Комментарии 47
Всем, кто дочитал до конца, в подарок альбом Kongos — Lunatic
заканчивается следующим слешем(/), знаком вопроса(?) или октоторпом(#)(да-да, «решеточка» зовется именно так=)) или концом URI
Октоторп О_О. Мир никогда не будет прежним…
За статью отдельное спасибо, экскурс в отличия URL от URI более чем познавательный.
BTW, я вижу в описании частей URI что, к примеру, один заканчивается на "?", а другой с этого же "?" начинается. Они что, накладываются друг на друга? Символ "?" входит одновременно в две части URI?
Хм, действительно есть некая двоякость в описании, но вообще, для всех под-компонент, кроме пути, границы указаны исключающим образом, т.е. ни краевые слеши, ни знаки вопроса и т.д. не входят в сами под-компоненты,
т.е. для URI
Попробую как-нибудь перефразировать сейчас то что в статье.
т.е. для URI
http://habrahabr.ru:80/post/232385/?some=val#comment_8495021:http— scheme
habrahabr.ru:80— host
/post/232385/— path
some=val— query
comment_8495021— fragment
Попробую как-нибудь перефразировать сейчас то что в статье.
Путь начинается со слеша(/) и заканчивается знаком вопроса(?), октоторпом(#) или концом URI
Я не помню, как это в RFC, но это значит, что "?", "#" и конец строки указывают, где уже НЕ путь. То есть, ["/", "?#\$"), если можно так выразиться =)
Ну вообще да, т.е. когда я писал у меня не было мыслей о том что оно может быть как-либо двояко воспринято, но вот прецедент.
Когда оканчивается включительно так обычно и пишут «включительно» %)
Когда оканчивается включительно так обычно и пишут «включительно» %)
А вообще, если судить по регулярке, которая описана в RFC, то они в конечном итоге делают разделение как я указал выше.
Описываемые спецсимволы разделяют под-компоненты, но в них не входят, исключение составляет путь, он включает в себя и начальный и конечный слеш.
Описываемые спецсимволы разделяют под-компоненты, но в них не входят, исключение составляет путь, он включает в себя и начальный и конечный слеш.
Сам только недавно узнал про октоторп, но вообще Вики говорит:
иные варианты названия: «решётка», «хеш», «знак номера», «диез» (или «шарп» (англ. sharp), из-за внешнего сходства этих двух символов), «знак фунта»
В избранное) спасибо большое.
Интересно! То есть, хотя разнообразные подключаемые внешние JS-скрипты обычно делают что-то вроде:
url = (is_https?'https://':'http://')+host+path;url = '//'+host+path;Для того чтобы ссылка считалась URI необходимо наличие:
либо scheme+authority+path,
либо sheme+authority,
либо только path.
Глупости какие-то. В абсолютном uri схема обязательна.
The scheme and path components are required, though the path may be
empty (no characters). When authority is present, the path must
either be empty or begin with a slash ("/") character. When
authority is not present, the path cannot begin with two slash
characters ("//"). These restrictions result in five different ABNF
rules for a path (Section 3.3), only one of which will match any
given URI reference.
А вот в относительном URI любые компоненты слева могут быть обрезаны. Так что «только path» — это относительный URI, «только query» и «только fragment» — тоже.
А в том моменте разве шла вообще речь об относительных и абсолютных URI?
Там указаны все комбинации при которых ссылка = URI, про относительность и абсолютность ни слова, про это более чем подробно рассказано в разделе 2.1
Там указаны все комбинации при которых ссылка = URI, про относительность и абсолютность ни слова, про это более чем подробно рассказано в разделе 2.1
В том моменте написаны глупости не соответствующие спецификации.
В URI схема обязательная, всё остальное — нет.
В relative-ref вообще нет ничего обязательного.
URI-reference = URI / relative-ref
URI = scheme ":" hier-part [ "?" query ] [ "#" fragment ]
relative-ref = relative-part [ "?" query ] [ "#" fragment ]
В URI схема обязательная, всё остальное — нет.
В relative-ref вообще нет ничего обязательного.
Т.е. ABNF вы читать не умеете и мне пытаетесь предъявить, что я пишу глупости. Ну тогда поехали.
Что есть
Что есть
То есть, резюмируя получаем следующую ABNF формулу:
То есть всегда обязательны либо
Ссылки сетевого пути в расчет не берутся ибо это специфичный вариант, разряда «исключение из общих правил».
Таким образом, ничего противоречащего спецификации в приведенном вами отрывке статьи нет.
Так кто из нас тут глупости то пишет?
URI-reference = URI / relative-refЧитается как
URI и/или relative-refURI = scheme ":" hier-part [ "?" query ] [ "#" fragment ]Читается как
scheme и ":" и hier-part и/или [ "?" и query ] и/или [ "#" и fragment ]relative-ref = relative-part [ "?" query ] [ "#" fragment ]Читается как
relative-part и/или [ "?" и query ] и/или [ "#" и fragment ]Что есть
hier-part? Это authority + path, но path может быть нулевым, то есть hier-part = authority [ "/" path ], или если так не нравится, то можно не оборачивать в квадратные скобки, но тогда учитывать что отсутствие path это тоже path.Что есть
relative-part? Это "/" path / path, то есть relative-part = ["/"] pathТо есть, резюмируя получаем следующую ABNF формулу:
URI-reference = scheme ":" authority [ "/" path ] [ "?" query ] [ "#" fragment ] / ["/"] path [ "?" query ] [ "#" fragment ]
То есть всегда обязательны либо
scheme ":" authority и любой набор оставшихся компонент и тогда это абсолютный URI, либо любой набор компонент при отсутствующей scheme ":" authority и тогда это относительный URI.Ссылки сетевого пути в расчет не берутся ибо это специфичный вариант, разряда «исключение из общих правил».
Таким образом, ничего противоречащего спецификации в приведенном вами отрывке статьи нет.
Так кто из нас тут глупости то пишет?
Как всё запущено…
Умею и читать, и писать. Писал парсеры на основе BNF. Кроме того мною разработана нотация лишённая основных недостатков BNF.
Не «и/или», а только «или».
… а не то, что вы написали.
И authority и собственно path — опциональны. Разница между «компонент есть, но он пустой» и «компонента нет» — есть только в BNF нотации. Семантической разницы тут нет.
ABNF вы читать не умеете и мне пытаетесь предъявить, что я пишу глупости.
Умею и читать, и писать. Писал парсеры на основе BNF. Кроме того мною разработана нотация лишённая основных недостатков BNF.
Читается как URI и/или relative-ref
Не «и/или», а только «или».
Что есть hier-part?
hier-part = "//" authority path-abempty / path-absolute / path-rootless / path-empty
path-abempty = *( "/" segment )
path-absolute = "/" [ segment-nz *( "/" segment ) ]
path-rootless = segment-nz *( "/" segment )
path-empty = 0<pchar>
… а не то, что вы написали.
И authority и собственно path — опциональны. Разница между «компонент есть, но он пустой» и «компонента нет» — есть только в BNF нотации. Семантической разницы тут нет.
Был дурак, исправился…
Только щас понял что действительно неверно было написано, пост подправил, должно быть так:
Искренние извинения, сказывается недостаток сна (╥_╥)
Только щас понял что действительно неверно было написано, пост подправил, должно быть так:
либо scheme+authority+path,
либо sheme+path,
либо только path.
Искренние извинения, сказывается недостаток сна (╥_╥)
>Кроме того мною разработана нотация лишённая основных недостатков BNF
Не поделитесь? Если сильно непричесано — то хотя бы приватно.
Не поделитесь? Если сильно непричесано — то хотя бы приватно.
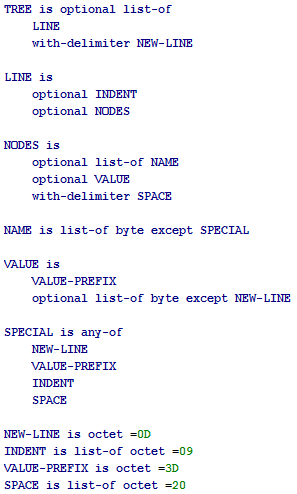
Пара дополнений на которые сам когда-то наткнулся:
1) #fragment НЕ передается в HTTP-запросе на сервер, а используется только самим браузером.
2) существует HTML-тэг base — которым можно переопределить часть authority для всех относительных URI на данной странице. Это иногда может сбивать с толку.
Вдруг кто не знает. :)
P.S. Да, еще я бы акцентировал, что PATH и QUERY регистрозависимы, в отличие от HOST.
1) #fragment НЕ передается в HTTP-запросе на сервер, а используется только самим браузером.
2) существует HTML-тэг base — которым можно переопределить часть authority для всех относительных URI на данной странице. Это иногда может сбивать с толку.
Вдруг кто не знает. :)
P.S. Да, еще я бы акцентировал, что PATH и QUERY регистрозависимы, в отличие от HOST.
Ну, это уже в больше степени браузерные аспекты и особенности HTTP, тем не менее, я планировал отметить эти моменты во второй главе =)
base не authority переопределяет, а base-uri, который по умолчанию равен uri, по которому эта страница получена.
scheme и host регистронезависимы. Остальные компоненты — в зависимости от реализации. Как правило регистрозависимость path зависит от регистрозависимости файловой системы, где ищутся соответствующие файлы.
scheme и host регистронезависимы. Остальные компоненты — в зависимости от реализации. Как правило регистрозависимость path зависит от регистрозависимости файловой системы, где ищутся соответствующие файлы.
> scheme и host регистронезависимы
Да, это есть в статье и с этим никто не спорил вроде бы. А вот про регистрозависимость остальных частей сказано расплывчато, что я и хотел подчеркнуть.
> Остальные компоненты — в зависимости от реализации.
Обсуждается не реализация, которая может (не)соответствовать RFC, а как это задумано, как должно быть. Должно быть — регистрозависимо. Хотя, конечно, в большистве случаев это не нужно и принудительно можно отключить. В том числе могут влиять и ФС, но это всего одна из возможных причин. Никаких файлов может не быть вовсе.
Да, это есть в статье и с этим никто не спорил вроде бы. А вот про регистрозависимость остальных частей сказано расплывчато, что я и хотел подчеркнуть.
> Остальные компоненты — в зависимости от реализации.
Обсуждается не реализация, которая может (не)соответствовать RFC, а как это задумано, как должно быть. Должно быть — регистрозависимо. Хотя, конечно, в большистве случаев это не нужно и принудительно можно отключить. В том числе могут влиять и ФС, но это всего одна из возможных причин. Никаких файлов может не быть вовсе.
С чего вы решили, что «Должно быть — регистрозависимо»?
Они не должны быть регистронезависимы, они могут быть регистронезависимы.
Спецификация допускает использование как верхнего так и нижнего регистров, остальное зависит от:
а) Спецификации схемы, которая может наложить эти ограничения, т.е. у HTTP нормализация URI производится таковым образом, что схема и хост — регистронезависимы, а все остальное нормализуется как регистрозависимое;
б) Реализации, тут уже кто на что способен, как говорится.
Спецификация допускает использование как верхнего так и нижнего регистров, остальное зависит от:
а) Спецификации схемы, которая может наложить эти ограничения, т.е. у HTTP нормализация URI производится таковым образом, что схема и хост — регистронезависимы, а все остальное нормализуется как регистрозависимое;
б) Реализации, тут уже кто на что способен, как говорится.
Согласен, но почти =) Читаем:
6.2.2. Syntax-Based Normalization
…
When a URI uses components of the generic syntax, the component
syntax equivalence rules always apply; namely, that the scheme and
host are case-insensitive and therefore should be normalized to
lowercase. For example, the URI <HTTP://www.EXAMPLE.com/> is
equivalent to <www.example.com>. The other generic syntax
components are assumed to be case-sensitive unless specifically
defined otherwise by the scheme (see Section 6.2.3).
Я это понимаю, так, что компоненты предполагаются регистрозависимыми, ЕСЛИ некоторая схема явно не отменяет это.
Т.е они могут быть регистроНЕзависимыми. Раз уж мы так трепетны к букве RFC :)
6.2.2. Syntax-Based Normalization
…
When a URI uses components of the generic syntax, the component
syntax equivalence rules always apply; namely, that the scheme and
host are case-insensitive and therefore should be normalized to
lowercase. For example, the URI <HTTP://www.EXAMPLE.com/> is
equivalent to <www.example.com>. The other generic syntax
components are assumed to be case-sensitive unless specifically
defined otherwise by the scheme (see Section 6.2.3).
Я это понимаю, так, что компоненты предполагаются регистрозависимыми, ЕСЛИ некоторая схема явно не отменяет это.
Т.е они могут быть регистроНЕзависимыми. Раз уж мы так трепетны к букве RFC :)
P.S. Да, еще я бы акцентировал, что PATH и QUERY регистрозависимы, в отличие от HOST.
scheme — регистронезависим
host — регистронезависим
path — в зависимости от имплементации файловой системы сервера
query — регистрозависим
fragment — в зависимости от браузера
А про зависимость от ФС сервера можно где-то в RFC ссылку? Я понимаю о чем речь, но это особенности реализации конкретных http-серверов, и обсуждаемые RFC тут ни при чем. Повторюсь, например, у меня реализация какого-нибудь REST-API, и там не будет никаких подкаталогов и файлов, иерархия PATH будет чисто виртуальной. И вообще без разницы на какой ФС работает сервер.
Кстати, меня все время мучил вопрос, почему в ссылке на локальный файл три слеша, например, file:///C:/test.htm. Думал в этой статье найти ответ, но нет, пришлось гуглить. Оказывается если в URI опущен host, то подразумевается localhost, то есть ссылка выше будет приравнена к file://localhost/C:/test.htm. Интересно, это особенность только схемы file, или это правило универсально?
Истолковать можно следующим образом:
схема — file
хост — нулевой, т.е. локалхост
путь — /C:/test.htm, т.е. здесь путь отсчитывается от корня, вот и получается 3 слеша
Я это планировал включить в следующую часть.
схема — file
хост — нулевой, т.е. локалхост
путь — /C:/test.htm, т.е. здесь путь отсчитывается от корня, вот и получается 3 слеша
Я это планировал включить в следующую часть.
НЛО прилетело и опубликовало эту надпись здесь
у mailto:, magnet: и иже с ними нет части authority, есть path, query и т.д., но authority нету.
//относится именно к компоненте authority.
Если, например посмотреть RFC по mailto, то можно увидеть вот такой момент:
Таким образом, mailto:addr@gmail.com это всего лишь специфичный для mailto синтаксис аналогичный mailto:?to=addr@gmail.com, т.е. для схемы mailto путь, если он задан, в конечном итоге преобразуется в хедер «to».
//относится именно к компоненте authority.
Если, например посмотреть RFC по mailto, то можно увидеть вот такой момент:
mailto:addr1%2C%20addr2
is equivalent to
mailto:?to=addr1%2C%20addr2
is equivalent to
mailto:addr1?to=addr2
Таким образом, mailto:addr@gmail.com это всего лишь специфичный для mailto синтаксис аналогичный mailto:?to=addr@gmail.com, т.е. для схемы mailto путь, если он задан, в конечном итоге преобразуется в хедер «to».
Недавно узнал что пустой URI это ссылка на текщий документ.
Синтаксис регистрационного имени позволяет использование процентно-кодированных символов, для представления не-ASCII символов
На chrome работает, IE11 не справляется, а в Firefox принудительно добавляет www., так не должно быть?
http://%D0%BF%D1%80%D0%B5%D0%B7%D0%B8%D0%B4%D0%B5%D0%BD%D1%82.%D1%80%D1%84 http://www.президент.рф/
Opera 30.0 открывает
В FF помогает установка browser.fixup.alternate.enabled = false
При этом имя декодирует, но все равно выдает ошибку. После перезагрузки страницы все ок.
Если кому интересно — принцип работы domain guessing
При этом имя декодирует, но все равно выдает ошибку. После перезагрузки страницы все ок.
Если кому интересно — принцип работы domain guessing
для доменов с национальными символами есть такая порнуха как IRI и IDN, там используется punycode шифрование, и к несчастью, это стандарт…
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
URI — сложно о простом (Часть 1)