Структура образов разделов, содержащих файловую систему. Часть 2.
Начало публикации читайте в Часть 1.
Оглавление
Продолжение следует…
5.Заключение.
6.Источники информации.
Часть 2
3.2._sparsechunk-файлы.
3.2.1.Структура _sparsechunk-файлов.
3.2.2.Примеры работы с _sparsechunk-файлами.
4.Создание dat-файлов.
4.1.Структура dat-файлов.
4.1.1.Структура transfer_list-файла.
4.1.2.Структура new_data-файла.
4.1.3.Структура patch_data-файла.
4.2.Описание структур данных.
4.2.1.Структура описания диапазона инфо-блоков (набор диапазонов [rangeset])
4.2.2.Структура stash-диапазона (stash_rangeset)
4.2.3.Структура набора входных данных <...>
4.3.Структура и описание команд transfer_list-файла.
4.3.1.Команды «erase», «new», «zero»
4.3.2.Команда «move»
4.3.3.Команды «bsdiff» и «imgdiff»
4.3.4.Команда «stash»
4.3.5.Команда «free»
3.2.1.Структура _sparsechunk-файлов.
3.2.2.Примеры работы с _sparsechunk-файлами.
4.Создание dat-файлов.
4.1.Структура dat-файлов.
4.1.1.Структура transfer_list-файла.
4.1.2.Структура new_data-файла.
4.1.3.Структура patch_data-файла.
4.2.Описание структур данных.
4.2.1.Структура описания диапазона инфо-блоков (набор диапазонов [rangeset])
4.2.2.Структура stash-диапазона (stash_rangeset)
4.2.3.Структура набора входных данных <...>
4.3.Структура и описание команд transfer_list-файла.
4.3.1.Команды «erase», «new», «zero»
4.3.2.Команда «move»
4.3.3.Команды «bsdiff» и «imgdiff»
4.3.4.Команда «stash»
4.3.5.Команда «free»
Продолжение следует…
Часть 3
4.4.Примеры работы с dat-файлами.
5.Заключение.
6.Источники информации.
3.2._sparsechunk-файлы
Т.к. sparse-файл, хоть и представляет собой сжатый исходный файл данных, тоже может иметь достаточно большой размер, то появилась его модификация, получившая название файлов типа _sparsechunk, которая представляет собой тот же sparse-файл, но разрезанный на части меньшего размера на основе заранее выбранной границы (по алгоритму разрезания файлов).
Это дополнение позволяет использовать сжатые sparse-файлы для передачи обновлений по ОТА или загрузке в режиме fastboot.
3.2.1.Структура _sparsechunk-файлов
По структуре каждый файл типа _sparsechunk представляет собой обычный sparse-файл, но содержащий не весь, а только часть входного файла, например, образа раздела. Размер этой части в сжатом состоянии, т.е. в sparse-виде, не должен превышать заранее заданного значения или границы. В настоящее время «граница» размера _sparsechunk-файла, составляет, как правило, 256Мб (268 435 456 байт).
Следующая часть sparse-файла содержится в следующем _sparsechunk-файле и т.д.
Внешне эти файлы различаются индексом в названии, который и определяет последовательность их обработки при декодировании. Индекс может быть просто порядковым числительным или может быть представлен как смещение во входном файле до куска.
Т.о. сначала образ раздела кодируется в sparse-файл, а затем уже преобразовывается (разрезается) в набор _sparsechunk-файлов.
Процесс создания _sparsechunk-файла можно описать следующим алгоритмом:
- просматривается готовый sparse-файл и все последовательно расположенные куски (chunks) типов Raw и Fill собираются в группу, называемую «данные», длина которой постоянно контролируется. Процедура выполняется до тех пор, пока размер группы не достигнет границы, значение которой указывается заранее и определяется требованиями, перечисленными выше при описании процесса разбиения файлов;
- Если присоединение следующего куска приведет к превышению границы, то он не включается в группу, а из уже сгруппированных кусков формируется отдельный файл, к которому дописывается кусок типа DontCare, называемый «завершающий», в котором в поле Chunk_Size указывается смещение данных до конца выходного файла. Этот файл получает название _sparsechunk.1;
- продолжается просмотр sparse-файла по методике пп.1-2 и формируется следующий _sparsechunk-файл, только перед его формированием к группе sparse-кусков спереди добавляется sparse-кусок типа DontCare, называемый «начальный», в котором в поле Chunk_Size указывается смещение данных, содержащихся в этом файле, от начала исходного образа. В конец дописывается «завершающий» кусок, сформированный по вышеописанному алгоритму;
- Так продолжается, пока не будет достигнут конец sparse-файла.
Таким образом, каждый _sparsechunk-файл может состоять из трех частей, которые я назвал:
- OFFSET_TO_START — содержит «начальный» кусок;
- INFO — часть, содержащая «данные»;
- OFFSET_TO_END — содержит «завершающий» кусок.
Часть OFFSET_TO_START представляет собой смещение во входном файле до начала части «данные», содержащей информацию в sparse виде.
Часть INFO содержит только информацию в sparse виде, состоящую из sparse-кусков типа Fill и Raw.
Часть OFFSET_TO_END представляет собой смещение до конца выходного файла. Если смещение равно нулю, т.е. рассматриваемый _sparsechunk-файл, содержащий инфо-группу, является последним в наборе _sparsechunk-файлов, то часть OFFSET_TO_END вообще отсутствует.
3.2.2.Работа с _sparsechunk-файлами
В качестве примера работы с _sparsechunk-файлами давайте рассмотрим конвертацию _sparsechunk-файлов в sparse-файл и обратно на примере набора файлов system.img_sparsechunk.0 — system.img_sparsechunk.4 прошивки от Moto X [5].
3.2.2.1.Преобразование списка _sparsechunk-файлов в один файл
Выше я показал, что при конвертации в _sparsechunk-файлы содержимое исходного sparse-файла просто делится на инфо-части, которые, при необходимости, оборачиваются дополнительными кусками. Соответственно, для восстановления исходного sparse-файла нужно от каждого _sparsechunk-файла отбросить куски-обертки, при их наличии, и просто сложить вместе все инфо-части, подсчитав общее число sparse-кусков.
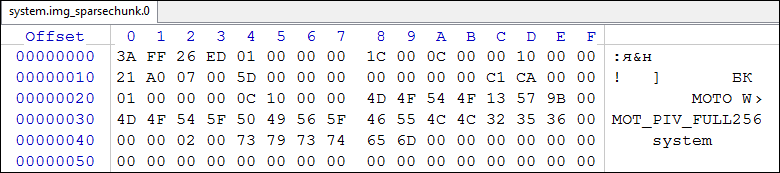
- Откроем system.img_sparsechunk.0 в hex-редакторе:
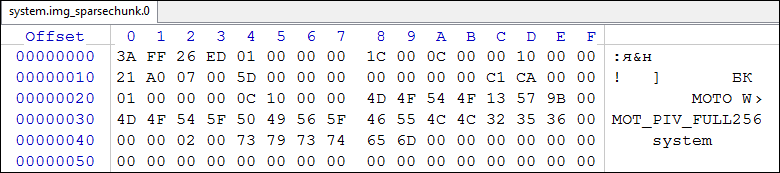
Рис.8. sparsechunk_0
Видно, что с адреса 0х0000 по адрес 0х001B расположен заголовок sparse-файла. Далее, с адреса 0х001С следует инфо-группа, начинающаяся с куска типа 0xCAC1, имеющего длину области данных вместе с заголовком 0х100С (адрес 0х0024). Следовательно, следующий кусок будет расположен, начиная с адреса:
0х001С + 0х100С = 0х1028
Посмотрим, что расположено по этому адресу:

Рис.9. Кусок2
По адресу 0х1028 расположен кусок типа 0xCAC2, имеющий длину 0х0010 (адрес 0х1030). Далее (адрес 0х1038) опять кусок типа 0xCAC1, и т.д.
Последний кусок этого файла расположен по адресу 0х0FFFF524 и имеет тип 0xCAC3, т.е. это кусок типа OFFSET_TO_END, имеющий размер 0х067AD4. Удалим его за ненадобностью:

Рис.10. Первый _sparsechunk_конец
Итак, от первого _sparsechunk-файла мы оставили только заголовок sparse-файла и «данные». Запомним также число кусков, находящихся в «данных» — 0x005D (см. поле по адресу 0х0014), но это вместе с куском типа OFFSET_TO_END, поэтому фактически нам «досталось» только
0x005D - 0х0001 = 0х005С
- Откроем в hex-редакторе следующий _sparsechunk-файл — system.img_sparsechunk.1:

Рис.11а.Начало второго куска

Рис.11б.Конец второго куска
Копируем содержимое, отбросив заголовок, начальный и последний куски типа 0xCAC3, т.е., начиная с адреса 0х0028 до адреса 0хFBFC46C, и добавляем его в конец предыдущей части на место удаленного последнего куска типа 0xCAC3 (адрес 0xFFFF524). Должна получиться вот такая картина:

Рис.12. Сложение двух частей
Т.е. у нас получился такой «пирог»:
- заголовок sparse-файла;
- «данные» первого _sparsechunk-файла;
- «данные» второго _sparsechunk-файла.

Рис.13. Конец сложенного файла
Не забудьте просуммировать общее число кусков, т.е. добавить число кусков, находящихся в добавленных «данных»
0x005С + (0x0050 - 0х0002) = 0x00AА
- Продолжим выполнять действия п.2 для всех оставшихся _sparsechunk-файлов кроме последнего. После обработки каждого нового файла наш «пирог» будет расти за счет дополнения самих «данных»:

Рис.14. Добавление второго файла
И продолжаем суммировать число кусков... - Добавим к «пирогу» последний _sparsechunk-файл, выполнив действия п.2, отбросив от него только заголовок и начальный кусок типа 0xCAC3. Вот что у нас получилось:

Рис.15. Результат
Размер этого файла составляет 0x4173FBD4 (1098120148 или примерно 1047МБ), а общее число кусков — 0x01FB (507), запишем его по адресу 0x0014 (поле число кусков заголовка Total_Chunks). 8 кусков, которые мы отняли из общего числа, это куски типа 0xCAC3: 1 завершающий кусок от части 0 _sparsechunk-файла, по 2 куска от частей 1-3 и 1 кусок от последней (четвертой) части.
Рис.16. Запись суммарного числа кусков во всех _sparsechunk-файлах
При необходимости, в поле Image_Checksum (адрес 0x0018) заголовка внесем контрольную сумму, рассчитанную по алгоритму Crc32 для всего файла, т.е. заголовок + все куски. Обычно это поле не заполняется и остается равным нулю. - Сохраним результирующий sparse-файл под именем, например, system.sparse.








Все, сборка sparse-файла из кусков завершена.
3.2.2.2.Преобразование sparse-файла в набор _sparsechunk-файлов или разрезание (разделение) на части (chunks)
Попробуем теперь разрезать созданный sparse-файл на _sparsechunk-файлы. В качестве значения границы примем 256МБ (0х10000000).
- Откроем файл system.sparse, в котором и будем производить все нижеописываемые действия, в hex-редакторе:
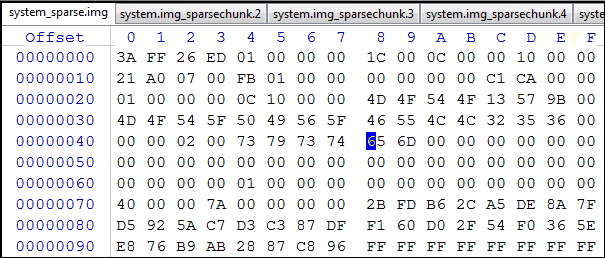
Рис.17. system.sparse-файл
и разделим его на отдельные _sparsechunk-части, содержащие только «данные». - Создадим первый _sparsechunk-файл. Для этого перейдем на смещение 0х10000000 от текущей позиции маркера (для первого файла это 0х0000), т.е. станем на максимальный размер будущего _sparsechunk-файла. Для первого файла это будет адрес 0х10000000:

Рис.18. Граница _sparsechunk-файла
и начнем искать в меньшую сторону начало куска любого типа, т.е. коды 0xCAC1 или 0xCAC2. Ближайший кусок типа 0xCAC1 расположен по адресу 0xFFFF524:

Рис.19. Граница раздела _sparsechunk-файлов
Чтобы убедиться, что мы нашли самый последний кусок, который «влазит» в размеры «границы», добавим к найденному смещению размер этого куска + размер заголовка, чтобы найти начало следующего куска:
0xFFFF524 + 0x41D2000 + 0x000C = 0x141D1530
Т.к. смещение следующего куска переходит «границу», то мы нашли точку раздела _sparsechunk-файлов. Сохраняем код system.sparse-файла от 0x00000000 до 0xFFFF524 в файл, например, system_new_sparsechunk_0.img. - Повторим действия п.2, приняв за текущую позицию маркера начало последнего, найденного на предыдущем шаге, куска, т.е. 0xFFFF524. Шагнем на смещение 0х10000000 от текущей позиции:

Рис.20. Граница второго файла
Получаем максимальное значение, т.е. адрес начала следующей _sparsechunk-части 0x1FFFF524. Найдем ближайший кусок в меньшую сторону, т.е. предполагаемую границу раздела частей _sparsechunk-файлов:

Рис.21. Вторая граница раздела _sparsechunk-файлов
Проверим, правильно ли мы нашли последний кусок, т.е. определяем смещение до следующего куска:
0x1FBFB968 + 0x01897000 + 0x000C = 0x21492968
Т.к. смещение переходит предполагаемое смещение начала следующей части, то мы правильно нашли точку раздела _sparsechunk-частей. Сохраняем следующий код system.sparse-файла от 0xFFFF524 до 0x1FBFB968 в файл, например, system_new_sparsechunk_1.img. - Повторим действия п.3 до конца system.sparse-файла. В результате, мы получили набор следующих файлов:
=========================================================================== | № | Имя | Размер | Смещение | Число | | п/п | файла | МБ | начало | окончание | кусков | |=====|===================|========|============|============|==============| | 1 | new_sparsechunk_0 | 256 | 0x00000000 | 0x0FFFF523 | 0x005C ( 92) | | 2 | new_sparsechunk_1 | 252 | 0x0FFFF524 | 0x1FBFB967 | 0x004E ( 78) | | 3 | new_sparsechunk_2 | 242 | 0x1FBFB968 | 0x2EE61403 | 0x00C2 (194) | | 4 | new_sparsechunk_3 | 235 | 0x2EE61404 | 0x3D92DA5B | 0x0074 (116) | | 5 | new_sparsechunk_4 | 62 | 0x3D92DA5C | 0x4173FBD3 | 0x001B ( 27) | |============================================================|==============| | Итого: | 0x01FB (507) | =========================================================================== - Создадим в каждой _sparsechunk-части, кроме первой, т.к. он там присутствовал сразу, заголовок sparse-файла. Для этого скопируем заголовок из system.sparse и вставим в каждую часть в начало файла. Используя данные предыдущей таблицы, заносим значение из колонки "Число кусков" в поле Total_Chunks по адресу 0x0014 каждого файла.




Все, процесс разрезания на _sparsechunk-части завершен.
P.S. Все эти «ужасы» с переходами по смещению, поиском нужных кусков, расчетом размеров файлов и т.д. я описал только для того, чтобы показать разработчику МУ процедуру, необходимую для выполнения работ по обработке sparse — и _sparsechunk-файлов. Я сам это никогда не делаю, т.к. существуют компьютеры… и приложения, написанные мной.
Желающие, изучив вышеприведенные материалы, могут и сами создать приложения на свой вкус и цвет.
4.Создание dat-файлов
Dat-файл представляет собой следующую ступень сжатия образов разделов. В отличие от sparse-файла он содержит только информационные части. А для обеспечения сборки исходного файла создается файл, называемый transfer_list.
При этом исходный файл делится на части, содержащие полезную информацию, т.е. инфо-блоки, и «пустые» блоки, т.е. содержащие нули. Затем все части с информацией копируются подряд в выходной файл, называемый new_data, а информация об их размещении в исходном файле и размер этих частей заносится в файл transfer_list.
Таким образом, конечный файл с информацией (new_data) не содержит блоков с нулями, т.е. «сжимается», становясь гораздо меньше по размеру, чем исходный.
Возможности такого преобразования данных и, соответственно, формат файла transfer_list со временем претерпели некоторые изменения. Существует несколько версий этого файла.
Первоначально файл new_data содержал все инфо-блоки, а в transfer_list заносилась информация, необходимая только для «разжатия», т.е. для восстановления полного исходного файла. Это была версия 1, которая используется для сжатия файлов в ОС Android, начиная с версии 5.0.0.
Затем, кроме простого сжатия, в функции dat и transfer_list-файлов добавилась возможность создавать файлы-патчи для замены только некоторых частей исходного файла, например, патч для recovery, так появилась версия 2, используемая в ОС Android, начиная с версии 5.1.0. Это привело к еще большему сжатию исходных образов, т.к. в патче передаются вообще только изменения.
В ОС Android 6.0 сильно изменился подход к системе безопасности, повсеместно используется шифрование, соответственно на свет появилась версия 3 файла transfer_list, позволяющая выполнять дешифрование на лету при помощи stash-команд.
4.1.Структура dat-файлов
Образ файла RAW-формата (.img) после преобразования в dat-файлы (.dat) представляет собой набор из следующих файлов:
- transfer_list-файл. Этот файл содержит описание размещения информационных частей и команды для их восстановления и верификации;
- new_data-файл. Он содержит только информационные части исходного файла, которые располагаются в нем непрерывно, т.е. без зазоров или выравниваний;
- patch_data-файл. Этот файл содержит только части, заменяющие информационные части исходного файла, которые располагаются в нем непрерывно, т.е. без зазоров или выравниваний.
В зависимости от типа преобразования, выполненного над исходным файлом RAW-формата, состав набора файлов может изменяется, но transfer_list-файл должен присутствовать всегда, тогда как new_data-файл и patch_data-файл могут быть как вместе, так и поодиночке.
Если преобразование состояло в простом удалении «пустых» блоков, то в набор помимо transfer_list-файла включается только new_data-файл, например, [7].
Если преобразование состояло в применении patch, т.е. замене части блоков на другие, то в наборе будет присутствовать только patch_data-файл, например, [8].
Если преобразование состояло как из удаления «пустых» блоков, так и в применении patch, т.е. замене части блоков на другие, то в наборе будут присутствовать как new_data-файл, так и patch_data-файл, например, [6].
Рассмотрим строение каждого из dat-файлов подробнее и начнем с transfer_list-файла, используемого всегда, т.к. именно он описывает преобразования, выполненные над исходным файлом и, соответственно, действия, которые необходимо выполнить для «получения» исходного файла. Я не сказал «восстановления», т.к. строго говоря, исходный файл, подвергшийся преобразованию, может не совпадать с конечным, полученным после обработки. Это может происходить, например, после применения патча, т.е. внесения изменений в исходный файл.
4.1.1.Структура transfer_list-файла
Файл transfer_list представляет собой набор строк количеством более 4, каждая строка описывает одно поле данных, и имеет следующее строение:
====================================================
| № | | |
| п/п | Название поля | Назначение поля |
| | | |
|=====|=================|============================|
| 1 | Version | Версия файла |
| 2 | Size New Data | Число блоков файла new_dat |
| 3 | Stash Entries | Число входов stash-таблицы |
| 4 | Stash Max Block | Макс.число stash-блоков |
| 5 | Commands | Список исполняемых команд |
====================================================
Поле-строка Version описывает версию файла transfer_list и может принимать значения от 1 до 3. Версии файлов различаются возможностями, что сказывается на числе строк самого файла. Версия 1 используется для файлов, созданных для Android версии не выше 5.0. Версия 2 используется, начиная с Android 5.1.0. Версия 3 используется, начиная с Android 6.0.1.
Версия 1 не содержит значения, описанные строками 3 и 4, но должна содержать не менее 2 команд. Поэтому длина transfer_list-файла составляет не менее 4 строк:
- Version;
- Size New Data;
- Command 1;
- Command 2.
Версии 2 и 3 уже могут выполнять stash-команды, поэтому transfer_list-файл будет содержать, как минимум, 6 строк:
- Version;
- Size New Data;
- Stash Entries;
- Stash Max Block;
- Command 1;
- Command 2.
Поле-строка Size New Data описывает размер в блоках выходного файла new_dat, содержащего только инфо-блоки, т.е. число блоков перемещаемых данных. По-умолчанию размер блока равен 4096 байт.
Поле-строка Stash Entries описывает число входов stash-таблицы, содержащей набор смещений до частей исходного файла одновременно используемых при команде stash.
Поле-строка Stash Max Block описывает максимальный размер такой stash-части исходного файла.
Поле-строка Command содержит команду, которую необходимо выполнить для получения конечного файла.
Вот пример transfer_list-файла версии 1:
1
140333
erase 2,0,190108
new 236,0,56,57,164,517,523,3717,21738,21739,32767,32768,32770,32825,32826,33285...
где в первой строке указана версия файла (1), во второй размер перемещаемых данных, т.е. размер файла new.dat в блоках (140333). Третья и четвертая строки содержат команды (erase и new). Эти строки приведены урезанными, т.к. имеют слишком большую длину.
А вот как выглядит transfer_list-файл версии 2:
2
317984
129
24931
move 2,117767,117787 20 2,128537,128557
move 2,113788,117574 3786 2,124558,128344
imgdiff 0 2187 2,117631,117633 2 2,128401,128403
imgdiff 2187 2210 2,117788,117902 114 2,128558,128672
move 2,117903,121984 4081 2,164515,168596
move 2,117609,117630 21 2,128379,128400
imgdiff 4397 2229 2,117575,117602 27 2,128345,128372
imgdiff 6626 16212 2,117636,117759 123 2,128406,128529
imgdiff 22838 2170 2,117760,117766 6 2,128530,128536
imgdiff 25008 2198 2,117603,117608 5 2,128373,128378
move 2,125336,125341 5 2,129329,129334
...
move 2,383166,383179 13 2,392851,392864
move 2,383475,383496 21 2,393160,393181
erase 70,32770,32929,32931,33443,65535,65536,65538,66050,98303,98304,98306,98465,98467,98979,131071,131072,131074,131586,163839,163840,163842...,589826,622592,622594,655360
где в первой строке опять номер версии, во второй размер перемещаемых данных. 3 и 4 строки равны 0, т.е. stash-таблица не используется. В строках с 5 и по последнюю расположены команды erase, move и imgdiff. Некоторые строки урезаны, т.к. имеют слишком большую длину.
Перейдем к рассмотрению строения new_data-файла.
4.1.2.Структура new_data-файла
Этот файл содержит только инфо-блоки кода исходного img-файла, взятые из него во время выполнения обработки. Они располагаются строго по-порядку, без промежутков и используются в качестве источника данных для команды new.
Давайте рассмотрим строение new_data-файла на конкретном примере. ОТА-прошивка МУ А7010а40 [6] имеет в своем составе файлы system.new.dat и system.transfer.list.
В последнем файле команда new встречается три раза, в строках 1901, 1945 и 1946. Т.к. выполнение команд осуществляется строго последовательно, то выполнение нервой команды new в строке 1901
new 2,226365,226468приведет к чтению из new_dat-файла первых 103 блоков, начиная с текущего положения указателя чтения, т.е. с 0, и записи в выходной файл 103 блоков в диапазон [226365,226468]. При этом указатель чтения источника будет перемещен на адрес 103. Выполнение следующей команды в строке 1945
new 2,294901,294902приведет к чтению из new_dat-файла следующего 1 блока, начиная с текущего положения указателя чтения, т.е. с 103, и записи в выходной файл 1 блока в диапазон [294901,294902]. При этом указатель чтения источника будет перемещен на адрес 104. Выполнение следующей команды в строке 1946
new 2,294902,294903приведет к чтению из new_dat-файла следующего 1 блока, начиная с текущего положения указателя чтения, т.е. с 104, и записи в выходной файл 1 блока в диапазон [294902,294903]. При этом указатель чтения источника будет перемещен на адрес 105.
Таким образом, new_dat-файл должен содержать 105 блоков джанных, соответственно его длина должна составлять 105 * 4096 = 430080, что и есть в действительности.
Перейдем теперь к рассмотрению строения patch_data-файла.
4.1.3.Структура patch_data-файла
Все данные патча объединены в один patch_data-файл в пакете обновления. Данные этого файла являются источником для команд bsdiff и imgdiff.
4.2.Описание структур данных
Все структуры описывают диапазоны данных, при этом за единицу данных принято значение блока, т.е. 4096 байт. Существуют следующие структуры описания данных:
- набор диапазонов [rangeset]
- набор диапазонов slash [stash_rangese]
- набор входных данных <...>
Рассмотрим их строение по-очередно.
4.2.1.Структура описания диапазона инфо-блоков (набор диапазонов [rangeset])
Набор диапазонов [rangeset] используется в командах transfer_list-файла для описания диапазонов инфо-блоков как источника, так и приемника данных. Также используется в команде stash для описания диапазонов stash-области сохранения.
Простой диапазон данных описывается двумя значениями: указателем на первый и последний элемент диапазона, например, [23,56). При этом левая граница включена в диапазон, а правая нет. Если диапазонов несколько, то для их описания требуется набор диапазонов, содержащий еще один элемент — число диапазонов в наборе.
Описание набора диапазонов независимо от версии transfer_list-файла имеет следующее строение:
[count,posStart1,posEnd1,posStart2,posEnd2,...] ,где
- count — число смещений в наборе диапазонов, т.е. чисел в строке набора диапазонов без первого. Количество диапазонов инфо-блоков равно половине этого значения, т.к. каждый диапазон описывается парой значений: начало и конец диапазона;
- posStart1 — смещение начала первого диапазона инфо-блоков в конечном файле, в блоках;
- posEnd1 — смещение последнего блока первого диапазона инфо-блоков в конечном файле в блоках;
- posStart2 — смещение начала второго диапазона инфо-блоков в конечном файле в блоках;
- posEnd2 — смещение последнего блока второго диапазона инфо-блоков в конечном файле в блоках.
Как видно, набор содержит перечисление диапазонов данных, каждое состоит из границы начала перечисления и границы конца. Причем правая граница не входит в перечисление. Длина диапазона рассчитывается следующим образом: длина = конец — начало.
Например, из приведенного выше примера transfer_list-файла, посмотрим, как описаны наборы диапазонов в команде move:
move 2,117767,117787 20 2,128537,128557Здесь указаны два набора диапазонов:
- диапазон-источник: 2,117767,117787. Означает, что в диапазоне содержится два смещения, т.е. строка содержит два числа смещений — 117767 и 117787, описывающие один диапазон данных. Соответственно, count = 2. Далее расположено смещение начала диапазона (posStart = 117767) и следом размещено смещение окончания диапазона (posEnd = 117787). Соответственно, диапазон содержит 117787 — 117767 = 20 элементов, т.е. его длина 20;
- диапазон-приемник: 2,128537,128557. Аналогично для целевого диапазона: count = 2, posStart = 128537, posEnd = 128557, длина — 20 элементов.
То, что оба диапазона содержат одинаковое число элементов, является атрибутом операции move (перемещения), т.е. 20 элементов источника будут перемещены в 20 элементов приемника.
4.2.2.Структура stash-диапазона (stash_rangeset)
stash-диапазон это набор инфо-блоков, предназначенный для хранения элементов данных в строго определенном месте, т.е. этот диапазон имеет не только набор элементов (от какого смещения и до какого), но и имя или указатель хранилища.
Набор инфо-блоков stash-диапазона имеет следующее строение:
number:[range_set],где
- number — идентификационный номер stash-хранилища, десятичное число;
- [range_set] — набор диапазонов данных.
Например, командная строка имеет следующий вид:
stash 10 2,298306,298307означает, что создан один (2/2) диапазон данных, начиная со смещения 298306 до смещения 298307 (не включая его), т.е. размером в один элемент (298307-298306=1), и помечен как stash-хранилище с идентификационным номером 10.
Другой пример:
stash 11 2,295927,295960означает, что создан один (2/2) диапазон данных, начиная со смещения 295927 до смещения 295960 (не включая его), т.е. размером в 33 элемента (295960-295927=33), и помечен как stash-хранилище с идентификационным номером 11.
Еще один пример:
stash 8 6,247114,247116,247150,247155,247156,247156означает, что 3 (6/2) диапазона данных:
1) начиная со смещения 247114 до смещения 247116 (не включая его), т.е. размером в 2 элемента (247116-247114=2);
2) начиная со смещения 247150 до смещения 247155 (не включая его), т.е. размером в 5 элементов (247155-247150=5);
3) начиная со смещения 247156 до смещения 247156 (не включая его), т.е. размером в 0 элементов (247156-247156=0), объединены и помечены вместе как stash-хранилище с идентификационным номером 8.
4.2.3.Структура набора входных данных <...>
Для версии 1 этот набор выглядит так:
[src_rangeset] [tgt_rangeset],где
- [src rangeset] — набор диапазонов инфо-блоков исходного файла (new_dat или patch_dat), т.е. источника данных;
- [tgt rangeset] — набор диапазонов инфо-блоков выходного файла (*.img), т.е. приемника данных.
Для версии 2 и 3 этот набор может быть следующих видов:
- [tgt_rangeset] <src_block_count> [src_rangeset];
- [tgt_rangeset] <src_block_count> [stash_rangeset];
- [tgt_rangeset] <src_range> <src_loc> [stash_rangeset];
где
- [tgt rangeset] — набор диапазонов инфо-блоков выходного файла (*.img), т.е. приемника;
- [src rangeset] — набор диапазонов инфо-блоков исходного файла, т.е. источника;
- [stash_rangeset] — набор диапазонов инфо-блоков stash-команды;
- <src_block_count> — число инфо-блоков в диапазоне источника и приемника;
- <src_range> — число stash-диапазонов;
- <src_loc> — .
4.3.Структура и описание команд transfer_list-файла
В transfer_list-файле используются следующие команды:
- bsdiff, imgdiff — применить патч.;
- erase — отметить указанные области как пустые;
- free — очистить stash-области. Имеется в версии, начиная с 2;
- new — заполнить информацией из new_data-файла указанные области выходного файла;
- move — переместить инфо-блоки в указанных областях;
- stash — выполнить перемещение указанных областей с предварительной обработкой. Имеется в версии, начиная с 2;
- zero — заполнить нулями указанные области файла.
4.3.1.Команды «erase», «new», «zero»
Эти команды имеют следующую структуру:
name [rangeset],где
- name — имя команды;
- [rangeset] — структура, описывающая набор диапазонов инфо-блоков.
Команда erase производит отметку пустых блоков, описанных структурой [rangeset]. Например, выполнение команды
erase 70,32770,32929,32931,33443,...из [7, transfer_list-файл, строка 2337] приведет к очистке 35 наборов блоков выходного файла с номерами [32770,32929], [32931,33443] и т.д.
Команда new производит запись инфо-блоков источника, т.е. new_dat-файла, в набор диапазонов, описанный структурой [rangeset], приемника, т.е. system.img-файла. Инфо-блоки из источника выбираются строго последовательно.
Например, в [7, transfer_list-файл] выполнение команды в строке 1901
new 2,226365,226468приведет к чтению из new_dat-файла, начиная с текущего положения указателя 103 блоков и записи в выходной файл в диапазон [226365,226468].
Команда zero очищает указанный набор диапазонов выходного файла, т.е. заполняет его нулями. Например, выполнение команды
zero 2,226365,226366приведет к очистке блока 226365 приемника.
4.3.2.Команда «move»
Эта команда производит простое копирование инфо-блоков из файла-источника, описанных структурой [src_rangeset], в существующий набор диапазонов выходного файла, описанный структурой [tgt_rangeset].
Команда move имеет следующее строение:
move <...>,где <...> — набор входных данных, который различается в зависимости от версии файла transfet_list.
Например, если команда имеет следующий вид:
move 2,117767,117787 20 2,128537,128557и это команда перемещения инфо-блоков (move), то здесь описаны два набора диапазонов:
- диапазон-источник: 2,117767,117787.
Означает, что в диапазоне содержится два смещения (count = 2), описывающие один диапазон данных. Далее расположено смещение начала диапазона (posStart = 117767) и следом размещено смещение окончания диапазона (posEnd = 117787); - диапазон-приемник: 2,128537,128557.
Аналогично для приемника: count = 2, posStart = 128537, posEnd = 128557.
4.3.3.Команды «bsdiff» и «imgdiff»
По этим командам читаются инфо-блоки исходного файла, выполняются обновления и измененные инфо-блоки записываются в выходной файл. Команды отличаются только типом преобразований, применяемых к инфо-блокам.
Обе команды имеют следующее строение:
name <patchstart> <patchlen> <...>,где
- name — имя команды;
- patchstart — смещение начала области patch в блоках;
- patchlen — длина области patch в блоках;
- <...> — набор входных данных.
4.3.4.Команда «stash»
Эта команда производит сохранение инфо-блоков в stash-область. Она имеет следующее строение:
stash <stash_id> <src_range>,где
- <stash_id> — идентификатор stash-диапазона;
- <src_range> — набор диапазонов инфо-блоков stash-области.
4.3.5.Команда «free»
Эта команда очищает stash-область. Она имеет следующее строение:
free <>,где
<...> — — набор входных данных.
Продолжение следует…
5.Заключение
Весь приведенный материал и примеры его использования представляет собой только «таблицу умножения», а не руководство к действию. Никто, конечно же, вручную не применяет патчи и не конвертирует system-файлы… Я просто описал принципы выполнения преобразований над «разреженными» файлами, к категории которых относятся, в основном, файлы, содержащие ФС.
Для обработки «разреженных» файлов используют, конечно же, компьютерные программы, которых уже большое количество. Если дойдут руки, то напишу обзор существующих средств конвертации.
Начиная писать публикацию, я хотел довести до пользователей только основы, так сказать, исключительно «теорию». Т.к. большая часть работ по «копанию» в исходных текстах и прошивках была выполнена мною еще в 2013-2014 годах, то в процессе работы мне пришлось существенно поработать: что-то вспоминать, что-то переосмыслить заново, да и основательно дополнить в связи с появлением новых версий Android. В следующей части я опишу примеры обработки «разреженных» файлов.
Материала получилось много, статью конечно же нужно было сразу разделить на две или три части для простоты усваивания да и подготовки. Но как вышло, так вышло. Это я про то, что не судите строго, я тоже чего-то могу не знать совсем, а чего-то не учесть… Если есть вопросы, предложения — милости просим.
6.Источники информации
1. Разрежённый_файл.
2. прошивка устройства Lenovo s90A
3. sparse_format.h
4. Lenovo Moto Z
5. Victara_Retail_China_XT1085_5.1_LPE23.32-53_CFC.xml.zip — Lenovo Moto X.
6. A7010a40_S111_150825_ROW_TO_A7010a40_S112_150901_ROW_WC15.zip.
7.
8. ОТА-обновление recovery.







