Комментарии 38
Хороший способ. Огорчает только то что такие объекты при кодировании в JSON и обратно перстают быть «голыми».
Use polyfill, Luke.
Стало интересно, насколько такие объекты быстрее, или медленнее обычных. Написал тест на jsperf-е.
На моем компьютере разница совсем незначительная.
На моем компьютере разница совсем незначительная.
НЛО прилетело и опубликовало эту надпись здесь
В том, что нельзя одновременно хранить toString и hasOwnProperty. Это ведь такой частый кейс!
А как раз самый частый кейс, что свойство может оказаться методом, который for… in спокойно себе проитерирует, хотя нам нужны только данные
Конечно, если в словарь положить функцию, то она там будет.
Тут, скорее, проблема в криворуком стороннем коде может быть. Вот тут да, лучше подстелить соломки.
Тут, скорее, проблема в криворуком стороннем коде может быть. Вот тут да, лучше подстелить соломки.
А какой другой код (положит)подложит туда toString и hasOwnProperty?
А откуда свойство окажется методом?:)
Ну вообще prototype.js и прочие sugar.js (и не только) любят пошалить в прототипах встроенных объектов. Из-за них, в основном, все эти страшилки про «не используйте for..in».
Ну вообще prototype.js и прочие sugar.js (и не только) любят пошалить в прототипах встроенных объектов. Из-за них, в основном, все эти страшилки про «не используйте for..in».
> А откуда свойство окажется методом?:)
потому что функция — полноправный объект, а контроль типов у нас по определению отсутствует
> «не используйте for..in».
потому, что мы итерируем по ключам вместо значений, это идет вразрез со всеми языками.
потому что функция — полноправный объект, а контроль типов у нас по определению отсутствует
> «не используйте for..in».
потому, что мы итерируем по ключам вместо значений, это идет вразрез со всеми языками.
Поэтому, кажется, придумали for-of. Осталось дождаться повсеместной поддержки. Честно говоря реализация в iojs не обрадовала =(
for-of не только эту проблему решает. А что там в iojs поломано на эту тему?
Из того что я запомнил: у меня не взлетело:
А жаль. Во многих местах пришлось отказаться от for-of из-за этого
for (var [key, value] of phoneBookMap)
А жаль. Во многих местах пришлось отказаться от for-of из-за этого
Мда, половина смысла теряется.
В babel работает, если что: github.com/hogart/alchemy/blob/fa4d02205fb4127d9e4d6a0524fb762752cead46/src/lib/alchemy.js#L16
В babel работает, если что: github.com/hogart/alchemy/blob/fa4d02205fb4127d9e4d6a0524fb762752cead46/src/lib/alchemy.js#L16
Полез смотреть где я вообще эти [] углядел. Увидел я их в статье на frontender.info. Но не обратил внимания на то, что там речь шла о Map. Впрочем это не отменяет того факта, что iojs ругался на синтаксис.
Тогда моя претензия больше к самой конструкции, хочется иметь сразу и ключ. Но похоже это претит самому принципу доступа через итераторы. Во всяком случае здесь я не нашёл решений.
Тогда моя претензия больше к самой конструкции, хочется иметь сразу и ключ. Но похоже это претит самому принципу доступа через итераторы. Во всяком случае здесь я не нашёл решений.
Нет, должно работать так, как вы и хотели: www.2ality.com/2015/02/es6-iteration.html, пример в пункте 2.3. Все зависит от того, что именно лежит в итерируемом под ключом Symbol.iterator. Ну и деконструкция должна тоже работать, я не помню, поддерживается она в iojs или нет.
В моем примере по ссылке используется Array#entries, который итерирует по парам индекс-значение.
В моем примере по ссылке используется Array#entries, который итерирует по парам индекс-значение.
Есть еще одна засада — объект невозможно отсортировать, в то время как массив — пожалуйста.
Поэтому, увы, как бы нам не хотелось, это не полноценная замена ассоциативным массивам.
Поэтому, увы, как бы нам не хотелось, это не полноценная замена ассоциативным массивам.
В качестве частного решения можно предложить такое:
Но, если честно, не помню, чтобы мне был нужен хэш, ключи в котором располагаются в определенном порядке. Приведите кейс, если не трудно?
Object.keys(obj).sort().forEach // ну или .map, смотря что нужно сделать
Но, если честно, не помню, чтобы мне был нужен хэш, ключи в котором располагаются в определенном порядке. Приведите кейс, если не трудно?
Я натыкался на эти грабли в 2011 году (когда только осваивал javascript). Использовал hash вместо массива, в качестве ключа были id-ки. В качестве значений нечто вроде: {id: int, position: int, ...}. Данные приходили из PHP, в котором сохранялся изначальный порядок сортировки (по position). А браузеры вели себя по разному. В итоге переделал на массивы. Хотя казалось, что будет удобнее иметь прямой доступ по id.
Не уверен, что сие описание сгодится как нормальный case, но меня на тот момент, такое поведение удивило :)
Не уверен, что сие описание сгодится как нормальный case, но меня на тот момент, такое поведение удивило :)
Насколько мне известно, такое поведение (определенный порядок ключей в словаре) только в PHP есть. Новички в Python, например, любят написать свой OrderedDict.
Вообще да, иногда хочется и быстрый доступ по id и итерацию по порядку — ну так, для красоты. Но обычно можно либо обойтись, либо воспользоваться какими-то обертками (Backbone.Collection, например).
Вообще да, иногда хочется и быстрый доступ по id и итерацию по порядку — ну так, для красоты. Но обычно можно либо обойтись, либо воспользоваться какими-то обертками (Backbone.Collection, например).
упс, не туда
> Object.keys(obj).sort().forEach
Тут вы получаете сортированные ключи, но не массив объектов.
В большинстве случаев сортировка должна производиться по содержимому. У меня такого вагон и маленькая тележка,
например
Вы в любом случае не отсортируете этот объект по полю value, в момент доступа он будет не отсортирован, вам будет нужен дополнительный массив для хранения порядка элементов. А конкретный бизнес пример — ну представьте что у вас есть таблица и строки в ней с ID. Это означает либо дополнительный массив для порядка, либо отсутствие доступа к строке по ID (если запихать эти объекты в обычный массив)
Тут вы получаете сортированные ключи, но не массив объектов.
В большинстве случаев сортировка должна производиться по содержимому. У меня такого вагон и маленькая тележка,
например
{
'foo': {
value: 3,
name: 'Vasya'
},
'bar': {
value: 2,
name: 'Petya'
}
}
Вы в любом случае не отсортируете этот объект по полю value, в момент доступа он будет не отсортирован, вам будет нужен дополнительный массив для хранения порядка элементов. А конкретный бизнес пример — ну представьте что у вас есть таблица и строки в ней с ID. Это означает либо дополнительный массив для порядка, либо отсутствие доступа к строке по ID (если запихать эти объекты в обычный массив)
НЛО прилетело и опубликовало эту надпись здесь
Для более функциональных структур данных придется подождать ES6 (ES2015), который предоставит нам нативные ассоциативные массивы в виде объектов Map, Set и других. А пока этот радужный момент не настал
Да ведь они уже везде реализованы, и недавно я с большим удовольствием и пользой использовал нативную Map (правда, в проекте только для Fx29+).
НЛО прилетело и опубликовало эту надпись здесь
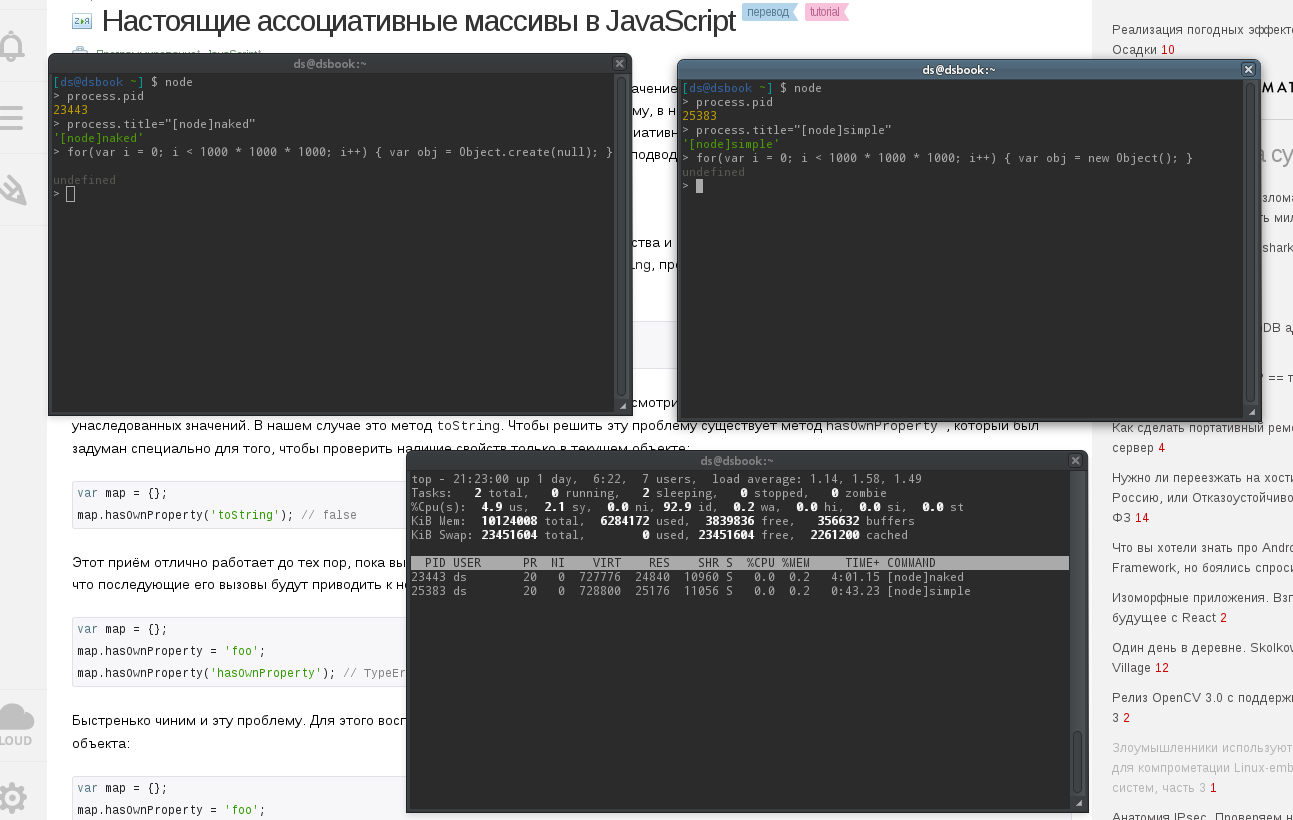
Что примечательно, запустил один и тот же код по созданию млрд обычных объектов и млрд голых. Память оба процесса расходуют одинаково. А вот процессорное время голые съели заметно больше, чем обычные.
Обычные объекты создались за 43 с хвостиком секунды процессорного времени.
Голые съели больше 4х минут.
Скриншот прилагается. Node v0.10.26

Обычные объекты создались за 43 с хвостиком секунды процессорного времени.
Голые съели больше 4х минут.
Скриншот прилагается. Node v0.10.26
Круто, а можете так же сравнить:
Может это Object.create не оптимизирован.
var normal = Object.create(Object.prototype);
var naked = Object.create(null);
Может это Object.create не оптимизирован.
Да, Вы правы по поводу
Поротестировал много разных вариантов прототипов.
Результаты приблизительно одинаковы везде — 4 минуты ± 15 секунд.
Тест показывал неоптимизированность именно
Сами тесты проводил самыми стандартными средствами: readline-интерфейс node и top с фильтром результатов по pid.
Есть еще один хороший сервис тестирования, но через браузер: jsperf.com/naked-vs-simple-objects
Тут надо быть вимательным, результаты отличаются в разных браузерах на разных ОС.
Также, по заявкам трудящихся на комментарий ниже, к утру потестирую вышеперечисленное на node v0.12.4.
Object.create().Поротестировал много разных вариантов прототипов.
Результаты приблизительно одинаковы везде — 4 минуты ± 15 секунд.
Тест показывал неоптимизированность именно
Object.create().Сами тесты проводил самыми стандартными средствами: readline-интерфейс node и top с фильтром результатов по pid.
Есть еще один хороший сервис тестирования, но через браузер: jsperf.com/naked-vs-simple-objects
Тут надо быть вимательным, результаты отличаются в разных браузерах на разных ОС.
Также, по заявкам трудящихся на комментарий ниже, к утру потестирую вышеперечисленное на node v0.12.4.
Интересно бы ещё посмотреть ситуацию на 12-ой.
Итак, скрин делать не буду. Оставлю результаты текстом.
Node v0.12.4
Node v0.12.4
for(var i = 0, l = 1000 * 1000 * 1000; i < l; i++) { var obj = {} } // => 0:07.29
for(var i = 0, l = 1000 * 1000 * 1000; i < l; i++) { var obj = new Object() } // => 0:34.58
for(var i = 0, l = 1000 * 1000 * 1000; i < l; i++) { var obj = Object.create(Object.prototype); } // => 1:11.67
for(var i = 0, l = 1000 * 1000 * 1000; i < l; i++) { var obj = Object.create(null) } // => 1:50.54
Отличная статья!
Идея (по крайней мере, для меня) новая, и, разумеется, имеет полное право на существование.
Но, ситуация, которую описывает Автор, скорее — ошибка проектирования, нежеле фича JavaScript. Это стоило бы отметить в статье. Сама статья может служить отличным гайдом, как исправить схожую ошибку проектирования на этапе программирования (когда все форматы для обмена и хранения данных утверждены, и нет возможности внести коррективы).
От себя хотел выделить правило: Никогда не используй название свойств объектов JS для хранения даннных. Свойства объектов используем только для структурирования данных.
Хранение данных в названиях свойств объектов равносильно хранению данных в названиях столбцов в таблицах реляционных СУБД.
Выше, в комментариях, обсуждалась технологическая проблема, в следствии которой приходилось держать отдельный массив для быстрого доступа к данным по сложному ключу или для сортировки этих данных. В теории СУБД такие массивы называются индексами. В использовании массивов такого назначения нет ничего плохого.
Если не нравится то, что приходится использовать несколько разных массивов с разными именами, один из самых производительных способов — создать свой класс, наследуемый от Array или Collection. Ну, и реализовать работу всех индексов в рамках этого класса.
Идея (по крайней мере, для меня) новая, и, разумеется, имеет полное право на существование.
Но, ситуация, которую описывает Автор, скорее — ошибка проектирования, нежеле фича JavaScript. Это стоило бы отметить в статье. Сама статья может служить отличным гайдом, как исправить схожую ошибку проектирования на этапе программирования (когда все форматы для обмена и хранения данных утверждены, и нет возможности внести коррективы).
От себя хотел выделить правило: Никогда не используй название свойств объектов JS для хранения даннных. Свойства объектов используем только для структурирования данных.
Хранение данных в названиях свойств объектов равносильно хранению данных в названиях столбцов в таблицах реляционных СУБД.
Выше, в комментариях, обсуждалась технологическая проблема, в следствии которой приходилось держать отдельный массив для быстрого доступа к данным по сложному ключу или для сортировки этих данных. В теории СУБД такие массивы называются индексами. В использовании массивов такого назначения нет ничего плохого.
Если не нравится то, что приходится использовать несколько разных массивов с разными именами, один из самых производительных способов — создать свой класс, наследуемый от Array или Collection. Ну, и реализовать работу всех индексов в рамках этого класса.
function AssocArray() {}
AssocArray.prototype = null;
Смысл, ведь, тот же?
А тест производительности что-то врет, видимо.
На моей машине в Chrome 43.0.2357.81 m 1M объектов {} создается за ≈1.5 сек, в то время как new AssocArray занимает ≈1.7 сек, а Object.create(null) — ≈2.1 сек.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Настоящие ассоциативные массивы в JavaScript