Мы были неподалёку от JavaScript, когда нами одолел php. Я помню сказал что-то вроде: Что-то у меня голова кружится. Может лучше тебе повести проект.

Внезапно, вокруг нас раздался ужасный бум… И весь WEB кишал этими статьями про LAMP…
Казалось, что они были написаны под любые нужды. Они разрастались и поглощали задачи для которых ранее пользовался perl, bash и даже С. Нет смысла говорить об этих статьях, подумал я. Все и так это знают.
У нас был пятый IE, немного Netscape, Opera и целое море разношёрстных cgi модулей на perl. Не то что бы это был необходимый стек технологий. Но если начал собирать дурь, становится трудно остановиться. Единственное что вызывало у меня опасение — это студент, употребляющий PHP. Нет ничего более беспомощного, безответственного и испорченного, чем это. Я знал, что рано или поздно мы перейдем и на эту дрянь.
В начале
Когда-то JS между браузерами отличался как конь от пробки, а XMLHttpRequest возможен был исключительно через ActiveX. Выхода особо не было. Что на корню вырубало динамический веб. IE 6 казался революцией. Но если вы хотели кросплатформености — ваш путь пролегал через объемный MiddleWare. А большое количество статей по php, инструментов и сопутствующих новоиспеченных библиотек делали своё дело.
Проклятый php, начинаешь вести себя как деревенский пьяница из старинных ирландских романов, полная потеря основных двигательных функций, размытое зрение, деревянный язык, мозг в ужасе. Интересное состояние когда все видишь, но не в силах что-либо контролировать. Подходишь к задаче, чётко зная, где данные, где логика и где представление. Но на месте всё происходит не так. Тебя запутывает злобный лапшичный код, а ты думаешь: в чём дело, что происходит?...
Постепенно титанические плиты между браузерами начали сходится. Везде появился XMLHttpRequest и мечты о динамическом WEB с четким разделение по фронтам становились реальностью.
Конечно же, я пал жертвой повального увлечения. Обыкновенный уличный бездельник, который изучал все, что попадало под руку. В воздухе витали идеи о едином языке для Web разработки. Погоди, вот увидишь эти изменения в новом обличие, мужик.
— Давай Node.js посмотрим.
— Чего? Нет!
— Здесь нельзя останавливаться. Это толстый Middle.
— Садись.
Что за чушь они прут, не знаю сколько нужно писать на JavaScript чтобы найти сходство между Front, Middle и BackEnd? Это неподходящий вариант. Слишком толсто для выбранной цели.
Но, подобные мысли я оставил. Пришло понимания того, что забить гвоздь можно и отвёрткой, но если иногда дотягиваться до молотка, то процесс серьезно ускорится.
Я почувствовал чудовищный протест против всей ситуации.
Есть же СУБД, такие как PostgreSQL, позволяющие невообразимо оперировать данными через встраиваемые функции. Бизнес логика внутри базы! Настоящий BackEnd. Не нравится бизнес логика в СУБД и ей там не место? А такие прямые потоки данных нравится?

Попробуем разобраться, с тернистым движением данных на «прямых» потоках курильщика.
Первое с чем мы сталкиваемся — это постоянная перегонка данных в середину, по любому поводу. К тому же, эти данные могут быть совсем не окончательными и требоваться только для расчёта последующих запросов. Для обработки данных используются циклы. Процедурные циклы — не оптимизированы на многопоточность.
Множественность запросов в одной сессии к СУБД ведёт к неизбежному апофеозу кончины скорости — многопроходности по таблицам базы.

Для исключения этих факторов, логику приходится переносить ближе к данным, т.е. в СУБД!
И это наиболее оптимальный способ вывести скорость на новые величины!
Со временем, браузеры научились полной динамической генерации интерфейса. Открылась ачивка чёткого разделения по фронтам данных и представления. Появилась полноценная возможность гонять от сервера к клиенту преимущественно данные. Оставался только один вопрос: Что делать со средним слоем? Как его минимизировать исключительно до транспортной функции с элементами простого роутинга запросов по коллекциям на стороне сервера.
Эти наивные разработчики полагали, что можно обрести душевный мир и понимание, изучив один из оплотов старого Middle, а результат — поколение толстого слоя, так и не понявших главную, старую как мир ошибку IT индустрии. Упустив убеждение, что Кто-то или Что-то может обладать фатальным недостатком.
К тому времени начал работать nginx, и уже не оставалось вопросов с чем нужно готовить предполагаемую мысль. Это больше была не идея. Теперь это было состязание программиста с ленью. Сама мысль, попытаться как-то описать архитектуру традиционным образом, через apache, казалась абсурдной.
В 2010 на github подоспел модуль ngx_postgres. Задание запросов в конфигурационном файле и выдача в JSON/CSV/ЧТОТОЕЩЕ.
Для конфигурации достаточно было простого SQL кода. Сложный можно было обернуть в функцию, которая потом вызывалась из конфига.
Но этот модуль не умел загружать тело http запроса в СУБД. Что накладывало серьезные ограничения на данные, оправляемые к серверу. URL же явно подходил только для фильтрации запроса.
Cериализация выходных данных проводилась средствами самого модуля. Что, с высоты моего дивана, казалось бессмысленным переводом ОЗУ — сериализовать умел и PostgreSQL.
Возникла мысль поправить, переписать. Я стал копать в коде этого модуля.
После бессонной ночи поисков многим хватило бы ngx_postgres. Нам нужно было что-то посильнее.
Мадам, сэр, детка, или как вас… вариант есть, вот, держите ngx_pgcopy.

После эксперимента экспериментов и анализа анализов, возникла мысль переписать всё практический с нуля. Для ускорения загрузки были выбраны запросы COPY, которые перегоняют данные в базу на порядок быстрее инсертов и содержат собственный парсер. К сожалению, ввиду скудности описания подобного типа запросов, сложно сказать как будет вести СУБД при особо массовых вызовах данного метода.
Мир безумен в любом направлении и в любое время, с ним сталкиваешься постоянно. Но было удивительное, вселенское ощущение правильности всего того, что мы делали.
Вместе с COPY-requests мы автоматом получили сериализацию в CSV по обоим направлениям, что избавило от необходимости заботы о преобразовании данных.
Начнём с примитива, отправка и получение всей таблицы в CSV по URL:
CSV часть import.export.nginx.conf

На текущий момент PostgreSQL не может в JSON и XML через COPY STDIN. Я надеюсь, что наступит день смирения с табами в код-стиле слона и я, или кто-нить, найдёт время и прикрутит этот функционал к COPY методам. Тем более, что в СУБД обработка этих форматов уже присутствует.
Однако! Способ применения здесь и сейчас всё же есть! Конфигурируем nginx на client_body_in_file_only on c последующим использованием в запросе переменной $request_body_file и передачей её в функцию pg_read_binary_file…
Разумеется придется это обернуть в COPY метод, т.к. работать будет только с моим мопедом, по причине полного body_rejecta у ngx_postgres. Других мопедов я пока не встречал, а ngx_pgcopy еще не созрел для дополнительного функционала.
Рассмотрим как это выглядит для json/xml в import.export.nginx.conf
Да, client_body_temp_path придётся выставить в директорию базы, а пользователю дать ALTER SUPERUSER. В ином случаем Postgres отправит наши желания за горизонт.
Экспорт, представленный в методах GET, использует встроенные функции, включённые в стандартную поставку Postgres. Все COPY выводят в STDOUT, на случай если мы захотим известить клиента о результатах этих действий. Импорт в фиксированную таблицу(simple_data) выглядит немного объемнее экспорта, посему вынесен в определяемые пользователем процедуры СУБД.
Часть из 1.import.export.sql для импорта в фиксированную таблицу
Функция импорта с гибким выбором таблицы для JSON особо не отличается от приведённой выше. А вот подобная гибкость для XML порождает более монструозное поделие.
В приведенных примерах, наименование table_name в импортируемом файле не влияет на целевую таблицу назначения, заданную в nginx. Применение иерархии xml документа table_name/rows/cols обусловлено исключительно симметрией со встроенной функцией table_to_xml.
Cами наборы данных…
Мы тут отдалились, поэтому вернёмся к истокам чистого COPY…
Ладно. Вероятно, это единственный выход. Только давай убедимся, что я всё понял верно. Ты хочешь отправлять данные между сервером и клиентом без обработки заливая их в таблицу?

Думаю я поймал страх.
Ерунда. Мы пришли, чтобы найти MidleWare мечту.
И теперь, когда мы прямо в её вихре, ты хочешь уйти?
Ты должен понять, мужик, мы нашли главный нерв.
Да, это почти так! Это отказ от CRUD.
Разумеется, многих возмутит как какой-то тип в паре предложений перечеркивает результаты работы Калифорнийских умов, стилизуя коротенькую статейку под диалоги наркоманского фильма. Однако, ещё не всё потеряно. Есть вариант передавать модификатор данных вместе с самими данными. Что всё равно уводит от привычной архитектуры RESTful.
К тому же, иногда, а когда и почаще, теоретические изыскания разбиваются о скалы реальности. Такими скалами является всё та же злополучная многопроходность. На деле, если вы допускаете изменение ряда позиций пользовательского документа, то вероятно, что данные изменения будут включать методы нескольких типов. В результате, для отправки в базу одного документа, потребуется провести несколько отдельных http запросов. А каждый http запрос, породит свою модификацию базы и свой проход по таблицам. Поэтому качественный прорыв требуют кардинальных изменений по отказу от классического понимания CRUD методов. Прогресс требует жертв.
Тут у меня возникли подозрения, что можно найти более интересное решение. Нужно только немного поэкспериментировать и подумать…
К тому времени, как я задался этим вопросом,
Никого, кто бы мог на него ответить еще не было рядом.
Да-да, я снова начинаю…
Мы отправляем данные в средний слой, который без обработки пересылает их в базу.
СУБД их парсит и кладёт в таблицу, выполняющую роль журнала/лога. Регистрация всех входных данных.
Ключевой момент, вот он! Журналируемость/логируемость потока данных из коробки! А дальше дело за триггерами. В них, исходя из бизнес логики решаем: обновлять, добавлять или делать что-либо еще. Прикручивание модификатора данных не является обязательным, но может быть приятным бонусом.
Это приводит нас к достаточности использования HTTP методов GET и PUT. Попробуем смоделировать как это применять. Для начала определимся с разницей между журналами и логом. Ключевую разницу выделяем через приоритет между ценностью маршрута изменения и конечным значением. Первый критерий отнесём к логам, второй — к журналам.
Несмотря на приоритет конечной цели в журналах, маршрут всё же необходим. Что приводит нас к разделению подобных таблиц на две части: результат и сам журнал.
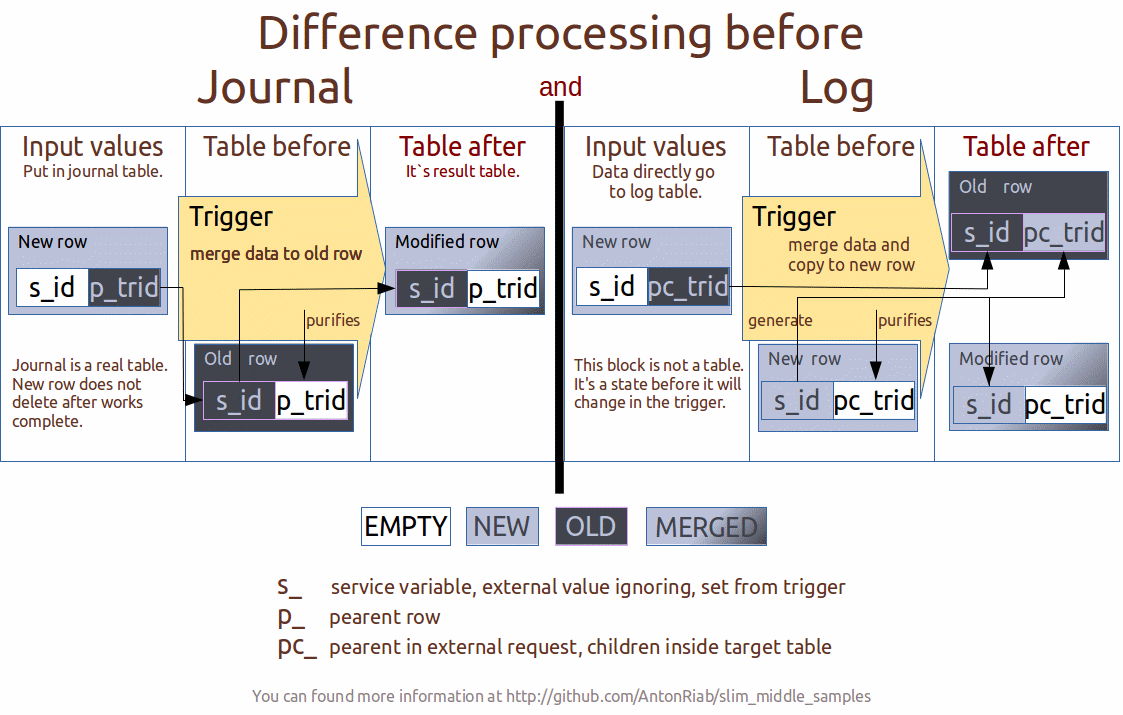
На что это можно натянуть? Логи: маршрут автомобиля, перемещение материальных ценностей и т.п. Журналы: остатки на складах, последний комментарий и иные последние мгновенные состояния данных.
Код из 2.jrl.log.sql:
Приведённые примеры не умеют очищать ячейки, т.к. для этого нужно прикрутить служебные значения. А они сильно зависят от способа импорта. В одних случаях это может быть любой тип с абсолютно произвольным содержанием. В других же, только тип целевого столбца с вероятным признаком по выходу из диапазона.
Триггеры вызываются в порядке текстовой сортировки по имени. Я рекомендую использовать префиксы trg_N_. От trg_0 до trg_4 считать служебными, обслуживающими только целостность общей логики и входящую фильтрацию. А с 5 до 9 использовать для прикладных расчетов. Девять триггеров будет достаточно всем!
Так же стоит сказать, что их нужно устанавливать на BEFORE INSERT. Так как в случае c AFTER, служебная переменная NEW будет положена в таблицу до модификации триггером. В принципе, если целостность в некоторый степени не критична, подобное решение может быть хорошим ускорителем пользовательских запросов, проходящих через журнал. Это не повлияет на значения результирующей таблицы.
Еще, при AFTER, мы не сможем вернуть ошибку, если пользователь не имеет прав на изменение. Но корректный FrondEnd и не должен проводить запрещенные сервером операций. Соответственно, подобное поведения скорее свойственно взлому, который мирно будет зафиксирован в журнале.

Маршрутиризируем URL стандартными средствами nginx. Тем же способом фильтруем запрос от инъекций. После удвоения проблем, код похожий на результат асимметричного шифрования загоняем в директиву map nginx.conf для получения удобоваримого и безопасного SQL запроcа. Которым, в последующем, фильтруем данные.
Есть некоторые сложности. Они вызваны отсутствием в nginx синтаксиса регулярок для множественной замены по типу sed s/bad/good/g. В результате мы…
Попадаем прямо в гущу этого ебаного террариума. И ведь у кого-то хватаем ума писать эти чёртовы выражения! Еще немного и они разорвут мозг в клочья.
до 4х фильтров эквивалентности по URL
Horrowshow part of filters.nginx.conf
C фильтрацией кириллиц в URL, через конфиг nginx, тоже не всё гладко — нужна нативная конвертация из одной переменной с base64 в другую, с человеко читаемым текстом. На текущий момент, такой директивы нет. Что достаточно странно, ибо в исходниках nginx, функции перекодировки присутствуют.
Как-нить обязательно соберусь с мыслями и ликвидирую это упущение, как и проблему с sed, если коллектив nginx inc этого не решит.
Можно было бы отдавать url строку с аргументами в СУБД, для внутренней генерации динамического запроса в прямом вызове функции или вызове через тригер лог таблицы. Но так как такие данные уже логируются в nginx-access.log — эти инициативы избыточны. А с учетом того, что подобные действия могут увеличить нагрузку на планировщик базы, еще и вредны.
Sm
— Модули под nginx давно и успешно пишутся. К чему фанфары?
Большинство существующих аналогов это узкоспециализированные решения. В статье представлен разумный компромис скорости и гибкости!
— Работать через диск(client_body_in_file_only) — медленно!
Да прибудет с вами RAM Drive и пророк его — кэш файловой системы.
— Что с правами для пользователей?
Авторизация с plain http пробрасывается в постгрес. Там разруливаете встроенными средствами. В общем полный BackEnd.
— А шифрование?
Модуль ssl через конфиг nginx. На текущем этапе может не взлететь из-за сырости кода ngx_pgcopy.
Соединение nginx c postgres, при разнесении серверов, параноики могут прокинуть через ssh.
— Нахрена символы JS в отражении очков, в начале? Где JavaScript?
JS идёт на FrontEnd. А это уже совсем другое кино.
— Есть ли жизнь на клиенте с отключенным JS?
Как вы вероятно успели заметить ранее, в примерах, Postgres может в xml. Т.е. получить на выходе готовый HTML не составляет проблемы. Как с использованием спагетти кода, так и через xsl схемы.
Это ужасно. Тем не менее, всё будет хорошо. Вы всё правильно делаете.
— Как ресайзить картинки, паковать архивчики и считать траекторию лептонов на GPU?

И так, чтобы попроще.
Может, мне лучше поболтать с этим парнем, подумал я.
Не подходи к FastCGI!
Они только этого от нас и ждут.
Заманить нас в эту коробку,
Cпустить в подвал. Туда.
Говорим ngixу client_body_in_file_only on, берём в охапку $request_body_file и plperlu, с доступом к комадной строке. И адаптируем что-нить из:
— Это похоже на CGI. А CGI не безопасен!
Безопасность больше зависит от вашей грамотности, чем от применяемых технологий. Да. После вкручивания переменных окружения, это совместимо с CGI. Более того, это можно применить для мягкого перехода с CGI при минимальной перестройки скриптов. Соответственно, способ походит для эвакуации с большинства PHP решений.
Еще можно пофантазировать на тему распределенных вычислений(благодаря кластеризации PostgreSQL) и свободе выбора подходов к асинхронности. Но делать это, я конечно же не буду.
→ ngx_pgcopy
→ PostgreSQL COPY request
→ slim_middle_samples (примеры из статьи + сборка демонстрации)
Модуль еще в разработке, поэтому возможны проблемы со стабильностью. Ввиду еще не реализованного мной keep alive соединения в сторону backend, на роль сверхзвукового истребителя сие творение, пока еще, ограничено годно. README модуля вам в чтиво.
PS. На самом деле, CRUD без проблем реализуется через хранимые процедуры, либо по журналу на метод, к логам не применимо. Еще я метод DELETE в модуль забыл добавить.
В статье использованы кадры и цитаты из х/ф «Страх и ненависть в Лас-Вегасе» 1998г. Материалы применены исключительно с некоммерческими целями и в рамках стимулировании культурного, учебного и научного развития общества.

Внезапно, вокруг нас раздался ужасный бум… И весь WEB кишал этими статьями про LAMP…
Казалось, что они были написаны под любые нужды. Они разрастались и поглощали задачи для которых ранее пользовался perl, bash и даже С. Нет смысла говорить об этих статьях, подумал я. Все и так это знают.
У нас был пятый IE, немного Netscape, Opera и целое море разношёрстных cgi модулей на perl. Не то что бы это был необходимый стек технологий. Но если начал собирать дурь, становится трудно остановиться. Единственное что вызывало у меня опасение — это студент, употребляющий PHP. Нет ничего более беспомощного, безответственного и испорченного, чем это. Я знал, что рано или поздно мы перейдем и на эту дрянь.
В начале было не было
Когда-то JS между браузерами отличался как конь от пробки, а XMLHttpRequest возможен был исключительно через ActiveX. Выхода особо не было. Что на корню вырубало динамический веб. IE 6 казался революцией. Но если вы хотели кросплатформености — ваш путь пролегал через объемный MiddleWare. А большое количество статей по php, инструментов и сопутствующих новоиспеченных библиотек делали своё дело.
Проклятый php, начинаешь вести себя как деревенский пьяница из старинных ирландских романов, полная потеря основных двигательных функций, размытое зрение, деревянный язык, мозг в ужасе. Интересное состояние когда все видишь, но не в силах что-либо контролировать. Подходишь к задаче, чётко зная, где данные, где логика и где представление. Но на месте всё происходит не так. Тебя запутывает злобный лапшичный код, а ты думаешь: в чём дело, что происходит?...
Постепенно титанические плиты между браузерами начали сходится. Везде появился XMLHttpRequest и мечты о динамическом WEB с четким разделение по фронтам становились реальностью.
Конечно же, я пал жертвой повального увлечения. Обыкновенный уличный бездельник, который изучал все, что попадало под руку. В воздухе витали идеи о едином языке для Web разработки. Погоди, вот увидишь эти изменения в новом обличие, мужик.
— Давай Node.js посмотрим.
— Чего? Нет!
— Здесь нельзя останавливаться. Это толстый Middle.
— Садись.
Что за чушь они прут, не знаю сколько нужно писать на JavaScript чтобы найти сходство между Front, Middle и BackEnd? Это неподходящий вариант. Слишком толсто для выбранной цели.
Но, подобные мысли я оставил. Пришло понимания того, что забить гвоздь можно и отвёрткой, но если иногда дотягиваться до молотка, то процесс серьезно ускорится.
Я почувствовал чудовищный протест против всей ситуации.
Есть же СУБД, такие как PostgreSQL, позволяющие невообразимо оперировать данными через встраиваемые функции. Бизнес логика внутри базы! Настоящий BackEnd. Не нравится бизнес логика в СУБД и ей там не место? А такие прямые потоки данных нравится?
Попробуем разобраться, с тернистым движением данных на «прямых» потоках курильщика.
Первое с чем мы сталкиваемся — это постоянная перегонка данных в середину, по любому поводу. К тому же, эти данные могут быть совсем не окончательными и требоваться только для расчёта последующих запросов. Для обработки данных используются циклы. Процедурные циклы — не оптимизированы на многопоточность.
Множественность запросов в одной сессии к СУБД ведёт к неизбежному апофеозу кончины скорости — многопроходности по таблицам базы.

Для исключения этих факторов, логику приходится переносить ближе к данным, т.е. в СУБД!
И это наиболее оптимальный способ вывести скорость на новые величины!
Становление идеи
Со временем, браузеры научились полной динамической генерации интерфейса. Открылась ачивка чёткого разделения по фронтам данных и представления. Появилась полноценная возможность гонять от сервера к клиенту преимущественно данные. Оставался только один вопрос: Что делать со средним слоем? Как его минимизировать исключительно до транспортной функции с элементами простого роутинга запросов по коллекциям на стороне сервера.
Эти наивные разработчики полагали, что можно обрести душевный мир и понимание, изучив один из оплотов старого Middle, а результат — поколение толстого слоя, так и не понявших главную, старую как мир ошибку IT индустрии. Упустив убеждение, что Кто-то или Что-то может обладать фатальным недостатком.
К тому времени начал работать nginx, и уже не оставалось вопросов с чем нужно готовить предполагаемую мысль. Это больше была не идея. Теперь это было состязание программиста с ленью. Сама мысль, попытаться как-то описать архитектуру традиционным образом, через apache, казалась абсурдной.
В 2010 на github подоспел модуль ngx_postgres. Задание запросов в конфигурационном файле и выдача в JSON/CSV/ЧТОТОЕЩЕ.
Для конфигурации достаточно было простого SQL кода. Сложный можно было обернуть в функцию, которая потом вызывалась из конфига.
Но этот модуль не умел загружать тело http запроса в СУБД. Что накладывало серьезные ограничения на данные, оправляемые к серверу. URL же явно подходил только для фильтрации запроса.
Cериализация выходных данных проводилась средствами самого модуля. Что, с высоты моего дивана, казалось бессмысленным переводом ОЗУ — сериализовать умел и PostgreSQL.
Возникла мысль поправить, переписать. Я стал копать в коде этого модуля.
После бессонной ночи поисков многим хватило бы ngx_postgres. Нам нужно было что-то посильнее.
Мадам, сэр, детка, или как вас… вариант есть, вот, держите ngx_pgcopy.
NGX_PGCOPY
После эксперимента экспериментов и анализа анализов, возникла мысль переписать всё практический с нуля. Для ускорения загрузки были выбраны запросы COPY, которые перегоняют данные в базу на порядок быстрее инсертов и содержат собственный парсер. К сожалению, ввиду скудности описания подобного типа запросов, сложно сказать как будет вести СУБД при особо массовых вызовах данного метода.
Мир безумен в любом направлении и в любое время, с ним сталкиваешься постоянно. Но было удивительное, вселенское ощущение правильности всего того, что мы делали.
Вместе с COPY-requests мы автоматом получили сериализацию в CSV по обоим направлениям, что избавило от необходимости заботы о преобразовании данных.
Начнём с примитива, отправка и получение всей таблицы в CSV по URL:
http://some.server/csv/some_tableCSV часть import.export.nginx.conf
pgcopy_server db_pub "host=127.0.0.1 dbname=testdb user=testuser password=123";
location ~/csv/(?<table>[0-9A-Za-z_]+) {
pgcopy_query PUT db_pub "COPY $table FROM STDIN WITH DELIMITER as ';' null as '';";
pgcopy_query GET db_pub "COPY $table TO STDOUT WITH DELIMITER ';';";
}

На текущий момент PostgreSQL не может в JSON и XML через COPY STDIN. Я надеюсь, что наступит день смирения с табами в код-стиле слона и я, или кто-нить, найдёт время и прикрутит этот функционал к COPY методам. Тем более, что в СУБД обработка этих форматов уже присутствует.
Однако! Способ применения здесь и сейчас всё же есть! Конфигурируем nginx на client_body_in_file_only on c последующим использованием в запросе переменной $request_body_file и передачей её в функцию pg_read_binary_file…
Разумеется придется это обернуть в COPY метод, т.к. работать будет только с моим мопедом, по причине полного body_rejecta у ngx_postgres. Других мопедов я пока не встречал, а ngx_pgcopy еще не созрел для дополнительного функционала.
Рассмотрим как это выглядит для json/xml в import.export.nginx.conf
client_body_in_file_only on;
client_body_temp_path /var/lib/postgresql/9.6/main/import;
location ~/json/(?<table>[0-9A-Za-z_]+) {
pgcopy_query PUT db_pub
"COPY (SELECT * FROM import_json_to_simple_data('$request_body_file'))
TO STDOUT;";
pgcopy_query GET db_pub
"COPY (SELECT '['||array_to_string(array_agg(row_to_json(simple_data)),
',')||']' FROM simple_data) TO STDOUT;";
}
location ~/xml/(?<table>[0-9A-Za-z_]+) {
pgcopy_query PUT db_pub
"COPY (SELECT import_xml_to_simple_data('$request_body_file') TO STDOUT;";
pgcopy_query GET db_pub
"COPY (SELECT table_to_xml('$table', false, false, '')) TO STDOUT;";
}
Да, client_body_temp_path придётся выставить в директорию базы, а пользователю дать ALTER SUPERUSER. В ином случаем Postgres отправит наши желания за горизонт.
Экспорт, представленный в методах GET, использует встроенные функции, включённые в стандартную поставку Postgres. Все COPY выводят в STDOUT, на случай если мы захотим известить клиента о результатах этих действий. Импорт в фиксированную таблицу(simple_data) выглядит немного объемнее экспорта, посему вынесен в определяемые пользователем процедуры СУБД.
Часть из 1.import.export.sql для импорта в фиксированную таблицу
CREATE OR REPLACE FUNCTION import_json_to_simple_data(filename TEXT)
RETURNS void AS $$
BEGIN
INSERT INTO simple_data
SELECT * FROM
json_populate_recordset(null::simple_data,
convert_from(pg_read_binary_file(filename), 'UTF-8')::json);
END;
$$ LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION import_xml_to_simple_data(filename TEXT)
RETURNS void AS $$
BEGIN
INSERT INTO simple_data
SELECT (xpath('//s_id/text()', myTempTable.myXmlColumn))[1]::text::integer AS s_id,
(xpath('//data0/text()', myTempTable.myXmlColumn))[1]::text AS data0
FROM unnest(xpath('/*/*',
XMLPARSE(DOCUMENT convert_from(pg_read_binary_file(filename), 'UTF-8'))))
AS myTempTable(myXmlColumn);
END;
$$ LANGUAGE plpgsql;
Функция импорта с гибким выбором таблицы для JSON особо не отличается от приведённой выше. А вот подобная гибкость для XML порождает более монструозное поделие.
Часть из 1.import.export.sql для импорта в произвольную таблицу
CREATE OR REPLACE FUNCTION import_vt_json(filename TEXT, target_table TEXT)
RETURNS void AS $$
BEGIN
EXECUTE format(
'INSERT INTO %I SELECT * FROM
json_populate_recordset(null::%I,
convert_from(pg_read_binary_file(%L), ''UTF-8'')::json)',
target_table, target_table, filename);
END;
$$ LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION import_vt_xml(filename TEXT, target_table TEXT)
RETURNS void AS $$
DECLARE
columns_name TEXT;
BEGIN
columns_name := (
WITH
xml_file AS (
SELECT * FROM unnest(xpath(
'/*/*',
XMLPARSE(DOCUMENT
convert_from(pg_read_binary_file(filename), 'UTF-8'))))
--read tags from file
), columns_name AS (
SELECT DISTINCT (
xpath('name()',
unnest(xpath('//*/*', myTempTable.myXmlColumn))))[1]::text AS cn
FROM xml_file AS myTempTable(myXmlColumn)
--get target table cols name and type
), target_table_cols AS ( --
SELECT a.attname, t.typname, a.attnum, cn.cn
FROM pg_attribute a
LEFT JOIN pg_class c ON c.oid = a.attrelid
LEFT JOIN pg_type t ON t.oid = a.atttypid
LEFT JOIN columns_name AS cn ON cn.cn=a.attname
WHERE a.attnum > 0
AND c.relname = target_table --'log_data'
ORDER BY a.attnum
--prepare cols to output from xpath
), xpath_type_str AS (
SELECT CASE WHEN ttca.cn IS NULL THEN 'NULL AS '||ttca.attname
ELSE '((xpath(''/*/'||attname||'/text()'',
myTempTable.myXmlColumn))[1]::text)::'
||typname||' AS '||attname
END
AS xsc
FROM target_table_cols AS ttca
)
SELECT array_to_string(array_agg(xsc), ',') FROM xpath_type_str
);
EXECUTE format('INSERT INTO %s SELECT %s FROM unnest(xpath( ''/*/*'',
XMLPARSE(DOCUMENT convert_from(pg_read_binary_file(%L), ''UTF-8''))))
AS myTempTable(myXmlColumn)', target_table, columns_name, filename);
END;
$$ LANGUAGE plpgsql;
В приведенных примерах, наименование table_name в импортируемом файле не влияет на целевую таблицу назначения, заданную в nginx. Применение иерархии xml документа table_name/rows/cols обусловлено исключительно симметрией со встроенной функцией table_to_xml.
Cами наборы данных…
simple_data_table.sql
CREATE TABLE simple_data (
s_id SERIAL,
data0 TEXT
);
data.csv
0;zero
1;one
data.json
[ {"s_id": 5, "data0": "five"},
{"s_id": 6, "data0": "six"} ]
data.xml
<simple_data xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<row>
<s_id>3</s_id>
<data0>three</data0>
</row>
<row>
<s_id>4</s_id>
<data0>four</data0>
</row>
</simple_data>
Мы тут отдалились, поэтому вернёмся к истокам чистого COPY…
Ладно. Вероятно, это единственный выход. Только давай убедимся, что я всё понял верно. Ты хочешь отправлять данные между сервером и клиентом без обработки заливая их в таблицу?

Думаю я поймал страх.
Ерунда. Мы пришли, чтобы найти MidleWare мечту.
И теперь, когда мы прямо в её вихре, ты хочешь уйти?
Ты должен понять, мужик, мы нашли главный нерв.
Да, это почти так! Это отказ от CRUD.
Разумеется, многих возмутит как какой-то тип в паре предложений перечеркивает результаты работы Калифорнийских умов, стилизуя коротенькую статейку под диалоги наркоманского фильма. Однако, ещё не всё потеряно. Есть вариант передавать модификатор данных вместе с самими данными. Что всё равно уводит от привычной архитектуры RESTful.
К тому же, иногда, а когда и почаще, теоретические изыскания разбиваются о скалы реальности. Такими скалами является всё та же злополучная многопроходность. На деле, если вы допускаете изменение ряда позиций пользовательского документа, то вероятно, что данные изменения будут включать методы нескольких типов. В результате, для отправки в базу одного документа, потребуется провести несколько отдельных http запросов. А каждый http запрос, породит свою модификацию базы и свой проход по таблицам. Поэтому качественный прорыв требуют кардинальных изменений по отказу от классического понимания CRUD методов. Прогресс требует жертв.
Тут у меня возникли подозрения, что можно найти более интересное решение. Нужно только немного поэкспериментировать и подумать…
Точка входа
К тому времени, как я задался этим вопросом,
Никого, кто бы мог на него ответить еще не было рядом.
Да-да, я снова начинаю…
Мы отправляем данные в средний слой, который без обработки пересылает их в базу.
СУБД их парсит и кладёт в таблицу, выполняющую роль журнала/лога. Регистрация всех входных данных.
Ключевой момент, вот он! Журналируемость/логируемость потока данных из коробки! А дальше дело за триггерами. В них, исходя из бизнес логики решаем: обновлять, добавлять или делать что-либо еще. Прикручивание модификатора данных не является обязательным, но может быть приятным бонусом.
Это приводит нас к достаточности использования HTTP методов GET и PUT. Попробуем смоделировать как это применять. Для начала определимся с разницей между журналами и логом. Ключевую разницу выделяем через приоритет между ценностью маршрута изменения и конечным значением. Первый критерий отнесём к логам, второй — к журналам.
Несмотря на приоритет конечной цели в журналах, маршрут всё же необходим. Что приводит нас к разделению подобных таблиц на две части: результат и сам журнал.
На что это можно натянуть? Логи: маршрут автомобиля, перемещение материальных ценностей и т.п. Журналы: остатки на складах, последний комментарий и иные последние мгновенные состояния данных.
Код из 2.jrl.log.sql:
Таблицы
CREATE TABLE rst_data ( --Output/result table 1/2
s_id SERIAL,
data0 TEXT, --Operating Data
data1 TEXT, --Operating Data
);
--Service variable with prefix s_, ingoring input value, it will be setting from trigers
CREATE TABLE jrl_data ( --Input/journal table 2/2
s_id SERIAL, --Service variable, Current ID of record
s_cusr TEXT, --Service variable, User name who created the record
s_tmc TEXT, --Service variable, Time when the record was created
p_trid INTEGER, --Service variable, Target ID/Parent in RST_(result) table,
-- if exists for modification
data0 TEXT,
data1 TEXT,
);
CREATE TABLE log_data ( --Input/output log table 1/1
s_id SERIAL,
s_cusr TEXT,
s_tmc TEXT,
pc_trid INTEGER, --Service variable, Target ID(ParentIN/ChilrdenSAVE)
-- in CURRENT table, if exists for modification
data0 TEXT,
data1 TEXT,
);
Триггер для журналов
CREATE OR REPLACE FUNCTION trg_4_jrl() RETURNS trigger AS $$
DECLARE
update_result INTEGER := NULL;
target_tb TEXT :='rst_'||substring(TG_TABLE_NAME from 5);
BEGIN
--key::text,value::text
DROP TABLE IF EXISTS not_null_values;
CREATE TEMP TABLE not_null_values AS
SELECT key,value from each(hstore(NEW)) AS tmp0
INNER JOIN
information_schema.columns
ON information_schema.columns.column_name=tmp0.key
WHERE tmp0.key NOT LIKE 's_%'
AND tmp0.key <> 'p_trid'
AND tmp0.value IS NOT NULL
AND information_schema.columns.table_schema = TG_TABLE_SCHEMA
AND information_schema.columns.table_name = TG_TABLE_NAME;
IF NEW.p_trid IS NOT NULL THEN
EXECUTE (WITH keys AS (
SELECT (
string_agg((select key||'=$1.'||key from not_null_values), ','))
AS key)
SELECT format('UPDATE %s SET %s WHERE %s.s_id=$1.p_trid', target_tb, keys.key, target_tb)
FROM keys)
USING NEW;
END IF;
GET DIAGNOSTICS update_result = ROW_COUNT;
IF NEW.p_trid IS NULL OR update_result=0 THEN
IF NEW.p_trid IS NOT NULL AND update_result=0 THEN
NEW.p_trid=NULL;
END IF;
EXECUTE format('INSERT INTO %s (%s) VALUES (%s) RETURNING s_id',
target_tb,
(SELECT string_agg(key, ',') from not_null_values),
(SELECT string_agg('$1.'||key, ',') from not_null_values))
USING NEW;
END IF;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
Триггер для логов
CREATE OR REPLACE FUNCTION trg_4_log() RETURNS trigger AS $$
BEGIN
IF NEW.pc_trid IS NOT NULL THEN
EXECUTE (
WITH
str_arg AS (
SELECT key AS key,
CASE WHEN value IS NOT NULL OR key LIKE 's_%' THEN key
ELSE NULL
END AS ekey,
CASE WHEN value IS NOT NULL OR key LIKE 's_%' THEN 't.'||key
ELSE TG_TABLE_NAME||'.'||key
END AS tkey,
CASE WHEN value IS NOT NULL OR key LIKE 's_%' THEN '$1.'||key
ELSE NULL
END AS value,
isc.ordinal_position
FROM each(hstore(NEW)) AS tmp0
INNER JOIN information_schema.columns AS isc
ON isc.column_name=tmp0.key
WHERE isc.table_schema = TG_TABLE_SCHEMA
AND isc.table_name = TG_TABLE_NAME
ORDER BY isc.ordinal_position)
SELECT format('WITH upd AS (UPDATE %s SET pc_trid=%L WHERE s_id=%L)
SELECT %s FROM (VALUES(%s)) AS t(%s)
LEFT JOIN %s ON t.pc_trid=%s.s_id',
TG_TABLE_NAME, NEW.s_id, NEW.pc_trid,
string_agg(tkey, ','),
string_agg(value, ','),
string_agg(ekey, ','),
TG_TABLE_NAME, TG_TABLE_NAME)
FROM str_arg
) INTO NEW USING NEW;
NEW.pc_trid=NULL;
END IF;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
Приведённые примеры не умеют очищать ячейки, т.к. для этого нужно прикрутить служебные значения. А они сильно зависят от способа импорта. В одних случаях это может быть любой тип с абсолютно произвольным содержанием. В других же, только тип целевого столбца с вероятным признаком по выходу из диапазона.
Триггеры вызываются в порядке текстовой сортировки по имени. Я рекомендую использовать префиксы trg_N_. От trg_0 до trg_4 считать служебными, обслуживающими только целостность общей логики и входящую фильтрацию. А с 5 до 9 использовать для прикладных расчетов. Девять триггеров будет достаточно всем!
Так же стоит сказать, что их нужно устанавливать на BEFORE INSERT. Так как в случае c AFTER, служебная переменная NEW будет положена в таблицу до модификации триггером. В принципе, если целостность в некоторый степени не критична, подобное решение может быть хорошим ускорителем пользовательских запросов, проходящих через журнал. Это не повлияет на значения результирующей таблицы.
Еще, при AFTER, мы не сможем вернуть ошибку, если пользователь не имеет прав на изменение. Но корректный FrondEnd и не должен проводить запрещенные сервером операций. Соответственно, подобное поведения скорее свойственно взлому, который мирно будет зафиксирован в журнале.
ProФильтрацию и маршрутиризацию

Маршрутиризируем URL стандартными средствами nginx. Тем же способом фильтруем запрос от инъекций. После удвоения проблем, код похожий на результат асимметричного шифрования загоняем в директиву map nginx.conf для получения удобоваримого и безопасного SQL запроcа. Которым, в последующем, фильтруем данные.
Есть некоторые сложности. Они вызваны отсутствием в nginx синтаксиса регулярок для множественной замены по типу sed s/bad/good/g. В результате мы…
Попадаем прямо в гущу этого ебаного террариума. И ведь у кого-то хватаем ума писать эти чёртовы выражения! Еще немного и они разорвут мозг в клочья.
до 4х фильтров эквивалентности по URL
http://some.server/csv/table_name/*?col1=value&col2=value&col3=value&col4=valueHorrowshow part of filters.nginx.conf
#Составляем фильтр SQL
map $args $fst0 {
default "";
"~*(?<tmp00>[a-zA-Z0-9_]+=)(?<tmp01>[a-zA-Z0-9_+-.,:]+)(:?&(?<tmp10>[a-zA-Z0-9_]+=)(?<tmp11>[a-zA-Z0-9_+-.,:]+))?(:?&(?<tmp20>[a-zA-Z0-9_]+=)(?<tmp21>[a-zA-Z0-9_+-.,:]+))?(:?&(?<tmp30>[a-zA-Z0-9_]+=)(?<tmp31>[a-zA-Z0-9_+-.,:]+))?(:?&(?<tmp40>[a-zA-Z0-9_]+=)(?<tmp41>[a-zA-Z0-9_+-.,:]+))?" "$tmp00'$tmp01' AND $tmp10'$tmp11' AND $tmp20'$tmp21' AND $tmp30'$tmp31' AND $tmp40'$tmp41'";
}
#Проверяем на корректность
map $fst0 $fst1 {
default "";
"~(?<tmp0>(:?[a-zA-Z0-9_]+='[a-zA-Z0-9_+-.,:]+'(?: AND )?)+)(:?( AND '')++)?" "$tmp0";
}
map $fst1 $fst2 {
default "";
"~(?<tmp0>[a-zA-Z0-9_+-=,.'' ]+)(?= AND *$)" "$tmp0";
}
#Если контроль корректности пройден, дописываем WHERE
map $fst2 $fst3 {
default "";
"~(?<tmp>.+)" "WHERE $tmp";
}
server {
location ~/csv/(?<table>result_[a-z0-9]*)/(?<columns>\*|[a-zA-Z0-9,_]+) {
pgcopy_query GET db_pub
"COPY (select $columns FROM $table $fst3) TO STDOUT WITH DELIMITER ';';";
}
}
C фильтрацией кириллиц в URL, через конфиг nginx, тоже не всё гладко — нужна нативная конвертация из одной переменной с base64 в другую, с человеко читаемым текстом. На текущий момент, такой директивы нет. Что достаточно странно, ибо в исходниках nginx, функции перекодировки присутствуют.
Как-нить обязательно соберусь с мыслями и ликвидирую это упущение, как и проблему с sed, если коллектив nginx inc этого не решит.
Можно было бы отдавать url строку с аргументами в СУБД, для внутренней генерации динамического запроса в прямом вызове функции или вызове через тригер лог таблицы. Но так как такие данные уже логируются в nginx-access.log — эти инициативы избыточны. А с учетом того, что подобные действия могут увеличить нагрузку на планировщик базы, еще и вредны.
Smokeall FAQ
— Модули под nginx давно и успешно пишутся. К чему фанфары?
Большинство существующих аналогов это узкоспециализированные решения. В статье представлен разумный компромис скорости и гибкости!
— Работать через диск(client_body_in_file_only) — медленно!
Да прибудет с вами RAM Drive и пророк его — кэш файловой системы.
— Что с правами для пользователей?
Авторизация с plain http пробрасывается в постгрес. Там разруливаете встроенными средствами. В общем полный BackEnd.
— А шифрование?
Модуль ssl через конфиг nginx. На текущем этапе может не взлететь из-за сырости кода ngx_pgcopy.
Соединение nginx c postgres, при разнесении серверов, параноики могут прокинуть через ssh.
— Нахрена символы JS в отражении очков, в начале? Где JavaScript?
JS идёт на FrontEnd. А это уже совсем другое кино.
— Есть ли жизнь на клиенте с отключенным JS?
Как вы вероятно успели заметить ранее, в примерах, Postgres может в xml. Т.е. получить на выходе готовый HTML не составляет проблемы. Как с использованием спагетти кода, так и через xsl схемы.
Это ужасно. Тем не менее, всё будет хорошо. Вы всё правильно делаете.
— Как ресайзить картинки, паковать архивчики и считать траекторию лептонов на GPU?

И так, чтобы попроще.
Может, мне лучше поболтать с этим парнем, подумал я.
Не подходи к FastCGI!
Они только этого от нас и ждут.
Заманить нас в эту коробку,
Cпустить в подвал. Туда.
Говорим ngixу client_body_in_file_only on, берём в охапку $request_body_file и plperlu, с доступом к комадной строке. И адаптируем что-нить из:
CREATE OR REPLACE FUNCTION foo(filename TEXT) RETURNS TEXT AS $$
return `/bin/echo -n "hello world!"`;
$$ LANGUAGE plperlu;
— Это похоже на CGI. А CGI не безопасен!
Безопасность больше зависит от вашей грамотности, чем от применяемых технологий. Да. После вкручивания переменных окружения, это совместимо с CGI. Более того, это можно применить для мягкого перехода с CGI при минимальной перестройки скриптов. Соответственно, способ походит для эвакуации с большинства PHP решений.
Еще можно пофантазировать на тему распределенных вычислений(благодаря кластеризации PostgreSQL) и свободе выбора подходов к асинхронности. Но делать это, я конечно же не буду.
Ссылки
→ ngx_pgcopy
→ PostgreSQL COPY request
→ slim_middle_samples (примеры из статьи + сборка демонстрации)
WARRNING
Модуль еще в разработке, поэтому возможны проблемы со стабильностью. Ввиду еще не реализованного мной keep alive соединения в сторону backend, на роль сверхзвукового истребителя сие творение, пока еще, ограничено годно. README модуля вам в чтиво.
PS. На самом деле, CRUD без проблем реализуется через хранимые процедуры, либо по журналу на метод, к логам не применимо. Еще я метод DELETE в модуль забыл добавить.
В статье использованы кадры и цитаты из х/ф «Страх и ненависть в Лас-Вегасе» 1998г. Материалы применены исключительно с некоммерческими целями и в рамках стимулировании культурного, учебного и научного развития общества.









