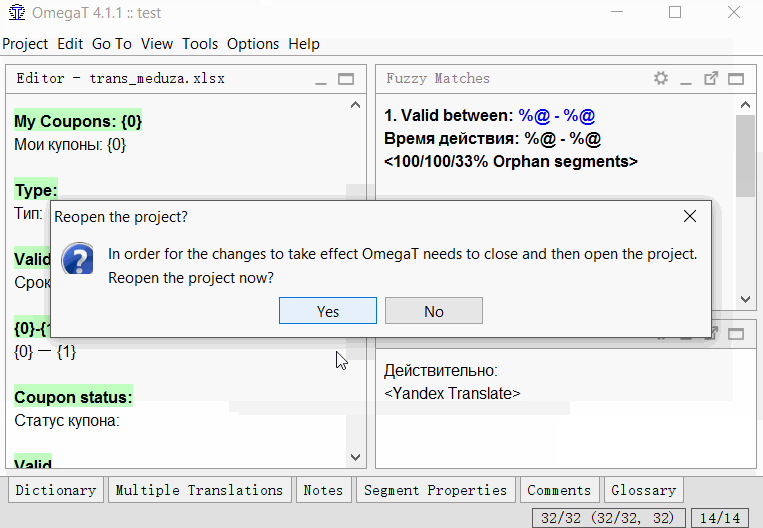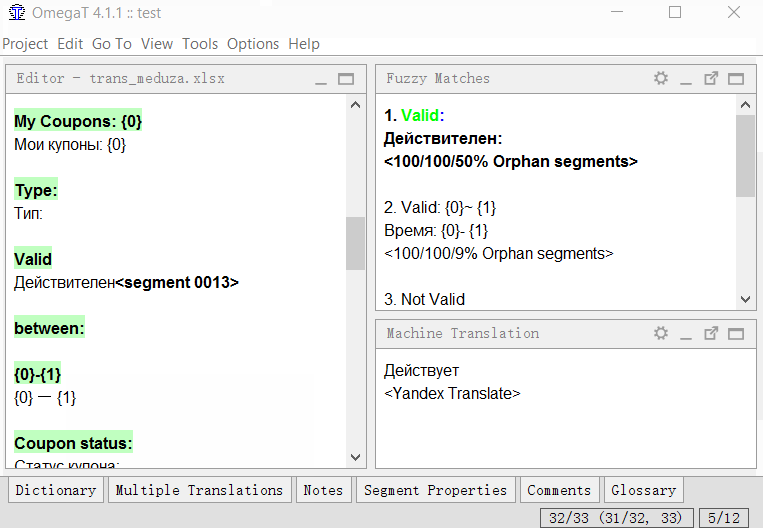
Программа покажет предупреждение с результатом разделения. Можете нажать ОК для разделения, или отменить действие.
Скрипт создаёт новое правило сегментации и применяет его к проекту. Скрипт очень далёк от идеала, и работает не всегда, но пока в OmegaT это единственный способ для точечного разделения/объединения сегментов.
Вместо заключения
Я объединил две заметки из своего уютного бложика в одну огромную простыню про OmegaT. Постарался раскрыть все её основные возможности, которыми сам пользуюсь регулярно. В комментариях обязательно напишите, почему статья стрёмная и в каком хабе ей на самом деле место.
Профессиональные переводчики должны покритиковать мой англо-русский перевод и поучаствовать в опросе по нормальным CAT-программам.
P.S.: кто-нибудь знает, почему движок GT не понимает html-ссылки внутри страницы?
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Каким софтом для переводчиков вы пользуетесь?
21.21%
Trados
7
21.21%
MemoQ
7
9.09%
SDL
3
9.09%
Deja Vu
3
0%
Memsource
0
21.21%
Poedit
7
18.18%
SmartCAT
6
6.06%
Wordfast
2
24.24%
другое (в комментариях)
8
Проголосовали 33 пользователя.
Воздержались 68 пользователей.










