Комментарии 20
А различные подходы к векторному представлению слов могут улучшить выдачу таких систем?
Вы обо всех рассмотренных задачах? Впрочем, даже если о какой-то конкретной, я ещё прочитал слишком мало статей, чтобы сходу ответить на вопрос. Я не волшебник-от-дип-лёрнинг, я только учусь :)
Может, есть эксперты?
Может, есть эксперты?
Я, конечно, не эксперт, но фишка здесь в том, что векторное представление слов показывает взаимозависимости между словами, которые люди не ожидали увидеть. И если простые взаимозависимости типа «король-королева» можно ожидать (пол в языке задаётся явным образом), то более сложные вещи, типа переводов — уже удивительны. При этом, эти свойства векторных реперзентаций являются свойством именно репрезентаций, а не матода их получения. Грубо говоря — нейронная сеть в данном случае делает то-же, что и всегда — решает задачу оптимизации. Но те исходные данные, по которым ИНС решает задачу оптимизации, и задают свойства репрезентаций.
Написал много, поэтому резюме — разные методы получения репрезентаций должны приводить к одинаковым свойствам репрезентаций, то есть — нет, изменив метод обучения, существенного выигрыша в качестве не будет. А вот изменив обучающую выборку — изменение качества может быть кардинальным.
Я недавно экспериментировал с Word2Vec, здесь результаты (смотрите также комментарии):
habrahabr.ru/post/249215/#first_unread
Написал много, поэтому резюме — разные методы получения репрезентаций должны приводить к одинаковым свойствам репрезентаций, то есть — нет, изменив метод обучения, существенного выигрыша в качестве не будет. А вот изменив обучающую выборку — изменение качества может быть кардинальным.
Я недавно экспериментировал с Word2Vec, здесь результаты (смотрите также комментарии):
habrahabr.ru/post/249215/#first_unread
Поправьте меня, если я не прав — задача обучения нейронной сети это по сути своей задача многомерной оптимизации. Так что многое тут зависит от начальных условий, в роли которых выступает обучающая выборка. Чем ближе н.у. в оптимальному решению, тем больше шанс того, что система в процессе не застрянет в локальном оптимуме и сойдется к приемлемому решению. Т.к. векторные репрезентации для слов, как я понял из статьи и некоторых ссылок в ней, задаются в виде случайных векторов, то у меня возник вопрос, нет ли какой либо эвристики, что могла бы векторные представления не от балды задавать, а по какому-либо принципу?
Случайными задаются только начальные вектора. Собственно, так работают многие алгоритмы обучения ИНС. Шагают от некой случайной точки к оптимуму.
Вот теперь не понял. Входное представление слова W(«cat») = (0.1,-0.2,0.5,...) статично и намертво привязано к конкретному слову. Оно подается на вход нейронной сети, на выходе дающей другое представление этого же слова, по которому уже и производится анализ различных слов, ведь так?
Векторное представление — это когда берут массив текста, и по нему обучаются (нейронной сетью). На выходе — каждому слову соответствует свой вектор. Потом эти вектора подаются на вход другой нейронной сети для получения описанных в статье результатов. То есть — связывание репрезентаций слов с атрибутами картинок делает другая нейронная сеть, которая на вход получает — отдельно репрезентации, отдельно — атрибуты картинок.
Берём репрезентацию слова на вход, на выходе получаем репрезентацию слова с картинкой или репрезентацию фразы.
Берём репрезентацию слова на вход, на выходе получаем репрезентацию слова с картинкой или репрезентацию фразы.
Простите, а как вы слово подадите на вход нейронной сети?
Это такая особая магия векторных репрезентаций. если коротко, то идея в том, что-бы каждому слову соответствовал вектор, причём, расстояние между векторами двух любых слов тем меньше, чем чаще эти слова встречаются вместе. Нейронная сеть изменяет репрезентацию каждого слова так, что-бы эти репрезентации соответствовали статистике совместного появления этих слов в корпусе.
Не слово подаётся на вход нейронной сети, а события совместного появления слов в обучающей выборке. И на выходе мы имеем не нейронную сеть, а репрезентации для каждого из слов.
Не слово подаётся на вход нейронной сети, а события совместного появления слов в обучающей выборке. И на выходе мы имеем не нейронную сеть, а репрезентации для каждого из слов.
То есть, каждый нейрон входного слоя такой сети сопоставлен конкретному слову из словаря? И вся система в целом похожа на автоэнкодер?
не совсем так. в каждый момент времени нейроны входного слоя сопоставлены разным словам.
упрощённо, есть таблица:
const int INPUT_SIZE=500;
const int WORD_COUNT=500000;
const int LEVEL1_SIZE = 500;
float vec[INPUT_SIZE][WORD_COUNT];
float W[INPUT_SIZE*5][LEVEL1_SIZE];
float b[LEVEL1_SIZE];
и дальше
function Q(w1, w2, w3, w4, w5){
float h1[LEVEL1_SIZE] = rectify(b+W * vstack(vec[w1], vec[w2], vec[w3], vec[w4], vec[w5]));
…
},
function rectify(x){
return clip(x, 0, 20);
}
это для первого примера сверху, где 5 слов сразу обрабатывается.
Вы это имели в виду?
Другой вариант — h1_group = hstack(rectify(b + W * vec[w1]), ...)) — тоже применяется, когда есть готовая таблица, например, сделанная с помощью word2vec.
И я даже не знаю, похоже ли это на автоенкодер. Потому что автоенкодер отличается алгоритмом обучения без учителя, вместо этого у него функция ошибки — процент совпадения выхода со входом.
Для обучения word2vec используется другая функция ошибки, точнее, функций несколько, но все они так или иначе связаны с совместным употреблением слов в текстах.
упрощённо, есть таблица:
const int INPUT_SIZE=500;
const int WORD_COUNT=500000;
const int LEVEL1_SIZE = 500;
float vec[INPUT_SIZE][WORD_COUNT];
float W[INPUT_SIZE*5][LEVEL1_SIZE];
float b[LEVEL1_SIZE];
и дальше
function Q(w1, w2, w3, w4, w5){
float h1[LEVEL1_SIZE] = rectify(b+W * vstack(vec[w1], vec[w2], vec[w3], vec[w4], vec[w5]));
…
},
function rectify(x){
return clip(x, 0, 20);
}
это для первого примера сверху, где 5 слов сразу обрабатывается.
Вы это имели в виду?
Другой вариант — h1_group = hstack(rectify(b + W * vec[w1]), ...)) — тоже применяется, когда есть готовая таблица, например, сделанная с помощью word2vec.
И я даже не знаю, похоже ли это на автоенкодер. Потому что автоенкодер отличается алгоритмом обучения без учителя, вместо этого у него функция ошибки — процент совпадения выхода со входом.
Для обучения word2vec используется другая функция ошибки, точнее, функций несколько, но все они так или иначе связаны с совместным употреблением слов в текстах.
в многомерном пространстве застрять в далёком от цели локальном минимуме намного сложнее, чем в двумерном или тем более одномерном. но удачный выбор начальных условий помогает ускорить обучение, так же как и улучшение функции оптимизации.
НЛО прилетело и опубликовало эту надпись здесь
функция, отображающая слова из некоторого естественного языка в векторы большой размерности (допустим, от 200 до 500 измерений)мне кажется, при таком количестве измерений можно оставить только знак:
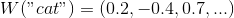
W("cat") = (+, -, +, ...)
2^500 тоже много, я согласен, но дробную часть можно считать парой дополнительных измерений, а чем больше измерений — тем лучше результат.
например, в шкалах-признаках бывают градации: крошечный-мелкий-небольшой-средний-крупный-огромный-гигантский,
молодой-старый, хороший-плохой.
также, близость слова к определённой теме («автомобильная тема», «военная тема», «спорт») можно приблизительно оценить вещественным числом.
например, в шкалах-признаках бывают градации: крошечный-мелкий-небольшой-средний-крупный-огромный-гигантский,
молодой-старый, хороший-плохой.
также, близость слова к определённой теме («автомобильная тема», «военная тема», «спорт») можно приблизительно оценить вещественным числом.
лингвистическая переменная из нечеткой логики
Есть такой подход в рамках Random Indexing: см. «bit vectors» en.wikipedia.org/wiki/Random_indexing.
Спасибо за пост. В статье есть очень полезные ссылки на научные статьи.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Deep Learning, NLP, and Representations