Буду потихоньку дорассказывать про Inception.
Предыдущая часть здесь — https://habrahabr.ru/post/302242/.
Мы остановились на том, Inception-v3 не выиграл Imagenet Recognition Challange в 2015-м, потому что появились ResNets (Residual Networks).

Disclaimer: пост написан на основе отредактированных логов чата closedcircles.com, отсюда и стиль изложения, и уточняющие вопросы.
Это результат работы людей в Microsoft Research Asia над проблемой тренировки очень глубоких сетей (http://arxiv.org/abs/1512.03385).
Известно, что если тупо увеличивать количество уровней в каком-нибудь VGG — он начнет тренироваться все хуже и хуже, и в смысле точности на тренировочном сете, и на validation.
Что в некотором смысле странно — более глубокая сеть обладает строго большим representational power.
И, вообще говоря, можно тривиально получить более глубокую модель, которая не хуже менее глубокой, тупо добавив несколько identity layers, то есть уровней, которые просто пропускают сигнал дальше без изменений. Однако, дотренировать обычным способом до такой точности глубокие модели не получается.
Вот это наблюдение, что всегда можно сделать не хуже identity, и есть основная мысль ResNets.
Давайте сформулируем задачу так, чтобы более глубокие уровни предсказывали разницу между тем, что выдают предыдущие лееры и таргетом, то есть всегда могли увести веса в 0 и просто пропустить сигнал.
Отсюда название — Deep Residual Learning, то есть обучаемся предсказывать отклонения от прошлых лееров.
Более конкретно это выглядит следующим образом.
Основной building block сети — вот такая конструкция:
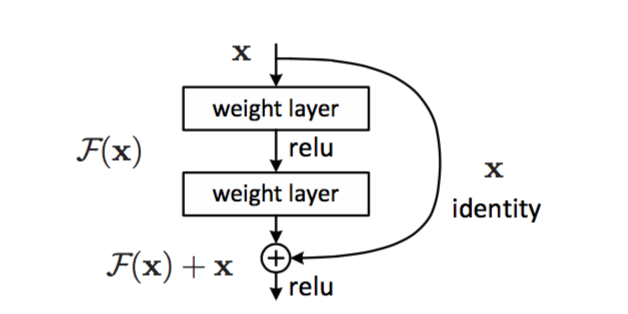
Два слоя с весами (могут быть convolution, могут быть нет), и shortcut connection, который тупо identity. Результат после двух лееров добавляется к этому identity. Почему каждые два уровня, а не каждый первый? Объяснений нет, видимо на практике заработало вот так.
Поэтому если в весах некого уровня будет везде 0, он просто пропустит дальше чистый сигнал.
И вот сначала они строят версию VGG на 34 леера, в которой вставлены такие блоки и все лееры сделаны поменьше, чтобы не раздувать количество параметров.
Оказывается, тренируется хорошо и показывает результаты лучше, чем VGG!
Как развить успех?
MOAR LAYERS!!!
Чтобы получилось больше лееров, надо делать их полегче — есть идея вместо двух convolutions делать например один и меньшей толщины:
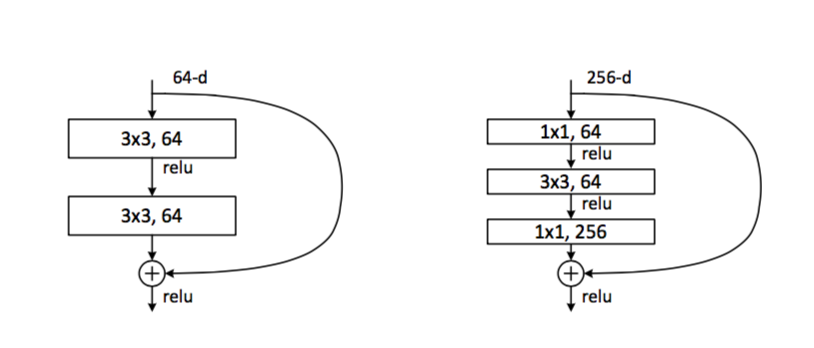
Было как слева, сделаем как справа. Количество и вычислений, и параметров уменьшается радикально.
И вот тут пацанам начинает переть и они начинают тренировать версию на 101 и 152(!) леера. Причем даже у таких сверх-глубоких сетей количество параметров меньше, чем у толстых версий VGG.
Финальный результат на ансамбле, как было упомянуто раньше — 3.57% top5 на Imagenet.
Отдельно нужно сказать, что в области идет активное развитие и обсуждение механизмов ResNets, соединять результаты слоев арифметическими операциями оказалось благодатной идеей.
Вот только несколько примеров:
http://torch.ch/blog/2016/02/04/resnets.html — мужики в Facebook исследуют, где лучше вставлять residual connections.
https://arxiv.org/abs/1605.06431 — теория о том, что ResNets представляют собой огромный ансамбль вложенных сетей.
https://arxiv.org/abs/1605.07146 — применение идей ResNets для тренировки очень широких, а не глубоких сетей. Кстати, топовый результат на CIFAR-10, for what it's worth.
https://arxiv.org/abs/1605.07648 — попытка конструировать и тренировать глубокие сети без residual connections в чистом виде, но все же с арифметикой между выходами слоев.
Результат работы — Inception-v4 и Inception-Resnet (http://arxiv.org/abs/1602.07261)
Кроме ResNets, основное что изменилось — это появление TensorFlow.
В статье рассказывается, что до TensorFlow модель Inception не влезала в память одной машины, и приходилось ее тренировать распределенно, что ограничивает возможности оптимизации. А вот теперь можно не сдерживать креатив.
(я не очень понимаю, как конкретно это происходило, вот обсуждение догадок — https://closedcircles.com/chat?circle=14&msg=6207386)
После этой фразы пацаны перестают объяснять, чем были вызваны изменения в архитектуре, и тупо постят три страницы полные вот таких картинок:
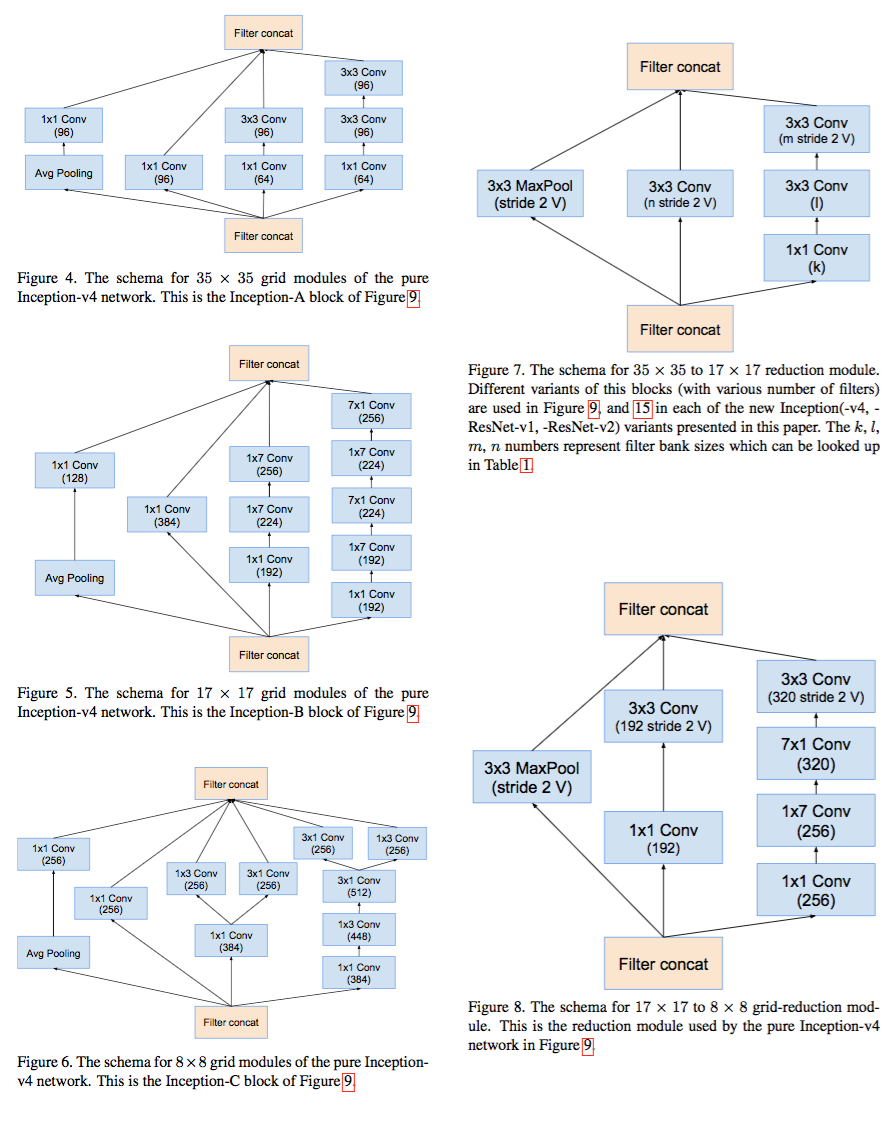
И есть у меня ощущение, что много там автоматики в построении архитектуры, но они пока не палятся.
В общем, у них есть Inception-v4, в которой нет Residual connections, и Inception-ResNet-2, у которой сравнимое количество параметров, но есть residual connections. На уровне одной модели результаты у них очень близкие, ResNet выигрывает чуть-чуть.
А вот ансамбль из одной v4 и трех ResNet-2 показывает новый рекорд на Imagenet — 3.08%.
Напомню прошлые вехи. Первая сетка, которая победила в Imagenet Recongition challenge, сделала это с ошибкой 15% в 2012. В конце 2015 допилили до 3.08%. Разумная оценка среднего результата человека — ~5%. Прогресс, как мне кажется, впечатляет.
Изначально очень простая архитектура с набором convolution layers, после которых следуют несколько fully connected layers, с каждым годом становится все более и более монструозной ради эффективности. И возможно есть один человек, который понимает все детали архитектурных микрорешений. А может и нет уже.
Полную архитектуру Inception-ResNet на одной картинке я уже сходу не нашел. Похоже, никому не пришло в голову ее нарисовать.
Забавная несвязанная с остальным деталь — они часто делают non-padded convolutions, то есть convolution layers, которые уменьшают размер картинки на 2 пикcеля с каждой стороны. Оптимизируют байты, практически!
Предыдущая часть здесь — https://habrahabr.ru/post/302242/.
Мы остановились на том, Inception-v3 не выиграл Imagenet Recognition Challange в 2015-м, потому что появились ResNets (Residual Networks).
Что такое вообще ResNets?

Disclaimer: пост написан на основе отредактированных логов чата closedcircles.com, отсюда и стиль изложения, и уточняющие вопросы.
Это результат работы людей в Microsoft Research Asia над проблемой тренировки очень глубоких сетей (http://arxiv.org/abs/1512.03385).
Известно, что если тупо увеличивать количество уровней в каком-нибудь VGG — он начнет тренироваться все хуже и хуже, и в смысле точности на тренировочном сете, и на validation.
Что в некотором смысле странно — более глубокая сеть обладает строго большим representational power.
И, вообще говоря, можно тривиально получить более глубокую модель, которая не хуже менее глубокой, тупо добавив несколько identity layers, то есть уровней, которые просто пропускают сигнал дальше без изменений. Однако, дотренировать обычным способом до такой точности глубокие модели не получается.
Вот это наблюдение, что всегда можно сделать не хуже identity, и есть основная мысль ResNets.
Давайте сформулируем задачу так, чтобы более глубокие уровни предсказывали разницу между тем, что выдают предыдущие лееры и таргетом, то есть всегда могли увести веса в 0 и просто пропустить сигнал.
Отсюда название — Deep Residual Learning, то есть обучаемся предсказывать отклонения от прошлых лееров.
Более конкретно это выглядит следующим образом.
Основной building block сети — вот такая конструкция:
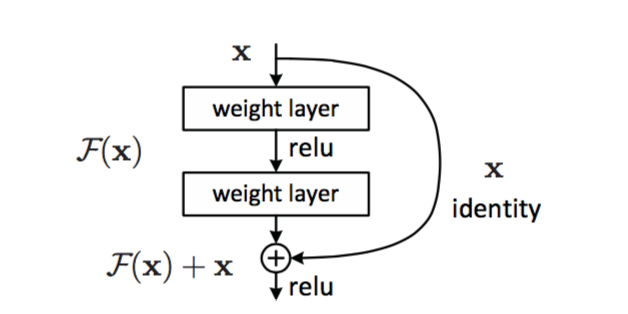
Два слоя с весами (могут быть convolution, могут быть нет), и shortcut connection, который тупо identity. Результат после двух лееров добавляется к этому identity. Почему каждые два уровня, а не каждый первый? Объяснений нет, видимо на практике заработало вот так.
Поэтому если в весах некого уровня будет везде 0, он просто пропустит дальше чистый сигнал.
И вот сначала они строят версию VGG на 34 леера, в которой вставлены такие блоки и все лееры сделаны поменьше, чтобы не раздувать количество параметров.
Оказывается, тренируется хорошо и показывает результаты лучше, чем VGG!
Как развить успех?
MOAR LAYERS!!!
Чтобы получилось больше лееров, надо делать их полегче — есть идея вместо двух convolutions делать например один и меньшей толщины:
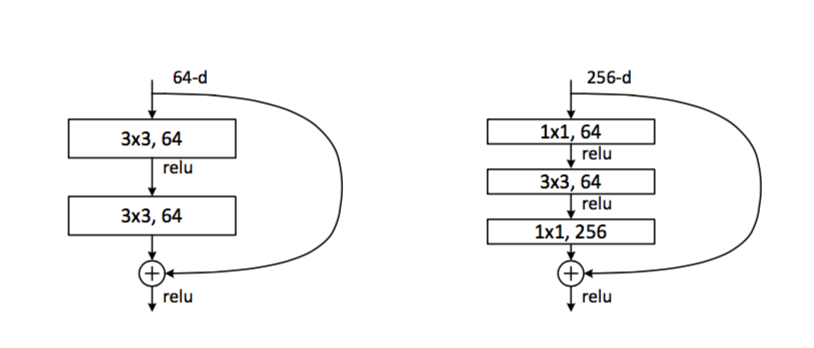
Было как слева, сделаем как справа. Количество и вычислений, и параметров уменьшается радикально.
И вот тут пацанам начинает переть и они начинают тренировать версию на 101 и 152(!) леера. Причем даже у таких сверх-глубоких сетей количество параметров меньше, чем у толстых версий VGG.
Финальный результат на ансамбле, как было упомянуто раньше — 3.57% top5 на Imagenet.
Разве там главная идея была не в том, что в очень глубоких сетях остро стоит проблема Vanishing Gradients, а Residual архитектура позволяет ее кое-как решить?
Это хороший вопрос!
Авторы ResNets исследуют этот вопрос в меру сил, и им кажется, что проблема vanishing gradients хорошо решается разумной инициализацией и Batch Normalization. Они смотрят на величину градиентов, которые попадают в нижние слои, она в целом разумная и не затухает.
Их теория в том, что более глубокие сетки просто экспоненциально медленнее сходятся в процессе тренировки, и поэтому такой же точности мы просто не успеваем дождаться с теми же вычислительными ресурсами.
вопрос — как работает back propagation c identity link?
Передает единицу, обычная производная.
Отдельно нужно сказать, что в области идет активное развитие и обсуждение механизмов ResNets, соединять результаты слоев арифметическими операциями оказалось благодатной идеей.
Вот только несколько примеров:
http://torch.ch/blog/2016/02/04/resnets.html — мужики в Facebook исследуют, где лучше вставлять residual connections.
https://arxiv.org/abs/1605.06431 — теория о том, что ResNets представляют собой огромный ансамбль вложенных сетей.
https://arxiv.org/abs/1605.07146 — применение идей ResNets для тренировки очень широких, а не глубоких сетей. Кстати, топовый результат на CIFAR-10, for what it's worth.
https://arxiv.org/abs/1605.07648 — попытка конструировать и тренировать глубокие сети без residual connections в чистом виде, но все же с арифметикой между выходами слоев.
Ну так вот, мужики в Гугле смотрят на этот мир и продолжают работать
Результат работы — Inception-v4 и Inception-Resnet (http://arxiv.org/abs/1602.07261)
Кроме ResNets, основное что изменилось — это появление TensorFlow.
В статье рассказывается, что до TensorFlow модель Inception не влезала в память одной машины, и приходилось ее тренировать распределенно, что ограничивает возможности оптимизации. А вот теперь можно не сдерживать креатив.
(я не очень понимаю, как конкретно это происходило, вот обсуждение догадок — https://closedcircles.com/chat?circle=14&msg=6207386)
После этой фразы пацаны перестают объяснять, чем были вызваны изменения в архитектуре, и тупо постят три страницы полные вот таких картинок:
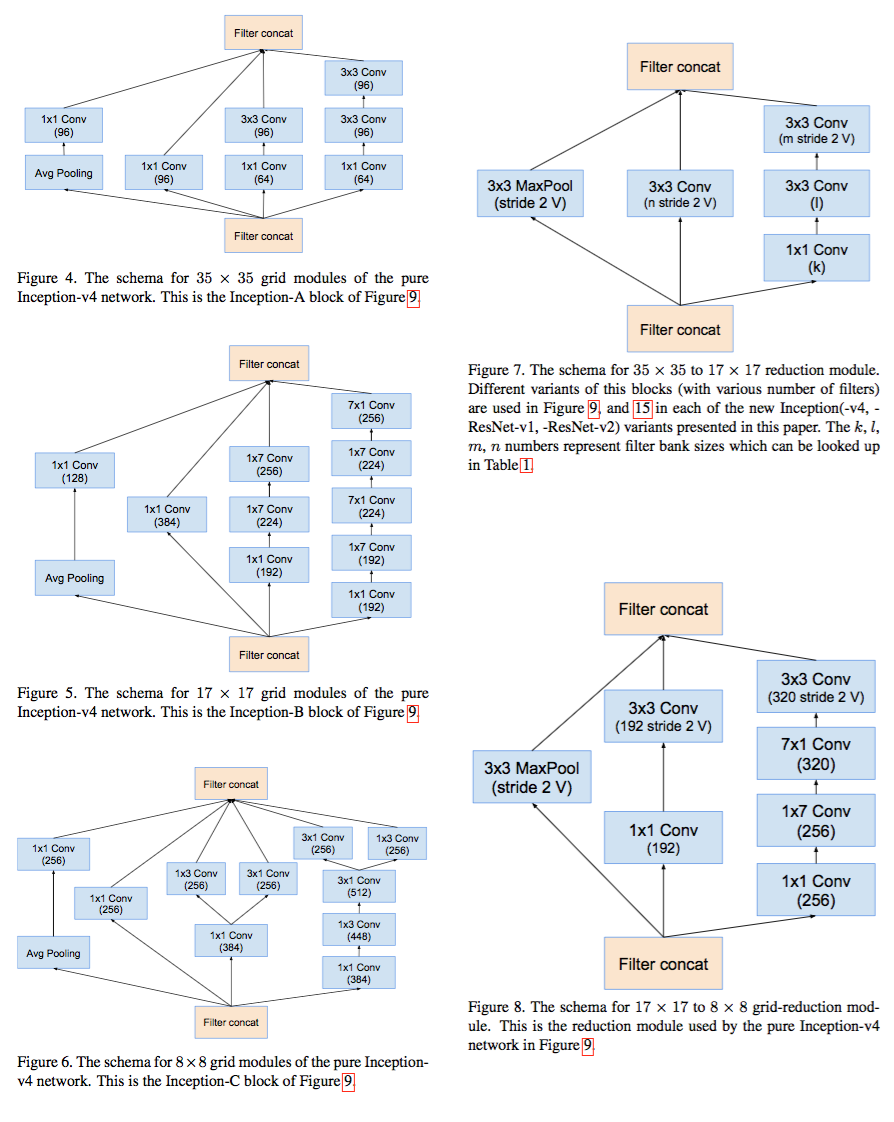
И есть у меня ощущение, что много там автоматики в построении архитектуры, но они пока не палятся.
В общем, у них есть Inception-v4, в которой нет Residual connections, и Inception-ResNet-2, у которой сравнимое количество параметров, но есть residual connections. На уровне одной модели результаты у них очень близкие, ResNet выигрывает чуть-чуть.
А вот ансамбль из одной v4 и трех ResNet-2 показывает новый рекорд на Imagenet — 3.08%.
Напомню прошлые вехи. Первая сетка, которая победила в Imagenet Recongition challenge, сделала это с ошибкой 15% в 2012. В конце 2015 допилили до 3.08%. Разумная оценка среднего результата человека — ~5%. Прогресс, как мне кажется, впечатляет.
В целом, Inception — это пример прикладного R&D в мире deep learning
Изначально очень простая архитектура с набором convolution layers, после которых следуют несколько fully connected layers, с каждым годом становится все более и более монструозной ради эффективности. И возможно есть один человек, который понимает все детали архитектурных микрорешений. А может и нет уже.
Полную архитектуру Inception-ResNet на одной картинке я уже сходу не нашел. Похоже, никому не пришло в голову ее нарисовать.
Полная схема на странице 7, рис 15, только там все слои не разрисованы целиком, а просто блоками обозначены. Думаю иначе только на ватман пришлось бы печатать, а особо понимания не добавило бы.
Я имел ввиду, что полная с точностью до финальных блоков. Для прошлых версий я такие картинки постил.
Тут раза в три шире получится картинка :)
Дада.
Забавная несвязанная с остальным деталь — они часто делают non-padded convolutions, то есть convolution layers, которые уменьшают размер картинки на 2 пикcеля с каждой стороны. Оптимизируют байты, практически!
ты сравниваешь странные вещи. человеческий результат — это топ1, а компутерный — это топ5, когда выбираются 5 подходящих категорий. в топ1 у компутеров результаты до сих пор где-то в районе double digits...
Не, человеческий — это тоже top5. Top1 человеку на imagenet тоже нечего делать, слишком большая неопределённость.
Вот как пример —
Какой класс у этой картинки? Например, есть классы "horse" и "woman's clothing".
Но правильный ответ, конечно, "hay".
good luck with top1.
разумеется. сена-то вон сколько. а бабы с конем еле-еле!











