Комментарии 117
Последовательность простых чисел это хаотическая последовательность, а не случайная, почему они удивляются, если находят закономерности в хаотической системе, не понимаю.
Они удивляются, что их раньше не нашли.
Причем заметьте, они не удивляются что число 2 один раз встречается. 4 — вообще не разу, но при этом удивляются что 9 встречается на 30% реже чем 7.
Про 2 и 4 результат доказан, и любой человек в теме на вопрос "сколько раз встречается 2" сходу ответит правильно. А вот на вопрос "как соотносятся 9 и 7 среди последних цифр простых чисел" — возможно, не ответит (хотя может быть специалистам по ТЧ ответ и очевиден; надо поймать такого и допросить).
Насчет хаотичности не доказано, как и не доказано обратное. Если не ошибаюсь, это одна из проблем современной математики (да и не современной тоже).
Вы, похоже, не в курсе что называется хаотической последовательностью, а что случайной.
Если вы меня просветите линком или текстом, буду рад!
Если сильно упростить, то хаотическая последовательность подчиняется правилам, а случайная нет. Каждое новое простое число не должно делиться нацело ни на одно из меньших чисел. Благодаря этому правилу формируется хаотическая последовательность, более того она детерминированная. Остальное лучше читать в книгах по теории хаоса, в любой будет хорошо написано чем случайность отличается от хаоса.
Можно сказать, что "Генератор псевдослучайных чисел" = "Генератор хаотических чисел"? Тут и детерминированность и зависимость от начальных данных
Вы верно говорите, генератор псевдослучайных чисел и есть генератор хаотических последовательностей. Но некоторые генераторы так сделаны, что они исходную хаотическую последовательность изменяют случайными данными, например берут системное время вызова функции или другую случайную величину и с её помощью делают действительно случайную последовательность. Минусующим неучам советую книги читать.
Мне тоже было показалось, что они удивились тому, что такую закономерность нашли, а не наоборот. Мне кажется с толку сбивает предложение:
правильнее было бы сказать
«Не могу поверить, что кто-то смог до этого додуматься. Это выглядит очень странно»
правильнее было бы сказать
«Не могу поверить, что НИКТО НЕ смог до этого додуматься РАНЬШЕ. Это выглядит очень странно»
Закон Берфорда ?https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BA%D0%BE%D0%BD_%D0%91%D0%B5%D0%BD%D1%84%D0%BE%D1%80%D0%B4%D0%B0
закон Берфорда при всей его красоте про первую цифру а не про последнюю
Ну при том что рассматривается последняя цифра в очень большом промежутке значений (где закон Берфорда как раз и сияет), можно предположить, что он сработает и тут. Соотношения последних цифр будут другими, но вполне возможно, что график будет очень похожим.
К первым цифрам простых чисел он вроде даже как применим.
НЛО прилетело и опубликовало эту надпись здесь
Проверим данное свойство? У кого какой процент получился?
Независимые экспериментаторы сообщают, что на деле получается наоборот
на свободном vds решил запустить утилитку, которая будет это дело подсчитывать вплоть до Long.MAX_VALUE
Результат тут: http://x-noname.ru/prime.html
На данный момент разница примерно 50%
PS: Интересно, сколько чисел переберет за месяц?
Результат тут: http://x-noname.ru/prime.html
На данный момент разница примерно 50%
PS: Интересно, сколько чисел переберет за месяц?
До первого апреля ещё две недели. Раньше опубликовалось?
«Если Алиса будет кидать монетки до тех пор, пока не получит решку, следующую за орлом, а Боб – до тех пор, пока не получит две решки подряд, то Алисе в среднем потребуется четыре броска монеты, в то время как Бобу – шесть.» — в описываемой ситуации шансы равные, неправильная цитата? Подобное расхождение может появится, если Алисе нужны просто разные монетки, не важно решка, следующая за орлом или орел за решкой, тогда при первом броске у Боба есть шанс выкинуть не ту сторону, а Алисе годится любая монетка.
Самый цимес в том что Тадаши абсолютно прав. Теорвер жесток к тем кто его не понимает. :(
Накатайте скриптец с нормальным распределением и погоняйте его. А можно просто просто попросить детей сделать лабораторную и покидать монетки, а потом вместе обработать данные. В шоке будете и Вы и дети ;)
Накатайте скриптец с нормальным распределением и погоняйте его. А можно просто просто попросить детей сделать лабораторную и покидать монетки, а потом вместе обработать данные. В шоке будете и Вы и дети ;)
Неинтересно, но наглядно. Я прикладной лабораторкой над детьми обычно измываюсь (А дети потом в свою очередь над одноклассниками и другими непричастными гражданами). Заодно можно выяснить дефект монетки, например. Да и обработку реальных данных надо развивать с детства. По моему мнению.
https://jsfiddle.net/gLwg2z8y/ — оба в одном месте. Равные шансы!
https://jsfiddle.net/gLwg2z8y/2/ — вот если сохранять прошлую монетку, перекидывать только 1 — сути не меняет.
Блин. Не две монетки кидаются, а осуществляется последовательность бросков (серия). У Алисы терминальная пара орел решка, у боба — решка решка.
Сударь. Условие задачи ведь вроде нормально написано. Окститесь пока епитимью не наложили.
Сударь. Условие задачи ведь вроде нормально написано. Окститесь пока епитимью не наложили.
А понял вас, тогда понятно в чем фокус… это вот так будет: https://jsfiddle.net/gLwg2z8y/4/
Тоже не идеально, у того кто первым проверяет результат вероятность победы становится выше, но это мелочи, главное основная мысль ясна — откуда берется ключевая разница.
Что?! У них разные условия победы, последовательность проверки абсолютно никак не влияет.
Рассмотрите последний шаг внутри for, если Алиса победила — для Боба перебросят дополнительный раз, если первый проиграл, а победил второй, никаких дополнительных бросков не случиться.
Про это и был мой комментарий:
https://jsfiddle.net/gLwg2z8y/5/ — и тут это было учтено.
Без else лишние победы Бобу, без проверки Алисы.
https://jsfiddle.net/gLwg2z8y/5/ — и тут это было учтено.
Прошу прошения, туплю, спорю со своим вариантом, адресуя это вам.
Чтобы лучше понять — лучше разделить на два цикла. они ведь независимо монетки бросают:
https://jsfiddle.net/gLwg2z8y/19/
https://jsfiddle.net/gLwg2z8y/19/
Извините, там, выше, уже это решение писали.
Именно. И определяем не разы, а среднюю длину последовательности победы у Алисы и у Боба (терминальные броски входят в длину). Сконцентрируйтесь и внимательно прочитайте условие задачи.
А мне не понятно в чем «фокус». Можете объяснить почему Алиса выигрывает чаще? Уже всю голову сломал.
Проще понять, если увеличить длину искомой последовательности до 3.
Вот у нас выложена бесконечная линия из брошенных монеток — Бобу надо найти три орла, а Алисе решку и два орла. Боб видит свои три орла и бежит к ним, но фиг там ведь они лежат так X000, т.е. прямо перед ними нужная Алисе решка и она выигрывает на шаг раньше — Боб остается ни с чем. В этом примере ничего не противоречит «банальной эрудиции», а принципиально этот пример тот же самый «фокус».
Вот у нас выложена бесконечная линия из брошенных монеток — Бобу надо найти три орла, а Алисе решку и два орла. Боб видит свои три орла и бежит к ним, но фиг там ведь они лежат так X000, т.е. прямо перед ними нужная Алисе решка и она выигрывает на шаг раньше — Боб остается ни с чем. В этом примере ничего не противоречит «банальной эрудиции», а принципиально этот пример тот же самый «фокус».
Это бы происходило, если бы один бросок засчитывался и Алисе, и Бобу, а в данном случае они кидают монетки независимо, и если боб выкинет орла за решкой,, для Алисы это ничего не значит — она свои монетки кидает.
Сути это не меняет. Шанс появления определенной последовательности равны у Боба и Алисы, если Алиса найдет два орла в ней быстрее, чем Боб три — это и увеличит ее шансы в целом. Для меня от этой точки было довольно просто допереть до сути, если вам не помогает попробуйте погуглить про игру Пенни, может какое-то пояснение там лучше прояснит вам картину.
Вот пример для отдельных испытаний Боба и Алисы: https://jsfiddle.net/uuLom8oo/
Боб все равно сливает, хотя уже в меньшей степени. Полный шизняк…
Боб все равно сливает, хотя уже в меньшей степени. Полный шизняк…
После N-го прочтения вашего комментария, наконец, дошел до сути. Спасибо за понятный пример. Очень интересный «фокус».
Мне кажется, что вы как раз описали игру Пенни — поиск двух паттернов в одной случайной последовательности. Тоже удивительная вещь — для любого трехбитного паттерна имеется другой паттерн с большей вероятностью выпадения. А если у Боба и Алисы разные последовательности, то надо просто посмотреть сколько возможных вариантов.
Для Боба:
РРО
ОРР
РРР
Для Алисы:
ОРР
ОРО
РОР
ООР
Т.е. уже на 3 бросках у Алисы больше шансов.
Для Боба:
РРО
ОРР
РРР
Для Алисы:
ОРР
ОРО
РОР
ООР
Т.е. уже на 3 бросках у Алисы больше шансов.
Они не играют. Они просто проводят статистический эксперимент. А математические ожидания разные, потому что вероятностные пространства разные.
Вот что меня поражает, так это "проверка" подобных теоретичских результатов численными методами.
Вот что меня поражает, так это "проверка" подобных теоретичских результатов численными методами.
На первый взгляд кажеться, как будто задача про то, что кидая пару монет шанс получить одну комбинацию выше, чем другую. Требуются некоторые усилия, чтобы представить абстракцию, которая приведет условия задачи и собственную картину мира в соответствие — это и вызывает интерес и нестандартные подходы.
Если Алиса после орла наткнётся не на решку, а на орла, то ей не нужно "начинать всё с начала", она уже на полпути к успеху. Ведь она опять в состоянии "после орла".
Давайте немного переформулируем. Скажем, что Алиса, выкинув решку, уступает место Еве, которая выигрывает, как только выкинет орла. Пусть А, Б и Е — ожидание числа бросков для Алисы, Боба и Евы.
Е = 1 + 1/2 Е [выкинута решка, которая Еве бесполезна] + 1/2 0 [выкинут орел — Ева выиграла]
откуда Е = 2.
А = 1 + 1/2 А [выкинут орел — Алиса начинает сначала] + 1/2 Е [выкинута решка — осталось выиграть Еве]
т.е. А = 1 + А/2 + 1, откуда А = 4
Б = 1 + 1/2 Б [выкинут орел] + 1/2 (1 + 1/2 Б [после орла выпала решка — всё сначала] + 1/2 0)
откуда Б = 3/2 + 3/4Б, Б = 6.
Е = 1 + 1/2 Е [выкинута решка, которая Еве бесполезна] + 1/2 0 [выкинут орел — Ева выиграла]
откуда Е = 2.
А = 1 + 1/2 А [выкинут орел — Алиса начинает сначала] + 1/2 Е [выкинута решка — осталось выиграть Еве]
т.е. А = 1 + А/2 + 1, откуда А = 4
Б = 1 + 1/2 Б [выкинут орел] + 1/2 (1 + 1/2 Б [после орла выпала решка — всё сначала] + 1/2 0)
откуда Б = 3/2 + 3/4Б, Б = 6.
Вроде всё логично, но почему вы на каждом шаге вычисляете новое значение для предыдущей монетки, а не берёте предыдущее?
Создаётся ощущение что вы как раз таки кидаете две монетки, а не смотрите последовательность бросков.
Создаётся ощущение что вы как раз таки кидаете две монетки, а не смотрите последовательность бросков.
Всё очень просто считается, если забыть формулы и вероятности и построить дерево решений. Сразу понимаешь что у Боба гораздо выше и сложнее условие. Для примера, дерево решения для Алисы:
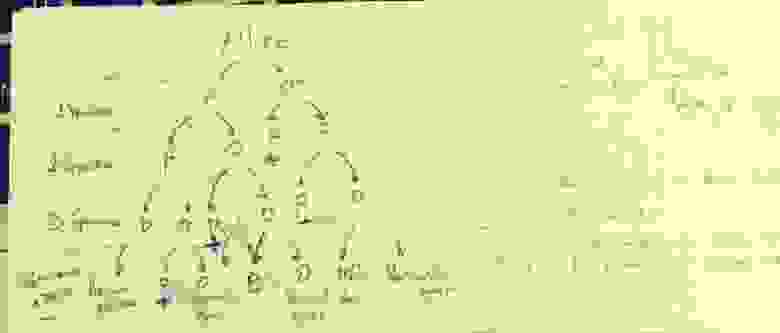

Странно что им для этого потребовалась лекция от Тадаши. Приколы с орлами и решками еще в стратегиях по потрошению рулетки (красное/черное) описаны. Да и формула Пуассона там неплохо смотрится по идентификации последовательностей.
Была давненько кстати хорошая статья на Хабре на эту тему.
Была давненько кстати хорошая статья на Хабре на эту тему.
Я кажется догадываюсь почему это. Свойство связано со свойствами числовой системы в которой мы записываем данные. Если брать те же самые распределения для простой системы счисления к примеру семиричной или одинадцатиричной, то распределение должно быть ровным.
Десятиричная системе не самая оптимальная для расчетов и изучения свойств чисел.
Десятиричная системе не самая оптимальная для расчетов и изучения свойств чисел.
У нашей десятичной системы счисления не простое основание. так что я с вами абсолютно согласен в этом вопросе. А вот в двоичной все вообще шикарно и без всяких глупостей ;)
В данном случае двоичное будет тоже не оптимальным. Для ровных результатов им нужно простое основание, которое исключает общих множителей. Семь, одинадцать, тринадцать и тд. Это предположение надо проверять.
Вроде брали основание 3 — тот же явление наблюдается. Чем 3 плохо? Вроде простое.
Большинство теоретиков сошлось бы на предположении, что шансы иметь на конце одну из возможных для простых чисел цифр (1, 3, 7, 9) примерно равны для всех таких чисел
Если 1 возможно в 3-тичной системе счисления, в остальных случаях речь идет явно не о ней. Скорее всего в статье идет речь о проверках для различных систем. Причем заметьте, цифра 2 будет встречаться всего один раз а 4 к примеру вообще не разу. При этом ученые удивляются что 9 встречается реже чем 7.
> Он обнаружил, что если записать простые числа в троичной системе, в которой примерно половина простых чисел оканчивается
> цифрой 1, а половина – цифрой 2, то для простых чисел, меньших 1000, за числом, оканчивающимся на цифру 1, в два раза более
> вероятно будет следовать число, оканчивающееся на 2, чем снова на 1.
> цифрой 1, а половина – цифрой 2, то для простых чисел, меньших 1000, за числом, оканчивающимся на цифру 1, в два раза более
> вероятно будет следовать число, оканчивающееся на 2, чем снова на 1.
Вы можете не верить, но 2 — простое число.
Если вы употребляете слово "оптимальная", тогда надо уточнять по какому параметру оптимальная. Тут больше подошел бы более абстрактный термин "удобная" или "рациональная".
Поделюсь еще одним "поразительным" наблюдением. В двоичной системе шанс, что за простым числом, оканчивающимся на 1, будет следовать число, оканчивающееся на 1 равен 100%.
В свое время задумался над закономерностями простых чисел. Получилось примерно так.
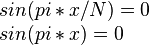
Первое уравнение имеет решения в точках, кратных N, второе в точках, кратных 1 (целые числа).
Рассмотрим первое уравнение отдельно. Заменим константу N на переменную y, получится трехмерный график
В плоскости x = P, где P — некоторое целое число, уравнение будет такое:
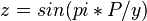
Уравнение имеет решения во всех точках y, где P/y дает целое число; y при этом может быть дробным, например 1.33(3) = 8 / 6.
Трехмерный график нам больше не нужен, поэтому для наглядности можно вернуться в 2 измерения и заменить обозначения y и z на обозначения x и y.
Чтобы найти целочисленные решения, можно сделать так.
Оба уравнения возведем в квадрат, точки пересечения с 0 от этого не изменятся. У первого уравнения график выше оси X. Второе уравнение возьмем со знаком минус, график ниже оси X.
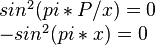
График для P = 8 (точки пересечения: 1, 2, 4, 8):
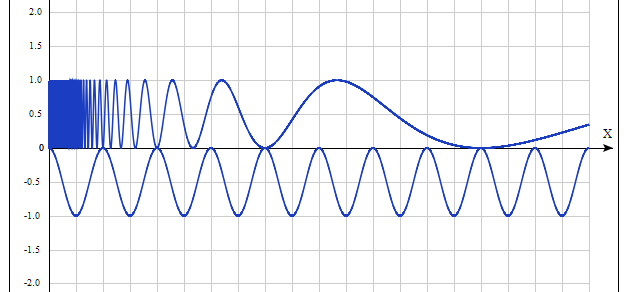
Так вот. Число P является простым, если на промежутке [1, P] есть всего 2 решения — 1 и P.
При решении у меня получилась такая система:
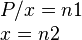
Что в принципе и логично: x — целое число, P/x — другое целое число. Поэтому ничего особенного здесь нет, просто интересное наблюдение.

Первое уравнение имеет решения в точках, кратных N, второе в точках, кратных 1 (целые числа).
Рассмотрим первое уравнение отдельно. Заменим константу N на переменную y, получится трехмерный график
z = sin(pi*x/y). Выглядит он как график синуса, у которого волна увеличивается с увеличением y.В плоскости x = P, где P — некоторое целое число, уравнение будет такое:

График для P = 8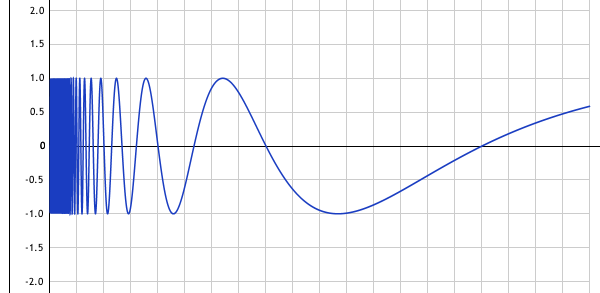

Уравнение имеет решения во всех точках y, где P/y дает целое число; y при этом может быть дробным, например 1.33(3) = 8 / 6.
Трехмерный график нам больше не нужен, поэтому для наглядности можно вернуться в 2 измерения и заменить обозначения y и z на обозначения x и y.
Чтобы найти целочисленные решения, можно сделать так.
Оба уравнения возведем в квадрат, точки пересечения с 0 от этого не изменятся. У первого уравнения график выше оси X. Второе уравнение возьмем со знаком минус, график ниже оси X.

График для P = 8 (точки пересечения: 1, 2, 4, 8):

Так вот. Число P является простым, если на промежутке [1, P] есть всего 2 решения — 1 и P.
При решении у меня получилась такая система:

Что в принципе и логично: x — целое число, P/x — другое целое число. Поэтому ничего особенного здесь нет, просто интересное наблюдение.
Выяснилось, что шансы на то, что за простым числом, оканчивающимся на 9, будет следовать число, оканчивающееся на 1, на 65% больше, чем шансы, что за ним будет следовать число, снова оканчивающееся на 9
Пропущено слово «простое»: «… что за простым числом, оканчивающимся на 9, будет следовать простое число...».
Понятно, что за числом, оканчивающимся на 9 будет следовать число, оканчивающееся на 0. Подразумевается последовательность простых чисел.
Как вы догадались, что подразумевается?
Я вижу только ложное утверждение.
Я вижу только ложное утверждение.
Написано "обнаружили ранее неизвестное свойство простых чисел". Рассматриваются только простые числа. А вот с чего вырешили, что рассматривается натуральный ряд не понятно.
Я ничего не говорил про натуральный ряд.
Второе предложение не слудует из первого. Здесь же математика обсуждается, а не поэзия или политика.
В оригинале статьи:
«Among the first billion prime numbers, for instance, a prime ending in 9 is almost 65 percent more likely to be followed by a prime ending in 1 than another prime ending in 9».
Написано «обнаружили ранее неизвестное свойство простых чисел». Рассматриваются только простые числа.
Второе предложение не слудует из первого. Здесь же математика обсуждается, а не поэзия или политика.
В оригинале статьи:
«Among the first billion prime numbers, for instance, a prime ending in 9 is almost 65 percent more likely to be followed by a prime ending in 1 than another prime ending in 9».
Существует феномен простых чисел-близнецов.
То есть: существуют пары простых чисел, разница между которыми равна двум. Возможно именно эти числа попадают в выборку "за простым числом заканчивающимся на 9 следует простое число, заканчивающееся на 1" и таким образом портят всю статистику.
То есть: существуют пары простых чисел, разница между которыми равна двум. Возможно именно эти числа попадают в выборку "за простым числом заканчивающимся на 9 следует простое число, заканчивающееся на 1" и таким образом портят всю статистику.
НЛО прилетело и опубликовало эту надпись здесь
По-моему, это отличный набор данных для марковской модели — есть 4 события A = 1, 3, 7 и 9. Следует найти Aij вероятности переходов. Ну, а затем проверять обученную модель на чебурашках.
В казино появиться огромный шанс получить прибыль с ничего не подозревающих людей изменив некоторые правила в нескольких играх, для одно игрока шанс не велик, даже для затяжной игры, но в большем масштабе это будет очень на руку владельцам казино…
Как вариант использования в быту…
Как вариант использования в быту…
Во-первых, как вы себе это представляете? Например?
Во-вторых, даже если бы реализуемо — казино это не выгодно. Проще второе зиро вернуть. Типа среди игроков нету людей, которые разбираются в математике и не пересчитают матожидание.
Во-вторых, даже если бы реализуемо — казино это не выгодно. Проще второе зиро вернуть. Типа среди игроков нету людей, которые разбираются в математике и не пересчитают матожидание.
А какие игры зависят от распределения последней цифры простых чисел?
В казино и так вероятности смещены (почти во всех играх) в пользу заведения.
А то, что среди простых чисел оканчивающихся на 3 и 7 больше, чем на 1 и 9, — это известный факт?
У него и объяснение есть простое.
На всякий случай проверил простые от 3 до 100 тыс. Статистика такая:
1: 2387
3: 2402
7: 2411
9: 2390
У него и объяснение есть простое.
На всякий случай проверил простые от 3 до 100 тыс. Статистика такая:
1: 2387
3: 2402
7: 2411
9: 2390
До 100 млн:
1: 1440298
3: 1440473
7: 1440495
9: 1440185
Распределение выглядит очень равномерным (но на X^2 не проверял).
1: 1440298
3: 1440473
7: 1440495
9: 1440185
Распределение выглядит очень равномерным (но на X^2 не проверял).
Ну да, ваши цифры, если вы им доверяете, тоже подтверждают это правило.
Непонятно, правда, чего вдруг 9-ка провалилась относительно 1. Их должно быть примерно одинаково.
Непонятно, правда, чего вдруг 9-ка провалилась относительно 1. Их должно быть примерно одинаково.
Ага, для HiddenMarkovModel готов вектор Bj = (0.25, 0.25, 0.25, 0.25). Now we are ready to check fraud of any consequence of numbers 1,3,7,9
Выяснилось, что шансы на то, что за простым числом, оканчивающимся на 9, будет следовать число, оканчивающееся на 1, на 65% больше, чем шансы, что за ним будет следовать число, снова оканчивающееся на 9.
А мне всегда казалось, что в десятичной системе шансы на то, что за простым числом, оканчивающимся на 9, будет следовать число, оканчивающееся на 1 или 9, всегда равны 0%, т.к. в 100% случаев следующее число будет оканчиваться на 0. /s
ну если уж начали подлавливать: а в какой системе исчисления это не так? Что это за система должна быть, чтобы у нее не было 0? ;-)
пфф, в римской например.
а в какой системе исчисления это не так?
в 16-ти ричной: следующее число после 9-ки = А
Если придерживаться общепринятых стандартов — во всех, кроме десятичной.
На самом деле, вполне можно говорить о свойствах чисел (p+1), где p — простое. Формулировка в посте неоднозначна — не очевидно, что речь о множестве простых чисел.
На самом деле, вполне можно говорить о свойствах чисел (p+1), где p — простое. Формулировка в посте неоднозначна — не очевидно, что речь о множестве простых чисел.
Если проанализировать числа в окрестности 2^40, получим карту переходов
25.0019: 19.8492 28.6524 28.5576 22.9407
25.0064: 24.5381 19.4783 27.4282 28.5554
24.9994: 25.3014 26.5211 19.5236 28.6539
24.9923: 30.3210 25.3753 24.4870 19.8167
Если же взять числа в окрестности 2^57, получится
25.0134: 21.0642 27.7100 27.5466 23.6792
25.0067: 24.9007 20.9652 26.6990 27.4351
24.9824: 25.2773 26.0573 20.9125 27.7530
24.9975: 28.8142 25.2948 24.7668 21.1242
Диапазон вероятностей переходов уменьшился с 10.8% до 7.9%. Возможно, рассматривая ещё более далёкие числа, можно ужаться и в 1%, и ещё меньше.
25.0019: 19.8492 28.6524 28.5576 22.9407
25.0064: 24.5381 19.4783 27.4282 28.5554
24.9994: 25.3014 26.5211 19.5236 28.6539
24.9923: 30.3210 25.3753 24.4870 19.8167
Если же взять числа в окрестности 2^57, получится
25.0134: 21.0642 27.7100 27.5466 23.6792
25.0067: 24.9007 20.9652 26.6990 27.4351
24.9824: 25.2773 26.0573 20.9125 27.7530
24.9975: 28.8142 25.2948 24.7668 21.1242
Диапазон вероятностей переходов уменьшился с 10.8% до 7.9%. Возможно, рассматривая ещё более далёкие числа, можно ужаться и в 1%, и ещё меньше.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Американские математики обнаружили ранее неизвестное свойство простых чисел