Привет всем.
Мы классический web 2.0 сайт сделаный на Drupal. Можно сказать, что мы медиа сайт, т.к. у нас очень много всевозможных статей, и постоянно выходят новые. Мы уделяем много внимания SEO. У нас для этого даже есть специально обученные люди, которые работают полный рабочий день.
К нам заходит более 400k уникальных пользователей в месяц. Из них 90% приходит из поиска Google.
И вот уже почти полгода мы разрабатывали Single Page Application версию нашего сайта.
Как вы уже наверное знаете, JS это вечная боль сеошников. И нельзя просто так взять и сделать сайт на JS.
Перед тем как начать разработку мы начали исследовать этот вопрос.
И выяснили, что общепринятым способом является отдача google боту уже отрисованой версии страницы.
Making AJAX applications crawlable
Также выяснилось, что этот способ более не рекомендуется Google и они уверяют, что их бот умеет открывать js сайты, не хуже современных браузеров.
We are generally able to render and understand your web pages like modern browsers.
Т.к. на момент принятия нашего решения Google только-только отказались от подобного метода, и еще никто не успел проверить как Google Crawler на самом деле индексирует сайты сделаные на JS. Мы решили рискнуть и сделать SPA сайт без дополнительной отрисовки страниц для ботов.
Зачем?
Из-за неравномерной нагрузки на сервера, и невозможности гибко оптимизировать страницы, было решено разделить сайт на backend (текущая версия на Drupal) и frontend (SPA на AngularJS).
Drupal будет использовать исключительно для модерации контента и отправки всевозможной почты.
AngularJS будет рисовать все что должно быть доступно пользователям сайта.
Технические подробности
В качестве сервера для frontend было решено использовать Node.js + Express.
REST Server
Из Drupal сделали REST сервер, просто создав новый префикс /v1/т.е. все запросы приходящие на /v1/ воспринимались как запросы к REST. Все остальные адреса остались без изменения.
Адреса страниц
Для нас очень важно, чтобы все публичные страницы жили на тех же адресах, как и раньше. По этому мы перед разработкой SPA версии структуризировали все страницы, чтобы они имели общие префиксы. Например:
Все forum странички должны жить по адресу /forum/*, при этом у форума есть категории и сами топики. Для них url будет выглядеть следующим образом /forum/{category}/{topic}. Не должно быть никаких случайных страниц по случайным адресам, все должно быть логично структурированно.
Redirects
Сайт доступен с 2007 года, и за это время очень многое изменилось. В том числе адреса страниц. У нас сохранена вся история, как страницы переезжали с одного адреса на другой. И при попытке запросить какой-нибудь старый адрес вы будете переправлены на новый.
Для того чтобы новый frontend также перенаправлял, мы перед отрисовкой страницы в nodejs отправляем запрос обратно в Drupal, и спрашиваем каково состояние запрашиваемого адреса. Выглядит вот так:
curl -X GET --header 'Accept: application/json' 'https://api.example.com/v1/path/lookup?url=node/1'На что Drupal отвечает:
{
"status": 301,
"url": "/content/industry/accountancy-professional-services/accountancy-professional-services"
}После чего nodeJS решает оставаться на текущем адресе, если это 200, либо сделать редирект на другой адрес.
app.get('*', function(req, res) {
request.get({url: 'https://api.example.com/v1/path/lookup', qs: {url: req.path}, json: true}, function(error, response, data) {
if (!error && data.status) {
switch (data.status) {
case 301:
case 302:
res.redirect(data.status, 'https://www.example.com' + data.url);
break;
case 404:
res.status(404);
default:
res.render('index');
}
}
else {
res.status(503);
}
});
});Images
В контенте приходящем с Drupal могут присутствовать файлы, которые не существуют в frontend версии. По этому мы решили просто стримить их с Drupal через nodejs.
app.get(['*.png', '*.jpg', '*.gif', '*.pdf'], function(req, res) {
request('https://api.example.com' + req.url).pipe(res);
});sitemap.xml
Т.к. sitemap.xml постоянно генерируется в Drupal, и адреса страниц совпадают с frontend, то было решено просто стримить sitemap.xml. Абсолютно также как с картинками:
app.get('/sitemap.xml', function(req, res) {
request('https://api.example.com/sitemap.xml').pipe(res);
});Единственное на что стоит обратить внимание, это на то чтобы Drupal подставлял правильный адрес сайта, который используется на frontend. Там есть настройка в админке.
robots.txt
- Доступный для google crawler bot контент не должен дублироваться между нашими двумя серверами.
- Весь запрашиваемый через frontend у Drupal контент должен быть доступен для просмотра ботом.
В результате чего наши robots.txt выглядят следующим образом:
В Drupal запретить все кроме /v1/:
User-agent: *
Disallow: /
Allow: /v1/В frontend просто разрешить все:
User-agent: *Подготовка к релизу
Перед релизом мы поместили frontend версию на https://new.example.com адрес.
А для Drupal версии зарезервировали дополнительный поддомен https://api.example.com/
После чего, мы связали frontend чтобы он работал с https://api.example.com/ адресом.
Релиз
Сам релиз выглядит как простая перестановка местами серверов в DNS. Мы указываем наш текущий адрес @ на сервер frontend. После чего сидим, и смотрим как все работает.
Тут стоит отметить, что если использовать CNAME записи, то замена сервера произойдет мгновенно. Запись A будет рассасываться по DNS до 48 часов.
Производительность
После разделения сайта на frontend и backend нагрузка на сервер стала размеренной. Также стоит отметить, что мы особо не оптимизировали sql запросы, все запросы проходят сквозь без кеширования. Вся оптимизация была запланирована уже после релиза.
У меня не осталось метрики до релиза, зато есть метрика после того как мы откатились обратно :)


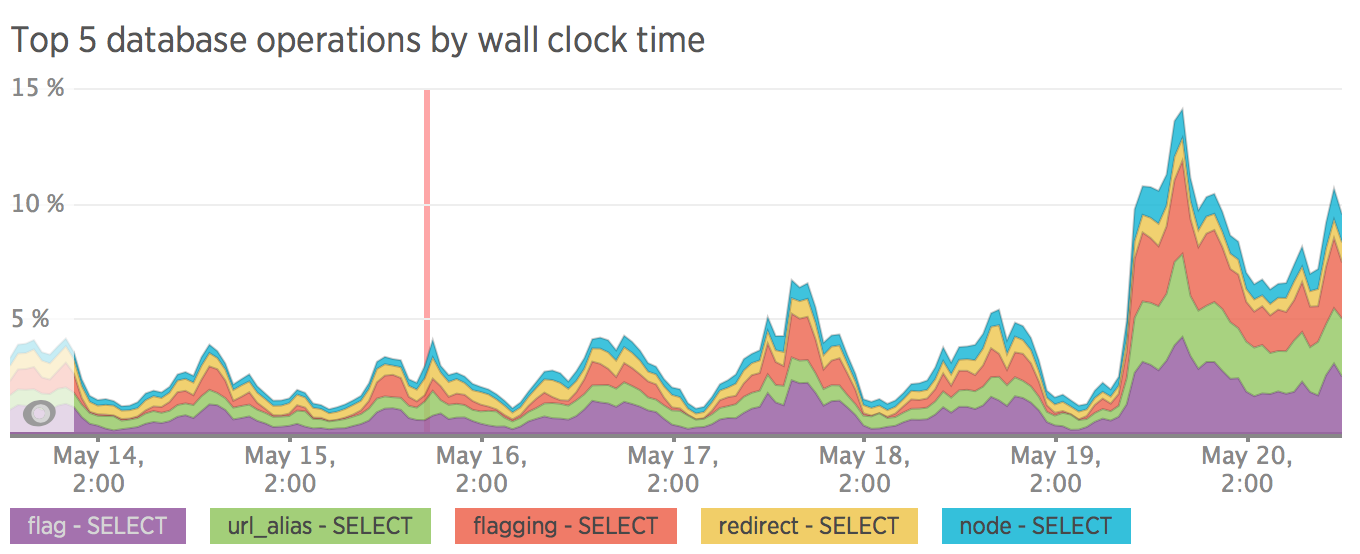
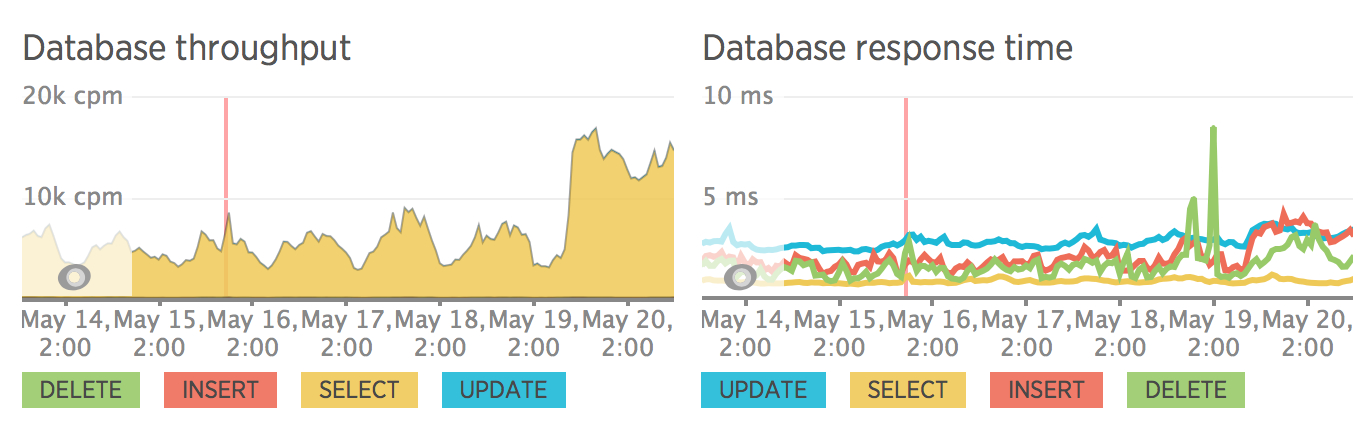
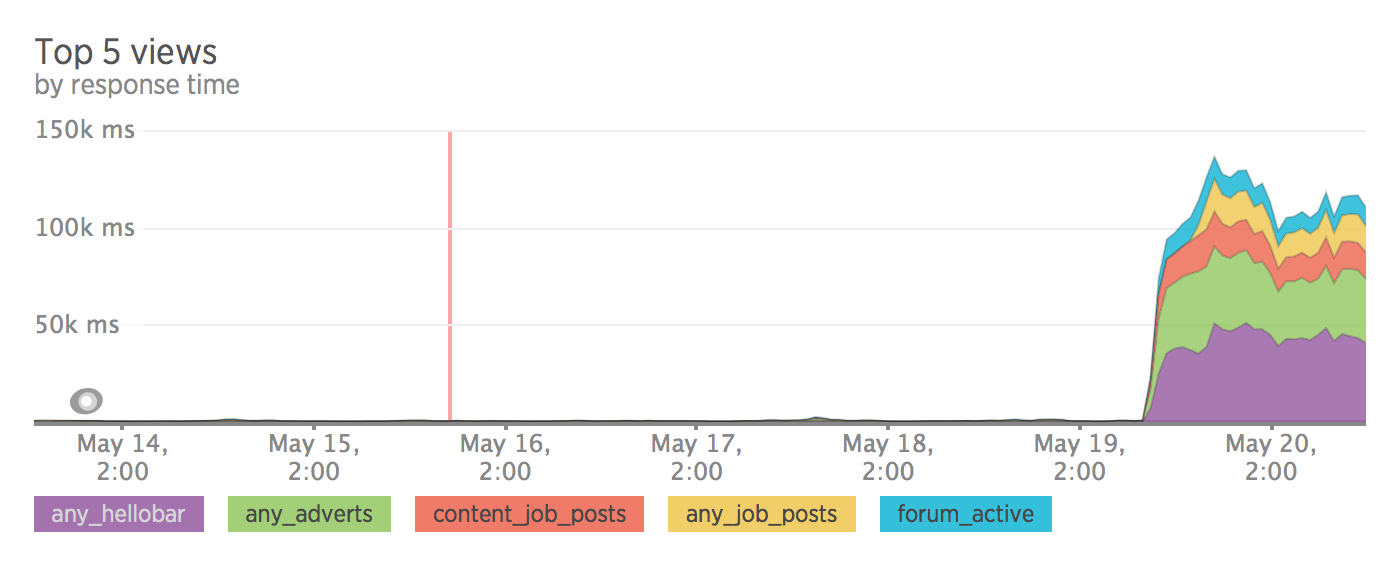
SEO
Вот тут все оказалось не так хорошо, как хотелось бы. После чуть более недели тестирования трафик на сайт упал на 30%.

Какие-то страницы выпали из индекса google, какие-то стали очень странно индексироваться, без meta description.
Пример того, как Google проиндексировал вот эту страницу.

Мы также заметили, что после релиза нового сайта Google заметил это, и начал а панике реиндексировать весь сайт. Тем самым обновив весь свой кэш.

После чего Crawler нашел огромное количество старых страниц, которых уже давным давно не должно было быть в индексе.
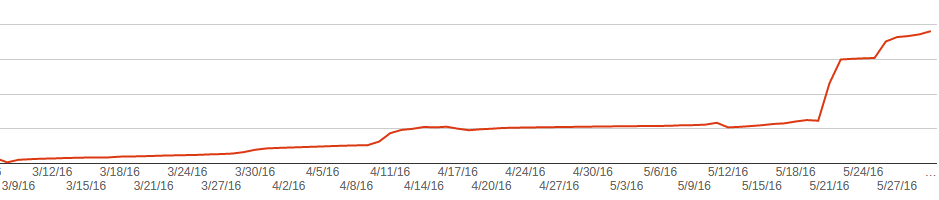
На графике ниже показан график найденый 404 страниц. Видно, что до релиза мы делали зачистку контента, и Google потихоньку удалял старые страницы. Но после релиза он начал это делать гораздо активнее.
Результат / Выводы
Из-за проблем с индексированием было принято решение откатиться назад на Drupal, и думать что мы сделали не так.
Все усложняется тем, что google является некой черной коробкой, которая если что-то идет не так просто удаляет страницы с индекса. И любые наши эксперименты требуют пары дней, чтобы это отразилось на результатах поиска.
Одной из более вероятных версий является то, что у Google Crawler есть определенные ограничения. Это может быть память, либо время отрисовки страницы.
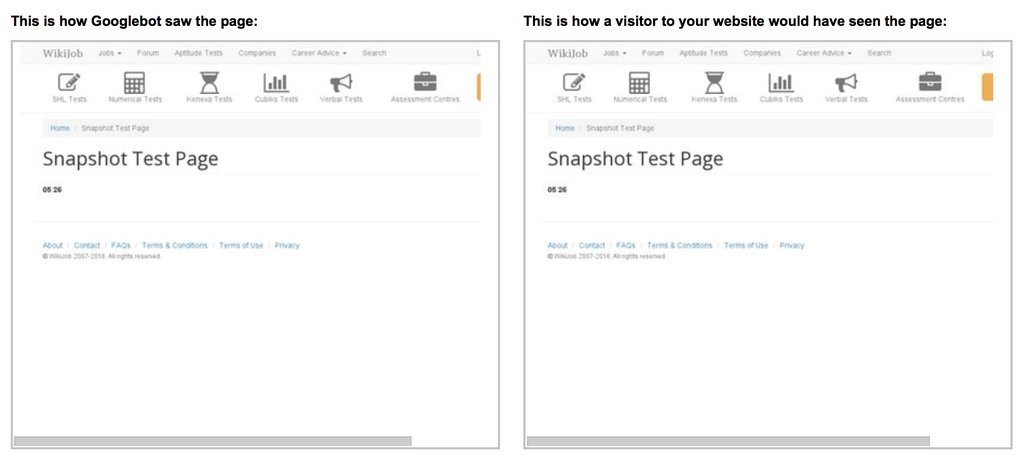
Я сделал небольшой тест, создав страницу с секундомером, и попробовал отрисовать ее как crawler в Google Search Console. На скриншоте секундомер остановился на 5.26 секундах. Думаю crawler ждет страницу около 5 секунд, и потом делает снапшот, а все что загрузилось после — в индекс не попадает.
Полезные ссылки
Update
- Добавил график из google analytics показывающий на как просел трафик.
- Выяснил, что Google Crawler имеет около 5 секунд на отрисовку страницы.
- Выяснил, что Google Crawler понимает когда обновляется сайт, и реиндексирует его.








