Комментарии 72
Все эти методы оперируют обычным растром, где каждый пиксель имеет три составляющих цвета. Но вот у 99.9% камер на матрице каждый пиксель имеет всего один светофильтр и собирает только одну составлящую цвета. Это так называемый фильтр Байера. И сначала информацию с баейра интерполируют в растр, а потом растр масштабируют. Имхо гораздо более высокого качества (цвета и деталей) можно было бы добиться, если считать конечную картинку в один проход без промежуточных преобразований. Есть ли какие-то существующие RAW-конверторы, умеющие применять тот же бикубический фильтр напрямую к байеровкому изображению (учитывая цвет фильтров пикселей и расстояние до них от центра результирующего пикселя)?
Для начала объясните зачем ресемплировать RAW?
Вопрос скорее. «что же эти изобретатели фотоаппаратов не додумались до такой простой вещи».
Но зачем? Ведь потом с полученным ресемлированным изображением придется как-то взаимодействовать алгоритму де-байеризаци. Да и сам практический смысл абсолютно не понятен.
Вы не поняли. На выходе я ожидаю получить нормальный растровый tiff или jpeg, а не ресемплированный байер.
Просто мылить байер в растр, потом его ресемплировать, потом шарпить, это как рыбу несколько раз замораживать-размораживать а потом удивляться чего она невкусная. Хочется сразу с байера получать выходной растр нужного размера без промежуточных преобразований. То что это сложно, медленно, требует сбора данных с нескольких рядов ради получения одного цвета — это понятно.
Если вы будите ресайзить картинку до дебайеризации, то потом вам Amaze это таким узорами разрисует — засмотришься.
Мне кажется вы не понимаете сути де-байеризации.
А если вы понимаете — не скажете, где можно посмотреть основные алгоритмы? Есть ли что-нибудь, кроме нескольких функций из dcraw, например, теория, которая за ними стоит, или хотя бы основные идеи?
По ссылкам я вижу только примеры использования. Нет ли каких-нибудь алгоритмов, для которых есть описание работы? Понимаю, что большинство из них — know-how, но ведь хоть что-то, более качественное, чем независимая билинейная интерполяция цветов, могло бы быть открыто?
Посмотрите в этой статье: http://www.int-arch-photogramm-remote-sens-spatial-inf-sci.net/XXXIX-B5/387/2012/isprsarchives-XXXIX-B5-387-2012.pdf. Там есть ссылки на статьи с описанием многих алгоритмов, правда как миниму некоторые из них доступны только по подписке.
Я связан с этими вещами только практической необходимостью: много снимаю и обрабатываю.
И для этого действительно нужно «понимать суть де-байеризации»?
Для меня совершенно неочевидно, что нельзя получить выигрыша, если переход от растра к масштабированному или повёрнутому изображению выполнять за один шаг, более сложным алгоритмом. И чтобы это понять, надо разобраться не только в том, какие алгоритмы есть и как они работают, но и почему они именно такие, какие особенности физики и физиологии в них используются. Тогда можно более или менее приблизиться к сути, и начать искать ответ на поставленный вопрос.
Для меня совершенно неочевидно, что нельзя получить выигрыша, если переход от растра к масштабированному или повёрнутому изображению выполнять за один шаг, более сложным алгоритмом. И чтобы это понять, надо разобраться не только в том, какие алгоритмы есть и как они работают, но и почему они именно такие, какие особенности физики и физиологии в них используются. Тогда можно более или менее приблизиться к сути, и начать искать ответ на поставленный вопрос.
Да. Потому что RAW это не просто картинка. Это сигнал с датчиков матрицы камеры. Каждый пиксель не имеет цвета. Это просто массив цифр. Если его отресайзить все значения тупо перемешаются и алгоритм де-байеризации выдаст не цвет, а подобие кислотного трипа.
Почему я знаю это, а товарищи программисты нет? Вот это интереснее.
Почему я знаю это, а товарищи программисты нет? Вот это интереснее.
Естественно никто не собирается тупо ресайзить RAW а потом вызывать дебайеризацию. Идея другая, и в общем разумная — совместить дебайеризацию с ресайзом.
Потому что при дебайеризации мы пытается повысить разрешение цветовых раналов картинки — восстановить значиние цвета там, где его в RAW не было. Но если затем мы все равно собираемся уменьшить картинку (для публикачии в интернете например), то получается что мы делаем лишнюю работу. Возможно, можно сразу при дебайеризации получить картинку нужного разрешения. Примерно так, как работает метод half в dcraw, только лучше.
Вот возможность такого и хочет изучить Mrrl
Потому что при дебайеризации мы пытается повысить разрешение цветовых раналов картинки — восстановить значиние цвета там, где его в RAW не было. Но если затем мы все равно собираемся уменьшить картинку (для публикачии в интернете например), то получается что мы делаем лишнюю работу. Возможно, можно сразу при дебайеризации получить картинку нужного разрешения. Примерно так, как работает метод half в dcraw, только лучше.
Вот возможность такого и хочет изучить Mrrl
Примерно так. При преобразовании мы хотим получить цвет не в исходных точках растра, а в интерполированных точках, или усреднённых, или свёрнутых с чем-то… Когда мы выполняем преобразование восстановленной картинки, то мы используем компоненты цвета, которые в некоторых точках исходные, а в других — восстановленные (в действительности, это неправда: поскольку при дебайеризации нам пришлось умножать вектор сигналов на матрицу преобразования в линейное цветовое пространство, цвета будут восстановлены всегда). Так может быть, если наша область свёртки захватывает больше 4 датчиков каждого цвета, то можно поменять действия местами — сначала найти значения каждого цвета в пространстве сигналов матрицы, а потом перейти в RGB?
Одна из идей: что если вместо восстановления цвета в каждом пикселе, считать значение в углах пикселей (точках, где сходятся датчики всех трёх цветов)? Раз так не делают, значит, будет плохо, но почему?
Одна из идей: что если вместо восстановления цвета в каждом пикселе, считать значение в углах пикселей (точках, где сходятся датчики всех трёх цветов)? Раз так не делают, значит, будет плохо, но почему?
Ну вообще-то так и делают. Это самый простой, очевидный и в принципе вполне пригодный алгоритм. Практически любое описание процесса дебайризации начинается с него.
И как после его работы будет выглядеть слегка наклонная граница чёрного и белого? На первый взгляд, там должны чередоваться жёлтый и голубой цвета (точнее, FF8000 и 0080FF). Если это так, то вряд ли хоть кто-нибудь назовёт его «вполне пригодным».
А так и будет выглядеть: habrahabr.ru/post/243285/#comment_8137547
Если конечно вы добьётесь такой границы.
Большинство других методов дебайеризации как раз и призваны избавится от этого дефекта.
Базовое описание: www.cambridgeincolour.com/ru/tutorials/camera-sensors.htm
Сравнение различных алгоритмов на практике: www.libraw.su/articles/bayer-moire.html
И вообще рекомендую:
www.libraw.su/
blog.lexa.ru/
Если конечно вы добьётесь такой границы.
Большинство других методов дебайеризации как раз и призваны избавится от этого дефекта.
Базовое описание: www.cambridgeincolour.com/ru/tutorials/camera-sensors.htm
Сравнение различных алгоритмов на практике: www.libraw.su/articles/bayer-moire.html
И вообще рекомендую:
www.libraw.su/
blog.lexa.ru/
Ну почему же не додумались? Кэноны, например, могут писать равы меньшего размера.
> Для начала объясните зачем ресемплировать RAW?
Имея в распоряжении исходные данные, для получения более качественного результата логично оперировать ими, а не суррогатом, полученным на их основе.
А зачем ресемплировать вообще — для получения растрового изображения требуемого размера в пикселях.
Имея в распоряжении исходные данные, для получения более качественного результата логично оперировать ими, а не суррогатом, полученным на их основе.
А зачем ресемплировать вообще — для получения растрового изображения требуемого размера в пикселях.
Меня наверно опять заминусуют, но я таки отвечу:
Проблема в байеровском муаре.
Вот это мишень:
www.libraw.su/sites/libraw.su/files/images/porcupine.png
её сфотографировали и вот что вышло:
www.libraw.su/sites/libraw.su/files/images/porcupine-q0.png
Красота? Это как раз и есть главная проблема демозаика. Как только в кадре появляется ритмично повторяющийся рисунок, шаг которого близок к шагу байровской сетки матрицы вы получаете вот такого рода артефакты.
Вы предлагаете отресеплить RAW и получить шаг сетки гораздо больший. Фактически у вас будет два шага в кадре — оригинальный и шаг который вам подарит ресемплер бесплатно без регистрации и смс. Таким образом вы только увеличите количество объектов которые покроются байеровским муаром.
Проблема в байеровском муаре.
Вот это мишень:
www.libraw.su/sites/libraw.su/files/images/porcupine.png
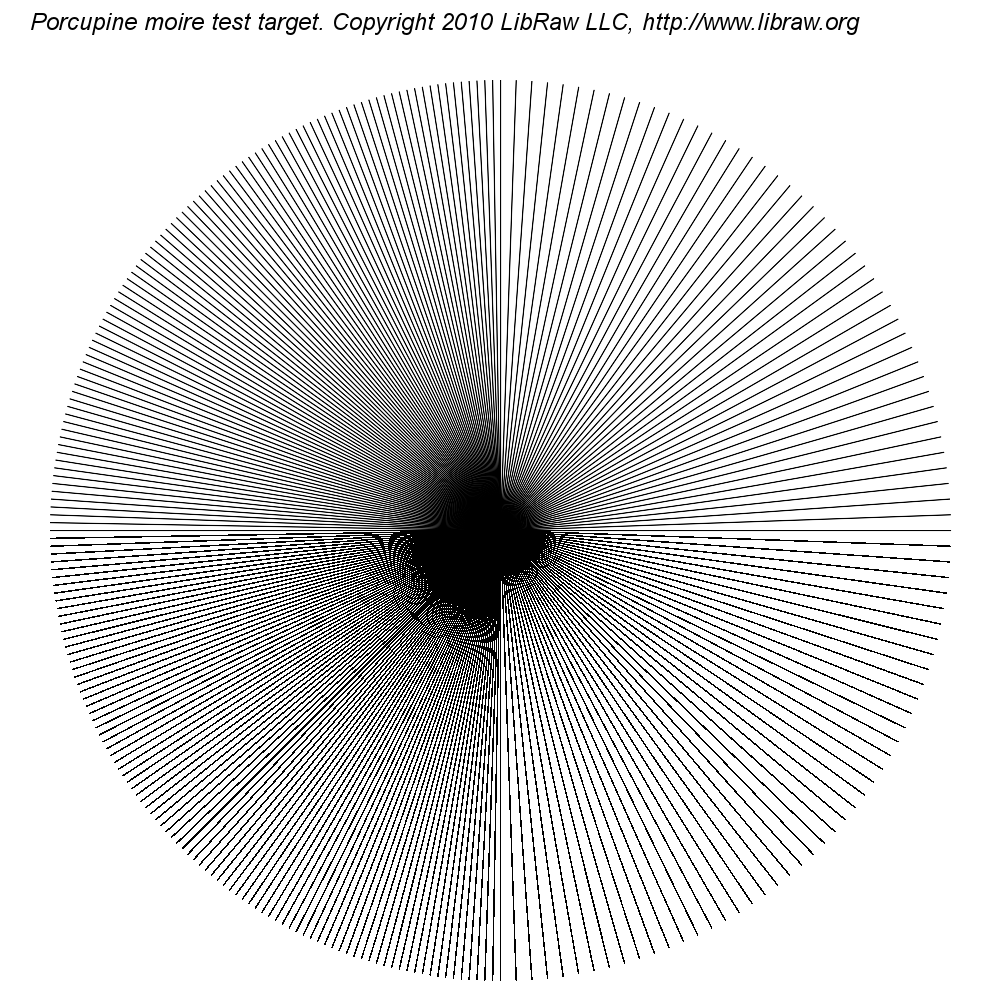{kind=link}
её сфотографировали и вот что вышло:
www.libraw.su/sites/libraw.su/files/images/porcupine-q0.png
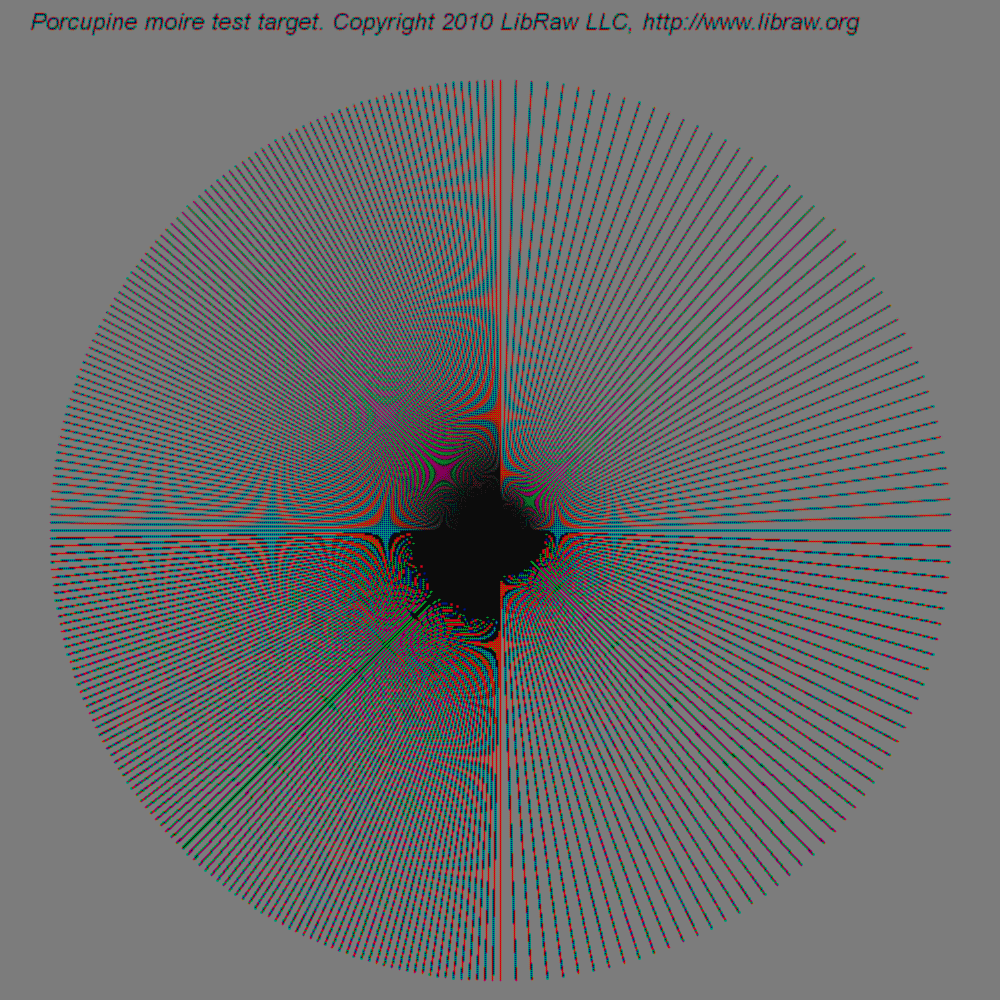{kind=link}
Красота? Это как раз и есть главная проблема демозаика. Как только в кадре появляется ритмично повторяющийся рисунок, шаг которого близок к шагу байровской сетки матрицы вы получаете вот такого рода артефакты.
Вы предлагаете отресеплить RAW и получить шаг сетки гораздо больший. Фактически у вас будет два шага в кадре — оригинальный и шаг который вам подарит ресемплер бесплатно без регистрации и смс. Таким образом вы только увеличите количество объектов которые покроются байеровским муаром.
Тогда надо учитывать порядок расположения сенсоров разных цветов, их размеры(сенсор разного цвета может быть разного размера) и узор расположения на матрице. фото- и видео-матрицы имеют разный узор расположения пикселей и субпикселей.
Спасибо. Познавательно.
К сожалению прочитав статью не могу сказать что с одного раза сформировал в голове четкий алгоритм в каком случае какой способ лучше.
Я бы рекомендовал в конце статьи составить простой список типа: входные условия — рекомендуемый фильтр. По такому списку можно быстро пробежать глазами и выбрать подходящий способ. Если захочется понять почему можно углубиться снова в статью и освежить информацию. Человек так устроен, что прочитав более менее обширную информацию через неделю забудет её (если интенсивно ей не пользуется конечно).
Ещё была бы интересна обзорная таблица где представлены ведущие радакторы и библиотеки для обработки изображений и поддерживаемые ими фильтры.
Спасибо
К сожалению прочитав статью не могу сказать что с одного раза сформировал в голове четкий алгоритм в каком случае какой способ лучше.
Я бы рекомендовал в конце статьи составить простой список типа: входные условия — рекомендуемый фильтр. По такому списку можно быстро пробежать глазами и выбрать подходящий способ. Если захочется понять почему можно углубиться снова в статью и освежить информацию. Человек так устроен, что прочитав более менее обширную информацию через неделю забудет её (если интенсивно ей не пользуется конечно).
Ещё была бы интересна обзорная таблица где представлены ведущие радакторы и библиотеки для обработки изображений и поддерживаемые ими фильтры.
Спасибо
Бикубический или Lanczos плюс шарп по желанию в тренде кучу лет.
Nearest neighbor если нужно показать крайне резкие детали… там листики… как в этой статье у меня:
habrahabr.ru/post/158381/

С бикубическим такого не получится и то… на любителя.
Остальные методы малоактуальные.
Nearest neighbor если нужно показать крайне резкие детали… там листики… как в этой статье у меня:
habrahabr.ru/post/158381/

С бикубическим такого не получится и то… на любителя.
Остальные методы малоактуальные.
Если мы говорим о своем приложении, то в большинстве случаев вы скованы имеющимися у вас библиотеками. Если ваша библиотека умеет только аффинные преобразования, то какой фильтр не используй, получится практически ближайший сосед. Если она умеет свертки, но не умеет суперсемплинг, то научить её можно только суперсемлпингу с округлением границ, используя box фильтр (т.е. фильтр, который дает единицу от -0.5 до 0.5, и ноль на остальном протяжении), но смысла в этом никакого, потому что такая эмуляция суперсемплинга все равно будет работать со скоростью сверток.
Если же у вас действительно есть выбор, то вот список от лучшего и медленного до неплохого, но очень быстрого:
Свертки с фильтром Ланцоша
Свертки с бикубическим фильтром (в ImageMagick он называется catrom)
Суперсемплинг без округления
Суперсемплинг с округлением
При этом нужно учитывать, что если вам нужно не только уменьшение, но и увеличение, то суперсемплинг не годится.
Если же у вас действительно есть выбор, то вот список от лучшего и медленного до неплохого, но очень быстрого:
Свертки с фильтром Ланцоша
Свертки с бикубическим фильтром (в ImageMagick он называется catrom)
Суперсемплинг без округления
Суперсемплинг с округлением
При этом нужно учитывать, что если вам нужно не только уменьшение, но и увеличение, то суперсемплинг не годится.
Бесит, когда мелкие картинки (типа иконок) отображаются сильно увеличенными (×10, ×100 и больше) в виде размазанного облака не пойми чего в программах-смотрелках. Я так понимаю, алгоритмы увеличения в разы должны бы сильно отличаться от алгоритмов увеличения на проценты. Бороться с пикселизацией в лоб имеет смысл только при небольших масштабированиях. На больших масштабах придумывали особые методы депикселизации, как то раз я видел статью про сглаживание пиксель-арта, там чуть ли не очень хитрая промежуточная векторизация проводилась.
тут ниже дали ссылку habrahabr.ru/post/120324/ на ту статью
Свертки с бикубическим фильтром (в ImageMagick он называется catrom)
Это просто один из вариантов коэффициентов Catmull–Rom сплайн
тут такой простой таблицей не обойтись. Скорей всего надо разложить по полочкам такие параметры фильтров как сложность, качество, направление и диапазон масштабирования, время работы. Так чтобы можно было подобрать нужный алгоритм прямо по месту по необходимым параметрам. Ведь ясное дело чем качественней картинка тем дольше работать алгоритм будет, но не всегда нужно качество иногда на первом месте стоит скорость работы(превьюшки создать для предпросмотра).
Это же всё можно на спектрах, теореме отсчётов и фильтрах нижних частот объяснить. Изменение частоты дискретизации, наложение спектров и так далее. Всё было бы наглядно.
Та же билиненая и треугольная функции (на первое место забыли вставить прямоугольную) являются последовательными свёртками: из двух одинаковых прямоугольников получается треугольник, из двух треугольников — кубический сплайн и так далее по посинения. Причём в области спектра это соответствует всё более узкому фильтру нижних частот: пресловутый синус Котельникова умножается на себя N-раз (N=1 — ближайший сосед, N=2 — билинейное, N=3 — кубическое).
Та же билиненая и треугольная функции (на первое место забыли вставить прямоугольную) являются последовательными свёртками: из двух одинаковых прямоугольников получается треугольник, из двух треугольников — кубический сплайн и так далее по посинения. Причём в области спектра это соответствует всё более узкому фильтру нижних частот: пресловутый синус Котельникова умножается на себя N-раз (N=1 — ближайший сосед, N=2 — билинейное, N=3 — кубическое).
Есть довольно примечательная работа по увеличению изображений под авторством А. Сухинова.
Идея его программы состоит в следующем:
Статья с частичным описанием алгоритма.
Идея его программы состоит в следующем:
- Предполагается, что входное изображение было передано в программу после уменьшения путем усреднения
- Программа отыскивает такое увеличенное изображение, которое при уменьшении усреднением пикселей дало бы исходное изображение
Программа дает довольно хорошие результаты:
Оригинал

Увеличение в два раза:


Увеличение в два раза:

Статья с частичным описанием алгоритма.
В вашем комменте изображения идентичны по масштабу. Возможно резкость чуть отличается.
Это результат отображения их движком сайта, который их таки немножко масштабирует. Нужно открывать ссылки и смотреть в отдельных окнах/вкладках:
Исходное
Увеличенное
Исходное
{kind=link}
Увеличенное
{kind=link}
НЛО прилетело и опубликовало эту надпись здесь
Видимо там нечто похожее на полный перебор результирующих пикселей, у меня давно была такая идея и они это всё же сделали.
Можно ещё добавить, что для операции свёртки с большим ядром (больше 8 пикселей, емнип), можно применять преобразование Фурье, тогда сложность зависит только от размеров изображения и не зависит от размера ядра.
Ещё можно рассказать, для чего нужны разные фильтры в последнем случае и что они делают. Недавно как раз читал небольшую заметку на эту тему (на англ.): hirntier.blogspot.ru/2008/12/downscaling-algorithms.html
Ещё можно рассказать, для чего нужны разные фильтры в последнем случае и что они делают. Недавно как раз читал небольшую заметку на эту тему (на англ.): hirntier.blogspot.ru/2008/12/downscaling-algorithms.html
Ещё важная деталь: ресайз следует проводить в линейном цветовом пространстве. Иначе будут артефакты и искажения.
Вы вот это www.4p8.com/eric.brasseur/gamma.html имеете в виду?
Уменьшение изображения

в два раза большинством программ дает результат

хотя корректно было бы так:

Уменьшение изображения

в два раза большинством программ дает результат

хотя корректно было бы так:

Как-то раз сравнивал алгоритмы, которые есть в ImageMagick, Irfanview, ImageJ (штатные и в виде плагинов). Сортировал их по резкости получаемого результата.
Получилось вот такое:
Также делал по ним объективное измерение и строил график:
Получилось вот такое:
Осторожно, картинка шириной 2600 px

Также делал по ним объективное измерение и строил график:
Тоже весьма немаленькая каритнка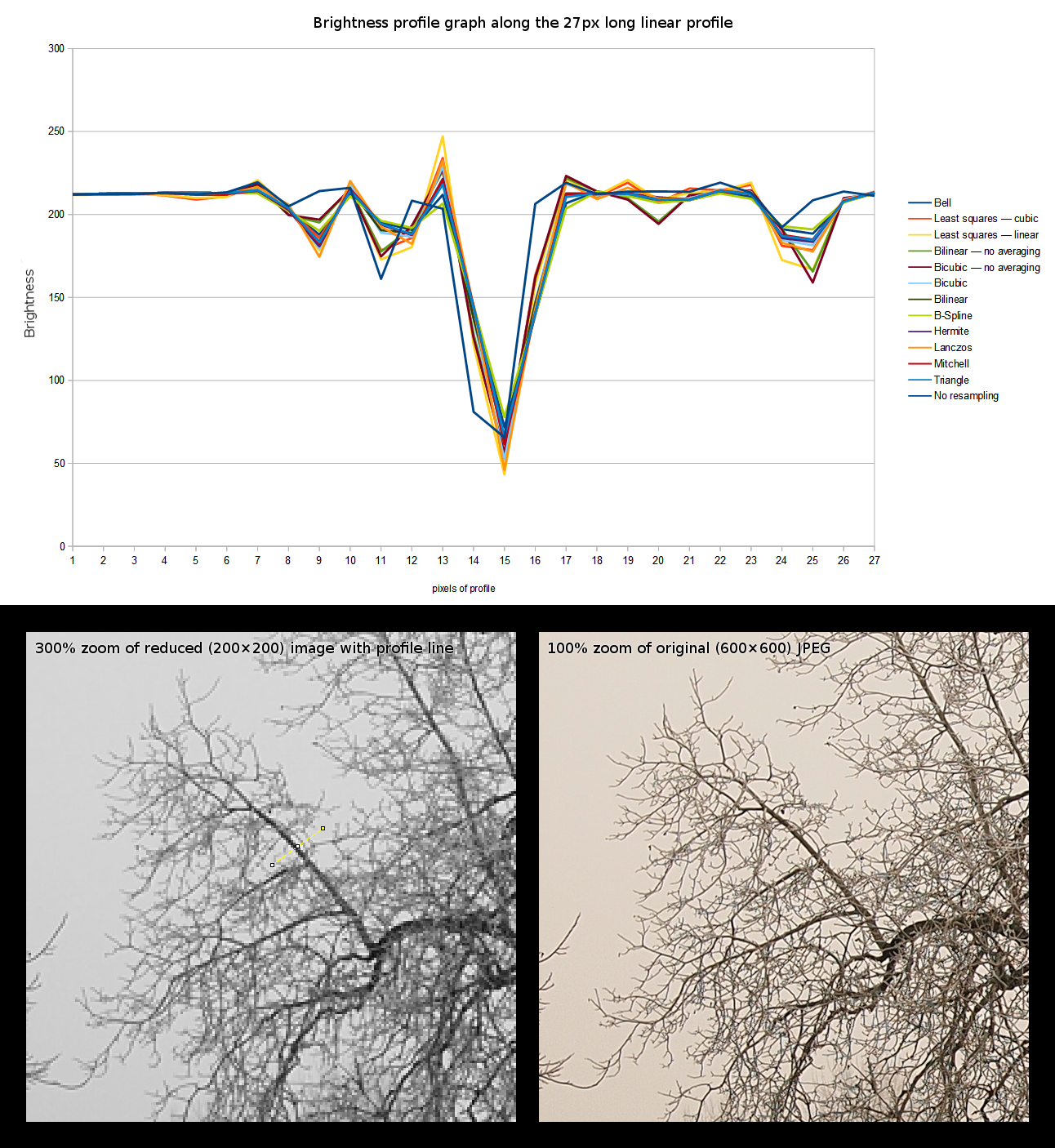

Least squares cubic на мой взгляд даёт самую приятную картинку. Максимально резкую из пластичных.
Где доступен данный алогритм?
Где доступен данный алогритм?
bigwww.epfl.ch/algorithms/ijplugins/resize/ это плагин для ImageJ и Fiji
Алгоритм хороший, но иногда — резковат.
Алгоритм хороший, но иногда — резковат.
Кстати, было бы неплохо всем этим методам выборки указать их названия. Вот XnView, например, предлагает, помимо бикубической, билинейной, интерполяции по соседним и упомянутого тут Lanczos, ещё следующие варианты:
Hermite
Gaussian (тут вроде всё понятно)
Bell
Bspline
Mitchell
Hanning
Было бы круто иметь под рукой список, как посоветовали выше, что есть что и в каком случае удобно применять. Ибо я тут даже затрудняюсь сказать что конкретно каждый из них делает вообще.
Hermite
Gaussian (тут вроде всё понятно)
Bell
Bspline
Mitchell
Hanning
Было бы круто иметь под рукой список, как посоветовали выше, что есть что и в каком случае удобно применять. Ибо я тут даже затрудняюсь сказать что конкретно каждый из них делает вообще.
В документации ImageMagick есть обширнейшая статья по этому поводу.
Все приведенные вами фильтры — свёрточные.
В частности, Hermite, B-spline и Mitchell относятся к кубическим — то есть их весовая функция это кубический полином. Там приводится такая картинка для кубических фильтров:

Gaussian приводит обычно к заметному размытию, и поэтому редко используется.
Bell означает использование колоколообразной функции, но что именно авторы XnView под этим понимают, я затрудняюь сказать.
Другой большой класс функций — это sinc, умноженный на разные "окна".
Hanning использует функцию sinc умноженную на окно Хана.
Lanzos это sinc * растянутый sinc в качестве окна.
В качестве рекомендации там сказано следующее:
В самом ImageMagick в по умолчанию для повышения разрешения используется Mithell, а во всех остальных случаях — Lanzos.
Все приведенные вами фильтры — свёрточные.
В частности, Hermite, B-spline и Mitchell относятся к кубическим — то есть их весовая функция это кубический полином. Там приводится такая картинка для кубических фильтров:
Gaussian приводит обычно к заметному размытию, и поэтому редко используется.
Bell означает использование колоколообразной функции, но что именно авторы XnView под этим понимают, я затрудняюь сказать.
Другой большой класс функций — это sinc, умноженный на разные "окна".
Hanning использует функцию sinc умноженную на окно Хана.
Lanzos это sinc * растянутый sinc в качестве окна.
В качестве рекомендации там сказано следующее:
The Best Filter?Для увеличения изображений рекомендуют Mitchell, для уменьшения подойдет любой их оконных (по умолчанию Lanzos), если есть много мелких «узоров». Если же «узоров» нет, зато есть прямы границы, то лучше Гаусс с повышением резкости либо Mitchell, чтобы избежать сильного звона.
That is something you will need to work out yourself. Often however it depends on what type of image and resizing you are doing.
For enlarging images 'Mitchell' is probably about the best filter you can use, while basically any of the Windowed Filters (default is 'Lanczos') are good for shrinking images, especially when some type of low level pattern is involved. However if you have no patterns, but lots of straight edges (such as GIF transparency), you may be better off using sharpened Gaussian Filter or again a 'Mitchell', so as to avoid strong ringing effects.
The 'Lagrange' filter is also quite good, especially with a larger Filter Support Setting, for shrinking images.
For those interested I recommend you look at the IM User Discussion topic a way to compare image quality after a resize? which basically shows that their is no way of quantitatively determining «The Best Filter», only a qualitative or subjective «Best Filter».
The choice is yours, and choice is a key feature of ImageMagick.
В самом ImageMagick в по умолчанию для повышения разрешения используется Mithell, а во всех остальных случаях — Lanzos.
Есть еще полином- преобразование — дающее алгебраическую точность (сотни лет применяется в картографии). На основе точек исходного изображения Можно составить полином который будет алгебраически приближатся к общей энтропийной функции изображения. Зависит только от количества выделенного времени на вычисление коофициентов полинома.
Но в уилитарных задачах точность приближения нам нужна не абсолюная, а соответствующая потребностям. Влияние пикселей на соседние падает с квадратом расстояния. Больше увеличение — считаем больше коофициентов. Для уменьшения — полином по шести соседям даст точность сильно выше любых других методов интерполяции…
P.S. И вообще почему бы изображение не хранить как набор коофициентов полинома. Можно формировать изображение нужного размера уже при открытии файла.
Но в уилитарных задачах точность приближения нам нужна не абсолюная, а соответствующая потребностям. Влияние пикселей на соседние падает с квадратом расстояния. Больше увеличение — считаем больше коофициентов. Для уменьшения — полином по шести соседям даст точность сильно выше любых других методов интерполяции…
P.S. И вообще почему бы изображение не хранить как набор коофициентов полинома. Можно формировать изображение нужного размера уже при открытии файла.
И вообще почему бы изображение не хранить как набор коофициентов полинома. Можно формировать изображение нужного размера уже при открытии файла
А разве в jpeg не так? Только вместо полинома там косинусы.
Тут важно понимать, что для изображений, как для звука, не имеет значения математическая точность приближения. Имеет значение только насколько хорошо это воспринимается человеком. Аппроксимация полиномами высокой степени даст ужасный «звон», к сожалению, и несмотря на высокий алгебраический порядок приближения, будет выглядеть плохо. Sinc используют не случайно, он максимально сохраняет полосу частот, но тоже подвержен звону.
Собственно, все методы ресайза изображений, это компромисс между резкостью, «звоном» на резких границах и алиасингом на мелких узорах.
Собственно, все методы ресайза изображений, это компромисс между резкостью, «звоном» на резких границах и алиасингом на мелких узорах.
Собственно, у математиков полиномы степени выше 5 также вызывают отвращение по тем же причинам — портят устойчивость, давая неприятные осцилляции: про это явление даже статья на вики есть.
Для апсэмплинга есть ещё фрактальные алгоритмы. Ну и специальные алгоритмы для пиксельной графики.
Спасибо, статья интересная, но всё же слишком «начального» уровня.
Наверное, сравнивать алгоритмы имеет смысл при изменении размера изображения не только в 2 раза, но и на несколько процентов. Во втором случае артефакты вылезут в явном виде и станет очевидной непригодность алгоритмов типа ближайшего соседа. Также интересно было бы сравнить ресайз в 2 раза с помощью Ланцоша с результатом вейвлета 9/7, но я такого сравнения пока нигде не видел.
Представление об алгоритмах на базе свёртки как о медленных, уже не совсем верно. Ресайз на GPU может быть быстрее во много раз по сравнению с CPU. Пример очень быстрого ресайза можно взять тут: CUDA Resize. Интересно посмотреть на время выполнения, но только только для карточек NVIDIA. Ядро Ланцоша там полифазное, т. е. коэффициенты ядра зависят от смещения нового пиксела по отношению к старой сетке.
Вот ещё одно интересное сравнение разных алгоритмов ресайза с картинками.
Наверное, сравнивать алгоритмы имеет смысл при изменении размера изображения не только в 2 раза, но и на несколько процентов. Во втором случае артефакты вылезут в явном виде и станет очевидной непригодность алгоритмов типа ближайшего соседа. Также интересно было бы сравнить ресайз в 2 раза с помощью Ланцоша с результатом вейвлета 9/7, но я такого сравнения пока нигде не видел.
Представление об алгоритмах на базе свёртки как о медленных, уже не совсем верно. Ресайз на GPU может быть быстрее во много раз по сравнению с CPU. Пример очень быстрого ресайза можно взять тут: CUDA Resize. Интересно посмотреть на время выполнения, но только только для карточек NVIDIA. Ядро Ланцоша там полифазное, т. е. коэффициенты ядра зависят от смещения нового пиксела по отношению к старой сетке.
Вот ещё одно интересное сравнение разных алгоритмов ресайза с картинками.
Наверное, сравнивать алгоритмы имеет смысл при изменении размера изображения не только в 2 раза, но и на несколько процентов.
Среди примеров и нет изменения размеров в 2 раза. В начале есть все исходные и конечные разрешения.
Представление об алгоритмах на базе свёртки как о медленных, уже не совсем верно. Ресайз на GPU может быть быстрее во много раз
Дак сложность алгоритмов не меняется от того, что появляются более быстрые процессоры или видеокарты. Если можно быстрее сделать свертки, все остальное тоже можно ускорить. Впрочем, я и не говорил, что свертки какие-то медленные. Просто популярные реализации не слишком оптимизированные. Я например использую реализацию, которая ресайзит 5120×2880 в 2048×1152 с фильтром Ланцоша за 150 ms на одном ядре процессора, т.е. делает это со скоростью 98 мегапикселей в секунду, и хорошо параллелится на все ядра сервера. Скорость GraphicMagick — 12 мегапикселей в секунду. А скорость CUDA Resize — 0 мегапикселей в секунду, потому что из трех ноутбуков у меня дома видеокарта от Nvidia только на одном, но и та ниже минимальной требуемой. И на сервере её либо нет, либо есть, но одна, в отличии от ядер процессора.
Ядро Ланцоша там полифазное, т. е. коэффициенты ядра зависят от смещения нового пиксела по отношению к старой сетке.А бывает по другому? Честно, не встречал.
У меня картинка 5120×2880 преобразуется в 2048×1152 с фильтром Ланцоша за 17 мс на карточке GeForce GTX 570. Причём половину этого времени уходит на передачу данных через PCI-Express в видеокарту и обратно. А смысл не только в ресайзе — так ведь можно делать всю обработку в GPU.
Сервер видимо упомянут был не зря, ресайз нужен часто чтобы изображение отдать клиенту по сети а не вывести на экран.
Тот подход, о котором я писал, как раз и используется для серверных приложений. На сервер ставят карточки с CUDA не для вывода на экран, а для вычислений. Например, для массового ресайза изображений в формате JPEG. Схема примерно такая: декодирование-ресайз-шарп-кодирование. Одна карточка Tesla K1 на сервере может сделать за сутки 15 миллионов ресайзов для изображений формата JPEG с разрешением 3 мегапиксела.
Я написал вам в личку, что вы что-то не отвечаете :)
Можете прислать вот эту картинку, отресайженую за 17мс на видеокарте Ланцошем: www.apple.com/imac-with-retina/5k.html? Хочу внимательно сравнить. Только присылайте не через хабрасторадж, и в png (без потерь). Можно через этот демо-проект.
Можете прислать вот эту картинку, отресайженую за 17мс на видеокарте Ланцошем: www.apple.com/imac-with-retina/5k.html? Хочу внимательно сравнить. Только присылайте не через хабрасторадж, и в png (без потерь). Можно через этот демо-проект.
Помоему, для CUDA есть специальные математические карты расширения, которые вполне можно вставить в сервер и даже не одну при необходимости. Они в любом случае будут выполнять работы подобного рода быстрее чем на процессоре.
Стоимость, правда, может стать камнем преткновения…
И да… одна видеокарта это сотня отдельных ядер, так что это не должно стать принципиальной проблемой разделения её ресурсов между приложениями.
Стоимость, правда, может стать камнем преткновения…
И да… одна видеокарта это сотня отдельных ядер, так что это не должно стать принципиальной проблемой разделения её ресурсов между приложениями.
Я например использую реализацию, которая ресайзит 5120×2880 в 2048×1152 с фильтром Ланцоша за 150 ms на одном ядре процессора, т.е. делает это со скоростью 98 мегапикселей в секунду, и хорошо параллелится на все ядра сервера.
Поделитесь?
Поделюсь. Я не зря везде писал «в текущей версии Pillow», потому что в следующей весь ресайз будет на свертах и в 2+ раза быстрее чем в текущей версии или ImageMagick. Остальное ускорение за счет SSE4, поэтому его не так просто влить в основной репозиторй и скорее всего будет в виде форка.
Как и обещал — первая часть больших изменений в Pillow вышла вчера.
А как же 2xSAI? Я помню, в эмуляторах старых игр он творил чудеса и восстанавливал картинку в апскейле до почти хайрезной.
FastStone Image Viewer предлагает следующие варианты:
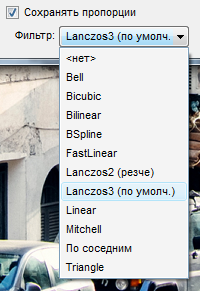
Чем лучше всего пользоваться? Тем что стоит по дефолту?

Чем лучше всего пользоваться? Тем что стоит по дефолту?
А есть ли специальные методы ресайза изображений в формате JPEG без декодирования?
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Ликбез: методы ресайза изображений