Эта история началась с короткой статьи в New York Times о Люке Робитейле, 13-летнем школьнике из Юлесса, штат Техас, который выиграл Raytheon Mathcounts National Competition, правильно ответив на следующий вопрос:
На следующий день Джордан Элленберг твитнул такую задачу:

«100 кур сидят в круге. Каждая клюёт случайным образом R или L. Клюнутые куры никого не клюют. Итерации проводятся до тех пор, пока не останется двух соседних неклюнутых кур. Сколько кур осталось?»
Мне не нужно умещать эту историю в 140 символов, поэтому я дополню вопрос Элленберга подробностями так, как я его понял. Исходная задача относилась к одной итерации синхронизированного случайного клевания, а теперь у нас есть несколько итераций. Во время одной итерации каждая курица случайным образом поворачивается влево или вправо и клюёт одну из своих соседок. Однако если курицу уже клюнули, она больше никогда не клюёт, даже её продолжают клевать. Если две соседние курицы клюют друг друга в одной итерации, обе они вылетают из игры на все последующие раунды. Если неклюнутая курица оказывается между двумя клюнутыми, её уже никогда не клюнут и поэтому она может клевать бесконечно. Вопрос заключается в том, какая часть кур выживет и станет «неуязвимыми»?
Ниже представлены спойлеры, так что сейчас вы можете попробовать ответить на вопрос сами. Пока вы этим занимаетесь, я немного поговорю о курах и о риторике и семиотике математических «текстовых задач».
Единственные мои знания о домашней птице взяты из поездки на ферму моей тёти Норетты в южном Нью-Джерси. Нельзя сказать, что мой опыт велик, но стоит заметить, что я никогда не видел куриц, сидящих вкруг, клюющих друг друга случайным образом. (У них есть порядок клевания!) Более того, я никогда не замечал в их социальных взаимодействиях чего-то, напоминавшего принцип «подставь другую щёку», который демонстрируют куры из описанной задачи. Почему клюнутая курица больше никогда не клюёт? Это ещё большая загадка, чем количественный вопрос, на который нам предстоит ответить. Открылась ли курице внезапно мудрость и сила непротивления насилию? У меня есть другое объяснение, но оно не подходит для чувствительных людей: возможно, клюнутые курицы не клюют в ответ, потому что клевки убивают наповал.
Я знаю, что глупо требовать от подобной истории реализма повествования. Математические текстовые задачи относятся к жанру, в котором никто не ожидает правдоподобия. Они происходят в мире, где лжецы всегда лгут, а рыцари всегда говорят правду, где потерпевшие кораблекрушение моряки одержимы возможностью делимости горы кокосов, где люди не знают цвет шляпы, которая на них надета. Даже законы физики склоняются перед математическими потребностями: муха, летающая между двумя сближающимися поездами, мгновенно меняет своё направление. Эти сидящие в кругу куры — не пушистые комки жёлтого пуха; они — математические абстракции. У них нет перьев, зато есть координаты и переменные состояния.
Меня вполне устраивают абстракции; давайте любыми средствами избавляться от избыточных подробностей. Тем не менее, разве смысл текстовых задач не в том, чтобы связать математику с какими-то аспектами знакомого читателям опыта? Вспомните древнюю знаменитую задачу о пересечении реки, в которой волка нельзя оставлять с козой, которую в свою очередь нельзя оставлять с капустой (прим. пер.: в оригинале лиса, курица и мешок кукурузы). Эти ограничения легко понять, если ты что-то знаешь о вкусовых предпочтениях волков и кур. Однако такая интуитивная помощь не применима к задаче с клеванием. Напротив, чем больше мы знаем об истинном поведении пернатых, тем более сбивающей с толку будет эта задача.
Ну да ладно. Приступим! Есть ли у вас уже собственный ответ?
Задача с одной итерацией из соревнований Mathcounts Competition сводится к старейшему трюку в учебнике по теории вероятностей. Курица остаётся неклюнутой, только если обе её соседки отвернулись и клюнули в другом направлении. Вероятность избежания клевка слева и справа равна . Два этих события независимы, поэтому вероятность остаться неклюнутой с обеих сторон равна
. Два этих события независимы, поэтому вероятность остаться неклюнутой с обеих сторон равна  . Эти рассуждения одинаково применимы ко всем птицам в кругу, поэтому нужно ожидать, что невредимыми останутся 25 процентов кур.
. Эти рассуждения одинаково применимы ко всем птицам в кругу, поэтому нужно ожидать, что невредимыми останутся 25 процентов кур.
Согласны ли вы с этим анализом? Когда читал статью в Times, я дошёл до него довольно быстро (конечно, совсем не так быстро, чтобы опередить нажавшего на кнопку Люка Робитейла). Но потом у меня зародились сомнения. Строго ли верно то, что соседки курицы слева и справа совершенно независимы? В конце концов, они связаны цепочкой других кур. Возможно, по кругу может распространиться какое-то влияние, создающее корреляции между левой и правой курицей и меняющее вероятность выживания.
Настало время экспериментов: напишем программу и запустим симуляцию. Выстроим кольцо из 100 неклёванных кур и выполним одну итерацию случайного одновременного клевания. Повторим много раз и вычислим среднее количество оставшихся неклюнутыми птиц. (Вот краткая запись: пусть — число кур в кольце, а
— число кур в кольце, а  — количество оставшихся неклюнутыми. Я обозначу как
— количество оставшихся неклюнутыми. Я обозначу как  среднее значение , усреднённое после
среднее значение , усреднённое после  повторений эксперимента.) Мои результаты:
повторений эксперимента.) Мои результаты:
Как и ожидалось, среднее значение довольно близко к 25 выжившим. Более того, при каждом увеличении размера выборки в 100 раз точность аппроксимации увеличивается примерно в десять раз. Этот паттерн соответствует эмпирическому правилу статистики: флуктуации случайного процесса пропорциональны квадратному корню размера выборки. То есть незначительные отклонения от похожи на невинный случайный шум, а не какое-то систематическое смещение.
похожи на невинный случайный шум, а не какое-то систематическое смещение.
То есть вопрос решён, не так ли?
Вообще, симуляция выглядит довольно убедительной для конкретного случая кур, но результат может отличаться для других значений N. В частности, возможно, существует некий эффект конечной размерности, становящийся очевидным только при малых N. Рассмотрим «круг» из всего двух кур. В этой симуляции левый и правый сосед — это одна и та же курица! Вне зависимости от случайно сделанных выборов две курицы сразу же клюнут друг друга, и часть выживших будет равна не 25 процентам, а нулю.
кур, но результат может отличаться для других значений N. В частности, возможно, существует некий эффект конечной размерности, становящийся очевидным только при малых N. Рассмотрим «круг» из всего двух кур. В этой симуляции левый и правый сосед — это одна и та же курица! Вне зависимости от случайно сделанных выборов две курицы сразу же клюнут друг друга, и часть выживших будет равна не 25 процентам, а нулю.
Следующий, более крупный «круг» состоит из трёх кур, собранных в треугольник. Два соседа теперь — это разные куры, но они также являются соседями друг друга. Что случится, когда три курицы набросятся друг на друга? В системе есть возможных комбинаций клевания, и мы легко можем изучить из все. Стрелками на схеме показано то, в какую сторону курицы выбрали клевать.
возможных комбинаций клевания, и мы легко можем изучить из все. Стрелками на схеме показано то, в какую сторону курицы выбрали клевать.

В двух случаях все курицы клюют влево или клюют вправо, и выживших нет. В каждом другом случае неклюнутой остаётся ровно одна курица. Собрав все восемь комбинаций, мы получаем шесть неклюнутых кур из 24, то есть соотношение равно . То есть, похоже, аномалия конечных значений затрагивает только случай задачи с двумя курами.
. То есть, похоже, аномалия конечных значений затрагивает только случай задачи с двумя курами.
Но постойте! Существует ещё один возможный искажающий результаты фактор. Можем ли мы быть уверены, что одинаковые результаты будут и для чётных, и для нечётных количеств кур? При любом нечётном значении N существует только один способ уничтожить всех кур за один раунд: все они должны клевать в одном направлении. Однако при чётном N к немедленному вымиранию приводит ещё одна комбинация: соседние куры разбиваются на пары и клюют друг друга. Не изменит ли этот дополнительный способ общую вероятности выживания?
Давайте посмотрим, что происходит при N = 4. Теперь существует возможных результатов:
возможных результатов:

Как и ожидалось, в четырёх комбинациях вообще нет выживших. С другой стороны, также есть четыре комбинации, в которых остаётся не одна, а две неклюнутые курицы. Дополнительные потери и дополнительные выигрыши чудесным образом уравновешивают друг друга. Всего у нас будет 16 выживших из 64 кур, то есть соотношение снова равно.
После этого долгого и извилистого обхода комбинаторики клевания кур мы вернулись ровно к тому, с чего начинали. Вероятность остаться неклюнутой после одной итерации клевания равна для любого
для любого  . Все мои волнения об эффектах конечных размеров и неравномерностей чёт-нечет были пустой тратой времени. Так зачем же я поделился ими с вами? Хотя мои волнения оказались ничем не обоснованными, они вовсе не надуманны. Даже небольшие изменения в порядке клевания приведут к другим результатам. Допустим, клевание будет последовательным, а не одновременным. Одна выбранная курица начинает последовательность клевков, а затем свои ходы делают другие птицы, расположенные по часовой стрелке от неё. Когда приходит очередь курицы, то если её уже клюнули, то она ничего не делает. Если её не клюнули, она клюёт влево или вправо, выбирая случайным образом. Итерация заканчивается, когда каждая курица сделает свой ход.
. Все мои волнения об эффектах конечных размеров и неравномерностей чёт-нечет были пустой тратой времени. Так зачем же я поделился ими с вами? Хотя мои волнения оказались ничем не обоснованными, они вовсе не надуманны. Даже небольшие изменения в порядке клевания приведут к другим результатам. Допустим, клевание будет последовательным, а не одновременным. Одна выбранная курица начинает последовательность клевков, а затем свои ходы делают другие птицы, расположенные по часовой стрелке от неё. Когда приходит очередь курицы, то если её уже клюнули, то она ничего не делает. Если её не клюнули, она клюёт влево или вправо, выбирая случайным образом. Итерация заканчивается, когда каждая курица сделает свой ход.
При легко увидеть, что первая клюющая курица всегда выживает, а другая всегда умирает, то есть доля выживших равна . Немного посчитав куриц на бумаге, можно выяснить, что доля выживших в 50 процентов также справедлива и для
легко увидеть, что первая клюющая курица всегда выживает, а другая всегда умирает, то есть доля выживших равна . Немного посчитав куриц на бумаге, можно выяснить, что доля выживших в 50 процентов также справедлива и для  . При исследовании бОльших значений компьютерные эксперименты показывают, что доля выживших при стремлении к бесконечности снова приближается к . Однако между этими предельными значениями существуют забавные ситуации:
. При исследовании бОльших значений компьютерные эксперименты показывают, что доля выживших при стремлении к бесконечности снова приближается к . Однако между этими предельными значениями существуют забавные ситуации:

При доля выживших опускается ниже 0,47. (Точная вероятность равна
доля выживших опускается ниже 0,47. (Точная вероятность равна  .) Это минимум значений. Но при возвращении соотношения к 0,5 в кривой появляются колебания, показывающие расхождения результатов при чётном и нечётном количествах: вероятность выживания снижается больше для чётных N, чем для нечётных N. Именно такое поведение я искал (но не нашёл) в исходной версии задачи с соревнований Mathcounts.
.) Это минимум значений. Но при возвращении соотношения к 0,5 в кривой появляются колебания, показывающие расхождения результатов при чётном и нечётном количествах: вероятность выживания снижается больше для чётных N, чем для нечётных N. Именно такое поведение я искал (но не нашёл) в исходной версии задачи с соревнований Mathcounts.
Давайте снова возьмёмся за задачу Элленберга про итерируемое клевание (с одновременным, а не последовательным клеванием). Мы уже знаем, что после первой итерации можно ожидать, что неклюнутыми останется примерно четверть кур. Очевидно, что часть неклюнутых не может увеличиваться после нескольких итераций. То есть в конечном состоянии ожидаемая доля выживших должна находиться где-то между нулём и .
Полезно будет посмотреть на обычную конфигурацию клюнутых (●) и неклюнутых (○) кур после одной итерации синхронизированного клевания:
(Мысленно соедините левый и правый концы массива, чтобы создать кольцо.) Заметьте, что здесь присутствуют длинные строки клюнутых кур, но неклюнутые куры присутствуют только в двух конфигурациях. Они являются или одиночками (●○●), или парами (●○○●). Причину такого паттерна понять просто. После раунда клевания существование группы из трёх неклюнутых кур подряд (●○○○●) невозможна. Средняя курица обязана клюнуть влево или вправо, то есть у неё не может быть двух неклюнутых соседей.
Такие ограничения упрощают анализ последующих итераций. Одиночки в сущности бессмертны и неизменяемы: неклюнутую курицу посередине никогда больше не клюнут, а клюнутых соседей никогда больше не вернуть в «неклюнутое» состояние. Для пар существует четыре возможных варианта развития событий, соответствующих четырём способам, которыми две активные курицы выберут клевать:
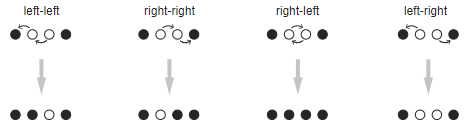
В любой итерации все эти четыре события имеют одинаковую вероятность, а именно. Первые три получившихся состояния являются заключительными, в том смысле, что дальнейшие итерации клевания не изменят их. В четвёртом случае у нас снова остаётся пара соседей, перед которой в следующей итерации предстанет тот же выбор вариантов. Со временем, когда количество итераций будет стремиться к бесконечности, четвёртый случай должен привести к одному из других результатов, а потому в длительной перспективе мы должны считать вероятность четвёртого случая равной нулю, а вероятность каждого из других трёх случаев равной  .
.
Теперь настало время соединить эти зависящие от обстоятельств события вместе и вычислить вероятность выживания курицы в длительной перспективе. На рисунке ниже показана схема. В первом раунде клевания три четверти кур сразу же уничтожаются. Из оставшейся четверти половина является одиночками, которые выживают бесконечно. Каждая другая выжившая курица является членом пары, а другая клюющая курица из её пары — это её левая или правая соседка.

В нижней части схемы подводится итог влияния всех последовательных итераций, которые продолжаются, пока все пары не уничтожатся или не уменьшаться до одиночек. (Я называю это клеванием до последнего.) Для каждого пути, ведущего к выживанию одиночки, вероятность является произведением отдельных вероятностей, встреченных на этом пути. Существует три таких пути с вероятностями ,
,  и и суммой
и и суммой  .
.
Должен признаться, что мне не удалось выполнить этот анализ — или получить верный ответ — с первой попытки. Я добился его только после выполнения симуляции, узнав таким образом, что мне нужно искать. И даже тогда у меня возникали проблемы с двойным подсчётом.
Вот как выглядят результаты симуляции:
Заметьте, что точность снова улучшается как квадратный корень от размера выборки, несмотря на то, что дисперсия здесь больше, чем в эксперименте с одной итерацией.
А как насчёт эффектов конечного размера? В кругу со всего двумя или тремя курами их судьба полностью определяется единственной итерацией клевания: соответственно равно 0 и . То есть эти наименьшие круги не соответствуют правилу , но похоже, что круги любого бОльшего размера сводятся к . Расхождений чёт-нечет в них не замечено.
Ещё одним подходом к пониманию задачи итерированного клевания кур является теория цепей Маркова. Для кольца из кур мы перечисляем все  состояний и назначаем вероятность каждому переходу между состояниями. Рассмотрим кольцо из четырёх кур, которое имеет 16 состояний. Симметрия позволяет нам объединить некоторые из состояний; другие состояния можно отбросить, потому что они недостижимы из начального состояния с четырьмя неклюнутыми курами (
состояний и назначаем вероятность каждому переходу между состояниями. Рассмотрим кольцо из четырёх кур, которое имеет 16 состояний. Симметрия позволяет нам объединить некоторые из состояний; другие состояния можно отбросить, потому что они недостижимы из начального состояния с четырьмя неклюнутыми курами ( ).
).
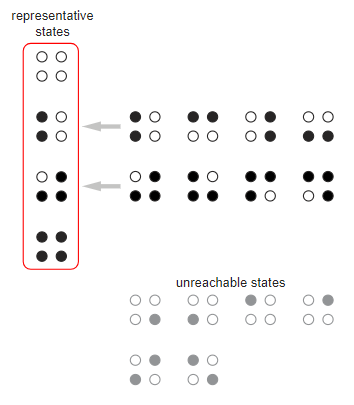
В модели должны сохраниться только четыре состояния выделенные красным контуром. Переходы между ними записываются в направленный граф, в котором каждая стрелка помечается соответствующей вероятностью. Стоит заметить, что у начального состояния есть только исходящие стрелки; после выхода из него туда невозможно вернуться. Состояния  и
и  являются поглощающими: единственная исходящая стрелка ведёт обратно в то же состояние; то есть однажды попав в одно из этих состояний, вы уже из него не выберетесь.
являются поглощающими: единственная исходящая стрелка ведёт обратно в то же состояние; то есть однажды попав в одно из этих состояний, вы уже из него не выберетесь.

Важную информацию из этого направленного графа можно отобразить в матрице , в которой строки и столбцы помечены четырьмя состояниями, а элементы матрицы представляют собой вероятность перехода из состояния строки в состояние столбца. Сумма элементов каждой строки равна 1, как и должно быть, если они представляют собой вероятности.
, в которой строки и столбцы помечены четырьмя состояниями, а элементы матрицы представляют собой вероятность перехода из состояния строки в состояние столбца. Сумма элементов каждой строки равна 1, как и должно быть, если они представляют собой вероятности.

Паттерн нулевых элементов в матрице переходов подразумевает, что в некоторые состояния нельзя попасть из других состояний, даже непрямым путём. По этой причине говорят, что марковская модель является иррегулярной. Это немного неприятно, потому что регулярные марковские модели проще в анализе и понимании. В регулярной модели, когда мы берём последовательные степени матрицы перехода, она сводится к установившемуся состоянию, в котором все строки одинаковы, а каждый столбец состоит из единственного повторяющегося значения. Такое фиксированное состояние отображает распределение вероятностей в долгосрочной перспективе. Иррегулярная марковская модель может даже не иметь установившегося ограничивающего распределения, но в нашей оно есть, и это даёт нам определённые подсказки. Любое кольцо из четырёх кур должно в результате прийти к одному из двух поглощающих состояний. С вероятностью «две третьих» это заключительное состояние будет и с вероятностью «одна третья» . Этот результат соответствует вычисленной одной шестой доле неклёванных кур.

То есть можно подводить итог, правда? И в задаче с соревнований, и в её итеративной версии Элленберга спрашивалось ожидаемое количество выживших кур, и мы дали ответ: при кур ожидаемое количество выживших равно  после единственной итерации клевания и
после единственной итерации клевания и  при клевании до конца. Однако иронично, что ожидаемое значение вероятностного процесса не обязательно сообщает нам, чего стоит ожидать. Рассмотрим простую задачу: подбросив монетку 100 раз, сколько «орлов» мы ожидаем увидеть? Очевидный ответ — 50, и он верен в том смысле, что никакое другое число не имеет большей возможности верно предсказать результат эксперимента. Однако вероятность увидеть ровно 50 «орлов» равна всего 0,08, то есть в 90 процентах случаев мы будем получать другое число.
при клевании до конца. Однако иронично, что ожидаемое значение вероятностного процесса не обязательно сообщает нам, чего стоит ожидать. Рассмотрим простую задачу: подбросив монетку 100 раз, сколько «орлов» мы ожидаем увидеть? Очевидный ответ — 50, и он верен в том смысле, что никакое другое число не имеет большей возможности верно предсказать результат эксперимента. Однако вероятность увидеть ровно 50 «орлов» равна всего 0,08, то есть в 90 процентах случаев мы будем получать другое число.
Вместо того, чтобы смотреть только на ожидаемое значение, давайте изучим интервал возможных значений игры с клеванием. Мы уже установили, что ноль выживших является возможным результатом, то есть нижняя граница у нас есть. А что насчёт верхней границы — максимального количества выживших? В процессе с одной итерацией клевок делает каждая курица, то есть после этой итерации у каждой курицы должен быть хотя бы один клюнутый сосед. На основании этого факта я заявляю, что выжившая популяция никогда не может быть больше  . (Вы согласны? Мне понадобилось какое-то время, чтобы убедить себя в этом.)
. (Вы согласны? Мне понадобилось какое-то время, чтобы убедить себя в этом.)
Если никогда не может быть больше , то следующим вопросом будет такой: сможет ли оно вообще когда-нибудь достичь этого предела? И если у нас может быть одинаковое количество клюнутых (●) и неклюнутых (○) кур, то как они будут расположены в кольце? Кажется логичным предложить следующую конфигурацию:
Это стабильное состояние: неклюнутых кур никогда не смогут клюнут, то есть дальнейшие изменения невозможны. А доля выживших равна. Но у этой схемы есть проблема: её невозможно достичь из начального состояния. Посмотрите на любую из клюнутых кур и задайте вопрос: какая из соседок её клюнула? Очевидно, что ни одна из них, потому что их обеих никто не клюнул. Но это невозможно, потому что каждая курица в первой итерации должна клюнуть.
Хотя схему из попеременных чёрных и белых кур мы исключили, мы находимся на верном пути. Существует ещё одна конфигурация, при которой после первой итерации тоже остаётся половина кур, и эта схема достижима из начального состояния:
Когда мы соединяем концы, чтобы получить кольцо, у каждой курицы, вне зависимости от того, клюнули её или нет, есть одна клюнутая соседка. Оказывается, что это единственный способ, если не считать очевидных симметричных случаев, чтобы достичь выживания 50 процентов. (Строго говоря, 50 процентов можно достичь только когда делится на 4, но никогда не меньше  .)
.)
Когда клевание выполняется до победного конца, верхняя граница больше недостижима. Допустим, что мы бы пытались сохранить через несколько итераций клевания. Очевидно, что нам пришлось бы начинать в первой итерации с максимальной доли выживших выживших.
больше недостижима. Допустим, что мы бы пытались сохранить через несколько итераций клевания. Очевидно, что нам пришлось бы начинать в первой итерации с максимальной доли выживших выживших.
Значит ли это, что является максимально возможным значением после клевания до победного конца? Нет, не значит. Существует ещё одна схема, в которой выживает одна из каждых трёх кур:
является максимально возможным значением после клевания до победного конца? Нет, не значит. Существует ещё одна схема, в которой выживает одна из каждых трёх кур:
Эта конфигурация достижима за одну итерацию и бесконечно устойчива, потому что ни у одной из клюющих кур нет клюющих соседок. Ни одна другая схема не имеет большей плотности выживших при выполнении процесса клевания до конца.
Подведём итог: после одной итерации клевания количество выживших кур должно находиться где-то между нулём и, а ожидаемое количество — ровно посередине, в . После завершения всех последующих итераций количество неклюнутых кур будет находиться в интервале между нулём и  , а ожидаемое значение снова будет посередине, в
, а ожидаемое значение снова будет посередине, в  .
.
«Сколько кур выживет?» — этот вопрос, кажется, требует численного ответа, но на самом деле наиболее информативным ответом на него будет совсем не число, а распределение:
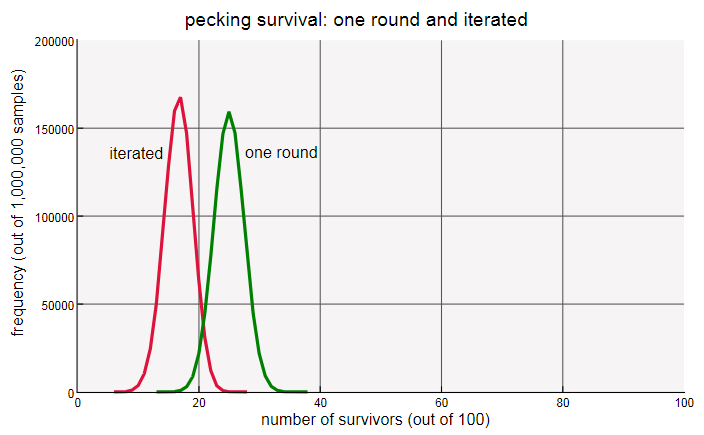
Каждая кривая фиксирует результаты миллиона экспериментов с кольцом из 100 кур, показывая частоту каждого возможного значения. Как и ожидалось, распределение при одной итерации имеет пик на 25 выживших, а кривая задачи с итерацией — на 17 (ближайшее к  целое). Заметьте, что красная кривая не только смещена влево, но также выше и уже.
целое). Заметьте, что красная кривая не только смещена влево, но также выше и уже.
Чтобы лучше рассмотреть результаты, давайте изменим масштаб. Чтобы кривые были более плавными, я перейду к экспериментам с кур. Зелёная кривая — для одной итерации, а красная — для эксперимента со множеством итераций клевания:
кур. Зелёная кривая — для одной итерации, а красная — для эксперимента со множеством итераций клевания:

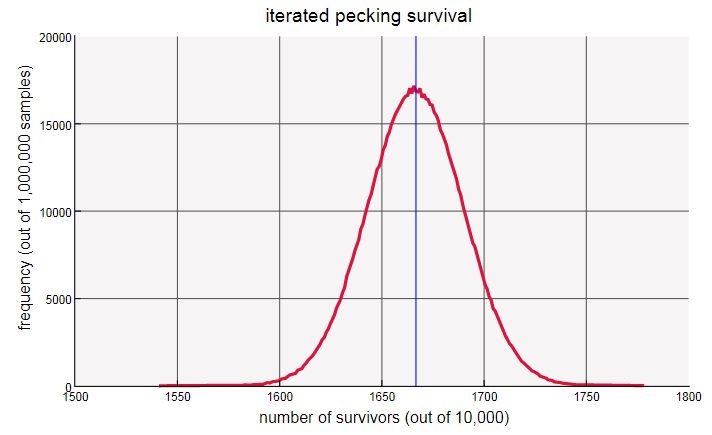
При бОльших значениях пики кривых находятся в 2500 и в 1666,67, то есть ровно в точках, ожидаемых для и . Было неудивительно найти пики в этих точках, но что же управляет шириной и общей формой кривой? Другими словами, каковая математическая природа распределений?
Первая догадка — всегда стоит попробовать нормальное (или гауссово) распределение. Для задачи клевания нормальное распределение определяет , вероятность наблюдения выживших, следующим образом:
, вероятность наблюдения выживших, следующим образом:
Довольно запутанное уравнение для такого знакомого понятия, но из него можно выделить основной смысл. Уравнение определяет симметрическую кривую с пиком, где равно  , то есть среднему значению распределения. Ширина пика зависит от стандартного отклонения
, то есть среднему значению распределения. Ширина пика зависит от стандартного отклонения  . Поскольку площадь под кривой постоянна, в сущности определяет её высоту: более узкий пик должен быть выше.
. Поскольку площадь под кривой постоянна, в сущности определяет её высоту: более узкий пик должен быть выше.
Мы можем согласовать нормальное распределение с данными о клевании с помощью процедуры, находящей оптимальные значения и , такие, которые минимизируют расхождение между точками данных и математической моделью. В двух представленных ниже графиках согласованные модели наложены на два графика данных, первая для одной итерации, вторая — для итераций до конца:


Согласование выглядит достаточно близким, теоретические кривые разделяют экспериментальные от начала до конца. В каком-то смысле, этот результат можно считать успехом, но я всё-таки не нахожу такой подход к задаче полностью удовлетворительным. Нормальная кривая создаёт очень хорошую описательную модель процесса клевания, но не прогнозирует и не объясняет её. Не забывайте, что мы согласовали кривую с данными, а не наоборот. Я не вижу очевидных способов создать некое нормальное распределение из того, что я знаю о взаимодействиях клюющихся кур. В частности, откуда берутся значения двух моделей? Почему  в модели с одной итерацией, но
в модели с одной итерацией, но  в модели с множеством итераций? Эти значения выглядят как независимые параметры, которые нам приходится подгонять для соответствия данным. Более того, они будут разными для каждого значения . Ещё одна проблема: нормальная кривая — это непрерывное распределение, определённое на всей вещественной числовой оси. Функция клевания дискретна, она имеет смысл только для целых величин.
в модели с множеством итераций? Эти значения выглядят как независимые параметры, которые нам приходится подгонять для соответствия данным. Более того, они будут разными для каждого значения . Ещё одна проблема: нормальная кривая — это непрерывное распределение, определённое на всей вещественной числовой оси. Функция клевания дискретна, она имеет смысл только для целых величин.
Давайте отложим в сторону нормальную кривую и рассмотрим ещё одну правдоподобную модель: биномиальное распределение, которое дискретно и возникает во многих контекстах, связанных с вероятностями. Предположим, что мы бросим 10 000 костей и посчитаем, на скольких из них выпала единица. Когда мы повторим эксперимент множество раз, ожидаемое количество единицы будет равно одной шестой от 10 000, то есть то же значение, что и ожидаемое количество выживших в итерируемом эксперименте с клюющимися курами. Для костей существует хорошо известное математическое выражение, определяющее не только ожидаемое значение, но и форму всего распределения. Предположим, что каждая кость имеет вероятность выбрасывания , обозначенную
, обозначенную  . Мы будем бросать костей и нам нужно знать вероятность увидеть
. Мы будем бросать костей и нам нужно знать вероятность увидеть  единицы= для любого от
единицы= для любого от  до . Формула для обработки этой информации имеет вид:
до . Формула для обработки этой информации имеет вид:
Здесь даёт вероятность любой отдельной комбинации единиц среди костей. Биномиальный коэффициент
даёт вероятность любой отдельной комбинации единиц среди костей. Биномиальный коэффициент  , равный
, равный  \), подсчитывает количество таких комбинаций.
\), подсчитывает количество таких комбинаций.
При и  мы получаем кривую, показывающую результат вышеупомянутого эксперимента с бросанием костей. Возможно, та же кривая описывает и то, что происходит в модели клевания со множеством итераций, которая имеет то же ожидаемое значение? Увы, но нет.
мы получаем кривую, показывающую результат вышеупомянутого эксперимента с бросанием костей. Возможно, та же кривая описывает и то, что происходит в модели клевания со множеством итераций, которая имеет то же ожидаемое значение? Увы, но нет.
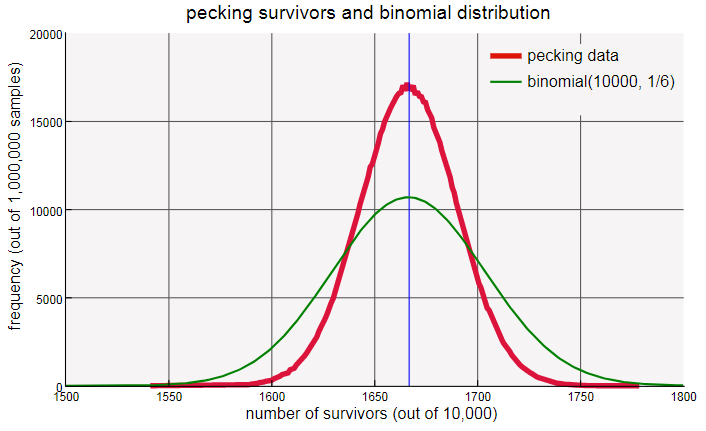
Биномиальная кривая шире и более плоская, чем распределение выживших при итерированном клевании. Что же пошло не так? Когда я впервые увидел график, у меня появилось предчувствие. Как сказано выше, биномиальный коэффициент подсчитывает все способы выбора элементов из множества размером . Он подходит для эксперимента с костями, потому что все возможные комбинации успехов среди равновероятны. В частности, когда мы бросаем  костей, мы можем вообще не увидеть единиц или увидеть все костей с единицами на верхней грани; весь интервал результатов имеет вероятность больше нуля.
костей, мы можем вообще не увидеть единиц или увидеть все костей с единицами на верхней грани; весь интервал результатов имеет вероятность больше нуля.
Задача с клеванием отличается, 100 процентов кур не может остаться неклюнутыми. То есть достижимо только подмножество комбинаций. Если биномиальное распределение и будет работать в таком контексте, нам нужно каким-то образом изменить его, чтобы включить только достижимые результаты.
С мыслью о том, что легче решить задачу, если уже знаешь ответ, я попытался поиграться с параметрами распределения, чтобы посмотреть, как будет реагировать график. Я стремился уместить кривую в более узкий и высокий график, сохранив центрирование по тому же среднему значению. Среднее равно , то есть если мы уменьшим , то нам придётся увеличивать на тот же коэффициент. Вот результаты некоторых экспериментов:
, то есть если мы уменьшим , то нам придётся увеличивать на тот же коэффициент. Вот результаты некоторых экспериментов:

Тёмно-зелёная кривая — это та, которую мы уже видели, для биномиального распределения при и . Изменение параметров на  и
и  кажется шагом в верном направлении, а
кажется шагом в верном направлении, а  и
и  оказываются ещё лучше. Тогда попробуем
оказываются ещё лучше. Тогда попробуем  и
и  Бинго! Жёлтая кривая идеально соответствует данным клевания. То есть, похоже, мы можем прогнозировать выживание в кольце клевания из членов, создав биномиальное распределение с параметрами
Бинго! Жёлтая кривая идеально соответствует данным клевания. То есть, похоже, мы можем прогнозировать выживание в кольце клевания из членов, создав биномиальное распределение с параметрами  и
и  .
.
Я могу повторить тот же трюк, чтобы найти биномиальное распределение, соответствующее одной итерации клевания. На этот раз волшебные числа, сгибающие кривую по нужной траектории, равны и
и  .
.

В отличие от нормального распределения, биномиальная модель конструктивна (то есть способна прогнозировать). Из двух параметров и
и  мы можем вычислить и среднее значение распределения, и стандартное отклонение. Среднее значение — это просто
мы можем вычислить и среднее значение распределения, и стандартное отклонение. Среднее значение — это просто  , стандартное отклонение — это
, стандартное отклонение — это  . Например, при кур среднее оказывается равным
. Например, при кур среднее оказывается равным (как и ожидается), а стандартное отклонение равно
(как и ожидается), а стандартное отклонение равно  . (У подогнанного нормального распределения
. (У подогнанного нормального распределения  .) Для случая с одной итерацией равно
.) Для случая с одной итерацией равно  , а равно
, а равно  . (Чтобы избежать ошибок округления, я взял , равное
. (Чтобы избежать ошибок округления, я взял , равное  , а не .)
, а не .)
Ну что, ура? По крайней мере, у нас есть формула для вычисления формы и расположения распределения клевания кур, зависящая всего от пары параметров- и . Но я снова ворчу, на самом деле я ещё более рассержен. Может быть, модель и объясняет данные, но как объяснить саму модель? При кур и вероятности выживания в первой итерации , зачем формуле нужны  и
и  ? Откуда берутся эти числа? И почему в случае со множественными итерациями подходят
? Откуда берутся эти числа? И почему в случае со множественными итерациями подходят  и
и  ?
?
Мне неудобно говорить, сколько времени я потратил на безнадёжные бултыхания в болотах теории вероятностей, пытаясь решить эти загадки. (Я даже обратился к недавно изданной книге The Probability Lifesaver («Спасатель в мире вероятностей»), которую я крайне рекомендую, но она меня не спасла.) В поисках ответов я исследовал полиномиальные обобщения биномов. Я изучал свёртки распределений и вычислял условные вероятности. Я заполнял целые блокноты ровными строками из ● и ○ в поисках паттернов, которые бы могли объяснить такие загадочные дроби в паре с  и в паре с
и в паре с  . Каждую ночь я ложился спать с многообещающей идеей, но потом просыпался и находил в ней существенный недостаток.
. Каждую ночь я ложился спать с многообещающей идеей, но потом просыпался и находил в ней существенный недостаток.
Теперь мне кажется, что у меня есть правильное объяснение. Оно пришло ко мне после множества проверок в течение нескольких вечеров. Я расскажу о нём, но только в самом конце статьи. Возможно, вам удастся найти его раньше. Тем временем, я хочу расширить горизонты задачи про кур.
Наш уютный кружок кур — это одномерная структура. В кольце можно пойти по часовой стрелке и против неё, других значимых направлений в этой маленькой вселенной нет. Теперь представьте, что вместо того, чтобы сажать всех кур в круг, мы поместим их в сетку, то есть в массив и строк и столбцов, заполнив область двухмерного пространства. Чтобы не оставлять последних кур по краям квадратного массива, мы можем соединить левый край с правым, а верхний с нижним. (С точки зрения топологии это превращает прямоугольник в тор.) Заставить реальных кур в этом эксперименте работать совместно оказалось бы ещё сложнее, чем в одномерной версии, но нас это не волнует; мы давно уже попрощались с нашей амбарной реальностью.
Самое важное в этом двухмерном расположении — это то, что у каждой курицы теперь не две, а четыре соседки. Враждебных соседей стало больше, так что можно было бы ожидать, что курица будет более уязвима к атакам. С другой стороны, каждая из этих соседок распределяет свои клевки на потенциальных жертв, количество которых увеличилось в два раза. Как же уравновешиваются эти условия соревнований?
При единственной итерации клевания мы можем вычислить вероятность выживания так же, как в одномерной системе. Курица остаётся неклюнутой, только если все её соседки клюют в какую-то другую сторону. Каждая соседка клюёт так с вероятностью, поэтому вероятность того, что все они отвернутся, равна  . Численно это оказывается равным примерно 0,3164, (в круге значение было равно 0,25). То есть доля выживающих в двух измерениях больше, чем в одном; отвлечение на бОльшее количество жертв перевешивает опасность бОльшего количества нападающих. Распределение, наблюдаемое в компьютерных экспериментах, подтверждает этот результат.
. Численно это оказывается равным примерно 0,3164, (в круге значение было равно 0,25). То есть доля выживающих в двух измерениях больше, чем в одном; отвлечение на бОльшее количество жертв перевешивает опасность бОльшего количества нападающих. Распределение, наблюдаемое в компьютерных экспериментах, подтверждает этот результат.

Здесь показано, как сетка из кур выглядит после одной итерации клевания.
выглядит после одной итерации клевания.

В двухмерном массиве находится 1600 кур. Если посчитаем неклюнутых, то обнаружим, что их 501, то есть доля выживших равна 0,3131, и это близко к теоретическому значению 0,3164. Симуляции подтверждают, что ожидаемая доля выживших равна для сеток  при любом значении больше
при любом значении больше  . (Для сетки
. (Для сетки  доля выживших равна , как и в одномерной системе. И на то есть причина!)
доля выживших равна , как и в одномерной системе. И на то есть причина!)
Когда я пристально смотрел на представленную выше схему, то заметил определённую повторяющуюся текстуру с цепочками ○, разделяющих пятна ●. Это может быть иллюзией, но я так не думаю. В двух измерениях ограничение «никаких трёх подряд» снимается; в массиве содержатся строки и столбцы, в которых есть до шести последовательных неклюнутых кур, а также диагональные линии. Но сплошного блока из неклюнутых кур (
из неклюнутых кур ( ) мы здесь не увидим, и даже перекрестья (
) мы здесь не увидим, и даже перекрестья ( ). Такие паттерны не могут существовать, потому что курица в середине блока должна клюнуть одну из своих четырёх соседок. В более общем смысле система по-прежнему ограничена правилом: каждая курица, клюнутая или неклюнутая, должна иметь хотя бы одну клюнутую соседку.
). Такие паттерны не могут существовать, потому что курица в середине блока должна клюнуть одну из своих четырёх соседок. В более общем смысле система по-прежнему ограничена правилом: каждая курица, клюнутая или неклюнутая, должна иметь хотя бы одну клюнутую соседку.
Так как при первой итерации клевания в двухмерном мире выживает больше кур, то кажется правдоподобным, что при продолжении итераций до завершения может выжить большая доля кур. Давайте попробуем провести эксперимент:

В этом массиве оказалось 238 выживших из 1600 кур, что меньше, чем доля выживших в одном измерении (одна шестая). При выборке в один миллион таких сеток я обнаружил, что средняя доля выживших примерно равна 0,1533. Сравните распределения в одно- и двухмерной системах:

При переходе из 1D в 2D пик сдвигается влево, а среднее перемещается от 0,1667 к 0,1533. Двухмерный холм также немного выше и уже, то есть он демонстрирует меньшую дисперсию.
Но зачем останавливаться на двух измерениях? Давайте попросим наших кур собраться в трёхмерную решётку, а противоположные границы снова соединим, создав трёхмерный аналог тороидальной поверхности. Несложно догадаться, к чему приведёт такой эксперимент. В одном измерении у каждой курицы было только две соседки, а доля выживших после одной итерации клевания была . В двух измерениях с четырьмя соседками соответствующее значение было равно
. В двух измерениях с четырьмя соседками соответствующее значение было равно  . В трёхмерном массиве у каждой курицы есть шесть соседок, то есть очевидно экстраполировать как
. В трёхмерном массиве у каждой курицы есть шесть соседок, то есть очевидно экстраполировать как  , получив значение
, получив значение  . После выполнения симуляции эти данные подтверждаются и демонстрируют чёткую тенденцию при создании массивов кур с увеличивающимся количеством измерений.
. После выполнения симуляции эти данные подтверждаются и демонстрируют чёткую тенденцию при создании массивов кур с увеличивающимся количеством измерений.
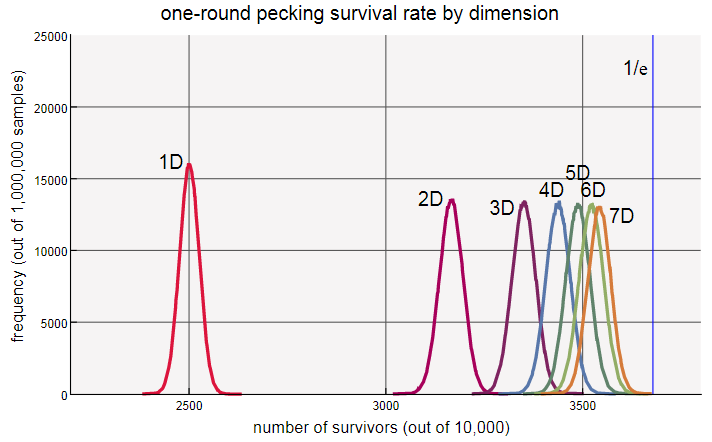
Исходя из этой серии результатов, мы можем смело обобщить: когда у курицы есть соседок, ожидаемая доля выживших после первой итерации клевания равна
соседок, ожидаемая доля выживших после первой итерации клевания равна
При увеличении это выражение сходится к значению, примерно равному  . Знакомо ли нам это число? Это же
. Знакомо ли нам это число? Это же  . (Поменяв минус на плюс, мы получим само
. (Поменяв минус на плюс, мы получим само  ,
,  .) Когда я пришёл к этой формуле, внезапное появление застало меня врасплох, хотя и не должно было. Константа появляется таким же способом, как в модели распространения слухов, о которой я писал несколько лет назад.
.) Когда я пришёл к этой формуле, внезапное появление застало меня врасплох, хотя и не должно было. Константа появляется таким же способом, как в модели распространения слухов, о которой я писал несколько лет назад.
А как насчёт итерируемого процесса клевания при больших количествах измерений? При увеличении измерений доля выживших стабильно снижается:

Доля кур, которых ни разу не клюнут, падает с 16,7 процентов в одном измерении примерно в два раза, когда мы засовываем наших кур в семимерное пространство. Другими словами, пространство с бОльшими измерениями повышает первоначальную долю выживших (после одной итерации клевания), но снижает выживание в долгосрочной перспективе (после клевания до победного конца). Вот ещё один способ демонстрации влияния измерений — отслеживание среднего количества выживших после каждой итерации клевания в пространствах от одного до семи измерений.
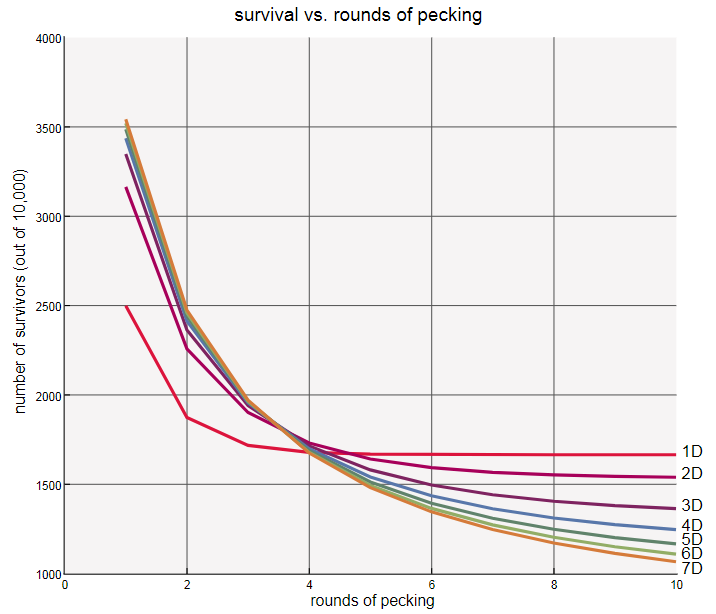
Я могу предложить грубую рационализацию этого тренда. Если вы — курица в одномерном кольце, то ваш шанс на выживание после первой итерации клевания равен всего, но если вы переживёте эту итерацию, то шанс избежать клевка во второй итерации не меньше . Почему он увеличился? Благодаря вашим собственным действиям: ваш удар клювом в первой итерации устранил угрозу от одной из двух соседок. В последующих итерациях шансы продолжают расти: чем дольше вы выживаете, тем больше вероятность того, что вы выживете после того, как соседки покоятся с миром.
Тот же тренд сохраняется и в большем количестве измерений, но величина эффекта снижается. Например, в четырёх измерениях у вас есть восемь соседок, и ваш шанс на выживание после первой итерации равен , или примерно 0,34. Поскольку вы клюёте одну из этих соседок, то вероятность выжить после второй итерации выше, но ненамного:
, или примерно 0,34. Поскольку вы клюёте одну из этих соседок, то вероятность выжить после второй итерации выше, но ненамного:  , или 0,39.
, или 0,39.
Посмотрев на приведённые выше графики, можно предположить, что при стремлении количества измерений к бесконечности количество выживших (после завершения клевания) упадёт до нуля. Чтобы изучить эту идею, нам на самом деле не нужно бесконечномерное пространство. Важнее не геометрическое расположение кур, а количество соседок, и мы можем аппроксимировать бесконечномерную сетку, просто заявив, что все куры являются ближайшими соседками. Другими словами, граф «кто кого клюёт» становится полным, в котором дуги соединяют каждую курицу со всеми другими. Похоже, это рецепт полного уничтожения; вы не можете быть в безопасности, пока клевать продолжает хотя бы одна курица. Но подробности конца игры дают небольшое пространство для вариаций. Останется ли один выживший, или их не будет совсем?
к бесконечности количество выживших (после завершения клевания) упадёт до нуля. Чтобы изучить эту идею, нам на самом деле не нужно бесконечномерное пространство. Важнее не геометрическое расположение кур, а количество соседок, и мы можем аппроксимировать бесконечномерную сетку, просто заявив, что все куры являются ближайшими соседками. Другими словами, граф «кто кого клюёт» становится полным, в котором дуги соединяют каждую курицу со всеми другими. Похоже, это рецепт полного уничтожения; вы не можете быть в безопасности, пока клевать продолжает хотя бы одна курица. Но подробности конца игры дают небольшое пространство для вариаций. Останется ли один выживший, или их не будет совсем?
Питер Уинклер рассматривал похожую задачу — «Групповую русскую рулетку» в книге Mathematical Puzzles: A Connoisseur’s Collection (стр. 33). Элементы этой версии игры — не куры, а «вооружённые и рассерженные люди», участвующие в раундах одновременной стрельбы в случайных соседей. Уинклер приходит к выводу, что вероятность выживания не приближается к пределу при увеличении. Я не вижу этого эффекта в задаче с курами: всегда остаётся одна выжившая курица. Как мне кажется, разница заключается в том, что в рулетке Уинклера игроки не тратят боеприпасы на уже застреленных врагов, в то время как куры продолжают клевать соседок, которые уже не отвечают.
Наконец, я вернусь к узким границам одного измерения и к загадочным биномиальным распределениям, которые, похоже, прогнозируют статистику клевания кур в этой системе. Повторю вкратце: если мы бросим 10 000 костей и посчитаем те из них, на которых выпали единицы, то ожидаем найти примерно 1667. Если поместить 10 000 кур в круг и дождаться, пока они закончат клевать, то мы ожидаем примерно 1667 неклюнутых выживших. Эксперимент с костями описывается биномиальным распределением с параметрами и . Та же модель не работает для кур: прогнозируемое распределение гораздо шире, чем наблюдаемое. Но странность заключается не в этом. Настоящая тайна в том, почему другая биномиальная модель с параметрами и , похоже, соответствует экспериментальным результатам.
То, что модель с костями не работает у кур, нас не удивляет. Важнейшее предположение, лежащее в основе биномиального распределения, заключается в том, что считаемые события или объекты независимы друг от друга. Для костей это справедливо; одну отдельную кость не волнует, что происходит с другими. Но в круге клюющихся кур самое важное — взаимодействие с соседями. Если вас клюнули, то это меняет шансы на то, что ваших соседей когда-нибудь клюнут. Независимость попадает в биномиальное распределение через коэффициент. При костей, на из которых выпала единица, все возможные варианты вместе с единицей равновероятны для всех других костей; биномиальный коэффициент считает количество таких комбинаций. Но при кур, из которых не клюнули, равновероятность всех комбинаций не является правдой. На самом деле, многие схемы, например, ○○○, невозможны.
Если взаимодействия с соседками портят биномиальную модель при и , то как эти взаимодействия побеждают в модели с и ? Дольше всего меня вводило в заблуждение то наблюдение, что 2500 — это ожидаемое количество выживших после одной итерации клевания, и что две третьи этих выживших ожидаемо выживут во всех последующих итерациях. Разумеется, появление этих двух чисел в биномиальном распределении не может быть бессмысленным совпадением. Возможно и нет, но мне удалось разобраться в ситуации только тогда, когда я полностью отказался от этой линии рассуждений.
Нам нужна модель, в которой мы считаем комбинации 2500 объектов, где две трети объектов можно считать успешными или выжившими. Я нашёл такую модель. Объекты — это не отдельные куры, а группы из четырёх кур. Рассмотрим это множество из четырёх кортежей:
Если случайным образом выбрать элементы из этого множества и соединить их как строку, любая создаваемая последовательность будет выходным результатом итерированного процесса клевания. Типичный результат выглядит следующим образом:
Заметьте, что эта последовательность удовлетворяет всем правилам для нашей кучи кур, которые клевались до победного конца. Все неклюнутые являются одиночками, окружёнными заклёванными соседками. Каждую пару ○ разделяет как миниум две ●, и это гарантирует, что каждый элемент последовательности имеет хотя бы одного соседа ●. Нет никаких способов конкатенировать любую выборку из элементов a, b и c, нарушающую эти правила. Более того, если a, b и c выбираются с равной вероятностью, то ожидаемая доля ○ в последовательности равна.
Я испытываю к этому открытию глубоко противоречивые чувства. С одной стороны, всегда радостно добраться до самой глубины мучившей тебя проблемы. С другой стороны, у нас здесь есть просто рецепт для создания последовательности с той же структурой и статистикой, что и результат процесса клевания, но он не даёт нам никаких намёков о природе этого процесса. Нет никакой связи с поведением кур. Что хуже, это даже не истинная и не точная модель. Хотя оказывается, что кривая совпадает с данными, это всего лишь аппроксимация. Доказать это очень просто. Биномиальное распределение с и имеет максимальный порог в . Любому числу выживших больше модель даёт нулевую вероятность, несмотря на то, что в стае из может на самом деле выжить до  кур.
кур.
Этот изъян становится заметным на меньшей модели, например, на такой, с :
:

Прогнозируемая и наблюдаемая кривые демонстрируют несовпадения повсюду, но особенно внимательно присмотритесь к правому концу распределения, где биномиальная кривая (фиолетовая) снижает до нуля все значения выживших больше шести, в то время как экспериментальные данные (красные) включают в себя 6718 случаев с семью выжившими и 49 случаев с восемью выжившими.
Похожая модель для процесса с одной итерацией клевания использует множество из четырёх трёхэлементных кортежей:
Он снова генерирует последовательность, которая очень похожа на результат эксперимента с клеванием, но ему не удаётся воспроизвести правую часть распределения. В модели максимальная возможная плотность выживших равна, в то время как она должна быть равна .
Возможно, вы считаете, что забавная задачка для старшеклассников о клюющихся курах не стоит статьи на 8000 слов с рассуждениями о цепях Маркова и распределениях вероятностей, с таблицами, уравнениями и 25 графиками и схемами. Мне это тоже приходило в голову. Однако я хочу возразить и сказать, что эти занятия не были совершенно несерьёзными.
Математика не обязана давать нам красивые, конечные и однострочные решения любой задачи, но мы бы обманули сами себя, если бы сдались слишком рано. В примере из этой статьи простыми и продуктивными оказались компьютерные симуляции. Запустив программу на пять минут, я могу получить ответы на множество подробных вопросов, и у меня не будет серьёзных сомнений в верности этих ответов. Но они не помогают мне найти связь между микроскопическими механизмами (случайные клевки курицы влево или вправо) и макроскопическими наблюдениями (распределение имеет b
b  ). В избитой цитате Ричарда Хэмминга говорится, что цель вычислений — озарение, а не числа, но именно озарения я и не достиг.
). В избитой цитате Ричарда Хэмминга говорится, что цель вычислений — озарение, а не числа, но именно озарения я и не достиг.
Во-вторых, на самом деле задача-то не о курах, реальных или абстрактных. Это дверь к множеству других многочастичных задач в статистической физике, динамических системах и клеточных автоматах.
И, наконец, мне было интересно, так что же в этом плохого? Возможно, забавы на этом не закончатся. Как насчёт куриц-зомби, чьи клевки возвращают других кур к жизни?
Постскриптум: Карл Уитти вычислил правильную вероятность для случая с одной итерацией, предоставим слово ему.
В амбаре кружком сидят 100 кур. Каждая из кур случайным образом клюёт свою ближайшую соседку слева или справа. Каково ожидаемое количество кур, которых никто не клюнул?Судя по статье Times, Робитейлу потребовалось на ответ меньше секунды.
На следующий день Джордан Элленберг твитнул такую задачу:

«100 кур сидят в круге. Каждая клюёт случайным образом R или L. Клюнутые куры никого не клюют. Итерации проводятся до тех пор, пока не останется двух соседних неклюнутых кур. Сколько кур осталось?»
Мне не нужно умещать эту историю в 140 символов, поэтому я дополню вопрос Элленберга подробностями так, как я его понял. Исходная задача относилась к одной итерации синхронизированного случайного клевания, а теперь у нас есть несколько итераций. Во время одной итерации каждая курица случайным образом поворачивается влево или вправо и клюёт одну из своих соседок. Однако если курицу уже клюнули, она больше никогда не клюёт, даже её продолжают клевать. Если две соседние курицы клюют друг друга в одной итерации, обе они вылетают из игры на все последующие раунды. Если неклюнутая курица оказывается между двумя клюнутыми, её уже никогда не клюнут и поэтому она может клевать бесконечно. Вопрос заключается в том, какая часть кур выживет и станет «неуязвимыми»?
Ниже представлены спойлеры, так что сейчас вы можете попробовать ответить на вопрос сами. Пока вы этим занимаетесь, я немного поговорю о курах и о риторике и семиотике математических «текстовых задач».
Единственные мои знания о домашней птице взяты из поездки на ферму моей тёти Норетты в южном Нью-Джерси. Нельзя сказать, что мой опыт велик, но стоит заметить, что я никогда не видел куриц, сидящих вкруг, клюющих друг друга случайным образом. (У них есть порядок клевания!) Более того, я никогда не замечал в их социальных взаимодействиях чего-то, напоминавшего принцип «подставь другую щёку», который демонстрируют куры из описанной задачи. Почему клюнутая курица больше никогда не клюёт? Это ещё большая загадка, чем количественный вопрос, на который нам предстоит ответить. Открылась ли курице внезапно мудрость и сила непротивления насилию? У меня есть другое объяснение, но оно не подходит для чувствительных людей: возможно, клюнутые курицы не клюют в ответ, потому что клевки убивают наповал.
Я знаю, что глупо требовать от подобной истории реализма повествования. Математические текстовые задачи относятся к жанру, в котором никто не ожидает правдоподобия. Они происходят в мире, где лжецы всегда лгут, а рыцари всегда говорят правду, где потерпевшие кораблекрушение моряки одержимы возможностью делимости горы кокосов, где люди не знают цвет шляпы, которая на них надета. Даже законы физики склоняются перед математическими потребностями: муха, летающая между двумя сближающимися поездами, мгновенно меняет своё направление. Эти сидящие в кругу куры — не пушистые комки жёлтого пуха; они — математические абстракции. У них нет перьев, зато есть координаты и переменные состояния.
Меня вполне устраивают абстракции; давайте любыми средствами избавляться от избыточных подробностей. Тем не менее, разве смысл текстовых задач не в том, чтобы связать математику с какими-то аспектами знакомого читателям опыта? Вспомните древнюю знаменитую задачу о пересечении реки, в которой волка нельзя оставлять с козой, которую в свою очередь нельзя оставлять с капустой (прим. пер.: в оригинале лиса, курица и мешок кукурузы). Эти ограничения легко понять, если ты что-то знаешь о вкусовых предпочтениях волков и кур. Однако такая интуитивная помощь не применима к задаче с клеванием. Напротив, чем больше мы знаем об истинном поведении пернатых, тем более сбивающей с толку будет эта задача.
Ну да ладно. Приступим! Есть ли у вас уже собственный ответ?
Задача с одной итерацией из соревнований Mathcounts Competition сводится к старейшему трюку в учебнике по теории вероятностей. Курица остаётся неклюнутой, только если обе её соседки отвернулись и клюнули в другом направлении. Вероятность избежания клевка слева и справа равна
. Два этих события независимы, поэтому вероятность остаться неклюнутой с обеих сторон равна . Эти рассуждения одинаково применимы ко всем птицам в кругу, поэтому нужно ожидать, что невредимыми останутся 25 процентов кур.Согласны ли вы с этим анализом? Когда читал статью в Times, я дошёл до него довольно быстро (конечно, совсем не так быстро, чтобы опередить нажавшего на кнопку Люка Робитейла). Но потом у меня зародились сомнения. Строго ли верно то, что соседки курицы слева и справа совершенно независимы? В конце концов, они связаны цепочкой других кур. Возможно, по кругу может распространиться какое-то влияние, создающее корреляции между левой и правой курицей и меняющее вероятность выживания.
Настало время экспериментов: напишем программу и запустим симуляцию. Выстроим кольцо из 100 неклёванных кур и выполним одну итерацию случайного одновременного клевания. Повторим много раз и вычислим среднее количество оставшихся неклюнутыми птиц. (Вот краткая запись: пусть
— число кур в кольце, а — количество оставшихся неклюнутыми. Я обозначу как среднее значение , усреднённое после повторений эксперимента.) Мои результаты: |
|
|---|---|
| 100 | 24,79 |
| 10 000 | 24,9881 |
| 1 000 000 | 25,000274 |
| 100 000 000 | 24,99991518 |
Как и ожидалось, среднее значение довольно близко к 25 выжившим. Более того, при каждом увеличении размера выборки в 100 раз точность аппроксимации увеличивается примерно в десять раз. Этот паттерн соответствует эмпирическому правилу статистики: флуктуации случайного процесса пропорциональны квадратному корню размера выборки. То есть незначительные отклонения от
похожи на невинный случайный шум, а не какое-то систематическое смещение.То есть вопрос решён, не так ли?
Вообще, симуляция выглядит довольно убедительной для конкретного случая
кур, но результат может отличаться для других значений N. В частности, возможно, существует некий эффект конечной размерности, становящийся очевидным только при малых N. Рассмотрим «круг» из всего двух кур. В этой симуляции левый и правый сосед — это одна и та же курица! Вне зависимости от случайно сделанных выборов две курицы сразу же клюнут друг друга, и часть выживших будет равна не 25 процентам, а нулю.Следующий, более крупный «круг» состоит из трёх кур, собранных в треугольник. Два соседа теперь — это разные куры, но они также являются соседями друг друга. Что случится, когда три курицы набросятся друг на друга? В системе есть
возможных комбинаций клевания, и мы легко можем изучить из все. Стрелками на схеме показано то, в какую сторону курицы выбрали клевать.
В двух случаях все курицы клюют влево или клюют вправо, и выживших нет. В каждом другом случае неклюнутой остаётся ровно одна курица. Собрав все восемь комбинаций, мы получаем шесть неклюнутых кур из 24, то есть соотношение равно
. То есть, похоже, аномалия конечных значений затрагивает только случай задачи с двумя курами.Но постойте! Существует ещё один возможный искажающий результаты фактор. Можем ли мы быть уверены, что одинаковые результаты будут и для чётных, и для нечётных количеств кур? При любом нечётном значении N существует только один способ уничтожить всех кур за один раунд: все они должны клевать в одном направлении. Однако при чётном N к немедленному вымиранию приводит ещё одна комбинация: соседние куры разбиваются на пары и клюют друг друга. Не изменит ли этот дополнительный способ общую вероятности выживания?
Давайте посмотрим, что происходит при N = 4. Теперь существует
возможных результатов:
Как и ожидалось, в четырёх комбинациях вообще нет выживших. С другой стороны, также есть четыре комбинации, в которых остаётся не одна, а две неклюнутые курицы. Дополнительные потери и дополнительные выигрыши чудесным образом уравновешивают друг друга. Всего у нас будет 16 выживших из 64 кур, то есть соотношение снова равно
.После этого долгого и извилистого обхода комбинаторики клевания кур мы вернулись ровно к тому, с чего начинали. Вероятность остаться неклюнутой после одной итерации клевания равна
для любого . Все мои волнения об эффектах конечных размеров и неравномерностей чёт-нечет были пустой тратой времени. Так зачем же я поделился ими с вами? Хотя мои волнения оказались ничем не обоснованными, они вовсе не надуманны. Даже небольшие изменения в порядке клевания приведут к другим результатам. Допустим, клевание будет последовательным, а не одновременным. Одна выбранная курица начинает последовательность клевков, а затем свои ходы делают другие птицы, расположенные по часовой стрелке от неё. Когда приходит очередь курицы, то если её уже клюнули, то она ничего не делает. Если её не клюнули, она клюёт влево или вправо, выбирая случайным образом. Итерация заканчивается, когда каждая курица сделает свой ход.При
легко увидеть, что первая клюющая курица всегда выживает, а другая всегда умирает, то есть доля выживших равна . Немного посчитав куриц на бумаге, можно выяснить, что доля выживших в 50 процентов также справедлива и для . При исследовании бОльших значений компьютерные эксперименты показывают, что доля выживших при стремлении к бесконечности снова приближается к . Однако между этими предельными значениями существуют забавные ситуации:
При
доля выживших опускается ниже 0,47. (Точная вероятность равна .) Это минимум значений. Но при возвращении соотношения к 0,5 в кривой появляются колебания, показывающие расхождения результатов при чётном и нечётном количествах: вероятность выживания снижается больше для чётных N, чем для нечётных N. Именно такое поведение я искал (но не нашёл) в исходной версии задачи с соревнований Mathcounts.Давайте снова возьмёмся за задачу Элленберга про итерируемое клевание (с одновременным, а не последовательным клеванием). Мы уже знаем, что после первой итерации можно ожидать, что неклюнутыми останется примерно четверть кур. Очевидно, что часть неклюнутых не может увеличиваться после нескольких итераций. То есть в конечном состоянии ожидаемая доля выживших
должна находиться где-то между нулём и .Полезно будет посмотреть на обычную конфигурацию клюнутых (●) и неклюнутых (○) кур после одной итерации синхронизированного клевания:
●○●●●○○●●●●○●●○●●○○●●●○○●●●●●○●●●●●●●●●○○●●●●●●○○●●●○●●●●●●○●●●○○●●●●●(Мысленно соедините левый и правый концы массива, чтобы создать кольцо.) Заметьте, что здесь присутствуют длинные строки клюнутых кур, но неклюнутые куры присутствуют только в двух конфигурациях. Они являются или одиночками (●○●), или парами (●○○●). Причину такого паттерна понять просто. После раунда клевания существование группы из трёх неклюнутых кур подряд (●○○○●) невозможна. Средняя курица обязана клюнуть влево или вправо, то есть у неё не может быть двух неклюнутых соседей.
Такие ограничения упрощают анализ последующих итераций. Одиночки в сущности бессмертны и неизменяемы: неклюнутую курицу посередине никогда больше не клюнут, а клюнутых соседей никогда больше не вернуть в «неклюнутое» состояние. Для пар существует четыре возможных варианта развития событий, соответствующих четырём способам, которыми две активные курицы выберут клевать:

В любой итерации все эти четыре события имеют одинаковую вероятность, а именно
. Первые три получившихся состояния являются заключительными, в том смысле, что дальнейшие итерации клевания не изменят их. В четвёртом случае у нас снова остаётся пара соседей, перед которой в следующей итерации предстанет тот же выбор вариантов. Со временем, когда количество итераций будет стремиться к бесконечности, четвёртый случай должен привести к одному из других результатов, а потому в длительной перспективе мы должны считать вероятность четвёртого случая равной нулю, а вероятность каждого из других трёх случаев равной .Теперь настало время соединить эти зависящие от обстоятельств события вместе и вычислить вероятность выживания курицы в длительной перспективе. На рисунке ниже показана схема. В первом раунде клевания три четверти кур сразу же уничтожаются. Из оставшейся четверти половина является одиночками, которые выживают бесконечно. Каждая другая выжившая курица является членом пары, а другая клюющая курица из её пары — это её левая или правая соседка.

В нижней части схемы подводится итог влияния всех последовательных итераций, которые продолжаются, пока все пары не уничтожатся или не уменьшаться до одиночек. (Я называю это клеванием до последнего.) Для каждого пути, ведущего к выживанию одиночки, вероятность является произведением отдельных вероятностей, встреченных на этом пути. Существует три таких пути с вероятностями
, и и суммой .Должен признаться, что мне не удалось выполнить этот анализ — или получить верный ответ — с первой попытки. Я добился его только после выполнения симуляции, узнав таким образом, что мне нужно искать. И даже тогда у меня возникали проблемы с двойным подсчётом.
Вот как выглядят результаты симуляции:
|
|
|---|---|
| 100 | 16,53 |
| 10 000 | 16,6835 |
| 1 000 000 | 16,664404 |
| 100 000 000 | 16,66701664 |
Заметьте, что точность снова улучшается как квадратный корень от размера выборки, несмотря на то, что дисперсия здесь больше, чем в эксперименте с одной итерацией.
А как насчёт эффектов конечного размера? В кругу со всего двумя или тремя курами их судьба полностью определяется единственной итерацией клевания:
соответственно равно 0 и . То есть эти наименьшие круги не соответствуют правилу , но похоже, что круги любого бОльшего размера сводятся к . Расхождений чёт-нечет в них не замечено.Ещё одним подходом к пониманию задачи итерированного клевания кур является теория цепей Маркова. Для кольца из
кур мы перечисляем все состояний и назначаем вероятность каждому переходу между состояниями. Рассмотрим кольцо из четырёх кур, которое имеет 16 состояний. Симметрия позволяет нам объединить некоторые из состояний; другие состояния можно отбросить, потому что они недостижимы из начального состояния с четырьмя неклюнутыми курами (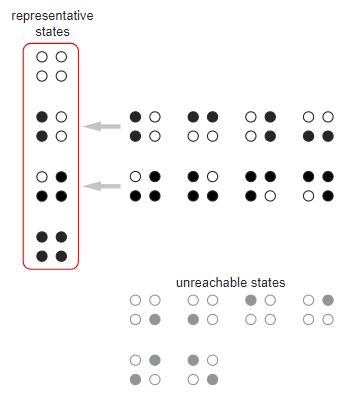
В модели должны сохраниться только четыре состояния выделенные красным контуром. Переходы между ними записываются в направленный граф, в котором каждая стрелка помечается соответствующей вероятностью. Стоит заметить, что у начального состояния

Важную информацию из этого направленного графа можно отобразить в матрице
, в которой строки и столбцы помечены четырьмя состояниями, а элементы матрицы представляют собой вероятность перехода из состояния строки в состояние столбца. Сумма элементов каждой строки равна 1, как и должно быть, если они представляют собой вероятности.
Паттерн нулевых элементов в матрице переходов подразумевает, что в некоторые состояния нельзя попасть из других состояний, даже непрямым путём. По этой причине говорят, что марковская модель является иррегулярной. Это немного неприятно, потому что регулярные марковские модели проще в анализе и понимании. В регулярной модели, когда мы берём последовательные степени матрицы перехода, она сводится к установившемуся состоянию, в котором все строки одинаковы, а каждый столбец состоит из единственного повторяющегося значения. Такое фиксированное состояние отображает распределение вероятностей в долгосрочной перспективе. Иррегулярная марковская модель может даже не иметь установившегося ограничивающего распределения, но в нашей оно есть, и это даёт нам определённые подсказки. Любое кольцо из четырёх кур должно в результате прийти к одному из двух поглощающих состояний. С вероятностью «две третьих» это заключительное состояние будет
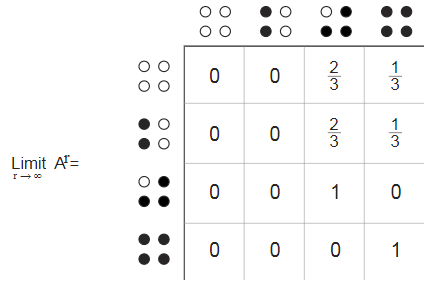
То есть можно подводить итог, правда? И в задаче с соревнований, и в её итеративной версии Элленберга спрашивалось ожидаемое количество выживших кур, и мы дали ответ: при
кур ожидаемое количество выживших равно после единственной итерации клевания и при клевании до конца. Однако иронично, что ожидаемое значение вероятностного процесса не обязательно сообщает нам, чего стоит ожидать. Рассмотрим простую задачу: подбросив монетку 100 раз, сколько «орлов» мы ожидаем увидеть? Очевидный ответ — 50, и он верен в том смысле, что никакое другое число не имеет большей возможности верно предсказать результат эксперимента. Однако вероятность увидеть ровно 50 «орлов» равна всего 0,08, то есть в 90 процентах случаев мы будем получать другое число.Вместо того, чтобы смотреть только на ожидаемое значение, давайте изучим интервал возможных значений
игры с клеванием. Мы уже установили, что ноль выживших является возможным результатом, то есть нижняя граница у нас есть. А что насчёт верхней границы — максимального количества выживших? В процессе с одной итерацией клевок делает каждая курица, то есть после этой итерации у каждой курицы должен быть хотя бы один клюнутый сосед. На основании этого факта я заявляю, что выжившая популяция никогда не может быть больше . (Вы согласны? Мне понадобилось какое-то время, чтобы убедить себя в этом.)Если
никогда не может быть больше , то следующим вопросом будет такой: сможет ли оно вообще когда-нибудь достичь этого предела? И если у нас может быть одинаковое количество клюнутых (●) и неклюнутых (○) кур, то как они будут расположены в кольце? Кажется логичным предложить следующую конфигурацию:●○●○●○●○●○●○Это стабильное состояние: неклюнутых кур никогда не смогут клюнут, то есть дальнейшие изменения невозможны. А доля выживших равна
. Но у этой схемы есть проблема: её невозможно достичь из начального состояния. Посмотрите на любую из клюнутых кур и задайте вопрос: какая из соседок её клюнула? Очевидно, что ни одна из них, потому что их обеих никто не клюнул. Но это невозможно, потому что каждая курица в первой итерации должна клюнуть.Хотя схему из попеременных чёрных и белых кур мы исключили, мы находимся на верном пути. Существует ещё одна конфигурация, при которой после первой итерации тоже остаётся половина кур, и эта схема достижима из начального состояния:
●●○○●●○○●●○○Когда мы соединяем концы, чтобы получить кольцо, у каждой курицы, вне зависимости от того, клюнули её или нет, есть одна клюнутая соседка. Оказывается, что это единственный способ, если не считать очевидных симметричных случаев, чтобы достичь выживания 50 процентов. (Строго говоря, 50 процентов можно достичь только когда
делится на 4, но никогда не меньше .)Когда клевание выполняется до победного конца, верхняя граница
больше недостижима. Допустим, что мы бы пытались сохранить через несколько итераций клевания. Очевидно, что нам пришлось бы начинать в первой итерации с максимальной доли выживших ●●○○●●○○●●○○. Однако по крайней мере половина неклюнутых кур в этой конфигурации должна погибнуть в последующих итерациях, оставив не больше выживших.Значит ли это, что
является максимально возможным значением после клевания до победного конца? Нет, не значит. Существует ещё одна схема, в которой выживает одна из каждых трёх кур:●●○●●○●●○●●○Эта конфигурация достижима за одну итерацию и бесконечно устойчива, потому что ни у одной из клюющих кур нет клюющих соседок. Ни одна другая схема не имеет большей плотности выживших при выполнении процесса клевания до конца.
Подведём итог: после одной итерации клевания количество выживших кур должно находиться где-то между нулём и
, а ожидаемое количество — ровно посередине, в . После завершения всех последующих итераций количество неклюнутых кур будет находиться в интервале между нулём и , а ожидаемое значение снова будет посередине, в .«Сколько кур выживет?» — этот вопрос, кажется, требует численного ответа, но на самом деле наиболее информативным ответом на него будет совсем не число, а распределение:

Каждая кривая фиксирует результаты миллиона экспериментов с кольцом из 100 кур, показывая частоту каждого возможного значения
. Как и ожидалось, распределение при одной итерации имеет пик на 25 выживших, а кривая задачи с итерацией — на 17 (ближайшее к целое). Заметьте, что красная кривая не только смещена влево, но также выше и уже.Чтобы лучше рассмотреть результаты, давайте изменим масштаб. Чтобы кривые были более плавными, я перейду к экспериментам с
кур. Зелёная кривая — для одной итерации, а красная — для эксперимента со множеством итераций клевания:

При бОльших значениях
пики кривых находятся в 2500 и в 1666,67, то есть ровно в точках, ожидаемых для и . Было неудивительно найти пики в этих точках, но что же управляет шириной и общей формой кривой? Другими словами, каковая математическая природа распределений?Первая догадка — всегда стоит попробовать нормальное (или гауссово) распределение. Для задачи клевания нормальное распределение определяет
, вероятность наблюдения выживших, следующим образом:
Довольно запутанное уравнение для такого знакомого понятия, но из него можно выделить основной смысл. Уравнение определяет симметрическую кривую с пиком, где
равно , то есть среднему значению распределения. Ширина пика зависит от стандартного отклонения . Поскольку площадь под кривой постоянна, в сущности определяет её высоту: более узкий пик должен быть выше.Мы можем согласовать нормальное распределение с данными о клевании с помощью процедуры, находящей оптимальные значения
и , такие, которые минимизируют расхождение между точками данных и математической моделью. В двух представленных ниже графиках согласованные модели наложены на два графика данных, первая для одной итерации, вторая — для итераций до конца:

Согласование выглядит достаточно близким, теоретические кривые разделяют экспериментальные от начала до конца. В каком-то смысле, этот результат можно считать успехом, но я всё-таки не нахожу такой подход к задаче полностью удовлетворительным. Нормальная кривая создаёт очень хорошую описательную модель процесса клевания, но не прогнозирует и не объясняет её. Не забывайте, что мы согласовали кривую с данными, а не наоборот. Я не вижу очевидных способов создать некое нормальное распределение из того, что я знаю о взаимодействиях клюющихся кур. В частности, откуда берутся значения
двух моделей? Почему в модели с одной итерацией, но в модели с множеством итераций? Эти значения выглядят как независимые параметры, которые нам приходится подгонять для соответствия данным. Более того, они будут разными для каждого значения . Ещё одна проблема: нормальная кривая — это непрерывное распределение, определённое на всей вещественной числовой оси. Функция клевания дискретна, она имеет смысл только для целых величин.Давайте отложим в сторону нормальную кривую и рассмотрим ещё одну правдоподобную модель: биномиальное распределение, которое дискретно и возникает во многих контекстах, связанных с вероятностями. Предположим, что мы бросим 10 000 костей и посчитаем, на скольких из них выпала единица. Когда мы повторим эксперимент множество раз, ожидаемое количество единицы будет равно одной шестой от 10 000, то есть то же значение, что и ожидаемое количество выживших в итерируемом эксперименте с клюющимися курами. Для костей существует хорошо известное математическое выражение, определяющее не только ожидаемое значение, но и форму всего распределения. Предположим, что каждая кость имеет вероятность выбрасывания
, обозначенную . Мы будем бросать костей и нам нужно знать вероятность увидеть единицы= для любого от до . Формула для обработки этой информации имеет вид:
Здесь
даёт вероятность любой отдельной комбинации единиц среди костей. Биномиальный коэффициент , равный \), подсчитывает количество таких комбинаций.При
и мы получаем кривую, показывающую результат вышеупомянутого эксперимента с бросанием костей. Возможно, та же кривая описывает и то, что происходит в модели клевания со множеством итераций, которая имеет то же ожидаемое значение? Увы, но нет.
Биномиальная кривая шире и более плоская, чем распределение выживших при итерированном клевании. Что же пошло не так? Когда я впервые увидел график, у меня появилось предчувствие. Как сказано выше, биномиальный коэффициент
подсчитывает все способы выбора элементов из множества размером . Он подходит для эксперимента с костями, потому что все возможные комбинации успехов среди равновероятны. В частности, когда мы бросаем костей, мы можем вообще не увидеть единиц или увидеть все костей с единицами на верхней грани; весь интервал результатов имеет вероятность больше нуля.Задача с клеванием отличается, 100 процентов кур не может остаться неклюнутыми. То есть достижимо только подмножество
комбинаций. Если биномиальное распределение и будет работать в таком контексте, нам нужно каким-то образом изменить его, чтобы включить только достижимые результаты.С мыслью о том, что легче решить задачу, если уже знаешь ответ, я попытался поиграться с параметрами распределения, чтобы посмотреть, как будет реагировать график. Я стремился уместить кривую в более узкий и высокий график, сохранив центрирование по тому же среднему значению. Среднее равно
, то есть если мы уменьшим , то нам придётся увеличивать на тот же коэффициент. Вот результаты некоторых экспериментов:
Тёмно-зелёная кривая — это та, которую мы уже видели, для биномиального распределения при
и . Изменение параметров на и кажется шагом в верном направлении, а и оказываются ещё лучше. Тогда попробуем и Бинго! Жёлтая кривая идеально соответствует данным клевания. То есть, похоже, мы можем прогнозировать выживание в кольце клевания из членов, создав биномиальное распределение с параметрами и .Я могу повторить тот же трюк, чтобы найти биномиальное распределение, соответствующее одной итерации клевания. На этот раз волшебные числа, сгибающие кривую по нужной траектории, равны
и .
В отличие от нормального распределения, биномиальная модель конструктивна (то есть способна прогнозировать). Из двух параметров
и мы можем вычислить и среднее значение распределения, и стандартное отклонение. Среднее значение — это просто , стандартное отклонение — это . Например, при кур среднее оказывается равным (как и ожидается), а стандартное отклонение равно . (У подогнанного нормального распределения .) Для случая с одной итерацией равно , а равно . (Чтобы избежать ошибок округления, я взял , равное , а не .)Ну что, ура? По крайней мере, у нас есть формула для вычисления формы и расположения распределения клевания кур, зависящая всего от пары параметров-
и . Но я снова ворчу, на самом деле я ещё более рассержен. Может быть, модель и объясняет данные, но как объяснить саму модель? При кур и вероятности выживания в первой итерации , зачем формуле нужны и ? Откуда берутся эти числа? И почему в случае со множественными итерациями подходят и ?Мне неудобно говорить, сколько времени я потратил на безнадёжные бултыхания в болотах теории вероятностей, пытаясь решить эти загадки. (Я даже обратился к недавно изданной книге The Probability Lifesaver («Спасатель в мире вероятностей»), которую я крайне рекомендую, но она меня не спасла.) В поисках ответов я исследовал полиномиальные обобщения биномов. Я изучал свёртки распределений и вычислял условные вероятности. Я заполнял целые блокноты ровными строками из ● и ○ в поисках паттернов, которые бы могли объяснить такие загадочные дроби
в паре с и в паре с . Каждую ночь я ложился спать с многообещающей идеей, но потом просыпался и находил в ней существенный недостаток.Теперь мне кажется, что у меня есть правильное объяснение. Оно пришло ко мне после множества проверок в течение нескольких вечеров. Я расскажу о нём, но только в самом конце статьи. Возможно, вам удастся найти его раньше. Тем временем, я хочу расширить горизонты задачи про кур.
Наш уютный кружок кур — это одномерная структура. В кольце можно пойти по часовой стрелке и против неё, других значимых направлений в этой маленькой вселенной нет. Теперь представьте, что вместо того, чтобы сажать всех кур в круг, мы поместим их в сетку, то есть в массив и строк и столбцов, заполнив область двухмерного пространства. Чтобы не оставлять последних кур по краям квадратного массива, мы можем соединить левый край с правым, а верхний с нижним. (С точки зрения топологии это превращает прямоугольник в тор.) Заставить реальных кур в этом эксперименте работать совместно оказалось бы ещё сложнее, чем в одномерной версии, но нас это не волнует; мы давно уже попрощались с нашей амбарной реальностью.
Самое важное в этом двухмерном расположении — это то, что у каждой курицы теперь не две, а четыре соседки. Враждебных соседей стало больше, так что можно было бы ожидать, что курица будет более уязвима к атакам. С другой стороны, каждая из этих соседок распределяет свои клевки на потенциальных жертв, количество которых увеличилось в два раза. Как же уравновешиваются эти условия соревнований?
При единственной итерации клевания мы можем вычислить вероятность выживания так же, как в одномерной системе. Курица остаётся неклюнутой, только если все её соседки клюют в какую-то другую сторону. Каждая соседка клюёт так с вероятностью
, поэтому вероятность того, что все они отвернутся, равна . Численно это оказывается равным примерно 0,3164, (в круге значение было равно 0,25). То есть доля выживающих в двух измерениях больше, чем в одном; отвлечение на бОльшее количество жертв перевешивает опасность бОльшего количества нападающих. Распределение, наблюдаемое в компьютерных экспериментах, подтверждает этот результат.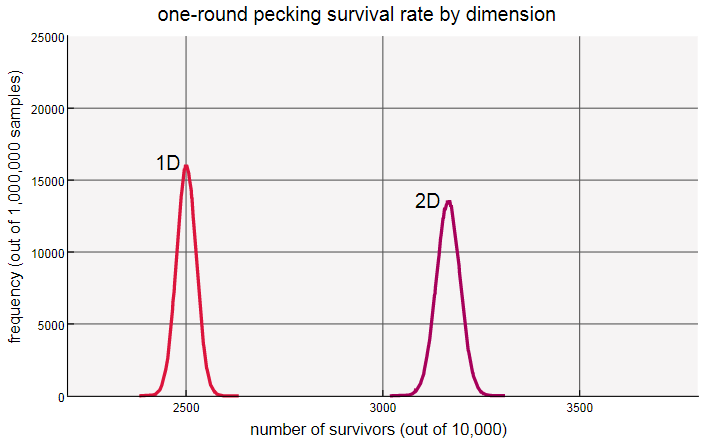
Здесь показано, как сетка из кур
выглядит после одной итерации клевания.
В двухмерном массиве находится 1600 кур. Если посчитаем неклюнутых, то обнаружим, что их 501, то есть доля выживших равна 0,3131, и это близко к теоретическому значению 0,3164. Симуляции подтверждают, что ожидаемая доля выживших равна
для сеток при любом значении больше . (Для сетки доля выживших равна , как и в одномерной системе. И на то есть причина!)Когда я пристально смотрел на представленную выше схему, то заметил определённую повторяющуюся текстуру с цепочками ○, разделяющих пятна ●. Это может быть иллюзией, но я так не думаю. В двух измерениях ограничение «никаких трёх подряд» снимается; в массиве содержатся строки и столбцы, в которых есть до шести последовательных неклюнутых кур, а также диагональные линии. Но сплошного блока
из неклюнутых кур ( (Так как при первой итерации клевания в двухмерном мире выживает больше кур, то кажется правдоподобным, что при продолжении итераций до завершения может выжить большая доля кур. Давайте попробуем провести эксперимент:

В этом массиве
оказалось 238 выживших из 1600 кур, что меньше, чем доля выживших в одном измерении (одна шестая). При выборке в один миллион таких сеток я обнаружил, что средняя доля выживших примерно равна 0,1533. Сравните распределения в одно- и двухмерной системах:
При переходе из 1D в 2D пик сдвигается влево, а среднее перемещается от 0,1667 к 0,1533. Двухмерный холм также немного выше и уже, то есть он демонстрирует меньшую дисперсию.
Но зачем останавливаться на двух измерениях? Давайте попросим наших кур собраться в трёхмерную решётку, а противоположные границы снова соединим, создав трёхмерный аналог тороидальной поверхности. Несложно догадаться, к чему приведёт такой эксперимент. В одном измерении у каждой курицы было только две соседки, а доля выживших после одной итерации клевания была
. В двух измерениях с четырьмя соседками соответствующее значение было равно . В трёхмерном массиве у каждой курицы есть шесть соседок, то есть очевидно экстраполировать как , получив значение . После выполнения симуляции эти данные подтверждаются и демонстрируют чёткую тенденцию при создании массивов кур с увеличивающимся количеством измерений.
Исходя из этой серии результатов, мы можем смело обобщить: когда у курицы есть
соседок, ожидаемая доля выживших после первой итерации клевания равна
При увеличении
это выражение сходится к значению, примерно равному . Знакомо ли нам это число? Это же . (Поменяв минус на плюс, мы получим само , .) Когда я пришёл к этой формуле, внезапное появление застало меня врасплох, хотя и не должно было. Константа появляется таким же способом, как в модели распространения слухов, о которой я писал несколько лет назад.А как насчёт итерируемого процесса клевания при больших количествах измерений? При увеличении измерений доля выживших стабильно снижается:

Доля кур, которых ни разу не клюнут, падает с 16,7 процентов в одном измерении примерно в два раза, когда мы засовываем наших кур в семимерное пространство. Другими словами, пространство с бОльшими измерениями повышает первоначальную долю выживших (после одной итерации клевания), но снижает выживание в долгосрочной перспективе (после клевания до победного конца). Вот ещё один способ демонстрации влияния измерений — отслеживание среднего количества выживших после каждой итерации клевания в пространствах от одного до семи измерений.

Я могу предложить грубую рационализацию этого тренда. Если вы — курица в одномерном кольце, то ваш шанс на выживание после первой итерации клевания равен всего
, но если вы переживёте эту итерацию, то шанс избежать клевка во второй итерации не меньше . Почему он увеличился? Благодаря вашим собственным действиям: ваш удар клювом в первой итерации устранил угрозу от одной из двух соседок. В последующих итерациях шансы продолжают расти: чем дольше вы выживаете, тем больше вероятность того, что вы выживете после того, как соседки покоятся с миром.Тот же тренд сохраняется и в большем количестве измерений, но величина эффекта снижается. Например, в четырёх измерениях у вас есть восемь соседок, и ваш шанс на выживание после первой итерации равен
, или примерно 0,34. Поскольку вы клюёте одну из этих соседок, то вероятность выжить после второй итерации выше, но ненамного: , или 0,39.Посмотрев на приведённые выше графики, можно предположить, что при стремлении количества измерений
к бесконечности количество выживших (после завершения клевания) упадёт до нуля. Чтобы изучить эту идею, нам на самом деле не нужно бесконечномерное пространство. Важнее не геометрическое расположение кур, а количество соседок, и мы можем аппроксимировать бесконечномерную сетку, просто заявив, что все куры являются ближайшими соседками. Другими словами, граф «кто кого клюёт» становится полным, в котором дуги соединяют каждую курицу со всеми другими. Похоже, это рецепт полного уничтожения; вы не можете быть в безопасности, пока клевать продолжает хотя бы одна курица. Но подробности конца игры дают небольшое пространство для вариаций. Останется ли один выживший, или их не будет совсем?Питер Уинклер рассматривал похожую задачу — «Групповую русскую рулетку» в книге Mathematical Puzzles: A Connoisseur’s Collection (стр. 33). Элементы этой версии игры — не куры, а «вооружённые и рассерженные люди», участвующие в раундах одновременной стрельбы в случайных соседей. Уинклер приходит к выводу, что вероятность выживания не приближается к пределу при увеличении
. Я не вижу этого эффекта в задаче с курами: всегда остаётся одна выжившая курица. Как мне кажется, разница заключается в том, что в рулетке Уинклера игроки не тратят боеприпасы на уже застреленных врагов, в то время как куры продолжают клевать соседок, которые уже не отвечают.Наконец, я вернусь к узким границам одного измерения и к загадочным биномиальным распределениям, которые, похоже, прогнозируют статистику клевания кур в этой системе. Повторю вкратце: если мы бросим 10 000 костей и посчитаем те из них, на которых выпали единицы, то ожидаем найти примерно 1667. Если поместить 10 000 кур в круг и дождаться, пока они закончат клевать, то мы ожидаем примерно 1667 неклюнутых выживших. Эксперимент с костями описывается биномиальным распределением с параметрами
и . Та же модель не работает для кур: прогнозируемое распределение гораздо шире, чем наблюдаемое. Но странность заключается не в этом. Настоящая тайна в том, почему другая биномиальная модель с параметрами и , похоже, соответствует экспериментальным результатам.То, что модель с костями не работает у кур, нас не удивляет. Важнейшее предположение, лежащее в основе биномиального распределения, заключается в том, что считаемые события или объекты независимы друг от друга. Для костей это справедливо; одну отдельную кость не волнует, что происходит с другими. Но в круге клюющихся кур самое важное — взаимодействие с соседями. Если вас клюнули, то это меняет шансы на то, что ваших соседей когда-нибудь клюнут. Независимость попадает в биномиальное распределение через коэффициент
. При костей, на из которых выпала единица, все возможные варианты вместе с единицей равновероятны для всех других костей; биномиальный коэффициент считает количество таких комбинаций. Но при кур, из которых не клюнули, равновероятность всех комбинаций не является правдой. На самом деле, многие схемы, например, ○○○, невозможны.Если взаимодействия с соседками портят биномиальную модель при
и , то как эти взаимодействия побеждают в модели с и ? Дольше всего меня вводило в заблуждение то наблюдение, что 2500 — это ожидаемое количество выживших после одной итерации клевания, и что две третьи этих выживших ожидаемо выживут во всех последующих итерациях. Разумеется, появление этих двух чисел в биномиальном распределении не может быть бессмысленным совпадением. Возможно и нет, но мне удалось разобраться в ситуации только тогда, когда я полностью отказался от этой линии рассуждений.Нам нужна модель, в которой мы считаем комбинации 2500 объектов, где две трети объектов можно считать успешными или выжившими. Я нашёл такую модель. Объекты — это не отдельные куры, а группы из четырёх кур. Рассмотрим это множество из четырёх кортежей:
a = ○●●●
b = ●○●●
c = ●●●●Если случайным образом выбрать элементы из этого множества и соединить их как строку, любая создаваемая последовательность будет выходным результатом итерированного процесса клевания. Типичный результат выглядит следующим образом:
●●●●○●●●●○●●○●●●●●●●○●●●●○●●●●●●●○●●○●●●●○●●●●●●○●●●●○●●●○●●○●●●●●●●○●●Заметьте, что эта последовательность удовлетворяет всем правилам для нашей кучи кур, которые клевались до победного конца. Все неклюнутые являются одиночками, окружёнными заклёванными соседками. Каждую пару ○ разделяет как миниум две ●, и это гарантирует, что каждый элемент последовательности имеет хотя бы одного соседа ●. Нет никаких способов конкатенировать любую выборку из элементов a, b и c, нарушающую эти правила. Более того, если a, b и c выбираются с равной вероятностью, то ожидаемая доля ○ в последовательности равна
.Я испытываю к этому открытию глубоко противоречивые чувства. С одной стороны, всегда радостно добраться до самой глубины мучившей тебя проблемы. С другой стороны, у нас здесь есть просто рецепт для создания последовательности с той же структурой и статистикой, что и результат процесса клевания, но он не даёт нам никаких намёков о природе этого процесса. Нет никакой связи с поведением кур. Что хуже, это даже не истинная и не точная модель. Хотя оказывается, что кривая совпадает с данными, это всего лишь аппроксимация. Доказать это очень просто. Биномиальное распределение с
и имеет максимальный порог в . Любому числу выживших больше модель даёт нулевую вероятность, несмотря на то, что в стае из может на самом деле выжить до кур.Этот изъян становится заметным на меньшей модели, например, на такой, с
:
Прогнозируемая и наблюдаемая кривые демонстрируют несовпадения повсюду, но особенно внимательно присмотритесь к правому концу распределения, где биномиальная кривая (фиолетовая) снижает до нуля все значения выживших больше шести, в то время как экспериментальные данные (красные) включают в себя 6718 случаев с семью выжившими и 49 случаев с восемью выжившими.
Похожая модель для процесса с одной итерацией клевания использует множество из четырёх трёхэлементных кортежей:
a = ○●●
b = ○●●
c = ●●○
d = ●●●Он снова генерирует последовательность, которая очень похожа на результат эксперимента с клеванием, но ему не удаётся воспроизвести правую часть распределения. В модели максимальная возможная плотность выживших равна
, в то время как она должна быть равна .Возможно, вы считаете, что забавная задачка для старшеклассников о клюющихся курах не стоит статьи на 8000 слов с рассуждениями о цепях Маркова и распределениях вероятностей, с таблицами, уравнениями и 25 графиками и схемами. Мне это тоже приходило в голову. Однако я хочу возразить и сказать, что эти занятия не были совершенно несерьёзными.
Математика не обязана давать нам красивые, конечные и однострочные решения любой задачи, но мы бы обманули сами себя, если бы сдались слишком рано. В примере из этой статьи простыми и продуктивными оказались компьютерные симуляции. Запустив программу на пять минут, я могу получить ответы на множество подробных вопросов, и у меня не будет серьёзных сомнений в верности этих ответов. Но они не помогают мне найти связь между микроскопическими механизмами (случайные клевки курицы влево или вправо) и макроскопическими наблюдениями (распределение имеет
b ). В избитой цитате Ричарда Хэмминга говорится, что цель вычислений — озарение, а не числа, но именно озарения я и не достиг.Во-вторых, на самом деле задача-то не о курах, реальных или абстрактных. Это дверь к множеству других многочастичных задач в статистической физике, динамических системах и клеточных автоматах.
И, наконец, мне было интересно, так что же в этом плохого? Возможно, забавы на этом не закончатся. Как насчёт куриц-зомби, чьи клевки возвращают других кур к жизни?
Постскриптум: Карл Уитти вычислил правильную вероятность для случая с одной итерацией, предоставим слово ему.
Первое: я считаю, что в разделе про цепи Маркова ваши графики неверны; у вас получилось много схем с одной чёрной точкой и тремя белыми точками, которые названы поглощающими, но на самом деле поглощающими должны быть три чёрные и одна белая. (Ошибка повторяется: по моим подсчётам, у вас пять неверных графических файлов (один из которых использован дважды). Кроме того, в первом неверном графическом файле недостижимые состояния с тремя «чёрными» (серыми) точками и одной белой точкой должны иметь три белые точки.)
Второе: я считаю, что у меня есть лучшее объяснение результатов одной итерации, по крайней мере, для случая с нечётным количеством кур.
Давайте начнём с того, что вычислим вероятность наблюдать ровно, на самом деле мы рассмотрим (смещённых на единицу) соседок
(не учитывая курицу в
). Мы можем объединить такие соседства в цепочку
, которая зацикливается в конце списка. Если
есть
и
. Если
есть
.
Мы можем представить цепочку как последовательность буквили
тогда и только тогда, когда курица между этими двумя курицами не клюнута. (Так как мы считаем, что концы этой цепочки соединены, то наличие
. Мы можем вычислить её, проверив, сколько из возможных цепочек
содержат
Между каждыми двумя «соседними» последовательностями; другими словами, в каждой цепочке содержится одинаковое количество последовательностей
изменений. Для любой заданной цепочки мы определяем цепочку изменения. Начнём с добавления
для обозначения «есть изменения» между каждой парой букв; то есть для цепочки
у нас в результате получится
. (Эта последняя
.
Любая цепочка преобразуется в единственную цепочку изменений; каждая цепочка изменений является преобразованием ровно двух цепочек (одной, в которой первая буква(и потом удвоить это число, потому что каждая цепочка изменения соответствует двум цепочкам). Тогда вероятность наличия
, или
.
Теперь, если мы вернёмся к исходной задаче с
Если. Тогда вероятность наличия
Вероятность чётного случая очень запутана (и я не знаю, как упростить её); кроме того, я не проверял её заново, так что в формуле могут быть незначительные ошибки. Далее я буду рассматривать только нечётный случай.
Если мы посмотрим на формулу для нечётного случая, то увидим, что она не является стандартным биномиальным распределением, но близка к нему. Если мы начнём со стандартного распределения, то можем превратить его в наше распределение, отбросив значения для нечётных
. Поскольку наше распределение для
и стандартным отклонением
(по крайней мере, когда
Поскольку нормальное и биномиальное распределение являются хорошими аппроксимациями друг друга, то это нормальное распределение для, а вероятность
; но это всего лишь аппроксимация аппроксимации правильного распределения, и я не считаю, что эти
Третье: у меня был план подхода к решению итерированной задачи. План реализовать не удалось, но по пути я собрал некоторые интригующие (и потенциально полезные) данные, которыми хочу поделиться.
Мой план заключался в том, чтобы взять результаты одной итерации и по отдельности записать количество кур-одиночек и пар кур. Затем я хотел аппроксимировать их отдельными нормальными распределениями, умножить среднее значение и стандартное отклонение распределения пар кур на 1/3 и сложить результат с распределением кур-одиночек. (Воспользовавшись (неправильно, как оказалось) результатом, по которому можно складывать нормальные распределения, складывая их средние значения и дисперсии.) Я надеялся, что это даст мне правильное среднее значение и стандартное отклонение экспериментального итерированного распределения.
Я решил начать с точных результатов, изучив все возможные результаты для небольшого количества кур; для
Вторым сюрпризом стало то, что все эти средние значения и дисперсии оказались точными числами довольно простого вида. Для. (Не очень удивительно, что это асимптотически правильные числа, но меня немного удивило, что что они точно правильны.) А для
, дисперсия кур-одиночек равна
, а для пар кур —
. (Результаты проверены до
, после чего я устал ждать выполнения моего медленного проверочного кода.)
Я не очень много знаю о статистике или вероятностях, чтобы продолжать, поэтому на этом я сдаюсь (по крайней мере, пока).












