Приветствую уважаемые.
«Ехали регулярные выражения, через регулярные выражения, видят регулярные выражения, в регулярных выражениях, регулярные выражения — регулярные выражения, регулярные выражения, регулярные выражения...»
Нет. Это не бред сумасшедшего. Именно так я хотел назвать мой небольшой обзор на тему поиска регулярных выражений с помощью регулярных выражений. Что по сути тоже не меньший бред. Даже не знаю может ли вам такое в жизни пригодиться. Лучше конечно избегать таких ситуаций когда надо искать непонятно что, непонятно где. Ведь что такое регулярное выражение? Да почти всё что угодно!
Вам может показаться странным, но:
Но давайте без паники, попробуем приступить, может что и выйдет приличное.
Регулярное выражение – это нечто в ограничителях и возможно с модификаторами в конце. К примеру, что-нибудь такое:
/регулярное выражение/isux
Ограничителем в регулярном выражении PCRE может являться не-цифра, не-буква, не-пробельный символ, не обратный слеш. [^\s\w\\] К тому же этот символ одновременно должен быть из ASCII: [[:ascii:]], иначе можно поймать всякие интересности ︷типа︷ ¼таких¼ как …эти…
Не надо меня только спрашивать, кому такое может в голову прийти.
Существуют также парные ограничители: ()[]{}<>. Т.е. первым ограничителем не может являться закрывающий парный ограничитель: [^\s\w\\\)\]\}\>]
Итого имеем условие поиска для первого ограничителя:
(?=[[:ascii:]]) [^\s\w\\\)\]\}\>]
К сожалению, мы не сможет проверить, какой именно символ попал к нам в качестве первого ограничителя, но мы можем ловить в скобки отдельно парные <,(,[,{ символы:
Данное регулярное выражение найдёт и распотрошит на: ([1] => ограничитель, [7] => шаблон, [8] =>модификаторы) только одно регулярное выражение. Т.к. используется жадный квантификатор .* который кушает всё до конца, а потом только бэктрекает до ближайшего совпадения. При большом желании оно может распотрошить само себя.
Настоящая жесть начинается тогда, когда нам нужно найти и распотрошить не одно регулярное выражение в одном тексте.
Во-первых, нужно использовать ленивый квантификатор (.*?)
Во-вторых, нужно искать совпадение с неэкранированным ограничителем, который, в свою очередь, может оказаться волею судеб закомментированным. А как вам вариант ограничителя с экранированным обратным слешем перед ним? / \\ \/ \\/is
Добро пожаловать в ад:
((?#ignore comments like this in the regular expression)
(?(6)
(?(?=
(?:(?!\6).|(?<=\\)\6)*[^\\][\(][\?][\#])
(?:(?!\6).|(?<=\\)\6)*[^\\][\(][\?][\#]
[^\)]*
(?-1)
))
.*?)
Немного поясню данный код:
1) Мы не можем искать [^\6], т.к. в символьном классе наш указатель теряет свою волшебную силу. Но благодаря опережающей негативной проверке мы можем проверить любой символ: [^\6]* => ((?!\6).)*
2) (?(?=строка)строка) – может показаться бессмысленным, но это необходимо в случаях когда нужно что-то добавить.
3) (?-1) – при совпадении снова проверять на совпадение. В данном случае мы ищем, например, совпадение (?# / в случае нахождения захватываем до закрывающей скобки.
Итого, на данный момент, мы имеем следующее: (upd: в конце статьи есть доработанный вариант)
Энтузиазм у меня ещё не угас, но навалилась работа. Если у кого есть желание — можно помучиться.
Текущие цели и задачи:
1) Еще не решена проблема с ограничителями-скобками. К сожалению для нас скобки можно не экранировать внутри:
((регулярное)(выражение))isu
2) Нужно добавить игнорирование ограничителей между # и переводом строки
3) Закрывающие парные ограничители в комментариях
4) Красиво решить проблему с экранированными \ перед последним ограничителем.
Ссылка на последний вариант, для желающих помочь довести дело до конца
Спасибо за внимательное внимание компьютерные маньяки.
Update:
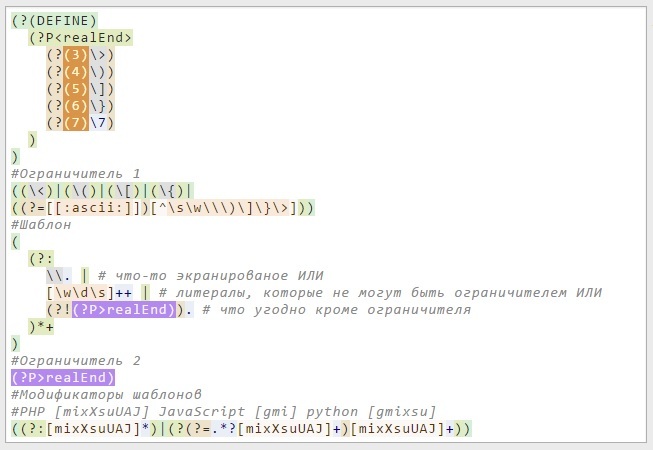
Благодаря ReinRaus, на текущий момент мы имеем следующую картину, вполне себе описывающую регулярное выражение:
«Ехали регулярные выражения, через регулярные выражения, видят регулярные выражения, в регулярных выражениях, регулярные выражения — регулярные выражения, регулярные выражения, регулярные выражения...»
Нет. Это не бред сумасшедшего. Именно так я хотел назвать мой небольшой обзор на тему поиска регулярных выражений с помощью регулярных выражений. Что по сути тоже не меньший бред. Даже не знаю может ли вам такое в жизни пригодиться. Лучше конечно избегать таких ситуаций когда надо искать непонятно что, непонятно где. Ведь что такое регулярное выражение? Да почти всё что угодно!
Вам может показаться странным, но:
.это, например, вполне себе регулярное выражение:.
(Или это тоже может быть (можете даже проверить))
~это~
<script src="И это - регулярка, вполне рабочая и может быть даже кому нибудь очень необходимая.js">Но давайте без паники, попробуем приступить, может что и выйдет приличное.
Регулярное выражение – это нечто в ограничителях и возможно с модификаторами в конце. К примеру, что-нибудь такое:
/регулярное выражение/isux
Ограничителем в регулярном выражении PCRE может являться не-цифра, не-буква, не-пробельный символ, не обратный слеш. [^\s\w\\] К тому же этот символ одновременно должен быть из ASCII: [[:ascii:]], иначе можно поймать всякие интересности ︷типа︷ ¼таких¼ как …эти…
Не надо меня только спрашивать, кому такое может в голову прийти.
Существуют также парные ограничители: ()[]{}<>. Т.е. первым ограничителем не может являться закрывающий парный ограничитель: [^\s\w\\\)\]\}\>]
Итого имеем условие поиска для первого ограничителя:
(?=[[:ascii:]]) [^\s\w\\\)\]\}\>]
К сожалению, мы не сможет проверить, какой именно символ попал к нам в качестве первого ограничителя, но мы можем ловить в скобки отдельно парные <,(,[,{ символы:
Регулярное выражение для поиска одного регулярного выражения
/(
(\<) |
(\() |
(\[) |
(\{) |
((?=[[:ascii:]])[^\s\w\\\)\]\}\>])
)
#А потом поставить к нему подходящий закрывающий ограничитель:
(.*)
(?(2)\>)
(?(3)\))
(?(4)\])
(?(5)\})
(?(6)\6)
#Ну и можно залакировать всё это дело модификаторами:
([mixXsuUAJ]*)
/xs
(\<) |
(\() |
(\[) |
(\{) |
((?=[[:ascii:]])[^\s\w\\\)\]\}\>])
)
#А потом поставить к нему подходящий закрывающий ограничитель:
(.*)
(?(2)\>)
(?(3)\))
(?(4)\])
(?(5)\})
(?(6)\6)
#Ну и можно залакировать всё это дело модификаторами:
([mixXsuUAJ]*)
/xs
Данное регулярное выражение найдёт и распотрошит на: ([1] => ограничитель, [7] => шаблон, [8] =>модификаторы) только одно регулярное выражение. Т.к. используется жадный квантификатор .* который кушает всё до конца, а потом только бэктрекает до ближайшего совпадения. При большом желании оно может распотрошить само себя.
Настоящая жесть начинается тогда, когда нам нужно найти и распотрошить не одно регулярное выражение в одном тексте.
Во-первых, нужно использовать ленивый квантификатор (.*?)
Во-вторых, нужно искать совпадение с неэкранированным ограничителем, который, в свою очередь, может оказаться волею судеб закомментированным. А как вам вариант ограничителя с экранированным обратным слешем перед ним? / \\ \/ \\/is
Добро пожаловать в ад:
((?#ignore comments like this in the regular expression)
(?(6)
(?(?=
(?:(?!\6).|(?<=\\)\6)*[^\\][\(][\?][\#])
(?:(?!\6).|(?<=\\)\6)*[^\\][\(][\?][\#]
[^\)]*
(?-1)
))
.*?)
Немного поясню данный код:
1) Мы не можем искать [^\6], т.к. в символьном классе наш указатель теряет свою волшебную силу. Но благодаря опережающей негативной проверке мы можем проверить любой символ: [^\6]* => ((?!\6).)*
2) (?(?=строка)строка) – может показаться бессмысленным, но это необходимо в случаях когда нужно что-то добавить.
3) (?-1) – при совпадении снова проверять на совпадение. В данном случае мы ищем, например, совпадение (?# / в случае нахождения захватываем до закрывающей скобки.
Итого, на данный момент, мы имеем следующее: (upd: в конце статьи есть доработанный вариант)
Регулярное выражение для поиска регулярных выражений
/#Ограничитель 1
((\<)|(\()|(\[)|(\{)|
((?=[[:ascii:]])[^\s\w\\\)\]\}\>]))
#Шаблон
((?#ignore comments like this in the regular expression)
(?(6)
(?(?=(?:(?!\6).|(?<=\\)\6)*[^\\][\(][\?][\#])
(?:(?!\6).|(?<=\\)\6)*[^\\][\(][\?][\#]
[^\)]*(?-1)))
.*?)
#Ограничитель 2
#экранированные обратные слеши +
#неэкранированный ограничитель
(?(2)(?<!(?<!(?<!(?<!(?<!(?<!(?<!(?<!\\)\\)\\)\\)\\)\\)\\)\\)\>)
(?(3)(?<!(?<!(?<!(?<!(?<!(?<!(?<!(?<!\\)\\)\\)\\)\\)\\)\\)\\)\))
(?(4)(?<!(?<!(?<!(?<!(?<!(?<!(?<!(?<!\\)\\)\\)\\)\\)\\)\\)\\)\])
(?(5)(?<!(?<!(?<!(?<!(?<!(?<!(?<!(?<!\\)\\)\\)\\)\\)\\)\\)\\)\})
(?(6)(?<!(?<!(?<!(?<!(?<!(?<!(?<!(?<!\\)\\)\\)\\)\\)\\)\\)\\)\6)
#Модификаторы шаблонов
#PHP [mixXsuUAJ] JavaScript [gmi] python [gmixsu]
((?(6)(?:[mixXsuUAJ]*)|(?(?=.*?[mixXsuUAJ]+)[mixXsuUAJ]+)))/xs
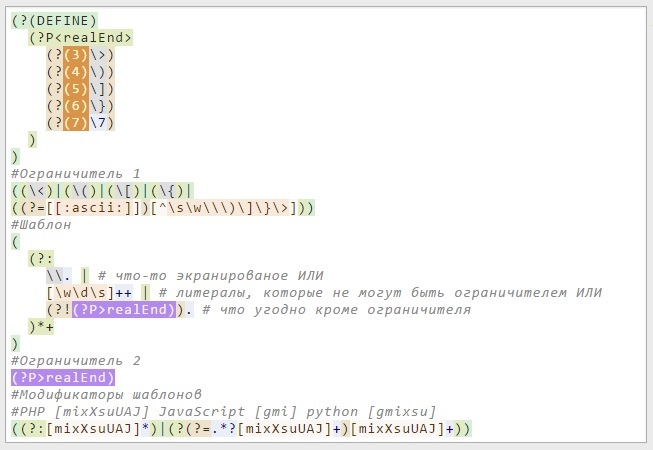
((\<)|(\()|(\[)|(\{)|
((?=[[:ascii:]])[^\s\w\\\)\]\}\>]))
#Шаблон
((?#ignore comments like this in the regular expression)
(?(6)
(?(?=(?:(?!\6).|(?<=\\)\6)*[^\\][\(][\?][\#])
(?:(?!\6).|(?<=\\)\6)*[^\\][\(][\?][\#]
[^\)]*(?-1)))
.*?)
#Ограничитель 2
#экранированные обратные слеши +
#неэкранированный ограничитель
(?(2)(?<!(?<!(?<!(?<!(?<!(?<!(?<!(?<!\\)\\)\\)\\)\\)\\)\\)\\)\>)
(?(3)(?<!(?<!(?<!(?<!(?<!(?<!(?<!(?<!\\)\\)\\)\\)\\)\\)\\)\\)\))
(?(4)(?<!(?<!(?<!(?<!(?<!(?<!(?<!(?<!\\)\\)\\)\\)\\)\\)\\)\\)\])
(?(5)(?<!(?<!(?<!(?<!(?<!(?<!(?<!(?<!\\)\\)\\)\\)\\)\\)\\)\\)\})
(?(6)(?<!(?<!(?<!(?<!(?<!(?<!(?<!(?<!\\)\\)\\)\\)\\)\\)\\)\\)\6)
#Модификаторы шаблонов
#PHP [mixXsuUAJ] JavaScript [gmi] python [gmixsu]
((?(6)(?:[mixXsuUAJ]*)|(?(?=.*?[mixXsuUAJ]+)[mixXsuUAJ]+)))/xs
Энтузиазм у меня ещё не угас, но навалилась работа. Если у кого есть желание — можно помучиться.
Текущие цели и задачи:
((регулярное)(выражение))isu
Ссылка на последний вариант, для желающих помочь довести дело до конца
Спасибо за внимательное внимание компьютерные маньяки.
Update:
Благодаря ReinRaus, на текущий момент мы имеем следующую картину, вполне себе описывающую регулярное выражение: