Комментарии 40
Полезная штука. Хочу такую же как плагин для sketch3. Ну или самому попереть справочники и портировать на праздниках
Возникла ошибка при установке библиотеки
SyntaxError: Non-ASCII character '\xe2' in file elizabeth\core\interdata.py on line 720, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
Проблема идентичная как на windows 10, так и на Ubuntu 16.04. На обоих ОС python 2.7.12.
Извиняюсь, ошибся веткой
Скажите, а в чем профит вашей реализации от того же faker?
Какого-то глубокого сравнения я не производил, но могу сказать, что данных больше, провайдеров больше. Данные для русского языка достаточно точны и валидны. Скорость работы выше. Я, конечно, не производил сравнения скорости генерации в в боевых условиях (т.е с бд), но даже в обычной генерации данных `elizabeth` работает в разы быстрее, чем `faker`.
Небольшой пример:
Ниже приведен скрины работы кода, который генерирует 250к имен (Ф.И).
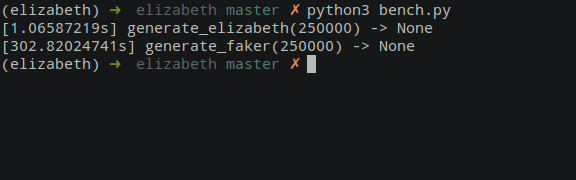
Небольшой пример:
Ниже приведен скрины работы кода, который генерирует 250к имен (Ф.И).

По ссылке старый пакет. Вот актуальный.
Привет, спасибо. Как-то создал синтетический мир из нескольких тысяч организаций и сотрудников для тестирования сервиса электронного документооборота. Нужны были ИНН, КПП, ОГРН, СНИЛС, ФИО, наименования, города, улицы, индексы, ...
Подборку исходных данных по ФИО и наименованиям, частично, вот тут отразил:
- http://qapositive.blogspot.ru/2015/01/dictionaries.html
Взял из Википедии. Потом была реализация, где источником были базы данных переписи населения.
А разные группы крови появляются с теми же вероятностями, что и в реальном мире? :)
Win10
Нетекстовые данные (и текстовые на английском) нормально генерируются.
Python 3.5.2 (v3.5.2:4def2a2901a5, Jun 25 2016, 22:01:18) [MSC v.1900 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from elizabeth import Personal
>>> user = Personal('is')
>>> for _ in range(0, 9):
... print(user.full_name(gender='male'))
...
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
File "C:\Users\mainj\AppData\Local\Programs\Python\Python35-32\lib\encodings\cp437.py", line 19, in encode
return codecs.charmap_encode(input,self.errors,encoding_map)[0]
UnicodeEncodeError: 'charmap' codec can't encode character '\xf0' in position 5: character maps to <undefined>
Нетекстовые данные (и текстовые на английском) нормально генерируются.

Игнорируя второй питон вы оставляете за бортом заметную часть разработчиков.
You know it.
You know it.
Интересно…
как насчет того, чтобы в текст добавить универсальный генератор речей?
_https://dezinfo.net/images2/image/09.2009/ukot/1001.jpg
как насчет того, чтобы в текст добавить универсальный генератор речей?
_https://dezinfo.net/images2/image/09.2009/ukot/1001.jpg
Да, думали над этим. Пока будет только текст, но когда иностранных контрибьюторов наберется — откажемся от текста в файлах и напишем генераторы.
Добавил универсальный генератор речей. Спасибо вам за идею.
>>> from elizabeth.builtins import RussiaSpecProvider
>>> rus = RussiaSpecProvider()
>>> rus.generate_sentence()
"Равным образом рамки, задачи и место обучения кадров требуют определения и уточнения направлений прогрессивного развития и перспектив отрасли."
НЛО прилетело и опубликовало эту надпись здесь
Библиотека не подразумевает, что имена и фамилии будут использоваться в одном контексте. Ф.И для одних задач, Текст — для других. Обеспечить такого рода тонкости для одного языка — это одно, а для 16 — другое. Каждый язык имеет свои тонкости. Потому проще генерировать текст из готовых Предложений.
НЛО прилетело и опубликовало эту надпись здесь
Спасибо за статью.
А если в файле models.py находится 100500 классов, и внутри каждого 100500 полей. Есть вариант скормить как-то весь models.py и получит готовую базу данных с фиктивными данными без написания staticmethod в каждом классе?
А если в файле models.py находится 100500 классов, и внутри каждого 100500 полей. Есть вариант скормить как-то весь models.py и получит готовую базу данных с фиктивными данными без написания staticmethod в каждом классе?
В этой библиотеке такой возможности нет и не будет, но мы начинаем работать над подобным проектом.
Планируется поддержка Django Models и SQLAlchemy.
Планируется поддержка Django Models и SQLAlchemy.
Либа названа в честь Элизабет из Биошока? :)
Да, все верно.
Переименовали? О_о
Так ведь давно: github.com/lk-geimfari/mimesis
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Генерация фиктивных данных с Mimesis: Часть I