Этот цикл статей описывает волновую модель мозга, серьезно отличающуюся от традиционных моделей. Настоятельно рекомендую тем, кто только присоединился, начинать чтение с первой части.
Информация, которой оперирует мозг, должна, с одной стороны, достаточно полно описывать происходящее, с другой стороны, должна храниться так, чтобы допускать выполнение над собой требуемых мозгу операций. В принципе, формат описания информации и алгоритмы ее обработки – вещи тесно связанные между собой. Первое во многом определяет второе. Поэтому говоря о том, как могут быть организованы данные, хранимые мозгом, мы, хотим того или нет, во многом предопределяем систему последующих мыслительных процессов. Так как разговор о принципах мышления нам предстоит позже, то сейчас мы сделаем акцент только на том, как обеспечить полноту текущего описания и последующего хранения информации. При этом подразумевая, что если, дойдя до мышления, окажется, что выбранный нами формат данных подошел под требуемые алгоритмы, то значит, нам повезло и мы пошли по правильному пути.
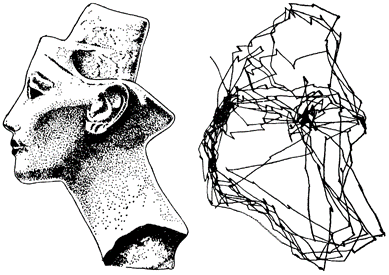
Чтобы понять, какой формат описаний использует мозг, проследим последовательность зрительного восприятия. Разглядывая изображение, мы «сканируем» его быстрыми движениями глаз, называемыми саккадами (рисунок на КДПВ). Каждая из них помещает в центр зрения один из фрагментов общей картины. На зонах зрительной коры возникают описания, соответствующие тому, что мы видим в этот момент в центре, что видит периферия и каково смещение в результате только что проделанной саккады. Каждая следующая саккада порождает новую картину. Эти описания сменяют друг друга одно за другим.
Так, разглядывая лицо, мы сначала, например, четко видим и распознаем один глаз, тот на который направлен взгляд. Остальные элементы лица, попадающие на относительную периферию зрения — нос, рот и так далее, мы узнаем с меньшей, но то же достаточно высокой вероятностью. После каждой саккады центральный фрагмент меняется, но общий набор узнанных элементов сохраняется неизменным.
В принципе, каждого из таких отдельных описаний, возникающих между саккадами, достаточно чтобы сказать, что перед нами лицо и даже узнать, кому оно принадлежит. Но каждое отдельное описание достоверно говорит только о том объекте, который для него расположен по направлению взгляда. Остальные объекты определяются достаточно приблизительно.
Если мы захотим получить более полное и подробное представление о лице, то для этого подойдет совокупность всех описаний, которые возникнут во время сканирования. При этом важно будет не только описание того, что за объекты узнаны, но и информация об сопутствующих смещениях взгляда. И тут мы подходим к очень важному моменту. Что же является тем итоговым описанием, которое должен выдавать зрительный анализатор? Просто картина активности ряда понятий? Это соответствует только той части описания, что мы видим прямо сейчас. А как же остальное? Получается, что корректное, не теряющее информации, описание – это пакет следующих друг за другом более простых описаний. Где каждый из слоев такого временного пакета описывает только некоторую часть информации, а полное описание получается, как их совокупность. Это справедливо при условии, что все описания в пакете соответствуют одному событию, то есть, получены до глобального переключения нашего внимания.
Если взять моментальный снимок активности коры мозга, то описание происходящего можно сопоставить с перечислением активных понятий на каждой из ее зон. Но такое описание имеет существенный недостаток. Предположим, что мы хотим описать натюрморт, изображенный на рисунке ниже.
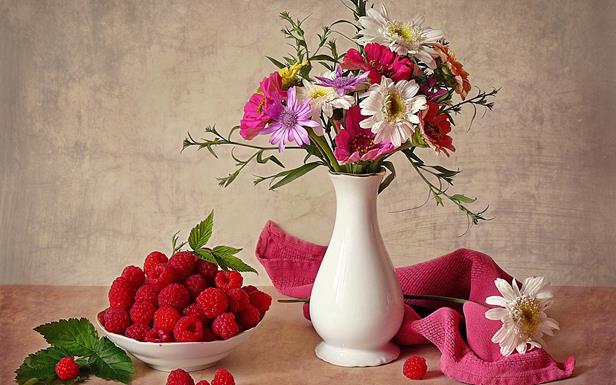
Мы можем это сделать, например, так:
- Ваза чуть правее центра;
- Букет в вазе;
- Полотенце справа от вазы;
- Белый цветок на полотенце;
- Миска с малиной слева;
- Малина на листе слева от миски;
- Три малины перед миской;
- Малина справа от вазы.
Общее описание складывается из набора таких коротких описаний. Каждое короткое описание можно, с некоторыми оговорками, заменить перечислением понятий, входящих в него. Но если мы захотим собрать итоговое описание, просто сложив все понятия, участвующие в коротких перечислениях, то нас постигнет неудача. При сложении исчезнет часть информации, так как станет непонятно, что к чему относится. Но, кроме того, окажется, что надо некоторые понятия использовать несколько раз. Например, малина она и слева, и справа, и перед миской. А если мы хотим использовать это «просто собранное» описание как аналогию того, как описывается такой натюрморт на зонах коры, то окажется, что обобщение «малина» у нас одно и оно не может одновременно быть «активным три раза». Выход из этого положения, который мне видится вполне логичным, — это использовать пакетное описание. Каждое простое описание может складываться из банального перечисления активных понятий. Полное же описание получается, как набор простых описаний. Поскольку простые описания разнесены между собой по времени, то, с одной стороны, понятно, что к чему относится, а, с другой стороны, одно и то же понятие может возникать несколько раз в разных слоях пакета в разных контекстах.
Такое пакетное представление очень хорошо соотносится с рассуждениями относительно объема внимания человека. Психологи, изучая свойства внимания, установили, что есть предел того количества объектов, на которых человек может одновременно сконцентрироваться. Обычно этот предел не превышает семи объектов. Первым измерения объема внимания с использованием механического тахистоскопа сделал основатель экспериментальной психологии Вильгельм Вундт.

Тахитоскоп – прибор, с помощью которого можно предъявлять последовательные зрительные стимулы
Оценить объем внимания очень просто. Посмотрите на предыдущий натюрморт и попробуйте сосчитать, сколько отдельных элементов вы способны, нет, не запомнить, это другое, а удержать в голове одновременно. Или возьмите семизначный телефонный номер, например, 1145618 и попробуйте «удержать» его в голове. Скорее всего, чтобы он не пропал, вам придется зациклено повторять его про себя. Если цифр в номер будет больше семи, что велик шанс, что удержать их все в памяти не удастся. Предельное количество воспринимаемых одновременно объектов натюрморта или цифр номера дает оценку объему вашего внимания.
Сделанное нами предположение о пакетном представлении информации в коре мозга позволяет сопоставить каждый из объектов, удерживаемых во внимании, с одним из слоев информационного пакета.
Если представить кору, состоящую из небольшого количества понятий, способную формулировать совсем простые мысли относительно двух объектов «A» и «B», то пакет, соответствующий мысли: «красный объект A лежит на синем объекте B», будет выглядеть, как показано на рисунке ниже.
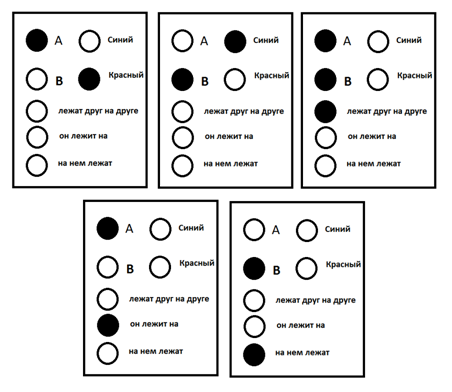
Пример информационного пакета
Кодирование сложных описаний
Вернемся к памяти и попробуем систематизировать, с какими типами информации, и, соответственно, типами описаний умеет оперировать наш мозг.
Первый тип – это простое описание, которое соответствует картине мгновенной активности коры. Это сочетание тех понятий, что детектированы мозгом именно сейчас.
Второй тип – это пакет простых описаний, соответствующих одному событию, одной мысли. В пакете несущественен порядок следования описаний. Перестановка слоев пакета не меняет общего смысла высказывания. Вспоминание пакета – это восстановление серии следующих друг за другом простых описаний.
Третий тип – это позиционное описание. В таком описании сохраняется связь одних объектов с другими, находящимися с ними в определенной системе отношений. Например, разновидность такого описания – это пространственное описание. Когда мы не просто фиксируем свое положение в пространстве, а увязываем его определенными описаниями с расположением других объектов.
Четвертый тип – это процедурное описание. Такое описание, в котором важна последовательность смены образов и сопутствующие этому интервалы. Например, восприятие речи определяется последовательностью звуков, при этом соотношение интервалов формирует интонацию, от которой сильно зависит общий смысл услышанной фразы. Вспоминание процедуры – это воспроизведение соответствующей последовательности образов.
И пятый тип – это хронологическое описание. Фиксация на продолжительных отрезках времени того в какой последовательности и с какими временными интервалами происходили те или иные события. Возможность вспомнить для хронологической памяти – это не воспроизведение сразу всего, относящегося к одной хронологии, а возможность перейти от одного описания к другому, связанному с ним общей временной последовательностью.
Несложно заметить, что многие описания так или иначе завязаны на время. Пакетное описание – это серия следующих друг за другом образов. Процедурное описание учитывает последовательность событий. Хронологическое описание требует учета позиционирования событий во времени.
Такая зависимость описаний от времени послужила поводом к возникновению соответствующих моделей. Наиболее известная из них – это пропагандируемая Джефом Хокинсом концепция иерархической темпоральной памяти (HTM) (Хокинс, 2011). Он и его коллеги исходят из того, что темпоральная смена событий – это единственное, что позволяет связать между собой отдельные информационные образы. Из этого делается вывод, что базовый информационный элемент коры должен работать не со статичными образами, а с временной последовательностью. В концепции HTM элемент хранения информации – это развернутая во времени последовательность сигналов. Узнавание – это определение совпадения двух последовательностей. При этом особый акцент делается на способность HTM к предсказанию. Как только нейрон узнает начало знакомой ему последовательности, он становится способен по своему опыту предсказать запомненное им продолжение. Описание текущей картины в HTM – это активность тех нейронов, которые откликнулись на текущую смену событий.
Сложности такого подхода достаточно очевидны. Во-первых, требование соблюдения временных масштабов. Небольшое ускорение или задержка в поступлении данных могут нарушить алгоритм узнавания. Во-вторых, необходимость переводить все статичные образы во временные последовательности перед тем, как кора сможет с ними оперировать. И тому подобное.
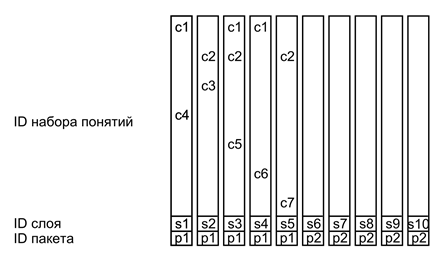
В нашей модели система идентификаторов дает нам универсальный инструмент, который одинаково хорошо подходит для описания всех возможных типов памяти. Основная идея проста – каждое простое описание представляет собой составной идентификатор, содержащий в себе все необходимое для указания всего набора, как ассоциативных, так и временных взаимосвязей.
На рисунке ниже приведено условное изображение такого простого описания. Простое описание – это волна, несущая в себе несколько наборов идентификаторов разных типов. Основное содержание кодируется набором идентификаторов понятий, описывающих суть происходящего. Идентификатор слоя помечает основное содержание, отделяя его от остальных простых описаний. Идентификатор пакета объединяет несколько слоев, относящихся к одному сложному описанию. Идентификаторы места, времени и последовательности создают систему соответствующих связей между сложными описаниями.
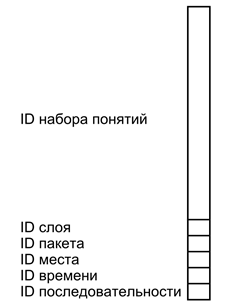
Формат простого описания
Возьмем предыдущий пример и обозначим волны идентификаторов, соответствующие используемым понятиям (concepts), как C1...C7 (рисунок ниже).
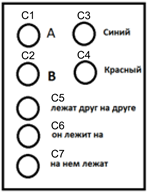
Понятия, используемые для описания
Тогда описание того, что «красный объект A лежит на синем объекте B» будет выглядеть, как показано на рисунке ниже.
Пример сложного описания
В этом примере каждый из слоев пакета является простым описанием со своим идентификатором слоя. Все слои пакета имеют общий идентификатор пакета p1. Когда заканчивается одно сложное описание, другое, следующее за ним имеет отличный от него идентификатор пакета p2 (понятия второго описания на рисунке не показаны).
Чтобы такая конструкция была работоспособной, мозгу необходима достаточно сложная система, создающая идентификаторы, формирующие пакеты. Причем для каждой из зон коры может потребоваться свой набор таких идентификаторов, уместный именно для нее.
Например, возьмем последовательность зрительного восприятия. Скачкообразные микродвижения глаз, называемые микросаккадами, заставляют глаз сканировать малый фрагмент изображения, приходящийся на центр сетчатки. Все образы, которые получаются в процессе такого сканирования, предположительно могут объединяться общим идентификатором. Микродвижениями глаз управляют верхние бугорки четверохолмия. Можно предположить, что именно они кодируют такой идентификатор. После нескольких микросаккад происходит сильный прыжок, называемый саккадой (выше на рисунке с головой Нефертити показаны именно саккады). Каждая саккада вызывают смену идентификатора микросаккад.
Можно предположить, что микросаккады принципиально важны для первичной зрительной коры. Общий идентификатор сообщает коре, что сери подряд идущих образов описывает один и тот же объект, но в разных его позициях на сетчатке, что позволяет объединить их в единое описание и реализовать инвариантное к положению на сетчатке узнавание.
Более продолжительное событие — серия саккад. Так как серия относится к разглядыванию единой картины, то получаемые описания тоже можно связать между собой еще одним общим идентификатором – идентификаторам саккад. Но этот идентификатор существенен уже не для первичной, а для вторичной и более глубоких уровней зрительной коры, где происходит последующая обработка информации. Идентификатор, сообщающий коре, что все, что мы видим во время серии саккад – это одна и та же картина, позволяет соотнести между собой одни и те же образы, видимые разными местами сетчатки.
Смена идентификатора саккад должна происходить, когда существенно меняется разглядываемая картина. Например, при сильном повороте головы, переключении внимания, смене плана или сцены в кино. Переключение внимания может кодироваться элементами лимбической системы мозга и распространяться на множество, завязанных на это, зон коры. Одновременно с этим в системе описаний присутствуют идентификаторы гиппокампа, кодирующие пространственно-временные описания событий. Короче, система идентификаторов, определяющих пакет, может быть достаточно сложна, и определяться особенностями той информации, с которой имеет дело каждая конкретная зона коры.
Используя идентификаторы несложно организовать фиксацию последовательности событий. Например, если взять идентификатор, состоящий из двух фрагментов, то поочередно меняя по одному из них, можно получить ассоциативную связанность соседних описаний (рисунок ниже).
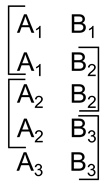
Кодирование последовательности
Каждый такой идентификатор будет содержать элемент от предыдущего и последующего идентификатора. Запомнив временную последовательность образов с такими идентификаторами, мы для каждого образа сможем найти его двух соседей по временной шкале. Несложно усложнив идентификатор можно закодировать не только общую связанность, но и направление течения времени.
Надо отметить, что в нашей модели каждое воспоминание имеет богатую систему идентификаторов. Это позволяет получить доступ к воспоминанию через множество совершенно различных ассоциаций. Можно вспомнить что-либо, исходя из совпадения смыла описаний. Можно проассоциировать информационные картины по месту или времени описываемых событий. Можно воспроизвести последовательность образов, относящихся к одному событию. Нетрудно заметить, что такой доступ к воспоминаниям имеет много общего с подходами, которые используются при создании традиционных реляционных баз данных.
Использованная литература
Продолжение
Предыдущие части:
Часть 1. Нейрон
Часть 2. Факторы
Часть 3. Персептрон, сверточные сети
Часть 4. Фоновая активность
Часть 5. Волны мозга
Часть 6. Система проекций
Часть 7. Интерфейс человек-компьютер
Часть 8. Выделение факторов в волновых сетях
Часть 9. Паттерны нейронов-детекторов. Обратная проекция
Часть 10. Пространственная самоорганизация
Часть 11. Динамические нейронные сети. Ассоциативность
Часть 12. Следы памяти
Часть 13. Ассоциативная память
Часть 14. Гиппокамп
Часть 15. Консолидация памяти
Алексей Редозубов (2014)







