Комментарии 22
1.5 месяца на 100 Гб обучающий файл, модели BagOfWords и Skipgram, на 24-х ядрах
Вот тут вы что-то недоговариваете…
Предположу что 1.5 месяца вы обучаете модель если исходные документы вытягиваете в 1 строчку и проходите по ним гигантским окном слов в 15+
Грешен, сам ставил похожие опыты. Обучение на ~170Гб текста (книги, википедия, поисковые запросы — все вперемешку) одной модели с окном 5-7 слов и размером вектора 500 занимало не больше недели на макбуке.
P.S.
Макбук кипел и его было жалко

2.5 млн. токенов словарь ужимается до 256 элементов вектора действительных чисел;
— это принудительно сжать, типа k-mean-ом? Или более хитро?
Алгоритм w2v ужимает матрицу совстречаемости токенов в 2.5M x 256, при этом сохраняя меру семантической близости. Если эспрессо и капучино часто встречаются в похожих контекстах, то косинусное расстояние между их w2v-векторами будет заметным (чем ближе токены по контекстам, тем ближе к единице).
P.S. word2vec предполагает контекстную близость, а семантическая является приятным побочным эффектом, выражаемым фразой:
A word is known by the company it keeps (Firth, J. R. 1957)
Просто тем, кто не сталкивался с w2v, может показаться, что машина понимает смысл слов. А по факту мы имеем дело с голой математикой, даже и с лингвистикой не связанной напрямую.
Но текст является глубоко вторичным к смыслам и первообразам, которые хранятся у нас в голове совершенно непонятно как. Не зря, читая художественную литературу нам так просто понять значение слова, употреблённого в переносном смысле, просто нарисовав в голове картинку-образ. Машины к этому пока даже не подступились.
Не говоря уже о том, что следуя теореме Гёделя о неполноте, можно сделать вывод о том, что наше мышление не алгоритмично своей природе. (замечательная книга на тему — Роджер Пенроуз. Новый ум короля)
Можете объяснить, почему решили не делать нормализацию текста и считать на базовых формах?
Но главное — такие методы как LSA, LDA и им подобные очень плохо себя чувствуют на больших словарях, а потому для их использования проводить нормализацию, отсекать низкочастотные слова (а всякие коды, имена собственные, жаргонизмы — это очень сильные признаки) необходимо, и это — вынужденная мера, от бедности.
Здесь мы можем себе позволить работать с полным словарём.
Добрый день, спасибо за объемный пост. Мы пару тройку лет назад использовали Max Entropy (и эту библиотеку) классификаторы, для авто классификации юр текстов. В целом тогда это было очень даже перспективное направление.
Скажите а не знакомы ли вам техники классификации когда нужно выбрать не одну а несколько категорий, например фильмы могут быть комедиями и мелодрамами одновременно? Заранее благодарен.
Сергей, добрый день.
Затронули очень болезненную для меня тему.
Дико извиняюсь что написал ниже много букв, но без такой вводной не смогу получить правильного ответа.
У нас текущий бизнес процесс сильно завязан на классификацию мастер-данных (справочников), если чуть детальней-то речь про работу с вином: ежедневно приходит массив грязных зашумленных данных от внешних поставщиков информации о продажах вин в крупнейших розничных сетях по всей России с детализацией до точки продаж. Речь не только про продажи Российских вин, а о всех винах вообще (со всего мира).
Операторы получают новые вариации названий вин ежедневно и должны их классифицировать, т.е. правильно привязать в справочниках новые объекты на вина заведенный в стандартах нашей компании (а если не нашлось ничего похожего то создать такой класс и привязать к этому созданному)
Естественно поток информации настолько велик, что приходится задейстовать машинное обучение: там где модель уверенна выше чем на 99%, то классификация происходит автоматически, там где модель уверенна ниже- она участвует в системе в роли рекомендательного алгоритма с которым оператор либо соглашается либо нет.
Итого сейчас у нас 31925 классов, из них пустых (то о чем Вы писали -не разметили еще ассесоры)= 1761
Дисбаланс классов на картинке ниже

Отличие от классических задач текст-майнинга в следующем:
Вина именуются в системах наших сетевых ритейлеров чаще всего на кириллице как правило из франко-итальянских словоформ с "трудностями перевода" — где-то двойные буквы, где то одинарные(напр. количество букв "с" подряд может быть в любом месте произвольным: Вино игристое Ламбруско ТМ Массимо Висконти бел.слад. 0,75*6 Италия /Аква Вита ТК/)-решается регулярками
Длина строки при вводе в систему у сетевых ритейлеров ограничена и их операторы что бы уместиться не теряя общего смысла начинают сокращать (например приходит к нам такой вот треш: "Вин.ПР.РОБ.РИБ.Д.ДУЭ.ДО кр.сух.0.75л" который становится у нас в классе "Вино Протос Робле Рибера дель Дуэро кр сух 0,75")- решается Гуглом и вангованием на стеклянном шаре с привлечением Астрологов
Очень много шума в тексте (импортеры, сетевой артикул и т.д.) -решается поддержкой списка стоп-слов
Слияния слов (AVESвиноМЕРЛО МаулеВелле кр.сух.0.75л)-решается регулярками
Разная степень сокращений ключевых для моделей термов ({красн, кр, крас};{п/сл, полусл, п-слад},{крпсл}) — решается регулярками
- Разная степень сокращений важных для моделей термов (Молоко любимой женщины; Мол.люб.жен...) — тут стеммер Портера приказал долго жить (из-за вышеописанных проблем), писал свой алгоритм обучения по термам, который рекурсивно ищет цепочку предок-наследник для термов с высокой степенью вероятности сокращенных до своих наследников и выдает на выходе такой вот справочник автозамены — "взять term и заменить на abbr отбросив цепочки с неоднозначными вариантами сокращений (там где может быть несколько разных предков)":
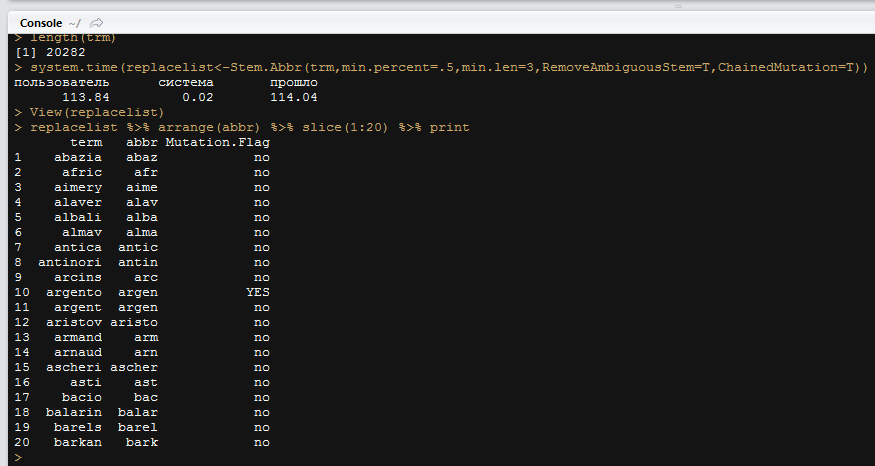

Далее по классике: токенизация, document-term matrix, tfidf, и удаление sparce-термов которые встречаются лишь в одном документе (не важно-в обучающей или предсказательной части матрицы).
И тут еще одна проблема: высокочастотные термы (красное, белое, розовое, сладкое, полусладкое, сухое, 0.75, 0.7, и т.д.) которые по понятным причинам имеют самый низкий tfidf оказывают решающую роль в классификации: если в векторном представлении бренды/винодельни или провиции произростания совпали но цвет вина или емкость оказались другими. то последствия такой ошибки классификации высоки — это мастер-данные к которым привязываются в системе продажи (в виде большого числа транзакций) и одна ошибка в цвете/емкости/сахарности транслируется многократно в отчетности.
Поэтому ничего не остается как такие ключевые высокочастотные термы с tfidf стремящимся к нулю докручивать до значений = 10000, что бы их вес был решающим.
Далее уже алгоритмы классификации: один — свой самописный (который возвращает еще и меру сходства с классом) и еще LIBLINEAR
Собственно сам вопрос:
можно ли из вышеописанных алгортимов Вашей статьи взять какую то часть на вооружение и улучшить текущий процесс с учетом вышеописанных проблем?
Вашу задачу я бы решал через расстояние редактирования (Левенштейна). То есть, есть полные названия вин, производителей, объёмы, градусы и другая должнествующая быть информация. Есть некий код, который пришёл из региона и который и человеку не всегда легко разобрать. Следует высчитать расстояние редактирования для всех обязательных полей и просуммировать результаты. Чем меньше сумма, тем лучше. Значит — нашлись все необходимые поля с хорошей достоверностью. Первую часть проблемы — взаимное расположение значимой информации мы уже сняли, не важно, где указан, к примеру, объём — важно, что он нашёлся.
Расстояние редактирования вычислять по словам (ну, или тому, что на них похоже), при этом:
1. штраф за вставку/удаление слов в крайних позициях — минимален (нулевой). Это позволяет нам искать нужные соответствия по всему тексту, вне зависимости от его фактического расположения;
2. штраф за удаление/вставку внутри последовательности — высокий (мол люб жен — не должен транслироваться в молодой женьшень, к примеру. Люб — значимое слово, его не просто так туда написали).
3. Стоимость замены слов. Если слова похожи на сокращения (укороченная первая часть слова, может быть с точкой), похожи на опечатки, на кривую транслитерацию — то штраф за такую замену низкий, если не похожи — высокий. При этом, факт похожести слова на сокращение, опечатку или кривую транслитерацию определяется тем же алгоритмом расстояния редактирования, но уже не на словах, а на буквах.
Хорошо то, что можно взять уже размеченные вручную соответствия, прогнать их указанным алгоритмом расстояния редактирования, и автоматически набрать словарь типовых сокращений, опечаток, транслитерации. И даже определить размеры штрафов. То есть — получается классическая задача машинного обучения на размеченной выборке.
«Критерий оптимизации – максимум площади под произведением полноты на точность на отрезке [0;1] при этом, выдача классификатора не попадающая в отрезок считается ложным срабатыванием.»
Каким образом задавали такой objective для XGBoost, писали пользовательскую целевую функцию?
R = a1 + a2C1 + a3C2 + a4C3, где C1,C2,C3 — выходы соотвествующих классификаторов, а a1-4 — параметры.
При этом, один из классификаторов — это сигнатурный, с очень узкой рабочей областью (допустим это C2).
Регрессия получается вида
R = -10 + 0.6C1 + 21C2 + 1.1C3
Узкая область сигнатурного классификатора растянута, и сдвинута примерно так, что бы соответствовать отрезку [0;1]. Без регрессии комбинировать узкий сигнатурный, широкий xgboost и средний шаблонный было бы трудно
1) геотаги, имена собственные и уникальные термины («стелс технология») — лучше характеризуют текст, чем слова общего назначения. Почему бы не сделать на текст 2 вектора: ключевых понятий/признаков (размерностью 100 чисел) и вектор обычных слов(все остальное)? Проверять спецвектор, если похож более, чем на 50%, брать в проверку полный вектор.
2) «Чтобы построить куличик — не обязательно просеивать три Камаза песка». Возможно, ваш алгоритм таскает порожний песок, вместо полезных камушков ;) И входящий поток данных избыточный, и его нужно грубово и "_не_ дорого" отфильтровать до подачи на наиболее ресурсоемкую часть алгоритма классификации. Например: откинуть окончания, частицы и предлоги. (-5% к объему текста), а там и слова можно на 2-3 байта заменить. Потому что в русском языке только немногим более 1 тысячи глаголов и 5 тысяч наиболее употребимых существительных. А образованный человек владеет 20-50 тыс. специализированных понятий (Они все есть в «политехническом словаре» :) ).
PS И интересно, как вы боретесь с изоморфизмом?
красива, красивый, красивой, красивому — для вас 4 терма или один?
2.1 Необратимая потеря информации при лемматизации/стемминге не нужна, ведь ресурсов достаточно для обработки с полным словарём. При этом, морфология сама по себе является сильным признаком для определённого вида текстов.
2.2 Кто сказал, что мы зацикливаемся только на русском языке? У меня целый раздел посвящён генерации семантических ядер на других языках.
Да, это 4-ре разных терма.
Технологический стек классификации текстов на естественных языках