Комментарии 27
немного в сторону.
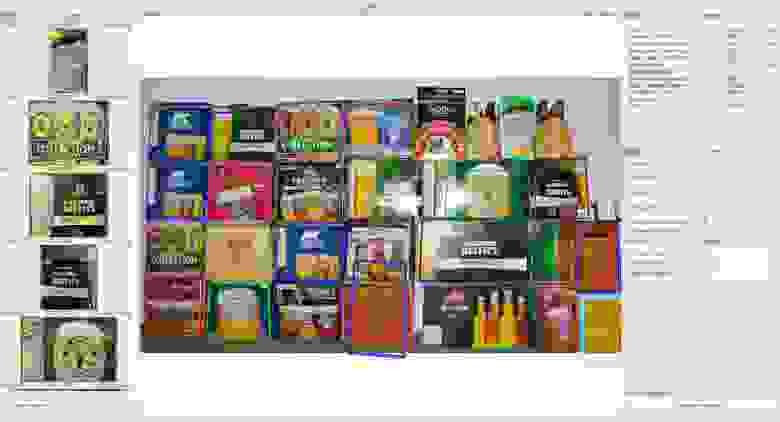
Есть фотография на которой изображена полка с продукцией в том числе и нашей фирмы, насколько сложно идентифицировать ее на фотографии.
Есть фотография на которой изображена полка с продукцией в том числе и нашей фирмы, насколько сложно идентифицировать ее на фотографии.
В теории все можно.
Но если ваш логотип будет нанесен на мятую/неровную поверхность с перекрытиями (видно только часть), и фотография будет качественная, а не сделанная дрожащей рукой смартфоном — то в общем случае нет либо затраты ресурсов на создание такой сети будут несоизмеримо велики.
p.s. помним, что для обучения сети с нуля потребуются не только данные но и мощные вычислительные ресурсы, и не один компьютер а кластер… амазон конечно вам все предоставит, за деньги!
не нужно нейронной сети, опишите каждый элемент вашего логотипа в виде функций (векторные рисунки) и запрограммируйте их поиск теми же алгоритмамми, которыми идет распознавание тех же qr-кодов
Но если ваш логотип будет нанесен на мятую/неровную поверхность с перекрытиями (видно только часть), и фотография будет качественная, а не сделанная дрожащей рукой смартфоном — то в общем случае нет либо затраты ресурсов на создание такой сети будут несоизмеримо велики.
p.s. помним, что для обучения сети с нуля потребуются не только данные но и мощные вычислительные ресурсы, и не один компьютер а кластер… амазон конечно вам все предоставит, за деньги!
не нужно нейронной сети, опишите каждый элемент вашего логотипа в виде функций (векторные рисунки) и запрограммируйте их поиск теми же алгоритмамми, которыми идет распознавание тех же qr-кодов
Если Вам необходимо идентифицировать лишь определённые логотипы продукции на полке, можете попробовать библиотеку opencv, вот пример. Вы можете использовать её для получения изображений продукции для обучающей выборки, затем как-либо разметить полученные изображения (напримет, бутылки, пакеты сока, и.т.д.), предобработать и обучить ими сеть. Я бы рекомендовал первые эксперименты проводить на неглубоких сетях. Если вы увидите, что на каком-то наборе гиперпараметров происходит снижение ошибки и повышение точности модели, тогда уже применяйте сеть глубже.
Можете это попробовать: http://introlab.github.io/find-object/
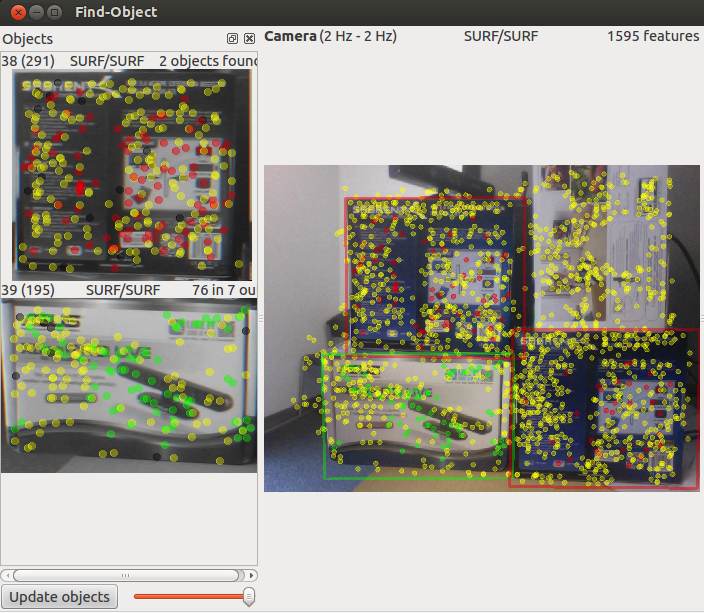


Спасибо! Всё очень чётко и подробно.
Я бы хотел только подчеркнуть границы применимости данного подхода.
Взята обученная сеть на ImageNet, в которой всего 14,197,122 изображений, причем изображений животных 2,799,000 (больше чем в любой другой категории). Собаки и кошки в ImageNet также есть. Потом взято 2000 изображений кошек и собак (то есть изображений концептуально похожих на огромную часть исходной обучающей выборки) и кусок сети переобучен/перенастроен на них. Получен неплохой результат.
Но если мы возьмём 2000 изображений, например, документов на русском и английском языке и попробуем использовать подобный подход, то, вероятно, он «не взлетит». А если изображений специфического типа для обучения ещё меньше, например, несколько десятков или пара сотен, то это наверняка тупиковый путь.
Судя по профилю, автор к.м.н. Есть ли мнение о применимости данного подхода для медицинских изображений?
Я бы хотел только подчеркнуть границы применимости данного подхода.
Взята обученная сеть на ImageNet, в которой всего 14,197,122 изображений, причем изображений животных 2,799,000 (больше чем в любой другой категории). Собаки и кошки в ImageNet также есть. Потом взято 2000 изображений кошек и собак (то есть изображений концептуально похожих на огромную часть исходной обучающей выборки) и кусок сети переобучен/перенастроен на них. Получен неплохой результат.
Но если мы возьмём 2000 изображений, например, документов на русском и английском языке и попробуем использовать подобный подход, то, вероятно, он «не взлетит». А если изображений специфического типа для обучения ещё меньше, например, несколько десятков или пара сотен, то это наверняка тупиковый путь.
Судя по профилю, автор к.м.н. Есть ли мнение о применимости данного подхода для медицинских изображений?
Transfer learning рабочий подход. К сожалению данная статья не иллюстрирует основной смысл transfer learning-а а и не объясняет ключевую концепцию. Архитектура deeplearning (а точнее сверточных нейросетей, в частности inception) похожа на работу зрительной коры мозга. Она состоит из нескольких уровней, каждый из которых определяет всё более сложные формы. На нижнем (ближайшем к глазу / входному изображению) сеть распознаёт различные ключевые точки, на следующем — выстраивает из них линии, затем более сложные фигуры, и так далее. И лишь на последних уровнях по целой кучи характерных паттернов происходит определение объекта. Чтобы обучить нейростеть такой сложности необходимо гигантское количество примеров (порядок — от десятков тысяч до миллионов). Transfer learning вместо обучения всей сети целиком предлагает дообучить лишь верхние слои, по которым происходит непосредственно определение объектов. Это работает, так как у большинство объектов похоже на уровне основных визуальных паттернов — почти везде будут различные линии (разной степени изогнутости), градиенты, выпуклости, острые части, сочетания цветов и прочие. Для transfer-learning-а достаточно коллекции из сотен / тысяч элементов.
OK, получается, что все проблемы распознавания изображений уже решены. Достаточно взять Inception V3, несколько сотен примеров, transfer learning и все проблемы решены. Так?
Здравый смысл должен подсказать, что в жизни всё гораздо сложнее.
Моё мнение основано на опыте коллег. Transfer learning в примере, который похож на приведённый выше не работает. Веса сети, настроенные на фотографиях животных, скамеек, самолётов и т.д. не помогают понять особенности сканированного документа в случае разных шрифтов, цветов, фонов и прочее.
Я считаю, что автор прекрасно демонстрирует, что иногда transfer learning работает. Мой комментарий относится к тому, что стоит добавить слово «иногда».
Здравый смысл должен подсказать, что в жизни всё гораздо сложнее.
Архитектура deeplearning (а точнее сверточных нейросетей, в частности inception) похожа на работу зрительной коры мозга.Ваше мнение основано на вере, что NN похожа на то, как человек видит или мыслит. На самом деле, наука пока не знает, как в точности у человека работает «зрительная кора мозга». Есть некоторые эксперименты, есть некоторые теории, общего знания нет. Автор поста врач, пусть он меня поправит, если я не прав.
Моё мнение основано на опыте коллег. Transfer learning в примере, который похож на приведённый выше не работает. Веса сети, настроенные на фотографиях животных, скамеек, самолётов и т.д. не помогают понять особенности сканированного документа в случае разных шрифтов, цветов, фонов и прочее.
К сожалению данная статья не иллюстрирует основной смысл transfer learning-а а и не объясняет ключевую концепцию.Тут одно «не», кажется, лишнее.
Я считаю, что автор прекрасно демонстрирует, что иногда transfer learning работает. Мой комментарий относится к тому, что стоит добавить слово «иногда».
OK, получается, что все проблемы распознавания изображений уже решены.
Интересно, откуда у вас такой вывод?
Ваше мнение основано на вере, что NN похожа на то, как человек видит или мыслит.
Вера тут не при чем. Есть научные работы в которых рассматривается устройство зрительной части мозга, к примеру в этом paper-е. Архитектура сверточных нейросетей (как вообщем то и сами нейросети) была позаимствована из биологии.
Transfer learning в примере, который похож на приведённый выше не работает.
Вы утверждаете что я не смогу дообучить inception определить язык документа по 1000 сканам русских и английских документов, я вас правильно понимаю?
OK, получается, что все проблемы распознавания изображений уже решены.Из Ваших слов: «Transfer learning вместо обучения всей сети целиком предлагает дообучить лишь верхние слои… Это работает, так как у большинство объектов похоже… Для transfer-learning-а достаточно коллекции из сотен / тысяч элементов. » Для любой задачи берем Inception и так далее -> задача решена.
Интересно, откуда у вас такой вывод?
Вы утверждаете что я не смогу дообучить inception определить язык документа по 1000 сканам русских и английских документов, я вас правильно понимаю?
Дообучить сможете. Но, если всё делать как написано в статье без дополнительных трюков, то работать будет плохо. По крайней мере, значительно хуже альтернативных подходов. Проверено.
Есть научные работыПусть своё мнение об устройстве мозга и биологии скажут врачи и биологи. Научных работ есть много. Периодически одни опровергают другие. В любом случае, все модели зрения/мышления очень условны.
По Transfer learning есть хороший пост, правда, он без кода. Единственное, при этом методе мы НЕ корректируем верхние слои, которые различают контуры предметов, потому что контуры, как раз, универсальны.
Действительно, работа таких сетей похожа на работу центрального отдела зрительного анализатора, о работе которого мы можем cудить прямыми измерениями у животных: в данном эксперименте был выявлен интересный феномен, говорящий о том, что отдельные зоны затылочной коры могут возбуждаться в зависимости от угла источника света. О работе зрительного анализатора у человека можно судить, например, при травматическом или ишемическом поражении различных отделов зрительной коры, а также при раздражении этой области, к примеру, опухолью или при ауре эпилепрического припадка. При этом человек видит различные феномены: искры, пятна и.т.д. (при повреждении медиальных отделов). Это позволяет нам в какой-то мере говорить, о том, что расположение образов в зрительной коре может быть топическим. Но, вот, точно сказать, как происходит идентификация предметов человеком пока что нельзя. Свёрточные НС — это, в какой-то степени, математическое представление (я бы сказал, чертёж) работы зрительного анализатора. Пока что трудно проводить между ними параллели.
Действительно, работа таких сетей похожа на работу центрального отдела зрительного анализатора, о работе которого мы можем cудить прямыми измерениями у животных: в данном эксперименте был выявлен интересный феномен, говорящий о том, что отдельные зоны затылочной коры могут возбуждаться в зависимости от угла источника света. О работе зрительного анализатора у человека можно судить, например, при травматическом или ишемическом поражении различных отделов зрительной коры, а также при раздражении этой области, к примеру, опухолью или при ауре эпилепрического припадка. При этом человек видит различные феномены: искры, пятна и.т.д. (при повреждении медиальных отделов). Это позволяет нам в какой-то мере говорить, о том, что расположение образов в зрительной коре может быть топическим. Но, вот, точно сказать, как происходит идентификация предметов человеком пока что нельзя. Свёрточные НС — это, в какой-то степени, математическое представление (я бы сказал, чертёж) работы зрительного анализатора. Пока что трудно проводить между ними параллели.
Спасибо за вопрос!
Я начал изучать свёрточные нейронные сети, чтобы применять их для классификации медицинских изображений, но в процессе построения таких сетей столкнулся с проблемой ресурсов компьютера. В данном посте я по большей части описал некоторые полезные приёмы работы со свёрточными сетями: как создавать модели, делать из нескольких моделей одну, изменять верхнюю часть модели, загружать веса на нужные нам слои, сохранять веса с наилучшими результатами, делать аугментацию данных и.т.д. Собственно, я решил, что данные моменты будут полезны для начинающих изучать эту тему.
Сейчас я веду работу с этой базой данных. Как только получу результаты, обязательно сделаю на эту тему пост.
Я начал изучать свёрточные нейронные сети, чтобы применять их для классификации медицинских изображений, но в процессе построения таких сетей столкнулся с проблемой ресурсов компьютера. В данном посте я по большей части описал некоторые полезные приёмы работы со свёрточными сетями: как создавать модели, делать из нескольких моделей одну, изменять верхнюю часть модели, загружать веса на нужные нам слои, сохранять веса с наилучшими результатами, делать аугментацию данных и.т.д. Собственно, я решил, что данные моменты будут полезны для начинающих изучать эту тему.
Сейчас я веду работу с этой базой данных. Как только получу результаты, обязательно сделаю на эту тему пост.
Я понимаю как с Keras работать и собрал бы вашу модель как надо, но можно попросить ссылку на исходный код?
Как и обещал, в конце статьи ссылка на Гитхаб
А каким образом магические цифры размеров слоев: 32-64-128-256-… и тд, связаны с размером исходных изображений для обучения (traning) и предсказаний (predict)? Откуда они такие берутся? Понятно, что их делить на два удобно, как опускать, так и поднимать, но как они связаны с размерами изображений используемых в обучении? Насколько их можно задирать вверх и вниз? Существует ли практическая эмпирика?
Тут смотря, с какой стороны посмотреть на вопрос:
1) Для корректной загрузки данных в сеть (например, изображений), нужно, чтобы размеру этих данных соответствовал ВХОДНОЙ слой сети. В моём случае, размер входного слоя пришлось указывать дважды: при создании Inception (там есть параметр: input_shape=((3, 150, 150))) и при создании FFN модели (input_shape=train_data.shape[1:])). Параметр input_shape говорит, что «нужно сделать слой Input, который будет содержать в первом случае 3*150*150 нейронов». Дальше, размер изображений ни с какими слоями модели не связан.
2) Второй момент связан уже с качеством вашей модели. Чем больше свёрточных слоёв и чем больше в них фильтров, тем лучше модель различает изображения, тем меньше величина ошибок и выше точность. Если, к примеру, вы возьмёте зашумлённые изображения сетчатки глаза (для классификации диабетической ретинопатии) размерами 3Х299Х299 и попытаетесь обучить ими VGG16, точность модели вам не понравится. Тут нужно либо с нуля учить более глубокую сеть (с бОльшим количеством слоёв), либо как-то подготавливать сами изображения.
3) Если мы решаем проблему muticlass классификации, то размер выходного слоя должен содержать столько же нейронов, сколько у нас классов. В случае бинарной классификации (как у нас) или регрессии, размер выхода будет один.
Пока что ни в какой работе я не увидел, чтобы размер слоя имел какое-либо значение. То есть размеры можно сделать и 30, 56, 110, 200.
1) Для корректной загрузки данных в сеть (например, изображений), нужно, чтобы размеру этих данных соответствовал ВХОДНОЙ слой сети. В моём случае, размер входного слоя пришлось указывать дважды: при создании Inception (там есть параметр: input_shape=((3, 150, 150))) и при создании FFN модели (input_shape=train_data.shape[1:])). Параметр input_shape говорит, что «нужно сделать слой Input, который будет содержать в первом случае 3*150*150 нейронов». Дальше, размер изображений ни с какими слоями модели не связан.
2) Второй момент связан уже с качеством вашей модели. Чем больше свёрточных слоёв и чем больше в них фильтров, тем лучше модель различает изображения, тем меньше величина ошибок и выше точность. Если, к примеру, вы возьмёте зашумлённые изображения сетчатки глаза (для классификации диабетической ретинопатии) размерами 3Х299Х299 и попытаетесь обучить ими VGG16, точность модели вам не понравится. Тут нужно либо с нуля учить более глубокую сеть (с бОльшим количеством слоёв), либо как-то подготавливать сами изображения.
3) Если мы решаем проблему muticlass классификации, то размер выходного слоя должен содержать столько же нейронов, сколько у нас классов. В случае бинарной классификации (как у нас) или регрессии, размер выхода будет один.
Пока что ни в какой работе я не увидел, чтобы размер слоя имел какое-либо значение. То есть размеры можно сделать и 30, 56, 110, 200.
Спасибо за ответ. Я вообщем-то может быть не совсем точно выразился. Я имел ввиду не степень двойки, а размер, например, почему не поставить 1024, 4096, 9132, в свертке и в Dense. Кроме как, увеличения объемов вычислений, для изображений с размерами 200*200, особого эффекта я не заметил в обработке. Даже в чем-то хуже. Такое впечатление, что количество слоев имеет влияние в районе значения стороны грани изображения. То есть для изображений 200*200 увеличивать его выше 128-256 смысла нет. Результативность останавливается, но это мое личное наблюдение, хотя может я и ошибаюсь.
Количество слоёв сети и размер свёрток зависит от данных. Для простых чб изображений типа MNIST достаточно небольшого размера сети, потому что в рукописных символах не так много признаков. Для набора изображений типа CIFAR требуется больше слоёв и больше свёрток. Также и с размером изображений: больший размер- большее количество признаков, значит и параметров требуется больше.
Для наглядности: простые изображения, сложные изображения.
Если даже при большом количестве слоёв и свёрток результат плохой, следует поиграться с гиперпараметрами (в первую очередь с методами оптимизации) и инициализацией весов.
Для наглядности: простые изображения, сложные изображения.
Если даже при большом количестве слоёв и свёрток результат плохой, следует поиграться с гиперпараметрами (в первую очередь с методами оптимизации) и инициализацией весов.
Скажите пожалуйста, а сколько времени ушло на проделывание вот этой всей реальной работы без учета написания самой статьи?
Сухой работы было немного (около 3-х часов), поскольку мне не нужно было предобрабатывать изображения. Много времени ушло на тренировку модели, потому что я экспериментировал с гиперпараметрами. Суммарно было 3-4 тренировки по 12 часов (ставил на ночь). Ну, а делал я это всё недели три, так как приходилось отвлекаться на работу с пациентами и дежурства :)
Непонятно только зачем сохранять промежуточные результаты на диск и обучать отдельную модель, можно ведь просто переобучить последние слои. Или это какое то ограничение в Keras?
Да, можно! Я отмечал, что не заметил разницы в результатах и скорости обучения как при загрузке весов в верхнюю модель. Но оставил этот раздел, так как в нём мы загружаем веса на отдельные слои, а это может пригодиться в других задачах.
Максим, подскажи пожалуйста, я правильно понимаю, что в самом начале в папку Train и папку Validation запихиваются одни и те же изображения из скаченного архива train.zip?
Я просто полагал, что изображения для validation должны быть как-то размечены, а тут выходит что достаточно в папку положить соответственно либо dog либо cat…
Я просто полагал, что изображения для validation должны быть как-то размечены, а тут выходит что достаточно в папку положить соответственно либо dog либо cat…
Спасибо за вопрос!
Я исправил названия изображений:
В папках train и validation у нас находятся по 2 папки классов: dogs и cats (соответствующих двум классам изображений). Для обучения сети и её проверки нам необходимы РАЗНЫЕ изображения собак и кошек.
Размечать изображения не нужно. Это делают генераторы изображений при помощи метода .flow_from_directory
Я исправил названия изображений:
data/
train/
dogs/
dog001.jpg
dog002.jpg
...
cats/
cat001.jpg
cat002.jpg
...
validation/
dogs/
dog1000.jpg
dog1001.jpg
...
cats/
cat1000.jpg
cat1001.jpg
...
В папках train и validation у нас находятся по 2 папки классов: dogs и cats (соответствующих двум классам изображений). Для обучения сети и её проверки нам необходимы РАЗНЫЕ изображения собак и кошек.
Размечать изображения не нужно. Это делают генераторы изображений при помощи метода .flow_from_directory
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Создаём нейронную сеть InceptionV3 для распознавания изображений