Пост будет о том, как сделать работу на Хадупе немного комфортнее.

В данной статье я хочу рассмотреть один из компонентов экосистемы Hadoop – HUE. Произносим правильно «Хьюи» или «Эйч Ю И», но не другими, созвучными с широко известным русским словом, вариантами.
HUE (Hadoop User Experience) – это веб интерфейс для анализа данных на Hadoopе. По крайней мере так они позиционируют себя сами, . HUE – это открытый проект(open source), выпускающийся под лицензией Apache. Принадлежит HUE, на момент написания статьи, компании Cloudera. Ставится он на все наиболее популярные дистрибутивы хадупа:
Если перевести аббревиатуру HUE, то получиться, что-то вроде «Опыт пользователей хадупа» или «Хадупный пользовательский опыт». И это действительно так. Я пришел к HUE, имея некоторый опыт работ с хадупом. Работал я с хадупом как через консоль, так и через CDM(cloudera manager). В основном пользовался фреймворками Spark и YARN, а также совсем чуть-чуть Oozie. И со временем у меня накопилась пара идей/пользовательских требований:
Это был мой пользовательский опыт, и он был реализован в HUE. Начну с файлового браузера. Он намного удобней чем нативный от клоудеры. Можно создавать/копировать/перемещать файлы и директории из одного места в HDFS в другое. Можно менять права доступа а также заливать файлы с локальной машины в HDFS, и открывать файлы, некоторых форматов (.txt, .seq), не скачивая их на локальную машину. Планировщик заданий – это по сути автоматизированный Oozie. HUE сам создает job.properties и workflow.xml, в общем всю ту рутинную работу что в Oozie приходилось делать руками HUE делает за нас! Ниже я приведу несколько примеров и расскажу об этом подробнее.
Но HUE – это не только файловый браузер и scheduler (планировщик задач), это набор приложений, дающих доступ практически ко всем модулям кластера, а также платформа для разработки приложений.
В этой статье будет рассказано о связках HUE + Oozie, HUE + YARN, HUE + Spark, HUE + HDFS.
Для начала напомню, что есть 3 основные типа задач в Oozie:

В верхней части экрана есть раздел Workflows, в нем два подраздела Dashboards и Editors, а в них соответственно подразделы для каждого типа задач.
Dashbord – это мониторинг запущенных/отработанных задач.
Editor – это редактор Oozie задач.
В Dashbord отображаются Oozie задачи. Т.е. если у вас висит какой-то координатор, который запускает воркфлоу(например задачу выполняющуюся в YARN) в 18.00, а сейчас только 12 часов дня, то в YARN Resource Manager вы не увидите ее, так как там отображаются только запущенные задачи, а в Dashbord она будет висеть, со статусом Running/Prepare (Running – если уже хотя бы один раз задача исполнялась, например координатор висит со вчерашнего дня и вчера уже был запуск воркфлоу; Prepare – если задача ещё ни разу не выполнялась). Ниже на картинке показан кусочек моего Dashbord, думаю по ней все понятно без дополнительных объяснений (черным замазал конфиденциальную информацию).

Начнем с раздела Workflows. В этом разделе отображаются все имеющиеся и доступные для данного пользователя Workflow. Отсюда можно запускать, делиться с другими пользователями, копировать, удалять, импортировать, экспортировать и создавать воркфлоу, а также некоторая информация о них. Рассмотрим процесс создания нового workflow:

В строке ACTIONS все возможные действия, на основе которых можно составить workflow, а именно: Hive Script, Hive Server2 Script, Pig Script, Spark program, Java program, Sqoop 1, Map Reduce job, Subworkflow, Shell, Ssh, HDFS fs, Email, Streaming, Distcp, Kill.
Создадим простенький workflow, который создает директорию в HDFS, при этом параметризуем его.

Где ${Dir} – это переменная, значением которой будет директория из которой будет создаваться наша директория.
${Year}, ${Month}, ${Day} – это тоже переменные, их назначение понятно.
Вокруг нашего действия появились серые поля, в них тоже можно помещать действия, таким образом можно получить разветвленный воркфлоу с несколькими выходами, пример такого воркфлоу покажу позже. Также появились шестеренки в углах нашего действия и stop действия. Нажимая на эти шестеренки, мы перейдем в меню настроек. Для каждого типа действия свои настройки, но есть общий набор настроек, например последовательность. К какому действию перейти при удачном завершении задачи, к какому действию при неудачном завершении задачи.
Если мы запустим наш воркфлоу, то он попросить задать значения переменных. Теперь давайте создадим coordinator, на основе нашего workflow.
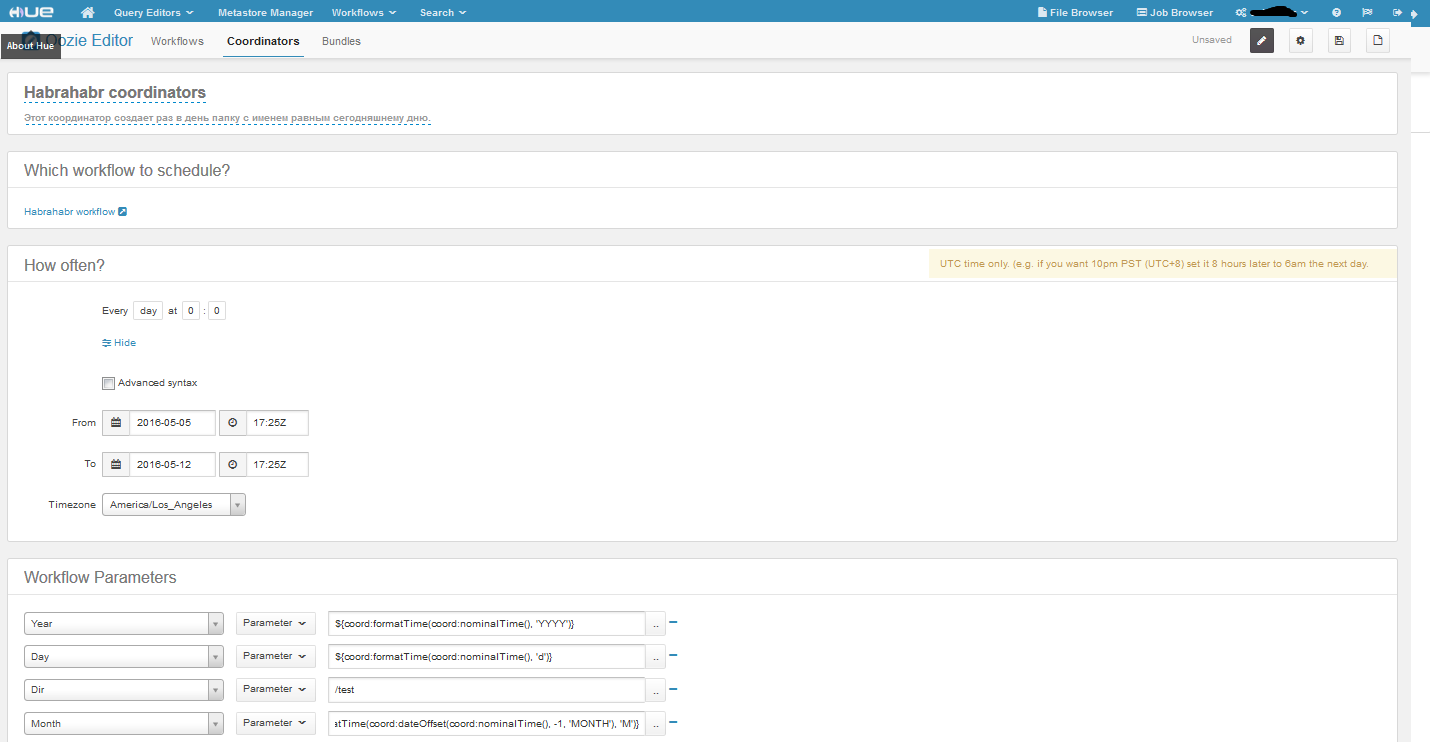
Вот наш координатор. Временные рамки задаем в соответствующих полях, тут все просто, единственная особенность, это то что можно запустить задачу в прошлом. В координаторе есть два вида времени nominal и actual. Nominal – это то которое идет во временных рамках, а actual – это реальное время. Про что хочу сказать ещё, это про Advanced syntax, сделав этот чекбокс активным, появится возможность задавать частоту в формате crontab. С частотой вроде бы все. Что касается параметров нашего workflow, то мы задали их с помощью EL функций (Expression Language Functions ). Функция заданная в переменной год вернет значение – 2016, день – 5, а вот с месяцем интересней – она вернет номер предыдущего месяца(начало не влезло, но оно такое же как у дня и года). Ну и Dir – это константа. По настройкам наш координатор запускается раз в день в течение недели, а значит, что у нас будет 7 папок, лежащих в HDFS по пути /test/2016/4/. Вот такой простенький пример, практического применения он не имеет, но если его немного изменить, например пусть наша задача не создает папки, а удаляет папки с логами за предыдущий день/месяц/год, то уже будет польза.
Можно создавать workflow с действиями типа Java program, MapReduce program и также их параметризировать как в примере со связкой с HDFS. Процесс исполнения задачи будет логироваться, при чем логи в HUE вытягиваются из YARN Resource Manager или History Server. Только они немного более удобно структурированы (это уже дело вкуса, конечно). И ещё одно отличие от прямого запуска задачи на YARN, это то, что затрачивается чуть больше ресурсов. Так как сначала создается Oozie задача, целью которой будет вызов нашего воркфлоу(Java/MapReduce/Spark задачи). Эта Oozie задача съедает одно ядро (vcore, а не реальное ядро) и 1.5 Gb RAM на кластере.
Данную связку рассмотрим на примере запуска MapReduce процедур, вызывая ее из Java program действия в воркфлоу.
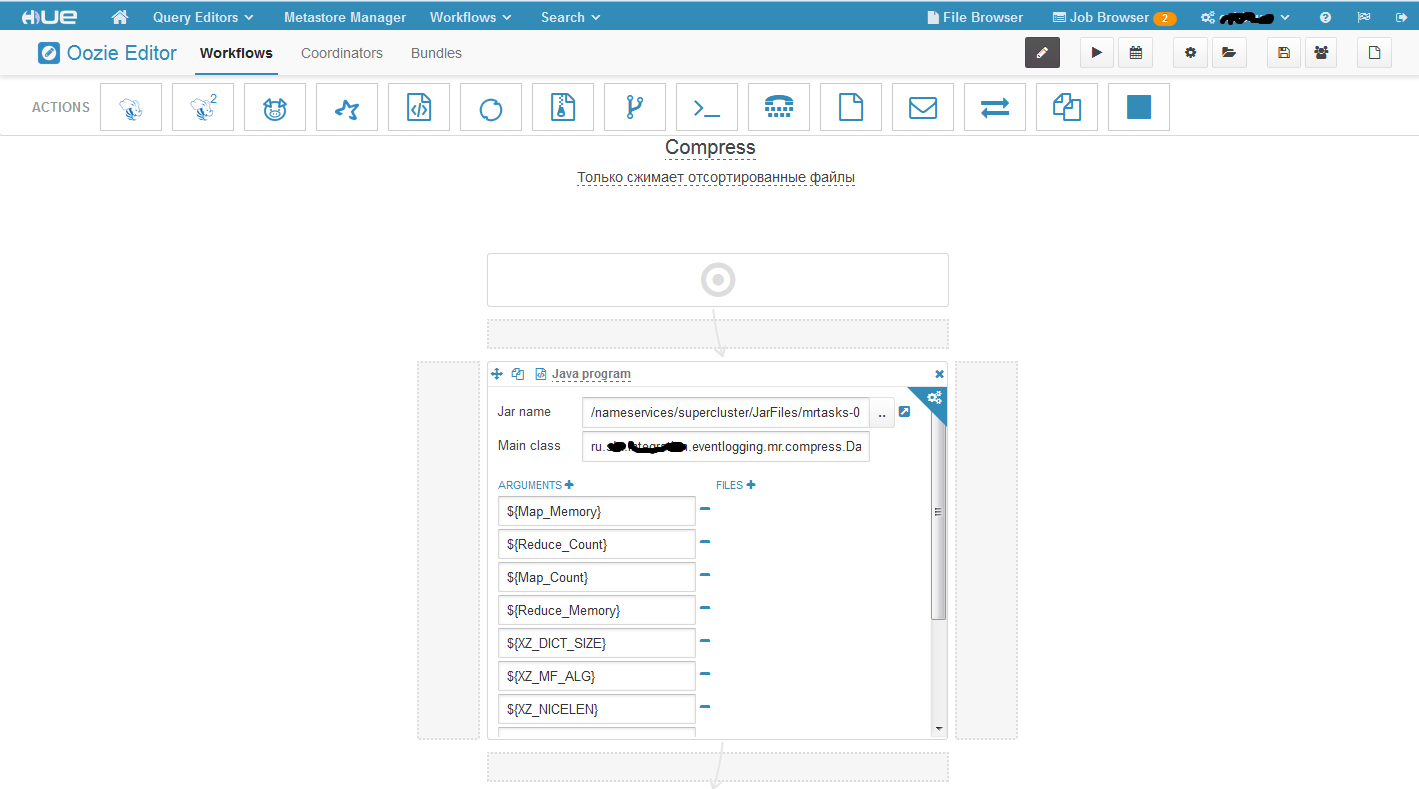
Вот как выглядит наш workflow. В поле Jar name мы указывает путь до исполняемого jar файла, который лежит у нас в HDFS. Дублировать его на все машины кластера не нужно, достаточно только поместить в HDFS. Поле Main class – это Main class. Ну а дальше параметры. В данной задаче я все параметризировал, но не обязательно параметризировать все параметры. Здесь стоит обратить на один очень важный момент! Часть параметров которые передаются задаются в формате: -Dимя_параметра = значение, а часть просто как стринговые аргументы массива подхватываются. Дак вот сначала нужно задать все параметры формата –D, а потом стринговые аргументы либо наоборот. Если Вы их перемещаете, то он неправильно их воспримет. Например, сначала задали часть параметров формата –D, потом обычные, а потом опять формата –D, в этом случае вторая часть параметров формата –D будет воспринята, как стринговые параметры. Пришлось потратить много времени, прежде чем выявить эту особенность. Теперь давайте создадим координатор на основе нашего воркфлоу.
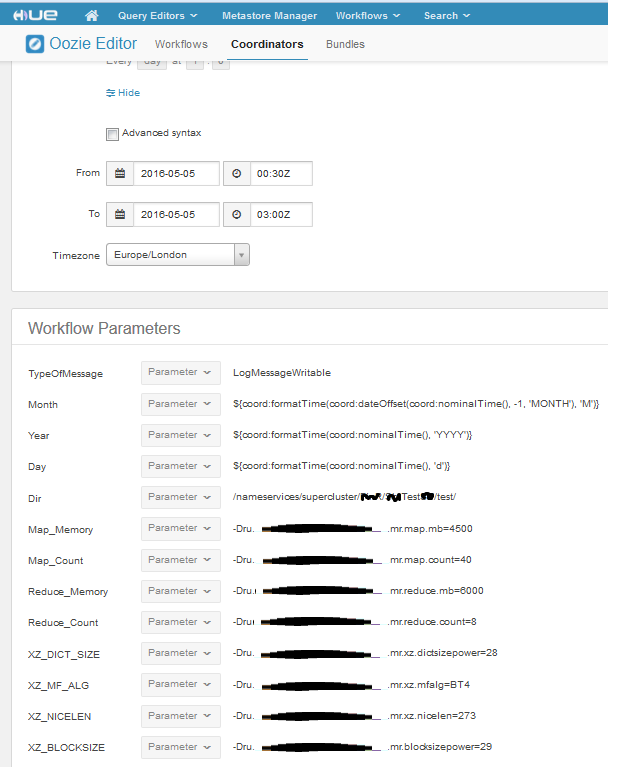
Создается он также как и в предыдущем примере.
Workflow создается аналогично предыдущему примеру, coordinator тоже аналогично. Есть одна особенность – усли у вас при запуске выдает ошибку типа main класс не найден, но вы точно положили свой jar файл в HDFS, то нужно продублировать jar файл по всем машинам в такие же директории, как он лежит в HDFS.
Ещё хочу показать разветвлённый воркфлоу:
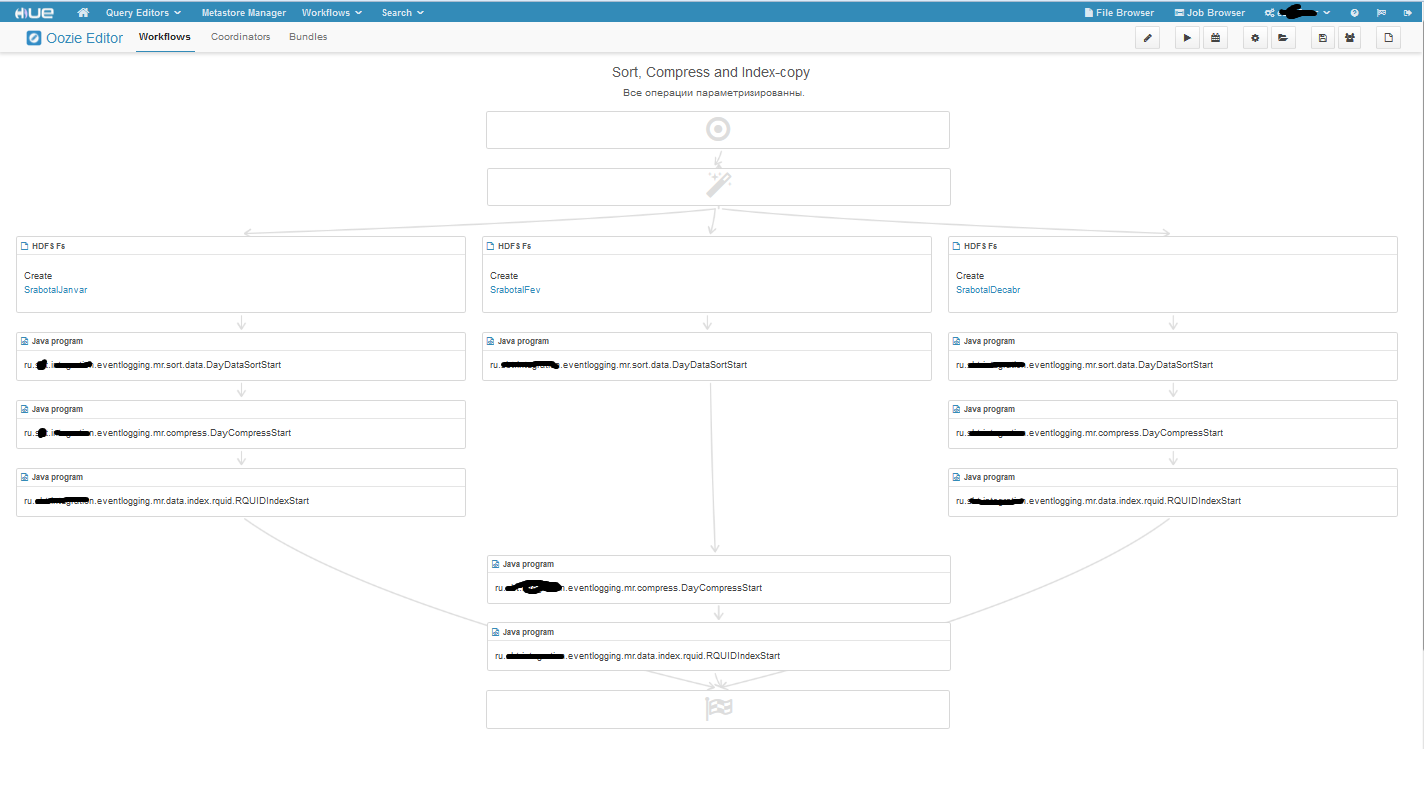
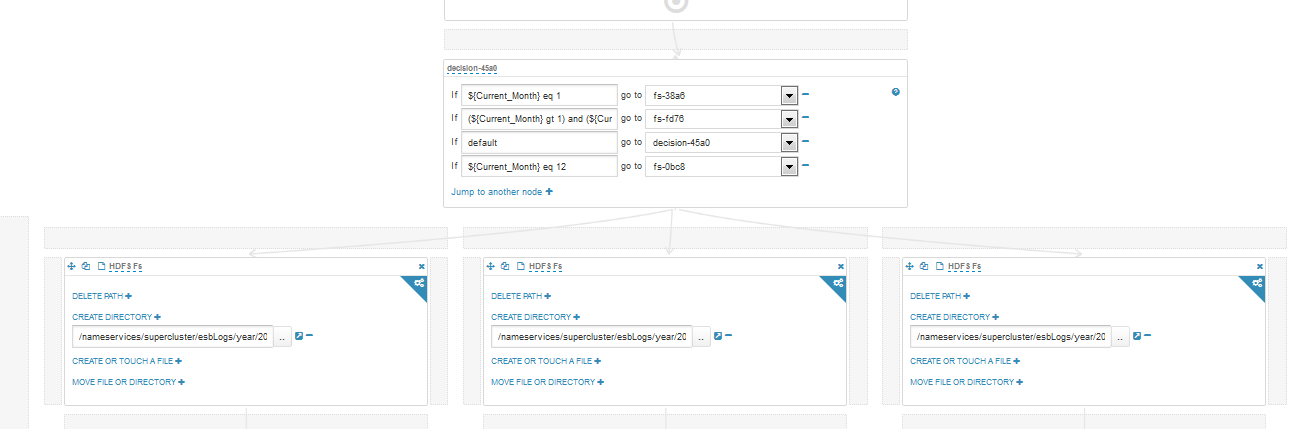
Волшебная палочка вначале воркфлоу – это блог решения, если войдем в режим редактирования, то увидим во что превращается волшебная палочка:
А на последок я скажу…
Лично мне HUE сделал работу в экосистеме Hadoop более комфортной. При этом я не использую и половину его возможностей. Я ничего не сказал про другие связки HUE, потому что либо они совсем простые, например связка с Shell, либо я ими не пользуюсь и ничего не могу про них сказать. Также не рассказал про Query Editors, Metastore Manager, Search, так как с ними я тоже не работал. Спасибо за внимание, успехов в познании этого мира.

В данной статье я хочу рассмотреть один из компонентов экосистемы Hadoop – HUE. Произносим правильно «Хьюи» или «Эйч Ю И», но не другими, созвучными с широко известным русским словом, вариантами.
HUE (Hadoop User Experience) – это веб интерфейс для анализа данных на Hadoopе. По крайней мере так они позиционируют себя сами, . HUE – это открытый проект(open source), выпускающийся под лицензией Apache. Принадлежит HUE, на момент написания статьи, компании Cloudera. Ставится он на все наиболее популярные дистрибутивы хадупа:
- Pivotal HD 3.0
- Apache Bigtop
- HDInsight Hadoop
- MAPR
- Hortonworks Hadoop (HDP)
- Cloudera Hadoop (CDH)
Если перевести аббревиатуру HUE, то получиться, что-то вроде «Опыт пользователей хадупа» или «Хадупный пользовательский опыт». И это действительно так. Я пришел к HUE, имея некоторый опыт работ с хадупом. Работал я с хадупом как через консоль, так и через CDM(cloudera manager). В основном пользовался фреймворками Spark и YARN, а также совсем чуть-чуть Oozie. И со временем у меня накопилась пара идей/пользовательских требований:
- Было бы неплохо иметь возможность быстро посмотреть с какими конфигурациями запускалась задача в YARN.
- Было бы здорово иметь более функциональный файловый браузер, чем нативный от Cloudera(я пользовался не Enterprise версией).
- Было бы ВОСХИТИТЕЛЬНО иметь более удобный, более автоматизированный планировщик заданий, чем Oozie.
Это был мой пользовательский опыт, и он был реализован в HUE. Начну с файлового браузера. Он намного удобней чем нативный от клоудеры. Можно создавать/копировать/перемещать файлы и директории из одного места в HDFS в другое. Можно менять права доступа а также заливать файлы с локальной машины в HDFS, и открывать файлы, некоторых форматов (.txt, .seq), не скачивая их на локальную машину. Планировщик заданий – это по сути автоматизированный Oozie. HUE сам создает job.properties и workflow.xml, в общем всю ту рутинную работу что в Oozie приходилось делать руками HUE делает за нас! Ниже я приведу несколько примеров и расскажу об этом подробнее.
Но HUE – это не только файловый браузер и scheduler (планировщик задач), это набор приложений, дающих доступ практически ко всем модулям кластера, а также платформа для разработки приложений.
В этой статье будет рассказано о связках HUE + Oozie, HUE + YARN, HUE + Spark, HUE + HDFS.
HUE + Oozie
Для начала напомню, что есть 3 основные типа задач в Oozie:
- Workflow – это Направленные Ацикличные Графы действий (DAGs action). Или, по-русски говоря, это просто какая-то задача(Map Reduce задача, YARN задача, Spark задача, задача по работе с HDFS и т.п.);
- Coordinator – это Workflow, с заданным временем/частотой запуска;
- Bundle – это высший уровень абстракции в Oozie. Представляет собой набор из Coordinators, не обязательно связанных между собой (я не пользовался им, так особо ничего сказать не могу).
В верхней части экрана есть раздел Workflows, в нем два подраздела Dashboards и Editors, а в них соответственно подразделы для каждого типа задач.
Dashbord – это мониторинг запущенных/отработанных задач.
Editor – это редактор Oozie задач.
Dashbord
В Dashbord отображаются Oozie задачи. Т.е. если у вас висит какой-то координатор, который запускает воркфлоу(например задачу выполняющуюся в YARN) в 18.00, а сейчас только 12 часов дня, то в YARN Resource Manager вы не увидите ее, так как там отображаются только запущенные задачи, а в Dashbord она будет висеть, со статусом Running/Prepare (Running – если уже хотя бы один раз задача исполнялась, например координатор висит со вчерашнего дня и вчера уже был запуск воркфлоу; Prepare – если задача ещё ни разу не выполнялась). Ниже на картинке показан кусочек моего Dashbord, думаю по ней все понятно без дополнительных объяснений (черным замазал конфиденциальную информацию).
Editors
Начнем с раздела Workflows. В этом разделе отображаются все имеющиеся и доступные для данного пользователя Workflow. Отсюда можно запускать, делиться с другими пользователями, копировать, удалять, импортировать, экспортировать и создавать воркфлоу, а также некоторая информация о них. Рассмотрим процесс создания нового workflow:
В строке ACTIONS все возможные действия, на основе которых можно составить workflow, а именно: Hive Script, Hive Server2 Script, Pig Script, Spark program, Java program, Sqoop 1, Map Reduce job, Subworkflow, Shell, Ssh, HDFS fs, Email, Streaming, Distcp, Kill.
HUE + HDFS
Создадим простенький workflow, который создает директорию в HDFS, при этом параметризуем его.
Где ${Dir} – это переменная, значением которой будет директория из которой будет создаваться наша директория.
${Year}, ${Month}, ${Day} – это тоже переменные, их назначение понятно.
Вокруг нашего действия появились серые поля, в них тоже можно помещать действия, таким образом можно получить разветвленный воркфлоу с несколькими выходами, пример такого воркфлоу покажу позже. Также появились шестеренки в углах нашего действия и stop действия. Нажимая на эти шестеренки, мы перейдем в меню настроек. Для каждого типа действия свои настройки, но есть общий набор настроек, например последовательность. К какому действию перейти при удачном завершении задачи, к какому действию при неудачном завершении задачи.
Если мы запустим наш воркфлоу, то он попросить задать значения переменных. Теперь давайте создадим coordinator, на основе нашего workflow.
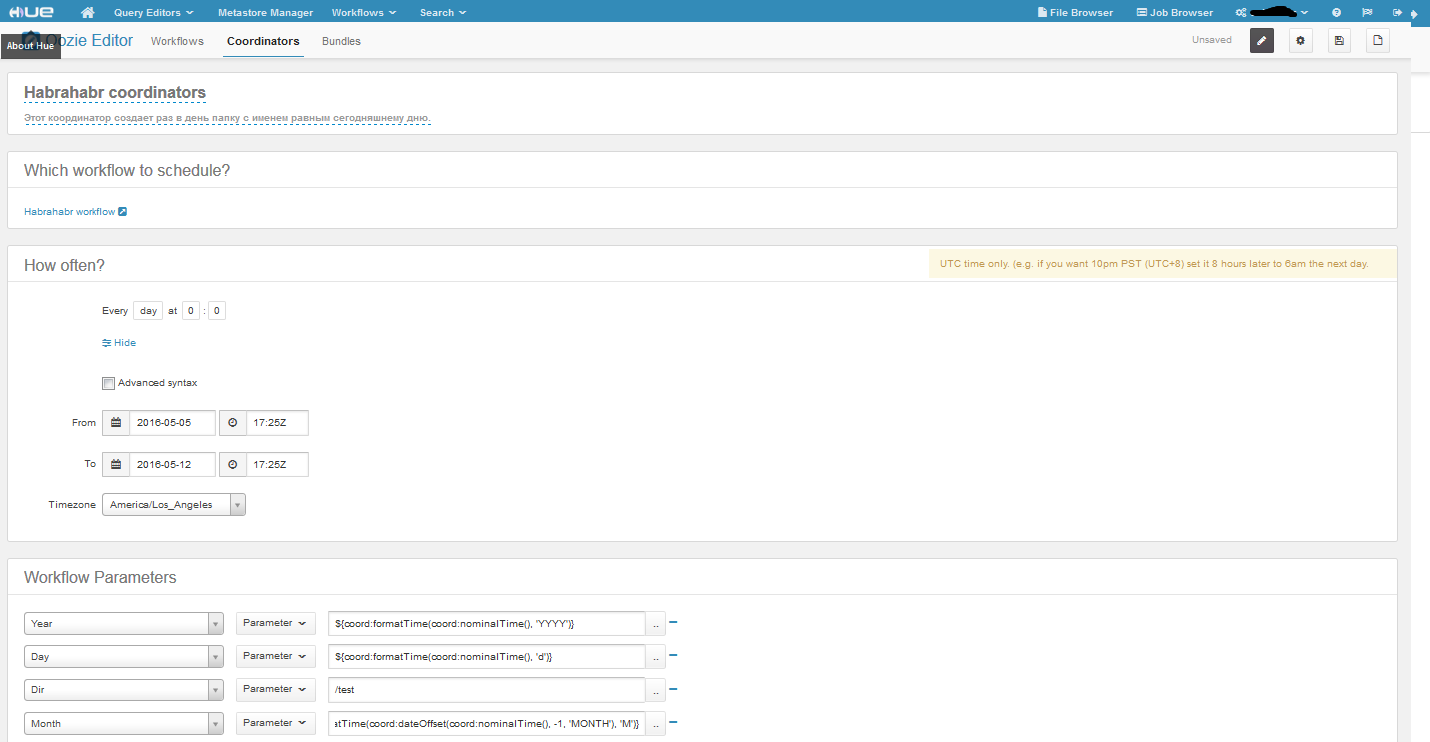
Вот наш координатор. Временные рамки задаем в соответствующих полях, тут все просто, единственная особенность, это то что можно запустить задачу в прошлом. В координаторе есть два вида времени nominal и actual. Nominal – это то которое идет во временных рамках, а actual – это реальное время. Про что хочу сказать ещё, это про Advanced syntax, сделав этот чекбокс активным, появится возможность задавать частоту в формате crontab. С частотой вроде бы все. Что касается параметров нашего workflow, то мы задали их с помощью EL функций (Expression Language Functions ). Функция заданная в переменной год вернет значение – 2016, день – 5, а вот с месяцем интересней – она вернет номер предыдущего месяца(начало не влезло, но оно такое же как у дня и года). Ну и Dir – это константа. По настройкам наш координатор запускается раз в день в течение недели, а значит, что у нас будет 7 папок, лежащих в HDFS по пути /test/2016/4/. Вот такой простенький пример, практического применения он не имеет, но если его немного изменить, например пусть наша задача не создает папки, а удаляет папки с логами за предыдущий день/месяц/год, то уже будет польза.
HUE + YARN
Можно создавать workflow с действиями типа Java program, MapReduce program и также их параметризировать как в примере со связкой с HDFS. Процесс исполнения задачи будет логироваться, при чем логи в HUE вытягиваются из YARN Resource Manager или History Server. Только они немного более удобно структурированы (это уже дело вкуса, конечно). И ещё одно отличие от прямого запуска задачи на YARN, это то, что затрачивается чуть больше ресурсов. Так как сначала создается Oozie задача, целью которой будет вызов нашего воркфлоу(Java/MapReduce/Spark задачи). Эта Oozie задача съедает одно ядро (vcore, а не реальное ядро) и 1.5 Gb RAM на кластере.
Данную связку рассмотрим на примере запуска MapReduce процедур, вызывая ее из Java program действия в воркфлоу.
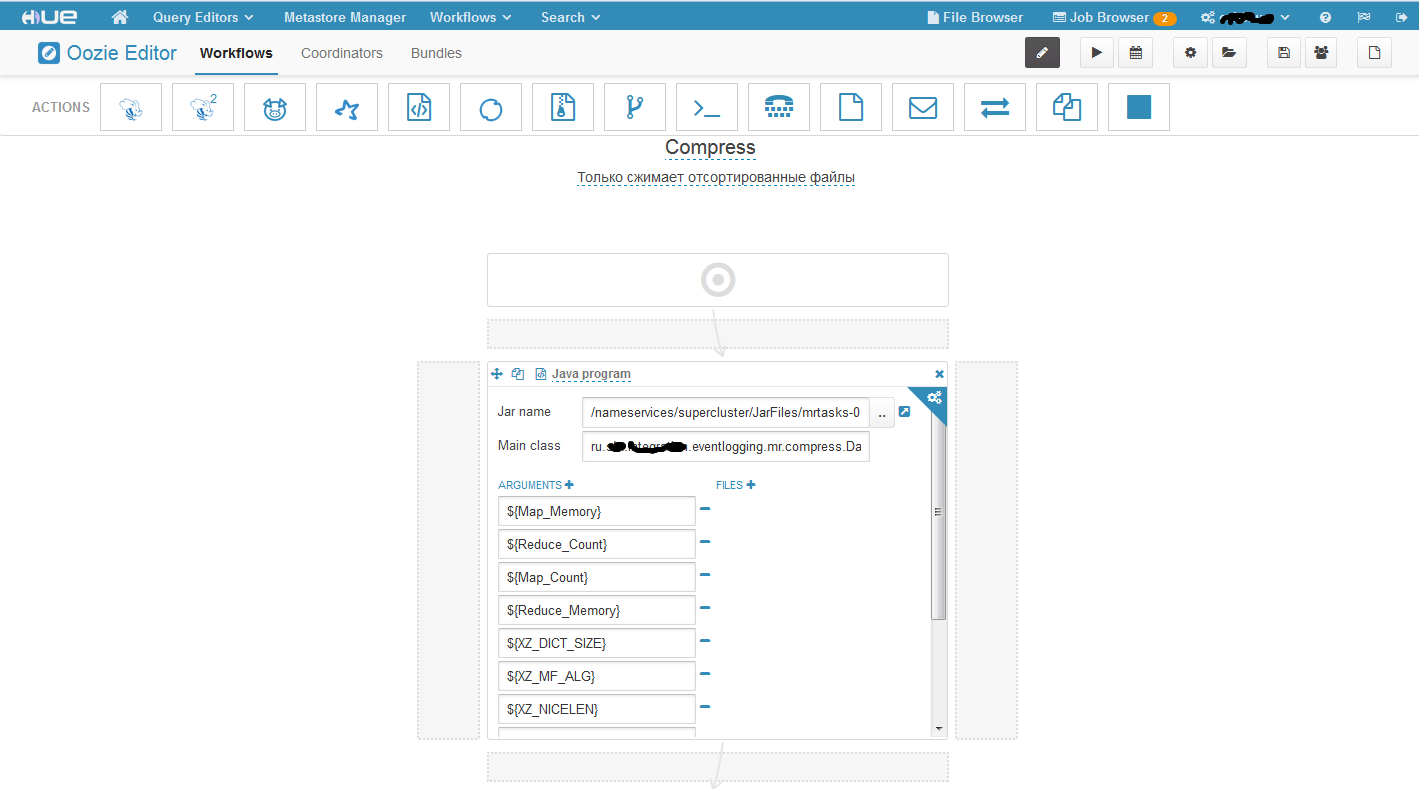
Вот как выглядит наш workflow. В поле Jar name мы указывает путь до исполняемого jar файла, который лежит у нас в HDFS. Дублировать его на все машины кластера не нужно, достаточно только поместить в HDFS. Поле Main class – это Main class. Ну а дальше параметры. В данной задаче я все параметризировал, но не обязательно параметризировать все параметры. Здесь стоит обратить на один очень важный момент! Часть параметров которые передаются задаются в формате: -Dимя_параметра = значение, а часть просто как стринговые аргументы массива подхватываются. Дак вот сначала нужно задать все параметры формата –D, а потом стринговые аргументы либо наоборот. Если Вы их перемещаете, то он неправильно их воспримет. Например, сначала задали часть параметров формата –D, потом обычные, а потом опять формата –D, в этом случае вторая часть параметров формата –D будет воспринята, как стринговые параметры. Пришлось потратить много времени, прежде чем выявить эту особенность. Теперь давайте создадим координатор на основе нашего воркфлоу.

Создается он также как и в предыдущем примере.
HUE + Spark
Workflow создается аналогично предыдущему примеру, coordinator тоже аналогично. Есть одна особенность – усли у вас при запуске выдает ошибку типа main класс не найден, но вы точно положили свой jar файл в HDFS, то нужно продублировать jar файл по всем машинам в такие же директории, как он лежит в HDFS.
Ещё хочу показать разветвлённый воркфлоу:
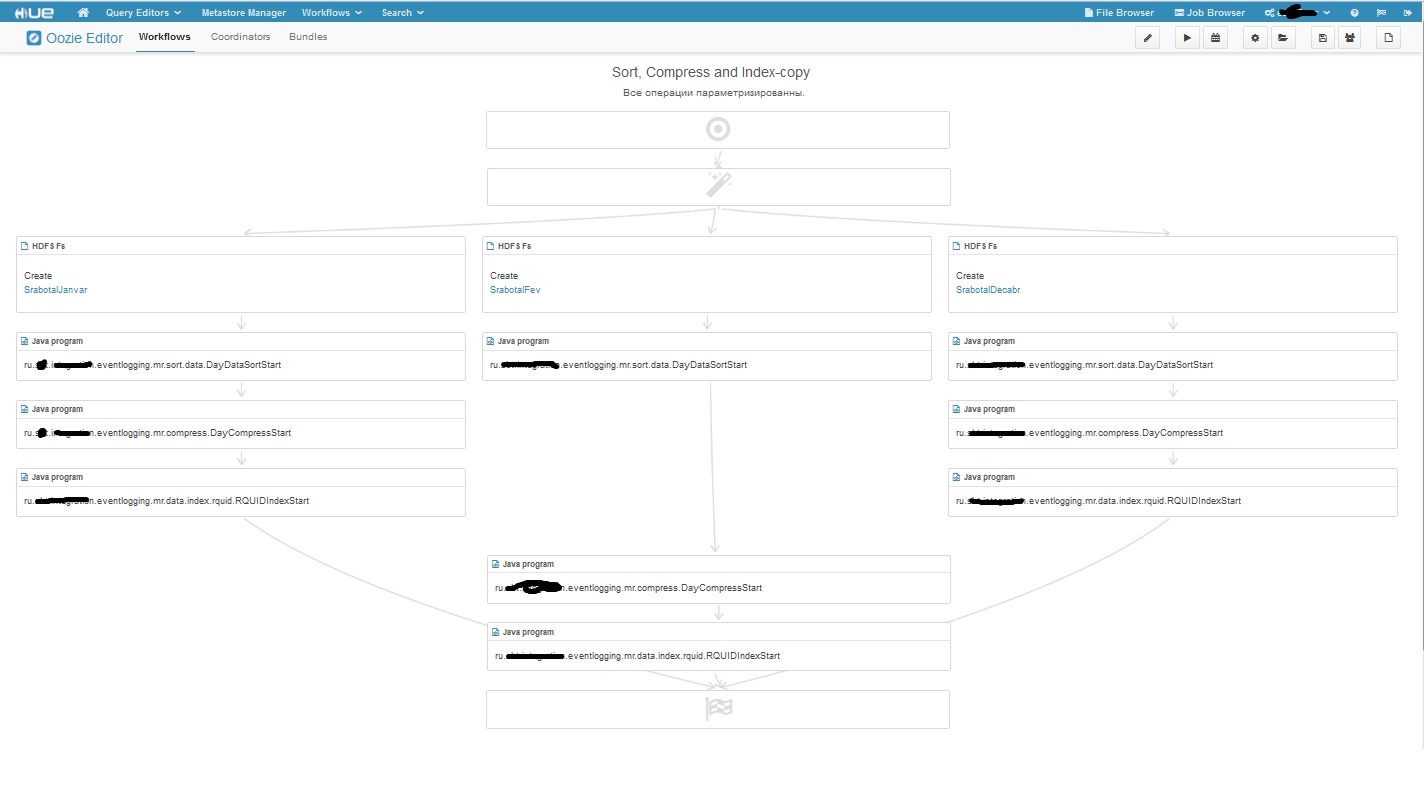
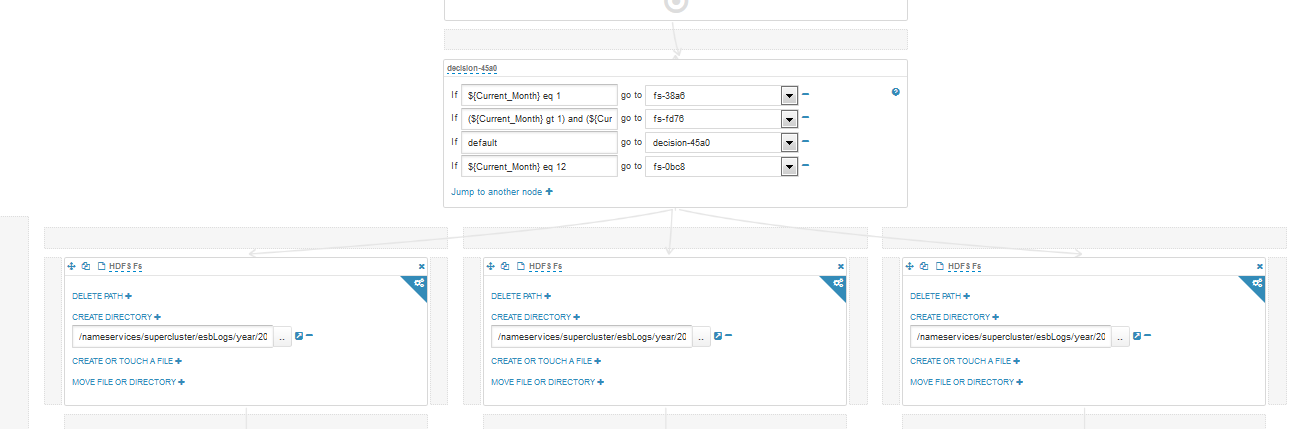
Волшебная палочка вначале воркфлоу – это блог решения, если войдем в режим редактирования, то увидим во что превращается волшебная палочка:
А на последок я скажу…
Лично мне HUE сделал работу в экосистеме Hadoop более комфортной. При этом я не использую и половину его возможностей. Я ничего не сказал про другие связки HUE, потому что либо они совсем простые, например связка с Shell, либо я ими не пользуюсь и ничего не могу про них сказать. Также не рассказал про Query Editors, Metastore Manager, Search, так как с ними я тоже не работал. Спасибо за внимание, успехов в познании этого мира.








