Комментарии 32
Антон, обгоняй уже Лекса.
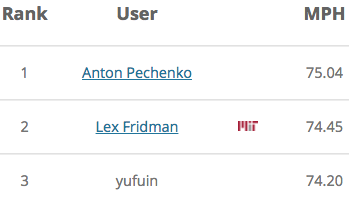
Меж тем Антон уже вышел на первое место с большим отрывом:
 https://habrastorage.org/files/d5e/a53/d9f/d5ea53d9f80a4e068670373a22537961.png
https://habrastorage.org/files/d5e/a53/d9f/d5ea53d9f80a4e068670373a22537961.png
 https://habrastorage.org/files/d5e/a53/d9f/d5ea53d9f80a4e068670373a22537961.png
https://habrastorage.org/files/d5e/a53/d9f/d5ea53d9f80a4e068670373a22537961.pngчто то кажется все таки с нейронами играть нельзя ибо слишком просто получается.
Набрал 71.32 на дефолтной модели, увеличив область видимости и количество нейронов на fc-слое. Больше набрать не получается, наверное надо менять архитектуру сети.
Кстати, там ещё есть DeepTesla http://selfdrivingcars.mit.edu/deepteslajs/
Кстати, там ещё есть DeepTesla http://selfdrivingcars.mit.edu/deepteslajs/
69 вышло очень легко — опять же бессистемным изменением параметров и количества нейронов.
Как сказать нейросети «Если справа открывается два окна по диагонали — прыгай туда»
Сделал прямоугольник 3*5 перед машиной, и в learn анализировал три средне-арифметических по каждому из столбцов. Если перед машиной сумма < 1 значит кого-то догоняем. Считаем суммы по соседним рядам. Где сумма больше получается, там и свободнее — перестраиваемся туда. Средняя скорость вышла ~71.5.
Правда при этом не учитывается скорость соседних рядов.
В идеале форма анализируемых клеток должна быть по форме близкая к символам X и V, т.е. приближенная к реальным условиям. Реальный водитель или лидар на три машины вперед врядли сможет видеть
Правда при этом не учитывается скорость соседних рядов.
В идеале форма анализируемых клеток должна быть по форме близкая к символам X и V, т.е. приближенная к реальным условиям. Реальный водитель или лидар на три машины вперед врядли сможет видеть
Лидары теоретически могут соединятся между собой по беспроводной сети и делится наблюдениями, там не так много информации нужно передавать. Таким образом у автопилота будет больше информации, чем у живого водителя.
5x3 (ШxВ) на расстоянии в 3-4 клетки впереди машины, fc размера 30-50 с relu и 100k итераций дают стабильно в районе 72-72.5. Честно, не очень понимаю, как получить больше, у меня даже при ручном управлении машинкой не выходит 75. Возможно, следует использовать набор conv-слоёв, но в варианте js уж слишком медленно оно работает.
А никто не знает, про что график?
Не нашел как там фарами поморгать.
73 пока максимум, без радикального изменения архитектуры.
Игра не так проста, как кажется. Первое, что пришло в голову, это
activation: 'relu'
заменить на
activation: 'sigmoid'
И сработало!
И далее можно добавить скрытых слоёв, просто копируя этот блок
layer_defs.push({
type: 'fc',
num_neurons: 5,
activation: 'sigmoid'
});
activation: 'relu'
заменить на
activation: 'sigmoid'
И сработало!
И далее можно добавить скрытых слоёв, просто копируя этот блок
layer_defs.push({
type: 'fc',
num_neurons: 5,
activation: 'sigmoid'
});
попробывал, 55 получается
пока лучшая идея из простых это убрать активацию на скрытом слое и увеличить его до 5
пока лучшая идея из простых это убрать активацию на скрытом слое и увеличить его до 5
«убрать» не получится. Активационная функция у нейрона есть всегда, без неё он просто не будет работать. В данном случае по умолчанию используется ReLU, если не указано другое.
точно нет
слой функции активации не отображается и поведение принципиально разное.
тут просто получается линейный классификатор.
слой функции активации не отображается и поведение принципиально разное.
тут просто получается линейный классификатор.
Вот только в Вашей конфигурации нет никакого смысла в линейном слое длины выходного слоя, ибо в результате получается всё та же линейная комбинация входных векторов. С тем же успехом этот слой можете просто убрать.
Если там 5 и больше, то да, но если там 3 или 2 то происходит сжатие пространства.
Которое затем просто заново расширяется на выходе. Если бы речь шла о модели энкодера-декодера, это могло бы иметь смысл, а так всё равно бесполезно.
это работает
10 впереди 2 по бокам, 5 сзади промежуточный слой 3 без функции
72
временныхсрезов =0
10 впереди 2 по бокам, 5 сзади промежуточный слой 3 без функции
72
временныхсрезов =0
Нет, это не работает. Вы вводите в модель абсолютно нефункциональный элемент. Ничего, кроме замедления расчёта, он не даёт.
попробуйте.
с ним обучение идет быстро и эффективно.
без него сходимость идет медленно.
с ним обучение идет быстро и эффективно.
без него сходимость идет медленно.
Давайте не будем заниматься здесь алхимией. Если этот слой даёт Вам какие-то преимущества, то у Вас где-то неэффективно работает trainer, возможно, один из других параметров неверен. Другой причины нет.
Согласен, я написал, что я поменял, можете проверить. причем тут результат достигается очень быстро, так как фактически есть только 2 решения — дернуться вправо или влево.
худший вариант это relu (relu6 был бы в тему, но его нет) так как приходиться делать или большой слой, что бы избежать вырождения или отказаться от него.
tanh ведет себя хорошо и позволяет получить лучшие результаты при долгом обучении.
Линейный вариант при увеличении числа слоев ведет себя также (или немного хуже).
хорошо было бы сделать веток.
простую линейную и нелинейную
худший вариант это relu (relu6 был бы в тему, но его нет) так как приходиться делать или большой слой, что бы избежать вырождения или отказаться от него.
tanh ведет себя хорошо и позволяет получить лучшие результаты при долгом обучении.
Линейный вариант при увеличении числа слоев ведет себя также (или немного хуже).
хорошо было бы сделать веток.
простую линейную и нелинейную
А можно объединять в слой несколько разных функций активации.
Мне такое на тензорфлоу давала лучшие результаты.
Мне такое на тензорфлоу давала лучшие результаты.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Домашнее задание от МТИ: пишем нейросеть для манёвров в дорожном трафике