Комментарии 25
Что такое пейпер?

котодемон



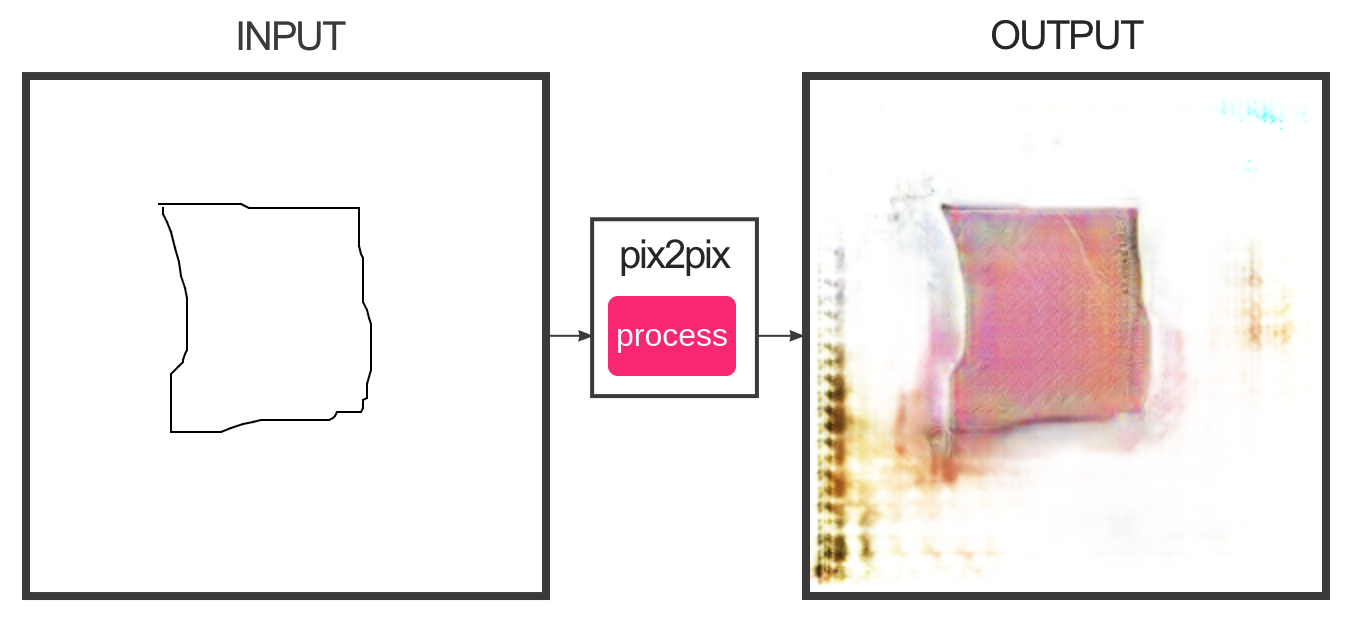
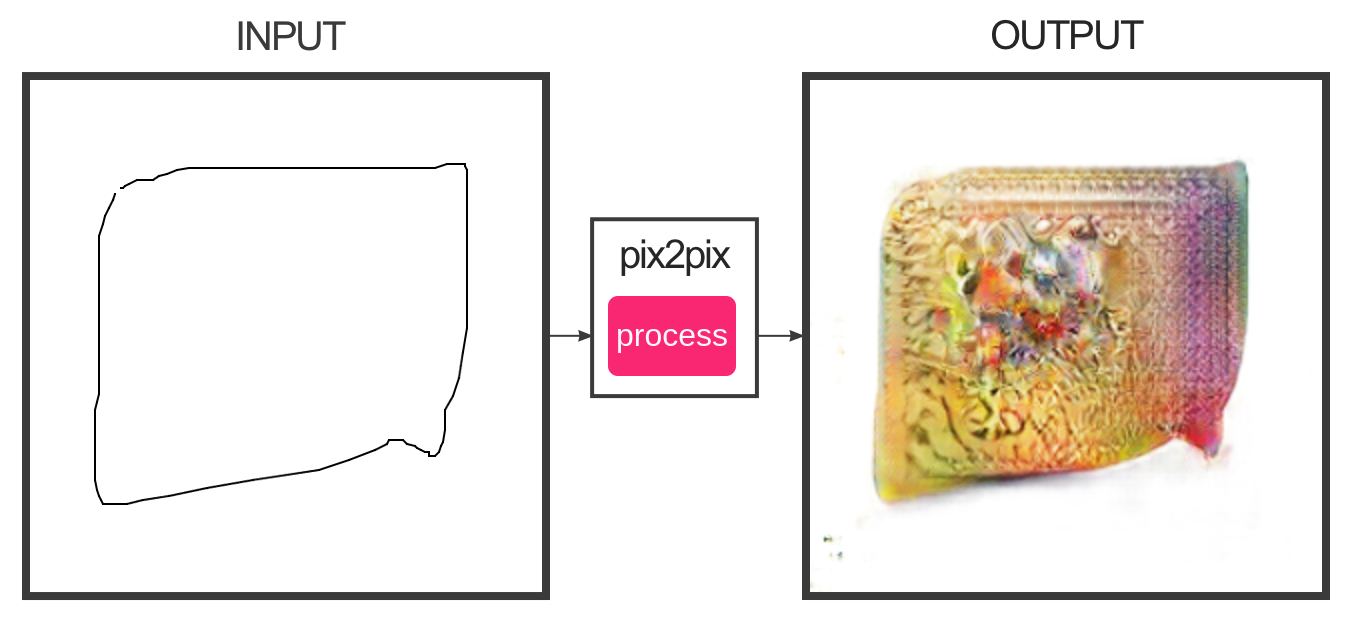
Качество картинок напрямую зависит от того какой по размеру объект. Чем меньше, тем больше алгоритм старается рисовать за его пределами.
Пример






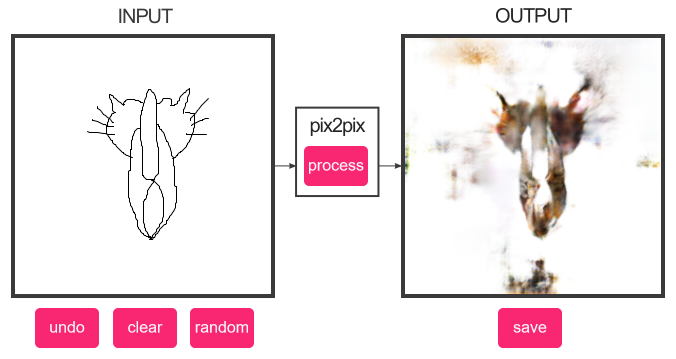
Надо ребра передавать, мне кажется. Прогони через какой-нибудь Canny edge detector?


Как вы вставили картинку в поле для рисования?
НЛО прилетело и опубликовало эту надпись здесь

Прошу меня извинить, не удержался((
эротика 18+


Репродукция картины известного художника.
Они тренируют модель на патчах 70x70, а потом применяют на больших картинках через full convolution. Забавно, что 70x70 дает в среднем результаты лучше, чем делать сразу на всей картинке 256x256 целиком.Судя по «пейпер», это не совсем так. Речь идет об архитектуре дискриминатора, а не об обучении модели на маленьких картинках. Смысл — если сравнивать фейк и рил попиксельно, то результат будет хуже, чем если сравнивать изображения, нарезанные на патчи 70х70. Там это называет receptive field sizes of the discriminator.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Pix2Pix: Как работает генератор кошечек