Комментарии 16
А нельзя сказать, что Big Data = Data Mining + инфраструктура?
Извините, но у вас не совсем верное «определение» big data. Более-менее адекватный сбор разных определений big data можно найти в статье "Undefined By Data: A Survey of Big Data Definitions". В то время как на ваше утверждение «Например, если мы используем RDBMS, то это уже 100% не Big Data» есть опровержение в публикации "MapReduce and parallel DBMSs: friends or foes?". На самом деле в большинстве случаев такое понятие как big data используется больше в маркетинговых целях.
В то время как на ваше утверждение «Например, если мы используем RDBMS, то это уже 100% не Big Data»
В заключение имеет смысл добавить, что многие пытаются сравнивать эти понятия между собой и другими понятиями (например, с задачей highload, как это сделал автор здесь: habrahabr.ru/company/beeline/blog/218669) по стеку программных средств. Например, если мы используем RDBMS, то это уже 100% не Big Data.
Не могу согласиться с такой точкой зрения
Не претендуя на энциклопедическую точность определения, я бы сказал, что Big data — это данные, которые невозможно эффективно обработать на одном компьютере.
Как только задачу надо распараллеливать, возникает необходимость в целом классе технических приёмов. Никакой магии там нет.
Как только задачу надо распараллеливать, возникает необходимость в целом классе технических приёмов. Никакой магии там нет.
Я бы добавил даже — на одном ОЧЕНЬ БОЛЬШОМ компьютере, ибо в серверах сейчас доступны кучи ядер и терабайты RAM и возможно, что для конкретной задачи вполне хватит аренды времени одной такой «балалайки»
А в соседней статье пишут (http://habrahabr.ru/post/267697/#comment_8590875):
> BigData начинаются там, где уже невозможно весь набор данных поместить в память сервера. Для текущих конфигураций 2х-сокетных серверов это где-то в районе 3ТБ twitter.com/thekanter/status/559034352474914816
Соответственно, если взять средние сервера, то задача будет из области bigdata, а если hi-end, то задача станет рядовой (у SGI есть решения с 64ТБ общей RAM).
На мой взгляд для термина BigData вообще некорректно давать количественные определения, иначе мы будем вынуждены его переписывать с каждым новым анонсом серверов.
> BigData начинаются там, где уже невозможно весь набор данных поместить в память сервера. Для текущих конфигураций 2х-сокетных серверов это где-то в районе 3ТБ twitter.com/thekanter/status/559034352474914816
Соответственно, если взять средние сервера, то задача будет из области bigdata, а если hi-end, то задача станет рядовой (у SGI есть решения с 64ТБ общей RAM).
На мой взгляд для термина BigData вообще некорректно давать количественные определения, иначе мы будем вынуждены его переписывать с каждым новым анонсом серверов.
Да, именно так. Я даже могу очертить численную границу перехода в состояние BigData…
[Не люблю самоцитирований, но здесь это имеет смысл]
habrahabr.ru/post/267697/#comment_8590875
Я полностью согласен с Девидом Кантором в его утверждении, что BigData начинаются там, где уже невозможно весь набор данных поместить в память сервера. Для текущих конфигураций 2х-сокетных серверов это где-то в районе 3ТБ twitter.com/thekanter/status/559034352474914816
Все что меньше по размеру — «не очень Big Data»
[Не люблю самоцитирований, но здесь это имеет смысл]
habrahabr.ru/post/267697/#comment_8590875
Я полностью согласен с Девидом Кантором в его утверждении, что BigData начинаются там, где уже невозможно весь набор данных поместить в память сервера. Для текущих конфигураций 2х-сокетных серверов это где-то в районе 3ТБ twitter.com/thekanter/status/559034352474914816
Все что меньше по размеру — «не очень Big Data»
> Итого — неструктурированных данных не существует.
— Вы в порядке?
— Да, в случайном
— Вы в порядке?
— Да, в случайном
Big Data Mining…
Big Data — это такой фрейдизм. Сегодня каждый разведенный презентациями подкованный клиент требует себе решение BigData. Типа у него этот Data очень Big, и чтобы все стояло, требуются различные модные велосипеды типа Hadoop и NoSQL. Но как показывает практика, в итоге в 90% случаев все решается в рамках обычной RDBMS, а остальные 10% — простым скриптом, который парсит логи.
Чтобы доходчиво объяснить что такое BigData с практической точки зрения, нужно задать вопрос: для начала у вас есть 20+ свободных машин в датацентре? Если ответ отрицательный, дальнейший разговор не имеет смысла.
Чтобы доходчиво объяснить что такое BigData с практической точки зрения, нужно задать вопрос: для начала у вас есть 20+ свободных машин в датацентре? Если ответ отрицательный, дальнейший разговор не имеет смысла.
Недавно поймал себя на мысли, что в зарубежных data science блогах люди все меньше используют базз-ворд BigData. Даже там, где бумага его бы стерпела (с).
Потом увидел, что даже попсовый Gartner в своем Hype Cycle 2015 года убрал «BigData» (кстати, теперь там появился «Machine Learning»).
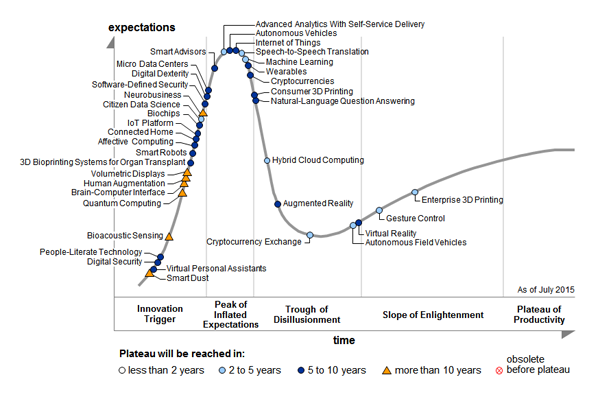
Похоже ажиотаж наконец-то начинает стихать.
Потом увидел, что даже попсовый Gartner в своем Hype Cycle 2015 года убрал «BigData» (кстати, теперь там появился «Machine Learning»).

Похоже ажиотаж наконец-то начинает стихать.
Machine Learning — да, новый тренд.
Кто-то пытается камаз научить видеть, хотя лично я не понимаю, зачем камазу зрение. Носорог же как-то справляется.
Кто-то организовывает СП в Сколково на тему Онкологии. Интересно, кто будет сидеть, в случае неверного диагноза. Внедренцы наверное думают, что разработчики, а разрабочики наверняка думают иначе.
Многие специалисты, которые занимаются «Machine Learning» гордо загружают данные в какое-то ПО (например в SPSS) и далее программа сама подбирает (тупой брутфорс) какие-то модели, в том числе и некие нейронные сети. Однако, результат обычно редко отличается кардинально от тривиальной модели, что собственно не удивительно. Программа ведь не знает о том, какие атрибуты важны, а какие не очень. Программа не владеет предметной областью.
Наиболее эффективно можно что-то проанализировать и предсказать только с применением человеческого мозга, когда мы создаем некий алгоритм, где параметры объекта интерпретируются с определенными весами и складываются в итоговый скоринг. Однако, можно ли это назвать машинным обучением? на мой взгляд, это обычное программирование.
Кто-то пытается камаз научить видеть, хотя лично я не понимаю, зачем камазу зрение. Носорог же как-то справляется.
Кто-то организовывает СП в Сколково на тему Онкологии. Интересно, кто будет сидеть, в случае неверного диагноза. Внедренцы наверное думают, что разработчики, а разрабочики наверняка думают иначе.
Многие специалисты, которые занимаются «Machine Learning» гордо загружают данные в какое-то ПО (например в SPSS) и далее программа сама подбирает (тупой брутфорс) какие-то модели, в том числе и некие нейронные сети. Однако, результат обычно редко отличается кардинально от тривиальной модели, что собственно не удивительно. Программа ведь не знает о том, какие атрибуты важны, а какие не очень. Программа не владеет предметной областью.
Наиболее эффективно можно что-то проанализировать и предсказать только с применением человеческого мозга, когда мы создаем некий алгоритм, где параметры объекта интерпретируются с определенными весами и складываются в итоговый скоринг. Однако, можно ли это назвать машинным обучением? на мой взгляд, это обычное программирование.
> Внедренцы наверное думают, что разработчики, а разрабочики наверняка думают иначе.
Это действительно проблема перекладывания ответственности. Обычно в software ответственность перекладывается в пользу конечного пользователя, в данном случае конкретного врача, который общается с клиентом. Но если разработанная система будет более чем на порядок точнее существующих «средних врачей» на ошибки будут закрывать глаза и постепенно поднимать точность системы.
Это действительно проблема перекладывания ответственности. Обычно в software ответственность перекладывается в пользу конечного пользователя, в данном случае конкретного врача, который общается с клиентом. Но если разработанная система будет более чем на порядок точнее существующих «средних врачей» на ошибки будут закрывать глаза и постепенно поднимать точность системы.
>Согласно проведенным выше декмопозициям определений — Data mining как бы “выигрывает” у Big Data за счет демократичного подхода к >объему данных.
Объем данных может быть любой, хотя обычно объемы у Big Data больше.
>Согласно списку задач, решаемым при помощи методов Big Data и Data Mining, “выигрывает” уже Big Data, так как решает задачи сбора и >хранения данных.
Это все равно что сравнить что руль от Мерседеса лучше чем Запорожец, т.к. Запорожец еще и едет =)
В целом не очень лаконично, более кратко нужно.
Я бы написал проще:
Data Mining это класс программ для нестандартного анализа данных, который работает только со структурированными данными.
Big Data это стек технологий и архитектурный принцип и т.д. и т.п.… который решает задачи ETL НЕструктурированных данных и в дальнейшем может включать и анализ этих данных. Хотя ничего не мешает после ETL Big Data направить данные уже в структурированном виде в Data Mining.
Хотя так же ничего не мешает Big Data не конвертировать данные в структурированный вид использовать специалезированные средства анализа заточенные именно для Big Data производить аналогичный анализ что делает Data Mining.
Объем данных может быть любой, хотя обычно объемы у Big Data больше.
>Согласно списку задач, решаемым при помощи методов Big Data и Data Mining, “выигрывает” уже Big Data, так как решает задачи сбора и >хранения данных.
Это все равно что сравнить что руль от Мерседеса лучше чем Запорожец, т.к. Запорожец еще и едет =)
В целом не очень лаконично, более кратко нужно.
Я бы написал проще:
Data Mining это класс программ для нестандартного анализа данных, который работает только со структурированными данными.
Big Data это стек технологий и архитектурный принцип и т.д. и т.п.… который решает задачи ETL НЕструктурированных данных и в дальнейшем может включать и анализ этих данных. Хотя ничего не мешает после ETL Big Data направить данные уже в структурированном виде в Data Mining.
Хотя так же ничего не мешает Big Data не конвертировать данные в структурированный вид использовать специалезированные средства анализа заточенные именно для Big Data производить аналогичный анализ что делает Data Mining.
Неструктурированные данные применительно к Big Data — это всего лишь данные, структура которых исследователю неизвестна (пока ещё… или в полной мере… или не может быть осмыслена человеком в принципе). Представьте себе массив информации обо всех органах человека, составляющих их тканях, различных видах клеток, эти ткани составляющих, и всех проходящих в каждой клетке биохимических реакциях, их скорости и сложности (например, ДНК «собирается» в клетке со скоростью 15 тысяч «знаков» в секунду). С одной стороны, человечество относительно скоро сможет смоделировать все процессы, происходящие в теле отдельно взятого человека на уровнях от биохимии до биологии и физиологии, но с другой стороны — тому же врачу, чтобы поставить диагноз, на практике не нужен весь массив этих исходных данных — достаточно выявить отклонения от типичного состояния и выделить из ряда возможных причин настоящую.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Big Data vs Data Mining