Комментарии 37
Желание иметь прямые потоки данных, конечно же, правильное… но почему бакэндом должна быть база данных?
Если вы об толстом Middle, то аргументация — в статье + смотрите ветку комментариев.
Ну а для FrontEnd разработчиков (JS в браузерах и иные потребители API через http), взаимодействующих с сервером, вся серверная сторона — BackEnd.
Я не настолько хорошо знаю nginx, чтобы конкретное что-то посоветовать. Я в нём только со статикой и fastcgi неплохо разобрался.
Пример конфига с фильтрацией через lua, кол-во переменных не ограничено:
set $filter_by_lua "";
location ~/lua/(?<table>[a-z0-9_]*)/(?<columns>\*|[a-zA-Z0-9,_]+) {
access_by_lua_block {
local rex = require "rex_pcre"
local tmp, tmp2, tmp3
tmp = string.gsub(ngx.var.args, "&", " AND ");
tmp2 = string.gsub(tmp, "([%a%d_]+)=([%a%d_+-.,:]+)", "%1='%2'")
tmp3 = rex.match(tmp2,
"[a-zA-Z0-9_]+='[a-zA-Z0-9_+-.,:]+'(?: AND [a-zA-Z0-9_]+='[a-zA-Z0-9_+-.,:]+')*")
if string.len(tmp3) > 0 then
ngx.var.filter_by_lua = "WHERE " .. tmp2
end
}
add_header Content-Type "text/plain; charset=UTF-8";
pgcopy_query GET db_pub
"COPY (select $columns FROM $table $filter_by_lua) TO STDOUT WITH DELIMITER ';';";
}
Если работать без lua модуля rex_pcre, то выражения идущие на контроль корректности, типа '(foo)+' работать не будут см.Limitations of Lua patterns. Соответственно в tmp3 придется вручную прописывать количество переменных. Пример для двух:
tmp3 = string.match(tmp2, "[%a%d_]+='[%a%d_+-.,:]+' AND [%a%d_]+='[%a%d_+-.,:]+'")
Еще как вариант, использовать встроенный ngx_http_perl_module. По производительности lua-nginx vs ngx_http_perl, к моему сожалению, не подскажу.
perl_set $filter_by_perl "sub {
my $r = shift;
$_ = $r->args;
s/&/ AND /g;
s/([a-zA-Z0-9_]+)=([a-zA-Z0-9_+-.,:]+)/$1='$2'/g;
if(m/([a-zA-Z0-9_]+='[a-zA-Z0-9_+-.,:]+'(?: AND [a-zA-Z0-9_]+='[a-zA-Z0-9_+-.,:]+')*)/g) {
return 'WHERE '.$1;
}
return '';
}";
server {
listen 8880;
server_name 127.0.0.1;
pgcopy_server db_pub "host=127.0.0.1 dbname=testdb user=testuser password=123";
location ~/perl/(?<table>[a-z0-9_]*)/(?<columns>\*|[a-zA-Z0-9,_]+) {
add_header Content-Type "text/plain; charset=UTF-8";
pgcopy_query GET db_pub
"COPY (select $columns FROM $table $filter_by_perl) TO STDOUT WITH DELIMITER ';';";
}
}
Еще некоторые особенности Nginx-Perl…
На content handler результат не предсказуем, т.к. неизвестно какой хэндлер раньше вызовется(ngx_pgcopy или Nginx-Perl). Соответственно, есть вероятность, что фильтр сработает после отправки sql запроса.
На access_handler не заработало, скорее всего дело в особенности ngx_pgcopy. Он вертится в этой фазе во время установки контакта с базой, принудительно откатывая статус соединения с клиентом. Что, вероятно не нравится Nginx-Perl и он преждевременно закрывает соединения.
Кусок из http блока nginx.conf
js_include SourceJavaScript.js;
js_set $filter_by_njs FilterFunc;
Файл SourceJavaScript.js с самым лайтовым вариантом регулярок:
function FilterFunc(req) {
var v0, value, data, full_filter = "";
var regex_value = /([\d\w]*)/;
var regex_data = /[\d\w,._]*/;
for (v0 in req.args) {
value = regex_value.exec(v0);
if (full_filter.length > 1) full_filter += " AND";
if(value != 'undefined') {
data = regex_data.exec(req.args[v0]);
full_filter += " " + value[1] + "='" + data + "'";
}
}
if (full_filter.length > 0)
return " WHERE"+full_filter+"\n";
}
Из положительных моментов: гораздо меньше требований ко внешним библиотекам системы, в отличии от lua и perl. Если уже собирали nginx из slim_middle_samples через make likeiamlazy и есть меркуриал, то можно вытянуть последнею версию slim-a и собрать make njs.config, после чего должен завестись url типа http://127.0.0.1:8880/njs/simple_data/*?s_id=1. Полная версия js конфига в директории nginx.conf в slim_middle_samples.
Я вот сейчас страшно крамольную вещь скажу, вы только не обижайтесь: то, что вы описываете, вполне легко делается в middleware, если не гнаться за RESTful API, а использовать RPC.
Выставлять базу напрямую для JS клиентов получится только на первых порах. Потом вас больно укусит ортогональность архитектуры stateless HTTP запросов к stateful соединениям в базу. Окажется, что кто-то должен держать в "голове" состояние процесса, и как бы middleware здесь самый логичный кандидат.
Может показаться соблазнительным держать всё состояние в клиенте, но это крайне небезопасно, чревато проблемами с разрывом синхронизации из-за ненадёжности сети, и потребует массивного траффика между клиентом и сервером.
В общем, идея интересная, но я буду придерживаться более проверенных решений. Всё уже украдено до нас. (с)
RESTful, по основным требованиям, описанная в статье архитектура — проходит. Отличается только RESTful-pattern — отсутствие CRUD.
Stateless vs stateful. Вспоминаю момент, когда я начинал писать на plsql. Я часто использовал процедурные циклы внутри функций с соответствующими последствиями — проседанием скорости исполнения. Сейчас, я вкручиваю однопроходный декларативный sql в такие места, о которых раньше и не догадывался.
Думаю это больше вопрос привычки, как и использование stateless.
Если использовать запись всех изменений данных(журнал/лог), подозреваю, что можно получить что-то вроде multistateful — сохранение состояний клиента внутри разных многостадийных процессов.
RESTful, по основным требованиям, описанная в статье архитектура — проходит. Отличается только RESTful-pattern — отсутствие CRUD.
Честно сказать, я не большой фанат REST подхода. Большей частью потому, что он религиозно наэлектризован и сильно напоминает мне пресловутую красную селёдку. "Это RESTful или недостаточно RESTful?" Да какая разница-то? Работает/не работает, подходит/не подходит, делает жизнь легче или нет, вот правильные критерии.
Зато я точно знаю, что RPC безо всякого пафоса и лишней идеологии делает многие вещи до неприличия простыми, особенно при хорошей поддержке в библиотеке на клиентской стороне. И я не только о разработке говорю, тестировать и поддерживать код тоже надо.
Вот скажем, вопрос сразу в лоб: а как вы юнит-тестирование организовывать будете? Глядя на примеры конфигурации nginx выше, напрашивается ответ: никак. Когда на любой чих нужна поднятая связка nginx + Postgres с полной схемой и тестовыми данными, это уже слишком хрупко на мой вкус. Я предпочитаю среды и инструменты, которые легко изолировать и тестировать.
И вы уж извините, но парсинг и переписывание SQL запросов регулярными выражениями это просто классический пример из шутки про "у вас есть проблема, и вы хотите использовать regex..."
Stateless vs stateful.… Думаю это больше вопрос привычки, как и использование stateless.
В том-то и дело, что нет. Одностраничные приложения на JavaScript накладывают архитектурные ограничения, и обойти stateless HTTP можно, но ценой отдельного колхоза. А с другой стороны — PostgreSQL, который рассчитан на stateful клиентов. Что-то должно заниматься скрещиванием ежа и ужа, и вы предлагаете это что-то размещать в самой базе. На мой взгляд это даст больше проблем, чем решений.
Чтобы не быть голословным, приведу пример решения на стеке, который сам предпочитаю: https://github.com/nohuhu/HTML5-StarterKit. Времени на этот проект у меня не хватает, поэтому он давно не обновлялся; идею же демонстрирует вполне.
Вот скажем, вопрос сразу в лоб: а как вы юнит-тестирование организовывать будете?
- Perl. Потом, а можно и сразу ngx_echo + парсиниг лога nginx.
- Точка входа — таблицы, т.е. отлаживаются простыми инсертами. Пример positive/negative standalone sql теста на журналы и логи в slim_middle_samples.
Регулярные выражения нужны для составления и контроля. Какие альтернативы для динамических sql выражений и проверке не прямых данных на инъекции?
Если это делать в полуручном режиме(map/for, if/case на встроенные переменные), тогда без большого среднего слоя — никуда. Узкое место подобной реализации я описал в статье + увеличение объем кода.
PostgreSQL, который рассчитан на stateful клиентовПарсинг и генерация json, xml, csv, чтотоеще — из коробки. Я думаю тут как раз обратное, но скорее всего, это уже дело религии.
Perl. Потом, а можно и сразу ngx_echo + парсиниг лога nginx.
Покажите пример, как это должно выглядеть на практике. Глядя на код и конфиги выше, очень трудно это представить.
Точка входа — таблицы, т.е. отлаживаются простыми инсертами.
Т.е. вы предлагаете вместо своей странной middleware тестировать, как работает база? Спасибо, я вполне убеждён, что разработчики PostgreSQL уже всё, что нужно, протестировали. Мне не интересно тестировать базу. Мне нужно убедиться, что middleware делает то, что мне нужно, не делает того, что мне не нужно, и умеет отличать одно от другого. Примеры в студию.
Регулярные выражения нужны для составления и контроля. Какие альтернативы для динамических sql выражений и проверке не прямых данных на инъекции?
Ну как бы, prepare/execute? Такие, знаете, старые-добрые инструменты, которые давным-давно уже доступны и проверены.
Если это делать в полуручном режиме(map/for, if/case на встроенные переменные), тогда без большого среднего слоя — никуда.
Так вот без него и никуда, получается. То, что вы предлагаете, это фактически middleware в базе плюс новый взгляд на PHP и ещё больше восхитительных дыр.
Узкое место подобной реализации я описал в статье + увеличение объем кода.
Узких мест у отдельного middleware полно, как и преимуществ. У вашего подхода тоже узких мест по самое не балуйся. О производительности вы уже подумали? О масштабируемости? Сколько одновременно открытых соединений ваша архитектура выдержит? А сколько одновременных запросов?
PostgreSQL, который рассчитан на stateful клиентов
Парсинг и генерация json, xml, csv, чтотоеще — из коробки. Я думаю тут как раз обратное, но скорее всего, это уже дело религии.
Сериализация JSON и XML это такие мелочи, что о них говорить смысла нет. И речь не о религии, а о прямой 1:1 зависимости клиент: соединение в Postgres. Или я что-то проспал, и libpq уже научилась переключать пользовательский контекст в пределах одного соединения? Оно даже больше одного активного запроса на соединение не умеет, чтобы хоть как-нибудь извернуться.
ngx_echo + парсиниг лога nginx. Покажите пример.
Т.е. вы предлагаете вместо своей странной middleware тестировать, как работает база? Спасибо, я вполне убеждён, что разработчики PostgreSQL уже всё, что нужно, протестировали.
Тестировать не субд, а собственную хранимую логику!
В этом есть суть и колоссальное преимущество над классическими решениями.
Средний слой настолько мал, что требует тестирование только фильтров.
А вся логика отлично проверяется не выходя из базы!
Итого
1. Тест регулярок для фильтрации, решение ngx_echo+curl+diff.
С ngx_echo я ошибся комментарием выше — он выводит клиенту. Этот момент исправлен в приведенном примере. В тесте ngx_pgcopy подключён, но можно закоментить pgcopy_query, а echo_after_body поменять на echo и будет standalone nginx.
2. Тест логики standalone sql.
Более подробное описание методов тестирования тянет на целую статью. В неизвестном будущем думаю запланировать это, а так же думаю добавить в модуль некоторый функционал для облегчения отладки фильтров.
map/for, if/case и восхитительные дырыНа страже дыр — регулярные выражения. Что эффективнее — я думаю, отдельный огромный и вечный вопрос. prepare/execute — в целевой архитектуре так же используется.
В вашем проекте HTML5-StarterKit для работы с базой используется DBIx::Class.
Код этого ORM содержит 113 регулярных выражений, без учёта динамических вызовов.
О производительности вы уже подумали? О масштабируемости? Сколько одновременно открытых соединений ваша архитектура выдержит? А сколько одновременных запросов? libpq и пользовательский контекст… Оно даже больше одного активного запроса на соединение не умеет.Отнюдь! На каждое новое соединение клиента ngx_pgcopy открывает одно новое соединение с базой. Как и классические решения.
Максимальное кол-во запросов, соединений и пользователей зависит только от nginx и postgresql.
Тестировать не субд, а собственную хранимую логику!
Которая в базе, да. Плюс в фильтрах, которые эту логику публикуют. Ибо если фильтр сломан, то логика доступна не будет, или будет доступна не полностью. Получается, что всё же тестировать надо в связке?
А вся логика отлично проверяется не выходя из базы!
Что-то мне подсказывает, что весь предположительный цимес данной затеи сводится как раз к тому, чтобы не вылезать за пределы уютненькой базы. И все воображаемые колоссальные преимущества притягиваются за уши, дабы оправдать затею.
Не покупаю.
На страже дыр — регулярные выражения.
Это означает, что стражи нет. Будь вы хоть семи пядей во лбу, ошибиться в regex как два пальца об асфальт. Особенно в развесистой клюкве, потребной для парсинга и валидирования SQL.
У меня подобный опыт был, в том случае смысл обработки SQL сводился к "переводу" Informix диалекта на Postgres. В результате долгих плясок с бубном решение перевелось на Parse::RecDescent с обвязкой из вдоль и поперёк протестированных статических регулярных выражений; сделать просто на regex не получилось. Слишком много косяков лезло.
И это всё, заметьте, принимало на вход запросы из строго контролируемых источников и только на SELECT. Делать что-то подобное для INSERT/UPDATE/DELETE я не буду никогда, слишком опасно. А уж принимать запросы в свободной форме от JavaScript клиентов вообще смерти подобно.
В вашем проекте HTML5-StarterKit для работы с базой используется DBIx::Class.
DBIx::Class в нём используется как вторичная зависимость, для ускорения разработки. Никто не мешает ORM выкинуть и работать с базой напрямую; суть же проекта всего лишь в демонстрации подхода.
Отнюдь! На каждое новое соединение клиента ngx_pgcopy открывает одно новое соединение с базой. Как и классические решения.
Классические middleware решения не открывают по соединению с базой на каждого клиента, а держат пул соединений и используют их по необходимости. Тысячи одновременно "открытых" stateless сессий с клиентами могут обслуживаться десятком соединений с базой. Ваша архитектура предполагает по соединению с базой на каждого клиента. Это совсем никак не похоже на классические решения, и гораздо более ресурсоёмко.
Максимальное кол-во запросов, соединений и пользователей зависит только от nginx и postgresql.
Проверил значение max_connections в postgresql.conf тестовой базы, почему-то там по умолчанию 100. Есть подозрение, что 10_000 слонёнку не понравится, а уж 100_000 тем более. Вот тут авторитетные товарищи утверждают, что больше "нескольких сотен" требует дополнительных костылей в виде connection pooling.
Ещё раз, вы же предлагаете по соединению на каждую активную клиентскую сессию, да? А вовсе не на одновременно обрабатываемые запросы, как в классических схемах с middleware.
А ещё у нас в какой-то момент времени может возникнуть необходимость во втором, третьем, N экземпляре nginx — и балансировки ради, и отказоустойчивости для. Сколько сладостных трудностей по синхронизации состояния это открывает!
Максимальное кол-во запросов, соединений и пользователей зависит только от nginx и postgresql.
А ещё, скажем, от количества памяти в сервере, т.к. libpq держит состояние открытого соединения "в голове". Как насчёт отлавливания недетерминистских отказов в обслуживании при флуктуациях доступного количества RAM? Или необходимости лимитировать количество HTTP соединений на экземпляр nginx, чтобы его процесс с разбухшим от счастья libpq внутри не сожрал всю память под соединения с базой?
Что касается производительности при обслуживании N одновременных запросов, это тоже отдельный и очень интересный вопрос, учитывая event based архитектуру nginx и несколько кривую реализацию асинхронности в Postgres. Настолько интересный, что ну его нафиг.
В общем, мсье знает большой толк в преодолении.
Получается, что всё же тестировать надо в связке?Вначале, unit tests, потом всё в связке. Как и везде.
Классические middleware решения не открывают по соединению с базой на каждого клиента, а держат пул соединений и используют их по необходимости. Тысячи одновременно «открытых» stateless сессий с клиентами могут обслуживаться десятком соединений с базой. Есть подозрение, что 10_000 слонёнку не понравится, а уж 100_000 тем более.Модуль еще в разработке, постоянно открытый пул еще не реализован — о чём и написано в конце статьи.
Одномоментно, на бд будет уходить столько, сколько настроите, остальные будут висеть в очереди nginx. Из-за ускорения логики, если её корректно перенести ввиде однопроходных запросов, серьезно сократится время обработки ответа. В результате — очередь пройдет быстрее, чем с толстым слоём.
А ещё у нас в какой-то момент времени может возникнуть необходимость во втором, третьем, N экземпляре nginx — и балансировки ради, и отказоустойчивости...10_000 100_000… лимитировать nginx чтобы libpq внутри не сожрал всю память
На той нагрузке о которой вы пишите — этой неизбежно и в классических решениях. libpq ест меньше, чем интерпретаторы fat middle.
Большинство проблем представленной технологии в её молодости — неполной реализации, отсутствию обширной обвязки с примерами и туториалами. Я этого и не скрывал.
Основная цель статьи — попытаться создать фундамент для будущего комьюнити. А не кидаться без оглядки с недоспелыми фруктами на амбразуру мирового продакшена.
Скорость скакуна, в начале 20ого века, как и несколько тысяч лет до этого, неспешным галопом составляла ~20км/ч, для дальних дистанции. Максималка более 60км/ч, при коротких пробежках в 1-3км. На лошадь можно посадить пару людей. А если пристегнуть повозку, то и с десяток.
В те времена считалось, что аппараты тяжелее воздуха летать — не могут. Однако, 1903 состоялся первый полёт такого аппарата. Скорости была ~15км/ч на дальность 260м. Он мог перемещать только одного человека.
Где сейчас самолёты, а где лошади — вы и сами знаете.
slim_middle_samples
- Общая документация по технологии
- Примеры реализации sql, nginx.conf
- Методики тестирования
- Туда же думаю неплохо было бы добавить примеры подключения FrontEnd
Модуль ngx_pgcopy, для отслеживания основного функционала. А так же для спецов по nginx, желающих поковыряться в кишках.
Вначале, unit tests, потом всё в связке. Как и везде.
Ещё раз: приведите примеры. Можно просто ссылку на гигантский набор юнит-тестов в вашем проекте.
На той нагрузке о которой вы пишите — этой неизбежно и в классических решениях. libpq ест меньше, чем интерпретаторы fat middle.
У меня есть ощущение, что вы не читаете мои сообщения, а отвечаете виртуальному собеседнику. :)
Основная цель статьи — попытаться создать фундамент для будущего комьюнити.
[...]
Где сейчас самолёты, а где лошади — вы и сами знаете.
Ах да, конечно. Laziness, impatience, and hubris. Как же я мог забыть.
Дерзайте!
+ При использовании журналов и логов — логирование из коробки.
— Требует от разработчика некоторое переосмысление устоявшийся идеологии
— Нужно хорошее знание plpgsql и регулярный выражений
Про написание кода, тестирование и други моменты разработки — вопрос спорный.
На самом деле выглядит, как огромный костыль, требует специфической настройки, узкая функциональность и специализация, может сломаться в любой момент и причину вы не найдете, т.к. никаких логов своей работы не ведет.
Я знаю, что сейчас некоторые люди, из любви к исскуству, делают сервер приложений на nginx.
Это чисто академическая задача.
Что касается логов, то есть подробный отладочный вывод в nginx-error.log. Если нужен лог только с модуля, то включить его можно раскоментировав строку в файле ngx_http_pgcopy_module.c.
//#define PGCOPY_DEBUG 1
Cегодня добавил автоматическое включение отладки, если configure, перед сборкой, был c опцией
--with-debug
Так же есть пример скрипта для парсинга лога модуля и отображения его в виде отформатированного xml с иерархией и порядком всех вызовов.
Вы просто засунули MiddleWare внутрь PostgreSQL.
Транспортная функция ушла в ngx_pgcopy.
Прикладная логика отправилась в PostgreSQL.
По энергоемкости nginx+ngx_pgcopy = nginx+ngx_http_fastcgi_module(только модуль nginx, без толстого MiddleWare)
Прикладную логику и раньше можно было пихать в субд, но для транспорта приходилось подгружать объемный средний слой. Теперь это не обязательно.
А то что СУБД подгружает дополнительную логику, никак на производительность не влияет?
Хорошо бы тесты какие-то прогнать.
Ну и отдельный вопрос, решение сделано исключительно для повышения производительности? Получается что в ущерб технологичности разработки: куда проще php-шника в проект найти чем нужного уровня специалиста по PostgreSQL. За разницу в зарплатах можно содержать дополнительные вычислительные мощности, чтоб гонять "толстый Middleware"
Там же думаю будет и небольшой раздел по встроенной логики против внешней. Для специалистов по PostgreSQL исход по логике - очевиден.
Очень давно, на заре моего перехода на Postgres, я анализировал maillog. Файлики были ~100т. строк ~50MB. C помощью perl отформатировал в csv и отсеял всё лишнее, сколько длилась обработка — уже не вспомню. Далее попробовал вытащить из этих файлов обширную статистику с помощью perl. Вначале решил тестануть на одном файле и… выключил после более чем часа. Немного подумав решил, что с индексами дело пойдёт порасторопнее.
Первое решение реализовал по следующему пути: из perl c помощью insert загнал данные в базу и потом уже через select доставал нужные куски обратно в perl и доводил результат до конца. Загрузка в БД заняла ~30 минут, анализ ~20 минут.
Порывшись в документации СУБД наткнулся на COPY, загрузка сократилась до ~30 секунд! Вторым откровением были WITH Queries и рекурсивные запросы. В течении следующих нескольких дней я упорно оптимизировал запрос. Полностью избавился от loop во встроенной функции. Результатом был один SQL request размером с Эверест. И оно того стоило! Мне удалось оптимизировать анализ до ~10 секунд!
Почувствуйте разницу: ~50 минут и ~40 секунд, на загрузку и анализ, на одной и той же машине!
Т.к. в моих интересах защита предложенной мной технологии, подобный пример может быть скептично принят людьми, плотно не связанными с PostgreSQL. Поэтому хотелось бы услышать комментарии со стороны других специалистов по СУБД.
Что касается зарплат — для разработчика это не последний фактор. А актуальность для бизнеса — зависит от масштаба:
— Для стартапа, если вам нужно привлекать специалистов снаружи — это, возможно, дорогое решение.
— Если в основании стартапа специалисты по PostgreSQL, гуру perl старой закалки и профи по кишкам nginx — то это будет вам очень интересно.
— Огромная компания с высокой нагрузкой? Тут уже одной экономией на электричестве можно покрыть эту разницу зарплат.
Не путайте бизнес-логику со сбором аналитики.
Мсье знает толк… ;) Я однажды тоже JFF написал машину Тьюринга на SQL без ХП: https://habrahabr.ru/post/113165/
Следующим шагом в развитии данного решения станет превращение postgres в аналог субд cache, где можно писать код прямо в базе человеческим языком. Либо, автору следует (согласно его же постулатам) сменить религию и в качестве монолитного бэкэнда использовать cache.
Возможно, всё то, что автор данной статьи хотел воплотить в своих необычных фантазиях, которые так высокохудожественно обернул в своем тексте, уже сделано в Cache: http://www.intersystems.com/ru/our-products/cache/tech-guide/chapter-4/ — там и nginx не нужен для того, чтобы обработать http запрос. Роутинг, разбор входных данных, обработку данных и выдачу результата делает один единственный СУБД сервер, и не надо писать костыли по связке nginx + postgres.
Но за стремление к исследованиям и интересный стиль изложения — однозначно плюс. Даже если твое творение окажется никому не нужным костылём — это всё равно будет бесценным опытом.
С Cache дело не имел, но порывшись по просторам сети нашёл следующую картинку на citforum
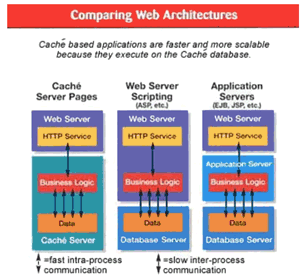
Статья старая, но посмотрев на гораздо более современные, думаю что картинка не утратила своей актуальности. И если это так, то архитектурно, связка Cache CSP + Cache СУБД очень близка к тому, что предлагаю я. Остальное уже дисциплина free open source vs. proprietary и postgresql vs. сache, что выходит за рамки данной статьи.
Страх и ненависть в MiddleWare