Комментарии 115
Учите английский. В программировании он просто необходим.
А что не так с английским в статье?
Его нет. Полезнее и правильнее писать методы на английском языке.
А что не так с английским в статье?Это относится к
на русском языке почти нет достойный литературы на эту тему
Этому плохо учат в вузах, об этом молчат самоучители PHP и официальный мануал, хотя это самый важный момент при разработке программы — создание архитектуры.
Ну это вы зря, что нигде это не описано. В руководстве по разработке на любом взрослом фреймворке это всё есть. При разработке при помощи фреймворков вам не надо думать про урлы и всё прочее и основная ваша задача сводится именно к описанию моделей и работе с ними. Более того, вам не надо делать «создать_запись» и прочее — CRUD встроен в любой фреймворк и работает без вашего участия. Понятное дело, что всё гораздо шире, но раз уж вы пишете про использование PHP для создания именно сайтов, то всё именно так и есть.
Начинать учиться с фреймворков — это никогда не научиться программировать. К фреймворкам приходят по мере накопления опыта, а не начинают с них. Как вы будете отлаживать чужой код, написанный без фреймворка, если кроме фреймворка ничего больше не знаете?
Если человек разберется с фреймворком, он тем более разберется с «говнокодом».
Фреймворк надо учить не в плане «тут контроллер, здесь моделька, тяп-ляп пару методов и готово», а вникать каким образом это реализовано и почему.
Фреймворк надо учить не в плане «тут контроллер, здесь моделька, тяп-ляп пару методов и готово», а вникать каким образом это реализовано и почему.
Я начинал с фреймворков и конкретных спецификаций — мне проще не писать лапшекод, и перерабатывать уже существующий.
Смотря что подразумевать под понятием «программирования» — у меня оно никак не связано с достижением поставленных задач любой ценой, не смотря на качество и гарантии долгосрочной поддержки.
Зачем копаться в «чужом» коде, который наверняка не покрыт тестами и наверняка плохо документирован, я уж не говорю об адекватном использовании разнообразных шаблонов проектирования?
Смотря что подразумевать под понятием «программирования» — у меня оно никак не связано с достижением поставленных задач любой ценой, не смотря на качество и гарантии долгосрочной поддержки.
Зачем копаться в «чужом» коде, который наверняка не покрыт тестами и наверняка плохо документирован, я уж не говорю об адекватном использовании разнообразных шаблонов проектирования?
Начинать учится с фреймворков — значит сразу обучиться лучшим практикам, используемым во всем мире, и не наступать на те грабли, на которые уже наступили другие.
Вы похожи на повара, который игнорирует хорошие ножи, комбайны, миксеры и прочие удобные инструменты, вместе с которыми приготовление пищи превращается в быструю и приятную процедуру, и пытается готовить что-то на костре и камне, заверяя всех, что так более правильно)
Может лучше взять нормальные и хорошие инструменты и не мучить себя и других?)
Вы похожи на повара, который игнорирует хорошие ножи, комбайны, миксеры и прочие удобные инструменты, вместе с которыми приготовление пищи превращается в быструю и приятную процедуру, и пытается готовить что-то на костре и камне, заверяя всех, что так более правильно)
Может лучше взять нормальные и хорошие инструменты и не мучить себя и других?)
Ну да а потом такие «повара» спрашивают как переменожить два числа помощью Jquery.
Хороший повар может приготовить вкусную еду, используя плохие ножи, комбайны, миксеры и неудобные инструменты. Удобные инструменты каждый подбирает для себя сам, когда уже есть опыт работы с неудобными. Удобство — трудноизмеримый параметр. У каждого своё понимание, что считать удобным.
1. Название статьи очень и очень косвенно говорит о ее содержании. Как минимум стоило бы написать в скобках (ч. 1).
2. Материалов по тому что вы написали, в довольно широком смысле и более раскрывающих тему в интернете огромное количество. Достаточно загуглить «mvc php».
3. Самый лучший способ понять поможет ли кому-то то что вы написали, это вспользоватся самостоятельно этим «tutorial». Поверьте, толку от него будет мало. То что вы описали мало того что часто уже написано в ORM библиотеках, так еще и может сбить с толку, когда будет выбираться подход к хранению бизнес-логики.
4. Если вам нужна информация, или хотите сделать что-то полезное, обратитесь сперва к опытным коллегам, они, как правило, помогут.
5. Лучше в черновики.
2. Материалов по тому что вы написали, в довольно широком смысле и более раскрывающих тему в интернете огромное количество. Достаточно загуглить «mvc php».
3. Самый лучший способ понять поможет ли кому-то то что вы написали, это вспользоватся самостоятельно этим «tutorial». Поверьте, толку от него будет мало. То что вы описали мало того что часто уже написано в ORM библиотеках, так еще и может сбить с толку, когда будет выбираться подход к хранению бизнес-логики.
4. Если вам нужна информация, или хотите сделать что-то полезное, обратитесь сперва к опытным коллегам, они, как правило, помогут.
5. Лучше в черновики.
кидаю в Вас вот этим (http://habrahabr.ru/search/?q=mvc)
Не понимаю, почему заминусовали статью. В ней говориться о правильных вещах, и она многим может быть полезна.
Нужно понимать что существует понятие «шаблона проектирования», и оно имеет очень поверхностное отношение к «архитектуре» приложения, так как обычно она состоит с 4-5 различных шаблонов. Нужно понимать что кроме MVC существует ещё и много других вариаций шаблонов «трёхзвенной архитектуры», ну там MVP MVVM etc.
Статья бы стоила внимания если бы в ней более детально рассматривался MVC шаблон в рамках нескольких существующих фреймворков, а также если бы было сравнение с другими шаблонами и были бы описаны примеры их реализации.
А так получается Вот есть MVC, а в нём всё есть CRUD — на каждую табличку нужно по контроллеру, и по другому быть не может, MVC — это «пилюля от всех болезней» и «вселенная вращается вокруг MVC».
По личному опыту могу сказать что большинство «школьных» РНР программистов не знают
p.s. мне 23, я бросил универ на втором курсе. Учитывая ситуацию с дилетантством студентов/аспирантов (бывают исключения) — совсем не жалею.
Статья бы стоила внимания если бы в ней более детально рассматривался MVC шаблон в рамках нескольких существующих фреймворков, а также если бы было сравнение с другими шаблонами и были бы описаны примеры их реализации.
А так получается Вот есть MVC, а в нём всё есть CRUD — на каждую табличку нужно по контроллеру, и по другому быть не может, MVC — это «пилюля от всех болезней» и «вселенная вращается вокруг MVC».
По личному опыту могу сказать что большинство «школьных» РНР программистов не знают
- что такое PSR, и как их использовать
- как производить менеджмент зависимостей
- как проектировать нормализированные модели БД
- почему за outer join'ы и count() нужно органов лишать
- что если есть push нотификации — нужно прикручивать beanstalk / gearmand / rabbitmq, и это уже далеко не MVC
p.s. мне 23, я бросил универ на втором курсе. Учитывая ситуацию с дилетантством студентов/аспирантов (бывают исключения) — совсем не жалею.
Погуглил и ничего не нашел. Спрошу у вас: что не так с count()?
Для красноречивости.
При больших выборках count() и outer join'ы занимают очень много времени, особенно при full table scan'ах. Нужно заводить отдельно счётчики, а не ялозить всю табличку из-за каждого чиха.
Счетчики на все возможные сочетания группировок?
А outer joinы почему долго?
А outer joinы почему долго?
Счетчики на все возможные сочетания группировок ?Это быстрее чем каждый раз пересчитывать всё заново.
Там могут возникать весёлые моменты с join'aми, иногда проще отдельно заводить счётчик чем сталкиваться с таким.
А outer joinы почему долго?Потому что, обычно, это 100% full table scan. Обычно проще заменить на UNION ALL, или на CROSS JOIN, типа так.
Жесть.
Вид джоина никак не должен влиять на full table scan — влияет сиатистика по индексам. Про count вам комбинаторная задача — в таблице 16 полей по которым мы хотим группировать в любых сочетаниях — сколько и каких индексов вы создадите в таблице счетчиков и как она должна вообще выглядеть?
Вид джоина никак не должен влиять на full table scan — влияет сиатистика по индексам. Про count вам комбинаторная задача — в таблице 16 полей по которым мы хотим группировать в любых сочетаниях — сколько и каких индексов вы создадите в таблице счетчиков и как она должна вообще выглядеть?
Вид джоина никак не должен влиять на full table scanЭто почему-же?
«Яичная диаграмка» left outer join'a говорит об обратном

В случае с Outer Join'aми заполняется внешняя часть круга — соответственно для её формирования нужен full table scan, или fast full index scan. Он может быть кэшированным в рамках профилятора СУБД, но это приводит к росту счётчиков MVCC транзакций, и возможному провалу уже существующих, что, собственно, лочит всю табличку.
В таблице 16 полей по которым мы хотим группировать в любых сочетанияхКакая-то прям утопически идеальная задачка — такого в реальной жизни не бывает. Чаще всего, всё приходится генерировать по требованию, и подчищать если давно не использовалось. А надеяться что пользователи будут равномерно пользоваться всеми существующими сочетаниями какого-либо функционала — очень наивно.
1. Если внешняя часть круга — это таблица без условий — то да. Как и в случае просто select без джоинов. Домашнее задание: получить план запроса select * from order outer join customer on order.customer = customer.Id where order.Id =3 при условии что есть уникальные индексы по order.id, customer.id и в таблицах большет1000тзаписей
2. Например в UI можно выбрать группировку самому (простейший pivot). В-общем, в каких-то случаях добавление счётчика ускоряет, а в каких-то замедляет (например, при массивных вставках обращение к таблице счётчиков будет приводить к блокировка и замедлению ввода данных.
В-общем, вы тему не знаете, но советуете в категоричной форме почитайте как работает оптимизатор посмотрите на планы запросов посмотрите какие проблемы возникают в случае использования счетчиков
2. Например в UI можно выбрать группировку самому (простейший pivot). В-общем, в каких-то случаях добавление счётчика ускоряет, а в каких-то замедляет (например, при массивных вставках обращение к таблице счётчиков будет приводить к блокировка и замедлению ввода данных.
В-общем, вы тему не знаете, но советуете в категоричной форме почитайте как работает оптимизатор посмотрите на планы запросов посмотрите какие проблемы возникают в случае использования счетчиков
1. Тут используется конкретный индекс B-дерева, но в любом случае происходит full index scan, как я уже успел упомянуть.
2. Я не предлагаю держать счётчики внутри БД и блокировать всё и всея, это тема для отдельной статьи.
Я советую, исходя из своего личного опыта работы, он наверняка очень сильно отличается от вашего, не думаю что тут применима эстимация какого-либо уровня квалификации. Не стоит так категорично «вы тему не знаете, но советуете», у меня есть на то свои, личные, причины.
2. Я не предлагаю держать счётчики внутри БД и блокировать всё и всея, это тема для отдельной статьи.
Я советую, исходя из своего личного опыта работы, он наверняка очень сильно отличается от вашего, не думаю что тут применима эстимация какого-либо уровня квалификации. Не стоит так категорично «вы тему не знаете, но советуете», у меня есть на то свои, личные, причины.
1. Зачем тут что-то кроме двух index seek
Вы ведь эксперимент не провели?
2. Нужно смотреть количество бухгалтерских поводок между двумя датами d1 и d2 даты водятся пользователем. Как вы организуете счётчики?
Я пока вижу что вы даете категоричные советы и знаете очень мало именно в той области, в которой даете. Все равно что говорить «не пользуйтесь ножом, потому, что если взять за лезвие и стучать по гвоздю, он взрывается»
Вы ведь эксперимент не провели?
2. Нужно смотреть количество бухгалтерских поводок между двумя датами d1 и d2 даты водятся пользователем. Как вы организуете счётчики?
Я пока вижу что вы даете категоричные советы и знаете очень мало именно в той области, в которой даете. Все равно что говорить «не пользуйтесь ножом, потому, что если взять за лезвие и стучать по гвоздю, он взрывается»
Я вас просто проигнорирую.
Не хочу вас обидеть, но вы все же зря бросили университет.
Это просто ваше личное, субъективное, мнение.
Если вы хотите чего-то объективного — проведите упомянутый эксперимент. Кстати, я могу оказаться не прав — в каком-нибудь MySQL может быть глюк, который препятствует логично оптимизации запросов именно с outer join. Тогда в рамках этой глюковины ваш совет будет верен :).
Правда, судя по аргументам, которые вы привели у вас весьма смутные представления о работе оптимизатора.
Правда, судя по аргументам, которые вы привели у вас весьма смутные представления о работе оптимизатора.
Меня игнорируйте ради бога. Эксперимент советую провести.
В случае с Outer Join'aми заполняется внешняя часть круга — соответственно для её формирования нужен full table scan, или fast full index scan.
Не нужен, достаточно определить пересечение A и B (обычный join) и наложить его на таблицу B и выдать результат. То есть, есть в таблице А и B по миллиону записей из них 10 общих. Мы получили эти 10 записей, запоминаем их, теперь возвращаем нужное кол-во строк таблицы B (например 100) с null вместо полей таблицы A, если встречаем индекс тех 10 записей, то подставляем вместо null нужные значения из А. В результате, сложность = обычный join А и B + обычный вывод данных таблицы B + небольшая подстановка из памяти.
Учитывая что обычно ещё накладывают фильтры where на A и B разница между обычным join и left join не существенна.
Я уже 3 раза успел пожалеть, что начал об этом всём разглагольствовать.
Скажем, так
Select B.*, A.* from A,B where A.date = today() and B.date = today() and B.id1 += A.id2.
Нормальный оптимизатор сначала обрежет A и B до today в результате речь будет идти не о полных таблицах на миллионы записей, а скажем о тысячах, потом сделает просто join (речь идет о десятках записей), потом просто выведет уже полученную таблицу B за сегодня легко модифицируя её общим join'ом.
При наличии индексов по date, id1 и id2 все будет быстро, большой разницы для оптимизатора между выводом просто join'a или join'a + таблица B в большинстве случаев не будет (там по сути всего лишь ещё один обычный join с двумя весьма небольшими таблицами и индексами на ключевые поля).
Select B.*, A.* from A,B where A.date = today() and B.date = today() and B.id1 += A.id2.
Нормальный оптимизатор сначала обрежет A и B до today в результате речь будет идти не о полных таблицах на миллионы записей, а скажем о тысячах, потом сделает просто join (речь идет о десятках записей), потом просто выведет уже полученную таблицу B за сегодня легко модифицируя её общим join'ом.
При наличии индексов по date, id1 и id2 все будет быстро, большой разницы для оптимизатора между выводом просто join'a или join'a + таблица B в большинстве случаев не будет (там по сути всего лишь ещё один обычный join с двумя весьма небольшими таблицами и индексами на ключевые поля).
Мне не нужны ваши объяснения, решение этой проблемы я сам описал выше.
Меня категорически не устраивает ни full table, ни full index scan в любом виде.
Да, я прекрасно знаю как работает оптимизация релятивных запросов, и какие проблемы могут возникать. Также я знаю что с индексов попадает в кэш, на примере PostgreSQL и Oracle, и как потом происходит синхронизация при конкурентном доступе (плохо). Я не собираюсь объяснять всех причин такого отношения к предмету, просто потому что в этом обсуждении никто не собирается входить в моё положение — у вас тут другие задачи (в основном компенсаторные).
Меня категорически не устраивает ни full table, ни full index scan в любом виде.
Да, я прекрасно знаю как работает оптимизация релятивных запросов, и какие проблемы могут возникать. Также я знаю что с индексов попадает в кэш, на примере PostgreSQL и Oracle, и как потом происходит синхронизация при конкурентном доступе (плохо). Я не собираюсь объяснять всех причин такого отношения к предмету, просто потому что в этом обсуждении никто не собирается входить в моё положение — у вас тут другие задачи (в основном компенсаторные).
>>>Мне не нужны ваши объяснения, решение этой проблемы я сам описал выше.
Нет никакой проблемы?
>>>Да, я прекрасно знаю как работает оптимизация релятивных запросов
Но мы-то речь идем по релятивистские!
>>>Я не собираюсь объяснять всех причин такого отношения к предмету, просто потому что в этом обсуждении никто не собирается входить в моё положение — у вас тут другие задачи (в основном компенсаторные).
Я, вот честно говоря, не понял вообще что у вас положение. Мой приведенный пример вы проигнорировали — привезите свой пример в котором будет продемонстрирована разница в планах запроса с outer join и c другими джоинами. Пока я виде вообще нежелание с вашей стороны аргументированно обсуждать. Вместо этого вы обижаетесь.
Нет никакой проблемы?
>>>Да, я прекрасно знаю как работает оптимизация релятивных запросов
Но мы-то речь идем по релятивистские!
>>>Я не собираюсь объяснять всех причин такого отношения к предмету, просто потому что в этом обсуждении никто не собирается входить в моё положение — у вас тут другие задачи (в основном компенсаторные).
Я, вот честно говоря, не понял вообще что у вас положение. Мой приведенный пример вы проигнорировали — привезите свой пример в котором будет продемонстрирована разница в планах запроса с outer join и c другими джоинами. Пока я виде вообще нежелание с вашей стороны аргументированно обсуждать. Вместо этого вы обижаетесь.
просто потому что в этом обсуждении никто не собирается входить в моё положение
По опыту работы в очень крупной международной компании с многомиллардными таблицами в базе Oracl'a, где left join'ы использовались постоянно — с ними проблем не было, естественно если использовать правильные индексы и правильные запросы (не пытаться, например, получить всю таблицу без фильтров). Если бы при этом был реально full table или full index scan на многомиллиардной таблице все бы умерло сразу.
Там могут возникать весёлые моменты с join'aми, иногда проще отдельно заводить счётчик чем сталкиваться с таким
Это не веселые моменты, это просто кривые руки того кто пишет запрос.
Потому что, обычно, это 100% full table scan. Обычно проще заменить на UNION ALL, или на CROSS JOIN, типа так.
Вообще-то, там речь идет о full outer join, который мало кем используется, а вот left join в той же статье назван вполне нормальным, не говоря уже о том что left join на union all никак не заменяется.
«Там могут возникать весёлые моменты с join'aми, иногда проще»
Прочитал.
Статья написана в каком-то дебильном стиле «возьмите нож за лезвие для забивания гвоздя, видите — порезались. Никогда не берите ножи и не забивайте гвозди» автора надо посадить на год в камеру и чтоб там была книжка дейта в качестве единственного источника информации.
Прочитал.
Статья написана в каком-то дебильном стиле «возьмите нож за лезвие для забивания гвоздя, видите — порезались. Никогда не берите ножи и не забивайте гвозди» автора надо посадить на год в камеру и чтоб там была книжка дейта в качестве единственного источника информации.
Вы не поверите, если нет там никаких join, то count по индексу работает ОЧЕНЬ быстро, а count(*) from table без условий работает мгновенно, ибо ничего не считает, а тупо выдает количество из схемы
Не понимаю, почему заминусовали статью. В ней говориться о правильных вещах, и она многим может быть полезна.
Мне показалось, что статья слишком поверхностный пересказ MVC своими словами. Если уж писать не на СМС и не на готовом фреймворке, явно стоит самому сесть и прочитать о разных архитектурах веб. приложений, благо информации о MVC и т.п. более чем достаточно (в том числе на русском). Совсем новичок вряд ли осилит создание сайта с нуля, без СМС, а более-менее опытного разработчика статья скорее запутает, слишком там мало архитектуры.
Определитесь, что на вашем сайте самое главное
Для блога — это, очевидно, записи. Для магазина — товары. Для сайта поликлиники — услуги.
для блога — читатели, для магазина — покупатели, для сайта поликлиники — клиенты. А вот их уже могут интересовать ваши записи, товары, услуги. Но не только! На бложик могут заходить пообщаться с тусовкой, на сайт магазина — посмотреть ТТХ товара(аналог в реале: зайти в магазин поболтать с продавцом), ну с поликлиникой понятно, для маневра места мало.
А вот с тем, для чего это делается, имхо, сюда отношения не имеет, потому как либо для зарабатывания денег либо для ЧСВ. Но в любом случае, мотивы к механике разворачивания сайта отношения не имеют.
Да, для такого же магазина — есть товары, есть корзина, есть заказы, есть постоянные покупатели, есть скидки, есть отзывы и комментарии. Для создания правильной архитектуры, надо не только понимать какие есть сущности в системе, но и те бизнес процессы, которые с ними происходят (чтобы не продать двум покупателям одну и тут же последнею единицу товара со склада).
Этому плохо учат в вузах
Не во всех ВУЗах!
Если университет имеет нормального преподавателя, то и учить он будет нормально. Да, студенты раздолбаи, но что по делаешь. Тот кто учит — все понимает. В нашем университете такая ситуация по веб-системам — разработайте систему и БД с 0. Проект очень объемный, много различных аспектов охватывается — от проектирования архитектуры как БД так и сайта, до написания тестов для отладки. В двух словах не описать.
Кто-то делает, кто-то балду пинает. Кто-то учиться, а кто-то отчисляется :)
в страшной аббревиатуре MVC
а почему MVC преподносится как единственно возможная архитектура для всего вэба? Не спорю, лучше MVC, чем отсутствие архитектуры совсем, но все-таки есть еще куча способов разделить данные, бизнес-логику и представление
composer create-project laravel/laravel awesome
и дальше по статье
>> public function создать_запись($заголовок, $текст) {}
Автору прямая дорога в 1Сники :)
Автору прямая дорога в 1Сники :)
в 1с это имеет смысл — многие бухгалтерские термины трудно перевести на английский без потери читабельности. для элементов сайта такой проблемы нет.
не имеет это смысла в 1С. 1С вообще бессмысленен и беспощаден. Код править будут все равно программисты со знанием бухгалтерии а не бухгалтеры со знанием программирования. Поэтому и язык строить надо было с учетом best practices программирования а не бухгалтерии.
1С 7 CSV-RPC over FTP… уже было так.
Вы сначала загляните в 1С, посмотрите на регистры и документы, на реализацию клиент-сервера там, потом пообщайтесь с кем-нибудь из программистов 1С, которые не только разрабатывают реальные проекты (про них тоже поинтересуйтесь), но и знают бухгалтерию/управление предприятиям (читай — предметную область). Ну или там посчитайте, сколько новых (работающих) best practices программирования утащено в 8-ку, например (они, правда, еще переименованы, чтобы бухгалтера в обморок не падали при разговорах программистов).
Читайте «Совершенный код» и не пишите своих велосипедов по проектированию. А с совета «продумайте архитектуру на бумаге» начинается 2 из трёх книг программировании которые я читал, не ясно почему вы не нашли материалов на русском по данной теме.
Когда-то давно я использовал Smarty в одном из своих первых проектов… Тяжелые были времена))
PHP уже изначально прекрасно приспособлен к генерации html-кода, и не так уж ему и нужны какие-то дополнительные шаблонизаторы. К тому же, они резко усложняют архитектуру приложения, а также в десятки раз увеличивает время генерации одной станицы сайта. Короче, крайне не советую использовать тяжелые шаблонизаторы. PHP прекрасно обходится без них.
А вот изучить какой-нибудь Laravel на досуге, прежде чем писать статьи о хорошей архитектуре — было бы полезно)
Вообще, честно, лучше бы автор сначала поработал несколько лет, набрался опыта. Пока еще рано учить других)
PHP уже изначально прекрасно приспособлен к генерации html-кода, и не так уж ему и нужны какие-то дополнительные шаблонизаторы. К тому же, они резко усложняют архитектуру приложения, а также в десятки раз увеличивает время генерации одной станицы сайта. Короче, крайне не советую использовать тяжелые шаблонизаторы. PHP прекрасно обходится без них.
А вот изучить какой-нибудь Laravel на досуге, прежде чем писать статьи о хорошей архитектуре — было бы полезно)
Вообще, честно, лучше бы автор сначала поработал несколько лет, набрался опыта. Пока еще рано учить других)
К тому же, они резко усложняют архитектуру приложения, а также в десятки раз увеличивает время генерации одной станицы сайта.Ерунда.
Резкого усложнения архитектуры нет.
Десятков раз тоже нет (вернее такие слоупоки есть, но никто не заставляет их использовать).
Любой шаблонизатор будет медленнее, но взамен они предоставляют:
— чистый и легкочитаемый код
— простой синтаксис, которому без труда можно научить верстальщиков
— легкая миграция шаблонов между платформами (если специально озадачится, то и вовсе плтаформонезависимые шаблоны).
В большинстве случаев в битве «скорость рендеринга страницы vs скорость/удобство разработки» побеждает второе, потому что нет разницы страница будет отрисована чистым PHP за 10 мс или шаблонизатором за 100 мс.
По этой же причине популярны и широко используются различные фреймворки и ORM.
Это вовсе даже не ерунда. У меня такое ощущение, что на вас надеты розовые очки) Если бы всё было так, как вы описываете, то я бы с радостью использовал шаблонизаторы в своих проектах. Однако, как я уже писал, мне довелось использовать Smarty, я столкнулся со всеми его недостатками и впоследствии больше не использовал его в своих проектах. И я еще ни разу не пожалел об этом.
Нет резкого усложнения архитектуры? А что насчёт дополнительного синтаксиса для работы с переменными, циклами, модификаторами, функциями? Согласен, он довольно прост, когда попрактикуешься с ним какое-то время, но факта это не меняет: в довесок к основной документации к PHP вам теперь придётся понимать еще и всё это: www.smarty.net/docs/en/
Также обязательно придётся бороться с новыми глюками и проблемами, которые будут возникать во время разработки, из-за того, что вы используете дополнительную сложную библиотеку для генерации своих шаблонов. Придётся дополнительно следить за настройками кеширования шаблонов. У меня лично были с этим проблемы. В общем, вам придётся неплохо разбираться в том, как работает движок шаблонизатора. Придётся тратить на это своё время и нервы.
Далее, что меня лично больше всего бесило в Smarty — это отсутствие возможности использовать стандартные функции PHP. Фактически, он загоняет тебя в жёсткие рамки своего синтаксиса и функционала, из которых ты никак не можешь выбраться. Чтобы дополнить шаблонизатор какими-то своими функциями, приходилось регистрировать их через специальное API, предоставляемое шаблонизатором… Сейчас я уже даже и не помню, как это делается. В общем, факт есть факт — быстро вызвать какую-то свою функцию в шаблонизаторе вы уже не сможете. Придётся изучать документацию, писать дополнительный код для расширения.
Насчёт обучения верстальщиков… Тоже весьма и весьма спорное утверждение. Сильной разницы между кодом на PHP там и нет, и там и там используются всякие циклы, методы. А список всяких функций и модификаторов придётся учить в любом случае. Легкая миграция шаблонов? Это вообще что такое?) И зачем оно нужно?) Куда их мигрировать из приложения?
На тему скорости генерации шаблонов… Как-то, в самом начале разработки одного из проектов, мы размышляли о том, следует ли использовать Smarty в новом проекте, или же писать всё на стандартных PHP шаблонах. Фреймворком мы тогда выбрали Кохану. И я решил на практике посмотреть разницу в скорости генерации страницы фреймворком вместе с шаблонизатором, и на основе нативных PHP шаблонов. Создал две одинаковых страницы, которые генерировали какой-то контент, одна на смарти — другая на нативном php-коде. В итоге, смарти генерировал ту же страницу в несколько десятков раз медленнее. Это не было заметно на глаз, но профайлер коханы ясно показал огромный разрыв в скорости генерации страниц.
В итоге, с тех пор я полностью отказался от данного шаблонизатора и до сих пор считаю это верным выбором. В завершение комментария, приведу вам кусок из текущего проекта на Laravel, в котором я использую их шаблонизатор Blade — но его и полноценным шаблонизатором-то назвать трудно… Это скорее небольшое расширение основного кода на PHP. Его практически не видно в проекте, и при этом в шаблонах можно легко использовать всю мощь PHP, так, как-будто мы и не используем никаких шаблонизаторов в своём коде. И в данный момент я считаю, что данный вариант — это лучший компромисс, который может быть сделан на PHP.
Посмотрите на код страницы редактирования пользователей с использованием Blade: paste.ofcode.org/nLijEzhiWC4t6KtYnYazG5
Разве настолько оно плохо выглядит, по сравнению с кодом на Смарти? Да разницы практически нет…
Ну так зачем нужны эти тяжелые шаблонизаторы, когда и без них всё прекрасно работает?)
Нет резкого усложнения архитектуры? А что насчёт дополнительного синтаксиса для работы с переменными, циклами, модификаторами, функциями? Согласен, он довольно прост, когда попрактикуешься с ним какое-то время, но факта это не меняет: в довесок к основной документации к PHP вам теперь придётся понимать еще и всё это: www.smarty.net/docs/en/
Также обязательно придётся бороться с новыми глюками и проблемами, которые будут возникать во время разработки, из-за того, что вы используете дополнительную сложную библиотеку для генерации своих шаблонов. Придётся дополнительно следить за настройками кеширования шаблонов. У меня лично были с этим проблемы. В общем, вам придётся неплохо разбираться в том, как работает движок шаблонизатора. Придётся тратить на это своё время и нервы.
Далее, что меня лично больше всего бесило в Smarty — это отсутствие возможности использовать стандартные функции PHP. Фактически, он загоняет тебя в жёсткие рамки своего синтаксиса и функционала, из которых ты никак не можешь выбраться. Чтобы дополнить шаблонизатор какими-то своими функциями, приходилось регистрировать их через специальное API, предоставляемое шаблонизатором… Сейчас я уже даже и не помню, как это делается. В общем, факт есть факт — быстро вызвать какую-то свою функцию в шаблонизаторе вы уже не сможете. Придётся изучать документацию, писать дополнительный код для расширения.
Насчёт обучения верстальщиков… Тоже весьма и весьма спорное утверждение. Сильной разницы между кодом на PHP там и нет, и там и там используются всякие циклы, методы. А список всяких функций и модификаторов придётся учить в любом случае. Легкая миграция шаблонов? Это вообще что такое?) И зачем оно нужно?) Куда их мигрировать из приложения?
На тему скорости генерации шаблонов… Как-то, в самом начале разработки одного из проектов, мы размышляли о том, следует ли использовать Smarty в новом проекте, или же писать всё на стандартных PHP шаблонах. Фреймворком мы тогда выбрали Кохану. И я решил на практике посмотреть разницу в скорости генерации страницы фреймворком вместе с шаблонизатором, и на основе нативных PHP шаблонов. Создал две одинаковых страницы, которые генерировали какой-то контент, одна на смарти — другая на нативном php-коде. В итоге, смарти генерировал ту же страницу в несколько десятков раз медленнее. Это не было заметно на глаз, но профайлер коханы ясно показал огромный разрыв в скорости генерации страниц.
В итоге, с тех пор я полностью отказался от данного шаблонизатора и до сих пор считаю это верным выбором. В завершение комментария, приведу вам кусок из текущего проекта на Laravel, в котором я использую их шаблонизатор Blade — но его и полноценным шаблонизатором-то назвать трудно… Это скорее небольшое расширение основного кода на PHP. Его практически не видно в проекте, и при этом в шаблонах можно легко использовать всю мощь PHP, так, как-будто мы и не используем никаких шаблонизаторов в своём коде. И в данный момент я считаю, что данный вариант — это лучший компромисс, который может быть сделан на PHP.
Посмотрите на код страницы редактирования пользователей с использованием Blade: paste.ofcode.org/nLijEzhiWC4t6KtYnYazG5
Разве настолько оно плохо выглядит, по сравнению с кодом на Смарти? Да разницы практически нет…
Ну так зачем нужны эти тяжелые шаблонизаторы, когда и без них всё прекрасно работает?)
Легкая миграция шаблонов? Это вообще что такое?) И зачем оно нужно?) Куда их мигрировать из приложения?Существуют другие ЯП, помимо PHP, и иногда возникает необходимость переписать часть на них.
Так вот, если я захочу переписать с PHP на Ruby/Python, то с вменяемым шаблонизатором правка существующих шаблонов будет минимальна. Это перспектива.
А вот суровая жизнь: на нескольких проектах у нас используются одновременно php, java, python, и при этом шаблоны у них общие. Потребуется завтра нода, руби или любой другой язык, в шаблоны даже лезть не придется.
Ну так зачем нужны эти тяжелые шаблонизаторы, когда и без них всё прекрасно работает?)Затем же за чем нужны фрэймворки.
Затем же за чем нужны ORM.
Затем же за чем нужнo PDO.
Без всех перечисленных тоже можно обойтись (в некоторых случаях даже стоит обойтись) и прекрасно работать.
Smarty далеко не единственный и не лучший шаблонизатор.
Если вы строите свои суждения на единственном печальном опыте — это ваше право, но картинку не расскрывает.
Дальнейший разговор невозможен, так как кроме smarty вы ничего другого не видали.
Фреймворки, ORM, PDO — без них реально плохо живётся, мой друг. Что касается тяжелых шаблонизаторов для PHP — то без них живётся даже проще и легче, как по мне. И почему дальнейший разговор невозможен? Аргументируйте, приводите примеры, гните свою линию, если вы действительно правы. Докажите, что есть более удобные шаблонизаторы в этом мире, лишенные описанных мною проблем)
Я лично увидел из ваших доводов пользу в шаблонизаторах в тех ситуациях, когда разработку проекта ведут странные ребята, пишущие проект сразу на нескольких языках… По-моему, это как-то странно и нетипично для остального мира. Почему не писать весь проект на чистом PHP? Тем более, что PHP сейчас сильно развился, и я не вижу смысла писать какие-то куски приложения к нему на яве и питоне, или предполагать подобное использование в будущем проекта, и только из-за этого внедрять в него тяжелый шаблонизатор. Опять же, повторюсь: PHP сейчас прекрасно справляется с созданием веб-приложений без сторонних шаблонизаторов, а также без явы и питона.
Вообще, по-моему, Smarty и ему подобные шаблонизаторы действительно полезны в тех архитектурах, которые не были основаны на паттерне MVC, и, по сути, он просто реализует в них функционал представления. Но в современных PHP-фреймворках это ведь уже реализовано…
Я лично увидел из ваших доводов пользу в шаблонизаторах в тех ситуациях, когда разработку проекта ведут странные ребята, пишущие проект сразу на нескольких языках… По-моему, это как-то странно и нетипично для остального мира. Почему не писать весь проект на чистом PHP? Тем более, что PHP сейчас сильно развился, и я не вижу смысла писать какие-то куски приложения к нему на яве и питоне, или предполагать подобное использование в будущем проекта, и только из-за этого внедрять в него тяжелый шаблонизатор. Опять же, повторюсь: PHP сейчас прекрасно справляется с созданием веб-приложений без сторонних шаблонизаторов, а также без явы и питона.
Вообще, по-моему, Smarty и ему подобные шаблонизаторы действительно полезны в тех архитектурах, которые не были основаны на паттерне MVC, и, по сути, он просто реализует в них функционал представления. Но в современных PHP-фреймворках это ведь уже реализовано…
Вы смешали теплое с мягким и слишком зациклены на слове «тяжелый».
Приведенный вами выше Blade — отнюдь не plain PHP, а шаблонизатор.
Что проще/нагляднее/читаемей:
По-моему выбор очевиден. И меня совершенно не парит, что в PHP версии Х вдруг выпилят short tags или отключат их по дефолту.
В контексте MVC, шаблонизатор как раз разделяет представление от данных: вы можете манипулировать данными, но не можете их изменять. Соответственно, меньше шансов выстрелить себе в коленку. И по хорошему, шаблонизатор не должен давать выполнять произвольный код в шаблоне. Соответственно, шансов выстрелить себе в коленку еще меньше.
Как бонус более удобный рефакторинг: можно как угодно переименовать переменные в контроллере не опасаясь что сломается что-то в шаблоне.
Теперь про производительность: разумеется она будет ниже, чем у plain PHP, поскольку добавляется дополнительная абстракция.
Шаблонизаторы (если специально их не попросить) парсят шаблоны только один раз и сохраняют их на диск в виде plain PHP-файлов, которые затем постоянно используются. Каждый шаблонизатор справляется с данной задачей по разному.
Но в абсолютных цифрах — эта разница равна экономии на спичках и может приниматься во внимание только если у вас либо совсем бедовый хостинг, либо супер-пупер-мега-хайлоад и вы бодаетесь за каждую наносекунду.
У меня где-то был тест 5 или 6 различных шаблонизаторов, если найду, то поделюсь.
Приведенный вами выше Blade — отнюдь не plain PHP, а шаблонизатор.
Что проще/нагляднее/читаемей:
<?php if ($items) {
foreach ($items as $item) { ?>
<li><?= strtoupper ($item) ?></li>
<?php }} else { ?>
Записей нет
<?php } ?>
// тоже самое, альтернативный синтаксис
<?php if ($items):
foreach ($items as $item): ?>
<li><?= strtoupper ($item) ?></li>
<?php endforeach;
else: ?>
Записей нет
<?php endif; ?>
{% for item in items %}
<li>{{ item|upper }}</li>
{% else %}
Записей нет
{% endfor %}
По-моему выбор очевиден. И меня совершенно не парит, что в PHP версии Х вдруг выпилят short tags или отключат их по дефолту.
Вообще, по-моему, Smarty и ему подобные шаблонизаторы действительно полезны в тех архитектурах, которые не были основаны на паттерне MVC, и, по сути, он просто реализует в них функционал представления. Но в современных PHP-фреймворках это ведь уже реализовано…Современные PHP-фреймворки предлагают использовать шаблонизаторы, а не plain PHP.
В контексте MVC, шаблонизатор как раз разделяет представление от данных: вы можете манипулировать данными, но не можете их изменять. Соответственно, меньше шансов выстрелить себе в коленку. И по хорошему, шаблонизатор не должен давать выполнять произвольный код в шаблоне. Соответственно, шансов выстрелить себе в коленку еще меньше.
Как бонус более удобный рефакторинг: можно как угодно переименовать переменные в контроллере не опасаясь что сломается что-то в шаблоне.
Теперь про производительность: разумеется она будет ниже, чем у plain PHP, поскольку добавляется дополнительная абстракция.
Шаблонизаторы (если специально их не попросить) парсят шаблоны только один раз и сохраняют их на диск в виде plain PHP-файлов, которые затем постоянно используются. Каждый шаблонизатор справляется с данной задачей по разному.
Но в абсолютных цифрах — эта разница равна экономии на спичках и может приниматься во внимание только если у вас либо совсем бедовый хостинг, либо супер-пупер-мега-хайлоад и вы бодаетесь за каждую наносекунду.
У меня где-то был тест 5 или 6 различных шаблонизаторов, если найду, то поделюсь.
Спасибо за ваши доводы. Да, я согласен, что шаблонизаторы полезны, но я склоняюсь в сторону чего-то вроде Блейда на ларавеле, лёгкого и непринуждённого.
А так, я вел разработку нескольких проектов на Кохане, и мы использовали там чистый php. И проекты эти были отнюдь не самые маленькие.
И сколько бы шаблонов мы не создавали, меня никогда особо не волновал вопрос красоты, вполне можно потерпеть и стандартный синтаксис php, это не самое страшное. А вот отзывчивость этих проектов, благодаря отсутствию лишних прослоек, реально хороша) даже без какого-либо кеширования, последний из них сейчас без каких-либо запинок держит около пяти тысяч уникальных посетителей в сутки. Конечно, это не миллионы, но ведь неплохой показатель нормальной архитектуры приложения?
Поэтому, я лично всё же склоняюсь в сторону небольшого дискомфорта от шаблонов на чистом php, но благодаря этому получаю скорость и отсутствие лишних прослоек в цикле обработки запросов сервером.
И переводить какой-либо проект на другую платформу… Это конечно интересно — всегда иметь под рукой такую возможность, но на практике я ещё ни разу не сталкивался с острой необходимостью в подобном.
А так, я вел разработку нескольких проектов на Кохане, и мы использовали там чистый php. И проекты эти были отнюдь не самые маленькие.
И сколько бы шаблонов мы не создавали, меня никогда особо не волновал вопрос красоты, вполне можно потерпеть и стандартный синтаксис php, это не самое страшное. А вот отзывчивость этих проектов, благодаря отсутствию лишних прослоек, реально хороша) даже без какого-либо кеширования, последний из них сейчас без каких-либо запинок держит около пяти тысяч уникальных посетителей в сутки. Конечно, это не миллионы, но ведь неплохой показатель нормальной архитектуры приложения?
Поэтому, я лично всё же склоняюсь в сторону небольшого дискомфорта от шаблонов на чистом php, но благодаря этому получаю скорость и отсутствие лишних прослоек в цикле обработки запросов сервером.
И переводить какой-либо проект на другую платформу… Это конечно интересно — всегда иметь под рукой такую возможность, но на практике я ещё ни разу не сталкивался с острой необходимостью в подобном.
Как вы можете судить об отзывчивости, если кроме смарти/блейда ничего не пробовали?
Как на отзывчивости скажется «рендеринг» страницы за 0.002 с (чистый PHP) или 0.02 с (не самый быстрый шаблонизатор)?
Вы понимаете, что в процессе построения страницы обработка шаблона — самая быстрая часть, и основное время будет потрачено на другие задачи?
Как на отзывчивости скажется «рендеринг» страницы за 0.002 с (чистый PHP) или 0.02 с (не самый быстрый шаблонизатор)?
Вы понимаете, что в процессе построения страницы обработка шаблона — самая быстрая часть, и основное время будет потрачено на другие задачи?
Какая разница, пробовал я другие шаблонизаторы или нет?) Они ведь все работают по одному принципу, а Смарти — один из самых известных
шаблонизаторов в мире пхп.
Насчет скорости обработки шаблона — это вопрос оптимизации. Это вроде и мелочь, но из таких мелочей и создаётся общая нагрузка.
Если же не думать о подобных мелочах, боюсь, вскоре ваше приложение неожиданно начнет проседать на каких-то запросах. Конкретно сейчас мы обсуждаем область шаблонов, и я, как человек, который заботится об общем качестве приложения, стараюсь оптимизировать его работу на всех его уровнях.
И если я могу увеличить в несколько десятков раз скорость работы одного из уровней приложения, без особых потерь от этого — почему бы это не сделать? Ведь несколько таких мелочей — и вот уже приложение начинает работать намного отзывчивее.
шаблонизаторов в мире пхп.
Насчет скорости обработки шаблона — это вопрос оптимизации. Это вроде и мелочь, но из таких мелочей и создаётся общая нагрузка.
Если же не думать о подобных мелочах, боюсь, вскоре ваше приложение неожиданно начнет проседать на каких-то запросах. Конкретно сейчас мы обсуждаем область шаблонов, и я, как человек, который заботится об общем качестве приложения, стараюсь оптимизировать его работу на всех его уровнях.
И если я могу увеличить в несколько десятков раз скорость работы одного из уровней приложения, без особых потерь от этого — почему бы это не сделать? Ведь несколько таких мелочей — и вот уже приложение начинает работать намного отзывчивее.
Какая разница, пробовал я другие шаблонизаторы или нет?)Потому что вы зациклены на «шаблонизаторы тяжелые».
Насчет скорости обработки шаблона — это вопрос оптимизации.Вам сюда.
И если я могу увеличить в несколько десятков раз скорость работы одного из уровней приложения, без особых потерь от этого — почему бы это не сделать?Уж не знаю где вы насчитали несколько десятков между 0.002 и 0.02.
Какие будут отговорки, если я вам покажу шаблонизатор, который в сравнении с 0.002 голого PHP будет показывать 0.006?
Опять про оптимизацию расскажете?
Большое спасибо за интересный сайт) прочитал его главы. Но так ли он относится к обсуждаемой нами сейчас теме? Там обсуждается тема оптимизации уже созданного приложения. И советы там сводятся к тому, что не надо болеть стремлением оптимизировать всё подряд и тратить на это кучу своего времени.
Мы же сейчас обсуждаем общую архитектуру приложения, и я стремлюсь создать продуманную архитектуру, изначально имеющую как можно меньше недостатков. Думаю, любой опытный программист скажет вам, что потратить время на размышление об архитектуре будущего приложения всегда полезно, если даже не обязательно. И данный процесс никак не связан с темой зацикливания на оптимизации, о которой говорит Карлос Буэно. По сути, это два разных этапа в цикле разработки приложения, не сваливайте всё в одну кучу)
И скорость работы шаблонизатора — это только один из множества факторов, которые побудили меня отказаться от него. Есть еще целая куча других проблем, которые я описал в одном из своих первых комментариев: habrahabr.ru/post/247495#comment_8215387
Насчёт нескольких десятков между 0.002 и 0.02… Откуда вы вообще взяли эти цифры?) У меня могут быть совсем другие, я уже говорил о том, что провёл как-то свои тесты и увидел большую разницу. Да и снова повторяю: вопрос у нас стоит не только в скорости, это лишь один из факторов. Мы сейчас говорим об общей архитектуре приложения и о том, насколько может быть полезно добавлять в него дополнительный шаблонизатор.
Мы же сейчас обсуждаем общую архитектуру приложения, и я стремлюсь создать продуманную архитектуру, изначально имеющую как можно меньше недостатков. Думаю, любой опытный программист скажет вам, что потратить время на размышление об архитектуре будущего приложения всегда полезно, если даже не обязательно. И данный процесс никак не связан с темой зацикливания на оптимизации, о которой говорит Карлос Буэно. По сути, это два разных этапа в цикле разработки приложения, не сваливайте всё в одну кучу)
И скорость работы шаблонизатора — это только один из множества факторов, которые побудили меня отказаться от него. Есть еще целая куча других проблем, которые я описал в одном из своих первых комментариев: habrahabr.ru/post/247495#comment_8215387
Насчёт нескольких десятков между 0.002 и 0.02… Откуда вы вообще взяли эти цифры?) У меня могут быть совсем другие, я уже говорил о том, что провёл как-то свои тесты и увидел большую разницу. Да и снова повторяю: вопрос у нас стоит не только в скорости, это лишь один из факторов. Мы сейчас говорим об общей архитектуре приложения и о том, насколько может быть полезно добавлять в него дополнительный шаблонизатор.
Откуда вы вообще взяли эти цифры?)С тестов.
Мы сейчас говорим об общей архитектуре приложения и о том, насколько может быть полезно добавлять в него дополнительный шаблонизатор.Это вы об этом говорите, я лишь комментирую ваше заявление:
PHP уже изначально прекрасно приспособлен к генерации html-кода, и не так уж ему и нужны какие-то дополнительные шаблонизаторы.
При этом сами демонстрируете пример с использованием шаблонизатора.
Я уже говорил о том, что лично вёл разработку нескольких проектов, в которых не использовались никакие шаблонизаторы, и был очень доволен результатами. Пара из этих проектов работают и по сей день, а один из них я даже продолжаю развивать, и до сих пор не увидел каких-либо особых проблем из-за того, что везде там используется чистый php в представлениях.
Что касается Блейда — то он действительно взял меня своей лаконичностью и прозрачностью, и он отличается в своём подходе от Смарти и Твига тем, что позволяет использовать в представлениях любой свой PHP-код. По сути, он лишь чуть расширяет основной PHP-функционал, не мешая основным подходам разработки представлений. И он настолько прост в работе, что я даже не замечаю его) Если говорить о таких лёгких и незаметных шаблонизаторах, то я полностью за их использование) И я уже писал об этом в своих ранних комментариях…
Что касается Блейда — то он действительно взял меня своей лаконичностью и прозрачностью, и он отличается в своём подходе от Смарти и Твига тем, что позволяет использовать в представлениях любой свой PHP-код. По сути, он лишь чуть расширяет основной PHP-функционал, не мешая основным подходам разработки представлений. И он настолько прост в работе, что я даже не замечаю его) Если говорить о таких лёгких и незаметных шаблонизаторах, то я полностью за их использование) И я уже писал об этом в своих ранних комментариях…
он отличается в своём подходе от Смарти и Твига тем, что позволяет использовать в представлениях любой свой PHP-код1. Использование кода в представлении — прекрасный способ отстрелить себе или коллеге яйца. Не обязательно так и произойдет, но вероятность резко возрастает.
2. Могу вас огорчить: и Смарти и Твиг позволяют выполнять кастомный код (непосредственно в шаблоне и/или через хэлперы/экстеншены). С остальными шаблонизаторами история такая же.
лично вёл разработку нескольких проектов, в которых не использовались никакие шаблонизаторы, и был очень доволен результатамиМожно не пользоваться фреймворками и прочими ништяками и также быть очень довольным. О чем разговор?
Можно еще колоться кактусом, вставать на грабли, плевать на устоявшиеся (не только в PHP-мире) best practices. И все ради того, чтоб страница была отдана клиенту за 3с, а не за 3.05с или, о боже мой, за 3.1с. И быть довольным.
Я знаю немало таких довольных людей. И глядя на них понимаю почему только ленивый не поносит PHP.
Если честно, с вами уже скучно вести беседу. Вы, кажется, вообще ничего не прочитали толком из того, что я написал. Каждый раз я пишу вам что-то, и каждый раз вы в ответ мне отвечаете теми словами, которые я уже писал ранее. Это уже похоже на бесконечный цикл какой-то…
Закончу нашу бедесу примером шаблона из проекта на Кохане, в котором всё написано на чистом PHP:
paste.ofcode.org/N39JSygJq7rpEJXKWCNGNT
Можете упираться сколько хотите, но мне реально нравится такой подход к разработке. Он практичен и удобен, он не стреляет ни в колено, ни в яйца. И мне реально плевать на чьи-либо «best practices» в тех ситуациях, когда код, противоречащий им, не страдает, однако, от проблем безопасности, тормозов и прекрасно делает своё дело.
Всего хорошего вам, и пусть Всевышний сделает благом для вас вашу жизнь) до свидания)
Закончу нашу бедесу примером шаблона из проекта на Кохане, в котором всё написано на чистом PHP:
paste.ofcode.org/N39JSygJq7rpEJXKWCNGNT
Можете упираться сколько хотите, но мне реально нравится такой подход к разработке. Он практичен и удобен, он не стреляет ни в колено, ни в яйца. И мне реально плевать на чьи-либо «best practices» в тех ситуациях, когда код, противоречащий им, не страдает, однако, от проблем безопасности, тормозов и прекрасно делает своё дело.
Всего хорошего вам, и пусть Всевышний сделает благом для вас вашу жизнь) до свидания)
Не холивара ради, а повышения образованности для. А чем поможет использование Smarty при переезде, скажем, с PHP на Python? Smarty же вроде чисто PHPшный шаблонизатор или есть полные аналоги для других ЯП?
plain PHP:
Smarty:
Django:
Какой по вашему мнению вариант из первых двух проще трансформировать в третий?
Особенно человеку, незнакомому с PHP?
Учитывая что приведен лишь фрагмент шаблона?
Это простой пример и я нигде не говорил о Smarty (наоборот, считаю его отстойным).
<?php if ($items) {
foreach ($items as $item) { ?>
<li><?= strtoupper ($item) ?></li>
<?php }} else { ?>
Записей нет
<?php } ?>
Smarty:
{foreach $items as $item}
<li>{$item|capitalize}</li>
{foreachelse}
Записей нет
{/foreach}
Django:
{% for item in items %}
<li>{{ item|upper }}</li>
{% else %}
Записей нет
{% endfor %}
Какой по вашему мнению вариант из первых двух проще трансформировать в третий?
Особенно человеку, незнакомому с PHP?
Учитывая что приведен лишь фрагмент шаблона?
Это простой пример и я нигде не говорил о Smarty (наоборот, считаю его отстойным).
или есть полные аналоги для других ЯП?
Шаблонизаторов много. Например, Twig и h2o имеют Django-подобный синтаксис, который также имеет и рубишный Liquid.
XSLT вообще никак не привязан к ЯП и может быть использован как «кроссплатформенный» шаблонизатор.
PHP
PHP
<?php if ($items) {
foreach ($items as $item) { ?>
<li><?= strtoupper ($item) ?></li>
<?php }} else { ?>
Записей нет
<?php } ?>
PHP
<?php
if ($items) {
foreach ($items as $item)
echo '<li>' , strtoupper ($item) ,'</li>';
} else {
echo 'Записей нет';
} ?>
Это код PHP, а не шаблон.
Я и не утверждал, что это шаблон. Если использать PHP как нативный шаблонизатор, совершенно не обязательно гонять туда-сюда переключение режимов его парсера. И выкалывать клаза читающему. Более того, плейн может быть разным и не менее понятным, чем код некоего шаблонизатора.
То есть вы серьезно считаете оборачивание всего html/css/js (с пареньем мозга как проэскейпать где надо) в echo годным решением?
И как, удобно редактировать html в такой каше?
И читается наверное легко и непренужденно?
И верстальщик отдаст вам шаблон именно в таком виде?
Ну и рефакторить код с такими шаблонами одно удовольствие, верно?
И как, удобно редактировать html в такой каше?
И читается наверное легко и непренужденно?
И верстальщик отдаст вам шаблон именно в таком виде?
Ну и рефакторить код с такими шаблонами одно удовольствие, верно?
Не впадайте в крайности и не приписывайте мне, о что мной не утверждается.
Причем тут js и css вообще для этого есть отдельные файлы.
html может быть редактировать удобно может не удобно, стиль оформления в зависимости участка может меняться, а может не меняться.
Все это «умный» холивар, как табуляция против пробелов. Кому как удобно, тот так и пишет. Чтобы вы больше не нервничали и не придумывали.
Я озвучу свое мнение:
Я считаю, что давно пора вынести работу с шаблонами из php и серверсайда в принципе.
Для этого есть куча удобных JS библиотек от jq,backbone, angular и тп до ExtJs и подобным.
Я возьмусь утверждать, что использование шаблонизатора значительно уменьшает производительность приложнения, нежели использование php как нативного шаблонизатора. При этом я лично ничего не имею против шаблонизов. Если кто-то считает их использование нужным и оправданным это их право и удобство.
Причем тут js и css вообще для этого есть отдельные файлы.
html может быть редактировать удобно может не удобно, стиль оформления в зависимости участка может меняться, а может не меняться.
Все это «умный» холивар, как табуляция против пробелов. Кому как удобно, тот так и пишет. Чтобы вы больше не нервничали и не придумывали.
Я озвучу свое мнение:
Я считаю, что давно пора вынести работу с шаблонами из php и серверсайда в принципе.
Для этого есть куча удобных JS библиотек от jq,backbone, angular и тп до ExtJs и подобным.
Я возьмусь утверждать, что использование шаблонизатора значительно уменьшает производительность приложнения, нежели использование php как нативного шаблонизатора. При этом я лично ничего не имею против шаблонизов. Если кто-то считает их использование нужным и оправданным это их право и удобство.
Причем тут js и css вообще для этого есть отдельные файлы.При том, что они бывают и не в отдельных файлах.
Ну ок, убераем js/css. Вы серьезно считаете оборачивание всего html (с пареньем мозга как проэскейпать где надо) в echo годным решением?
Кому как удобно, тот так и пишет.«Если кому-то удобно говнокодить, пусть говнокодит дальше» — отличный аргумент.
Я считаю, что давно пора вынести работу с шаблонами из php и серверсайда в принципе.Речь о PHP, а не JS.
Для этого есть куча удобных JS библиотек от jq,backbone, angular и тп до ExtJs и подобным.
Я возьмусь утверждать, что использование шаблонизатора значительно уменьшает производительность приложнения, нежели использование php как нативного шаблонизатора.Чем-то подкрепите свое утверждение?
Я вот утверждаю обратное: шаблонизатор уменьшает производительность приложнения незначительно.
И готов/могу это доказывать цифрами.
Давайте не будем заниматься демагогией. Уверяю Вас, говнокодить можно и с шаблонизатором и даже придерживаясь стиля вашего любимого фреймворка. Поэтому наличие/отсутствие шаблонизатора совершенно не признак говнокода.
Нужно исходить из особенностей конкретных проектов.
Есть целый пласт веб ориентированного софта, где практически нет шаблов и использование шаблонизатора там совершенно излишне. С другой стороны есть проекты в которых доступ к оформлению предоставляется пользователям там без шаблонизатора вообще никак.
Будь у вас оыт профилирования PHP кода шаблонизатора в каком нибудь cachegrind, вы бы так не утверждали. Совершенно очевидно, что парсинг шаблона средствами PHP дело накладное. Начиная от памяти на инициализацию парсера, заканчивая временем исполнения. Вы можете даже сослаться на кэш, но нейтив шаблон так же можно кэшировать. Всеравно время валидации кэша сторонним громозким шаблонизатором будет больше. Если мы говорим одинамическом контенте.
Вы можете сослаться, что разница времени исполнения скрипта 0.3 c. (шаблонизатор) против 0.2 (без него) на единичном запуске «приложения в вакуме» роли не играет. На это я вам сразу возражу, натравите на свой скрипт 2000 rps рандомных запросов. Если мы делаем сайт с посещаемостью 3 человека в день, никаких вопросов, мы можем поставить и шаблонизатор шаблонизатора и 2 раза отрендерить шаблон на всякий случай. Иначе, стоит беречь вычислительные мощности, но и в крайности не впадать.
В том то и дело, что речь именно о PHP, если снять с него ответственность за шаблоны всем будет легче. Если конечно это допустимо в конкретном случае.
Выбор инструментов и ответственность лежит на разработчике, а не на нас советчиках.
Альтернатива должна иметь место быть. Прислушиваться к мнениям также стоит, даже если они кажутся глупыми. В них может скрываться потребность разработчика с которой вы еще сталкивались.
Нужно исходить из особенностей конкретных проектов.
Есть целый пласт веб ориентированного софта, где практически нет шаблов и использование шаблонизатора там совершенно излишне. С другой стороны есть проекты в которых доступ к оформлению предоставляется пользователям там без шаблонизатора вообще никак.
Я вот утверждаю обратное: шаблонизатор уменьшает производительность приложнения незначительно.
И готов/могу это доказывать цифрами.
Будь у вас оыт профилирования PHP кода шаблонизатора в каком нибудь cachegrind, вы бы так не утверждали. Совершенно очевидно, что парсинг шаблона средствами PHP дело накладное. Начиная от памяти на инициализацию парсера, заканчивая временем исполнения. Вы можете даже сослаться на кэш, но нейтив шаблон так же можно кэшировать. Всеравно время валидации кэша сторонним громозким шаблонизатором будет больше. Если мы говорим одинамическом контенте.
Вы можете сослаться, что разница времени исполнения скрипта 0.3 c. (шаблонизатор) против 0.2 (без него) на единичном запуске «приложения в вакуме» роли не играет. На это я вам сразу возражу, натравите на свой скрипт 2000 rps рандомных запросов. Если мы делаем сайт с посещаемостью 3 человека в день, никаких вопросов, мы можем поставить и шаблонизатор шаблонизатора и 2 раза отрендерить шаблон на всякий случай. Иначе, стоит беречь вычислительные мощности, но и в крайности не впадать.
Речь о PHP, а не JS.
В том то и дело, что речь именно о PHP, если снять с него ответственность за шаблоны всем будет легче. Если конечно это допустимо в конкретном случае.
Выбор инструментов и ответственность лежит на разработчике, а не на нас советчиках.
Альтернатива должна иметь место быть. Прислушиваться к мнениям также стоит, даже если они кажутся глупыми. В них может скрываться потребность разработчика с которой вы еще сталкивались.
Давайте не будем заниматься демагогией.Без проблем, если и вы сможете от нее отказаться.
Нужно исходить из особенностей конкретных проектов.Конечно нужно.
Разница в том, что практически в любом проекте шаблонизатор будет самым последним «узким» местом или не будет вовсе.
Совершенно очевидно, что парсинг шаблона средствами PHP дело накладное. Начиная от памяти на инициализацию парсера, заканчивая временем исполнения.Конечно очевидно. Также очевидно, что парсинг шаблона — операция одноразовая, после которой он автоматически превращается в plain-php код с разной степенью оверхэда.
Если у вас шаблоны парсятся постоянно, у меня для вас плохие вести.
Будь у вас оыт профилирования PHP кода шаблонизатора в каком нибудь cachegrind, вы бы так не утверждали.
На это я вам сразу возражу, натравите на свой скрипт 2000 rps рандомных запросов.Все это делалось и не раз.
Именно поэтому я и утверждаю, что использование шаблонизаторов оправдано в подавляющем большинстве случаев.
Альтернатива должна иметь место быть. Прислушиваться к мнениям также стоит, даже если они кажутся глупыми. В них может скрываться потребность разработчика с которой вы еще сталкивались.Совершенно верно.
Я — не упоротый олень и далек от мысли: «шаблонизаторы надо использовать в 100 случаях из 100».
Только альтернатива должна быть аргументированной.
«Использую А вместо В, потому что он потребляет на Х меньше памяти и Y процессора, и для меня это критично» — это аргумент.
«Использую А вместо В, потому что он быстрее в 10 раз (1000 микросекунд)» — извините, но в контексте беседы это совершенно не аргумент. «Потому что я так привык и мне так удобно» — тем более.
Ок. Предложите 3-4 шустрых на ваш взгляд шаблонизатора. А я проведу их тестирование относительно плейна. Если Разница окажется не велика принису свои личные извинения, иначе разнесу в статье ваши доводы о 5 копейках. Так будет правильнее.
volt, blitz, xslt на клиенте.
Итого blitz. Первое phalkon, последнее не шаблонизатор php. Ок, остальные возьму популярные. Займёт какое то время думаю недельку.
рукалицо.жпег
volt — без проблем используется вне phalcon.
xslt — для вас откровение, что его можно использовать как шаблонизатор?
volt — без проблем используется вне phalcon.
xslt — для вас откровение, что его можно использовать как шаблонизатор?
Ну затестил я ваш twig все не более, чем предсказуемо разница в 10 раз на одном запуске.
0.0010 без шаблонизатора
0.010 с Twig
(вывод таблицы с 500 строками)
Что на ab выплывает в обработанные запросы клиентов:
13509 против 2198 ( -t10 -c10 10 с теста)
25182 против 4104 ( -t20 -c10 20 с теста)
50000 против 12882 ( -t60 -c10 20 с теста)
Тоесть при максимальной нагрузке сервера в вакуме мы за минуту только из-за шаблонизатора не дообслуживаем > 37 000 клиентских запросов
Это по вашему небольшая разница? Да толку то тут говорить, зря трачу время читая диванную аналитику.
0.0010 без шаблонизатора
0.010 с Twig
(вывод таблицы с 500 строками)
Что на ab выплывает в обработанные запросы клиентов:
13509 против 2198 ( -t10 -c10 10 с теста)
25182 против 4104 ( -t20 -c10 20 с теста)
50000 против 12882 ( -t60 -c10 20 с теста)
Тоесть при максимальной нагрузке сервера в вакуме мы за минуту только из-за шаблонизатора не дообслуживаем > 37 000 клиентских запросов
Это по вашему небольшая разница? Да толку то тут говорить, зря трачу время читая диванную аналитику.
Ну затестил я ваш twig все не более, чем предсказуемо разница в 10 раз на одном запуске.Я предлагал вам тестить twig? o_O
Ох и точно my Fault.
Значит Twig уже в топке. Сейчас посмотрим blitz
Значит Twig уже в топке. Сейчас посмотрим blitz
И так мы имеем 2 «ТРУ» шаблонизатора для избранных, забываем про шаред хостинги и хостинги с отсутствием прав на установку ПО. Расширения наше все, придется для сайта визитки виртуалку клиенту заказать.
Но вот незадача Blitz не захотел компилироваться по 5.6 64bit с похожей проблемой toster.ru/q/17633
Ну да ничего, можно списать на кривизну рук, головы или ног, ведь чтобы удостоиться права использовать чудо инженерии нужно с бубном немного побегать. Не все так страшно, любитель найдется.
Volt 0.0016 s на одном запуске. Всего на 40% медленнее. Как это мало или много. Я бы не сказал, что незнечительно. Признаю, это не так катастрофично, как с Twig. Псле махинаций с установкой модуля phalcon производительность стенда слегка просела, кстати на эти же 40%. Думаю можно подшаманить, чтобы разница сократилась до 30%, но расширение вносит свой вклад в утяжеление PHP.
Volt идет в поставке Phalcon, тесно связан с ним, использовать отдельно нет смысла, зачем нам загруженный в память Phalcon, легче сразу писать на нем, но это не всегда это приемлемо.
Дьявол кроется в деталях. Открываем кэш шаблона Volt
Боже мой что это? Адовъ говнокод! :)
Мы гонялись за собственным хвостом, только нам на шею присел сел лишний пассажир который хочет есть и не дает хозяйничать. Спрашивается зачем баласт? Ах да, чтобы верстальщику было удобно, но вот незадача у меня нет верстальщика исключительно под html. Идти нанимать? Скорее всего мне очень повезло повезло, вокруг люди умеют и программировать и верстать, интересуеются, развиваются.
Вот такая вот занимательная история о потерянном времени исполнения.
PS Жаль, ожидал интересной реализации кэширования шаблонов volt.
Но вот незадача Blitz не захотел компилироваться по 5.6 64bit с похожей проблемой toster.ru/q/17633
Ну да ничего, можно списать на кривизну рук, головы или ног, ведь чтобы удостоиться права использовать чудо инженерии нужно с бубном немного побегать. Не все так страшно, любитель найдется.
Volt 0.0016 s на одном запуске. Всего на 40% медленнее. Как это мало или много. Я бы не сказал, что незнечительно. Признаю, это не так катастрофично, как с Twig. Псле махинаций с установкой модуля phalcon производительность стенда слегка просела, кстати на эти же 40%. Думаю можно подшаманить, чтобы разница сократилась до 30%, но расширение вносит свой вклад в утяжеление PHP.
Volt идет в поставке Phalcon, тесно связан с ним, использовать отдельно нет смысла, зачем нам загруженный в память Phalcon, легче сразу писать на нем, но это не всегда это приемлемо.
Дьявол кроется в деталях. Открываем кэш шаблона Volt
<!DOCTYPE html>
<html>
<head>
<title>My Webpage</title>
</head>
<body>
<h1>My Webpage</h1>
<table>
<?php foreach ($records as $item) { ?>
<tr><td><?php echo $item['id']; ?></td><td> <?php echo $item['name']; ?> </td></tr>
<?php } ?>
</table>
</body>
</html>
Боже мой что это? Адовъ говнокод! :)
Мы гонялись за собственным хвостом, только нам на шею присел сел лишний пассажир который хочет есть и не дает хозяйничать. Спрашивается зачем баласт? Ах да, чтобы верстальщику было удобно, но вот незадача у меня нет верстальщика исключительно под html. Идти нанимать? Скорее всего мне очень повезло повезло, вокруг люди умеют и программировать и верстать, интересуеются, развиваются.
Вот такая вот занимательная история о потерянном времени исполнения.
PS Жаль, ожидал интересной реализации кэширования шаблонов volt.
Дабы не давать повода для продолжения.40% взялось из нагрузочного тестирования.
Открываем кэш шаблона VoltПоздравляю, вы открыли принцип работы шаблонизатора (о которм я неоднократно писал выше).
Боже мой что это? Адовъ говнокод! :)Это код, с которым человеку работать не предстоит.
Остальное комментировать не имеет смысла без цифр и кода.
PS а ведь кто-то сам просил без демагогии.
И чтоб два раза не вставать.
Задача: вывод таблицы с 500 рядами, шаблон с одним инклюдом.
Разница просто убивающая, особенно на втором тесте.
Нам действительно не о чем говорить.
Желаю успехов в натагивании PHP на HTML.
Задача: вывод таблицы с 500 рядами, шаблон с одним инклюдом.
PHP-шаблон
$ ab -t10 -c30 http://127.0.0.1/test/php/index.php
This is ApacheBench, Version 2.3 <$Revision: 1528965 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 127.0.0.1 (be patient)
Completed 5000 requests
Completed 10000 requests
Finished 14019 requests
Server Software: nginx/1.0.15
Server Hostname: 127.0.0.1
Server Port: 80
Document Path: /test/php/index.php
Document Length: 41464 bytes
Concurrency Level: 30
Time taken for tests: 10.001 seconds
Complete requests: 14019
Failed requests: 0
Total transferred: 582994134 bytes
HTML transferred: 581283816 bytes
Requests per second: 1401.76 [#/sec] (mean)
Time per request: 21.402 [ms] (mean)
Time per request: 0.713 [ms] (mean, across all concurrent requests)
Transfer rate: 56927.48 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.1 0 2
Processing: 5 21 1.2 21 48
Waiting: 5 21 1.1 21 43
Total: 5 21 1.2 21 48
Percentage of the requests served within a certain time (ms)
50% 21
66% 21
75% 22
80% 22
90% 22
95% 22
98% 24
99% 24
100% 48 (longest request)
$ ab -n10000 -c30 http://127.0.0.1/test/php/index.php
This is ApacheBench, Version 2.3 <$Revision: 1528965 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 127.0.0.1 (be patient)
Completed 1000 requests
Completed 2000 requests
Completed 3000 requests
Completed 4000 requests
Completed 5000 requests
Completed 6000 requests
Completed 7000 requests
Completed 8000 requests
Completed 9000 requests
Completed 10000 requests
Finished 10000 requests
Server Software: nginx/1.0.15
Server Hostname: 127.0.0.1
Server Port: 80
Document Path: /test/php/index.php
Document Length: 41464 bytes
Concurrency Level: 30
Time taken for tests: 7.147 seconds
Complete requests: 10000
Failed requests: 0
Total transferred: 415860000 bytes
HTML transferred: 414640000 bytes
Requests per second: 1399.17 [#/sec] (mean)
Time per request: 21.441 [ms] (mean)
Time per request: 0.715 [ms] (mean, across all concurrent requests)
Transfer rate: 56822.26 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.1 0 2
Processing: 10 21 1.1 21 47
Waiting: 10 21 1.0 21 46
Total: 10 21 1.0 21 47
Percentage of the requests served within a certain time (ms)
50% 21
66% 21
75% 22
80% 22
90% 22
95% 22
98% 23
99% 24
100% 47 (longest request)
Haanga
$ ab -t10 -c30 http://127.0.0.1/test/haanga/index.php
This is ApacheBench, Version 2.3 <$Revision: 1528965 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 127.0.0.1 (be patient)
Completed 5000 requests
Completed 10000 requests
Finished 13064 requests
Server Software: nginx/1.0.15
Server Hostname: 127.0.0.1
Server Port: 80
Document Path: /test/haanga/index.php
Document Length: 42977 bytes
Concurrency Level: 30
Time taken for tests: 10.000 seconds
Complete requests: 13064
Failed requests: 0
Total transferred: 563088435 bytes
HTML transferred: 561494505 bytes
Requests per second: 1306.39 [#/sec] (mean)
Time per request: 22.964 [ms] (mean)
Time per request: 0.765 [ms] (mean, across all concurrent requests)
Transfer rate: 54988.81 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.1 0 2
Processing: 7 23 1.3 23 52
Waiting: 6 22 1.3 22 49
Total: 7 23 1.3 23 52
Percentage of the requests served within a certain time (ms)
50% 23
66% 23
75% 23
80% 24
90% 24
95% 24
98% 25
99% 26
100% 52 (longest request)
$ ab -n10000 -c30 http://127.0.0.1/test/haanga/index.php
This is ApacheBench, Version 2.3 <$Revision: 1528965 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 127.0.0.1 (be patient)
Completed 1000 requests
Completed 2000 requests
Completed 3000 requests
Completed 4000 requests
Completed 5000 requests
Completed 6000 requests
Completed 7000 requests
Completed 8000 requests
Completed 9000 requests
Completed 10000 requests
Finished 10000 requests
Server Software: nginx/1.0.15
Server Hostname: 127.0.0.1
Server Port: 80
Document Path: /test/haanga/index.php
Document Length: 42977 bytes
Concurrency Level: 30
Time taken for tests: 7.829 seconds
Complete requests: 10000
Failed requests: 0
Total transferred: 430990000 bytes
HTML transferred: 429770000 bytes
Requests per second: 1277.26 [#/sec] (mean)
Time per request: 23.488 [ms] (mean)
Time per request: 0.783 [ms] (mean, across all concurrent requests)
Transfer rate: 53758.44 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.1 0 1
Processing: 6 23 1.3 23 47
Waiting: 6 23 1.3 23 46
Total: 7 23 1.3 23 47
Percentage of the requests served within a certain time (ms)
50% 23
66% 24
75% 24
80% 24
90% 24
95% 25
98% 26
99% 27
100% 47 (longest request)
Разница просто убивающая, особенно на втором тесте.
Нам действительно не о чем говорить.
Желаю успехов в натагивании PHP на HTML.
>> Тоесть при максимальной нагрузке сервера в вакуме мы за минуту только из-за шаблонизатора не дообслуживаем > 37 000 клиентских запросов
>> Расширения наше все, придется для сайта визитки виртуалку клиенту заказать.
Вы определитесь уже, вы делаете визитку или адский хайлоад. Каждой задаче свой инструмент. Кроме того частенько можно кешировать куски html, а то и целые страницы, и нагрузка на шаблонизатор будет сильно меньше. Например, визитка элементарным образом целиком засовывается в html-кеш и отдается веб-сервером напрямую без участия php со скоростью овер 100500 запросов в секунду, есть там шаблонизатор или нет.
>> Расширения наше все, придется для сайта визитки виртуалку клиенту заказать.
Вы определитесь уже, вы делаете визитку или адский хайлоад. Каждой задаче свой инструмент. Кроме того частенько можно кешировать куски html, а то и целые страницы, и нагрузка на шаблонизатор будет сильно меньше. Например, визитка элементарным образом целиком засовывается в html-кеш и отдается веб-сервером напрямую без участия php со скоростью овер 100500 запросов в секунду, есть там шаблонизатор или нет.
Тоесть при максимальной нагрузке сервера в вакуме мы за минуту только из-за шаблонизатора не дообслуживаем > 37 000 клиентских запросовДа там не ясно что и как он тестирует.
Даже на тормознутом смарти не будет такого проседания.
Второе был юмор.
Заявлено: «Кто не использует шаблонизатор тот говнокодер» безотносительно задачи. Попытался убедить человека, что не нужно впадать в крайности. Так же было заявлено, что шаблонизатор незначительно влияет на производительнось, потом правда оказалось, что это должен быть особенный «тру» шаблонизатор на С.
Заявлено: «Кто не использует шаблонизатор тот говнокодер» безотносительно задачи. Попытался убедить человека, что не нужно впадать в крайности. Так же было заявлено, что шаблонизатор незначительно влияет на производительнось, потом правда оказалось, что это должен быть особенный «тру» шаблонизатор на С.
Так же было заявлено, что шаблонизатор незначительно влияет на производительнось, потом правда оказалось, что это должен быть особенный «тру» шаблонизатор на С.Глазки протираем и смотрим на habrahabr.ru/post/247495/?reply_to=8217855#comment_8217671
Haanga написана на чистом PHP.
Прежде всего прошу прощения, что заставил вас ждать и провел тесты всего 3х решений.
И так результаты тестирования на другой машине Php 5.6 + OpCache + nginx +php-fpm за 30с нагрузки
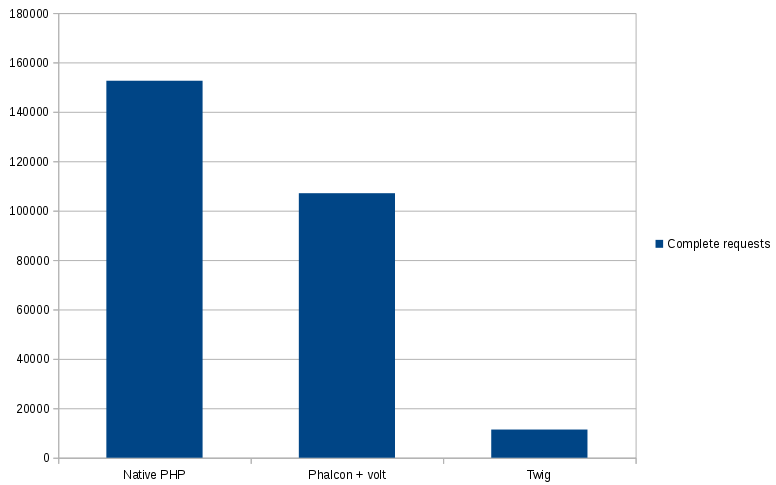
Native PHP 0.0010359287261963 s (1 просмотр)
Phalcon + Volt 0.004223108291626 s(1 просмотр)
Twig 0.022145986557007 s (1 просмотр)
Результаты по количеству обработанных запросов за 30с:
1. Native PHP: 152 586 запросов
2. Phalcone + Volt (152586 — 107060): — 45 526 не успел
3. Twig (152586 — 11407): — 141 179 не успел
Приличные цифры за 30 то секунд.
Всем неверящим предлагаю проверить самостоятельно.
На этом вопрос исчерпан.
И так результаты тестирования на другой машине Php 5.6 + OpCache + nginx +php-fpm за 30с нагрузки

Native PHP 0.0010359287261963 s (1 просмотр)
Профиль AB2
ab2 -t30 -c10 -n200000 -l test.ru:81/test.php
This is ApacheBench, Version 2.3 <$Revision: 1604373 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, www.zeustech.net/
Licensed to The Apache Software Foundation, www.apache.org/
Benchmarking test.ru (be patient)
Completed 20000 requests
Completed 40000 requests
Completed 60000 requests
Completed 80000 requests
Completed 100000 requests
Completed 120000 requests
Completed 140000 requests
Finished 152586 requests
Server Software: nginx/1.7.9
Server Hostname: test.ru
Server Port: 81
Document Path: /test.php
Document Length: Variable
Concurrency Level: 10
Time taken for tests: 30.000 seconds
Complete requests: 152586
Failed requests: 0
Total transferred: 3696740048 bytes
HTML transferred: 3668664224 bytes
Requests per second: 5086.16 [#/sec] (mean)
Time per request: 1.966 [ms] (mean)
Time per request: 0.197 [ms] (mean, across all concurrent requests)
Transfer rate: 120335.61 [Kbytes/sec] received
Connection Times (ms)
min mean[±sd] median max
Connect: 0 0 0.0 0 0
Processing: 1 2 1.2 2 32
Waiting: 1 2 1.2 1 32
Total: 1 2 1.2 2 32
Percentage of the requests served within a certain time (ms)
50% 2
66% 2
75% 2
80% 2
90% 3
95% 4
98% 6
99% 7
100% 32 (longest request)
This is ApacheBench, Version 2.3 <$Revision: 1604373 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, www.zeustech.net/
Licensed to The Apache Software Foundation, www.apache.org/
Benchmarking test.ru (be patient)
Completed 20000 requests
Completed 40000 requests
Completed 60000 requests
Completed 80000 requests
Completed 100000 requests
Completed 120000 requests
Completed 140000 requests
Finished 152586 requests
Server Software: nginx/1.7.9
Server Hostname: test.ru
Server Port: 81
Document Path: /test.php
Document Length: Variable
Concurrency Level: 10
Time taken for tests: 30.000 seconds
Complete requests: 152586
Failed requests: 0
Total transferred: 3696740048 bytes
HTML transferred: 3668664224 bytes
Requests per second: 5086.16 [#/sec] (mean)
Time per request: 1.966 [ms] (mean)
Time per request: 0.197 [ms] (mean, across all concurrent requests)
Transfer rate: 120335.61 [Kbytes/sec] received
Connection Times (ms)
min mean[±sd] median max
Connect: 0 0 0.0 0 0
Processing: 1 2 1.2 2 32
Waiting: 1 2 1.2 1 32
Total: 1 2 1.2 2 32
Percentage of the requests served within a certain time (ms)
50% 2
66% 2
75% 2
80% 2
90% 3
95% 4
98% 6
99% 7
100% 32 (longest request)
код
test.php
Template.php
phpTemplate.php
ob_start();
$t = microtime (true);
$records = array ();
for($i = 0; $i < 500; $i ++) {
$records [] = array ('id' => $i , 'name' => 'Name' , 'value'=>'Value');
}
include_once './Template.php';
$template = new Template();
echo $template->render('./phpTemplate.php' , array('records'=>$records));
echo microtime ( true ) - $t . '.s' . "\n";
echo ob_get_clean();
Template.php
<?php
class Template
{
public $data = array();
public function render($path , $data){
$this->data = $data;
ob_start();
include $path;
return ob_get_clean();
}
public function get($key){
return $this->data[$key];
}
}
phpTemplate.php
<!DOCTYPE html>
<html>
<head>
<title>My Webpage</title>
</head>
<body>
<h1>My Webpage</h1>
<table>
<?php
foreach ( $this->get('records') as $item )
echo '<tr><td>' , $item['id'] , '</td><td>' , $item['name'] , '</td><td>' , $item['value'] , '</td></tr>';
?>
</table>
</body>
</html>
Phalcon + Volt 0.004223108291626 s(1 просмотр)
Профиль AB2
ab2 -t30 -c10 -n200000 -l test.ru:81/testvolt.php
This is ApacheBench, Version 2.3 <$Revision: 1604373 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, www.zeustech.net/
Licensed to The Apache Software Foundation, www.apache.org/
Benchmarking test.ru (be patient)
Completed 20000 requests
Completed 40000 requests
Completed 60000 requests
Completed 80000 requests
Completed 100000 requests
Finished 107060 requests
Server Software: nginx/1.7.9
Server Hostname: test.ru
Server Port: 81
Document Path: /testvolt.php
Document Length: Variable
Concurrency Level: 10
Time taken for tests: 30.000 seconds
Complete requests: 107060
Failed requests: 0
Total transferred: 3990651615 bytes
HTML transferred: 3970952575 bytes
Requests per second: 3568.66 [#/sec] (mean)
Time per request: 2.802 [ms] (mean)
Time per request: 0.280 [ms] (mean, across all concurrent requests)
Transfer rate: 129903.94 [Kbytes/sec] received
Connection Times (ms)
min mean[±sd] median max
Connect: 0 0 0.0 0 0
Processing: 1 3 1.6 2 33
Waiting: 1 3 1.6 2 33
Total: 1 3 1.6 2 33
Percentage of the requests served within a certain time (ms)
50% 2
66% 2
75% 3
80% 3
90% 5
95% 6
98% 8
99% 10
100% 33 (longest request)
This is ApacheBench, Version 2.3 <$Revision: 1604373 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, www.zeustech.net/
Licensed to The Apache Software Foundation, www.apache.org/
Benchmarking test.ru (be patient)
Completed 20000 requests
Completed 40000 requests
Completed 60000 requests
Completed 80000 requests
Completed 100000 requests
Finished 107060 requests
Server Software: nginx/1.7.9
Server Hostname: test.ru
Server Port: 81
Document Path: /testvolt.php
Document Length: Variable
Concurrency Level: 10
Time taken for tests: 30.000 seconds
Complete requests: 107060
Failed requests: 0
Total transferred: 3990651615 bytes
HTML transferred: 3970952575 bytes
Requests per second: 3568.66 [#/sec] (mean)
Time per request: 2.802 [ms] (mean)
Time per request: 0.280 [ms] (mean, across all concurrent requests)
Transfer rate: 129903.94 [Kbytes/sec] received
Connection Times (ms)
min mean[±sd] median max
Connect: 0 0 0.0 0 0
Processing: 1 3 1.6 2 33
Waiting: 1 3 1.6 2 33
Total: 1 3 1.6 2 33
Percentage of the requests served within a certain time (ms)
50% 2
66% 2
75% 3
80% 3
90% 5
95% 6
98% 8
99% 10
100% 33 (longest request)
код
testvolt.php
Controller
Template
<?php
try {
$t = microtime(true);
//Register an autoloader
$loader = new \Phalcon\Loader();
$loader->registerDirs(array(
'./controllers/',
'../app/models/'
))->register();
//Create a DI
$di = new Phalcon\DI\FactoryDefault();
//Setting up the view component
$di->set('view', function(){
$view = new \Phalcon\Mvc\View();
$view->setViewsDir('./volt/');
$view->registerEngines(array(
".phtml" => 'Phalcon\Mvc\View\Engine\Volt'
));
return $view;
});
//Handle the request
$application = new \Phalcon\Mvc\Application($di);
echo $application->handle()->getContent();
echo microtime(true) - $t.'.s';
} catch(\Phalcon\Exception $e) {
echo "PhalconException: ", $e->getMessage();
}
Controller
<?php
class IndexController extends \Phalcon\Mvc\Controller
{
public function indexAction()
{
$records = array ();
for($i = 0; $i < 500; $i ++) {
$records [] = array ('id' => $i , 'name' => 'Name' , 'value'=>'Value');
}
$this->view->setVar("records", $records);
}
}
Template
<!DOCTYPE html>
<html>
<head>
<title>My Webpage</title>
</head>
<body>
<h1>My Webpage</h1>
<table>
{% for item in records %}
<tr><td>{{ item['id'] }}</td><td> {{ item['name'] }} </td> <td> {{ item['value'] }} </td></tr>
{% endfor %}
</table>
</body>
</html>
Twig 0.022145986557007 s (1 просмотр)
Профиль AB2
ab2 -t30 -c10 -n200000 -l test.ru:81/testTwig.php
This is ApacheBench, Version 2.3 <$Revision: 1604373 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, www.zeustech.net/
Licensed to The Apache Software Foundation, www.apache.org/
Benchmarking test.ru (be patient)
Finished 11407 requests
Server Software: nginx/1.7.9
Server Hostname: test.ru
Server Port: 81
Document Path: /testTwig.php
Document Length: Variable
Concurrency Level: 10
Time taken for tests: 30.003 seconds
Complete requests: 11407
Failed requests: 0
Total transferred: 425183302 bytes
HTML transferred: 423084414 bytes
Requests per second: 380.20 [#/sec] (mean)
Time per request: 26.302 [ms] (mean)
Time per request: 2.630 [ms] (mean, across all concurrent requests)
Transfer rate: 13839.37 [Kbytes/sec] received
Connection Times (ms)
min mean[±sd] median max
Connect: 0 0 0.0 0 0
Processing: 11 26 9.8 22 100
Waiting: 11 26 9.8 22 100
Total: 11 26 9.8 22 100
Percentage of the requests served within a certain time (ms)
50% 22
66% 26
75% 30
80% 33
90% 40
95% 46
98% 55
99% 61
100% 100 (longest request)
This is ApacheBench, Version 2.3 <$Revision: 1604373 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, www.zeustech.net/
Licensed to The Apache Software Foundation, www.apache.org/
Benchmarking test.ru (be patient)
Finished 11407 requests
Server Software: nginx/1.7.9
Server Hostname: test.ru
Server Port: 81
Document Path: /testTwig.php
Document Length: Variable
Concurrency Level: 10
Time taken for tests: 30.003 seconds
Complete requests: 11407
Failed requests: 0
Total transferred: 425183302 bytes
HTML transferred: 423084414 bytes
Requests per second: 380.20 [#/sec] (mean)
Time per request: 26.302 [ms] (mean)
Time per request: 2.630 [ms] (mean, across all concurrent requests)
Transfer rate: 13839.37 [Kbytes/sec] received
Connection Times (ms)
min mean[±sd] median max
Connect: 0 0 0.0 0 0
Processing: 11 26 9.8 22 100
Waiting: 11 26 9.8 22 100
Total: 11 26 9.8 22 100
Percentage of the requests served within a certain time (ms)
50% 22
66% 26
75% 30
80% 33
90% 40
95% 46
98% 55
99% 61
100% 100 (longest request)
код
testTwig.php
index.html
<?php
$t = microtime(true);
$records = array ();
for($i = 0; $i < 500; $i ++) {
$records [] = array ('id' => $i , 'name' => 'Name' , 'value'=>'Value');
}
require_once './Twig/lib/Twig/Autoloader.php';
Twig_Autoloader::register();
$loader = new Twig_Loader_Filesystem('./TwigTpl');
$twig = new Twig_Environment($loader, array(
'cache' => './TwigCache',
));
$template = $twig->loadTemplate('index.html');
echo $template->render(array(
'records'=>$records
));
echo microtime(true) - $t.'.s';
index.html
<!DOCTYPE html>
<html>
<head>
<title>My Webpage</title>
</head>
<body>
<h1>My Webpage</h1>
<table>
{% for item in records %}
<tr><td>{{ item.id }}</td><td> {{ item.name }} </td> <td> {{ item.value }} </td></tr>
{% endfor %}
</table>
</body>
</html>
Результаты по количеству обработанных запросов за 30с:
1. Native PHP: 152 586 запросов
2. Phalcone + Volt (152586 — 107060): — 45 526 не успел
3. Twig (152586 — 11407): — 141 179 не успел
Приличные цифры за 30 то секунд.
Всем неверящим предлагаю проверить самостоятельно.
На этом вопрос исчерпан.
А можно еще немного цифр если не сложно. Возьмите ваш реальный нагруженный проект, ну там где вы голый пхп используете. И выполните ab2 индекса к примеру. Потом отключите рендеринг шаблона, оставьте только формирование контекста( то что вы вторым аргументом скармливаете Template). Проведите замер еще раз. И опубликуйте тут, если вас не затруднит. Ну чтобы окончательно закрыть тему.
Это фуфло, а не тест: позднее аргументирую (сейчас вне дома).
Если вы к тому что не нужно впадать в крайности я с вами полностью согласен.
Далеко не всегда рендеринг это проблема. Там где это возможно решает кэш, данные берутся из быстрых хранилищ и шаблоны вовсе не рендерятся. Случаи и проекты бывают разные как и нештатные ситуации.
Если у разработчика голова на плечах, а я уверен у многих местных она на месте, вообще нет нерешимых проблем. А уж если они между собой могут договорится, вообще сила.
Приходилось встречаться с легаси проектами где отсутствовал кэш шаблонов как класс (кэш того, что возвращает Temlate или шаблонизатор) и это был ацкий ад. БЫл случай данные забирались из memcached, а дальша начиналась череда рендеринга (кстати шаблонизатором), соотношение времени исполнения было 10% на днные 90% на шаблоны (очень много шаблонов веселых и разных).
С другой стороны есть проекты где и шаблонов-то как таковых нет, вопрос вовсе не стоит. Об этом мы уже говорили в этой ветке.
Было утверждение, что шаблонизатор незначительно сокращает время обработки, оно опровергнуто. При этом я не призывал повсеместно от чего-то отказываться или использовать только 1 вариант и не вешал ярлыков. Это альтернатива для крикливых троллей комментаторов с чсв > 9000.
Далеко не всегда рендеринг это проблема. Там где это возможно решает кэш, данные берутся из быстрых хранилищ и шаблоны вовсе не рендерятся. Случаи и проекты бывают разные как и нештатные ситуации.
Если у разработчика голова на плечах, а я уверен у многих местных она на месте, вообще нет нерешимых проблем. А уж если они между собой могут договорится, вообще сила.
Приходилось встречаться с легаси проектами где отсутствовал кэш шаблонов как класс (кэш того, что возвращает Temlate или шаблонизатор) и это был ацкий ад. БЫл случай данные забирались из memcached, а дальша начиналась череда рендеринга (кстати шаблонизатором), соотношение времени исполнения было 10% на днные 90% на шаблоны (очень много шаблонов веселых и разных).
С другой стороны есть проекты где и шаблонов-то как таковых нет, вопрос вовсе не стоит. Об этом мы уже говорили в этой ветке.
Было утверждение, что шаблонизатор незначительно сокращает время обработки, оно опровергнуто. При этом я не призывал повсеместно от чего-то отказываться или использовать только 1 вариант и не вешал ярлыков. Это альтернатива для крикливых троллей комментаторов с чсв > 9000.
coh
Вот этим недоразумением под названием тест?
Это альтернатива для крикливых троллей комментаторов с чсв > 9000Не стоит мне приписывать своих фантазий.
Было утверждение, что шаблонизатор незначительно сокращает время обработки, оно опровергнутоОпровергнуто чем?
Вот этим недоразумением под названием тест?
Но вот незадача Blitz не захотел компилироваться по 5.6 64bit
PHP Version 5.6.2-1
System Linux www 3.16.0-4-amd64 #1 SMP Debian 3.16.7-2 (2014-11-06) x86_64
Blitz support enabled, Version 0.8.14
Что я делаю не так?
Смотрите, по нашему опыту Blitz примерно от 10 до 100 раз быстрее Twig'а
И от чистого plain-php или eval отстает на 10-15%. Остановились на нем кстати. Но! Никаких калбеков, инклюдов и т.п. внутри Blitz, только цикло-блоки и условия. Все вложения шаблонов обрабатываются сверху для получения готового большого шаблона и кладутся в кеш
И от чистого plain-php или eval отстает на 10-15%. Остановились на нем кстати. Но! Никаких калбеков, инклюдов и т.п. внутри Blitz, только цикло-блоки и условия. Все вложения шаблонов обрабатываются сверху для получения готового большого шаблона и кладутся в кеш
Вот это вообще тихий ужас. На лурке была хорошая цитата по этому поводу: И не забудьте ударить его головой об клавиатуру ровно столько раз сколько вычисляется по этой формуле: X = E-1, где X — количество ударов об клавиатуру, а E — количество echo используемых в скрипте.
Благодарю за разъяснение.
>> К тому же, они резко усложняют архитектуру приложения
Может быть наоборот?
Может быть наоборот?
Let the holy war begin! Уважаемый автор. Спасибо Вам большое за статью и старание, но пожалуйста — не пишите больше. Из-за таких статей люди потом php-шников презирают. Спасибо за понимание.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Пошаговый алгоритм создания архитектуры PHP-сайта