Комментарии 5
Я тоже на одном проекте такую штуку реализовывал. Но коллеги потом сказали, что это не по богу и не надо так. В общем-то я по итогу с ними согласился. Ведь может что первый раз тест упал потому-что словил какой-то баг, а второй раз не словил. Мы тест помечаем как прошедший, а по факту от нас спрятался баг.
согласен, идея тоже правильная. наверное, применять данный функционал стоит с оговорками и пониманием. например, у нас на проекте задействовано большое кол-во api и собственных прослоек, что в сумме значительно повышает кол-во возможных точек отказа.
потому на текущем этапе я предпочитаю их переопросить, вдруг они передумали и решили работать)
но с вами согласен, палка двух концов.
потому на текущем этапе я предпочитаю их переопросить, вдруг они передумали и решили работать)
но с вами согласен, палка двух концов.
Касательно масштабирования тестов — идея то замечательная. Но если у вас на этой почве начали падать больше половины тестов, сдается мне, что проблему надо искать на уровне конфигурации / архитектуры вашего фреймворка, а не городить workarounds в виде IRetryAnalyzer.
К слову, сама фича — весьма сомнительна. Соглашусь с комментарием snowrain по поводу сокрытия реальных проблем. Многие ошибочно считают, что конечная цель автоматизации — зеленый репорт. Но вот только к кому потом прибежит менеджмент, когда рандомный баг, сокрытый сей чудесной фичей, всплывет на продакшене?
Помимо всего прочего, представьте ситуацию, когда, к примеру, билд вообще лежит, а тесты запустились ночью по расписанию. В итоге, благодаря IRetryAnalyzer вы будете ломиться в мертвое окружение x3 раз (исходя из ваших ограничений).
Насчет репортинга тоже усложнили. Как вы думаете, что проще — добавить нужные фичи в существующее решение, или с нуля написать свое? Рекомендую посмотреть в сторону Allure, ExtentReports, ну или на худой конец — ReportNG. При желании и наличии определенных навыков программирования, любой из них можно адаптировать под ваши нужды. Но показывать стейкхолдерам гусей и прочих животных на пол экрана — нонсенс.
К слову, сама фича — весьма сомнительна. Соглашусь с комментарием snowrain по поводу сокрытия реальных проблем. Многие ошибочно считают, что конечная цель автоматизации — зеленый репорт. Но вот только к кому потом прибежит менеджмент, когда рандомный баг, сокрытый сей чудесной фичей, всплывет на продакшене?
Помимо всего прочего, представьте ситуацию, когда, к примеру, билд вообще лежит, а тесты запустились ночью по расписанию. В итоге, благодаря IRetryAnalyzer вы будете ломиться в мертвое окружение x3 раз (исходя из ваших ограничений).
Насчет репортинга тоже усложнили. Как вы думаете, что проще — добавить нужные фичи в существующее решение, или с нуля написать свое? Рекомендую посмотреть в сторону Allure, ExtentReports, ну или на худой конец — ReportNG. При желании и наличии определенных навыков программирования, любой из них можно адаптировать под ваши нужды. Но показывать стейкхолдерам гусей и прочих животных на пол экрана — нонсенс.
Спасибо за совет, действительно дельный. Следующим шагом выберу и прикручу какой-то из предложенных плагинов по репортингу.
Заюзать их действительно будет красивее и, надеюсь, проще.
Относительно гусей — вы же понимаете, что это не боевой отчет и на их месте можно установить лого проекта) Или убрать полностью, картинка только для примера.
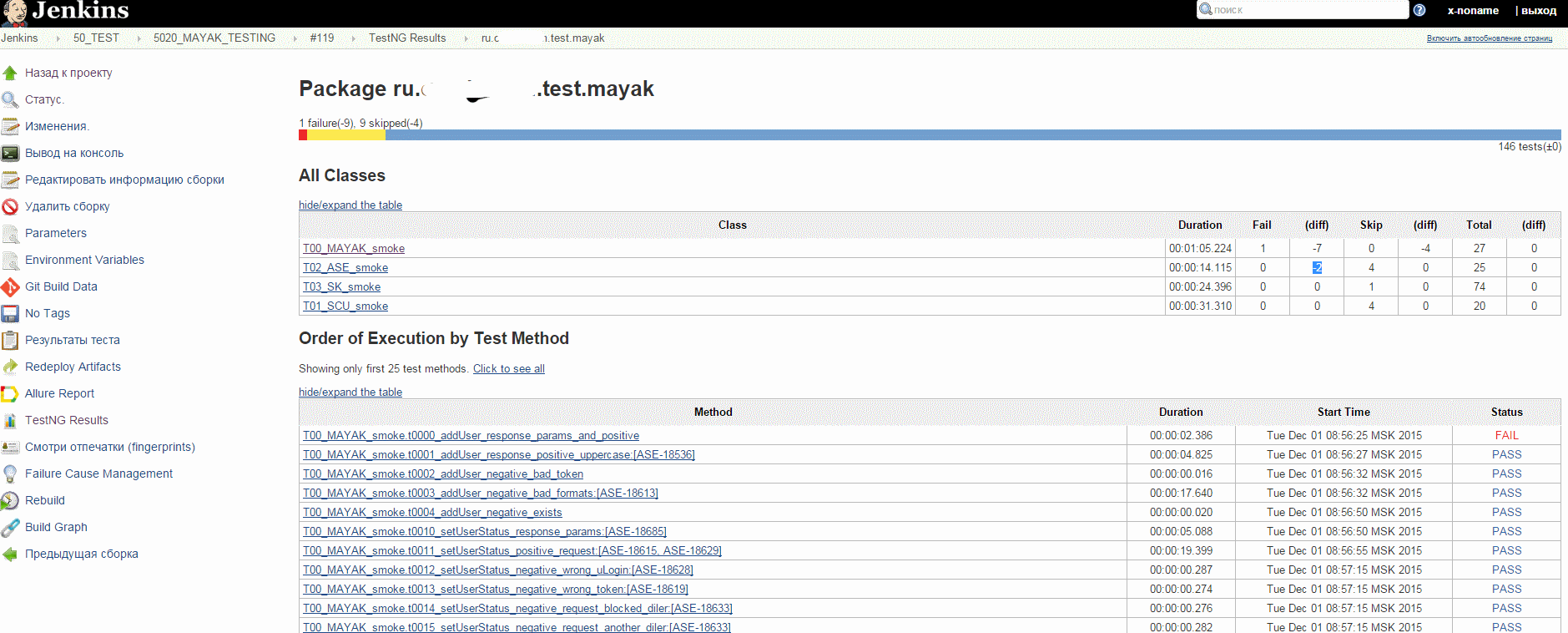
По поводу доработок конфигурации/архитектуры: действительно, если бы стало падать более половины тестов — это было бы правильным решением. В моем случае тестов стало валиться в 2 раза больше, но не больше половины. Т.е. из ситуации 300 (285/15) я попал в ситуацию 300 (270/30).
А что касается сокрытия реальных проблем — уже писал выше, применять стоит с оговорками. Моя цель — не зеленый репорт. И применение данного функционала на моем проекте оправдано, на другом — может быть не допустимо. Все зависит от того, сколько компонентов входит в ваш тестовый фреймворк. В нашем случае UI-тесты — не единственный барьер, который защищает прод от багов.
Заюзать их действительно будет красивее и, надеюсь, проще.
Относительно гусей — вы же понимаете, что это не боевой отчет и на их месте можно установить лого проекта) Или убрать полностью, картинка только для примера.
По поводу доработок конфигурации/архитектуры: действительно, если бы стало падать более половины тестов — это было бы правильным решением. В моем случае тестов стало валиться в 2 раза больше, но не больше половины. Т.е. из ситуации 300 (285/15) я попал в ситуацию 300 (270/30).
А что касается сокрытия реальных проблем — уже писал выше, применять стоит с оговорками. Моя цель — не зеленый репорт. И применение данного функционала на моем проекте оправдано, на другом — может быть не допустимо. Все зависит от того, сколько компонентов входит в ваш тестовый фреймворк. В нашем случае UI-тесты — не единственный барьер, который защищает прод от багов.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Реализация автоматического перезапуска failed-тестов в текущей сборке и преодоление сопутствующих бед