Комментарии 88
Рекомендую обратить внимание на проект The Graph (github, opensource), демо.
Он является частью целой системы для Flow Based программирования, , есть среда выполнения графов как минимум для nodeJS, и браузера. Можно взять только сам редактор графов, а выполняющее их ядро реализовать самостоятельно. Я например таким образом реализовал ETL загрузчик для OLAP системы.

И не дождавшись ответа (до сих пор), я в ту же ночь наплодил более 1000 строк кода на JavaScript, так все таки используется рафаэль? Или своя реализация отрисовки. В исходниках вижу что он подключен.
Как минимум, мы вытащили все значимые таблицы и колонки для пользователей с человеческими именами. С помощью системы типов облегчили JOINы. Для всех enum-like полей создали соответствующие компоненты. Пользователю не надо знать как в системы называются статусы вроде executed, он просто видит удобный выпадающий список.
Также мы очень активно пользуемся всеми навороченными фичами PostgreSQL, и в данном случае, очевидно, что работу с hstore/jsonb/array/CTE/хранимками лучше вытащить в визуальные компоненты. Например, такие SQL:
SELECT
o.delivery_service_external_order_id AS "ШПИ"
, (clm.details#>>'{status,sent_to_russian_post}')::DATE AS "Дата подачи претензии"
, clm.status AS status
FROM tbl_order AS o
INNER JOIN claim.tbl_claim_order AS co ON o.id = co.order_id
INNER JOIN claim.tbl_claim AS clm ON co.claim_id = clm.id
WHERE fn_get_param('minimal_faccept_date', ARRAY['CT#' || clm.customer_id])::DATE > '2017-03-01'::DATEвряд ли кто либо из не-технарей согласиться писать :)
Плюс бесплатно у нас появляется возможность явно выделить эти фильтры, и отдельно запускать каждый, чтобы в дальнейшем проводить аудит, по какой именно причине заказ по ним отсеялся или наоборот. А имея 200 строчный SQL со ста OR-ами или AND-им тяжело понять, что именно отработало, и надо много чего доделывать.
Вообще, SQL не самая сложная область, как я упоминал в статье, всё это дело было вдохновлено UE4 Blueprints, которые вообще в С++ код транслируются.
Ну и ещё раз хочу сказать, что сам инструмент не привязан никак конкретно к SQL — его можно использовать в любой области.
Сам проект хорош, обязательно попробую, если подойдёт — буду пользоваться.
Читать сложновато, всё в одном файле. Есть планы по переоформлению кодовой базы с использованием какой-нибудь системы сборки?
В статье написано что инструмент передан в общественное достояние, а в репо на github стоит лицензия MIT. Я не юрист, но на мой взгляд тут есть противоречие, и должно быть и в репо тогда public domain указано.
Я тоже не силён в лицензировании ПО, и сама тема не очень интересна, но при публикации проекта пришлось что-то всё таки поизучать. Сначала сразу захотелось повесить WTFPL, но бегло ознакомившись с содержимым https://habrahabr.ru/post/243091/, и посмотрев, что используют некоторые популярные open-source проекты — решил, что MIT вроде краткая и понятная, и без ругательных слов, и вроде позволяет делать с кодом что вам заблагорассудиться.
Есть планы по переоформлению кодовой базы с использованием какой-нибудь системы сборки?
Да, конечно. Как-то так вышло, что за пару-тройку дней файл разросся до 3к строчек, и мне не хотелось тратить запал на разбитие на файлы :) Плюс, я не front-end разработчик по специализации, и отстал от современных тенденций, поэтому, если посоветуете что-то конкретное — буду благодарен.
Ну, я бы предложил перейти на ES8 (или 7/6) чтобы использовать сахар новых версий, например через https://babeljs.io. Ну и, разбить код как-то, и научиться его собирать в обычную и минифицированную версию. Для сборки модулей берите наверное webpack, а если хотите просто компиляцию общего назначения — gulp.
Чуть не забыл: выберите и настройте линтер, например ESLint, JSLint или JSHint — это очень помогает. А ещё пишите тесты: это Mocha или Jasmine.
Насчёт общественного достояния понятно — по закону России нельзя вот так просто взять и перевести код в общественное достояние, а только по истечении времени (https://habrahabr.ru/post/243091/), отсюда не возникает противоречий и код лицензируется по MIT.
Всё что я хотел сказать, так это — пользуйтесь на здоровье :) Главное, что лицензия MIT позволяет всем это делать.
MIT позволяет линковку с кодом, использующим сторонние лицензии без копилефта. Как по мне практически идеальная лицензия для того чтобы использовать компоненты лицензированные ею в коммерческой разработке без каких-либо проблем.
А есть где-то примеры передачи кода в public domain? Просто насколько я знаю и лицензия MIT и лицензии Creative Commons так и остаются лицензиями, стараясь приблизиться к идее общественного достояния. Вроде как нигде в мире на данный момент нет возможности как-то иначе отчуждать свои права на произведение.
Как вариант форкнуть пока оно под MIT и пользовать как собственный продукт.
Автор остается автором всегда.
Есть сложные случаи типа работы по договору и т.п., но это дебри.
Соответственно все вариации свободных и копилефт лицензий описывают случаи интеллектуальной СОБСТВЕННОСТИ а не авторства. Это важный вопрос а не придирка.
Собственно наиболее широкие лицензии вроде MIT реально накладывают только ограничения на необходимость указывать авторство. ИМХО не велика проблема. Есть лицензии которые не требуют и этого.
Упомянутая СС0 предназначена для целей передачи в общественное достояние. Лучше процитирую:
CC0 — передача в общественное достояние от Creative Commons. Произведение, выпущенное по CC0, передано в общественное достояние в максимальной степени, разрешенной законом. Если это невозможно по любой причине, CC0 также предоставляет простую пермиссивную лицензию в качестве запасного варианта. И произведения в общественном достоянии, и простая лицензия, предоставляемая CC0, совместимы с GNU GPL. Если вы хотите передать ваше произведение в общественное достояние, мы рекомендуем вам использовать CC0.
Пермессивная лицензия это когда от тебя требуют только автора указывать. Вроде СС0 лучше, не требуется даже этого… вроде как больше свобод и все такое, но…
Вот не указываешь ты автора. А потом возникают вопросы правомочности использования этого кода. Придется доказывать всю цепочку. что код взял тут, что его давали под СС0, и т.п… Зачем?
Укажи автора и спи спокойно.
ИМХО MIT самая удобная. Единственное что — лично для себя я хочу к ней добавить один дополнительный пункт, что если кто-то присылает пулреквесты или другим образом отправляет свои патчи и доработки, то он автоматически (если не было обсуждено другое) отдает свои права правообладателю основного продукта. Чисто для простоты. Чтобы и код был свободен, и основной разработчик имел развязанные руки — кому не нравится сделает форк.
Я говорил не про авторское право, а про все права на произведение. С авторским правом как раз все просто и понятно — из всех ограничений оно разве что может заставлять указывать авторство.
CC0 для кода возможно создает сложности из-за того что каждая версия становится некоторым отдельным куском в общественном достоянии. Хотя конкретно этот момент было бы неплохо уточнить у кого-то более подкованного, чем я.
Оно, конечно, выглядит попроще.
Но дело делает.
VAX больше про работу с графом. И SQL здесь, возможно, даже сбивающий пример :)
На простых примерах выглядит вдохновляюще, но как посмотришь на сложные схемы — уж лучше какой-то текстовый формат...
Я думаю, этот инструмент нужен именно в коммуникации между обычными пользователями (для нас это бизнес) и разработчиками.
Сейчас медленно пытаюсь довести свой фреймворк до вида когда можно показывать.
У меня похожая концепция ориентированная на визуальное редактирование, но пока без визуального редактирования.
У меня в ORM есть понятие «правило».
У модели (активрекорд) есть набор полей у каждого набор правил.
Также есть правила которые влияют на бокс (что-то вроде репозитория, в простейшем случае таблица или папка/файл где лежат все однотипные модели).
Хранится сие в JSON. Например так:
{
"#default": {
"#class" : "app\\prototype\\Model",
"scenarios": {
"default": {
},
"list": {
"id": "default"
},
"view": {
"id": "default"
},
"search": {
}
},
"box":{
"#class" : "app\\prototype\\Box",
"limit": 20
}
},
"registry" : {
"scenarios": {
"default": {
"id": ["string"],
"type": ["modelType","boxType&value=registry"],
"created": ["int","ordered","timeCreate","timestamp"],
"updated": ["int","ordered","timeUpdate","timestamp"],
"updateHistory":["updateHistory"]
},
"list": {
"id": "default",
"type":"default"
},
"advancedInfo": {
"id": "default",
"created": "default",
"updated": "default"
}
},
"box":{
"#class": "\\drycore\\orm\\box\\FolderBox",
"runtimeFolder":"registry"
}
},
"dbConfig": {
"#parent": "registry",
"scenarios": {
"default": {
"host": ["string","default&value=localhost","block&name=default"],
"dbname": ["string","block&name=default"],
"user": ["string","block&name=default"],
"password": ["string","block&name=default"],
"updateHistory":null
}
}
},
"user":{
"#parent":"drycart/site/#user",
"box":{
"#class": "\\drycore\\core\\user\\UserBox"
}
},
"#sitePage": {
"#parent": "drycart/cms/#sitePage",
"box":{
"where": [{"0": "`type` != :type","type": "adminPage"}]
}
},
}
Я знаю что правило updateHistory создает связь на одноименную таблицу, и при сохранении модельки сохраняет историю ее изменений. Знаю что timeCreate это таймштамп создания, timestamp это правило наследующееся от целого и основное назначение которого выводить в админке контрол времени, а при выводе красивую дату (или время еслидата недавняя), block&name влияет на то в каком табе выводить данное поле если мы отображаем форму для модели… я знаю все 130 правил. Ведь я же сам их писал.
Но если честно, то а) частенько путаюсь какое как называется и какой синтаксис параметров (у блока параметр нейм или блок?). Нужно открывать документацию или пример. Чтобы отследить наследование надо листать несколько файлов (или компилированный конфиг). А уж взаимодействия полсотни моделек так вообще нереально увидеть в тексте.
Многие доработки я откладываю до того времени когда у меня дойдут руки сделать визуальный редактор.
Уже не могу без него. Я и в тему зашел в надежде что будет просто это утащить себе. Но похоже не судьба. Оно будет удобно для языка запросов. У 1С очень приятный конструктор запросов, думаю с этим можно сделать что-то похожее.
Я и в тему зашел в надежде что будет просто это утащить себе. Но похоже не судьба.
Почему не судьба?
Пока вижу только применение к построению запросов (но писать много надо), к дереву наследования (правда тоже надо будет свои контролы сюда пристраивать), но все это пока не совсем то.
Появилась идея сделать на базе Вашего редактора графов конструктор для правил, чтобы можно было делать цепочки действий и т.п. но сыро. В общем статья интересная, но дальше…
Ну мне больше интересно добавление/редактирование полей, чем связи.
Почти что угодно можно представить в виде связи:
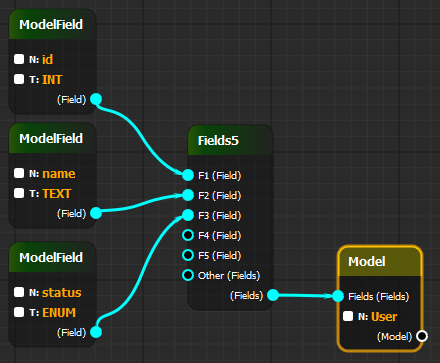
Появилась идея сделать на базе Вашего редактора графов конструктор для правил, чтобы можно было делать цепочки действий и т.п. но сыро.
Подскажите, пожалуйста, что именно сыро?
В общем статья интересная, но дальше…
Не пойму, о чём вы говорите. Поясните, пожалуйста.
Мне скорее нужен инструмент по написанию своей грамматики а не по написанию с помощью уже готовой грамматики. А для готовой грамматики да, прикольно выглядит.
Вот типичный юзкейс:
Мы хотим на сайте сделать опрос клиентов.
Для этого нужно вывести форму с каким-то набором полей и неким стандартным поведением. Допустим у нас уже есть абстрактная модель #опрос
Админу нужно отнаследоваться от нее (тут просто — мы или из списка выбираем родителя или он фиксированный) и добавить к ней полей.
Допустим моделька уже умеет разбираться с дополнительными полями. Или сериализирует в жсон, или EAV использует, не суть.
Нам нужно дать пользователю красивенько добавить поля. Есть кнопка добавления полей, есть кнопочки добавления правил к этим полям. Допустим это будет опрос «ваш любимый мультик».
Мы хотим добавить поле «Ваш любимый мультик». К этому полю мы добавим правило «связь с таблицей Мультики, поле связи — id_мультика». К нему мы добавим правило «выбор из выпадающего списка», и еще правило «если вариант не выбран, то по умолчанию — Щенячий патруль».
Потом мы добавляем поле «Ваш возраст». К нему добавляем правило «целое», к нему добавляем «минимум 5», и правило «максимум 80». Также добавляем правило «если не заполнено, то по умолчанию берем возраст из такого-то поля текущего пользователя».
Ну и раз уж инструмент универсальный то у нас должны быть видны поля из родителя, например связь по ИД текущего пользователя, время создания, айпи опрошенного и т.п.
Ну и соответственно например если мы захотим сделать совсем анонимный опрос, то мы переопределим поле «ид пользователя» на «по умолчанию NULL» (грязный хак, не SOLID, но сходу более удачный пример не приходит в голову).
Что я ожидал из заголовка (заголовок правильный, это мои тараканы) — интерфейс создания мышкой структуры базы данных. Добавления полей, их свойств и т.п.
Ну или на худой конец именно построитель запросов (жестко к предметной области, как у 1С).
Вы сделали красиво и интересно, это просто мои тараканы, не заморачивайтесь.
Ну и плюс функция резинового утенка. Пока писал, у меня лучше сформировалась концепция как оно должно быть. Жаль времени пока нет.
Можно же делать целые компоненты с интерфейсами, а подробности реализации скрывать в подсхемах/текстовой реализации
Только хотел написать — да, группировка частей схемы. Выделяешь кусок связанных блоков, группируешь, и получается один блок с общим названием.
А в обратную сторону SQL-запросы он нормально по узлам раскидывает?
З.Ы. под спойлером пример визуального программирования в вебе — мойлюбимыйкорезоид

А в обратную сторону SQL-запросы он нормально по узлам раскидывает?
VAX вообще ничего не знает про SQL, он просто работает со схемой доменной области, которую вы ему скормите. И на выходе даёт граф либо деревья, сериализованные в JSON. Это уже backend нашего проекта превратил их в SQL.
Но естественно, можно в VAX загружать графы, т.е. если вы придумаете как разбить ваш SQL на узлы из вашей схемы, то можно смело рендерить такой граф. Но, вряд ли, такая задача кому нужна.
Ну вот, к примеру, пара первых упражнений из «Проекта Эйлера»:


Цветом кодируется тип данных на линии — синие — целочисленные данные, зелёный пунктир — булевы.
Но с помощью VAX, вот что можно получить:

Одна из самых больших проблем в графическом программировании — это использование места на экране и постоянно разрастающаяся диаграмма. При работе в той же LabVIEW одно из основных правил — любая диаграмма должна занимать не более одного экрана (и этого вполне можно достичь, грамотно разбивая программу на подпрограммы). Но я это к тому, что вы можете немного сэкономить место — сравните ваш «Equals 0?» с похожим LabVIEW элементом — в общем-то нет необходимости указывать тип Integer/Boolean на каждом коннекторе.
На самом деле LabVIEW не заточена под определённую предметную область (да, там есть специфические элементы для сбора данных с железок NI, но это всё на уровне библиотек), а так там совершенно «классические» базовые конструкции и типы данных, присутствующие практически в любом языке, и позволяющие писать вполне себе нормальные десктопные приложения. Я вообще придерживаюсь мнения, что через много много лет (несколько десятилетий, вероятно) классический текстовый подход к написанию программ постепенно заменится на графическое программирование на уровне диаграмм и в этом смысле вы двигаетесь в правильном направлении.
При работе в той же LabVIEW одно из основных правил — любая диаграмма должна занимать не более одного экрана (и этого вполне можно достичь, грамотно разбивая программу на подпрограммы). Но я это к тому, что вы можете немного сэкономить место — сравните ваш «Equals 0?» с похожим LabVIEW элементом — в общем-то нет необходимости указывать тип Integer/Boolean на каждом коннекторе.
Да верно подметили, это большая проблема. Среди задач на будущее есть возможность кастомизировать отображение узлов, чтобы их делать более компактными и/или информативными, возможность зумировать.
...LabVIEW элементом — в общем-то нет необходимости указывать тип Integer/Boolean на каждом коннекторе.
Хорошая идея, спасибо. Можно их в принципе показывать только по наведению, или как-то ещё.
Создание функций не интуитивно. Если я сходу не понял, то и юзер не поймет. Я могу прочитать документацию, а юзер нет… Ограниченное колво входов у функции (т.е. фиксированный список входов, 1,2,3?) удивляет.
Хочется больше гибкости в грамматике.
И хочется более компактного вида у узлов, да и у всей схемы.
Общее ощущение после более детального ознакомления — интересно поиграться. Интересно поучить на нем детей. Но в бою пока не вижу как использовать.
узел появляется в произвольном месте (в демке на сайте это выше зоны просмотра),
При нажатии кнопки X он появляется в месте, где был курсор, при создании из провода, он тоже под курсором появляется. Единственное, когда его создаёшь из кнопки на меню, да он появляется где-то непонятно. Но я не думаю, что тулбаром есть смысл пользоваться.
плюс надо листать список и т.п.
там есть autosuggest
1) Опять же места для комментариев в списке не очень много.
2) Мне кажется тут было бы удобнее сделать панель с элементами из которой мы бы перетягивали мышкой.
Да список элементов, наверное, надо очень крутым делать. Но в большинстве существующих подобных редакторов (в том же UE4) это просто список c autoSuggestом, т.к, как правило, очень много элементов.
Создание функций не интуитивно.
Да, это пока хромает.
Ограниченное колво входов у функции (т.е. фиксированный список входов, 1,2,3?) удивляет.Не понял о чём вы. Вы всё определяете в схеме. Их там может быть сколько угодно. Если вы про пользовательские, то их там тоже может быть сколько угодно.
Хочется больше гибкости в грамматике.
Если есть конкретные идеи, будет круто.
И хочется более компактного вида у узлов, да и у всей схемы.
Да это в TODO всё.
Но суть в том, что это всё просто недоделки редактора, которые понятно как улучшать, сама модель вряд ли претерпит изменения.

Выбор из трех вариантов.
Я так понимаю что в грамматике можно указать хоть десять, но если пользователю понадобится одиннадцать, то внезапно не получится. При этом в описании будет куча кода для шести параметров, которых в реальных кейсах ни разу не будет.
Ну как-то так я понимаю.
def map[A,B](l: List[A])(f: A=>B):List[B] = l map fclass BoxPrinter<T> {
private T val;
public BoxPrinter(T arg) {
val = arg;
}
public String toString() {
return "{" + val + "}";
}
public T getValue() {
return val;
}
} template<typename T>
void f(T s)
{
std::cout << s << '\n';
}И ваши функции тоже могут быть параметризованы типами, как если бы создали сами такой компонент:
components:
FoldArray:
typeParams: [T]
in:
A: Array[@T]
out:
O: @TЯ не думаю, что на практике, кому-то понадобиться более 3 типов-параметров (если вообще кому-то хоть 1 тип понадобиться :))
Хорошая идея, спасибо. Можно их в принципе показывать только по наведению, или как-то ещё.
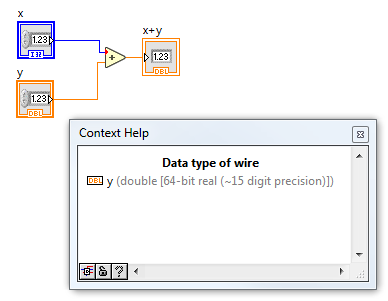
В LabVIEW именно по наведению и сделано. Если я нажму Ctrl+H, то появится всплывающее окошко и по наведению мыши на проводник мне будет показан тип данных. Кроме того, если происходит приведение типов (ну, скажем я складываю int и double, то int будет автоматически приведён к double, о чём LabVIEW сообщит красной точкой (coercion dot) на входе. Ну как-то так это выглядит:
Вот несколько ссылок на аналогичные библиотеки для работы с визуальными графами:
А вот этот проект не видели — noflojs? Чем-то похож на Ваш.

http://js.cytoscape.org
https://www.graphdracula.net
https://jsplumbtoolkit.com
http://sigmajs.org
Эти вроде (не утверждаю) все либо просто для рисования/анализа/layout графов, либо с захардкоженной доменной областью.
Сама работа с графом в моём случае не является центральной идеей.
Да, noflojs интересный и похожий инструмент. Возможно есть смысл подумать над интеграцией с форматом FBP, если кому-то будет нужно.
Вы видите сразу схему вашей базы. Если вас интересует какое-то поле — вы его вытягиваете из схемы и сразу получаете табличку которая делает group by по этому полю и считает count. Потом можно в неё кинуть другое поле как значение и оно тоже саггрегируется. Тип аггреграции — свойство колонки. Надо фильтрацию — или вписываем условие вида «поле больше x» или клацаем на нужной строке для фильтрации. Ну и так далее. Общая идея в том, чтоб работать сразу с данными, а не представлять те же абстракции в другом виде.
P.S. Странно, что уже комментариев 5 к этой статье я насчитал, которые явно не поняли суть инструмента.
Я своим девелоперам руки обрываю за такие творения.
Было бы очень интересно узнать ситуацию с производительностью до и после. Или вы такой ерундой не заморачиваетесь?
Было бы очень интересно узнать ситуацию с производительностью до и после.
Это сугубо аналитические запросы, вынесенные за OLTP основного приложения, запускаемые поверх read-only аналитических реплик. Раз в месяц по всем клиентам, и изредка (максимум раз в день) для теста новых гипотез.
Или вы такой ерундой не заморачиваетесь?
Мы такой ерундой заморачиваемся.
просто подобное действительно в основном пытаются решить для SQL, востребованно.
Только на моей памяти в одной компании пытались решить эту проблему двумя путями:
1) улучшениями бизнес процесса между IT и бизнесом (на что жалуется Mendel внизу). Универсализация/упрощение запросов от бизнеса.
2) просто скопировали какую-то систему (backend only), которая создавала динамические запросы. Она в оригинале то работала с тормозами. Пришлось улучшать, благо типовой набор запросов был не бесконечным.
Мышакодинг для единичных запросов на много порядков улучшает производительность.
У меня бывали запросы в 1с которые выполнялись по 20-30 секунд. Даже с учетом их продвинутого кеширования (всякие регистры с предвычислениями сильно облегчающие групповые операции).
Безумно много если выполнять регулярно. Но пофиг если написание запроса заняло час, и повторно выполняться он не будет никогда.
А вот оптимизировать написание самого запроса — бесценно.
Для относительно простых аналитических запросов больше половины времени уходит на то чтобы манагер которому нужен запрос и программист поняли друг-друга. При этом 90% запросов никто не пишет по принципу «ой, пока напишут, пока посчитают, та ну...».
Когда мышкой потыкать и получить инфу — намного эффективнее.
Именно по этой причине девелоперы в нормальных кампаниях не имеют доступа к боевым серверам.
И только люди кто реально понимают как это работает, работают напрямую.
Уж лучше пускай потратит час (к вопросу об профессионализме) на написания запроса, чем бизнес кампании зависнет на несколько минут.
В сухом остатке: динамические запросы зло. не важно как они создаются.
Хотите создать что-то что тыкается мышкой, спросите ДБА спеца как лучше (естественно применительно только к SQL). Универсальных решений не бывает, в каждом случае свой подход.
Именно чтобы один запрос не уронил сервер.
Самые простые — оптимизация базы и серверов, отдельная база для аналитики стоящая слейвом у боевой, ограничение времени исполнения запроса.
Ну и конечно конструктор запросов должен быть умным.
Возьмем самый известный среди окружающих мышепостроитель запросов — пхпмайадмин.
Самая важная его функция защищающая сервер от краша это — добавление лимита к селектам.
Вот буквально на этой неделе у меня выплыла задачка парсинга некоторых публичных баз. И у одной из них у результатов поиска нет пагинации и лимита.
По каждому чиху падает. Но это ведь не от сложного построителя запросов которого там просто нет, а от плохого проектирования.
А вот в 1С где у меня были самые толстые неоптимизированные запросы, с кучей вложенных запросов и т.п… юнион от восьми групповых запросов каждый из которых жоин на три таблицы. Причем все это по большим таблицам и подтаблицам (в языке 1С-запросов это по сути скрытые жоины). Никогда проблем не было. Да и не могло быть. Везде индексы, где статистика какая-то — регистры накопления (эдакие предвычисления по суммам и оборотам). Один запрос — один поток. На сервере 16 ядер плюс гупертрейтинг. Клиентов в базе всего человек двадцать кто мог работать с основной базой (была еще почти сотня удаленных баз в филиалах которые синхронизировались с основной, и была еще одна копия основной синхронизированная где жило большинство пользователей). Так чтобы одновременно — ну максимум человек 5. Запросы они одновременно не делали. Бывало запросы и по 5 минут считали, может и больше, но так чтобы сервер положить… не представляю что для этого нужно.
А уж так чтобы «работу парализовать», так вообще невозможно — остальные экземпляры базы будут живы и даже те кто имели доступ к основной базе — имели доступ к другим.
Единственное что — задержки в процессе синхронизации. Но это проблема архитектуры сети которую я выбрал, и исключительно потому что задержки в час были заложены как штатные, так что я не оптимизировал эту сторону. А если бы статистика была бы на дочерней базе а не на основной, то и этого бы не было.
VAX — инструмент для визуального программирования, или как написать SQL мышкой