Комментарии 63
Зря Вы так на меня. Я ж по доброму. Ну получилась схема С-элемента как у Варшавского. Целью было не представление схемы, а демонстрация метода. Варшавский схему изобрел, и сам не знает как. Я могу подробно описать весь процесс синтеза.
Я не настаиваю на двухвходовых реализациях. Это экстремальный пример. Могу сделать в 3-входовом базисе, могу в 4-входовом, в любом. Если количество входов не проблема, еще проще. Уверяю, при одинаковых условиях я сделаю схему существенно меньше и быстрее.
Ну, очевидно, что самосинхроника в тупике. По быстродействию не лучше синхронных, по площади уступает сильно. Единственно хорошо с энергопотреблением. Но и здесь предел не достигнут. Индикатор — по сути тот же тактовый генератор, только умный, подстраивается под скорость схемы.
Я не настаиваю на двухвходовых реализациях. Это экстремальный пример. Могу сделать в 3-входовом базисе, могу в 4-входовом, в любом. Если количество входов не проблема, еще проще. Уверяю, при одинаковых условиях я сделаю схему существенно меньше и быстрее.
Ну, очевидно, что самосинхроника в тупике. По быстродействию не лучше синхронных, по площади уступает сильно. Единственно хорошо с энергопотреблением. Но и здесь предел не достигнут. Индикатор — по сути тот же тактовый генератор, только умный, подстраивается под скорость схемы.
Спасибо Вам, Леонид Петрович, за указание массы источников для прочтения. И Вашему оппоненту спасибо тоже.
Пункт 2. Здесь же на хабре схема в 200 с лишним сигналов. Все переключения до одного выписаны.
Я, честное слово, сразу заметил, что в книге нет событийных описаний.
Если ДИ, ДП описывают автономные схемы, это проблема только этих моделей. Введите входные, выходные сигналы. То что описание представляет собой замкнутую структуру — это хорошо. Оно описывает две половинки единого целого: поведение схемы и поведение внешней среды. При желании их можно разделить. Поэтому смысл функционального подхода сужается до одного пункта: отказаться от событийных описаний.
Я, честное слово, сразу заметил, что в книге нет событийных описаний.
Если ДИ, ДП описывают автономные схемы, это проблема только этих моделей. Введите входные, выходные сигналы. То что описание представляет собой замкнутую структуру — это хорошо. Оно описывает две половинки единого целого: поведение схемы и поведение внешней среды. При желании их можно разделить. Поэтому смысл функционального подхода сужается до одного пункта: отказаться от событийных описаний.
Пункт 3. По поводу терминологии действительно ломать копья не стоит. Главное понимать друг друга.
По поводу определения. Читаем в книге следующий абзац: отказобезопасность — свойство схемы останавливаться при константных неисправностях. Не что иное как бесконечная задержка. Второй пункт следствие первого. А первый пункт обеспечивается двухфазностью и индикацией в совокупности. При кодировании сигнала обязательна нужна структура, отслеживающая изменение на одном из двух проводов.
По поводу полумодулярности совершенно согласен. У меня по этому поводу несколько абзацев в конце.
По поводу определения. Читаем в книге следующий абзац: отказобезопасность — свойство схемы останавливаться при константных неисправностях. Не что иное как бесконечная задержка. Второй пункт следствие первого. А первый пункт обеспечивается двухфазностью и индикацией в совокупности. При кодировании сигнала обязательна нужна структура, отслеживающая изменение на одном из двух проводов.
По поводу полумодулярности совершенно согласен. У меня по этому поводу несколько абзацев в конце.
Пункт 4. О сложности описаний. Посчитаем буквы. Для начала возьмем автономные поведения, где сигналы переключаются по 2 раза. N — количество сигналов. Сложность событийного описания 2*N. При функциональном описании этого хватило бы только для описания схемы, состоящей из одних инверторов.
Я не против описать 4-разрядное АЛУ. Сообщите подробнее что от него требуется. Заодно иерархическое событийное описание продемонстрирую.
По поводу Варшавского. Это не он пошутил: «Вы могли бы вложиться в нас с точно таким же результатом»?
По поводу «метода Маллера» да, погорячился. Пусть будет метод Варшавского. Суть от этого не меняется: проверка на полумодулярность и вычисление функций.
А ДИ я не люблю. Если уж классифицировать описания, то событийные надо поделить пополам: на модели событий и модели состояний. На мой взгляд последние еще хуже функциональных описаний.
Инициатор и континуатор все-таки события и имеют хоть и опосредованную, но причинно-следственную связь.
Я не против описать 4-разрядное АЛУ. Сообщите подробнее что от него требуется. Заодно иерархическое событийное описание продемонстрирую.
По поводу Варшавского. Это не он пошутил: «Вы могли бы вложиться в нас с точно таким же результатом»?
По поводу «метода Маллера» да, погорячился. Пусть будет метод Варшавского. Суть от этого не меняется: проверка на полумодулярность и вычисление функций.
А ДИ я не люблю. Если уж классифицировать описания, то событийные надо поделить пополам: на модели событий и модели состояний. На мой взгляд последние еще хуже функциональных описаний.
Инициатор и континуатор все-таки события и имеют хоть и опосредованную, но причинно-следственную связь.
Последнее. Вся критика событийного подхода обосновывается одним: «Мы не умеем». Я умею.
Комментарий Л.П.Плеханова
1. Меня удивляют манеры на этом форуме: безапелляционность суждений при
отсутствии/ограниченности знаний и понимания предмета.
Споры приобретают характер перепирательств.
Так в научных кругах не принято.
Такие дискуссии вводят в заблуждение аудиторию, которая не очень в курсе, но
интересуется.
Если хотите обсуждать книгу, потрудитесь понять хотя бы идею.
2. Одному из комментаторов понадобилось больше теории.
Но, как сказано Оккамом, не придумывайте лишних сущностей, читайте
теории Маллера и Варшавского, их достаточно для создания самосинхронных (СС)
схем. Также читайте упомянутую комментатором превосходную книгу:
Мараховский В. Б., Розенблюм Л. Я., Яковлев А. В.
«Моделирование параллельных процессов. Сети Петри», СПб, 2014.
Там и про самосинхронные схемы (именно этот термин) и про роль В.И.Варшавского.
Это все событийный подход.
3. У меня — другой подход, инженерный.
Хотя все написано в книге, повторю еще раз кратко для заинтересованной
аудитории.
Упомянутые ранее свойства СС-схем:
1) отсутсвие гонок,
2) отказобезопасность
есть следствие полумодулярности. Это не ново, об этом писал еще В.И.Варшавский.
Почему-то дискутанты все про быстродействие (оно по большинству наших
разработок не хуже синхронных аналогов), энергопотребление (оно лучше
синхронных). А про бессбойность и надежность забыли.
Платой за них является повышенные затраты СС-схем в транзисторах. Ничто даром
не дается.
Таким образом, обеспечив полумодулярность, обеспечим эти два свойства схем.
Именно эти свойства хотят получить пользователи от СС-схем, в этом уникальность
таких схем.
Теперь перевернем задачу. Если неким образом сразу обеспечить эти свойства, без
событийности, то не надо майнить полумодулярность, не нужны ДП, ДИ, STG и Петри
(при всем к ним уважении).
Этот некий способ есть функциональных подход.
Делаем иерархически, на каждом уровне собираем фрагмент и проверяем полученное.
1) Собираем по В.И.Варшавскому: двухфазная работа, парафазное представление,
индикация. Здесь настолько все отработано, что придумать нечего.
2) А проверяем каждое из двух свойств по отдельности.
Отсутсвие гонок — по межсоединениям элементов, т.е. по структуре. В подходе
сформулированы для этого правила соединений. А инициаторы и континуаторы — это
не сигналы. Это провода, соединения.
Отказобезопасность:
а) на самом нижнем уровне — прямой метод: делается один расчет функций
без отказов, затем имитируется отказ каждого элемента и сравниваются резултаты
с первым расчетом. Делается вывод о том, остановится ли схема при каждом
отдельном отказе.
б) на всех остальных более верхних уровнях — также межсоединения уже фрагментов
и трансляция списков индикации внутренних переменных на выходы верхнего
фрагмента. Это еще проще, чем на самом нижнем уровне.
Хотя это не нужно для практики, но многократно проверено, что построенные так
схемы при правильном замыкании являются полумодулярными.
4. Теперь об элементах и библиотеках.
Вот примеры элементов из промышленной библиотеки СС-элементов 65нм
в Зеленограде:
A2O211AI с функцией Y = ^((A0*A1+B)*C0*C1),
O22A2O2I с функцией Y = ^((A0+A1)*(B0+B1)+C).
5. Если Рецензент желает создать 4-разрядное АЛУ (полумодулярное/SI/
самосинхронное), флаг ему в руки.
Условия таковы:
Минимальная конфигурация всех АЛУ:
а) 2 операнда (здесь по 4 бита),
б) операции:
— сложеиние/вычитание,
— сдвиги туда-сюда,
— побитовые И, ИЛИ, НЕ.
Для гарантии полумодулярности надо учесть все рабочие состояния и переходы
(например от одной команды к другой) для всех сочетаний значений операндов,
коих ровно 256.
Л.П.Плеханов
1. Меня удивляют манеры на этом форуме: безапелляционность суждений при
отсутствии/ограниченности знаний и понимания предмета.
Споры приобретают характер перепирательств.
Так в научных кругах не принято.
Такие дискуссии вводят в заблуждение аудиторию, которая не очень в курсе, но
интересуется.
Если хотите обсуждать книгу, потрудитесь понять хотя бы идею.
2. Одному из комментаторов понадобилось больше теории.
Но, как сказано Оккамом, не придумывайте лишних сущностей, читайте
теории Маллера и Варшавского, их достаточно для создания самосинхронных (СС)
схем. Также читайте упомянутую комментатором превосходную книгу:
Мараховский В. Б., Розенблюм Л. Я., Яковлев А. В.
«Моделирование параллельных процессов. Сети Петри», СПб, 2014.
Там и про самосинхронные схемы (именно этот термин) и про роль В.И.Варшавского.
Это все событийный подход.
3. У меня — другой подход, инженерный.
Хотя все написано в книге, повторю еще раз кратко для заинтересованной
аудитории.
Упомянутые ранее свойства СС-схем:
1) отсутсвие гонок,
2) отказобезопасность
есть следствие полумодулярности. Это не ново, об этом писал еще В.И.Варшавский.
Почему-то дискутанты все про быстродействие (оно по большинству наших
разработок не хуже синхронных аналогов), энергопотребление (оно лучше
синхронных). А про бессбойность и надежность забыли.
Платой за них является повышенные затраты СС-схем в транзисторах. Ничто даром
не дается.
Таким образом, обеспечив полумодулярность, обеспечим эти два свойства схем.
Именно эти свойства хотят получить пользователи от СС-схем, в этом уникальность
таких схем.
Теперь перевернем задачу. Если неким образом сразу обеспечить эти свойства, без
событийности, то не надо майнить полумодулярность, не нужны ДП, ДИ, STG и Петри
(при всем к ним уважении).
Этот некий способ есть функциональных подход.
Делаем иерархически, на каждом уровне собираем фрагмент и проверяем полученное.
1) Собираем по В.И.Варшавскому: двухфазная работа, парафазное представление,
индикация. Здесь настолько все отработано, что придумать нечего.
2) А проверяем каждое из двух свойств по отдельности.
Отсутсвие гонок — по межсоединениям элементов, т.е. по структуре. В подходе
сформулированы для этого правила соединений. А инициаторы и континуаторы — это
не сигналы. Это провода, соединения.
Отказобезопасность:
а) на самом нижнем уровне — прямой метод: делается один расчет функций
без отказов, затем имитируется отказ каждого элемента и сравниваются резултаты
с первым расчетом. Делается вывод о том, остановится ли схема при каждом
отдельном отказе.
б) на всех остальных более верхних уровнях — также межсоединения уже фрагментов
и трансляция списков индикации внутренних переменных на выходы верхнего
фрагмента. Это еще проще, чем на самом нижнем уровне.
Хотя это не нужно для практики, но многократно проверено, что построенные так
схемы при правильном замыкании являются полумодулярными.
4. Теперь об элементах и библиотеках.
Вот примеры элементов из промышленной библиотеки СС-элементов 65нм
в Зеленограде:
A2O211AI с функцией Y = ^((A0*A1+B)*C0*C1),
O22A2O2I с функцией Y = ^((A0+A1)*(B0+B1)+C).
5. Если Рецензент желает создать 4-разрядное АЛУ (полумодулярное/SI/
самосинхронное), флаг ему в руки.
Условия таковы:
Минимальная конфигурация всех АЛУ:
а) 2 операнда (здесь по 4 бита),
б) операции:
— сложеиние/вычитание,
— сдвиги туда-сюда,
— побитовые И, ИЛИ, НЕ.
Для гарантии полумодулярности надо учесть все рабочие состояния и переходы
(например от одной команды к другой) для всех сочетаний значений операндов,
коих ровно 256.
Л.П.Плеханов
У меня вопросы остались. Бывают ли не самосинхронные схемы, но не зависящие от задержек элементов? Если да, обладают ли они уникальными свойствами (а если не обладают, то почему)? Может ли схема называться самосинхронной если у нее нет кодированного представления сигналов?
Охватывает ли метод поведения с выбором? Может выбор считается не существенным типом поведения, без которого можно обойтись? Или этот вопрос пока остается открытым?
Раз речь зашла о библиотеке элементов, видимо ограничение базиса реализации имеет место. Есть ли в этом направлении какие-то теоретические результаты?
Рецензент не брал на себя обязательств сделать АЛУ. Он говорил только об исходном задании. Но раз уж зашла речь, будет время что-нибудь наваяю.
А на стр. 180 речь все-таки об упорядоченности переключений сигналов.
Охватывает ли метод поведения с выбором? Может выбор считается не существенным типом поведения, без которого можно обойтись? Или этот вопрос пока остается открытым?
Раз речь зашла о библиотеке элементов, видимо ограничение базиса реализации имеет место. Есть ли в этом направлении какие-то теоретические результаты?
Рецензент не брал на себя обязательств сделать АЛУ. Он говорил только об исходном задании. Но раз уж зашла речь, будет время что-нибудь наваяю.
А на стр. 180 речь все-таки об упорядоченности переключений сигналов.
Сергей, независимость от задержек элементов — следствие полумодулярности (математический термин — читайте книгу Мараховского-Яковлева-Розенблюма), а независимость от задержек в проводах и элементах — свойство дистрибутивности (снова математический термин, фактически означающий более жесткую полумодулярность). Все полумодулярные (и дистрибутивные) схемы — самосинхронные. При этом, обратное утверждение не верно. Что из этого следует: если и можно делать «не самосинхронные схемы, но не зависящие от задержек элементов», то необходимо придумать математическое доказательство «независимости от ..». Лично мне ничего неизвестно о существовании чего то подобного.
Про кодирование. Для автоматов, полученных по графу или таблице переходов, используется синфазное кодирование. А вот для самосинхронной реализации арифметики кроме логического нуля и единицы необходимо передавать третье состояние, поэтому вынужденно используется более сложное кодирование сигналов: парафазное, трех- четырех- и т.д. фазное. Если придумаете, как по другому (без третьего логического состояния сигнала) проектировать самосинхронную реализацию арифметики, сделаете революцию (кажется, я повторяюсь).
p.s. Для самосинхронной реализации арифметики с использованием парафазного кодирования Варшавский придумал несколько методов, лучший из которых (на мой взгляд) — перекрестная реализация. Что такое «функциональный подход» мне не очень понятно, но вот «перекрестная реализация» Варшавского очень даже работает. Для этого метода можно адаптировать коммерческие САПР синтеза (Genus, Design Compiler и т.д.). По ПЛИС ничего сказать не могу, программируемой логикой не занимаюсь.
Про кодирование. Для автоматов, полученных по графу или таблице переходов, используется синфазное кодирование. А вот для самосинхронной реализации арифметики кроме логического нуля и единицы необходимо передавать третье состояние, поэтому вынужденно используется более сложное кодирование сигналов: парафазное, трех- четырех- и т.д. фазное. Если придумаете, как по другому (без третьего логического состояния сигнала) проектировать самосинхронную реализацию арифметики, сделаете революцию (кажется, я повторяюсь).
p.s. Для самосинхронной реализации арифметики с использованием парафазного кодирования Варшавский придумал несколько методов, лучший из которых (на мой взгляд) — перекрестная реализация. Что такое «функциональный подход» мне не очень понятно, но вот «перекрестная реализация» Варшавского очень даже работает. Для этого метода можно адаптировать коммерческие САПР синтеза (Genus, Design Compiler и т.д.). По ПЛИС ничего сказать не могу, программируемой логикой не занимаюсь.
Алексей, что-то Вы опять поторопились, срочно исправляйтесь. Я про то, что независимость от задержек элементов и проводов это дистрибутивность. В Вашем духе могу посоветовать: читайте википедию, гы-гы. Посмотрел книгу, которую Вы порекомендовали. Там с терминологией порядок. В итоге могу сказать, что я проповедую самосинхронные схемы, работающие в однофазном режиме. Только чем вам SI не угодил? А все самосинхронщики должны уточнять, что развивают именно многофазное направление. Так что необходимость математического доказательства отпадает. Кстати, сама Ваша формулировка не очень корректна: если уж схема не самосинхронна, то значит зависит от задержек.
Революцию я уже сделал. Арифметика реализована без кодирования, фаз и т.д. Это сделано с помощью выбора. А выбор, как я вижу является неудобной темой. Если кто о нем упоминает, то вскользь. На самом деле выбор проще, чем параллелизм. Надо только в этом разобраться.
Многофазный подход имеет полное право на существование. Он специально заточен под комбинационные схемы. Только надо учитывать, что решение с заранее навязанной структурой заведомо избыточно. Ну, и за пределами комбинационных схем такой подход мягко говоря не очень удобен.
Революцию я уже сделал. Арифметика реализована без кодирования, фаз и т.д. Это сделано с помощью выбора. А выбор, как я вижу является неудобной темой. Если кто о нем упоминает, то вскользь. На самом деле выбор проще, чем параллелизм. Надо только в этом разобраться.
Многофазный подход имеет полное право на существование. Он специально заточен под комбинационные схемы. Только надо учитывать, что решение с заранее навязанной структурой заведомо избыточно. Ну, и за пределами комбинационных схем такой подход мягко говоря не очень удобен.
Что такое «выбор»?
Сергей, если сделали революцию, то изложите в понятной всем форме. Я имею ввиду, что арифметику не задают в виде STG, это громоздко и потому неудобно. Кроме того, арифметика сама по себе не интересна, а интересна только в составе автомата. К примеру, автомата Мура(арифметика, и после нее память + обратная связь). Это очень простая задача, сделать самосинхронный автомат Мура, если использовать dual rail. Так покажите как работает Ваш метод, постройте асинхронный (SI или как угодно) автомат Мура на single rail. Только исходную функцию задавайте в классическом виде f=a&b+c, а не STG. Либо сначала покажите, как получить STG по функции, заданной в классическом виде. На мой взгляд, это не тривиальная задача.
Да уже сделана арифметика с памятью ( a+b — обычное, не логическое). Я уже говорил: через выбор. Подробнее, как соберусь с силами. То что схема большая — результат самоограничения в элементной базе. Более сложная арифметика делается примерно также. А то что записать уравнение проще, чем рисовать поведение, не спорю.
НЛО прилетело и опубликовало эту надпись здесь
можно
НЛО прилетело и опубликовало эту надпись здесь
Я думаю, любую программу можно реализовать аппаратными средствами. Тут вопрос цены. Готовы ли платить за скорость железом.
НЛО прилетело и опубликовало эту надпись здесь
Если сигнал представлен одним проводом, то изменение на этом проводе и есть окончание переходного процесса. Если же сигнал представлен 2 проводами (кодирование), окончание переходного процесса нужно отслеживать по 2 проводам. Необходима какая-то структура, которая бы этим занималась. Такой структурой является индикатор. Кодирование введено для реализации в монотонном базисе, чтобы все входы элемента переключались в одном направлении. Поэтому нельзя при переключении сигнала просто поменять 1 на 0 (и наоборот) на обоих проводах, представляющих сигнал. Надо сначала оба провода перевести в 0 (это и есть вторая фаза — спейсер), и только после этого подать 1 на соответствующий провод. Это рабочая фаза. Вот именно с этим и связано разделение на фазы.
Коллеги.
А другого места обсуждать научные публикации нету, кроме как на Хабре?
Я по моему если не ошибаюсь, это приветствуется в рамках конференций и научных журналов.
Еще, в мое время, авторам замечания по книгам писали напрямую, сейчас я думаю тоже это не проблема.
P.S. Понравилось как составлены структурно статьи и что за обсуждение никто на личности не перешел. Это приятно видеть :-)
А другого места обсуждать научные публикации нету, кроме как на Хабре?
Я по моему если не ошибаюсь, это приветствуется в рамках конференций и научных журналов.
Еще, в мое время, авторам замечания по книгам писали напрямую, сейчас я думаю тоже это не проблема.
P.S. Понравилось как составлены структурно статьи и что за обсуждение никто на личности не перешел. Это приятно видеть :-)
Ну, мы так решили — раз уж замечания были опубликованы без нашего ведома публично, то и ответ мы дадим публичный. А дальше да, лично я теперь пытаюсь организовать онлайн-встречу оппонентов :)
Хм, ну подход конечно логичный.
Но я бы вообще радовался, что кто то (бесплатно!) рецензирует статьи. Если что то оскорбительное бы написали — другой вопрос, а что человек как то не так что то понял, или спорит т.к. имеет другие данные (может быть вообще парадигму) — это нормально.
Жаль в ВАКовских журналах такого нет — может быть, статьи писали бы качественнее.
Но я бы вообще радовался, что кто то (бесплатно!) рецензирует статьи. Если что то оскорбительное бы написали — другой вопрос, а что человек как то не так что то понял, или спорит т.к. имеет другие данные (может быть вообще парадигму) — это нормально.
Жаль в ВАКовских журналах такого нет — может быть, статьи писали бы качественнее.
Ну с Сергеем, автором замечаний у меня был контакт в Скайпе до опубликованных ответов. Так что здесь никто не чьи интересы не задевает, а идет вполне интересная научная и что важно открытая дискуссия. И то, что она публичная, на мой взгляд в этом только плюсы.
Я же свою точку зрения обозначил в предисловии. В нашем отделе достигнуты хорошие результаты по самосинхронным схемам, но как это часто бывает в постсоветской науке, никто не предает эти данные широкой огласке, только публикации в профильных конференциях и сборниках, например МЭС. Я со своей стороны считаю, что надо рассказывать о результатах и давно хотел осветить тему на Хабре. Буквально на прошлой неделе получил добро на публикацию серии статей по самосинхронике и на тебе — Сергей ajrec предоставил такой шанс опубликоваться оперативно :) Так что лично я надеюсь, это только начало и в дальнейшем будет интереснее, уже не только в рамках научных диспутов, а в рамках популяризации подхода. И последующие статьи будут рассчитаны на более широкую аудиторию. Стей тюнед. :)
Я же свою точку зрения обозначил в предисловии. В нашем отделе достигнуты хорошие результаты по самосинхронным схемам, но как это часто бывает в постсоветской науке, никто не предает эти данные широкой огласке, только публикации в профильных конференциях и сборниках, например МЭС. Я со своей стороны считаю, что надо рассказывать о результатах и давно хотел осветить тему на Хабре. Буквально на прошлой неделе получил добро на публикацию серии статей по самосинхронике и на тебе — Сергей ajrec предоставил такой шанс опубликоваться оперативно :) Так что лично я надеюсь, это только начало и в дальнейшем будет интереснее, уже не только в рамках научных диспутов, а в рамках популяризации подхода. И последующие статьи будут рассчитаны на более широкую аудиторию. Стей тюнед. :)
НЛО прилетело и опубликовало эту надпись здесь
Я сижу в деревне. Ни с какими научными, производственными структурами не связан. Податься мне некуда.
Товарищи учёные!
А расскажите лаптю о том, какие результаты на сегодня достигнуты на поприще самосинхронных схем?
Вот, в частности, упомянута реализация FMA (Fused Multiply Add, я так понимаю?) для Комдива.
Получилось ли в итоге компактнее или быстрее или эффективнее по мощности, чем стандартные 3-5 стадий пайплайна? А насколько?
Самый интересный вопрос: как оценивается работоспособноть схемы после производства? В обычной методологии есть дорогой, но понятный Design For Test со всеми регистрами в скан-чейне, пачкой тестовых векторов и ожидаемыми результатами комбинационной логики. А здесь?
Скорость работы такого юнита, как я понимаю, будет варьироваться от чипа к чипу. Как это вписывается в фиксированный процессорный конвейер?
Можно ли выразить эту методологию своими словами, без ссылок на литератуту и (особенно) википедию, для тех, кто знаком со стандартным подходом?
А расскажите лаптю о том, какие результаты на сегодня достигнуты на поприще самосинхронных схем?
Вот, в частности, упомянута реализация FMA (Fused Multiply Add, я так понимаю?) для Комдива.
Получилось ли в итоге компактнее или быстрее или эффективнее по мощности, чем стандартные 3-5 стадий пайплайна? А насколько?
Самый интересный вопрос: как оценивается работоспособноть схемы после производства? В обычной методологии есть дорогой, но понятный Design For Test со всеми регистрами в скан-чейне, пачкой тестовых векторов и ожидаемыми результатами комбинационной логики. А здесь?
Скорость работы такого юнита, как я понимаю, будет варьироваться от чипа к чипу. Как это вписывается в фиксированный процессорный конвейер?
Можно ли выразить эту методологию своими словами, без ссылок на литератуту и (особенно) википедию, для тех, кто знаком со стандартным подходом?
Я не ученый, но немного занимался темой в босоногом детстве. Представляете себе pipeline с back-pressure? Теперь представьте себе, что механизм back-pressure реализован на уровне логических/запоминающих элементов. При таком подходе вам не нужен тактовый сигнал, каждый элемент сам знает, когда он готов принять новые данные и когда у него есть новые данные, и сообщает об этом соседям.
Интеграция с синхронными схемами, очевидно потребует сигнала BP и сигнала готовности данных, достаточно тривиально.
Интеграция с синхронными схемами, очевидно потребует сигнала BP и сигнала готовности данных, достаточно тривиально.
Ну вот именно в процессорных конвейерах backpressure в чистом виде работает не очень хорошо (собственно, отсюда и вопросы)
Например, в случае явной зависимости:
Умножение почти всегда имеет latency три и выше тактов, а сложение — один, редко два. Физически, сложение что так, что эдак быстрее.
При этом, декодировать инструкцию и зачитать операнды все же нужно. И вот, если я наперед знаю, что результат умножения готов через четыре такта, я могу запустить зависимое сложение на исполнение через три, когда результа первой инструкции еще нет.
Получается:
Вместо случая с backpressure, когда сначала нужно подождать, пока умножение завершится полностью:
Например, в случае явной зависимости:
r3 = mul(r2, r1)
r5 = add(r3, r4)Умножение почти всегда имеет latency три и выше тактов, а сложение — один, редко два. Физически, сложение что так, что эдак быстрее.
При этом, декодировать инструкцию и зачитать операнды все же нужно. И вот, если я наперед знаю, что результат умножения готов через четыре такта, я могу запустить зависимое сложение на исполнение через три, когда результа первой инструкции еще нет.
Получается:
mul RF M1 M2 M3 M4 WB
add __ __ __ __ RF EX WBВместо случая с backpressure, когда сначала нужно подождать, пока умножение завершится полностью:
mul RF M1 M2 M3 M4 WB
add __ __ __ __ __ RF EX WBНу вот тут как раз имеет значение эта тонкость, что BP реализован поэлементно. Те ступени конвейера, которые не требуют результата умножения спокойно выполнятся. Только когда потребуются данные от умножатора, все зависнет.
Это абстрактно, конечно, что именно кого ждет зависит от реализации. У меня сложилось впечатление, что асинхронщина больше подходит для какого-нибудь кастомного dataflow, чем для процессора общего назначения.
Это абстрактно, конечно, что именно кого ждет зависит от реализации. У меня сложилось впечатление, что асинхронщина больше подходит для какого-нибудь кастомного dataflow, чем для процессора общего назначения.
Вы абсолютно правы. Самосинхронная схемотехника очень похожа по своему, скажем так, «духу» :) на dataflow. Более того, в нашем отделе мы разрабатываем рекуррентный процессор, который является в том числе потоковым (dataflow) и очень надеемся, что хватит сил и самое главное ресурсов (с этим сами понимаете, не очень) реализовать самосинхронный вариант рекуррентного процессора.
Что касается конвейера. Насколько я представляю, то конвейер также как и самосинхронная схемотехника работает по принципу запрос-ответа. То есть, если ступени будут короткими, то эффект будет по сравнению с синхронной реализацией, если будет какая-то ступень длинной, то тут все будет также как и в синхронном случае. Во всяком случае мне так это видится. Насчет поднятой вами темы с предсказанием окончания операции, ну на вскидку вы правы. Уточню видение у начальника отдела.
Что касается конвейера. Насколько я представляю, то конвейер также как и самосинхронная схемотехника работает по принципу запрос-ответа. То есть, если ступени будут короткими, то эффект будет по сравнению с синхронной реализацией, если будет какая-то ступень длинной, то тут все будет также как и в синхронном случае. Во всяком случае мне так это видится. Насчет поднятой вами темы с предсказанием окончания операции, ну на вскидку вы правы. Уточню видение у начальника отдела.
А с другой стороны, для поддержки такого рода решений, можно также реализовать сигнал-индикатор, который позволит начать параллельное сложение до окончания умножения. Посложнее конечно, но в целом тоже можно как мне кажется такое реализовать.
По скольку я в данном случае лишь посредник (как я говорил, я занят рекуррентным процессором, а не самосинхроникой), хоть и с очевидной целью популяризации достижений нашего отдела, я не берусь браться за такие комментарии.
Но! Кое-что сообщу. Вот например вот здесь можно почитать, несмотря на то, что статья аж 2007 года (к вопросу о популяризации науки, а точнее о полной ее отсутствии):
САМОСИНХРОННАЯ СХЕМОТЕХНИКА – ПЕРСПЕКТИВНЫЙ
ПУТЬ РЕАЛИЗАЦИИ АППАРАТУРЫ
Там в частности, проводится сравнение двух микроядер, реализованных в базисе БМК на синхронной и самосинхронной основе.
И выводы:
Что касается FMA, то я получил такой ответ, в апреле месяце мы опубликуем подробную статью на этот счет. Сейчас готовится статья на МЭС-2018, и поэтому будет полноценный развернутый ответ уже здесь на Хабре. Извините, что не ответил на Ваш вопрос полностью. Надеюсь, хотя бы частично ответил на первую часть :)
Но! Кое-что сообщу. Вот например вот здесь можно почитать, несмотря на то, что статья аж 2007 года (к вопросу о популяризации науки, а точнее о полной ее отсутствии):
САМОСИНХРОННАЯ СХЕМОТЕХНИКА – ПЕРСПЕКТИВНЫЙ
ПУТЬ РЕАЛИЗАЦИИ АППАРАТУРЫ
Там в частности, проводится сравнение двух микроядер, реализованных в базисе БМК на синхронной и самосинхронной основе.
Как будет показано ниже, реальное среднее быстродействие ССС-образцов на
рассматриваемой смеси операций почти в два раза выше заданного быстродействия С-
образцов. Попытка увеличения входной тактовой частоты С-образцов в 1,5 раза (до
24 МГц или до 6 МГц их рабочей частоты) как и ожидалось, негативно сказывается на
зоне их работоспособности. Из рис. 4 видно, что при этом нижняя граница
работоспособности питающих напряжений у образцов № 2 и № 4 превышает
гарантированный минимум 4,65 B и 4,51 В, соответственно. Таким образом, следует
признать, что 50-процентное повышение быстродействия С-образцов невозможно по
причине резкого снижения выхода годных БМК-микросхем.
На рис. 5 приведены результаты экспериментов по проверке работоспособности
всех рассмотренных выше ССС-образцов и одного С-образца (№ 2) в рассмотренном
выше диапазоне питающих напряжений и при изменении температуры окружающей
среды в диапазоне от – 63 до +1250 C.
Зона работоспособности у всех четырех испытанных ССС-образцов осталась
абсолютно идентичной, что является косвенным подтверждением наличия у них свойства
строгой самосинхронности – независимости поведения от задержек элементов. При этом
зона их работоспособности в области высоких температур расширилась – предельное
напряжение, при котором прекращалась работа ССС-образцов, снизилось с 0,6 до 0,4 В.
Дальнейшие исследования показали, что исключение из цепи питания микросхем
миллиамперметра и использование низкоомного провода минимальной длины от источника
питающего напряжения до микросхемы позволяет расширить зону работоспособности до
беспрецедентно низкого уровня – 0,2 В. Этот интересный феномен требует дополнительного
исследования и подтверждения на более представительной выборке микросхем
И выводы:
Самосинхронная аппаратура характеризуется реальным быстродействием,
самонастраивающимся (адаптирующимся) на реальные условия работы: уровень
питающего напряжения, температуру окружающей среды, текущее состояние параметров
элементной базы, вид обрабатываемой информации и т.д. Эффективные самосинхронные
решения обеспечивают более высокое быстродействие аппаратуры. Например, в зоне
работоспособности, гарантированной изготовителем БМК, быстродействие ССС-
Микроядра в среднем выше быстродействия С-Микроядра почти в 2 раза.
3. Самосинхронное исполнение аппаратуры обеспечивает создание энергетически
эффективных аппаратных решений. Например, во всем исследуемом диапазоне
работоспособности тестируемых кристаллов энергетическая эффективность ССС-
Микроядра по сравнению с С-Микроядром была не ниже 50 %.
Что касается FMA, то я получил такой ответ, в апреле месяце мы опубликуем подробную статью на этот счет. Сейчас готовится статья на МЭС-2018, и поэтому будет полноценный развернутый ответ уже здесь на Хабре. Извините, что не ответил на Ваш вопрос полностью. Надеюсь, хотя бы частично ответил на первую часть :)
Спасибо! Статья по ссылке выше весьма любопытна. Самый интересный (с моей точки зрения) вопрос верификации и сравнения с DFT коварно обойден стороной, но (а) поддержки DFT на БМК может и не быть и (б) вообще круто, что оно работает. Ну и про интеграцию FMA завсегда интересно почитать.
Я вот сам начинаю припоминать, что несколько лет назад были публикации на тему полностью асинхронного МИПСа.
Вот сходу нашлось две:
http://www.cs.bham.ac.uk/research/projects/parlard/papers/acsac2003-37.pdf
http://ieeexplore.ieee.org/document/634853/
Судя по авторам и организациям, это разные группы.
Вот такое — это та же техника, что в книге или что-то совсем другое?
Я вот сам начинаю припоминать, что несколько лет назад были публикации на тему полностью асинхронного МИПСа.
Вот сходу нашлось две:
http://www.cs.bham.ac.uk/research/projects/parlard/papers/acsac2003-37.pdf
http://ieeexplore.ieee.org/document/634853/
Судя по авторам и организациям, это разные группы.
Вот такое — это та же техника, что в книге или что-то совсем другое?
DFT — это вы про преобразование Фурье? Эм, там же делалась копия ядра PIC18 кажется, даже не припомню как там с БПФ, FMA помоему там точно нет. Давно дело было и не помню.
На Западе регулярно всплывают статьи по асинхронным/самосинхронным схемам. Чаще всего это творения учеников Варшавского, уехавших на Запад. Но насколько я понимаю, там так называемая квазисамосинхронная схемотехника. т.е. стабильность работы схемы добивается встраиванием элементов задержки, что искусственно занижает быстродействие в целях надежного завершения переходных процессов, но по сути является неким аналогом такта. Поэтому в ИПИ РАН и был введет термин Строго-самосинхронные схемы (ССС), чтобы различать с такими квазисамосинхронными.
На Западе регулярно всплывают статьи по асинхронным/самосинхронным схемам. Чаще всего это творения учеников Варшавского, уехавших на Запад. Но насколько я понимаю, там так называемая квазисамосинхронная схемотехника. т.е. стабильность работы схемы добивается встраиванием элементов задержки, что искусственно занижает быстродействие в целях надежного завершения переходных процессов, но по сути является неким аналогом такта. Поэтому в ИПИ РАН и был введет термин Строго-самосинхронные схемы (ССС), чтобы различать с такими квазисамосинхронными.
Нет-нет, DFT — это я выше расшифровал, Design For Test. Правильно говорят, что аббревиатуры — зло :)
Это решение проблемы «как определить работоспособен ли чип после изготовления». В случае с микропроцессором, факта включения и исполнения программ для оценки работоспособности недостаточно даже близко, вот в частности из-за проблем с состоянием. Поэтому в синхронной технике есть такое решение: все триггеры в системе нанизываются на длинный scan-chain. И если отключить основной тактовый сигнал, мы получем возможность считывать и записывать любое состояние, целиком, включая невозможные. После этого можно тактировать схему единожды или дважды и сравнить с состоянием расчетным. Входы можно генерировать в том числе и случайно и получить при этом достаточно хорошее покрытие всех элементов схемы (и, что немаловажно, можно посчитать, сколько логики покрыто)
А иначе с этим вообще же работать страшно. Ну перестанет там работать один инвертор, который нужен раз в неделю (я не преувеличиваю, такое бывает) — как такой кристалл отбраковать?
Это решение проблемы «как определить работоспособен ли чип после изготовления». В случае с микропроцессором, факта включения и исполнения программ для оценки работоспособности недостаточно даже близко, вот в частности из-за проблем с состоянием. Поэтому в синхронной технике есть такое решение: все триггеры в системе нанизываются на длинный scan-chain. И если отключить основной тактовый сигнал, мы получем возможность считывать и записывать любое состояние, целиком, включая невозможные. После этого можно тактировать схему единожды или дважды и сравнить с состоянием расчетным. Входы можно генерировать в том числе и случайно и получить при этом достаточно хорошее покрытие всех элементов схемы (и, что немаловажно, можно посчитать, сколько логики покрыто)
А иначе с этим вообще же работать страшно. Ну перестанет там работать один инвертор, который нужен раз в неделю (я не преувеличиваю, такое бывает) — как такой кристалл отбраковать?
Насколько я в курсе, и в статье, что я давал там это должно было упоминаться, у самосинхронных схем с этим как раз лучше. Я не очень понимаю это магию, просто потому что не касался, но самосинхронные схемы обладают свойствами самодиагностики и и даже саморемонта. Вот тут можно почитать:
elibrary.ru/item.asp?id=22105455
Там кстати и про практическую реализацию для КОМДИВа тоже есть. Насколько я помню, в БМК как раз выгодно реализовывать самосинхронные схемы, потому что процент выхода рабочих изделий выше, чем в синхронном варианте. Что-то такое было… Надо уточнять. Вы пишите, я потом по всем вопросам заставлю начальника статью написать сюда :)
Вообще самосинхроника в первую очередь должна найти применение там, где требуется надежность и есть экстримальные условия. Это вот наиболее очевидное применение. В других применениях ее достоинства менее очевидны.
elibrary.ru/item.asp?id=22105455
Там кстати и про практическую реализацию для КОМДИВа тоже есть. Насколько я помню, в БМК как раз выгодно реализовывать самосинхронные схемы, потому что процент выхода рабочих изделий выше, чем в синхронном варианте. Что-то такое было… Надо уточнять. Вы пишите, я потом по всем вопросам заставлю начальника статью написать сюда :)
Вообще самосинхроника в первую очередь должна найти применение там, где требуется надежность и есть экстримальные условия. Это вот наиболее очевидное применение. В других применениях ее достоинства менее очевидны.
Судя по публикациям, зарубежным, DFT делают, точно так же. Ведь самосинхронные схемы используют все тот же базис элементов логики, только триггеры немного более сложные. Не вижу никакой принципиально разницы, разве что — нет смысла в таких продвинутых режимах DFT как at-speed testing. Что касается отечественной электроники, то не каждый дизайн-центр умеет даже в синхронные чипы DFT вставлять… :-)
Вообще вот сайт мы запустили:
selftiming.ru
В ближайшее время он будет переделан, поэтому мы его не пиарим особо. Там проблемы с кодировкой, CMS Modx и много другого. Но в целом там можно найти очень много, но правда не самой свежей информации. В том числе и зарубежные источники. Вот кстати мне статья попалась про конвейер самосинхронный, правда зарубежная статья, хотя где-то мне кажется была и наша…
selftiming.ru/files/articles/foreign/NEGATIVE/negative.pdf
selftiming.ru
В ближайшее время он будет переделан, поэтому мы его не пиарим особо. Там проблемы с кодировкой, CMS Modx и много другого. Но в целом там можно найти очень много, но правда не самой свежей информации. В том числе и зарубежные источники. Вот кстати мне статья попалась про конвейер самосинхронный, правда зарубежная статья, хотя где-то мне кажется была и наша…
selftiming.ru/files/articles/foreign/NEGATIVE/negative.pdf
Мне тут ответы подошли от разных сотрудников отдела, на все комменты по этой статье:
1.
> Вот, в частности, упомянута реализация FMA (Fused Multiply Add, я так понимаю?) для Комдива.
> Получилось ли в итоге компактнее или быстрее или эффективнее по мощности, чем стандартные
> 3-5 стадий пайплайна? А насколько?
ОТВЕТ:
CC схемы изначально характеризуются избыточными аппаратурными затратами, необходимыми для реализации индицируемости элементов схемы, обеспечивающей контроль за окончанием переключения каждого фрагмента СС схемы в очередную фазу работы. Поэтому они никогда не смогут быть «компактнее» своих синхронных аналогов, если речь не идет о реализации отказоустойчивых цифровых устройств.
Вопрос о быстродействии и энергопотреблении пока остается открытым, т.к. спроектированный СС блок Fused Multiply Add еще находится в стадии изготовления. Тестирование более простого устройства — четырехразрядного Микроядра, аналога цифрового ядра микроконтроллера PIC фирмы Microchip, содержащего регистровую память, умножитель, сдвигатель и отказоустойчивый последовательно-параллельный 8-разрядный порт — изготовленного по КМОП технологии с 1.5-мкм проектными нормами на основе базового матричного кристалла 5503БЦ7У (МИЭТ, Москва), в сравнении с синхронным аналогом показало, что быстродействие СС варианта Микроядра в зоне работоспособности синхронного аналога, гарантированной изготовителем БМК, в среднем почти в 2 раза выше быстродействия синхронного аналога на статистически средней последовательности операций. Во всем диапазоне подтвержденной работоспособности протестированных кристаллов энергетическая эффективность (отношение производительности к мощности потребления) СС Микроядра по сравнению с синхронным аналогом была также в 2 раза выше.
2.
> Самый интересный вопрос: как оценивается работоспособноть схемы после производства?
> В обычной методологии есть дорогой, но понятный Design For Test со всеми регистрами
> в скан-чейне, пачкой тестовых векторов и ожидаемыми результатами комбинационной логики.
> А здесь? Скорость работы такого юнита, как я понимаю, будет варьироваться от чипа к чипу.
ОТВЕТ:
СС схемы не имеют дерева синхронизации, и проверять их работоспособность традиционным синхронным методом напрямую нельзя, т.к. время выполнения операции цифровой СС схемой зависит от содержимого операндов. Однако достаточно внести в схему проверки запрос-ответный механизм и можно применять те же самые «Design For Test со всеми регистрами в скан-чейне, пачкой тестовых векторов и ожидаемыми результатами комбинационной логики». Вся разница будет только в том, что в синхронной схеме тестовые вектора подаются на тестируемую схему строго периодически, а в СС схеме смена одно тестового вектора другим будет происходить при наличии сигнала готовности результата, выдаваемого СС схемой. Кстати сказать, и в синхронных схемах изготовленные кристаллы с целью повышения выхода годных разбраковываются на разных частотах. Возьмите, к примеру, линейку процессоров фирмы Intel: один и тот же, с точки зрения начинки, процессор продается по разной цене в зависимости от пиковой устойчивой производительности, продемонстрированной им при тестировании.
> Как это вписывается в фиксированный процессорный конвейер?
ОТВЕТ:
Вписаться в процессорный конвейер с фиксированной частотой, действительно, непросто. Но, во-первых, есть и асинхронные конвейеры (и даже целые асинхронные процессоры, например, семейство Amulet), и во-вторых, существует целый ряд приложений, в которых отдельные функциональные блоки, например, делитель, используются эпизодически и могут быть встроены в общий синхронный конвейер с помощью дополнительных блоков входного и выходного FIFO. Конечно, это задача более сложная, нежели построение традиционного синхронного конвейера, но ведь и «бонус» в виде устойчивой работы в широком диапазоне условий эксплуатации и обретения свойства обнаружения константной неисправности («залипания» выхода или входа элемента в статическом состоянии) тоже чего-то ст'оит?
4.
> Можно ли выразить эту методологию своими словами, без ссылок на литератуту и
> (особенно) википедию, для тех, кто знаком со стандартным подходом?
ОТВЕТ:
В «двух словах».
Общая методология разработки СС схемы заключается в последовательном выполнении ряда этапов.
Разработка комбинационных СС схем включает в себя следующие этапы (для «внутренних» функциональных СС схем, не требующих согласования интерфейса с синхронным окружением):
1) разработка синхронного функционального аналога в базисе логических функций и/или простейших логических ячеек;
2) выбор типа спейсера входных и выходных парафазных сигналов;
3) разработка блока преобразования бифазного кода в парафазный, если источником входных сигналов является триггерное устройство, например, регистр;
4) преобразование синхронного аналога функциональной «начинки» схемы в СС схему с помощью парафазного и/или бифазного кодирования входных, выходных и промежуточных сигналов;
4.1) «дуализация» системы логических функций синхронного аналога — дополнение каждой логической функции ее инверсией;
4.2) замена инверсных значений переменных парафазными сигналами;
5) разработка индикаторной подсхемы.
Разработка триггерных (последовательностных) СС схем включает в себя следующие этапы:
1) разработка синхронного функционального аналога;
2) преобразование синхронного аналога в СС вариант и согласование типа спейсера входных сигналов;
2.1) «дуализация» системы логических функций синхронного аналога — дополнение каждой логической функции ее инверсией;
2.2) замена инверсных значений переменных парафазными сигналами;
3) выбор способа и типа начальной предустановки;
4) разработка индикаторной подсхемы.
Результатом такой разработки является функциональное HDL-описание СС схемы на (Verilog, VHDL), которое затем может быть покрыто элементами используемой библиотеки стандартных элементов программными средствами (логическим синтезатором, например, Design Compiler, Genus) или вручную ;).
В настоящее время, к сожалению, нет готового САПР СС схем (точнее, есть для подкласса СС схем «NULL Convention Logic», имеющих самую большую избыточность среди вариантов реализации СС схем, — система BALSA), но работа в этом направлении ведется.
В конце хотелось бы еще раз напомнить о потенциальных преимуществах СС схем (ради чего всё затевалось):
а) отсутствие накладных аппаратных и энергетических расходов, связанных с реализацией «тактового дерева»;
б) быстродействие, максимально возможное в текущих условиях эксплуатации;
в) естественная устойчивость к параметрическим отказам, вызываемым изменением параметров ячеек из-за процессов старения и неблагоприятных воздействий окружающей среды;
г) максимально возможная область эксплуатации (диапазон работоспособности), определяемая только физическим сохранением переключательных свойств активных ячеек базиса реализации, и, как следствие, возможность работать на пониженном питающем напряжении;
д) естественная самопроверяемость и самодиагностируемость по отношению к множественным константным неисправностям;
е) безопасность функционирования на основе бестестовой локализации неисправностей, т.е. прекращение работы в момент отказа ячейки, исключающее выдачу недостоверной информации, с одновременной локализацией места сбоя;
ж) увеличение числа годных чипов за счет нечувствительности схемы к разбросу параметров;
и) упрощенное тестирование: функциональные тесты одновременно являются и проверочными на неисправности;
к) увеличенный срок службы за счёт нечувствительности к старению;
л) простота стыковки СС схем между собой из-за отсутствия принудительной синхронизации, отсутствие аномального арбитража;
м) высокая эффективность создания надёжных изделий;
н) простота контроля и резервирования;
о) отсутствие проблемы контроля схем контроля;
п) существенно меньший объем аппаратных затрат (не менее, чем в 1,5 раза) при одном и том же коэффициенте покрытия неисправностей при реализации отказоустойчивого устройства.
С наилучшими пожеланиями,
Ю.Дьяченко
1.
> Вот, в частности, упомянута реализация FMA (Fused Multiply Add, я так понимаю?) для Комдива.
> Получилось ли в итоге компактнее или быстрее или эффективнее по мощности, чем стандартные
> 3-5 стадий пайплайна? А насколько?
ОТВЕТ:
CC схемы изначально характеризуются избыточными аппаратурными затратами, необходимыми для реализации индицируемости элементов схемы, обеспечивающей контроль за окончанием переключения каждого фрагмента СС схемы в очередную фазу работы. Поэтому они никогда не смогут быть «компактнее» своих синхронных аналогов, если речь не идет о реализации отказоустойчивых цифровых устройств.
Вопрос о быстродействии и энергопотреблении пока остается открытым, т.к. спроектированный СС блок Fused Multiply Add еще находится в стадии изготовления. Тестирование более простого устройства — четырехразрядного Микроядра, аналога цифрового ядра микроконтроллера PIC фирмы Microchip, содержащего регистровую память, умножитель, сдвигатель и отказоустойчивый последовательно-параллельный 8-разрядный порт — изготовленного по КМОП технологии с 1.5-мкм проектными нормами на основе базового матричного кристалла 5503БЦ7У (МИЭТ, Москва), в сравнении с синхронным аналогом показало, что быстродействие СС варианта Микроядра в зоне работоспособности синхронного аналога, гарантированной изготовителем БМК, в среднем почти в 2 раза выше быстродействия синхронного аналога на статистически средней последовательности операций. Во всем диапазоне подтвержденной работоспособности протестированных кристаллов энергетическая эффективность (отношение производительности к мощности потребления) СС Микроядра по сравнению с синхронным аналогом была также в 2 раза выше.
2.
> Самый интересный вопрос: как оценивается работоспособноть схемы после производства?
> В обычной методологии есть дорогой, но понятный Design For Test со всеми регистрами
> в скан-чейне, пачкой тестовых векторов и ожидаемыми результатами комбинационной логики.
> А здесь? Скорость работы такого юнита, как я понимаю, будет варьироваться от чипа к чипу.
ОТВЕТ:
СС схемы не имеют дерева синхронизации, и проверять их работоспособность традиционным синхронным методом напрямую нельзя, т.к. время выполнения операции цифровой СС схемой зависит от содержимого операндов. Однако достаточно внести в схему проверки запрос-ответный механизм и можно применять те же самые «Design For Test со всеми регистрами в скан-чейне, пачкой тестовых векторов и ожидаемыми результатами комбинационной логики». Вся разница будет только в том, что в синхронной схеме тестовые вектора подаются на тестируемую схему строго периодически, а в СС схеме смена одно тестового вектора другим будет происходить при наличии сигнала готовности результата, выдаваемого СС схемой. Кстати сказать, и в синхронных схемах изготовленные кристаллы с целью повышения выхода годных разбраковываются на разных частотах. Возьмите, к примеру, линейку процессоров фирмы Intel: один и тот же, с точки зрения начинки, процессор продается по разной цене в зависимости от пиковой устойчивой производительности, продемонстрированной им при тестировании.
> Как это вписывается в фиксированный процессорный конвейер?
ОТВЕТ:
Вписаться в процессорный конвейер с фиксированной частотой, действительно, непросто. Но, во-первых, есть и асинхронные конвейеры (и даже целые асинхронные процессоры, например, семейство Amulet), и во-вторых, существует целый ряд приложений, в которых отдельные функциональные блоки, например, делитель, используются эпизодически и могут быть встроены в общий синхронный конвейер с помощью дополнительных блоков входного и выходного FIFO. Конечно, это задача более сложная, нежели построение традиционного синхронного конвейера, но ведь и «бонус» в виде устойчивой работы в широком диапазоне условий эксплуатации и обретения свойства обнаружения константной неисправности («залипания» выхода или входа элемента в статическом состоянии) тоже чего-то ст'оит?
4.
> Можно ли выразить эту методологию своими словами, без ссылок на литератуту и
> (особенно) википедию, для тех, кто знаком со стандартным подходом?
ОТВЕТ:
В «двух словах».
Общая методология разработки СС схемы заключается в последовательном выполнении ряда этапов.
Разработка комбинационных СС схем включает в себя следующие этапы (для «внутренних» функциональных СС схем, не требующих согласования интерфейса с синхронным окружением):
1) разработка синхронного функционального аналога в базисе логических функций и/или простейших логических ячеек;
2) выбор типа спейсера входных и выходных парафазных сигналов;
3) разработка блока преобразования бифазного кода в парафазный, если источником входных сигналов является триггерное устройство, например, регистр;
4) преобразование синхронного аналога функциональной «начинки» схемы в СС схему с помощью парафазного и/или бифазного кодирования входных, выходных и промежуточных сигналов;
4.1) «дуализация» системы логических функций синхронного аналога — дополнение каждой логической функции ее инверсией;
4.2) замена инверсных значений переменных парафазными сигналами;
5) разработка индикаторной подсхемы.
Разработка триггерных (последовательностных) СС схем включает в себя следующие этапы:
1) разработка синхронного функционального аналога;
2) преобразование синхронного аналога в СС вариант и согласование типа спейсера входных сигналов;
2.1) «дуализация» системы логических функций синхронного аналога — дополнение каждой логической функции ее инверсией;
2.2) замена инверсных значений переменных парафазными сигналами;
3) выбор способа и типа начальной предустановки;
4) разработка индикаторной подсхемы.
Результатом такой разработки является функциональное HDL-описание СС схемы на (Verilog, VHDL), которое затем может быть покрыто элементами используемой библиотеки стандартных элементов программными средствами (логическим синтезатором, например, Design Compiler, Genus) или вручную ;).
В настоящее время, к сожалению, нет готового САПР СС схем (точнее, есть для подкласса СС схем «NULL Convention Logic», имеющих самую большую избыточность среди вариантов реализации СС схем, — система BALSA), но работа в этом направлении ведется.
В конце хотелось бы еще раз напомнить о потенциальных преимуществах СС схем (ради чего всё затевалось):
а) отсутствие накладных аппаратных и энергетических расходов, связанных с реализацией «тактового дерева»;
б) быстродействие, максимально возможное в текущих условиях эксплуатации;
в) естественная устойчивость к параметрическим отказам, вызываемым изменением параметров ячеек из-за процессов старения и неблагоприятных воздействий окружающей среды;
г) максимально возможная область эксплуатации (диапазон работоспособности), определяемая только физическим сохранением переключательных свойств активных ячеек базиса реализации, и, как следствие, возможность работать на пониженном питающем напряжении;
д) естественная самопроверяемость и самодиагностируемость по отношению к множественным константным неисправностям;
е) безопасность функционирования на основе бестестовой локализации неисправностей, т.е. прекращение работы в момент отказа ячейки, исключающее выдачу недостоверной информации, с одновременной локализацией места сбоя;
ж) увеличение числа годных чипов за счет нечувствительности схемы к разбросу параметров;
и) упрощенное тестирование: функциональные тесты одновременно являются и проверочными на неисправности;
к) увеличенный срок службы за счёт нечувствительности к старению;
л) простота стыковки СС схем между собой из-за отсутствия принудительной синхронизации, отсутствие аномального арбитража;
м) высокая эффективность создания надёжных изделий;
н) простота контроля и резервирования;
о) отсутствие проблемы контроля схем контроля;
п) существенно меньший объем аппаратных затрат (не менее, чем в 1,5 раза) при одном и том же коэффициенте покрытия неисправностей при реализации отказоустойчивого устройства.
С наилучшими пожеланиями,
Ю.Дьяченко
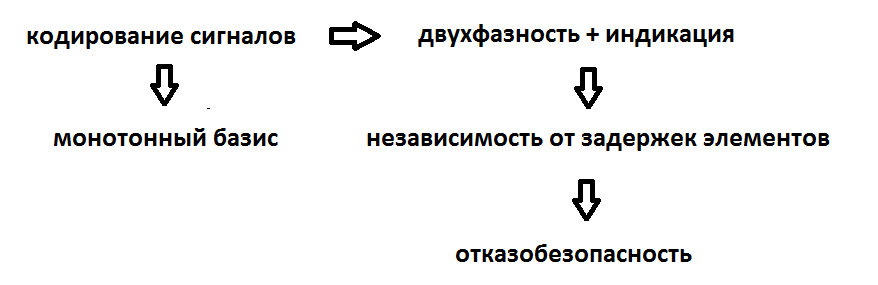
Функционал самосинхронных схем сводится к 3 пунктам: реализация в монотонном базисе, независимость от задержек элементов, совместимость с другими самосинхронными схемами.
НЛО прилетело и опубликовало эту надпись здесь
Это вопрос не ко мне. Из того что я прочитал: достоинством функционального описания как раз считается уход от детализации переключений сигналов.
Редакторы существуют. Очень визуальные и очень удобные. К сожалению, этот софт пишется не у нас. В настоящее время самая сильная группа, занимающаяся самосинхронными схемами, находится в Ньюкасле (Англия)
Обращение к неизвестному. Чем я тебе дорогу то перешел, что так минусишь старательно. Написал бы что не нравится. А то фигу в кармане показываешь. По-детски это.
У меня вот возник вопрос В ответе автора говорится о сложности проектирования 4-разрядного АЛУ. И говорится, что 8-разрядное АЛУ, а тем более 16-разрядное, гораздо сложнее. В связи с этим вопрос: неужели в самосинхронном блоке Вы задействуете сразу все разряды обоих операндов? Да, при сложении есть проблема переноса из младшего разряда. Но формировать группу переноса более, чем из 4 разрядов не практично, элементы получатся слишком сложные.
И не удержусь. В ответе больше эмоций, чем логики. Пример: «отказобезопасность НЕ ЕСТЬ следствие независимости от задержек элементов». В книге, в абзаце сразу за определением: «отказобезопасность — способность схемы останавливаться при константных неисправностях». Константная неисправность — эквивалент бесконечной задержки элемента. При бесконечной задержке элемента схема должна остановиться.
И не удержусь. В ответе больше эмоций, чем логики. Пример: «отказобезопасность НЕ ЕСТЬ следствие независимости от задержек элементов». В книге, в абзаце сразу за определением: «отказобезопасность — способность схемы останавливаться при константных неисправностях». Константная неисправность — эквивалент бесконечной задержки элемента. При бесконечной задержке элемента схема должна остановиться.
Самое главное из виду упустили. В подходе, излагаемом в книге Плеханова, важное место занимает преобразователь моносигнала в ПФС-сигнал. При синтезе реальной схемы без него не обойтись. На 143 стр. книги, на рис 4.30 изображена схема такого преобразователя. В фазе спейсер возбуждение инвертора может сняться без его переключения (при достаточно быстром изменении сигнала М). Схема не полумодулярна, не самосинхронна. В общем-то ничего особо страшного в этом нет. Но говорить о строгой самосинхронности метода уже нельзя. Проблемы синтеза преобразователя связаны с упорным нежеланием использовать событийный анализ. Если будет интерес, могу помочь.
Ответ Леонида Петровича:
Самое главное из виду упустили. В подходе, излагаемом в книге Плеханова, важное место занимает преобразователь моносигнала в ПФС-сигнал. При синтезе реальной схемы без него не обойтись. На 143 стр. книги, на рис 4.30 изображена схема такого преобразователя. В фазе спейсер возбуждение инвертора может сняться без его переключения (при достаточно быстром изменении сигнала М). Схема не полумодулярна, не самосинхронна. В общем-то ничего особо страшного в этом нет. Но говорить о строгой самосинхронности метода уже нельзя.
Да, это так.
Если сигнал M никак не связан ц преобразователем, то есть изменяется произвольно,
никакой преобразователь не будет строго самосинхронным.
Выхода два:
а) Сделать так, чтобы внешний сигнал M менялся по изменениям I1.
Тогда все будет самосинхронным.
б) Наложить условие, чтобы M менялся не быстрее преобразователя.
Тогда самосинхронности не будет, будет КВАЗИ, но для практики может быть полезно.
—
С уважением,
Леонид Плеханов
Самое главное из виду упустили. В подходе, излагаемом в книге Плеханова, важное место занимает преобразователь моносигнала в ПФС-сигнал. При синтезе реальной схемы без него не обойтись. На 143 стр. книги, на рис 4.30 изображена схема такого преобразователя. В фазе спейсер возбуждение инвертора может сняться без его переключения (при достаточно быстром изменении сигнала М). Схема не полумодулярна, не самосинхронна. В общем-то ничего особо страшного в этом нет. Но говорить о строгой самосинхронности метода уже нельзя.
Да, это так.
Если сигнал M никак не связан ц преобразователем, то есть изменяется произвольно,
никакой преобразователь не будет строго самосинхронным.
Выхода два:
а) Сделать так, чтобы внешний сигнал M менялся по изменениям I1.
Тогда все будет самосинхронным.
б) Наложить условие, чтобы M менялся не быстрее преобразователя.
Тогда самосинхронности не будет, будет КВАЗИ, но для практики может быть полезно.
—
С уважением,
Леонид Плеханов
Согласен. Проявил излишнюю подозрительность. Исходил из более жестких условий для входных сигналов. Для заявленного поведения схема отличная.
Строгая самосинхронность вещь настолько синтетическая, что существует только на бумаге да в головах разработчиков, а как только доходит до реализации, то остаются одни только квази решения. К сожалению, теория самосинхронных схем очень плохо ложится на КМОП технологию, особенно ниже 100нм, когда цифровая схема становится все в большей степени аналоговой. Было бы любопытно почитать по реализации на, скажем, электромеханических ключах или мемристорах. Но — не пишут :-)
Похоже на высказывания в упомянутой книге. Делаются схемы заведомо худшие более чем в 2 раза по быстродействию (по сравнению с однофазными), в n+1 раз худшие по энергопотреблению (n — количество кодированных сигналов). А потом говорится: схемы может не идеальные, но это плата за самосинхронность. А схема, о которой речь, действительно отличная, в выбранном базисе реализации лучше не сделать. Если же модель не соответствует реальности, наверно надо модель править. К примеру, тот же базис реализации.
Зарегистрируйтесь на Хабре , чтобы оставить комментарий
Ответ Л.П. Плеханова на замечания по книге «Основы самосинхронных электронных схем»