Комментарии 96
Так вот куда «пропадают» вещи периодически перед тем как внезапно появиться на том же месте через некоторое время при повторном поиске или случайно. Интересный феномен, может и мозг использует множественную перепроверку.
НЛО прилетело и опубликовало эту надпись здесь
Вывод один нужно вводить в нейронную сеть понятие лени.
НЛО прилетело и опубликовало эту надпись здесь
В нейропсихологии есть понитие описывающее механизм «скипа» — en.wikipedia.org/wiki/Latent_inhibition
Пока не будет решена проблема однопоточности вычислительных систем, о самообучающихся нейронных сетях можно только мечтать.
Думаю, вы зря переживаете насчет однопоточности. Нейроны мозга работают параллельно, но сравнительно медленно. Допустим, время переключения — порядка 1/100 секунды. Компьютер за это же время проходит десяток миллионов тактов. Т.е. компьютер может обсчитать миллионы нейронов в последовательном режиме, и результат будет такой же, как у параллельного мозга. Ну, я имею в виду, будет такой же, когда люди поймут алгоритм работы мозга:)
Ой, ерунду вы какую-то написали.
Вы путаете систему распознавания с интеллектуальным агентом. Нейронная сеть — это система распознавания — классификатор, регрессор, статистическая модель и т.д. Её задача — обрабатывать показания с датчиков и выдавать «осмысленные» выводы, например, «это собака», «сейчас темно», «скоро врежемся в дерево». Как на эти выводы реагировать решает интеллектуальный агент. Например, автономный автомобиль ежесекундно снимает под сотню показателей, включая скорость, направление джижения, картинки с камер, температуру воздуха, ускорение, давление и т.д. Все эти данные вполне себе параллельно обрабатываются многочисленными системами распознавания, а затем уже агент на основе полученных от распознавателей результатов поворачивает руль, снижает скорость, совершает манёвр и т.д. Ну и, как бы, вычислительные ресурсы пока что — далеко не главная проблема интеллектуальных систем (в отличие от человеческого мозга).
Так же не стоит исключать то, что человеческий мозг, в отличии от машины многопоточный. Мы управляем своей тушкой сознательно, но бессознательно мы получаем еще уйму информации о состоянии «системы» и окружающей среды
Вы путаете систему распознавания с интеллектуальным агентом. Нейронная сеть — это система распознавания — классификатор, регрессор, статистическая модель и т.д. Её задача — обрабатывать показания с датчиков и выдавать «осмысленные» выводы, например, «это собака», «сейчас темно», «скоро врежемся в дерево». Как на эти выводы реагировать решает интеллектуальный агент. Например, автономный автомобиль ежесекундно снимает под сотню показателей, включая скорость, направление джижения, картинки с камер, температуру воздуха, ускорение, давление и т.д. Все эти данные вполне себе параллельно обрабатываются многочисленными системами распознавания, а затем уже агент на основе полученных от распознавателей результатов поворачивает руль, снижает скорость, совершает манёвр и т.д. Ну и, как бы, вычислительные ресурсы пока что — далеко не главная проблема интеллектуальных систем (в отличие от человеческого мозга).
А они все эти картинки в виде битмапы в сеть передают? Или на, родная, кушай жпг, только не подавись?
И еще у меня есть вопрос чайника — есть ли вообще какие-то математические выкладки по нейронным сетям, хоть что-то… доказано?
И еще у меня есть вопрос чайника — есть ли вообще какие-то математические выкладки по нейронным сетям, хоть что-то… доказано?
В сеть передаются цвета пикселей, а не байты. Причем, я бы в какой-нибудь HSB сначала переводил, хотя сеть и сама способна до такого догадаться (ценой одного слоя).
>есть ли вообще какие-то математические выкладки по нейронным сетям, хоть что-то… доказано?
Есть хорошие и подробные математические выкладки и по ним пишут толстые книги.
К сожалению люди, которые этим занимаются серьёзно, редко пишут научно-популярные статьи и интернеты застраны описанием «магических» нейронных сетей без какого-либо объяснения принципов их работы.
Есть хорошие и подробные математические выкладки и по ним пишут толстые книги.
К сожалению люди, которые этим занимаются серьёзно, редко пишут научно-популярные статьи и интернеты застраны описанием «магических» нейронных сетей без какого-либо объяснения принципов их работы.
В нейронных сетях гораздо больше математики, чем биологии, откуда они взяли своё название. Например, стандартный мультислойный перцептрон — это сеть из отдельных юнитов-функций логистической регрессии; RBM, на которых часто строят глубокие сети — двудольные графы с почти марковской логикой; алгоритм обратного распространения ошибки — градиентный спуск через несколько слоёв и т.д. Другое дело, что своей гибкости сети добиваются за счёт большого количества гиперпараметров, и никто толком не представляет, как эти гиперпараметры правильно выбирать. Поэтому эксперименты часто проводятся наугад, а для объяснения логики проводятся аналогии с другими областями науки.
Хайкин С. «Нейронные сети: полный курс»
Я не то чтобы жалуюсь, но не понял, за что мне накидали минусов. Эм, спасибо, не буду больше ничего спрашивать здесь, только на тостере.
Ваш вопрос касался совсем уж азов нейросетей, в то время как статья написана для тех, кто в них немного разбирается.
А что плохого в том, чтоб спрашивать про основы? Вопрос о математических основах — не такой и простой. Нвпример, на вопрос о математических основах нейросетей Yann LeCun (один из основоположников Deep Learning) вот что пишет:
Градиентный спуск, логистическая регрессия и т.д. — это не математические основы, которые что-то серьезное гарантируют применительно к нейросетям, это просто алгоритмы, которые, как оказалось, хорошо работают на практике. Алгоритм обратного распространения — это не математическая основа, а трюк, позволяющий тренировать много логистических регрессий одновременно за вменяемое время. Все эти dropout-ы — эвристики, которые дали хорошие результаты, и к которым потом «подогнали» кое-какое математическое описание. Вместо «софтмакса» сейчас часто что-то более простое использует, вроде «ступенчатой» функции или просто
Если битмапы с одним цветом и одного размера, то да, на вход можно передавать битмап «как есть». Да даже если и RGB. Фишка «deep networks» как раз в том, что не нужно битмап преобразовывать самому — контуры выделять и т.д., т.к. первые слои нейросети что-то похожее будут сами делать.
You have to realize that our theoretical tools are very weak. Sometimes, we have good mathematical intuitions for why a particular technique should work. Sometimes our intuition ends up being wrong.
Every reasonable ML technique has some sort of mathematical guarantee. For example, neural nets have a finite VC dimension, hence they are consistent and have generalization bounds. Now, these bounds are terrible, and cannot be used for any practical purpose. But every single bound is terrible and useless in practice (including SVM bounds).
Градиентный спуск, логистическая регрессия и т.д. — это не математические основы, которые что-то серьезное гарантируют применительно к нейросетям, это просто алгоритмы, которые, как оказалось, хорошо работают на практике. Алгоритм обратного распространения — это не математическая основа, а трюк, позволяющий тренировать много логистических регрессий одновременно за вменяемое время. Все эти dropout-ы — эвристики, которые дали хорошие результаты, и к которым потом «подогнали» кое-какое математическое описание. Вместо «софтмакса» сейчас часто что-то более простое использует, вроде «ступенчатой» функции или просто
_/ — никакого особенного мат. обоснования тут нет, просто вычислять это быстрее, и работает не хуже на практике (а часто лучше).Если битмапы с одним цветом и одного размера, то да, на вход можно передавать битмап «как есть». Да даже если и RGB. Фишка «deep networks» как раз в том, что не нужно битмап преобразовывать самому — контуры выделять и т.д., т.к. первые слои нейросети что-то похожее будут сами делать.
Представьте, вы написали статью про библиотеку pymorphy2 — а вас в комментариях спрашивают:
Как думаете, сколько минусов собрал бы такой комментарий?
Скажите, а на вход вашей библиотеки надо строку передавать — или можно поток байт кинуть, а кодировку она сама определит?
Как думаете, сколько минусов собрал бы такой комментарий?
Проблема в том, любой хабаропользователь, который не разобрался в вопросе, но при этом наглухо уверен в своём превосходстве, может легко накидать минусов. Власть помноженная на массовую безответственность, вот и весь ответ на вопрос автора десяти статей.
Специалист из АББИ подробно рассмотрел статью и показал, что почти единственное интересное наблюдение в ней это то, что «ломающий» пример одинаково ломает разные сети, обученные разными способами. habrahabr.ru/company/abbyy/blog/225349 А я там же в комментариях показал, что ответ на этот вопрос фактически сводится к способу кодирования исходной картинки. Таким образом вопрос о способе кодирования картинки один из двух интересных вопросов к этой статье.
И то что именно его закидали минусами говорит о качественном уровне хабрасообщества. Знаний побольше, чем у гопников на митинге, но основа стадного поведения точно та же самая.
Специалист из АББИ подробно рассмотрел статью и показал, что почти единственное интересное наблюдение в ней это то, что «ломающий» пример одинаково ломает разные сети, обученные разными способами. habrahabr.ru/company/abbyy/blog/225349 А я там же в комментариях показал, что ответ на этот вопрос фактически сводится к способу кодирования исходной картинки. Таким образом вопрос о способе кодирования картинки один из двух интересных вопросов к этой статье.
И то что именно его закидали минусами говорит о качественном уровне хабрасообщества. Знаний побольше, чем у гопников на митинге, но основа стадного поведения точно та же самая.
Я сам когда начинал pymorphy писать, потоки байт кидал, т.к. питон знал не очень. Иногда не работало. Да и библиотекой пользуются не только программисты, и вот они подобные вопросы задают чаще. Я им рад :) Хорошо, если человек задает вопрос — ему можно чем-то помочь, он не уйдет с молчаливым недовольством. Люди могут быть умные, и хотеть разобраться, но просто базовые знания иметь в другой области. Мое мнение — минусовать простые вопросы не нужно, простые вопросы — это хорошо, они сигнализируют о любознательности и интересе к теме. Ну не знает человек чего-то, и спросил — это же хорошо? Это же лучше, чем если бы человек не спросил — ему бы тогда не ответили, и «сумма знаний» была бы меньше.
В интернет-дискуссиях еще один фактор есть — на десять человек, которым непонятно, один спросит. А дискуссию прочитают (и какую-то информацию получат) все.
В интернет-дискуссиях еще один фактор есть — на десять человек, которым непонятно, один спросит. А дискуссию прочитают (и какую-то информацию получат) все.
Суть в том, что я уже изучал основы нейронных сетей, знаю как они функционируют и из чего состоят, на лабах в универе парочку запрограммил. И да, я ни разу за весь курс ИИС не увидел ни одной математической выкладки, доказывающей хоть что-нибудь.
А статья как раз таки написана для тех, кто в них не разбирается совершенно, на уровне деского сада/желтой прессы.
А статья как раз таки написана для тех, кто в них не разбирается совершенно, на уровне деского сада/желтой прессы.
Посмотрите лекции Andew Ng на Coursera, хотя бы избранные темы: градиентый спуск, логистическую регрессию и, затем уже, нейронные сети (которые активно используют материал предыдущих тем). Это займёт не так много времени, но зато вы подковырнёте ту огромную математическую теорию, на которой базируются не только сети, но и большинство методов машинного обучения.
По-моему полезной информации в статье чуть больше нуля и тем более никаких философских вопросов она ставить не может в принципе.
Изучался один тип сетей из многих и результат применим только к нему.
>если у вас есть фотография кота, существует набор небольших изменений, которые могут сделать так, что сеть будет распознавать кота как собаку
Бредовое утверждение, хотя бы потому, что сеть, распознающая котов о собаках ничего не знает. Она может распознать кота как «не кота», не более.
Даже если сеть обучена распознавать и котов и собак, из эффекта описанного в статье не следует, что можно подобрать пример, который будет воспринимать кота собакой, а не «не котом».
Изучался один тип сетей из многих и результат применим только к нему.
>если у вас есть фотография кота, существует набор небольших изменений, которые могут сделать так, что сеть будет распознавать кота как собаку
Бредовое утверждение, хотя бы потому, что сеть, распознающая котов о собаках ничего не знает. Она может распознать кота как «не кота», не более.
Даже если сеть обучена распознавать и котов и собак, из эффекта описанного в статье не следует, что можно подобрать пример, который будет воспринимать кота собакой, а не «не котом».
по-моему типы были разными:
• For the MNIST dataset, we used the following architectures [11]
– A simple fully connected, single layer network with a softmax classifier on top of it.
We refer to this network as “softmax”.
– A simple fully connected network with two hidden layers and a classifier. We refer to
this network as “FC”.
– A classifier trained on top of autoencoder. We refer to this network as “AE”.
– A standard convolutional network that achieves good performance on this dataset:
it has one convolution layer, followed by max pooling layer, fully connected layer,
dropout layer, and final softmax classifier. Referred to as “Conv”.
• The ImageNet dataset [3].
– Krizhevsky et. al architecture [9]. We refer to it as “AlexNet”.
• ⇠ 10M image samples from Youtube (see [10])
– Unsupervised trained network with ⇠ 1 billion learnable parameters. We refer to it as
“QuocNet”.
так что начало вполне себе положено.
Подразумевается, что общественность озаботится и последуют более детальные и обширные исследования.
• For the MNIST dataset, we used the following architectures [11]
– A simple fully connected, single layer network with a softmax classifier on top of it.
We refer to this network as “softmax”.
– A simple fully connected network with two hidden layers and a classifier. We refer to
this network as “FC”.
– A classifier trained on top of autoencoder. We refer to this network as “AE”.
– A standard convolutional network that achieves good performance on this dataset:
it has one convolution layer, followed by max pooling layer, fully connected layer,
dropout layer, and final softmax classifier. Referred to as “Conv”.
• The ImageNet dataset [3].
– Krizhevsky et. al architecture [9]. We refer to it as “AlexNet”.
• ⇠ 10M image samples from Youtube (see [10])
– Unsupervised trained network with ⇠ 1 billion learnable parameters. We refer to it as
“QuocNet”.
так что начало вполне себе положено.
Подразумевается, что общественность озаботится и последуют более детальные и обширные исследования.
1. Это далеко не все разработанные типы НС, а лишь малая их часть. Всё равно что одну исследовать.
2. Все они обучались методом глубокого обучения, которому и посвящена исходная статья.
То есть вся исходная статья посвящена особенностям работы конкретного метода обучения на паре конкретных архитектур.
Исследователи молодцы, что нашли существенный баг в этом популярном и перспективном методе, но их результаты никак не могут претендовать на революционность или философскую ценность.
2. Все они обучались методом глубокого обучения, которому и посвящена исходная статья.
То есть вся исходная статья посвящена особенностям работы конкретного метода обучения на паре конкретных архитектур.
Исследователи молодцы, что нашли существенный баг в этом популярном и перспективном методе, но их результаты никак не могут претендовать на революционность или философскую ценность.
Ошибки часто подталкивают на действительно революционные окрытия. Так же часто открытия могут покрывать сферы приминения более широкого масштаба нежели сфера в которой была воспроизведена ошибка.
Ещё чаще ошибки никуда не подталкивают, а являются просто ошибками. И если бы статья была о революционных результатах, полученных из найденной проблемы, её сенсационный тон был бы оправдан.
А так, имеем пустозвонство из совершенно рядового события.
А так, имеем пустозвонство из совершенно рядового события.
Ошибки, описанные в статье, интересные и неочевидные — нейросеть ошибается не на сложных примерах, а, казалось бы, на простых. Ну и в статье (pdf) пустозвонства никакого нет — хорошая научная статья, довольно интересная.
НЛО прилетело и опубликовало эту надпись здесь
По-моему, статья закрывает нейронные сети. Есть, правда, надежда, что закрываются не все нейронные сети, а только некоторый подкласс, именно такой, какой исследовали специалисты Гугла. Но надежда довольно призрачная. Чтобы сказать, какой класс нейронных сетей заражен «проклятьем Гугла», а какой — нет, надо сначала разобраться, почему вообще такая беда с нейронными сетями происходит. И мне почему-то кажется, что эта задача практически эквивалентна задаче создания действительно работающей нейронной сети.
Я как-то заметил, что если те же входные данные, что и на первом слое, подавать на второй, то прогнозируемость на валидационной выборке будет лучше. Возможно мозг работает похожим образом: рецепторов много, одни и те же входные данные попадают на разные «слои», причем под разным соусом, для каждого «слоя» различная искаженность, ну и интерпретация разная, соответственно, а отсюда и обобщение в теории может быть лучше.
Похоже на голографический принцип, нет?
Из того, что я прочел о нем в википедии, да, похоже. Вообще, этот пример с двумя слоями может быть очень близок к генетическим алгоритмам, когда в качестве фитнесс-функции выступает следующий слой за этими двумя, но тут на второй слой помимо внешних данных подаются еще выходы предыдущего слоя. Может быть это и не работает как генетические алгоритмы, но чисто интуитивно, как мне кажется, сходство есть.
А вообще связка «ансамбль нейронных сетей -> генетический алгоритм», на мой взгляд, гораздо ближе по своему функционалу к мозгу, чем любая нейронная сеть любой сложности в чистом виде.
А вообще связка «ансамбль нейронных сетей -> генетический алгоритм», на мой взгляд, гораздо ближе по своему функционалу к мозгу, чем любая нейронная сеть любой сложности в чистом виде.
спасибо за статью!
Ну во-первых, мозг и искусственные нейронные сети — очень разные вещи. Когда говорят про нейронные сети, то обычно понимают сети прямого распространения, где сигнал передается от уровня к уровню. Но есть еще и другие типы сетей, например — рекуррентные, где сигнал может передаваться и на предыдущие уровни.
Во-вторых, научные статьи и промышленное применение — разные вещи. Всегда есть этап докручивания и допиливания до результата.
Во-вторых, научные статьи и промышленное применение — разные вещи. Всегда есть этап докручивания и допиливания до результата.
Подавать в нейросеть, а если быть точным многослойный персептрон, цвета пикселей это плохая идея. Достаточно знать элементарные основы работы нейросетей.
Нейросеть это функция, которая получает на вход вектор и на выходе дает вектор. Если размер картинки 100 на 100 пикселей, то размер входного вектора — 10000 элементов. Для тренировки надо подать входных данных примерно в 10 раз больше размерности, чтобы получать адекватный результат, иначе даже локальный минимум функции квадратичной ошибки получить неудастся.
Кроме того картинка как набор пикселей очень неудачный формат ибо небольшое изменение, например сдвиг на 1 пиксел, не меняет сути изображения, но сильно меняет сами данные.
Нейросеть это функция, которая получает на вход вектор и на выходе дает вектор. Если размер картинки 100 на 100 пикселей, то размер входного вектора — 10000 элементов. Для тренировки надо подать входных данных примерно в 10 раз больше размерности, чтобы получать адекватный результат, иначе даже локальный минимум функции квадратичной ошибки получить неудастся.
Кроме того картинка как набор пикселей очень неудачный формат ибо небольшое изменение, например сдвиг на 1 пиксел, не меняет сути изображения, но сильно меняет сами данные.
таким образом квадратную матрицу пикселей для нейросети разворачивают в вектор.Я правильно вас понял?
А какие есть альтернативы? Просто интересно.
Смотря для чего. В computer vision обычно используются сверточные нейросети, в которых перед обычной нейросетью ставится несколько слоев свертки и субдискретизации для выделения особенностей (features) изображения. А перед этим еще выполняется нормализация, например выделение яркости изображения, устранение поворотов и центрирование распознаваемых образов.
Все эти телодвижения уменьшают размерность входных данных, что хорошо для точности алгоритма, но плохо для решения обобщенных задач, вроде определения белых и черных собак или русских или американских танков.
Все эти телодвижения уменьшают размерность входных данных, что хорошо для точности алгоритма, но плохо для решения обобщенных задач, вроде определения белых и черных собак или русских или американских танков.
речь наверное о глубоких сетях, там сначала идет предобработка сетью без учителя — автоэнкодером, потом обработанными данными, а это уже не пиксели, а фрагменты разного масштаба, обучается сеть с учителем
Там же многослойные сети. deep learning и прочие прелести жизни.
Говоря совсем упрощённо, каждый уровень отвечает за свой уровень representation на основе входа с предыдущего уровня — т.е. первый уровень научится находить паттерны, соответствующие кускам прямых и углам, следующий будет объединять их, на каком-то уровне возникнет обнаружение значимых фрагментов объекта (человеческое ухо, глаз и т.д.)
Вот простенькая иллюстрация s3.amazonaws.com/datarobotblog/images/deepLearningIntro/013.png
Говоря совсем упрощённо, каждый уровень отвечает за свой уровень representation на основе входа с предыдущего уровня — т.е. первый уровень научится находить паттерны, соответствующие кускам прямых и углам, следующий будет объединять их, на каком-то уровне возникнет обнаружение значимых фрагментов объекта (человеческое ухо, глаз и т.д.)
Вот простенькая иллюстрация s3.amazonaws.com/datarobotblog/images/deepLearningIntro/013.png
Неужели спустя столько лет до хабровчан дойдет, что пора забыть слово «нейросеть» и искать новое модное слово, значение которого, однако, тоже не будут понимать.
Ха, а я как раз примерно такого результата от нейросетей и ожидал после студенческого еще опыта работы с ними. И был честно говоря неприятно удивлен работами Google по нейросетям, поскольку мне казалось что это явная дорога в тупик, тогда как Google подавал нейросети чуть ли не как панацею и чудо-алгоритм за которым виднеется явное будущее систем распознавания :)
Ну что же, моя вера в Google восстановлена :). Статья великолепная, прекрасно иллюстрирует всю глубину распространенных заблуждений о нейросетях и особенно ценна тем, что написана людьми, которые являются одними из лучших на сегодняшний день в предметной области. Надеюсь что она подействует отрезвляюще на специалистов считающих нейросети надежным и эффективным способом решения сложных проблем.
Ну что же, моя вера в Google восстановлена :). Статья великолепная, прекрасно иллюстрирует всю глубину распространенных заблуждений о нейросетях и особенно ценна тем, что написана людьми, которые являются одними из лучших на сегодняшний день в предметной области. Надеюсь что она подействует отрезвляюще на специалистов считающих нейросети надежным и эффективным способом решения сложных проблем.
У меня почему-то возникла аналогия с хэш-функцией. Если взять хэш-функцию, то к любому ключу можно подобрать другой, совершенно на него непохожий, который, тем не менее, будет вызывать коллизию. Но если взять две или более хэш-функций…
… то ничего принципиально не поменяется. Если хэш-функция «сложная», то к ней и одной коллизию будет подобрать фантастически сложно, а если две «простые», то коллизию для них найти будет сравнительно несложно.
Хеш-функция сворачивает вектор переменного и потенциально большого размера в вектор фиксированного размера. Тут без коллизий никак не обойтись, сколько хеш-функций ни бери
habrahabr.ru/post/168707/ — keccak использует псевдослучайные перестановки, чтобы исключить коллизии
Вопрос чайника — как часто в автомобиле сеть перепроверяет данные с датчиков?
В движушемся автомобиле картинка с камер постоянно меняется и слепая зона в конце концов пропадет. Успеет-ли нейросеть в ситуации со слепой зоной исправить свою ошибку и не сбить пешехода?
В движушемся автомобиле картинка с камер постоянно меняется и слепая зона в конце концов пропадет. Успеет-ли нейросеть в ситуации со слепой зоной исправить свою ошибку и не сбить пешехода?
Успеет. Поскольку в автомобилях не только видео-датчики. Обычно несколько источников информации…
Заявленные проблемы в самом простом приближении решаются добавлением шума к сигналу.
Заявленные проблемы в самом простом приближении решаются добавлением шума к сигналу.
… или не решаются. Потому что шум самой сетью успешно фильтруется…
Шум только ухудшит ситуацию. Там проблема в том, что нейросеть абсолютно ничего не гарантирует за исключением того, что она пристойно работает на обучающей выборке. Если взять любую сеть и любую точку обучающей выборки, то для этой точки можно сравнительно легко построить два направления — по одному выход детектора будет меняться максимально быстро, по другому — максимально медленно. Пройдя по первому направлению некоторое время мы довольно скоро добьемся изменения результата распознавания, пройдя по второму — сможем долго идти не меняя результата распознавания. Вопрос стоит только в том насколько мало придется пройти в первом случае и насколько много можно пройти во втором. Вот это, собственно, в гугловском исследовании и было проверено и, на мой взгляд ожидаемо, показало что для широкого диапазона применяемых сегодня нейросетей идти в первом направлении достаточно всего чуть-чуть, а во втором можно уйти очень далеко — см. картинки выше. И от того что Вы добавите к входным данным шум, Вы ничего в этой ситуации не поменяете — просто сдвинете начальную точку (причем вполне возможно сломав при этом правильный выход с детектора). Проще говоря в гугловской работе отлично показано что нейросети НЕ обладают двумя волшебными свойствами которые им без какого-либо обоснования приписывают:
1) способности к разумному обобщению данных
2) способности к надежному отделению выборки от всех остальных данных
А потому никаких гарантий работоспособности для нейросетей в общем случае нет и быть не может. Разве что взять исчерпывающую обучающую выборку которая почти полностью закроет пространство возможных входных данных. Но при наличии такой выборки в нейросетях нету смысла — проще тупо искать наиболее похожий вариант из выборки, при такой плотности обучающих данных работать этот подход будет не хуже.
1) способности к разумному обобщению данных
2) способности к надежному отделению выборки от всех остальных данных
А потому никаких гарантий работоспособности для нейросетей в общем случае нет и быть не может. Разве что взять исчерпывающую обучающую выборку которая почти полностью закроет пространство возможных входных данных. Но при наличии такой выборки в нейросетях нету смысла — проще тупо искать наиболее похожий вариант из выборки, при такой плотности обучающих данных работать этот подход будет не хуже.
Откуда столько эмоций? Речь идет о т.н. 'adversarial noise'. Т.е. мы сознательно генерируем шум такого рода, что заставляет классификатор ошибаться. Это применимо, вообще, к любым классификаторам. В статье показано как это делать с нейронной сетью.
На счет автомобилей и т.п. — привожу пример обсуждения на форуме (с участием автора статьи):
На счет автомобилей и т.п. — привожу пример обсуждения на форуме (с участием автора статьи):
Minh Lê 2 июня 2014 г.:
Regarding driverless cars: this finding should not be a problem to them because they examine many samples per second and it is unlikely that «adversarial examples» occur in majority.
Christian Szegedy 2 июня 2014 г.
Agreeing with Minh.
Не всё так просто. Решающее значение имеет следующий момент.
Если авторы работы показывают, что существуют некоторые входные вектора, малое изменение которых вызывает отнесение их к разным множествам (образам) — то в это нет вообще ничего странного/важного/критичного. Очевидно, что любые вектора, находящиеся на границе областей соседних множеств (образов) могут быть легко изменены малыми отклонениями, так чтобы формально попасть в одно или другое множество образов.
Но, если авторы показали что для любого (т.е. каждого который они проверяли, и если проверяли они очень много) входного вектора существуют такие малые его изменения которые дают ложное срабатывание классификатора, и если это справедливо для большинства применяемых архитектур нейросетей — то тогда, действительно, вся парадигма нейросетей дискредитирована.
Т.е. вопрос в том, идет ли речь про каждый входной вектор (и тогда всё плохо), или лишь про некоторые входные векторы (т.е. про малое их кол-во, и тогда всё ОК).
Если авторы работы показывают, что существуют некоторые входные вектора, малое изменение которых вызывает отнесение их к разным множествам (образам) — то в это нет вообще ничего странного/важного/критичного. Очевидно, что любые вектора, находящиеся на границе областей соседних множеств (образов) могут быть легко изменены малыми отклонениями, так чтобы формально попасть в одно или другое множество образов.
Но, если авторы показали что для любого (т.е. каждого который они проверяли, и если проверяли они очень много) входного вектора существуют такие малые его изменения которые дают ложное срабатывание классификатора, и если это справедливо для большинства применяемых архитектур нейросетей — то тогда, действительно, вся парадигма нейросетей дискредитирована.
Т.е. вопрос в том, идет ли речь про каждый входной вектор (и тогда всё плохо), или лишь про некоторые входные векторы (т.е. про малое их кол-во, и тогда всё ОК).
For all the networks we studied (MNIST, QuocNet [10], AlexNet [9]), for each sample, we always manage to generate very close, visually indistinguishable, adversarial examples that are misclassified by the original network
ALL the networks FOR EACH SAMPLE.
Мало того, там дальше еще интереснее:
A relatively large fraction of examples will be misclassified by networks trained from scratch with different hyper-parameters (number of layers, regularization or initial weights)
Т.е. мало того что для каждой сети и каждого элемента выборки можно построить ложное срабатывание неотличимое визуально, при переобучении сети с другими параметрами в значительном числе случаев тот же самый контрпример изначально построенный для другой сети сработает снова.
A relatively large fraction of examples will be misclassified by networks trained from scratch trained on a disjoint training set
То есть можно обучать сеть вообще на других данных, и все равно значительная часть контрпримеров сработает и для этой, новой сети.
Траурная музыка, занавес.
Я так понимаю что нормализация и фильтрация данных на входе поможет отбросить лишний шум, даже если он был внедрен во входные данные намеренно.
Что меня сильно смутило в исследовании, так это то, что используются академические примеры нейросетей. Интересно можно ли подобный трюк повторить с боевыми примерами. Было бы очень прикольно иметь номер на машине визуально нормальный, но не определяющийся на камере.
А то мне недавно штраф на 3к пришел…
Что меня сильно смутило в исследовании, так это то, что используются академические примеры нейросетей. Интересно можно ли подобный трюк повторить с боевыми примерами. Было бы очень прикольно иметь номер на машине визуально нормальный, но не определяющийся на камере.
А то мне недавно штраф на 3к пришел…
Понятно что для любого классификатора можно найти такой шум который заставит его ошибиться. Понятно что дообучая классификатор с использованием такого шума можно получить улучшенный классификатор, которому для ошибки потребуется шум побольше.
Проблема в том насколько большой требуется шум. Нетривиальность гугловской работы состоит в том что они показали что, по видимому, для больших нейросетей всегда достаточно очень небольшого шума. Там приводится хорошая аналогия: представим себе классификатор как нелинейную многомерную ф-ю соответствующую «уровню достоверности» того что поданный на вход объект принадлежит заданному классу. Тогда «традиционные» классификаторы построят непрерывные функции — небольшие изменения входных данных не будут сильно менять значение ф-и. Для нейросетей же это не так — более того, показывается что они всегда строят «разрывные» функции — в небольшой окрестностях любой точки находятся сильно отличающиеся значения ф-и классификации.
Что до оптимистических тезисов, то они, по сути сводятся к радостному предположению что хотя для любой нейросети всегда можно построить близко расположенный контрпример, но вероятность случайно найти этот контрпример стремится к нулю. «Небольшой» ньюанс, однако, состоит в том что как-либо обосновать или доказать это утверждение никто даже не пытается. Это снова вопрос веры. Раньше люди верили что достаточно большие и достаточно глубоко обученные нейросети не будут ошибаться на простых примерах вообще, теперь верят в то что вероятность ошибки стремится к нулю.
Проблема в том насколько большой требуется шум. Нетривиальность гугловской работы состоит в том что они показали что, по видимому, для больших нейросетей всегда достаточно очень небольшого шума. Там приводится хорошая аналогия: представим себе классификатор как нелинейную многомерную ф-ю соответствующую «уровню достоверности» того что поданный на вход объект принадлежит заданному классу. Тогда «традиционные» классификаторы построят непрерывные функции — небольшие изменения входных данных не будут сильно менять значение ф-и. Для нейросетей же это не так — более того, показывается что они всегда строят «разрывные» функции — в небольшой окрестностях любой точки находятся сильно отличающиеся значения ф-и классификации.
Что до оптимистических тезисов, то они, по сути сводятся к радостному предположению что хотя для любой нейросети всегда можно построить близко расположенный контрпример, но вероятность случайно найти этот контрпример стремится к нулю. «Небольшой» ньюанс, однако, состоит в том что как-либо обосновать или доказать это утверждение никто даже не пытается. Это снова вопрос веры. Раньше люди верили что достаточно большие и достаточно глубоко обученные нейросети не будут ошибаться на простых примерах вообще, теперь верят в то что вероятность ошибки стремится к нулю.
Что самое интересное, гугловская работа-то на самом деле довольно тривиальна. Достаточно взять тот же метод обратного распространения ошибки — но вместо коррекции параметров нейросети распространить ошибку до входных нейронов и скорректировать их. Другое дело, что походу так никто до них не делал — а результат-то оказался большим сюрпризом.
Зато если найденный шум наложить на исходное изображение — то можно будет увидеть, что же на самом деле научилась распознавать нейросеть. В случае с автомобилем, к примеру, такое ощущение что распознавалось наличие левой фары и зеркала заднего вида (говорю очень приблизительно, накладывать изображения не пробовал — ибо ни Фотошопа, ни аналога у меня нет за ненадобностью). Если это действительно так — то нет ничего удивительного в том, что данная ошибка классификации сохранялась вне зависимости от используемой нейросети и даже обучающей выборки — ведь вряд ли во всех этих обучающих выборках присутствовали сломанные автомобили.
Так хочется повторить их эксперимент, но я не знаю современного состояния нейросетей…
Зато если найденный шум наложить на исходное изображение — то можно будет увидеть, что же на самом деле научилась распознавать нейросеть. В случае с автомобилем, к примеру, такое ощущение что распознавалось наличие левой фары и зеркала заднего вида (говорю очень приблизительно, накладывать изображения не пробовал — ибо ни Фотошопа, ни аналога у меня нет за ненадобностью). Если это действительно так — то нет ничего удивительного в том, что данная ошибка классификации сохранялась вне зависимости от используемой нейросети и даже обучающей выборки — ведь вряд ли во всех этих обучающих выборках присутствовали сломанные автомобили.
Так хочется повторить их эксперимент, но я не знаю современного состояния нейросетей…
Вот интересная пришла мысль. Известно, что мозг для классификации использует все органы чувств. Если вы определили запах неправильно, после взгляда на предмет вы почувствуете другой запах (по крайней мере, это верно для определения направления звука, было много соответствующих опытов)
Что если в этом случае собрать и обучить две нейронные сети, которым на вход подавать по-разному переработанные исходные изображения (напрмер, в одном случае выделяем из изображения контуры, во втором обрабатываем стандартное изображение), а потом использовать результаты их работы для обучения друг друга. есть предположение, что эффект «слепых пятен» будет нивелирован.
Что если в этом случае собрать и обучить две нейронные сети, которым на вход подавать по-разному переработанные исходные изображения (напрмер, в одном случае выделяем из изображения контуры, во втором обрабатываем стандартное изображение), а потом использовать результаты их работы для обучения друг друга. есть предположение, что эффект «слепых пятен» будет нивелирован.
Если соединить две нейросети — то получится еще одна нейросеть, а не что-то принципиально новое. Переработка изображения дело не спасает — большинство таких переработок являются гладкими функциями — и они совсем не помешают найти градиент выходного сигнала по входному. И даже если намеренно отказаться от гладких функций — то невозможность нахождения «плохих» изображений совершенно не означает их отсутствие.
угу, точно так же, как в криптографии — невозможность за разумное время нахождения секретного ключа не означает его отсутствие
вы скептически смотрите на возможность улучшить характеристики алгоритма на нейросетях? или ваша мысль в том, что все, что потенциально может быть сломано, будет сломано, поясните мысль, плз?
вы скептически смотрите на возможность улучшить характеристики алгоритма на нейросетях? или ваша мысль в том, что все, что потенциально может быть сломано, будет сломано, поясните мысль, плз?
Если сравнивать с криптографией, то надо вспомнить не секретный ключ — а печально известный принцип «security through obscurity». До тех пор, пока мы можем самостоятельно сгенерировать плохое изображение — можно пытаться улучшать нейросеть. Минимальное расстояние между изображениями, на котором ошибается классификатор — это вообще-то критерий качества классификации. Как только мы не имеем такой возможности — мы не можем даже оценить вероятность появления таких плохих данных на входе в процессе эксплуатации.
А злоумышленник такого изображения на вход нейросети не подбросит никогда — просто потому что он заранее не знает всех коэффициентов.
А злоумышленник такого изображения на вход нейросети не подбросит никогда — просто потому что он заранее не знает всех коэффициентов.
Часто для предобработки изображений используется преобразование фурье и манипуляции с результатом, это, насколько я помню матан, гладкой функцией не является.
Да ладно. Дискретное преобразование Фурье — вообще линейная функция…
Может быть непрерывная?
{kind=link}
Уточню — манипуляции с результатами преобразования не являются непрерывной функцией.
Манипуляции какого рода?
Например обрезание высоких частот для подавления случайных шумов или вырезание пиков для подавления наведенных шумов. Сорри, с двумерными преобразованиям не очень активно работал, поэтому некоторые вещи для картинок могут быть неактуальны.
Вырезание высоких частот — это просто отбрасывание части компонент. Оставшиеся компоненты все так же линейно зависят от входа.
Вырезание пиков — это, по сути, применение пороговой функции. Да, она не является гладкой — но может быть вполне успешно заменена аналитической сигма-функцией.
Кроме того, у пороговой функции всего одна особая точка. Если рабочее значение на данном наборе входных данных оказалось достаточно далеко от этой точки — то пороговая функция никак не помешает найти градиент.
Вырезание пиков — это, по сути, применение пороговой функции. Да, она не является гладкой — но может быть вполне успешно заменена аналитической сигма-функцией.
Кроме того, у пороговой функции всего одна особая точка. Если рабочее значение на данном наборе входных данных оказалось достаточно далеко от этой точки — то пороговая функция никак не помешает найти градиент.
Забавно. Авторы повторили мои выводы из статьи: habrahabr.ru/post/219647/
Если бы им довелось прочитать её и посмотреть картинки начиная с шестой они бы даже узнали почему они получили такой невероятный результат про две похожие картинки. Там на сине-зелёных картинках с точками это очень хорошо видно. К счастью их выводы верны только для сетей с ограниченной глубиной, меньшей, чем необходимо для расшифровки способа кодирования входного сигнала. Иначе перспективы нейроныых сетей действительно были бы грустными. К счастью есть множество сетей совершенно других конструкций начиная с полносвязанных.
Некоторые особенно пессимистичные выводы попросту неверны. Например вот этот: «Это значит, что нейронные сети не «дескремблируют» данные, отображая особенности на отдельные нейроны, например, выходного слоя». Я бы очень расстроился прочитав это если бы буквально вчера не дёргал своей нейронную сеть за нейрон, отвечающий за ширину крыльев, и не любовался тем как эта сеть потеряв возможность передавать эту информацию по одному синапсу (Я его вес вручную занулил) прокладывает себе путь для этой же информации в обход через другие нейроны.
Если бы им довелось прочитать её и посмотреть картинки начиная с шестой они бы даже узнали почему они получили такой невероятный результат про две похожие картинки. Там на сине-зелёных картинках с точками это очень хорошо видно. К счастью их выводы верны только для сетей с ограниченной глубиной, меньшей, чем необходимо для расшифровки способа кодирования входного сигнала. Иначе перспективы нейроныых сетей действительно были бы грустными. К счастью есть множество сетей совершенно других конструкций начиная с полносвязанных.
Некоторые особенно пессимистичные выводы попросту неверны. Например вот этот: «Это значит, что нейронные сети не «дескремблируют» данные, отображая особенности на отдельные нейроны, например, выходного слоя». Я бы очень расстроился прочитав это если бы буквально вчера не дёргал своей нейронную сеть за нейрон, отвечающий за ширину крыльев, и не любовался тем как эта сеть потеряв возможность передавать эту информацию по одному синапсу (Я его вес вручную занулил) прокладывает себе путь для этой же информации в обход через другие нейроны.
В статье рассматриваются полносвязанные и многослойные конструкции, причем взяты они не с потолка, а из эффективных и часто используемых реализаций
For the MNIST dataset, we used the following architectures [11]
– A simple fully connected, single layer network with a softmax classifier on top of it. We refer to this network as “softmax”.
– A simple fully connected network with two hidden layers and a classifier. We refer to this network as “FC”.
– A classifier trained on top of autoencoder. We refer to this network as “AE”.
– A standard convolutional network that achieves good performance on this dataset: it has one convolution layer, followed by max pooling layer, fully connected layer, dropout layer, and final softmax classifier. Referred to as “Conv”.
The ImageNet dataset [3].
– Krizhevsky et. al architecture [9]. We refer to it as “AlexNet”.
10M image samples from Youtube (see [10])
– Unsupervised trained network with ⇠ 1 billion learnable parameters. We refer to it as “QuocNet”
А мне кажется что как раз верны и тезис о дескремблировании особенностей есть выдавание желаемого за действительное. Прочитайте статью-то. Там показано что то что обычно выдается за «детектируемую нейроном „фичу изображения“ на самом деле, по видимому, есть либо свойство тестового набора данных, либо целого слоя нейросети, но никак не отдельных нейронов.
Традиционный подход ведь как устроен? Возьмем какой-нибудь нейрон и посмотрим какие входные данные из обучающей выборки максимизируют его активацию. Получим некий набор картинок. При этом этом окажется что во всех этих картинках будет какой-то общий элемент, идентифицируемый с этим вектором. Отсюда стало быть заключаем что нейросеть самостоятельно нашла этот общий элемент и выбранный нейрон как раз его детектирует. Логично?
А теперь посмотрим что сделали ребята из Google. Вместо того чтобы искать в обученной нейросети вектор который бы максимизировал отклик какого-то одного нейрона (или набора нейронов), они считали взвешенную сумму активации всех нейронов одного слоя, выбирая при этом совершенно случайные веса. То есть результаты отдельных нейронов одного слоя просто случайным образом перемешивались в некую кашу, которая заведомо никакому детектированию специально не обучалась. Но прогоняем тот же самый процесс поиска в обучающей выборке изображений максимизирующих отклик этой случайной смеси, пристально вглядываемся в результат — и, надо же, тоже находим на картинках совершенно явные общие элементы. Упс. То есть одиночные нейроны в рамках подобной методики „дескремблируют“ изображение ничем не лучше чем случайная смесь из нейронов. Но как можно говорить тогда о том что нейросеть раскладывает входные данные на отдельные осмысленные компоненты, по одному на нейрон?
For the MNIST dataset, we used the following architectures [11]
– A simple fully connected, single layer network with a softmax classifier on top of it. We refer to this network as “softmax”.
– A simple fully connected network with two hidden layers and a classifier. We refer to this network as “FC”.
– A classifier trained on top of autoencoder. We refer to this network as “AE”.
– A standard convolutional network that achieves good performance on this dataset: it has one convolution layer, followed by max pooling layer, fully connected layer, dropout layer, and final softmax classifier. Referred to as “Conv”.
The ImageNet dataset [3].
– Krizhevsky et. al architecture [9]. We refer to it as “AlexNet”.
10M image samples from Youtube (see [10])
– Unsupervised trained network with ⇠ 1 billion learnable parameters. We refer to it as “QuocNet”
Некоторые особенно пессимистичные выводы попросту неверны.
А мне кажется что как раз верны и тезис о дескремблировании особенностей есть выдавание желаемого за действительное. Прочитайте статью-то. Там показано что то что обычно выдается за «детектируемую нейроном „фичу изображения“ на самом деле, по видимому, есть либо свойство тестового набора данных, либо целого слоя нейросети, но никак не отдельных нейронов.
Традиционный подход ведь как устроен? Возьмем какой-нибудь нейрон и посмотрим какие входные данные из обучающей выборки максимизируют его активацию. Получим некий набор картинок. При этом этом окажется что во всех этих картинках будет какой-то общий элемент, идентифицируемый с этим вектором. Отсюда стало быть заключаем что нейросеть самостоятельно нашла этот общий элемент и выбранный нейрон как раз его детектирует. Логично?
А теперь посмотрим что сделали ребята из Google. Вместо того чтобы искать в обученной нейросети вектор который бы максимизировал отклик какого-то одного нейрона (или набора нейронов), они считали взвешенную сумму активации всех нейронов одного слоя, выбирая при этом совершенно случайные веса. То есть результаты отдельных нейронов одного слоя просто случайным образом перемешивались в некую кашу, которая заведомо никакому детектированию специально не обучалась. Но прогоняем тот же самый процесс поиска в обучающей выборке изображений максимизирующих отклик этой случайной смеси, пристально вглядываемся в результат — и, надо же, тоже находим на картинках совершенно явные общие элементы. Упс. То есть одиночные нейроны в рамках подобной методики „дескремблируют“ изображение ничем не лучше чем случайная смесь из нейронов. Но как можно говорить тогда о том что нейросеть раскладывает входные данные на отдельные осмысленные компоненты, по одному на нейрон?
Всё бы хорошо, но у меня на планшете как раз есть моя собственная нейронная сетка, рисующая картинку птички. В ней всего 30 нейронов, и меньше 200 синапсов. Я на обеденном перерыве из интереса подёргал за 8 из 30 нейронов, и успел обнаружить там нейрон отвечающий за границы леса на заднем фоне, нейрон, раскрашивающий красным цветом всю картинку кроме собственно птички, Нейрон отвечающий за синий ореол над голове птички и по бокам, нейрон, который урпавляет зоной, на которую нужно наносить полосатенькую расцветочку, и так далее. Это только из тех которые я на перерыве подёргать успел. Там в первых слоях сидят нейроны отвечающие за геометрическую форму птички, так я там на днях дёргал за синапс, определяющий у птички ширину крыльев. Причём скомбинировать несколько нейронов и получить осмысленно выглядящий результат тут явно не получится, хотя бы потому что одни нейроны отвечают, например, за контрастность изображения, а другие за его пространственное положение. Если их между собой смешать вы получите птичку, которая сдвинута выше, а полосатые зоны на крыльях подсвечены. Но новым признаком это явно не является.
То есть ребята из гугла попросту не правы. А раз так, гораздо интереснее разобрать вопрос почему именно они не правы. Я предположил, что они не правы, потому что не умеют работать с глубиной, но, по вашим словам получается, что это не так. Значит проблема в другом.
Но если я на своей сетке вижу синапс, раскрашивающий законцовки крыльев в розовый цвет, убедить меня не верить своим глазам довольно трудно.
То есть ребята из гугла попросту не правы. А раз так, гораздо интереснее разобрать вопрос почему именно они не правы. Я предположил, что они не правы, потому что не умеют работать с глубиной, но, по вашим словам получается, что это не так. Значит проблема в другом.
Но если я на своей сетке вижу синапс, раскрашивающий законцовки крыльев в розовый цвет, убедить меня не верить своим глазам довольно трудно.
Если их между собой смешать вы получите птичку, которая сдвинута выше, а полосатые зоны на крыльях подсвечены. Но новым признаком это явно не является.
Так в том и суть. Кажется что должна получиться полная чушь. А на практике этого не случается. И я не думаю что это ошибка ребят из гугла, поскольку они реально поставили соответствующий эксперимент, а следствие фатальной ошибки в методике поиска «детектируемых признаков».
Поклонники Элона Маска мне карму в минус забили, так что отвечать чаще чем раз в час не могу.
Во-первых, существование «нейрона Дженифер Анистон» в реальном мозге уже доказанный факт. То есть нейросети в биологии успешно реализовали то, что искусственные сети от гугла сделать не могут. Но даже не это главное.
Ещё раз, я говорю не об общих теоретических рассуждениях, а о реальной сети. С которой я всё это проделал пару часов назад. В ней есть синапс, например, который отвечает за раскраску законцовок крыльев в рыжий цвет. Я его своими руками обнулил и видел как раскраска крыльев сменилась на коричневый. Это было единственное рыжее пятно на всей картинке, спутать его не с чём. Что мне теперь предлагаете делать? Выцарапать себе глаза потому что гугл сказал, что так не бывает? Ладно бы у меня были тысячи нейронов, но у меня их 30 штук, я с каждым из них, что называется, в лицо знаком. :-\
Во-первых, существование «нейрона Дженифер Анистон» в реальном мозге уже доказанный факт. То есть нейросети в биологии успешно реализовали то, что искусственные сети от гугла сделать не могут. Но даже не это главное.
Ещё раз, я говорю не об общих теоретических рассуждениях, а о реальной сети. С которой я всё это проделал пару часов назад. В ней есть синапс, например, который отвечает за раскраску законцовок крыльев в рыжий цвет. Я его своими руками обнулил и видел как раскраска крыльев сменилась на коричневый. Это было единственное рыжее пятно на всей картинке, спутать его не с чём. Что мне теперь предлагаете делать? Выцарапать себе глаза потому что гугл сказал, что так не бывает? Ладно бы у меня были тысячи нейронов, но у меня их 30 штук, я с каждым из них, что называется, в лицо знаком. :-\
Что происходит в мозгу у человека я не знаю — да и, полагаю, никто не знает. Меня интересуют лишь компьютерные нейронные сети, биологические — это отдельная самостоятельная тема (и там вполне возможны аналогичные косяки с интерпретацией результатов экспериментов)
Относительно Вашей реальной сети, я не могу Вам ничего содержательно возразить пока Вы не объясните мне что у Вас за сеть.
Что за картинки генерируются Вашей сетью? Обычно сеть используют для распознавания картинок и именно этот эксперимент был поставлен в Google. Я проинтерпретировал Ваши слова аналогично гугловскому эксперименту: Вы взяли сеть и обучили её на базе из некоторого кол-ва картинок распознавать картинки где есть бабочка. Затем Вы стали смотреть какие картинки вызывают срабатывание каких нейронов (аналогично «нейрону Дженифер Астон») и нашли что этот нейрон срабатывает, скажем, если законцовка крыльев бабочки имеет рыжий цвет. Вот в рамках этой модели если Вы возьмете не один нейрон, а случайную комбинацию из десяти и посмотрите что вызывает срабатывание этой комбинации, то окажется, что есть некий признак (возможно совершенно несхожий с признаками каждого из 10 использованных нейронов) который соответствует этой комбинации.
Но, судя по всему, у Вас какая-то другая модель нейросети, которая не распознает, а генерирует картинки? Можно ли узнать какие?
Относительно Вашей реальной сети, я не могу Вам ничего содержательно возразить пока Вы не объясните мне что у Вас за сеть.
Что за картинки генерируются Вашей сетью? Обычно сеть используют для распознавания картинок и именно этот эксперимент был поставлен в Google. Я проинтерпретировал Ваши слова аналогично гугловскому эксперименту: Вы взяли сеть и обучили её на базе из некоторого кол-ва картинок распознавать картинки где есть бабочка. Затем Вы стали смотреть какие картинки вызывают срабатывание каких нейронов (аналогично «нейрону Дженифер Астон») и нашли что этот нейрон срабатывает, скажем, если законцовка крыльев бабочки имеет рыжий цвет. Вот в рамках этой модели если Вы возьмете не один нейрон, а случайную комбинацию из десяти и посмотрите что вызывает срабатывание этой комбинации, то окажется, что есть некий признак (возможно совершенно несхожий с признаками каждого из 10 использованных нейронов) который соответствует этой комбинации.
Но, судя по всему, у Вас какая-то другая модель нейросети, которая не распознает, а генерирует картинки? Можно ли узнать какие?
ПО всей видимости, об этом будет статья. Со всей очевидностью её теперь придётся писать.
habrahabr.ru/post/249031/
написал на этот счёт статью со своими сетями и подробным разбором что и как там внутри сетей. Не прошло и пол года. Хотя нет, прошло.
написал на этот счёт статью со своими сетями и подробным разбором что и как там внутри сетей. Не прошло и пол года. Хотя нет, прошло.
Картинки в студию. В статье отлично видны результаты второго эксперимента — но не первого.
Честно говоря, у меня такое ощущение, что попросту проверялись мусорные нейроны, которые особо ни за что не отвечают.
Честно говоря, у меня такое ощущение, что попросту проверялись мусорные нейроны, которые особо ни за что не отвечают.
Читайте первоисточник, ссылка приведена в начале статьи
cs.nyu.edu/~zaremba/docs/understanding.pdf
Смотрите на Fig. 1 — результаты для отдельных нейронов и Fig. 2 — результаты для случайной комбинации нейронов
cs.nyu.edu/~zaremba/docs/understanding.pdf
Смотрите на Fig. 1 — результаты для отдельных нейронов и Fig. 2 — результаты для случайной комбинации нейронов
Теперь понял, о чем вы говорили. Но интерпретация результатов исследования все равно выходит странной. Исследование попросту говорит о том, что картинка, максимизирующая отклик нейрона не является тем признаком, который нейрон ищет. Для этого достаточно взглянуть на картинку Fig. 1b:
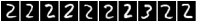
Можно подумать, что эта нейросеть ищет двойки среди прочих цифр, хотя вообще-то ее задача — поиск любых цифр, просто двойки оказались самыми цифровыми среди исходного набора…
На самом деле, контрпример построить еще проще, не надо даже делать никаких экспериментов, кроме мысленного. Возьмем нейросеть, и обучим ее распознавать котиков и собачек, отнеся их обязательно в один класс. Теперь попробуем выяснить, какой именно признак «ищет» выходной нейрон. Если сеть обучена правильно, этот признак никак не может быть котико-собачным мутантом, он может быть либо котиком, либо собачкой, в зависимости от того, чей отклик случайно оказался чуть-чуть больше. Допустим, это был котик. Означает ли это, что нейрон, дающий одинаково высокие отклики как на котиков, так и на собачек, ищет исключительно кошачие признаки?
Подводя итог всему вышесказанному, нейрон, особенно старших слоев, может искать признак любой сложности, и логику его работы невозможно представить одной картинкой, что пытались делать исследователи.

Можно подумать, что эта нейросеть ищет двойки среди прочих цифр, хотя вообще-то ее задача — поиск любых цифр, просто двойки оказались самыми цифровыми среди исходного набора…
На самом деле, контрпример построить еще проще, не надо даже делать никаких экспериментов, кроме мысленного. Возьмем нейросеть, и обучим ее распознавать котиков и собачек, отнеся их обязательно в один класс. Теперь попробуем выяснить, какой именно признак «ищет» выходной нейрон. Если сеть обучена правильно, этот признак никак не может быть котико-собачным мутантом, он может быть либо котиком, либо собачкой, в зависимости от того, чей отклик случайно оказался чуть-чуть больше. Допустим, это был котик. Означает ли это, что нейрон, дающий одинаково высокие отклики как на котиков, так и на собачек, ищет исключительно кошачие признаки?
Подводя итог всему вышесказанному, нейрон, особенно старших слоев, может искать признак любой сложности, и логику его работы невозможно представить одной картинкой, что пытались делать исследователи.
Нейросеть в этом примере не ищет цифры, она распознает какая именно рукописная цифра ей предъявлена, от 0 до 9. Так что как раз приведенный пример вполне можно было бы интерпретировать именно как то что данный нейрон «узнает» двойку среди всех остальных цифр. Но авторы, вообще говоря, таких обобщений не делали, на картинке Fig. 1b, по их мнению, изображены картинки на которые реагирует нейрон, распознающий полукруглый штрих в верхней части картинки и прямой штрих в нижней.
Кроме того в чем странность логики-то? Авторы не изобретали своей логики, они использовали типовой штамп исследователей нейросетей который заключается в том что если отдельный нейрон срабатывает, скажем, при предъявлении в серии картинок картинки Дженнифер Лопес и не срабатывает при предъявлении других картинок из серии, то этот нейрон занимается тем что «узнает» Дженнифер Лопес. Эта серия картинок — как раз моделирование подобного эксперимента и это моделирование ставит под вопрос эту логику.
Что касается Вашего мысленного эксперимента, то в гугловском эксперименте искалось-то не одно, максимальное, изображение, а серия. И логично предположить что для Вашего гипотетического котико-собачьего детектора в этой серии окажется какое-то число изображений котиков и какое-то число изображений собак, что, собственно, и будет служить для наблюдателя подтверждением версии о том что этот нейрон детектирует кошек и собак. При этом в исследовании, вообще говоря, не рассматривались нейроны выходного слоя, поскольку с ними все более-менее и так ясно, их выходы напрямую оптимизируются под желаемый результат. Вопрос стоял в том как именно они этого результата достигают и в рамках этого вопроса рассматривалась популярная гипотеза о том, что нейроны промежуточных слоев детектируют какие-то разумные признаки типа, к примеру, наличия на картинке животного или наличия на картинке ушей. Из практики известно что действительно если взять отдельный нейрон в обученной сети и посмотреть на какую серию картинок он реагирует, то между картинками этой серии можно найти много общего (ну то есть например на всех картинках будут присутствовать уши). Этот результат сейчас часто принято интерпретировать как свидетельство правильности гипотезы о том что сеть декомпозирут сложную проблему (распознавание котов и собак) на более простые (поиск ушей в изображении). Гугловская работа ставит этот тезис под большой вопрос поскольку показывает что подобные «общие признаки» в серии можно найти и просто взяв случайную смесь нейронов выбранного промежуточного слоя.
Кроме того в чем странность логики-то? Авторы не изобретали своей логики, они использовали типовой штамп исследователей нейросетей который заключается в том что если отдельный нейрон срабатывает, скажем, при предъявлении в серии картинок картинки Дженнифер Лопес и не срабатывает при предъявлении других картинок из серии, то этот нейрон занимается тем что «узнает» Дженнифер Лопес. Эта серия картинок — как раз моделирование подобного эксперимента и это моделирование ставит под вопрос эту логику.
Что касается Вашего мысленного эксперимента, то в гугловском эксперименте искалось-то не одно, максимальное, изображение, а серия. И логично предположить что для Вашего гипотетического котико-собачьего детектора в этой серии окажется какое-то число изображений котиков и какое-то число изображений собак, что, собственно, и будет служить для наблюдателя подтверждением версии о том что этот нейрон детектирует кошек и собак. При этом в исследовании, вообще говоря, не рассматривались нейроны выходного слоя, поскольку с ними все более-менее и так ясно, их выходы напрямую оптимизируются под желаемый результат. Вопрос стоял в том как именно они этого результата достигают и в рамках этого вопроса рассматривалась популярная гипотеза о том, что нейроны промежуточных слоев детектируют какие-то разумные признаки типа, к примеру, наличия на картинке животного или наличия на картинке ушей. Из практики известно что действительно если взять отдельный нейрон в обученной сети и посмотреть на какую серию картинок он реагирует, то между картинками этой серии можно найти много общего (ну то есть например на всех картинках будут присутствовать уши). Этот результат сейчас часто принято интерпретировать как свидетельство правильности гипотезы о том что сеть декомпозирут сложную проблему (распознавание котов и собак) на более простые (поиск ушей в изображении). Гугловская работа ставит этот тезис под большой вопрос поскольку показывает что подобные «общие признаки» в серии можно найти и просто взяв случайную смесь нейронов выбранного промежуточного слоя.
По поводу того, что признаки не отображаются на отдельные нейтроны, замечу, что в этом нет никакого математического смысла, пока они не оцениваются целевой функцией. Веса, влияющие на какой-то один определенный выходной нейрон могут быть распределены среди произвольного количества нейронов предыдущего слоя — главное чтобы в сумме они достигали его порога.
Если проводить аналогии с фон-Неймановым «адресным пространством», то в типичной нейронной сети нет нумерации, и поэтому отдельные «биты» определенной информации могут отображаться на разные части разных «байтов» из которых они потом собираются с помощью логических операций.
Однако, существуют методики, которые перераспределяют веса и пороги между нейронами так, что определенные максимизируются.
Если проводить аналогии с фон-Неймановым «адресным пространством», то в типичной нейронной сети нет нумерации, и поэтому отдельные «биты» определенной информации могут отображаться на разные части разных «байтов» из которых они потом собираются с помощью логических операций.
Однако, существуют методики, которые перераспределяют веса и пороги между нейронами так, что определенные максимизируются.
Веса, влияющие на какой-то один определенный выходной нейрон могут быть распределены среди произвольного количества нейронов предыдущего слоя — главное чтобы в сумме они достигали его порога.
Так в этом случае признак просто отображается на этот единственный выходной нейрон — значение его активации прямо коррелирует с наличием признака, верно?
А популярная идея состоит в предположении что не только выходной, но и в целом каждый нейрон в сети есть отображение какого-то признака, начиная с простейших в нижних слоях и постепенно усложняющихся по мере приближения к выходному. А на выходном, соответственно, признак самый сложный. И стало быть чем больше слоев в сети — тем более сложные признаки сеть сможет детектировать. То есть нейросеть не просто случайным образом перемешивает данные, а вначале разлагает их на какие-то фундаментальные осмысленные кирпичики, а затем «собирает» из этих кирпичиков некий осмысленный критерий.
Математически в этом нет смысла, но можно придумать методику исследования нейросетей которая создает иллюзию того что и отдельные нейроны в сети действительно детектируют осмысленные фичи. Получается недоказуемая, но вроде бы как подтверждаемая экспериментально теория. А гугловская работа интересна тем что там приводятся сильные аргументы показывающие что «экспериментальные доказательства», по видимому, являются простым артефактом используемой методики и выдаванием желаемого за действительное.
А как же «Бабушкины нейроны» в сетях от Andrew Ng, который тоже ex-google?
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Что скрывают нейронные сети?