Комментарии 50
А есть ли возможность PIPE-интерфейса? Я например не пользуюсь саблаймом, но в Geany можно любой кусок кода отправить внешней программе на обработку и ваш плагин можно будет прикрутить в два счёта при условии наличия интерфейса командной строки.
Тоже делал такую штуку, но выравнивает лишь переменные: github.com/scriptum/geany-scripts/blob/master/align-declarations.py
Тоже делал такую штуку, но выравнивает лишь переменные: github.com/scriptum/geany-scripts/blob/master/align-declarations.py
Жуть! За такие «выравнивания» руки надо программистам выдергивать. Во всех трех примерах первый код был значительнее приятней глазу и более читабельный, чем эти «крестики-нолики», в которые их превратили. Зачем из кода делать вышиванку? — Выглядит ужасно, восприятие кода теряется, появляется куча лишних табов/пробелов.
Бывает, что иногда надо вставить себе чужой код. Первым делом приходится его восстанавливать после таких вот «улучшателей».
Бывает, что иногда надо вставить себе чужой код. Первым делом приходится его восстанавливать после таких вот «улучшателей».
Склонен не согласиться. Восстановление пробелов по-умолчанию значительно проще — это вопрос нажатия 1 кнопки в любой современной IDE.
Согласен только по последнему примеру. В первом выравнивал бы не все (default бы оставил), последний пример вообще бы не выравнивал. Но, как говорится, на вкус и цвет…
В некоторых style-guide-ах можно наоборот встретить подобное требование, в частности, align-declarations. Из известных примеров — GNOME, где выравнивают даже аргументы функций. Кроме того, это помогает в редакторах с поддержкой длинного (на несколько строк) курсора. Скажем, прототип функции поменялся, и нужно в 10 строк добавить по одному одинаковому аргументу. Проблему вижу только при миграции (методом копипасты) кода из проекта с одним стилем кодирования в другой.
Категорически не согласен. Скорость чтения выровненного кода значительно выше. Не говоря уже о скорости поиска опечаток.
Вы просто привыкли читать код без выравнивания, вот вам и кажется, что он лучше. Объективно соотносить разные части кода и находить ошибки визуально проще, когда код выровнен.
Когда только начинал программировать, мне маниакально хотелось выравнивать, выравнивать и выравнивать. Теперь я смотрю на выровненный код, и у меня кровоточат глаза, мне хочется всё вернуть обратно.
Я не хочу сказать, что выравнивание — это плохо. Это скорее дело вкуса и правил в вашем стандарте оформления кода, но я решил больше не выравнивать.
Кстати, в Python PEP8 тоже запрещает выравнивание.
Я не хочу сказать, что выравнивание — это плохо. Это скорее дело вкуса и правил в вашем стандарте оформления кода, но я решил больше не выравнивать.
Кстати, в Python PEP8 тоже запрещает выравнивание.
Из вашего примера
Я бы оставил без выравнивания. :)
// From
long int a = 2;
long long double b = 1;
const int doubl = 4;
// To
long int a = 2;
long long double b = 1;
const int doubl = 4;
Я бы оставил без выравнивания. :)
Это дело конкретных данных, которые выравниваются. Если они ближе к табличной природе — выравнивание улучшает восприятие. Но выравнивание всего подряд (например, аргументов разных функций, как в первом неудачном примере из статьи), я считаю, однозначно плохо.
Поэтому, пожалуй, желательно было бы иметь возможность динамически проставлять признак выравнивания для таких наборов данных, нежели отдавать это на откуп IDE, которая принимает решение на основе синтаксического анализа.
Поэтому, пожалуй, желательно было бы иметь возможность динамически проставлять признак выравнивания для таких наборов данных, нежели отдавать это на откуп IDE, которая принимает решение на основе синтаксического анализа.
Хм. я бы так написал:
long int a = 2;
long long double b = 1;
const int doubl = 4;
Я думаю, кровоточат от того, что вы подсознательно пытаетесь представить, как трудно будет поддерживать правильное выравнивание в вашей любимой IDE, где это не делается автоматически. Если подобное делается само собой или одной хоткеей, то проблем никаких.
А как насчет массового переименования типов?
до переименования:
после переименования:
до переименования:
Type1 a = 1;
long int b = 2;
BlaBlaType2 c = 3;
const int d = 4;
после переименования:
Type1Renamed a = 1;
long int b = 2;
BananaBananaType2 c = 3;
const int d = 4;
Я полагаю, пример с кучей разных типов скорее был как демонстрация возможностей системы. Никто не заставляет так делать, если не нравится. А в целом подружить с рефакторингами, я думаю, можно. Можно сделать кнопки типа «автоматически выравнивать/не выравнивать определения переменных, если потребовалось вставлять не более X пробелов подряд». Главное, что автор движок написал, а прикрутить тонкую настройку — дело техники.
Как тут в комментариях заметили, выравнивание хорошо подходит для table-like кода. Косить весь код под одну гребёнку выравнивания часто просто не нужно, потому что читабельнее он от этого зачастую не становится.
Инструмент будет полезен для выравнивания отдельных участков, например, выделенных пользователем, и которые меняются не часто (те же константы с табличными данными и т. п.).
Инструмент будет полезен для выравнивания отдельных участков, например, выделенных пользователем, и которые меняются не часто (те же константы с табличными данными и т. п.).
Выравнивание затрудняет код ревью и аннотирование изменений в файле. Представьте, что вы добавили новое свойство в объект и его название длиннее, чем все предыдущие. Теперь вы выровняли код — все строчки в объекте будут помечены как измененные. Что означает — ревьюеру кода нужно дополнительно напрягать зрение и вычитывать, что в остальных строчках действительно изменились только вайтспейсы. Если вы захотите проаннотировать файл на изменения — вы будете автором последних изменений всех строк этого объекта.
Бесполезные \s символы diff не должен учитывать, вообще diff по хорошему должен семантику языка понимать.
Согласен, а то привыкли к тупым универсальным инструментам. И мысли даже нет стремиться к лучшему.
diff -w
Он не может не учитывать, когда накладывается патч. А при простом сравнении глазами можно и выкинуть (см. выше). Проблема, конечно, есть, но никто ещё не умер.
Кстати, что вы можете посоветовать из diff-ов, понимающих скажем c++?
Именно я особо ничего не могу, но гугль (вероятно я уже это гуглил и у меня персонализированная выдача ) подсказывает SmartDifferencer и cmpp.coodesoft.com. А ещё я ребят из jetbrains всё на это подбиваю youtrack.jetbrains.com/issue/IDEABKL-725, благо у них уже есть AST, а с ним дальше всё в принципе понятно +-
Есть платная программа Beyond Compare. У неё есть опция «Ignore Unimportant Differences». Уже много лет пользуюсь ей для просмотра разницы и мерджа. Мне кажется, она своих денег стоит.
Пример работы на python-коде

На С++ коде работает тоже хорошо.


На С++ коде работает тоже хорошо.
А точно оно работает для разницы
— test(" some string ")
+ test(«some string»)
?
— test(" some string ")
+ test(«some string»)
?
Вы имеете в виду файлы патчей? Она может создавать отчёты в разных форматах, в том числе в формате патчей.
Как видно, строки с изменениями пробелов в патче не учитываются.
Вот так это выглядит
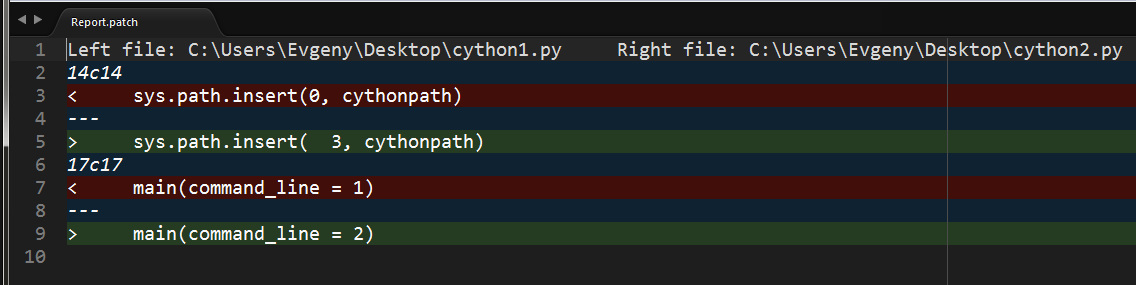


Как видно, строки с изменениями пробелов в патче не учитываются.
Я имею ввиду пробел внутри строки-аргумента функции. Он значим.
То есть как выглядит сравнение файла 1:
с файлом, где пробелы _в строке_ удалены:
То есть как выглядит сравнение файла 1:
somefun(" test ")
с файлом, где пробелы _в строке_ удалены:
somefun("test")

Автор, вы подняли холиварную тему. Щас люди, которые выравниванием не пользуются, дабы победить это явление, накидают вам минусов, и хорошо еще если не в карму.
Я лично вас поддерживаю. Хотелось бы иметь такой инструмент для js и coffee в webstorm-е.
Я лично вас поддерживаю. Хотелось бы иметь такой инструмент для js и coffee в webstorm-е.
+1 вам на github-е
В таком деле как выравнивание хорошо знать меру. Лично я выравниваю, но если строки не слишком «разбежались», в противном случае от выравнивания получается не польза, а вред, т.к. читаемость, наоборот, падает.
Например, я выравниваю, если у меня есть два схожих выражения, в которых длины имён переменных отличаются на 1..2 символа. Тогда можно добить одну из строк, чтобы привести её в соответствие с другой. Если же есть блок объявления переменных, в котором одна переменная имеет, скажем, четыре символа в имени, а другая 15, то я не буду выравнивать значения по умолчанию, просто потому что это один блок. Плюс, если придёт ещё одна переменная, ещё более длинная, то две предыдущих декларации придётся приводить в соответствие.
Короче, иногда, такое выравнивание может привнести в читаемость плюсы, и я считаю, что было бы очень круто эту технику знать. Но с другой стороны, её возможности далеко не безграничны.
Например, я выравниваю, если у меня есть два схожих выражения, в которых длины имён переменных отличаются на 1..2 символа. Тогда можно добить одну из строк, чтобы привести её в соответствие с другой. Если же есть блок объявления переменных, в котором одна переменная имеет, скажем, четыре символа в имени, а другая 15, то я не буду выравнивать значения по умолчанию, просто потому что это один блок. Плюс, если придёт ещё одна переменная, ещё более длинная, то две предыдущих декларации придётся приводить в соответствие.
Короче, иногда, такое выравнивание может привнести в читаемость плюсы, и я считаю, что было бы очень круто эту технику знать. Но с другой стороны, её возможности далеко не безграничны.
Автор молодец, за статью и код на github плюс. Но сама идея как уже отметили выше холиварная. По своему опыту скажу, что в коде стараюсь избегать использования выравнивания, потому что считаю его злом в большинстве случаев. Такие украшательства «полезны» только если вы консервируете ваш код и больше никогда его не изменяете. Но, очевидно, чаще всего это не так и позже его приходится править (и не только автору, но и другим людям). Так вот после малейшего рефакторинга все такие «произведения искусства» приходится реставрировать.
P.S. Стив Макконнелл в данном случае дает одно простое правило: «Исправление одной строки не должно приводить к изменению нескольких других».
P.S. Стив Макконнелл в данном случае дает одно простое правило: «Исправление одной строки не должно приводить к изменению нескольких других».
Нет, я все понимаю, на вкус и цвет фломастеры разные…
Но почему нет пробела после : в switch?
Но почему нет пробела после : в switch?
Весьма спорные подходы к выравниванию. Надо заметить, что я сам выравниваю таблицы значений, если их приходится хардкодить, чтобы было удобней воспринимать данные в их табличном представлении и столбцы не скакали влево-вправо. Но отрывать точку с запятой от того к чему она относится — нехорошо. Это как отрывать запятую от слова, после которого она идет в предложении. Выравнивание квадратных скобок, тоже весьма спорно, ровно как и дополнительные пробелы в именах типов. Хотя вы правы, что это дело вкуса и при достаточном тюнинге можно заставить работать алгоритм по своему вкусу.
А как вы решаете вопрос совместной работы товарищей с разным подходом в стиле?
Каждый чекаут требует переформатирования перед сессией работы?
Или как?
Каждый чекаут требует переформатирования перед сессией работы?
Или как?
Не вижу разницы между разными подходами к выравниванию и общим стилем кода в этом случае. Проблема должна решаться соглашением.
Для таких товарищей пишутся Coding Style Guide-ы, непокорных просто не пускают на сервер до тех пор пока не исправят код. В Гугле ещё веселее — перед пушем ваш код сканирует валидатор, если он ему не нравится — придётся переделывать.
Это как? Если file.lines != uncrustify(file.lines), то отбой?
Что ли это негуманно…
Что ли это негуманно…
Гайды гугла + валидатор. Вешается как git-хук.
Алентяи двигатели прогресса в свою очередь пилят AStyle.
А
забыл статью но создатель nodejs однажды написал, что если вы е6ете мозг выравнием то это все не программирование а чушь несусветная
я его понял
и с тех пор я равношки выравнивать перестал/ и счастлив!
я его понял
и с тех пор я равношки выравнивать перестал/ и счастлив!
IMHO правильнее всего что бы не холиварить хорошо выравнивание или плохо, сначала надо выбрать чего мы хотим достичь, ну там уменьшения перечитывания человеком строк кода, скоростью чтения и скоростью проглядывания кода, ещё что-нибудь про удобство редактирования и наверно про понимание кода, затем напридумывать метрики всего этого, измерять для каждого человека и делать как ему удобно(ну там при загрузке/выгрузке из/в VCS переформатировать для каждого). Благо сейчас пошли стартапы предлагающие ±точные(погрешность еденицы mm) и не шибко дорогие(100$) eye-tracking девайсы, например theeyetribe.com
my $a = 1;
my $abc = "123";
my $abcdef = 3;
после perltidy:
my $a = 1;
my $abc = "123";
my $abcdef = 3;
Задумываться о выравнивании во время написания кода это издевательство — думать надо о коде, а не о пробелах. Но вот при чтении правильное выравнивание, в том числе выравнивание деклараций переменных очень удобно.
Потому код написал, и сразу perltidy на него.
Есть давольно удобный плагин для vim — github.com/junegunn/vim-easy-align
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Автоматическое выравнивание кода