Комментарии 14
Код я писал в dbForge Studio, у этого IDE самый лучший форматировщик исходников (это единственный плюс этого IDE), но у меня он не настроен, поэтому форматирование выполнено в ручную
Функционал форматирования у них действительно классный, но то что не он настроен – это поправимо. Недавно разработчикам я уже выслал свои настройки, которые как они мне сказали «включат как дефолтные в следующем релизе». Позавчера они их на сайте выложили… Поэтому для нетерпеливых публикую ссылки: мой стиль форматирования, стиль форматирования «под SQL Prompt».
Относительно «единственного плюса» не согласен. У них хороший функционал есть для анализа плана выполнения (которым я пользуюсь попеременно с Plan Explorer), дата и схема компараторы. Но самое главное – IntelliSense, который взят от SQL Complete, которым я пользуюсь не один год. И возвращаться обратно на промпт банально нет желания...
Мне не везёт с "dbForge Studio" у меня он падает в случайные моменты времени. Версия для MS SQL сервера на порядок стабильней версии для ORACLE SQL, но тем не менее тоже падает. конечно не проблема обратно открыть 10 окошек, но вымораживает.
Два простых примера — простейший рефакторинг — переименовать переменную — переименовывает во всём документе, до и после DECLARE этой переменной, то есть переименовывает там где заведомо делать этого не надо, при этом если вызвать переименование не на DECLARE, а просто в коде то как раз про DECLARE dbForge забудет.
Второе — а) генерация тестового набора данных( описано в статье ) — не генерил значение внешнего ключа, пришлось руками доделывать, б) при наборе записей больше 16 000 скрипт вставки данных превращался в венегрет, который конечно можно было распутать, но желания нет, в) Если задать генерацию справочника ( 10 записей ) и данных ( 10 000 записей ), то генерил данных ровно столько же сколько записей в справочнике, вместо 10 000 записей в таблице данных, всего 10.
"dbForge Studio" несомненно отличный продукт, если знать где раскиданы грабли.
Единственное что в нём отлично работает это форматировщик, у которого очень гибкие настройки, но и его порой заставить работать без бубна не получается.
на мой вкус dbForge — сырой продукт. и спорить с вами о вкусах я не буду.
Два простых примера — простейший рефакторинг — переименовать переменную — переименовывает во всём документе, до и после DECLARE этой переменной, то есть переименовывает там где заведомо делать этого не надо, при этом если вызвать переименование не на DECLARE, а просто в коде то как раз про DECLARE dbForge забудет.
Второе — а) генерация тестового набора данных( описано в статье ) — не генерил значение внешнего ключа, пришлось руками доделывать, б) при наборе записей больше 16 000 скрипт вставки данных превращался в венегрет, который конечно можно было распутать, но желания нет, в) Если задать генерацию справочника ( 10 записей ) и данных ( 10 000 записей ), то генерил данных ровно столько же сколько записей в справочнике, вместо 10 000 записей в таблице данных, всего 10.
"dbForge Studio" несомненно отличный продукт, если знать где раскиданы грабли.
Единственное что в нём отлично работает это форматировщик, у которого очень гибкие настройки, но и его порой заставить работать без бубна не получается.
на мой вкус dbForge — сырой продукт. и спорить с вами о вкусах я не буду.
Просмотрел Ваши запросы. Не знаю уместно ли, но много лишнего кода. Например:
можно упростить до:
Также немного смутили комментарии:
Что временные таблицы, что табличные переменные — все хранится в tempdb. А то что будет оно в BufferPool или нет… это как повезет. Единственная гарантия (из известных мне), что данные в табличной переменной будут в памяти — использовать InMemory:
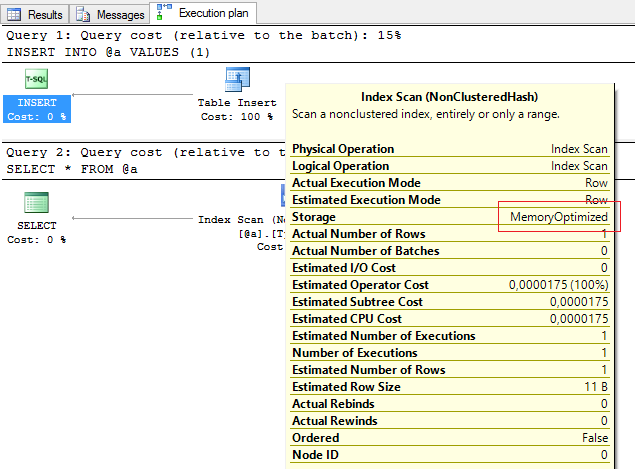
DECLARE @consumers_report_columns TABLE (column_id INT)
INSERT INTO @consumers_report_columns (column_id)
SELECT rc.column_id
FROM consumers_report_columns rc
WHERE rc.consumer_id = @ConsumerId
DECLARE consumers_report_columns_cursor CURSOR
FOR
SELECT rc.column_id
FROM @consumers_report_columns rcможно упростить до:
DECLARE consumers_report_columns_cursor CURSOR LOCAL READ_ONLY
FOR
SELECT column_id
FROM dbo.consumers_report_columns
WHERE consumer_id = @ConsumerIdТакже немного смутили комментарии:
--освобождаем оперативную память
DELETE @consumers_report_columnsЧто временные таблицы, что табличные переменные — все хранится в tempdb. А то что будет оно в BufferPool или нет… это как повезет. Единственная гарантия (из известных мне), что данные в табличной переменной будут в памяти — использовать InMemory:
USE test
GO
ALTER DATABASE test
ADD FILEGROUP test_mem CONTAINS MEMORY_OPTIMIZED_DATA
ALTER DATABASE test
ADD FILE (name='test_mem', filename='D:\test_mem') TO FILEGROUP test_mem
GO
CREATE TYPE dbo.ListInt AS TABLE (
ID INT NOT NULL,
INDEX Type_IX_ID HASH (ID) WITH (BUCKET_COUNT = 1000)
)
WITH (MEMORY_OPTIMIZED = ON)
GO
DECLARE @a dbo.ListInt
INSERT INTO @a VALUES (1)
SELECT * FROM @a
Не знаю уместно ли, но много лишнего кода
у меня в коде есть комментарий который поясняет этот момент — с правильным использование курсоров в T-SQL не было времени разбираться, это согласитесь не на пол часа занятие.
Получить набор данных и спокойно с ним работать, не парясь ни за какие нюансы — на мой вкус это хорошая практика.
Кто то пишет супер оптимизированный код, кто то пишет много элементарного атомарного кода — мне ближе второй подход, с точки сопровождения это более удобный вариант.
я привожу ссылку Временные таблицы на статью про временные таблицы и табличные переменные, там написано, что табличная переменная живёт только в оперативке, на stack overflow пишут, что дропнуть табличную переменную нельзя, потому что её на жёстком диске нет, это как бы намекает что табличные переменные в tempdb не пишутся.
Кто из вас прав выясняйте без меня.
Кто из вас прав выясняйте без меня.
Не знаю, почему Вы в негативном ключе воспринимаете мои слова. Выяснять кто прав не стоит… Вот написанная "на коленке" элементарная проверка:
SELECT COUNT(1) FROM tempdb.sys.tables
GO
DECLARE @t TABLE (i INT)
SELECT COUNT(1) FROM tempdb.sys.tables-----------
1
-----------
2про tempdb ок, пусть пишется. не в этом суть, суть моих возражений была в том что табличная переменная всегда использует оперативную память. вы с этим не согласились :
можно поиграться с кодом :
но этом нам даст только, то что "DELETE " это единственный способ удалить записи из табличной переменной.
из моего списка "литературы" идём по ссылке Temporary Tables
находим текст :
теперь курим MSDN
оказывается табличные переменные бывают двух типов:
Memory-optimized должны быть объявлены с использованием пользовательского типа, пример:
ок.
справедливость восстановлена?
Также немного смутили комментарии
можно поиграться с кодом :
-- Test registration in tempdb
SELECT COUNT(1) AS BEFOR FROM tempdb.sys.tables -- До объявления табличной переменной
GO
DECLARE @t1 TABLE (i INT)
SELECT COUNT(1) AS AFTER FROM tempdb.sys.tables -- После объявления табличной переменной
GO
SELECT COUNT(1) AS PAST FROM tempdb.sys.tables -- После блока кода с объявлением табличной переменной
-- Test Drop
SELECT COUNT(1) AS BEFOR FROM tempdb.sys.tables
GO
DECLARE @t2 TABLE (i INT)
SELECT COUNT(1) AS AFTER FROM tempdb.sys.tables
DROP TABLE @t2
GO
-- Test Trunc
SELECT COUNT(1) AS BEFOR FROM tempdb.sys.tables
GO
DECLARE @t3 TABLE (i INT)
SELECT COUNT(1) AS AFTER FROM tempdb.sys.tables
TRUNCATE TABLE @t3
GO
-- Test Delete
SELECT COUNT(1) AS BEFOR FROM tempdb.sys.tables
GO
DECLARE @t4 TABLE (i INT)
SELECT COUNT(1) AS AFTER FROM tempdb.sys.tables
DELETE @t4
GOно этом нам даст только, то что "DELETE " это единственный способ удалить записи из табличной переменной.
из моего списка "литературы" идём по ссылке Temporary Tables
находим текст :
If you are using SQL Server 2000 or higher, you can take advantage of the new TABLE variable type. These are similar to temporary tables except with more flexibility and they always stay in memory.
теперь курим MSDN
Like memory-optimized tables, memory-optimized table variables,
- Must fit in memory and do not use disk resources.
Disk-based table variables exist in tempdb. Memory-optimized table variables exist in the user database (but they do not consume storage and are not recovered).
You cannot create a memory-optimized table variable using in-line syntax. Unlike disk-based table variables, you must create a type first.
оказывается табличные переменные бывают двух типов:
- Disk-based
- Memory-optimized
Memory-optimized должны быть объявлены с использованием пользовательского типа, пример:
CREATE TYPE [Sales].[SalesOrderDetailType_inmem] AS TABLE(
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
INDEX [IX_ProductID] HASH ([ProductID]) WITH ( BUCKET_COUNT = 8),
INDEX [IX_SpecialOfferID] NONCLUSTERED
)
WITH ( MEMORY_OPTIMIZED = ON )- должен быть минимум один индекс
- обязательно "MEMORY_OPTIMIZED = ON"
ок.
справедливость восстановлена?
справедливость восстановлена?
Нет.… и все потому, что Вы раскидываетесь понятиями не до конца понимая как все работает.
Временная таблица и табличная переменная используют базу tempdb (обсуждаем общий случай). Вот пруф, что данные туда действительно попадают:
DECLARE @t TABLE(i INT)
INSERT INTO @t
VALUES (1), (2)
SELECT sys.fn_PhysLocFormatter(%%physloc%%)
FROM @tДалее происходит чтение страниц в BufferPool:
SELECT *
FROM sys.dm_os_buffer_descriptors
WHERE database_id = DB_ID('tempdb')
И уже потом когда страницы в буфер-пуле SQL Server ними может оперировать… И как быть если размер моей таблицы больше, чем размер свободного места в BufferPool? Как он сможет хранить такой объект в памяти? Делать пример, имитировать недостаток памяти и нагрузку… и что-то доказывать я желания не имею.
И еще… используя термины "память" Вы упускаете из виду другие другие особенности табличных переменных. Отсутствие статистики. Неверную оценку кардинальности. Необходимость делать рекомпиляцию. Еще можно вспомнить про транзакции и прочие приколы.
Не верите мне. Почитайте, что говорит Martin Smith в этом случае.
я ни чего не упускаю, вы пишите :
я пишу в статье:
MSDN пишет:
что я упустил? у меня что количество колонок, что количество разделов в пределах десятка, мне надо тупо перебрать записи как элементы массива, зачем мне индексы? в чём я не прав?
В том что вы игнорируете описанные нюансы и настаиваете на единственно верном решении?
в нашем с вами обсуждении табличных переменных мы выяснили, что они бывают двух разных видов:
Теперь почитаем, что
в своём коменте пишет:
мой перевод «оптимизированные для памяти сильно отличаются от тех которые обсуждаются ниже, подробности по ссылке»,
перейдём по ссылку, и увидим:
Мой перевод: «Эти переменных истинно в памяти, они гарантировано ни когда не скидываются на диск»
поэтому касательно моей комента к коду, за который вы меня мурыжите:
```sql
/* очищаем табличную переменную — освобождаем оперативную память */
```
можно сказать следующее:
а теперь вернёмся к:
Который касается вашей адекватности, я о себе пишу:
Но вы из контекста статьи вырываете отдельные части и относитесь к моим словам как к изречению гуру по T-SQL.
А потом понеслось «в Интернете кто то не прав» :))
Надо оно вам?
Отсутствие статистикии т.п.
я пишу в статье:
Временная таблица может быть записана на диск и проиндексирована, временная таблица существует даже после завершения выполнения блока кода.
Табличная переменная существует только в оперативной памяти и только внутри блока кода и не может быть проиндексирована.
MSDN пишет:
Table variables does not have distribution statistics, theywill not trigger recompiles. Therefore, in many cases, the optimizer will build a query plan on the assumption that the table variable has no rows. For this reason, you should be cautious about using a table variable if you expect a larger number of rows (greater than 100).
что я упустил? у меня что количество колонок, что количество разделов в пределах десятка, мне надо тупо перебрать записи как элементы массива, зачем мне индексы? в чём я не прав?
В том что вы игнорируете описанные нюансы и настаиваете на единственно верном решении?
в нашем с вами обсуждении табличных переменных мы выяснили, что они бывают двух разных видов:
- Disk-based
- Memory-optimized
Теперь почитаем, что
Martin Smith
в своём коменте пишет:
Caveat
This answer discusses «classic» table variables introduced in SQL Server 2000. SQL Server 2014 in memory OLTP introduces Memory-Optimized Table Types. Table variable instances of those are different in many respects to the ones discuss
мой перевод «оптимизированные для памяти сильно отличаются от тех которые обсуждаются ниже, подробности по ссылке»,
перейдём по ссылку, и увидим:
The use of memory-optimized table variables has a number of advantages over traditional table variables:
- The variables are truly in memory: they are guaranteed to never spill to disk
Мой перевод: «Эти переменных истинно в памяти, они гарантировано ни когда не скидываются на диск»
поэтому касательно моей комента к коду, за который вы меня мурыжите:
```sql
/* очищаем табличную переменную — освобождаем оперативную память */
```
можно сказать следующее:
- если табличная переменная объявлена с типом имеющим «MEMORY_OPTIMIZED = ON» ( Memory-optimized ), то всё верно
- если это old school table variable — Disk-based, то комментарий вводит в заблуждение
а теперь вернёмся к:
Не знаю, почему Вы в негативном ключе воспринимаете мои слова
Который касается вашей адекватности, я о себе пишу:
мой первый опыт «серьезной» работы с T-SQL
Но вы из контекста статьи вырываете отдельные части и относитесь к моим словам как к изречению гуру по T-SQL.
А потом понеслось «в Интернете кто то не прав» :))
Надо оно вам?
Уважаемый, я не гуру и никогда этого о себе не говорил. Заявляете, что если в табличную переменную записать 4Гб данных при 2Гб ОЗУ на машине и все будет в памяти — это Ваше право. Относительно адекватности, лично я Вас не провоцировал. И Вы правы мне оно не надо — тратить свое рабочее время, чтобы доказать Вам что-то...
Код я писал в dbForge Studio, у этого IDE самый лучший форматировщик исходников ( это единственный плюс этого IDE ), но у меня он не настроен, поэтому форматирование выполнено в ручную, и только там где я про него помнил.
Единственный плюс!? Хотите подкину еще парочку?
Русскоязычная редакция dbForge Studio for SQL Server Professional абсолютно бесплатна, а это значит, что Вы можете пользоваться абсолютно всеми фичами при решении своих задач: генерировать тестовые данные (сотни тысяч записей в десятки таблиц) в два клика, сравнивать схемы баз и данные на различных инстансах, профилировать запросы (сравнивать планы выполнения), дебажить процедуры, версионировать базу при помощи популярных систем контроля версий, быстро анализировать состояние индексов и выполнять дефрагментацию при необходимости, экспортировать и импортировать данные в различных форматах, создавать бекапы и ресторить их (этот процесс можно автоматизировать/настроить по расписанию).
Поскольку статья об отчетах, имеется там и встроенный SQL Server Report Builder, который позволяет очень быстро и удобно настроить генерацию отчетов по данным.
Ну, и как уже написали выше, встроенный Intellisense — очень крут! Форматирование работает из коробки. Если не устраивает дефолтное форматирование — есть куча предустановленных профилей на выбор, или можно создать свой. В общем, плюсов гораздо больше, чем 1-н :)
В Report Builder когда то искал возможность добавить параметры в отчет. Не знаете такой функционал там есть вообще?
по поводу бесплатности это как бы не аргумент, суровая российская реальность с вами не согласиться. Одна половина фишек из джентельменского набора, другой половиной я не пользуюсь. По поводу стабильности читайте мой комент
Не знаю какой хороший инструментарий для MS SQL, а для Oracle я пользуюсь PL/SQL Developer и TOAD, мне хватает, dbForge — только как форматировщик.
ЗЫ
ссылку на dbForge я даю в своём списке ссылок, вы до этого места видимо не дочитали?
Не знаю какой хороший инструментарий для MS SQL, а для Oracle я пользуюсь PL/SQL Developer и TOAD, мне хватает, dbForge — только как форматировщик.
ЗЫ
ссылку на dbForge я даю в своём списке ссылок, вы до этого места видимо не дочитали?
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Движок для построения отчётов на SQL. Черновик решения