
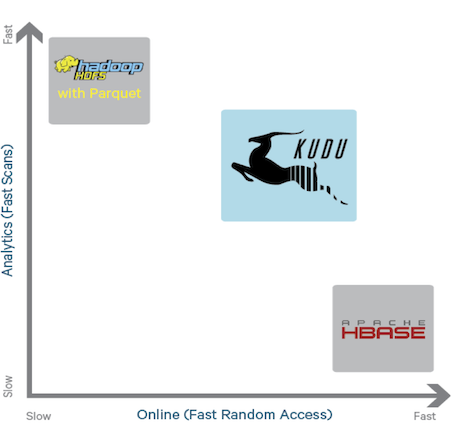
Kudu был одной из новинок, представленых компанией Cloudera на конференции “Strata + Hadoop World 2015”. Это новый движок хранения больших данных, созданный чтобы покрыть нишу между двумя уже существующими движками: распределенной файловой системой HDFS и колоночной базой данных Hbase.
Существующие на данный момент движки не лишены недостатков. HDFS, прекрасно справляющаяся с операциями сканирования больших объемов данных, показывает плохие результаты на операциях поиска. C Hbase все с точностью до наоборот. К тому же HDFS обладает дополнительным ограничением, а именно, не позволяет модифицировать уже записанные данные. Новый движок, согласно разработчикам, обладает преимуществами обеих существующих систем:
— операции поиска с быстрым откликом
— возможность модификации
— высокая производительность при сканировании больших объемов данных
Некоторыми вариантами использования Kudu могут быть анализ временных рядов, анализ логов и сенсорных данных. В настоящее время системы, которые используют Hadoop для подобных вещей, имеют довольно сложную архитектуру. Как правило, данные находятся в нескольких хранилищах одновременно (так называемая “Лямбда-архитектура”). Необходимо решать ряд задач по синхронизации данных между хранилищами (неизбежно возникает лаг с которым, как правило, просто смиряются и живут). Так же приходится настраивать политики безопасности доступа к данным для каждого хранилища отдельно. Да и правило “чем проще – тем надежней” никто не отменял. Используя Kudu вместо нескольких одновременных хранилищ можно значительно упростить архитектуру подобных систем.
Характеристики Kudu:
— Высокая производительность при операциях сканирования больших объемов данных
— Быстрое время отклика в операциях поиска
— Колоночная БД, тип СP в теореме CAP, поддерживает несколько уровней согласованности данных
— Поддержка “update”
— Транзакции на уровне записей
— Отказоустойчивость
— Настраиваемый уровень избыточности данных (для сохранности данных при отказе одной из нод)
— API для C++, Java и Python. Поддерживается доступ из Impala, Map/Reduce, Spark.
— Открытый исходный код. Apache License
НЕКОТОРЫЕ СВЕДЕНИЯ ОБ АРХИТЕКТУРЕ
Кластер Kudu cостоит из двух типов сервисов: master – сервис ответственный за управление метаданными и координацию между нодами; tablet – сервис, установленный на каждой ноде предназначенной для хранения данных. В кластере может быть только один активный master. В целях отказоустойчивости могут быть запущены еще несколько master-сервисов в режиме standby. Tablet – сервера разбивают данные на логические разделы (называемые “tablets”).

C точки зрения пользователя данные в Кudu хранятся в таблицах. Для каждой таблицы необходимо определить структуру (довольно нетипичный подход для NoSQL баз данных). Кроме столбцов и их типов пользователь должен определить первичный ключ и политику разбиения на разделы.
В отличии от других компонентов экосистемы Hadoop Кudu не использует HDFS для хранения данных. Используется файловая система ОС (рекомендуется использовать ext4 или XFS). Для того, чтобы гарантировать сохранность данных при отказе одтельных нод, Кudu реплицирует данные между серверами. Как правило каждый tablet хранится на трех серверах (однако только один из трех серверов принимает операции на запись, остальные принимают операции только на чтение). Синхронизация между репликами tablet-a реализована по протоколу raft.
ПЕРВЫЕ ШАГИ
Попробуем поработать с Kudu с точки зрения пользователя. Создадим таблицу и попытаемся обратиться к ней при помощи SQL и Java API.
Для заполнения таблицы данными используем этот открытый датасет:
https://raw.githubusercontent.com/datacharmer/test_db/master/load_employees.dump
В настоящий момент у Kudu нет своей клиентской консоли. Для создания таблицы будем использовать консоль Impala (impala-shell).
Прежде всего создадим таблицу “employees” с хранением данных в HDFS:
CREATE TABLE employees (
emp_no INT,
birth_date STRING,
first_name STRING,
last_name STRING,
gender STRING,
hire_date STRING
);
Загружаем датасет на машину с клиентом impala-shell и импортируем данные в таблицу:
impala-shell -f load_employees.dump
После того, как команда завершит выполнение, запустим impala-shell cнова и выполним следующий запрос:
create TABLE employees_kudu
TBLPROPERTIES(
'storage_handler' = 'com.cloudera.kudu.hive.KuduStorageHandler',
'kudu.table_name' = 'employees_kudu',
'kudu.master_addresses' = '127.0.0.1',
'kudu.key_columns' = 'emp_no'
) AS SELECT * FROM employees;
Данный запрос создаст таблицу с аналогичными полями, но уже с Kudu в качестве хранилища. При помощи “AS SELECT” в последней строчке копируем данные из HDFS в Kudu.
Не выходя из impala-shell запустим несколько SQL-запросов к только что созданной таблице:
[vm.local:21000] > select gender, count(gender) as amount from employees_kudu group by gender;
+--------+--------+
| gender | amount |
+--------+--------+
| M | 179973 |
| F | 120051 |
+--------+--------+
Можно составлять запросы к обоим хранилиам (Kudu и HDFS) одновременно:
[vm.local:21000] > select employees_kudu.* from employees_kudu inner join employees on employees.emp_no=employees_kudu.emp_no limit 2;
+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
+--------+------------+------------+-----------+--------+------------+
Теперь попробуем воспроизвести результаты первого запроса (подсчет сотрудников мужского и женского пола) используя Java API. Вот код:
import org.kududb.ColumnSchema;
import org.kududb.Schema;
import org.kududb.Type;
import org.kududb.client.*;
import java.util.ArrayList;
import java.util.List;
public class KuduApiTest {
public static void main(String[] args) {
String tableName = "employees_kudu";
Integer male = 0;
Integer female = 0;
KuduClient client = new KuduClient.KuduClientBuilder("localhost").build();
try {
KuduTable table = client.openTable(tableName);
List<String> projectColumns = new ArrayList<>(1);
projectColumns.add("gender");
KuduScanner scanner = client.newScannerBuilder(table)
.setProjectedColumnNames(projectColumns)
.build();
while (scanner.hasMoreRows()) {
RowResultIterator results = scanner.nextRows();
while (results.hasNext()) {
RowResult result = results.next();
if (result.getString(0).equals("M")) { male += 1; }
if (result.getString(0).equals("F")) { female += 1; }
}
}
System.out.println("Male: " + male);
System.out.println("Female: " + female);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
client.shutdown();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
После компиляции и запуска получаем следующий результат:
java -jar kudu-api-test-1.0.jar
[New I/O worker #1] INFO org.kududb.client.AsyncKuduClient - Discovered tablet Kudu Master for table Kudu Master with partition ["", "")
[New I/O worker #1] INFO org.kududb.client.AsyncKuduClient - Discovered tablet f98e05a4bbbe49528f38b5a46ef3a7a4 for table employees_kudu with partition ["", "")
Male: 179973
Female: 120051
Как видно результат совпадает с тем, что выдал SQL-запрос.
ЗАКЛЮЧЕНИЕ
Для систем больших данных, в которых должны выполняться как аналитические операции на всем объеме хранимых данных, так и операции поиска c быстрым временем отклика, Kudu представляется естественным кандидатом в качестве движка хранения данных. Благодаря своим многочисленным API он хорошо интегрирован в экосистему Hadoop. В заключении следует сказать, что в данный момент Kudu находится в стадии активной разработки и не готов для использования в продакшн.







