В предыдущей публикации я описывал список продуктов и их настройки, которые необходимы для работы нашей организации.
В этой статье я постараюсь описать, как мы это всё используем в ежедневной работе всего коллектива разработки.
На протяжении 4-х лет у нас выработался следующий формат команды разработки:
В итоге команда размером около 10-11 человек. Таких команд (ячеек) у нас несколько.
Работа в основном в стиле стартапа, когда нет конкретной и подробной постановки. Очень часто эксперименты вроде “а давайте попробуем так, посмотрим что получится” или “вы классно все сделали, но теперь надо все совсем по-другому”.
За эти годы концепцию нашей работы можно описать одной фразой — это “стремительная смена концепции”.
Понятное дело, что применить в таких условиях различные методологии никак не удавалось.
Начинал в этой системе я как программист, потом Team lead, ну а теперь PM (DM). Т.е. руковожу, полностью участвую в проектировании и иногда даже пописываю. Во времена моего программирования у меня был замечательный ПМ (выходец из тестировщиков), которая поддерживала все мои идеи по автоматизации workflow. Даже более того, концептуально этот процесс придуман ей, а я уже смог его технически реализовать и в некоторых местах усовершенствовать.
Как мы работали ранее с использованием только Jira и SVN:
После сложного пути проб и ошибок, спустя 3 года мы пришли к следующему процессу.

Все задачи появляются у нас либо после совещания с высшим руководством, либо пожелания от заказчика, либо придумываем что-то сами (или находим баги).
В случаях, когда задача не односложная, собирается мини-совещание из ПМ, тимлида, QA-лида и аналитика. После обсуждения и придумывания, что и как будем разрабатывать, обычно сразу дробим это на логически завершенные небольшие задачки (не дольше работы 1-го дня программиста) и грубо прикидываем сроки на реализацию (для планов для высшего руководства).
Аналитик садится и вдумчиво излагает постановку в Confluence. После этого данную постановку согласовывает с ПМ, а тот при необходимости с высшим руководством.
Затем на основании этой постановки создается задача в Jira.
Часто задачи сразу появляются в Jira минуя этап с Confluence.
Любая задача, которая появляется в Jira сразу попадает на шаг “Постановка задачи”. На данном этапе заполняются такие данные как:
На этапе постановки задача находится у ее автора и на нее больше никто не смотрит и о ней не знает.
Как только автор окончательно формулирует постановку задачи, он ее толкает на следующий (единственно возможный) шаг в workflow — ревизия постановки.
При переходе на этот шаг триггеры Jira автоматом меняют ответственного задачи на ПМ-а.
Этот шаг предназначен для того, чтобы ПМ перечитал описание задачи и убедился, что автор правильно понял постановку и корректно описал задание для программиста. Очень часто из-за недостаточного взаимопонимания задача делается и тестируется до самого конца и только уже при релизе видно, что сделали совсем не то, что изначально требовалось.
Также на этом шаге ПМ принимает решение нужно ли реализовывать вообще данную задачу. Или нужно ли ее реализовывать именно в эту версию.
На этом этапе есть два варианта workflow: вернуть назад на постановку (доработку описания) или продвинуть дальше в работу.
Также я часто на этом шаге назначаю ответственного тимлида для того, чтобы он сам определил исполнителя

При выборе этого шага я настроил экран, в котором надо задавать исполнителя, поле “Программист” и планируемое время.
Этот шаг — пул задач программиста, который надо выполнить за версию в порядке, указанном в поле приоритет или в порядке любом удобном, если приоритет одинаковый.
Так уж получается, что во время работы над версией частенько этот список пополняется.
Нажимая на кнопку “В работу”, задача переходит в состояние “В работе” и благодаря плагину “Automated Log Work for JIRA” автоматически запускается счетчик логирования времени, который останавливается и сохраняет набежавшее значение при переводе задачи в другие статусы. На этом шаге программист может:
Чтобы работала связка FishEye+Crucible+Bitbucket+Jira, при комите программист обязательно в комменте должен указать номер задачи (PRJ-343).
У нас в команде договоренность, что мелкие правки типа подвинуть кнопку правее или раскрасить зелёный зеленее, можно сразу бросать на сборку. Иначе — ОБЯЗАТЕЛЬНО на ревизию кода.
Итак, бросаем задачу на ревизию кода, и при этом ответственным назначаем тимлида.
На этом шаге тимлид в специальной секции Development в Jira смотрит какой именно комит был сделан программистом и нажимает специальную кнопку “Code Review”.

После нажатия автоматически открывается Crucible и создается ревью на указанный комит (или несколько комитов).
Тимлид может видеть дерево файлов, которые правил программист ну и соответственно диференсы. Может оставить комментарий к любой строке кода или общий к ревизии. Crucible позволяет даже указать степень критичности проезда программиста.
После мук изучения чужого гуанокода, тимлид либо проталкивает задачу на шаг сборки, либо возвращает программисту в ожидание работ.
Программист в этом случае в секции Development видит Code Review и его статус. При переходе на этот Code Review опять же открывается Crucible, где программист может наглядно увидеть, где именно он налажал.
При переводе на шаг “Ожидание сборки”, тимлид выбирает ответственным тестировщика, который указан в спец поле, либо если оно не заполнено, то QA-лида.
Так как сервер тестирования у нас один общий, то сборка по расписанию не годится. Нельзя подменять сайт во время его тестирования.
Поэтому обычно у нас тестировщики договариваются и, если никто не против, собирают себе свежую версию ресурса.
Делают они это с помощью Jenkins. В нем созданы по три сборки на каждый проект: сборка для тестов, сборка для разработки, сборка БД.
В сборке исходников настроен следующий алгоритм:
В сборках БД все тоже самое, только вместо шага 3 выполняется следующее с помощью ssh команд на сервере:
3.1. Отрубить все коннекты к БД.
3.2. Удалить БД.
3.3. Восстановить БД прошлой версии.
3.4. Прокрутить на ней все скрипты новой версии.
БД у нас собирают крайне редко, только когда тестировщик видит в измененных файлах sql скрипты.
На этом шаге могут быть задачи, которые уже были в тесте, а могут быть и в первый раз. Если задача уже в тесте была, то тимлид уже ответственным ставит именно того тестировщика, который вернул задачу в работу.
Иначе все задачи скапливаются у QA-лида. Он смотрит на пул задач и нагрузку каждого тестировщика, и определяет кому назначить задачу на тест. Более того, сразу же определяет и тестировщика для парного тестирования.
С данного шага, задачу можно перевести практически на любой шаг workflow. Тестировщик может:
Так же как и с шагом “В работе”, на этом шаге автоматически запускается счетчик времени, который логирует затраченное на работу время.
Этот шаг был придуман по нескольким причинам. Многие не понимали его целесообразности, но в итоге спустя какие-то время соглашались, что он необходим.
Суть его заключается в том, что есть основной тестировщик по задаче, который очень глубоко и усиленно ковыряет задачу со всевозможных аспектов и есть парный тестировщик, который поверхностно просматривает задачу только после полностью завершенных тестов первого. Это очень похоже на ревизию кода у программистов.
В итоге получаем то, что не только один тестировщик знает как устроена та или иная функциональность. Если задача футболялась 10 раз между программистом и тестировщиком, то свежий взгляд парного тестировщика может заметить что-то пропущенное. Ну и самое важное, то что каждый тестировщик работает по-своему и привыкает использовать софт определенным образом (логинится не используя мышь, аплоадить файлы драг-н-дропом, вместо фильтров использовать сортировки, при вводе данных копипастить тексты и т.д.). Очень часто бывает, что одни и те же функции можно использовать по-разному, и парный тестировщик натыкается на ошибки, которые были проверены основным, но немного по-своему.
Если на этом шаге обычно уже можно считать, что задача почти закончена. И очень часто, когда поторапливают с выпуском версии, его можно пройти формально.
После успешно проведенных тестирований уже окончательно определена функциональность и ее реализация. И вот теперь этой задачей занимается техпис. Обычно все задачи, кроме совсем незначительных или тех, которые сами сломали в процессе работы над версией, мы помечаем меткой “ReadMe”.
Парный тестировщик, если видит эту метку отправляет задачу на шаг “ReadMe” и назначает на техписа.
Техпис в специальном поле описывает очень кратко Release notes по этой задаче. Обычно это оповещение пользователя об изменении функциональности или исправлении ошибки, или о появлении новой функциональности и как ей пользоваться.
На этом же шаге техпис исправляет или дополняет справку ресурса в Confluence.
После проделанной работы, задача отправляется на финальный шаг “Ревизия функциональности”.
При переходе задачи на этот шаг, триггеры Jira автоматом назначают ответственным ПМ-а.
На этом шаге ПМ проверяет работу всей команды в целом. Было ли реализовано то что хотели, именно так как хотели, нормальное ли описание в ReadMe и т.д.
Бывает, что на этом шаге оказывалось, что программист с тестировщиком что-то между собой порешали и отрезали “ненужную функциональность” или изменили ее потому что посчитали так лучше, и именно эта функциональность требовалась высшим руководством и именно в таком виде. Тогда задача опять идет на “Ожидание работ”.
Ценность данного шага заключается в том, что хороший ПМ или ДМ после выпуска и звонка заказчика с фразой “что вы наделали?”, должен знать как именно реализовали задачу, как назвали кнопки, тексты сообщений, нюансы алгоритмов и смело ответить “сам дурак”. А не мяться и гадать, а как же они сделали ту форму и чего в ней кнопка задизейблена…
Ну тут все и так понятно. Задача закрывается после удачно прошедшей ревизии функциональности.
Или задача в любой момент может оказаться никому не нужной, потому переход на этот шаг возможен с любого другого шага.
Для удобства в Jira были разработаны рабочие столы для каждого проекта с четырьмя гаджетами:
Еще с помощью GreenHopper я настроил такую доску:

Очень удобна для обзора всего процесса целиком.
При выпуске версии, мы выгружаем из Jira все задачи версии в виде двух колонок: компонент и поле ReadMe. Вот и получается у нас ReadMe сгруппированное по разделам.
С помощью “Scroll HTML Exporter” мы экспортируем страницу хелпа в Confluence и все ее дочерние страницы в набор html файлов, которые внутри выглядят так же красиво как в Confluence и ссылаются друг на друга.
Вот по такому workflow мы уже работаем несколько лет, иногда его дорабатывая и дотачивая.
Но в целом он очень удобен.
Для ПМ тем, что в любой момент времени видно, кто именно и на каком шаге держит задачу.
Для разработчиков удобно видеть только свой объем работ.
Ну и, конечно же, автоматизация на всех шагах. Т.е. нет такого человека, без которого рабочий процесс может остановиться.
В этой статье я постараюсь описать, как мы это всё используем в ежедневной работе всего коллектива разработки.
На протяжении 4-х лет у нас выработался следующий формат команды разработки:
- 1 Project Manager, он же Product Manager, он же Delivery Manager.
- 4-5 программистов
- 1 Team lead
- 3-4 QA
- 1 Аналитик
- 1 Техпис (иногда он же и аналитик в одном лице).
В итоге команда размером около 10-11 человек. Таких команд (ячеек) у нас несколько.
Работа в основном в стиле стартапа, когда нет конкретной и подробной постановки. Очень часто эксперименты вроде “а давайте попробуем так, посмотрим что получится” или “вы классно все сделали, но теперь надо все совсем по-другому”.
За эти годы концепцию нашей работы можно описать одной фразой — это “стремительная смена концепции”.
Понятное дело, что применить в таких условиях различные методологии никак не удавалось.
Начинал в этой системе я как программист, потом Team lead, ну а теперь PM (DM). Т.е. руковожу, полностью участвую в проектировании и иногда даже пописываю. Во времена моего программирования у меня был замечательный ПМ (выходец из тестировщиков), которая поддерживала все мои идеи по автоматизации workflow. Даже более того, концептуально этот процесс придуман ей, а я уже смог его технически реализовать и в некоторых местах усовершенствовать.
Перейдем к сути.
Как мы работали ранее с использованием только Jira и SVN:
- На словах получили задание от заказчика или высокого руководства.
- ПМ создал конкретную задачу в JIRA.
- Программист выполнил, залил в SVN и протолкнул в JIRA на тест.
- Тестировщик попросил лида собрать билд.
- Качнул новый билд и давай тестить задачи.
- Плохие опять на пункт 3, хорошие — в «Закрыто».
- В конце версии техпис описывал все, что получилось.
- Лид собрал все в кучу и приготовил инсталлятор.
- ПМ спаковал и передал заказчику.
После сложного пути проб и ошибок, спустя 3 года мы пришли к следующему процессу.
Постановка задачи
Все задачи появляются у нас либо после совещания с высшим руководством, либо пожелания от заказчика, либо придумываем что-то сами (или находим баги).
В случаях, когда задача не односложная, собирается мини-совещание из ПМ, тимлида, QA-лида и аналитика. После обсуждения и придумывания, что и как будем разрабатывать, обычно сразу дробим это на логически завершенные небольшие задачки (не дольше работы 1-го дня программиста) и грубо прикидываем сроки на реализацию (для планов для высшего руководства).
Аналитик садится и вдумчиво излагает постановку в Confluence. После этого данную постановку согласовывает с ПМ, а тот при необходимости с высшим руководством.
Затем на основании этой постановки создается задача в Jira.
Часто задачи сразу появляются в Jira минуя этап с Confluence.
Любая задача, которая появляется в Jira сразу попадает на шаг “Постановка задачи”. На данном этапе заполняются такие данные как:
- тип задачи (новая функциональность, изменение функциональности, ошибка, тех. работы, документация)
- версия (обычно текущая в разработке)
- компоненты (например: админка, интерфейс, главная, финансы, отчетность...)
- описание задачи
На этапе постановки задача находится у ее автора и на нее больше никто не смотрит и о ней не знает.
Как только автор окончательно формулирует постановку задачи, он ее толкает на следующий (единственно возможный) шаг в workflow — ревизия постановки.
Ревизия постановки
При переходе на этот шаг триггеры Jira автоматом меняют ответственного задачи на ПМ-а.
Этот шаг предназначен для того, чтобы ПМ перечитал описание задачи и убедился, что автор правильно понял постановку и корректно описал задание для программиста. Очень часто из-за недостаточного взаимопонимания задача делается и тестируется до самого конца и только уже при релизе видно, что сделали совсем не то, что изначально требовалось.
Также на этом шаге ПМ принимает решение нужно ли реализовывать вообще данную задачу. Или нужно ли ее реализовывать именно в эту версию.
На этом этапе есть два варианта workflow: вернуть назад на постановку (доработку описания) или продвинуть дальше в работу.
Также я часто на этом шаге назначаю ответственного тимлида для того, чтобы он сам определил исполнителя
Ожидание работ
При выборе этого шага я настроил экран, в котором надо задавать исполнителя, поле “Программист” и планируемое время.
Этот шаг — пул задач программиста, который надо выполнить за версию в порядке, указанном в поле приоритет или в порядке любом удобном, если приоритет одинаковый.
Так уж получается, что во время работы над версией частенько этот список пополняется.
В работе
Нажимая на кнопку “В работу”, задача переходит в состояние “В работе” и благодаря плагину “Automated Log Work for JIRA” автоматически запускается счетчик логирования времени, который останавливается и сохраняет набежавшее значение при переводе задачи в другие статусы. На этом шаге программист может:
- Приостановить работу (ожидание работ);
- На ревизию кода;
- На ревизию постановки (не понял, что требуется делать или есть технические препятствия к реализации именно в такой постановке);
- На тестирование (не смог воспроизвести).
Чтобы работала связка FishEye+Crucible+Bitbucket+Jira, при комите программист обязательно в комменте должен указать номер задачи (PRJ-343).
У нас в команде договоренность, что мелкие правки типа подвинуть кнопку правее или раскрасить зелёный зеленее, можно сразу бросать на сборку. Иначе — ОБЯЗАТЕЛЬНО на ревизию кода.
Итак, бросаем задачу на ревизию кода, и при этом ответственным назначаем тимлида.
Ревизия кода
На этом шаге тимлид в специальной секции Development в Jira смотрит какой именно комит был сделан программистом и нажимает специальную кнопку “Code Review”.
После нажатия автоматически открывается Crucible и создается ревью на указанный комит (или несколько комитов).
Тимлид может видеть дерево файлов, которые правил программист ну и соответственно диференсы. Может оставить комментарий к любой строке кода или общий к ревизии. Crucible позволяет даже указать степень критичности проезда программиста.
После мук изучения чужого гуанокода, тимлид либо проталкивает задачу на шаг сборки, либо возвращает программисту в ожидание работ.
Программист в этом случае в секции Development видит Code Review и его статус. При переходе на этот Code Review опять же открывается Crucible, где программист может наглядно увидеть, где именно он налажал.
При переводе на шаг “Ожидание сборки”, тимлид выбирает ответственным тестировщика, который указан в спец поле, либо если оно не заполнено, то QA-лида.
Ожидание сборки
Так как сервер тестирования у нас один общий, то сборка по расписанию не годится. Нельзя подменять сайт во время его тестирования.
Поэтому обычно у нас тестировщики договариваются и, если никто не против, собирают себе свежую версию ресурса.
Делают они это с помощью Jenkins. В нем созданы по три сборки на каждый проект: сборка для тестов, сборка для разработки, сборка БД.
В сборке исходников настроен следующий алгоритм:
- Вытащить свежие исходники из Git.
- Скопировать их на FTP.
- Найти все задачи в Jira на шаге “Ожидание сборки” и перевести их на ожидание тестирования.
- Разослать письма.
В сборках БД все тоже самое, только вместо шага 3 выполняется следующее с помощью ssh команд на сервере:
3.1. Отрубить все коннекты к БД.
3.2. Удалить БД.
3.3. Восстановить БД прошлой версии.
3.4. Прокрутить на ней все скрипты новой версии.
БД у нас собирают крайне редко, только когда тестировщик видит в измененных файлах sql скрипты.
Ожидание тестирования
На этом шаге могут быть задачи, которые уже были в тесте, а могут быть и в первый раз. Если задача уже в тесте была, то тимлид уже ответственным ставит именно того тестировщика, который вернул задачу в работу.
Иначе все задачи скапливаются у QA-лида. Он смотрит на пул задач и нагрузку каждого тестировщика, и определяет кому назначить задачу на тест. Более того, сразу же определяет и тестировщика для парного тестирования.
Тестирование
С данного шага, задачу можно перевести практически на любой шаг workflow. Тестировщик может:
- вернуть задачу на постановку (чтобы ПМ определил нужно ли прямо сейчас или вообще исправлять, то что нашлось при тестировании);
- вернуть на ожидание работ программисту;
- отправить описание ReadMe (и назначить ее на техписа);
- протолкнуть на парное тестирование (и назначить ее на соответствующего тестировщика)
- перевести на ревизию функциональности (автоматом назначится ПМ).
Так же как и с шагом “В работе”, на этом шаге автоматически запускается счетчик времени, который логирует затраченное на работу время.
Ожидание парного тестирования
Этот шаг был придуман по нескольким причинам. Многие не понимали его целесообразности, но в итоге спустя какие-то время соглашались, что он необходим.
Суть его заключается в том, что есть основной тестировщик по задаче, который очень глубоко и усиленно ковыряет задачу со всевозможных аспектов и есть парный тестировщик, который поверхностно просматривает задачу только после полностью завершенных тестов первого. Это очень похоже на ревизию кода у программистов.
В итоге получаем то, что не только один тестировщик знает как устроена та или иная функциональность. Если задача футболялась 10 раз между программистом и тестировщиком, то свежий взгляд парного тестировщика может заметить что-то пропущенное. Ну и самое важное, то что каждый тестировщик работает по-своему и привыкает использовать софт определенным образом (логинится не используя мышь, аплоадить файлы драг-н-дропом, вместо фильтров использовать сортировки, при вводе данных копипастить тексты и т.д.). Очень часто бывает, что одни и те же функции можно использовать по-разному, и парный тестировщик натыкается на ошибки, которые были проверены основным, но немного по-своему.
Парное тестирование
Если на этом шаге обычно уже можно считать, что задача почти закончена. И очень часто, когда поторапливают с выпуском версии, его можно пройти формально.
ReadMe
После успешно проведенных тестирований уже окончательно определена функциональность и ее реализация. И вот теперь этой задачей занимается техпис. Обычно все задачи, кроме совсем незначительных или тех, которые сами сломали в процессе работы над версией, мы помечаем меткой “ReadMe”.
Парный тестировщик, если видит эту метку отправляет задачу на шаг “ReadMe” и назначает на техписа.
Техпис в специальном поле описывает очень кратко Release notes по этой задаче. Обычно это оповещение пользователя об изменении функциональности или исправлении ошибки, или о появлении новой функциональности и как ей пользоваться.
На этом же шаге техпис исправляет или дополняет справку ресурса в Confluence.
После проделанной работы, задача отправляется на финальный шаг “Ревизия функциональности”.
Ревизия функциональности
При переходе задачи на этот шаг, триггеры Jira автоматом назначают ответственным ПМ-а.
На этом шаге ПМ проверяет работу всей команды в целом. Было ли реализовано то что хотели, именно так как хотели, нормальное ли описание в ReadMe и т.д.
Бывает, что на этом шаге оказывалось, что программист с тестировщиком что-то между собой порешали и отрезали “ненужную функциональность” или изменили ее потому что посчитали так лучше, и именно эта функциональность требовалась высшим руководством и именно в таком виде. Тогда задача опять идет на “Ожидание работ”.
Ценность данного шага заключается в том, что хороший ПМ или ДМ после выпуска и звонка заказчика с фразой “что вы наделали?”, должен знать как именно реализовали задачу, как назвали кнопки, тексты сообщений, нюансы алгоритмов и смело ответить “сам дурак”. А не мяться и гадать, а как же они сделали ту форму и чего в ней кнопка задизейблена…
Закрыто
Ну тут все и так понятно. Задача закрывается после удачно прошедшей ревизии функциональности.
Или задача в любой момент может оказаться никому не нужной, потому переход на этот шаг возможен с любого другого шага.
Рабочий стол
Для удобства в Jira были разработаны рабочие столы для каждого проекта с четырьмя гаджетами:
- Мои задачи на всех шагах. Это список всех шагов workflow и с количеством задач напротив каждого, где я отмечен программистом или тестировщиком. Т.е. смотря на этот гаджет, я сразу могу видеть сколько моих задач сейчас на тестировании, разработке или постановке. Я могу понимать примерный объем моих задач.

- Я ответственный. Список задач, которые ждут моего решения. Пока я их не обработаю, никто другой у себя их не увидит.

- Сколько задач на каждом. Список всей команды разработки с количеством задач на каждом. Используется лидами для ориентирования кто больше загружен.
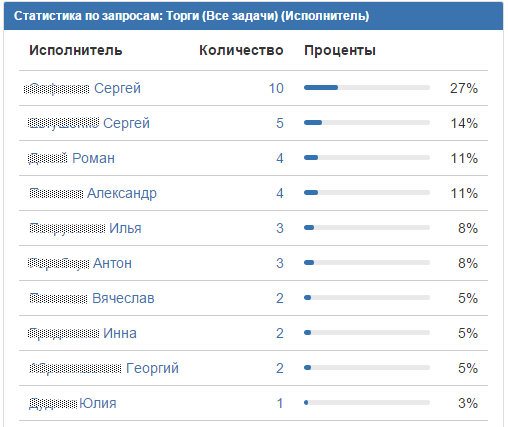
- Статистика по двумерному фильтру. Подробно видно на ком и на каких шагах сколько задач прямо сейчас.
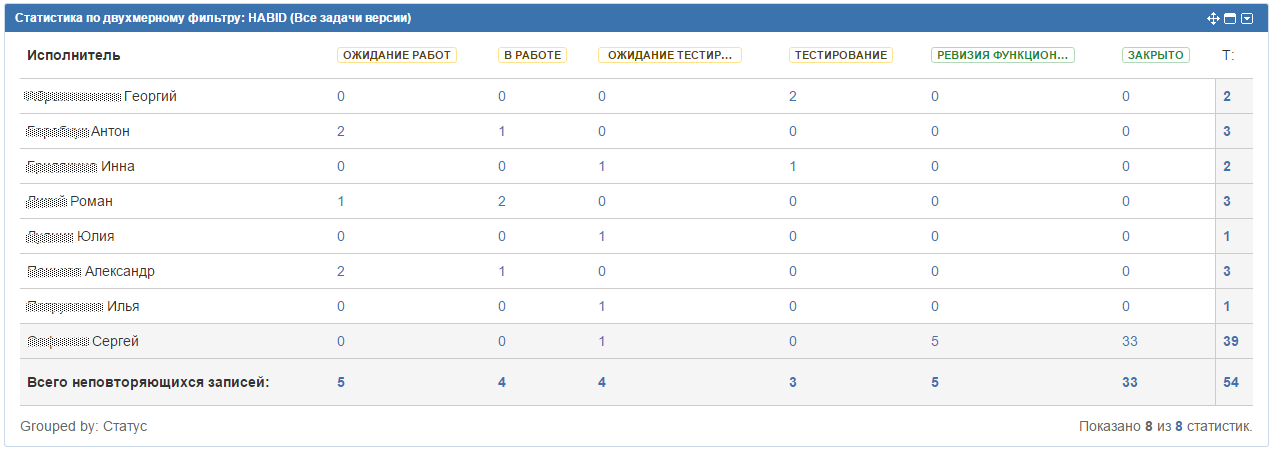
Еще с помощью GreenHopper я настроил такую доску:
Очень удобна для обзора всего процесса целиком.
Выпуск версии
При выпуске версии, мы выгружаем из Jira все задачи версии в виде двух колонок: компонент и поле ReadMe. Вот и получается у нас ReadMe сгруппированное по разделам.
С помощью “Scroll HTML Exporter” мы экспортируем страницу хелпа в Confluence и все ее дочерние страницы в набор html файлов, которые внутри выглядят так же красиво как в Confluence и ссылаются друг на друга.
Итоги
Вот по такому workflow мы уже работаем несколько лет, иногда его дорабатывая и дотачивая.
Но в целом он очень удобен.
Для ПМ тем, что в любой момент времени видно, кто именно и на каком шаге держит задачу.
Для разработчиков удобно видеть только свой объем работ.
Ну и, конечно же, автоматизация на всех шагах. Т.е. нет такого человека, без которого рабочий процесс может остановиться.







