Комментарии 101
Дело в том, что если у двух файлов изменить имена или расширения, то их хэш-сумма будет по-прежнему одинаковой. При изменении содержимого файла автоматически изменится и хэш-сумма.
Т.е. достаточно изменить одну букву в meta info видео/мп3 файла, и всё будет ок?
Т.е. достаточно изменить одну букву в meta info видео/мп3 файла, и всё будет ок?Т.е. вы серьёзно не знаете, что такое хэш? :) (шучу если что)
Да, будет ок, только этим мало кто заморачивается, в основном тупо копируют. Тот жалкий процент, кто этим озадачился, мало кого волнует.
Ну ладно, будут в zip архивах при надобности шарить:)
А под пароль в архив оже противоречит пользовательскому соглашению.
Нормально так… Почти как роскомнадзор. И всегда можно отмазаться, кивнув на борьбу с терроризмом, вот это все…
В следующий раз они так возьмут и перестанут принимать письма с посторонних почтовых сервисов. Разумеется, исключительно ради борьбы со спамом. Хотите переписываться с пользователями GMail — тоже заводите там аккаунт.
Имеет ведь Google право так сделать? Поменять, как они обычно делают, соглашение задним числом и разослать всем пользователям новые правила.
Конечно имеют право. Такое же право имеет Apple — запретить входящие звонки с аппаратов других брэндов. И магазин у подъезда может брать деньги за вход. Другое дело, что пользователей/клиентов станет меньше и никто в здравом уме этого не станет делать.
А под пароль в архив оже противоречит пользовательскому соглашению.Серьёзно? Надо наконец его почитать :)
То же самое и у DropBox, но на нем 5 лет вполне себе жил гигабайтный TrueCrypt образ. Инкрементальная синхронизация годная вешь. В гугл он недавно был загружен как бекап и пока гугл молчит про него.
А вообще бред — файл он и файл, мой файл, что внутри — не ваше дело. Видимо просто перестраховываются этим пользовательским соглашением.
И любое шифрование данных рушит всю дедупликацию хранимых данных и мешает эффективно их индексировать. Т.е. сильно увеличивает их расходы на хранение пользовательских данных если пользователи вдруг начинают активно пользоваться шифрованием.
В случае же гугла это наглое заявление — не смейте мешать нам копаться в ваших данных, не для того мы их собираем, чтобы просто хранить.
С паролем исполняемый не хочет передать? Или просто любой архив с паролем? Кроме того, есть такая опция, как шифрование названия файлов.
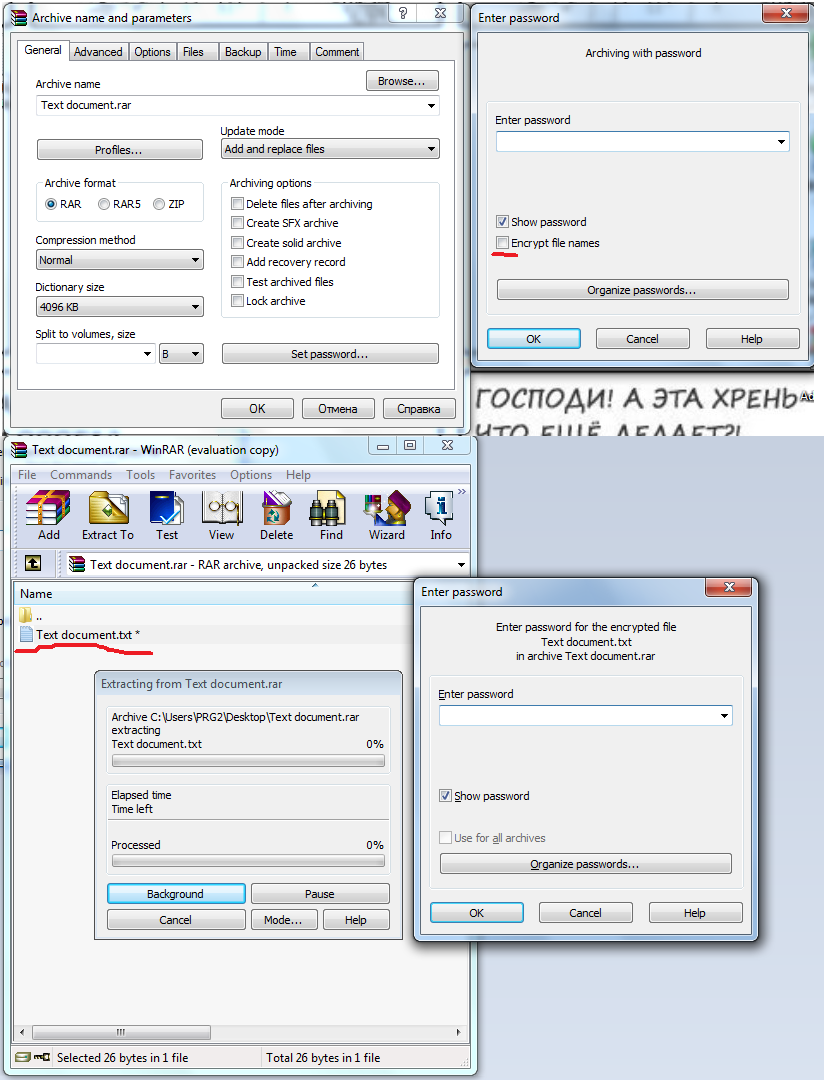
это проблемы ведь и для принимающей стороны и никогда не знаешь пройдут файлы или нет. Проще избавиться от этого и гарантировано доставлять почту. Гугл банальный mdb с макросами может не пропустить даже.
Будем тогда в метаинформации кодировать пиратский контент
И тут внезапно появятся программы на дельфи и бейсике, с большими кнопками «скопировать контент с защитой от детекта», которые будут копировать файл, меняя пару байт в метаданных. Или может быть даже точку в каком-нить кадре. И все наработки по хешированию придется переделывать.
Затем появятся программы, которые будут добавлять маленький водяной знак в каждый кадр с краю экрана, и поломается проверка по хешированию разных блоков.
В общем рано переживать.
Надеюсь времена дельфёвых кнопок «скопировать» прошли и человечество перешагнуло это как детский лепет. По современным стандартам должен появиться софт, который будет прозрачно и незаметно обфусцировать и деобфусцировать файлы на стороне клиентов, а торрент-клиенты научатся учитывать обфускацию.
Но вы прав и это классическое противостояние брони и пули. Правообладателей меньше, чем пользователей, но они сообща и знают чего хотят, в отличие от народных масс.
И тут я бы сам рад был видеть решение в стиле PGP, SSL, P2P, VPN, а не партизанского колхоза.
Но не переживайте. Как только корпоративные облака станут тесными и душными, появится спрос и возникнут предложения в виде нормальных P2P решений. BTSync был только первым шагом, причем проприетарным. Все впереди. Будет интересно.

Уже существует облачный провайдер, предоставляющий серверы LAFS: https://leastauthority.com/
Подключайтесь к общему пулу хранилища в I2P: http://jf2g5hus6gp2jfgk7zgc2cxtzeedxbstr3ju374amtoaq6p2ax6a.b32.i2p
Но на посмотреть обязательно попробую.
У меня флудфил без ограничения трафика примерно 15-20% на VPS.
Кстати сегодня вышел новый релиз 2.12.0
В результате получается «почти» вечный архиватор для отдельного пользователя.
IPFS сочетает в себе распределенную хэш-таблицу, децентрализованный обмен блоками, а также самосертифицирующееся пространство имён. При этом IPFS не имеет точек отказа, и узлы не обязаны доверять друг другу
Из-за этого гугл уже начал даже набор армии людей добровольцев-стукачей, которые должны среди полезных вещей в т.ч. стучать на нарушения авторских прав. Понимают что только на уровне ПО с этим полностью справится невозможно.
возможно, они не считают хеш для всего файла, а бьют его на куски и считают для них по отдельности. поменяете в 1м месте в других останется. как при поиске плагиата.
https://en.wikipedia.org/wiki/Perceptual_hashing
https://habrahabr.ru/post/120562/
На ютубе в хвост приклеивают дополнительное видео размером вполовину от цели и диким, какофоническим звуком.
Я так понимаю что этим занимаются несколько груп, там разные хвосты, одиноковые в пределах группы.
— Я купил альбом на идиотских Tidal Store, Beatport, Junodownload, тысячи их — которые разрешают скачать купленный альбом только один раз. Чтобы забэкапить, закинул на гуглодиск
ИЛИ
— Я скачал этот же альбом на трекере
Естественно, хеши в обоих случаях будут совпадать, если конечно создатель раздачи на трекере не менял метаданные, и если мы не говорим о каком-нибудь iTunes, который в метаданные добавляет информацию о покупателе.
С фильмами такое не прокатит, ведь стриминг, к сожалению, почти победил. А вот с теми же книгами тоже вполне актуально.
Но при бекапе вы не будете делать общедоступную ссылку
А если мне захочется скинуть один трек другу послушать… Ах да, копирасты же негодуют даже от того, что мы друг другу диски даем и вообще друг у друга слушаем, Fair use надо испепелить, чтобы все сидели на подписках и покупали
Гуглопочтой пользуются и корпоративные клиенты, либо контрагенты корпоративных клиентов.
Часто по требованиям IT безопасности передача конфиденциальной информации по email допустима только в зашифрованных архивах (пароли от архивов передаются по отдельному независимому каналу). Не можешь передать/получить зашифрованный архив — твои проблемы.
Прикрепил, отправил, получил, проверил. Всё ок. ЧЯДНТ?
Я даже не могу подсказать почтового провайдера, который бы рискнул сделать у себя подобное ограничение.
Случайное совпадение хэшей даже у небольших кусков стремится к нулю, поэтому любое такое совпадение если не признак, того что это замаскированные файл, то как минимум файл с заимствованиями из закопирайченного файла.
Чтобы от такого маскироваться нужно все содержимое файла изменить — например перекодировать другим кодеком или случайного мусора более-менее равномерно по всему файлу накидать, если структура позволяет это сделать не испортив сам контент.
Если пойдет тенденция менять содержимое файлов перед заливкой, то скоро не останется ни одного повторяющегося файла на серверах гугла, прощай дедупликация.
Хэш-функции не идеальны, сотни миллионов пользователей теоретически вполне способны сгенерировать достаточное число файлов, чтобы появились коллизии. Но это не точно :)
Checking SHA1… pirated!
Checking SHA256… pirated!
Ur pozt pirated movi! Собственно говоря — одновременная коллизия нескольких хеш-функций, причём одинаковая чуется мне, что вероятность этого будет около 10^(-999)
У таких решений есть проблемы с надежностью. А городить географически разнесенное дублирование — уже дорого для домашнего пользователя.
Я бы предпочел систему типа торрентов. Сдавать свое место, получать за это рейтинг, тратить рейтинг на место на чужих жестких дисках (к примеру, сдавать свои 200 гб в обмен на 2 дублирующихся тома по 100 гб каждый у разных пользователей, или на 4 тома по 50 гб).
А то аналогичный проект (FileCoin, базирующийся на IPFS) уже превратился в бесконечный долгострой, уже 3й год, «ждите, скоро будет»
За прошедшее время плотно ознакомился и со Storj и SiaCoin. Как оказалось проекты действительно уже вполне работают и масштабы их использования постепенно растут.
Теперь среди прочего на домашнем сервере и нода Storj постоянно работает (несколько месяцев и Sia была).
Предложение действительно все еще многократно превышает спрос, но за несколько месяцев на моей около 30 Гб чьих-то хранимых данных все-таки набралось.
Деньги с этого совсем небольшие капают (порядка 2$ / месяц сейчас получается, причем основная часть это фиксированная выплата в 1.5$, которая начисляется просто за сам факт поддержания ноды онлайн, а не за хранимые данные), так что специально под это дело сервер поднимать смысла не имеет.
А вот если сервер уже и так в любом случае круглосуточно работает (для других целей), то почему бы и не выделить часть места на диске и оперативки под работу службы.
Own все, продался
Content-ID на Youtube — отстой десятой воды ржавого источника загрязнённой химикатами реки! Сколько уже раз наше образовательное учреждение размещало видеороликов, в которых звучит гимн России (sic!), столько же раз и получало уведомление, что музыка нарушает права какой-то конторы и ди-джея, впихнувшего гимн в своё "творение". Приходится каждый раз отписываться, что присвоение общественного достояния — уголовное преступление, и каждый раз получать ответ, что жалоба снята.
Хеш-сумма не является уникальным идентификатором файла.
Google Drive добавил сканирование «пиратского» контента по хэшам файлов