Комментарии 93
Интересно такое проделать с wav форматом, т.к. возможно на результат оказало сильное влияние то, как сжимает flac.
что преобразование из 192000 Гц в 44100 Гц является сжатием без потерь— я бы лучше сказал, что такое преобразование не внесёт в звук значительных искажений.
Где срач?!
Так автор ведь ничего и не доказал — взял покореженный цифрой файл (пусть и 192 кГц), пережал его с меньшей частотой и радуется что ничего не потерял (конечно, аналоговая теплота уже потеряна при первом сжатии). Да и вообще не вижу списка кабелей, которые использовались при проведении эксперимента, могу поспорить что ни один из них не омыт слезами девственниц. /sarcasm
Хм, если Вы сначала обрезали руками частоты до 20 КГц, то любая частота дискретизации выше ~40 КГц даст одинаковую картинку «по определению».
Частоты выше 20 КГц — это не ультразвук, а тонкие детали волнового профиля.
Частоты выше 20 КГц — это не ультразвук, а тонкие детали волнового профиля.
Частоты выше 20 КГц — это не ультразвук, а тонкие детали волнового профиля.
Которые вы никогда не услышите.
Об этом пусть спорят суровые аудиофилы. Я лично точно не услышу:)
НЛО прилетело и опубликовало эту надпись здесь
По-моему, автор на практике проверил верность теоремы Котельникова. И, кстати, если ей следовать, то обрезать стоило на частоте выше 22 кГц.
Как человек далекий от цифрового аудио хочу спросить, а от применяемого ПО (алгоритмов) тут ничего не могло зависеть?
Сомнения может вызывать если только эквалайзер. Можно проделать такой же эксперимент с любым другим фильтром.
Думаю, здесь многое могло бы зависеть от исходного звука. Что там записано? Телефонный разговор или увертюра симфонического оркестра?
Я сам себя аудиофилом не считаю, по моему мнению частота свыше 44 или 48 КГц в звуковых файлах для прослушивания — это излишество, но что касается записи и обработки — здесь и высокая частота и разрядность 24 или 32 бита вполне оправданы.
Я сам себя аудиофилом не считаю, по моему мнению частота свыше 44 или 48 КГц в звуковых файлах для прослушивания — это излишество, но что касается записи и обработки — здесь и высокая частота и разрядность 24 или 32 бита вполне оправданы.
НЛО прилетело и опубликовало эту надпись здесь
Если использовать 32 бита, то, полагаю, особой беды не будет, а в остальных случаях зависит от того сколько раз и насколько сильно снижали (повышали) амплитуду сигнала.
НЛО прилетело и опубликовало эту надпись здесь
Я полагаю, что вся обработка в наши дни ведётся именно во float (32 бита). По крайней мере многие программы делают обработку именно во float. Посмотрите на AIMP, библиотеку Bass. В статье же говорилось о форматах хранения данных. Это разные вещи.
В реалистичных ситуациях неискажённый звук обычно потребен только человеку с недешёвым железом (потому как наушники за 20$ один фиг всё исказят), а в таком случае он может выставить в софтине звук на 100%, и пустить его мимо всех микшеров на звуковую карту (ASIO, WASAPI Exclusive, Kernel Streaming), а уже на ней покрутить громкость аппаратно.
Для чистоты эксперимента можно еще сгенерировать исходный 192kHz звук (взять например синусы на пределе слышимости на 18kHz, 16kHz, 14kHz), а не брать готовый файл (который мог быть получен апсемплингом с тех же 44,1kHz), и провести те же опыты.
Повышенные частоты дискретизации имеет смысл применять при оцифровке аналогого сигнала, то-есть допустим при записи материала на студии, т.к. побочный ультразвук накладывается в слышимый диапазон методом «вращения колеса в обратную сторону», что по сути является «шумодобавлением», а аналоговые фильтры, применяемые в звуковых картах для среза ультразвука, далеко не так совершенны как цифровые. Впрочем при достаточном качестве железа, его малошумности — этот эффект будет незначительным. Ещё имеет смысл использовать опять же при записи для борьбы с джиттером, но сейчас железо стало достаточно качественным, и проблем с джиттером практически не возникает вообще.
Ну кто так делает?
Обрезал высокие частоты, а потом проверил, что их нет :)
Надо было сделать так:
1. Записываешь звук на «высокой» частоте с реального источника.
2. Из него методом выборки каждого N-ного сэмпла делаешь файл на «традиционной» частоте.
3. (собственно, в этом — суть проверки) проигрываешь два файла через одну и ту же систему (а туда входит ЦАП + динамик/наушник) и уже там пытаешься анализировать разницу — либо ухом либо инструментально.
От себя добавлю что ещё не видел ни одной системы воспроизведения звука чтобы я перепутал записанную музыку с живой.
Наверно, это были записи недостаточно хорошего качества или не очень хорошие колонки ;)
Честно говоря, мне и самому интересно убедиться в том, что «44 КГц достаточно всем».
Прежде чем ударяться в тонкости измерений, хотелось бы для начала обмануться самому на тему «ух ты, а я думал, это — живая музыка». После этого было бы, что обсуждать.
Обрезал высокие частоты, а потом проверил, что их нет :)
Надо было сделать так:
1. Записываешь звук на «высокой» частоте с реального источника.
2. Из него методом выборки каждого N-ного сэмпла делаешь файл на «традиционной» частоте.
3. (собственно, в этом — суть проверки) проигрываешь два файла через одну и ту же систему (а туда входит ЦАП + динамик/наушник) и уже там пытаешься анализировать разницу — либо ухом либо инструментально.
От себя добавлю что ещё не видел ни одной системы воспроизведения звука чтобы я перепутал записанную музыку с живой.
Наверно, это были записи недостаточно хорошего качества или не очень хорошие колонки ;)
Честно говоря, мне и самому интересно убедиться в том, что «44 КГц достаточно всем».
Прежде чем ударяться в тонкости измерений, хотелось бы для начала обмануться самому на тему «ух ты, а я думал, это — живая музыка». После этого было бы, что обсуждать.
Живую от записанной легко не перепутать, т.к. мастеринг разный.
Он может быть разный, но он не всегда разный.
А например классическай музыка, в идеале, должна вообще одинаково звучать.
Если взять отдельно звук ударных или смычковых инструментов — он живой очень хорошо слышен.
А например классическай музыка, в идеале, должна вообще одинаково звучать.
Если взять отдельно звук ударных или смычковых инструментов — он живой очень хорошо слышен.
Друг звукорежиссер говорил что есть принципиально 2 разные «школы» мастеринга — «чтобы как будто в на коцерте сидишь» или «чтобы вкусно было слушать». Большинство исповедуют вторую.
Я исхожу из того, что человек никак не воспринимает частоты выше 20 кГц.
Целью всего этого было показать, что в файлах 44100 Гц и 192000 Гц содержится одинаковое количество информации о звуке, т.е. при преобразовании в 44100 не теряется ничего, если не считать погрешностей ниже -96 дБ, которые никто не услышит. Вы не путаете частоту дискретизации со звуковым диапазоном?
Что касается реалистичности, то по-хорошему звуковая техника должна была шагать в сторону формирования определённого пространственного расположения звуковых колебаний в точке, где находится слушатель (куча датчиков, сложная математика с компенсацией влияния помещения). Но маркетинг взял верх, и начали тупо штамповать ЦАП и АЦП с высокими частотами дискретизации, делая вид, что это какое-то новый этап в повышении качества.
Целью всего этого было показать, что в файлах 44100 Гц и 192000 Гц содержится одинаковое количество информации о звуке, т.е. при преобразовании в 44100 не теряется ничего, если не считать погрешностей ниже -96 дБ, которые никто не услышит. Вы не путаете частоту дискретизации со звуковым диапазоном?
Что касается реалистичности, то по-хорошему звуковая техника должна была шагать в сторону формирования определённого пространственного расположения звуковых колебаний в точке, где находится слушатель (куча датчиков, сложная математика с компенсацией влияния помещения). Но маркетинг взял верх, и начали тупо штамповать ЦАП и АЦП с высокими частотами дискретизации, делая вид, что это какое-то новый этап в повышении качества.
Это да. Я вот про акустическую голографию слышал, но нигде нормального применения не видел.
А есть какие-то данные о том, как работает конвертор частоты оцифровки в Audacity и как работает ЦАП на компе и в плеере?
Для проверки, на сколько там реально используется теорема Котельникова и на сколько там действительно жёсткая математика, можно сгенерить в 21990*10 Гц синусоиду, преобразовать её в 22000 Гц и потом попробовать восстановить? Там должны получиться биения — это непростой случай.
Я далёк от современных разработок звуковых систем, но не ужели там ЦАПы уже на столько мощные чтобы в реальном времени считать свёртки и восстанавливать такие сигналы?
Тут же вопрос, мне кажется, не столько в теоретической возможности, а в том, происходит ли это реально в моих наушниках.
Вот например если тупо повысить частоту дискретизации, то никакого интеллекта в ЦАПах вообще не понадобится. Можно будет тупо играть сэмплы подряд. Может быть, в этом смысл?
Для проверки, на сколько там реально используется теорема Котельникова и на сколько там действительно жёсткая математика, можно сгенерить в 21990*10 Гц синусоиду, преобразовать её в 22000 Гц и потом попробовать восстановить? Там должны получиться биения — это непростой случай.
Я далёк от современных разработок звуковых систем, но не ужели там ЦАПы уже на столько мощные чтобы в реальном времени считать свёртки и восстанавливать такие сигналы?
Тут же вопрос, мне кажется, не столько в теоретической возможности, а в том, происходит ли это реально в моих наушниках.
Вот например если тупо повысить частоту дискретизации, то никакого интеллекта в ЦАПах вообще не понадобится. Можно будет тупо играть сэмплы подряд. Может быть, в этом смысл?
ЦАП никаких свёрток не считают они просто преобразуют цифровой код в уровень напряжения на выходе. В них вообще нет интеллекта — простейший ЦАП это набор резисторов. Уточните что вы понимаете под ЦАП.
Это частный случай ЦАП.
Современные чипы могут содержать внутри сложную обработку при этом являясь ЦАП-ом т.е. в прямом смысле на входе цифра на выходе аналог.
А уж каким образом там цифра преобразуется в аналог — это принцип черного ящика. Может там черти сидят и потенциометры крутят в зависимости от поступившего на вход кода.
Современные чипы могут содержать внутри сложную обработку при этом являясь ЦАП-ом т.е. в прямом смысле на входе цифра на выходе аналог.
А уж каким образом там цифра преобразуется в аналог — это принцип черного ящика. Может там черти сидят и потенциометры крутят в зависимости от поступившего на вход кода.
А вот по теореме Котельникова именно что нужно считать свертки.

В современных ЦАП сначала в целое число раз повышается частота дискретизации исходных данных с помощью какой-либо простой интерполяции. А потом пользуются тем, что спектр погрешностей интерполяции находится выше частоты дискретизации исходных данных, делённой на два, и давят погрешности с помощью цифрового фильтра. Затем данные с повышенной частотой дискретизации и тишиной в области частот выше звуковой преобразуются в аналоговую «лесенку». Так как частота дискретизации у нас была повышена, то составляющая, формирующая лесенку, лежит намного выше звукового диапазона (большой промежуток сформирован до этого с помощью цифрового фильтра) и легко фильтруется аналоговым фильтром без ущерба для непосредственно слышимой составляющей. Как-то так.
На мой взгляд, 44 КГц «недостаточно». Со всем своим невежеством заявляю, что Найквиста люди понимают как-то слишком примитивно. Люди обычно рассуждают так «о, возьму частоту в два раза выше топовой, и запросто восстановлю из неё исходный сигнал». Позвольте, но это же ерунда. Вы так восстановите лишь намек на то, что там был сигнал, но никак не его форму и амплитуду. Возьмем крайний случай, синусоиду с частотой ровно в два раза ниже частоты дискретизации. Что получится при дискретизации? Сюрприз, тишина. Для реального восстановления формы сигнала нужен хотя бы четырехкратный запас по частоте, т.е., в случае идеального человеческого слуха, ~80 КГц, а желательно — ещё в пару раз выше!
ровно половинная частота равно как и 0 частота исключаются из допустимого диапазона.
В остальных случаях сигнал МОЖНО восстановить теоретически если предположить что он бесконечный, на практике к этому состоянию можно только приблизиться с заданной точностью, и чем больше точность тем выше величина необходимого отрезка.
Причем, восстанавливать нужно не простой интерполяцией.
В остальных случаях сигнал МОЖНО восстановить теоретически если предположить что он бесконечный, на практике к этому состоянию можно только приблизиться с заданной точностью, и чем больше точность тем выше величина необходимого отрезка.
Причем, восстанавливать нужно не простой интерполяцией.
На самом деле во время записи и обработки избыточная частота дискретизации лишней не будет.
Дело в том, что это в уже готовом файле можно просто взять и убрать все высокие частоты. Пока же сигнал аналоговый, мы либо срежем ещё и слышимый звук, либо пропустим часть ультразвука. Чаще всего получается компромисс — и то и другое одновременно.
А что происходит при оцифровке сигнала, содержащего ультразвук, на частоте 44100? Муар. Причём частота этого муара может быть очень низкой.
Самый надёжный способ этого избежать — это взять частоту дискретизации с большим запасом, чтобы аналоговые фильтры могли убрать весь сигнал выше половины частоты дискретизации не задев при этом слышимый диапазон.
В процессе цифровой обработки звука могут возникать всякие артефакты и зачастую — в области высоких частот. Если частота дискретизации взята с запасом в 2-4 раза, то практически все артефакты окажутся в области ультразвука, а от того ни на что не повлияют.
Но конечную запись, конечно, вполне можно делать на 44100 или 48000. Причём последний вариант лучше: большинство аудиокарт не умеют работать напрямую с 44100 и преобразуют их в 48000, при этом опять таки могут возникать артефакты.
Дело в том, что это в уже готовом файле можно просто взять и убрать все высокие частоты. Пока же сигнал аналоговый, мы либо срежем ещё и слышимый звук, либо пропустим часть ультразвука. Чаще всего получается компромисс — и то и другое одновременно.
А что происходит при оцифровке сигнала, содержащего ультразвук, на частоте 44100? Муар. Причём частота этого муара может быть очень низкой.
Самый надёжный способ этого избежать — это взять частоту дискретизации с большим запасом, чтобы аналоговые фильтры могли убрать весь сигнал выше половины частоты дискретизации не задев при этом слышимый диапазон.
В процессе цифровой обработки звука могут возникать всякие артефакты и зачастую — в области высоких частот. Если частота дискретизации взята с запасом в 2-4 раза, то практически все артефакты окажутся в области ультразвука, а от того ни на что не повлияют.
Но конечную запись, конечно, вполне можно делать на 44100 или 48000. Причём последний вариант лучше: большинство аудиокарт не умеют работать напрямую с 44100 и преобразуют их в 48000, при этом опять таки могут возникать артефакты.
Кстати, по поводу эквалайзера и спектра, который у вас получился после него. Есть мнение, что:
1. Шумы, которые появляются после усиления на 96 dB это как раз результат эквалайзера. Но тут есть контр мнение — возможно это из-за недостаточного динамического диапазона файла, например если создать пустой файл некоторой длины и начать в нём увеличивать громкость, то на каком-то этапе у него появятся шумы, которые, фактически, являются (должны являться) белым шумом, пришедшим из ничего (не знаю как это правильно сказать, но такое определение мне нравится). Но 96 dB это как-то мало, белый шум на пустом файле у меня появляется где-то после усиления на 200 dB, может быть дело всё-таки в эквалайзере (а может в разрядности звука).
2. По идее, такой ровный срез на эквалайзере у вас получился как раз из-за высокой частоты. Если бы частота была ниже, это, вероятно, могло вызвать появление искажений на краях диапазона, и они были бы видны при сравнении, но это, опять же, зависит от алгоритма эквалайзера.
Впрочем, оба пункта никак ваши выводы не оспаривают и лишь прозрачно намекают, что обрабатывать (запись, мастеринг, etc) звук как раз желательно в 192 кГц, а делать даунсепмлинг до 44 кГц уже непосредственно перед передачей… эээ… «в продакшн».
1. Шумы, которые появляются после усиления на 96 dB это как раз результат эквалайзера. Но тут есть контр мнение — возможно это из-за недостаточного динамического диапазона файла, например если создать пустой файл некоторой длины и начать в нём увеличивать громкость, то на каком-то этапе у него появятся шумы, которые, фактически, являются (должны являться) белым шумом, пришедшим из ничего (не знаю как это правильно сказать, но такое определение мне нравится). Но 96 dB это как-то мало, белый шум на пустом файле у меня появляется где-то после усиления на 200 dB, может быть дело всё-таки в эквалайзере (а может в разрядности звука).
2. По идее, такой ровный срез на эквалайзере у вас получился как раз из-за высокой частоты. Если бы частота была ниже, это, вероятно, могло вызвать появление искажений на краях диапазона, и они были бы видны при сравнении, но это, опять же, зависит от алгоритма эквалайзера.
Впрочем, оба пункта никак ваши выводы не оспаривают и лишь прозрачно намекают, что обрабатывать (запись, мастеринг, etc) звук как раз желательно в 192 кГц, а делать даунсепмлинг до 44 кГц уже непосредственно перед передачей… эээ… «в продакшн».
Слишком много псевдо науки в людях и теоремы не правильно интерпретируют. Смотреть надо на вопрос с точки зрения цифроаналоговых преобразований и понятия процесса дискретизации. Про мастеринг и сведение в 192кгц вы мифолизируете, больше на этапе сведения влияет битность сумматора сигналов, а спектра с частотой дискретизации в 44.1кгц хватит за уши, подумаешь, что 22.5кгц будут представлены 2мя дискретными показаниями и форма волны не будет восстановлена так как не понятно там синус или пила или прямоугольный импульс, на 11.25кгц — 4мя — точнее восстановит форму волны. Все потери и артефакты будут на частоте выше 11.25кгц, но тут на помощь приходит психоаккустика и она гласит, что наш мозг не может интерпретировать форму сигнала на вч и ему побарабану, там синус, пила или прямоугольный импульс. В профессиональной среде даже есть понятие, что хороший микс не перестает хорошо звучать даже если срезать все вч частоты выше 12.5кгц, так как основные резонансы инструментов находятся ниже и информация об направлении источка сигнала тоже ниже. Этим кстати пользуются разные алгоритмы сжатия сигнала, и алгоритмы компрессии динамического диапазона. На радио и тв например динамический диапазон ограниченый и там не стесняются разными алгоритмами подавлять часть вч спектра, чтобы вписаться в динамический диапазон. Меня больше пугает не частота дискретизации, а очень маленький динамический диапазон современной музыки, современную клубную и поп музыку можно хоть в 8бит передавать, так как идет война громкостей, все изначально сильно искажено и разница между тихими и громкими частями минимальная и rms всего -3db, когда раньше например за стандарт брали rms -12db -18db -20db. Можно сказать спасибо айподам, айфонам, айпадам, смартфонам, ноутбукам с тухлыми динамиками, которые заточены по маленький динамический диапазон, а если воспроизвести широкий динамический диапазон на них, то будет слишком тихо и некоторые элементы вообще не будут слышны.
22.5кгц будут представлены 2мя дискретными показаниями и форма волны не будет восстановлена так как не понятно там синус или пила или прямоугольный импульс
Пила и прямоугольник имеют бесконечный спектр частот. Они — сумма бесконечного ряда синусоид.
наш мозг не может интерпретировать форму сигнала на вч и ему побарабану, там синус, пила или прямоугольный импульс
Как уже сказано выше, эта самая форма сигнала — это сумма множества синусоид. И все из них, что попадают в слышимый диапазон, важны. Вы легко отличите 5 кГц чистого синуса от пяти тысяч прямоугольных импульсов.
Как-то давно мучился с пониманием Гц в звуке, очень много всякой чуши и заблуждений написано.
На деле 192КГц и 44,1КГц разница будет всегда если в исходном сигнале достаточно много информации, другое дело сможем ли мы её услышать.
Это как с частотой кадров, то что если прогнать в секунду 100 кадров и 400, мы не заметим разницы в обычном состоянии, ещё не значит что там разницы нет, если мы замедлим в 4 раза эти 100 и эти 400, разницу мы заметим (если было произведено снятие чего-то динамичного, быстрого по своей природе, чего требуется передать большим числом снимков).
Вот суть:
Когда я воспроизвожу звук со скорость 0,14-0,18x я слышу разницу, на 0,21х уже нет, но у меня аппаратура довольно дерьмовая и слух наверное уже далеко не самый лучший, да и источник сигнала под сомнением, так что может и на относительном более быстром воспроизведении при должных условиях можно ещё заметить разницу.
Другой вопрос стоит ли эти тонкие детали хранить. Как по мне лучше (если есть возможности) хранить информацию в более точном её представлении, во-первых это может быть полезно для будущей возможной обработки, во-вторых мало ли что мы сейчас не воспринимаем, в будущем ситуация может быть измениться и увы будет восприниматься образно говоря как сейчас видео с ютуба с 30 кадр/сек, только касаемо звука (хотя 44,1КГц это конечно не 30 кадр/сек, если проводить параллели, а вероятно все ~200).
На деле 192КГц и 44,1КГц разница будет всегда если в исходном сигнале достаточно много информации, другое дело сможем ли мы её услышать.
Это как с частотой кадров, то что если прогнать в секунду 100 кадров и 400, мы не заметим разницы в обычном состоянии, ещё не значит что там разницы нет, если мы замедлим в 4 раза эти 100 и эти 400, разницу мы заметим (если было произведено снятие чего-то динамичного, быстрого по своей природе, чего требуется передать большим числом снимков).
Вот суть:

Вот расскажи как ты мне это сверху восстановишь из нижего?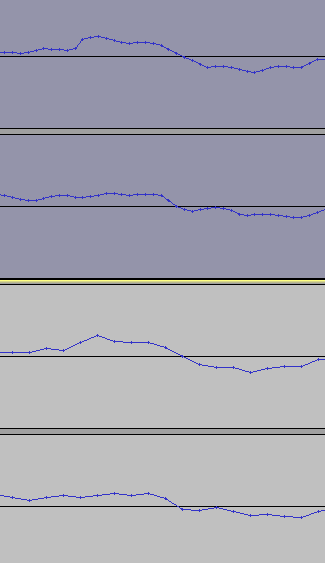
Интерполяция только сгладит, и детали в потоке (чего-то «пролетевшего» с большой скоростью) не восстановит.
Когда я воспроизвожу звук со скорость 0,14-0,18x я слышу разницу, на 0,21х уже нет, но у меня аппаратура довольно дерьмовая и слух наверное уже далеко не самый лучший, да и источник сигнала под сомнением, так что может и на относительном более быстром воспроизведении при должных условиях можно ещё заметить разницу.
Другой вопрос стоит ли эти тонкие детали хранить. Как по мне лучше (если есть возможности) хранить информацию в более точном её представлении, во-первых это может быть полезно для будущей возможной обработки, во-вторых мало ли что мы сейчас не воспринимаем, в будущем ситуация может быть измениться и увы будет восприниматься образно говоря как сейчас видео с ютуба с 30 кадр/сек, только касаемо звука (хотя 44,1КГц это конечно не 30 кадр/сек, если проводить параллели, а вероятно все ~200).
Сразу оговорюсь, выше в спойлере на картинке сравнение 44,1КГц и 96КГц, выше под рукой у меня нет.
Если вы не заметили, автор первоначально выкинул все «тонкие детали» с помощью эквалайзера, а потом уже ставил опыт.
Ну а про воспроизведение звука на 1/5-1/6 от реальной скорости и говорить не приходится: ясное дело, что там нужна в соответствующее число раз более высокая частота дискретизации. Да только лично я ни разу в жизни таким прослушивание не занимался… В отличии от видео, кстати, которое лично регулярно снимаю на 1200 кадров в секунду.
Ну а про воспроизведение звука на 1/5-1/6 от реальной скорости и говорить не приходится: ясное дело, что там нужна в соответствующее число раз более высокая частота дискретизации. Да только лично я ни разу в жизни таким прослушивание не занимался… В отличии от видео, кстати, которое лично регулярно снимаю на 1200 кадров в секунду.
Перейдите от формы сигнала к его спектру. Тогда станет понятней, что оцифрованный сигнал содержит полную копию исходного сигнала при частоте дискретизации как минимум в 2 раза выше верхней частоты спектра. Ну а дальше дело за фильтрами.
> мало ли что мы сейчас не воспринимаем, в будущем ситуация может быть измениться
Теория эволюции всё же оперирует настолько большими интервалами времени, что даже если это случится в будущем с человеческим слухом — нынешние записи, даже если сохранятся физически, безнадёжно устареют.
Теория эволюции всё же оперирует настолько большими интервалами времени, что даже если это случится в будущем с человеческим слухом — нынешние записи, даже если сохранятся физически, безнадёжно устареют.
C.FLAC получен из B.FLAC или из A.FLAC?
Ну хорошо, если автор не хочет делать такой эксперимент, его сделаю я :)
Шаги:
1. Создаём трек с частотой дискретизации 192 КГц
2. Генерим сигнал частотой 21200 Гц
3. Ресемплируем его в 44100 Гц, которых достаточно всем, а больше — не надо, потому что сигнал «можно» восстановить (но кто это делает?)
4. Восстанавливаем частоту дискретизации в 192 КГц. По задумке автора, сигнал должен стать идентичным первому.
Смотрим результат:

Как-то первая и третья волна, на первый взгляд, не совпадают, правда?
Должен ли я сделать вывод о том, что для простых ЦАП, всё-таки, повышение частоты доскретизации — самый простой способ восстановить форму волны?
Ибо без Котельникова и свёрток тут иначе не обойтись.
Шаги:
1. Создаём трек с частотой дискретизации 192 КГц
2. Генерим сигнал частотой 21200 Гц
3. Ресемплируем его в 44100 Гц, которых достаточно всем, а больше — не надо, потому что сигнал «можно» восстановить (но кто это делает?)
4. Восстанавливаем частоту дискретизации в 192 КГц. По задумке автора, сигнал должен стать идентичным первому.
Смотрим результат:
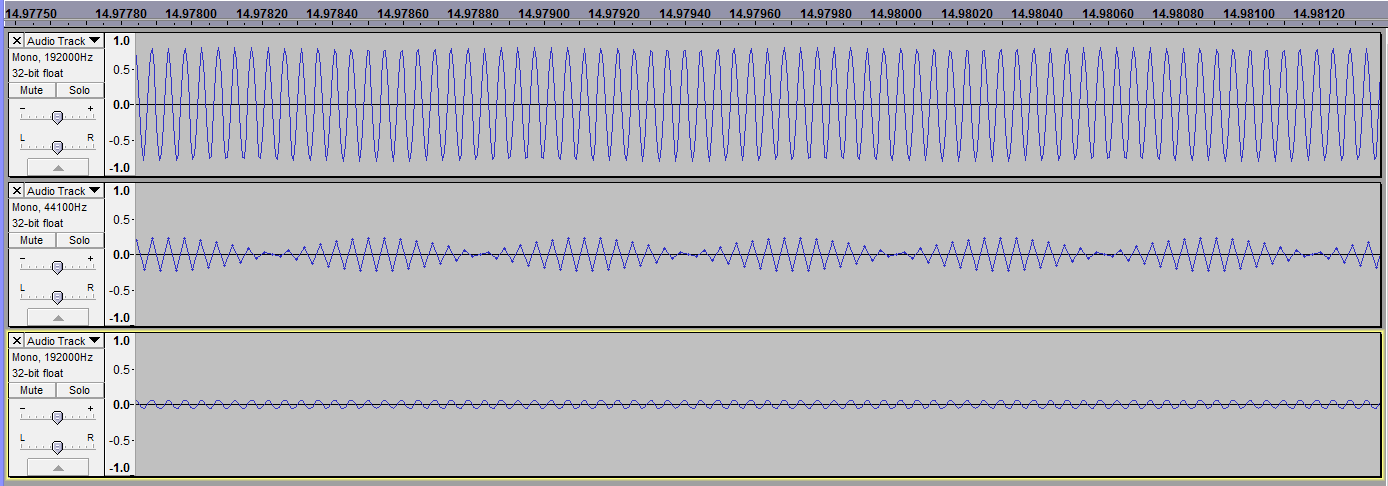
Как-то первая и третья волна, на первый взгляд, не совпадают, правда?
Должен ли я сделать вывод о том, что для простых ЦАП, всё-таки, повышение частоты доскретизации — самый простой способ восстановить форму волны?
Ибо без Котельникова и свёрток тут иначе не обойтись.
Не 21200 Гц, а 20 000 Гц брать надо было. 21 200 — это даже формально ультразвук (реально и 20 000 только дети слышат).
Формально — ультразвук, а реально — его слышно.
Повторяю: реально и 20 кГц не слышно. И даже 18 кГц, если вы не подросток.
Не надо повторять, я хорошо читаю :)
И я предпочитаю «говорить о вкусе устриц с тем, кто их ел»: в данном случае, с тем, кто хотя бы провёл эксперимент хотя бы на себе.
А ещё возникает пара вопросов:
1. Подростки — это не люди?
2. Слух дегредирует у всех людей одинаково?
3. Если нет, то какой процент людей, старше «подростка», таки слышит 21 КГц?
Впрочем, если вас интересует формальное определение ультразвука, это всё не важно.
И я предпочитаю «говорить о вкусе устриц с тем, кто их ел»: в данном случае, с тем, кто хотя бы провёл эксперимент хотя бы на себе.
А ещё возникает пара вопросов:
1. Подростки — это не люди?
2. Слух дегредирует у всех людей одинаково?
3. Если нет, то какой процент людей, старше «подростка», таки слышит 21 КГц?
Впрочем, если вас интересует формальное определение ультразвука, это всё не важно.
21 кГц не слышит никто.
Авторитетное заявление.
Даже википедия с этим не согласна :) не говоря уже…
Даже википедия с этим не согласна :) не говоря уже…
Во-во: авторитетное высказывание в Википедии… Без ссылки на источник… Кое-где пишут вообще про 200 кГц у отдельных людей! Да только что-то никто на практике без пиборов разговоры дельфинов не слушает…
Если брать источники, связанны с медициной, то:
«Дети воспринимают звуковые волны в диапазоне от 16 до 20 000 Гц, но приблизительно с 15—20 лет диапазон частотного восприятия начинает суживаться в связи с утратой чувствительности слуховой системы к самым высоким звукам».
meduniver.com/Medical/Physiology/310.html
Если брать источники, связанны с медициной, то:
«Дети воспринимают звуковые волны в диапазоне от 16 до 20 000 Гц, но приблизительно с 15—20 лет диапазон частотного восприятия начинает суживаться в связи с утратой чувствительности слуховой системы к самым высоким звукам».
meduniver.com/Medical/Physiology/310.html
А теперь взгляните спектр последней дорожки. Есть что-то лишнее? Вы только показали, что чем ближе к половине частоты дискретизации, тем больше влияние фильтра, обрезающего высокие частоты. Если синусоида 20 кГц, то всё отлично.
А в современных ЦАП и так повышается частота дискретизации для возможности использования цифровой фильтрации.
А в современных ЦАП и так повышается частота дискретизации для возможности использования цифровой фильтрации.
Лишнее?!
Сигнал — разный, о чём речь? :) Или по картинкам это не очевидно?
Каким образом я что-то показал про фильтры, обрезающие частоты, если я их не применял ни разу?
Сигнал — разный, о чём речь? :) Или по картинкам это не очевидно?
Каким образом я что-то показал про фильтры, обрезающие частоты, если я их не применял ни разу?
У сигнала изменилась только амплитуда. Это очевидно даже по вашей картинке.
Фильтры применяют алгоритмы преобразования частоты дискетизации.
Ваш пример лежит выше звукового диапазона, поэтому не вижу смысла его вообще обсуждать в контексте избыточности высоких частот дискретизации для хранения музыки, предназначенной для прослушивания у конечного пользователя.
Фильтры применяют алгоритмы преобразования частоты дискетизации.
Ваш пример лежит выше звукового диапазона, поэтому не вижу смысла его вообще обсуждать в контексте избыточности высоких частот дискретизации для хранения музыки, предназначенной для прослушивания у конечного пользователя.
А про ЦАП очень хорошо, что тут всплыло.
Вот ЦАП повысил свою внутреннюю частоту и… что он сделал дальше?
Посчитал интегралы и свёртки для восстановления сигнала?
Сразу скажу, что в этом нет ничего невозможного. Современные DSP вполне могли бы с этим справиться. Вполне вероятно, что в профессиональном оборудовании это используется.
Но не в плеерах за 3 копейки, конечно же.
Вот это и называется «можно» восстановить. Весь вопрос — восстанавливается ли сигнал в действительности.
Это исследование показывает, что программа Audacity таким образом сигнал НЕ восстанавливает.
Ок, примем к сведению. Но это ещё не победа и не поражение.
Давайте найдём хоть одну софтину или железяку, которая это делать умеет.
Есть хоть кто-то, кто это «можно» превратил в «делает»?
Вот ЦАП повысил свою внутреннюю частоту и… что он сделал дальше?
Посчитал интегралы и свёртки для восстановления сигнала?
Сразу скажу, что в этом нет ничего невозможного. Современные DSP вполне могли бы с этим справиться. Вполне вероятно, что в профессиональном оборудовании это используется.
Но не в плеерах за 3 копейки, конечно же.
Вот это и называется «можно» восстановить. Весь вопрос — восстанавливается ли сигнал в действительности.
Это исследование показывает, что программа Audacity таким образом сигнал НЕ восстанавливает.
Ок, примем к сведению. Но это ещё не победа и не поражение.
Давайте найдём хоть одну софтину или железяку, которая это делать умеет.
Есть хоть кто-то, кто это «можно» превратил в «делает»?
Так вы Audacity и не говорили что необходимо использовать не простую интерполяцию. Проще всего эта функция выполняется в железе в виде ПЛМ, для программы же необходим будет довольно приличный объём вычислений.
Если плеер стоит 3 копейки, то он и с 192000 Гц ничего хорошего на выходе не даст. А есть вообще плееры за 3 копейки, у которых частота дискретизации 192000 Гц?
Цифровому звуку уже больше 50 лет. За это время встраивать DSP в ЦАП, чтобы снизить требования к аналоговым фильтрам, стало обыденным делом. Сейчас ЦАП, производящие цифровую обработку, стоят копейки, например, PCM2704.
Есть у меня плеер Sansa Clip Plus. Подключал к осциллографу и воспроизводил синусоиду 20 кГц — на выходе красивая синусоида без каких-либо кривостей и ступенек. Могу потом записать с него звук на хорошую звуковую с высокой частотой дискретизации и проанализировать его.
Цифровому звуку уже больше 50 лет. За это время встраивать DSP в ЦАП, чтобы снизить требования к аналоговым фильтрам, стало обыденным делом. Сейчас ЦАП, производящие цифровую обработку, стоят копейки, например, PCM2704.
Есть у меня плеер Sansa Clip Plus. Подключал к осциллографу и воспроизводил синусоиду 20 кГц — на выходе красивая синусоида без каких-либо кривостей и ступенек. Могу потом записать с него звук на хорошую звуковую с высокой частотой дискретизации и проанализировать его.
У сигнала кроме частоты есть ещё амплитуда и фаза.
Для того, чтобы было «нормально», всё должно сохраняться.
Прекрасно, что синусоида осталась синусоидой. Хорошо, что её частота не поменялась.
В моём примере выше плохо — что синусоида во-1, немного усохла и во-2, на фронтах у неё ещё и фаза съезжает (и частота тоже).
На каком основании фаза и амплитуда у вас считаются не важными? Они важны точно так же, как и сама частота звука.
Они поменялись => сигнал НЕ восстановлен.
Насчёт частоты в 20 КГц и названия «ультразвук» инсинуации вообще прошу прекратить.
Прямо сейчас сделал себе генератор на 21КГц. Совершенно точно могу заявить, что этот звук — СШЫШНО.
Если есть какие-то сомнения в моей честности или чистоте эксперимента, готов повторить эксперимент в присутствии любых людей.
Для того, чтобы было «нормально», всё должно сохраняться.
Прекрасно, что синусоида осталась синусоидой. Хорошо, что её частота не поменялась.
В моём примере выше плохо — что синусоида во-1, немного усохла и во-2, на фронтах у неё ещё и фаза съезжает (и частота тоже).
На каком основании фаза и амплитуда у вас считаются не важными? Они важны точно так же, как и сама частота звука.
Они поменялись => сигнал НЕ восстановлен.
Насчёт частоты в 20 КГц и названия «ультразвук» инсинуации вообще прошу прекратить.
Прямо сейчас сделал себе генератор на 21КГц. Совершенно точно могу заявить, что этот звук — СШЫШНО.
Если есть какие-то сомнения в моей честности или чистоте эксперимента, готов повторить эксперимент в присутствии любых людей.
Я продолжу основываться на общепринятом мнении, что выше 20 кГц люди не слышат. К результатам многолетних исследований у меня больше доверия, чем к вашему эксперименту, который очень трудно корректно провести в домашних условиях без лабораторного генератора и излучателя. Считаю, что дальше спорить бессмысленно. И если считать 20 кГц верхней границей звукового диапазона, воспринимаемого человеком, то 44100 Гц достаточно для хранения исчерпывающей информации о форме звукового сигнала в фиксированной точке пространства.
Съезжание частоты и фазы — стандартное влияние частотных фильтров.
Съезжание частоты и фазы — стандартное влияние частотных фильтров.
Общепринятым является несколько другое мнение, а именно, что-то вроде «большинство людей в старшем возрасте на слышат частоты выше 20 КГц».
Это — немного другое мнение, не так ли?
Даже википедия с этим согласна, не говоря уже о результатах эксперимента.
Если действительно есть какие-то «многолетние исследования», которые говорят о том, что выше 20 КГц услышать никак невозможно, хотелось бы на них взглянуть. Не найдётся ли ссылки на исследования или описание простого эксперимента, который бы меня привёл к этим выводам?
Пока, простой эксперимент с Audacity говорит мне о том, что я эти звуки слышу.
Это — немного другое мнение, не так ли?
Даже википедия с этим согласна, не говоря уже о результатах эксперимента.
Если действительно есть какие-то «многолетние исследования», которые говорят о том, что выше 20 КГц услышать никак невозможно, хотелось бы на них взглянуть. Не найдётся ли ссылки на исследования или описание простого эксперимента, который бы меня привёл к этим выводам?
Пока, простой эксперимент с Audacity говорит мне о том, что я эти звуки слышу.
Кстати, в чём именно заключается сложность домашнего эксперимента? Один надевает наушники и отворачивается, другой нажимает кнопку, а первый ему сообщает об этом.
Качество аппаратуры мешает. Нет гарантии что на данном оборудовании ультразвук не будет вызывать колебания в слышимом диапазоне.
Попробовал я файлы воспроизвести с ультразвуком — на моей звуковой карте это просто ужас, ультразвук вызывал появление слышимых колебаний в частотном диапазоне меньше 20кГц.
Попробовал я файлы воспроизвести с ультразвуком — на моей звуковой карте это просто ужас, ультразвук вызывал появление слышимых колебаний в частотном диапазоне меньше 20кГц.
Для условной корректности эксперимента необходимо рядом с человеком расположить звукозаписывающее оборудование и кроме вывода сигнала через оборудование способное его воспроизвести — проводить запись и смотреть что на самом деле выходило из колонок.
О Боже, зачем на практике проверять доказанные теоремы? Для надежности?
Проблема всех подобных антиаудиофильских «разоблачений» в том, что либо берется для анализа 1 несчастная синусоида и тогда забывается напрочь об импульсно-переходной характеристике, либо эксперимент делается «сферически в вакууме» — без привязки к звуковому оборудованию, в частности к ЦАП. Так вот ЦАПы сегодня повсеместно дельта-сигма. И работают они на 44.1 весьма паршиво, чего нельзя сказать о частотах 192+ кГц. Апсемплинг тоже не лекарство — нельзя добавить новой информации таким образом, а вот огрех — да. Мне ни разу не доводилось слушать музыку с апсемплингом, которая звучала бы лучше, чем на исходной частоте.
Добавлять новую инфомрацию не нужно, т.к. в 192 кГц ровно столько же информации о звуке, как в 44.1 кГц, что я и продемонстрировал на практике. При апсемплинге огрехи могут быть сколько угодно исчезающе ничтожными, что я тоже наглядно продемонстрировал.
Вот прямо все ЦАП с частотой 44.1 звучат хуже, чем 192 кГц? В каких условиях сравнивали? Сколько ЦАП сравнили? Какие у них были цены?
Вот прямо все ЦАП с частотой 44.1 звучат хуже, чем 192 кГц? В каких условиях сравнивали? Сколько ЦАП сравнили? Какие у них были цены?
Я верю больше своим ушам. При апсемплинге звук меняется. С одной стороны в нем кажется больше деталей, но это только фейк. С другой стороны, явно ухудшаются любые резкие звуки, теряется резкость фронта волны. Это вполне согласуется с картиной меандра, прошедшего такую обработку.
По поводу ЦАПов, слышал я может чуть больше, чем среднестатистический пользователь. Однако, я видел и измерения меандра на 44.1/16. Мультибитный ЦАП с меандром с Т=100Гц справляется практически идеально. В то же время, ни один дельтасигма ЦАП не способен был воспроизвести фронт и спад без существенных искажений.
Мне этого достаточно.
Вот картинки ozvuke.pro/index.php?showtopic=434&view=findpost&p=1626
По поводу ЦАПов, слышал я может чуть больше, чем среднестатистический пользователь. Однако, я видел и измерения меандра на 44.1/16. Мультибитный ЦАП с меандром с Т=100Гц справляется практически идеально. В то же время, ни один дельтасигма ЦАП не способен был воспроизвести фронт и спад без существенных искажений.
Мне этого достаточно.
Вот картинки ozvuke.pro/index.php?showtopic=434&view=findpost&p=1626
1. Зря вы верите своим ушам. Очень плохой измерительный прибор, показания которого существенно меняются даже от того, что вы ели на завтрак.
2. Музыку вы тоже слушаете осциллографом? :-) Спектр ровного меандра бесконечен. Возможности ушей ограничены сверху 20 кГц. Ваши уши в слепом тесте не отличат ровный меандр от «изуродованного».
2. Музыку вы тоже слушаете осциллографом? :-) Спектр ровного меандра бесконечен. Возможности ушей ограничены сверху 20 кГц. Ваши уши в слепом тесте не отличат ровный меандр от «изуродованного».
Повышенная частот дискредитации обычно используется для последующего прорежения (oversampling) с сглаживанием сигнала. На цифровой DAC физически поступает частота более низкая, но высокочастотные шумы сглаживаются. Матчасть надо учить прежде чем тратит время на эксперименты.
Бесполезно проводить тесты на исходниках в виде классики или голоса, это всё достаточно медленно звучит - реальную разницу можно услышать только в спидкоре зарендеренном в высокой частоте, вы различите больше киков и снейров даже если у вас нет звуковой карты и фиговые динамики/наушники
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Проверяем на практике бессмысленность высоких частот дискретизации