Комментарии 83
Я бы предложил начать изучение SAN с изучения английского языка хотя бы на уровне свободного чтения. Всё равно без английского толку не будет.
Как-то делал наглядную картинку для коллег
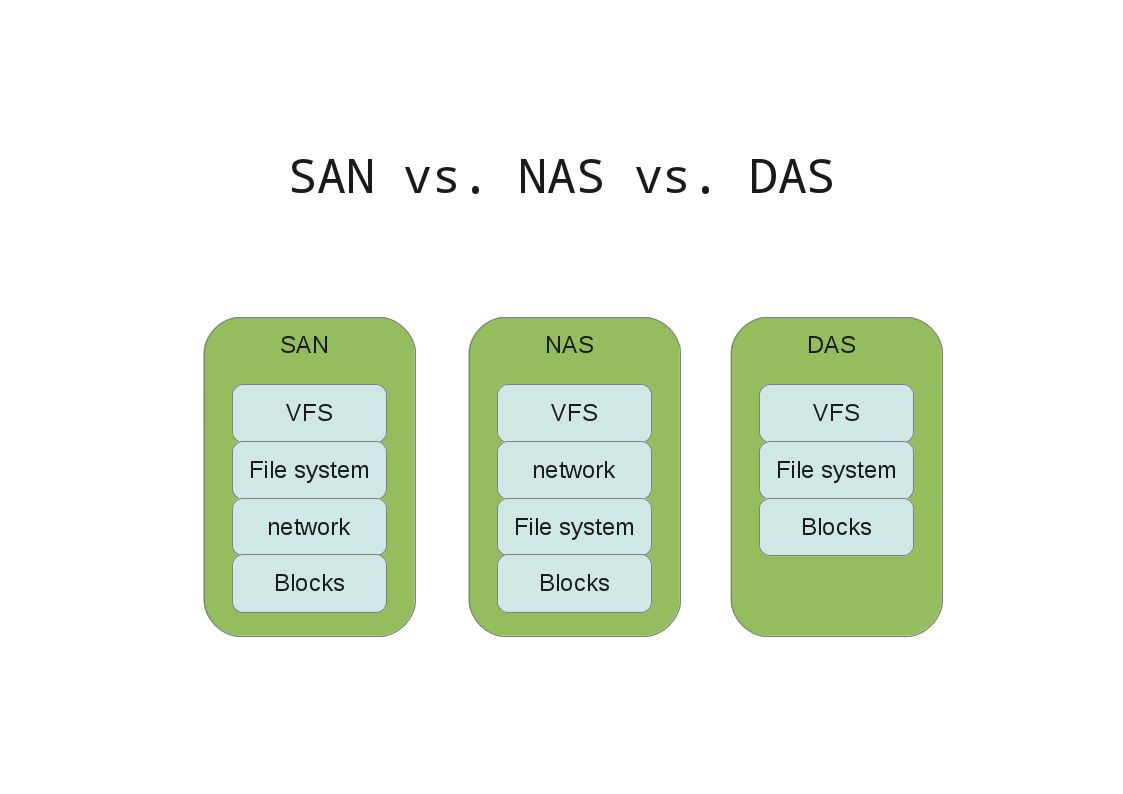

Ну и SAN это не только FC, но и ISCSI. Очень часто используется параллельно. В частности, ISCSI дублирует FC для надёжности, но при этом цена вопроса не возрастает в двое.
НЛО прилетело и опубликовало эту надпись здесь
Никогда не говори никогда
www.divshare.com/direct/24958051-947.pdf
Вопрос 52:
QUESTION 52
What is the functionality of the latest Data ONTAP DSM for Windows?
A. It can handle FCP and iSCSI paths to the same LUN.
B. It allows you to take snapshots for both FCP and iSCSI LUNS.
C. It allows you to enable ALUA on the igroup from the host.
D. It allows you to create new LUNs from the host.
Correct Answer: A
class10e.com/NetworkAppliance/what-is-the-functionality-of-the-latest-data-ontap-dsm-for-windows/
www.divshare.com/direct/24958051-947.pdf
Вопрос 52:
QUESTION 52
What is the functionality of the latest Data ONTAP DSM for Windows?
A. It can handle FCP and iSCSI paths to the same LUN.
B. It allows you to take snapshots for both FCP and iSCSI LUNS.
C. It allows you to enable ALUA on the igroup from the host.
D. It allows you to create new LUNs from the host.
Correct Answer: A
class10e.com/NetworkAppliance/what-is-the-functionality-of-the-latest-data-ontap-dsm-for-windows/
НЛО прилетело и опубликовало эту надпись здесь
Нормально все у NetApp c FCP. Проблем за очень многолетний опыт и общение с кучей систем нетаппа не встречал, именно по вине нетапп. А так был пример, что спокойно LUN шарится по FC и iSCSI и все отлично работает в общем доступе на более чем 40 хостов.
ALUA только в таком совместном использовании не работает.
ALUA только в таком совместном использовании не работает.
НЛО прилетело и опубликовало эту надпись здесь
А мне страшно пускать инженера который конфигурит СХД из GUI.
НЛО прилетело и опубликовало эту надпись здесь
Похоже вы тестировали FAS3240 (не FAS3420) со старой операционкой. В 8.х которая вышла уже как пару лет больше нет Filer View (если вы об этом), а есть отдельная утилита ставящаяся на управляющий хост, называется Oncommand SystemManager.
На счёт стоимости это как посмотреть. Если вы изучили DataOntap для любой модели, то имея разные модели NetApp ничему учиться больше не нужно.
А вот у того же HP куча зоопарка которому нужно учиться: EVA/3PAR/P9000 — это всё кардинально разные продукты.
На счёт стоимости это как посмотреть. Если вы изучили DataOntap для любой модели, то имея разные модели NetApp ничему учиться больше не нужно.
А вот у того же HP куча зоопарка которому нужно учиться: EVA/3PAR/P9000 — это всё кардинально разные продукты.
НЛО прилетело и опубликовало эту надпись здесь
Filer View давно вырезали из функционала. Тот действительно был не достаточно удобный и выгляел скуповато. Вы по http на файлер заходили или на 127.0.0.1 запустив иконку на рабочем столе?
НЛО прилетело и опубликовало эту надпись здесь
Тогда это точно Oncommand SystemManager (не путать с Filer View, а Oncommand View вообще не существует).
Ну и разве вам интерфейс не понравился? А глубокие инженерные фичи так они всегда прячутся от «шаловливых ручёнок» :)
Ну и разве вам интерфейс не понравился? А глубокие инженерные фичи так они всегда прячутся от «шаловливых ручёнок» :)
НЛО прилетело и опубликовало эту надпись здесь
Takeover есть и был во всех версиях OnCommand SystemManger.
Может вам инженер показывал который любит всё в консоли делать?
Оно когда к чему-то привыкнешь всё остальное в округе фигнёй кажется.
Про FreeNAS это вы загнули. Я честно сказать, сам иногда в этих кнопочках теряюсь :)
Может вам инженер показывал который любит всё в консоли делать?
Оно когда к чему-то привыкнешь всё остальное в округе фигнёй кажется.
Про FreeNAS это вы загнули. Я честно сказать, сам иногда в этих кнопочках теряюсь :)

НЛО прилетело и опубликовало эту надпись здесь
Так он не переростает, он так и начинался :)
Про ownership вы как конечный заказчик ни сном ни духом знать не должны :)
Другой вопрос почему вы об этой процедуре узнали. В свете вышесказанного про демо-тест могу предположить, что вам приехали запчасти или может даже диски от «разных» СХД, что часто имеет место при тестах. К примеру как вы могли знать FAS2240 может легко превращаться в «полку» — одним нужна СХД 2240, другим полка для 3240, а денег у интегратора на все «хочу» — нет. В результате конечный заказчик смотрит на страшную процедуру назначения ownership дисков из какого-то «maitanance mode», да и ещё через командную строку, полагаю это действительно может отпугнуть и навеять «не юзабильность интерфейса». Далее клиент думает, «неужели мне всё-это самому потом делать, какой кашмар». Ничего делать не нужно, когда система приходит все диски уже перераспределены. Ну а если хотите «странного», то это к моему коменту про "инженерные" фичи. пускай ваш интегратор в следующий раз думает перед тем как везти какую-либо СХД по запчастям.
Почему у вас не работали SNMP трепы, не знаю, тут разбираться нужно. У меня Nagios с первого раза заработал и много других раз с первого раза. Было пару раз когда «не работало», оказалось, что люди или не ту версию SNMP использовали или забывали что поменяли community :)
А если хотите собирать статистику и видеть красивые графички — смотрите не в OnCommand System Manager — это не тот инструмент. А скачайте бесплатный для пользователей NetApp Oncommand Core (Unified manager). В этой статейке можно увидеть интерфейс. Настраивается очень гибко, уверен гибкость вас устроит, особенно на фоне прикрутки Nagios к чему-либо.
Про ownership вы как конечный заказчик ни сном ни духом знать не должны :)
Другой вопрос почему вы об этой процедуре узнали. В свете вышесказанного про демо-тест могу предположить, что вам приехали запчасти или может даже диски от «разных» СХД, что часто имеет место при тестах. К примеру как вы могли знать FAS2240 может легко превращаться в «полку» — одним нужна СХД 2240, другим полка для 3240, а денег у интегратора на все «хочу» — нет. В результате конечный заказчик смотрит на страшную процедуру назначения ownership дисков из какого-то «maitanance mode», да и ещё через командную строку, полагаю это действительно может отпугнуть и навеять «не юзабильность интерфейса». Далее клиент думает, «неужели мне всё-это самому потом делать, какой кашмар». Ничего делать не нужно, когда система приходит все диски уже перераспределены. Ну а если хотите «странного», то это к моему коменту про "инженерные" фичи. пускай ваш интегратор в следующий раз думает перед тем как везти какую-либо СХД по запчастям.
Почему у вас не работали SNMP трепы, не знаю, тут разбираться нужно. У меня Nagios с первого раза заработал и много других раз с первого раза. Было пару раз когда «не работало», оказалось, что люди или не ту версию SNMP использовали или забывали что поменяли community :)
А если хотите собирать статистику и видеть красивые графички — смотрите не в OnCommand System Manager — это не тот инструмент. А скачайте бесплатный для пользователей NetApp Oncommand Core (Unified manager). В этой статейке можно увидеть интерфейс. Настраивается очень гибко, уверен гибкость вас устроит, особенно на фоне прикрутки Nagios к чему-либо.
НЛО прилетело и опубликовало эту надпись здесь
Еще раз, 3420 нет такой модели у NetApp :) Конечно же я не могу знать. Но поверьте я вижу как интеграторы раз за разом делают это — привозят диски от другой системы, а потом на глазах заказчика без внятных объяснений переовнивают диски. Я считаю, что политически опрометчиво «на первом знакомстве» производить такие манипуляции. Вот посмотрите, вы сразу же предположили, что приовнивание должно быть в GUI. А вот я имея опыт с СХД NetApp, считаю, что этого категорически делать нельзя или делать это из «обычной» командной строки. Далее сделан был вывод, GUI «не доработан». А вот произойди всё то же самое в другой последовательности, я уверен такого «эффекта» не обнаружилось бы, поверьте опыту общения и демонстрации.
>интересует именно возможность в CLI
О теперь вы про CLI :)
FreeBSD, не FreeBSD, снять можно и это легко. Если не получилось это не значит, что так всегда, как я уже повторил — ни разу не имел проблемы со снятием статистики ни Nagios ни OnCommand Core из-за проблем с NetApp'ом. Детализация в обоих вариантах возможна идентичная, просто во втором случае это намного удобнее быстрее, автоматизированее и легче. Всю статистику, которую можно из CLI снимать можно и из них. В том числе LUN, RAID/Aggregate, дисков и т.д.
Кстати был реально случай, когда приехали диски от другой СХД, после приовнивания дисков, данные не стирались, а решили просто «подхватить» что было. Предыдущие тестеры настроили snmp community password, при тесте с первого раза этого не заметили, долго бились головой.
>интересует именно возможность в CLI
О теперь вы про CLI :)
FreeBSD, не FreeBSD, снять можно и это легко. Если не получилось это не значит, что так всегда, как я уже повторил — ни разу не имел проблемы со снятием статистики ни Nagios ни OnCommand Core из-за проблем с NetApp'ом. Детализация в обоих вариантах возможна идентичная, просто во втором случае это намного удобнее быстрее, автоматизированее и легче. Всю статистику, которую можно из CLI снимать можно и из них. В том числе LUN, RAID/Aggregate, дисков и т.д.
Кстати был реально случай, когда приехали диски от другой СХД, после приовнивания дисков, данные не стирались, а решили просто «подхватить» что было. Предыдущие тестеры настроили snmp community password, при тесте с первого раза этого не заметили, долго бились головой.
НЛО прилетело и опубликовало эту надпись здесь
Я вам говорю попробуйте OnCommand Core, а вы мне:
«уже видел у Symantec в виде Symantec NetBackup OpsCenter»
Не асбурд ли?
Функционал OnCommand Core на самом деле далеко не заканчивается назначением «для отчётности и SNMP трапов». Вы почитайте про него подробнее. Скорее сбор SNMP трапов там побочный эффект предназначенный для дополнительного функционала :)
А вы где-то видели инженерные фичи не спрятанные? Да уж %)
NetApp и многие другие вендоры инженерные фичи прячут, чтобы горе-админы не наступили сами себе на яйца. И это правильно, так должно быть. Это продакшн, а не ОС линукс общего назначения, где «что root сказал», «так тому и быть». Самая большая ценность и приоритет здесь данные, а не «админы» ;) А если уж кто-то хочет «странного», то пускай будут любезны, знают, как это делать — это называется «защита от дурака».
Поверьте, для нормального обслуживания СХД, GUI воплне достаточно. А если вы решили претендовать на звание «филда», то ни о каком GUI речь идти не может :)
Как вы могли понять из вышесказанного «вывод» был сделан поспешно, «познакомили» вас не лучшим образом.
«уже видел у Symantec в виде Symantec NetBackup OpsCenter»
Не асбурд ли?
Функционал OnCommand Core на самом деле далеко не заканчивается назначением «для отчётности и SNMP трапов». Вы почитайте про него подробнее. Скорее сбор SNMP трапов там побочный эффект предназначенный для дополнительного функционала :)
А вы где-то видели инженерные фичи не спрятанные? Да уж %)
NetApp и многие другие вендоры инженерные фичи прячут, чтобы горе-админы не наступили сами себе на яйца. И это правильно, так должно быть. Это продакшн, а не ОС линукс общего назначения, где «что root сказал», «так тому и быть». Самая большая ценность и приоритет здесь данные, а не «админы» ;) А если уж кто-то хочет «странного», то пускай будут любезны, знают, как это делать — это называется «защита от дурака».
Поверьте, для нормального обслуживания СХД, GUI воплне достаточно. А если вы решили претендовать на звание «филда», то ни о каком GUI речь идти не может :)
Как вы могли понять из вышесказанного «вывод» был сделан поспешно, «познакомили» вас не лучшим образом.
>Инженер при сборке нашего демо лишь потёр предыдущую конфигурацию :)
Так как NetApp это СХД А-Бренда, предназначенная для высоконагруженных систем в продакшн, функция «просто потереть конфигу» просто отсутствует :)
Есть два варианта: либо человек инициализирует все диски заново или создаёт новый root вольюм. В обоих случаях НЕТ неоходимости в переовнивании дисков, что тем не мение имело место у вас. Другими словами «простого» потирания конфиги небыло, было что-то ещё.
Переовинивание дисков может быть вызвано, как я уже говорил тем, что приехали диски «от другой» СХД. Либо же инженер исправлял то, что «наделали» предшественники настроив что-то «странное», что не соответствует бестпрактису, к примеру не равномерно распредилили диски между контроллерами. Либо наоборот: инженер сам делал вам что-то «странное». К сожалению в условиях демо-систем такая ситуация и в условиях демо-тестирования допускается, а также иногда имеет место быть из-за ограниченного количества оборудования и дисков в часности — содержать большой парк демо оборудования очень дорого. Ещё раз повторюсь в продакшн «странное» никто делать не должен — есть бестпрактис, это не ОС общего назначения. Не нужно забивать микроскопом гвозди. Самодеятельность в продакшн наказуема — как самый лучший вариант это лишиться техподдержки, как худший потерять данные. Сетовать потом можно только на себя.
Как резюме: ещё раз повторюсь:
1. В большинстве ситуаций закзчик не знает и никогда не узнает, про процедуру установки ownership и этот функционал не должен присутствовать в «лёгкой доступности».
2. Если претендуете на флда, готовьтесь использовать CLI.
3. Всё что доступно через GUI сделано так, чтобы вы «не думали», но были вынуждены соблюдать все бестпрактисы даже не зная о них (хотя если захотеть… помните поговорку про стеклянный предмет и дурака?)
4. Фич действительно очень много, если их нет в GUI это значит что их применение и использование требует знаний «филда» (читай п.2 ).
Так как NetApp это СХД А-Бренда, предназначенная для высоконагруженных систем в продакшн, функция «просто потереть конфигу» просто отсутствует :)
Есть два варианта: либо человек инициализирует все диски заново или создаёт новый root вольюм. В обоих случаях НЕТ неоходимости в переовнивании дисков, что тем не мение имело место у вас. Другими словами «простого» потирания конфиги небыло, было что-то ещё.
Переовинивание дисков может быть вызвано, как я уже говорил тем, что приехали диски «от другой» СХД. Либо же инженер исправлял то, что «наделали» предшественники настроив что-то «странное», что не соответствует бестпрактису, к примеру не равномерно распредилили диски между контроллерами. Либо наоборот: инженер сам делал вам что-то «странное». К сожалению в условиях демо-систем такая ситуация и в условиях демо-тестирования допускается, а также иногда имеет место быть из-за ограниченного количества оборудования и дисков в часности — содержать большой парк демо оборудования очень дорого. Ещё раз повторюсь в продакшн «странное» никто делать не должен — есть бестпрактис, это не ОС общего назначения. Не нужно забивать микроскопом гвозди. Самодеятельность в продакшн наказуема — как самый лучший вариант это лишиться техподдержки, как худший потерять данные. Сетовать потом можно только на себя.
Как резюме: ещё раз повторюсь:
1. В большинстве ситуаций закзчик не знает и никогда не узнает, про процедуру установки ownership и этот функционал не должен присутствовать в «лёгкой доступности».
2. Если претендуете на флда, готовьтесь использовать CLI.
3. Всё что доступно через GUI сделано так, чтобы вы «не думали», но были вынуждены соблюдать все бестпрактисы даже не зная о них (хотя если захотеть… помните поговорку про стеклянный предмет и дурака?)
4. Фич действительно очень много, если их нет в GUI это значит что их применение и использование требует знаний «филда» (читай п.2 ).
НЛО прилетело и опубликовало эту надпись здесь
>NetApp позиционирует себя как более NAS СХД
Кстати 60% продаж NetApp это SAN ;) Когда-то, чёрт знает когда, был только NAS, так до сих пор конкуренты поют старую песню :)
А у VNX когда-то чёрт-знает когда был только SAN, а теперь посмотрите на V-MAX и 70% использования NAS, так что теперь им вспоминать это спустя столько времени? Я бы назвал NetApp не NAS'овским производителем, а софтверным.
>Но всё это делает NetApp при детальном рассмотрении сильно нишевым продуктом с опредлёнными ограничениями
Ха :)
SAN, NAS, резервное копирование, виртуализация СХД, Disaster Recovery, архивирование, Compliance и этого мало? У большинства решений есть только «специализированное решение», а тут один раз учиться.
>странно работающая дедупликация при высоких нагрузках на массив (демон чаще уходит в сон)
Дедубликация работает в фоновом режиме, чтобы не нагружать СХД и не занимать ресурсы продакшна — странного ничего нет.
>резкие изменениях функционала ONTAP
Это резкое заявление, учитывая что ONTAP методично дорабатывался и имеет обратную совместимость даже с таким древним прибором как 2040. Есть Cluster-Mode 8.1 для FAS2040 ;) И взглянуть на туже обратную совместимость того же VNX ->VNX2
Кстати 60% продаж NetApp это SAN ;) Когда-то, чёрт знает когда, был только NAS, так до сих пор конкуренты поют старую песню :)
А у VNX когда-то чёрт-знает когда был только SAN, а теперь посмотрите на V-MAX и 70% использования NAS, так что теперь им вспоминать это спустя столько времени? Я бы назвал NetApp не NAS'овским производителем, а софтверным.
>Но всё это делает NetApp при детальном рассмотрении сильно нишевым продуктом с опредлёнными ограничениями
Ха :)
SAN, NAS, резервное копирование, виртуализация СХД, Disaster Recovery, архивирование, Compliance и этого мало? У большинства решений есть только «специализированное решение», а тут один раз учиться.
>странно работающая дедупликация при высоких нагрузках на массив (демон чаще уходит в сон)
Дедубликация работает в фоновом режиме, чтобы не нагружать СХД и не занимать ресурсы продакшна — странного ничего нет.
>резкие изменениях функционала ONTAP
Это резкое заявление, учитывая что ONTAP методично дорабатывался и имеет обратную совместимость даже с таким древним прибором как 2040. Есть Cluster-Mode 8.1 для FAS2040 ;) И взглянуть на туже обратную совместимость того же VNX ->VNX2
НЛО прилетело и опубликовало эту надпись здесь
Ну надеюсь другие полезные коменты вашего "+1" тоже не обойдут :)
Обратная совместимость присутствует, как я уже отметил на (очень) старое железо можно поставить Cluster-Mode, разве это «хорошо»? Это афигенно! Вы хоть где-то такое видели в СХД А-Бренда? Или на HP EVA вам удавалось (даже с простоем) натянуть прошивку от 3Par или c Hitachi VSP/HUS-VM на HUS-150/130?
Без потери данных переехать возможно. Здесь также присутствует обратная совместимость. Только не нужно ставить NetApp в рамки того, как «вы видите» переезд. NetApp'у видней как это сделать. Я также допускаю возможность, что в одном из будещих релизов можно будет «просто загрузиться» с «новой ОС» Cluster-Mode. На данный момент, насколько мне известно, все необходимые фичи, такие как Qtree и SnapMirror for Clustered Ontap, уже «подтянуты». Но это зависит от того, сочтёт ли NetApp целесообразным приводить версионность RAID-DP и WAFL в соответствие на 7-Mode, исходя из количества кастомеров, которым это проще выполнить именно так.
На данный момент времени NetApp считает более целесообразным выполнять миграцию путём применения промежуточного оборудования. Во многих случаях можно просто вязть оборудование «на тест» у вашего партнёра и осуществить таким образом при его помощи миграцию своими силаси за бесплатно, т.е. даром ©. Если вы хотите, чтобы миграцию вам осуществлял партнёр, всё необходимое оборудование NetApp готов предоставлять дистрибюторам по специальной программе Data Migration Gear Program.
Обратная совместимость присутствует, как я уже отметил на (очень) старое железо можно поставить Cluster-Mode, разве это «хорошо»? Это афигенно! Вы хоть где-то такое видели в СХД А-Бренда? Или на HP EVA вам удавалось (даже с простоем) натянуть прошивку от 3Par или c Hitachi VSP/HUS-VM на HUS-150/130?
Без потери данных переехать возможно. Здесь также присутствует обратная совместимость. Только не нужно ставить NetApp в рамки того, как «вы видите» переезд. NetApp'у видней как это сделать. Я также допускаю возможность, что в одном из будещих релизов можно будет «просто загрузиться» с «новой ОС» Cluster-Mode. На данный момент, насколько мне известно, все необходимые фичи, такие как Qtree и SnapMirror for Clustered Ontap, уже «подтянуты». Но это зависит от того, сочтёт ли NetApp целесообразным приводить версионность RAID-DP и WAFL в соответствие на 7-Mode, исходя из количества кастомеров, которым это проще выполнить именно так.
На данный момент времени NetApp считает более целесообразным выполнять миграцию путём применения промежуточного оборудования. Во многих случаях можно просто вязть оборудование «на тест» у вашего партнёра и осуществить таким образом при его помощи миграцию своими силаси за бесплатно, т.е. даром ©. Если вы хотите, чтобы миграцию вам осуществлял партнёр, всё необходимое оборудование NetApp готов предоставлять дистрибюторам по специальной программе Data Migration Gear Program.
FC поставляется 'бесплатно' а за NAS надо отдельно платит. Вот и используют как SAN в целях экономии.
>необходимость наличия свободного пространства не менее 50-70%, иначе начинаются падения производительности
Учитывая эти и другие накладные расходы, сколько в результате полезного пространства может быть использовано в каждом из агрегатов в абсолютных значениях по результатам вашего теста?
50-70% это от чего, при каких условиях и почему разбежность в 20%?
Я имею ввиду более конкретно предоставить информацию, а то расплывчато получается. Тут недавно был один товарищ, который оперировал цифрой «200 тыс» мейлбоксов с неизвестной нагрузкой и без конфигурации VNX — та ещё хохма была :)
Вот пример:
=======================Пример===========================
Есть СХД FAS3240 с двумя контроллерами
У контроллера «А» есть 48 диска 600ГБ
Создан агрегат aggr0 из (21+2) + (21+2) (т.е 2x RAID-DP) + 2х спардиска
Итого полезного RAW пространства грубо говоря 2*21*600 = 25200 ГБ
df -A -h для агрегата aggr0 показывает 22ТБ из них реально заюзать для SAN чтобы не падал перфоменс 19TB на все 100%.
=======================Пример===========================
В таком духе. Спасибо. Чтобы небыло вот этого habrahabr.ru/post/212453/#comment_7335349
Учитывая эти и другие накладные расходы, сколько в результате полезного пространства может быть использовано в каждом из агрегатов в абсолютных значениях по результатам вашего теста?
50-70% это от чего, при каких условиях и почему разбежность в 20%?
Я имею ввиду более конкретно предоставить информацию, а то расплывчато получается. Тут недавно был один товарищ, который оперировал цифрой «200 тыс» мейлбоксов с неизвестной нагрузкой и без конфигурации VNX — та ещё хохма была :)
Вот пример:
=======================Пример===========================
Есть СХД FAS3240 с двумя контроллерами
У контроллера «А» есть 48 диска 600ГБ
Создан агрегат aggr0 из (21+2) + (21+2) (т.е 2x RAID-DP) + 2х спардиска
Итого полезного RAW пространства грубо говоря 2*21*600 = 25200 ГБ
df -A -h для агрегата aggr0 показывает 22ТБ из них реально заюзать для SAN чтобы не падал перфоменс 19TB на все 100%.
=======================Пример===========================
В таком духе. Спасибо. Чтобы небыло вот этого habrahabr.ru/post/212453/#comment_7335349
Извините, что встреваю, но как раз расчётами ёмкостей netapp довелось заниматсья плотно, в своё время.
Допустим, есть 3240 с двумя контроллерами и 48 дисками.
6 дисков уходят на систему (ведь использование системного aggr0 не соответствует бест практис), 2 на spare.~1,6% у SAS уходит на специфику WAFL (у SATA теряется ~11,2%). Ну и два диска на RAID-DP.
Калькулятор показывает 20,74 TiB
Ещё -20%, которые рекомендуется держать свободными внутри aggregate и -20% внутри volume. То есть ещё где-то минус 4-5 ТБ.
Итого 15-16 ТБ можно использовать «на все 100%».
Ну это в новой конфигурации. Дополнительные полки уже не будут требовать системных аггрегейтов, так что будет на полтора ТБ больше.
Хотя SATA-полка из 24 дисков по 1 ТБ даёт 16 ТБ полезной ёмкости. SAS полки мы использовали по 300 ГБ и точную полезную ёмкость их я забыл.
У «классической» СХД дополнительная полка в 24 диска по терабайту даст от 12 до 20 ТБ, в зависимости от типа RAID и конфигурации spare.
Не то чтобы прям критическая разница, но иметь ввиду стоит.
Допустим, есть 3240 с двумя контроллерами и 48 дисками.
6 дисков уходят на систему (ведь использование системного aggr0 не соответствует бест практис), 2 на spare.~1,6% у SAS уходит на специфику WAFL (у SATA теряется ~11,2%). Ну и два диска на RAID-DP.
Калькулятор показывает 20,74 TiB
Ещё -20%, которые рекомендуется держать свободными внутри aggregate и -20% внутри volume. То есть ещё где-то минус 4-5 ТБ.
Итого 15-16 ТБ можно использовать «на все 100%».
Ну это в новой конфигурации. Дополнительные полки уже не будут требовать системных аггрегейтов, так что будет на полтора ТБ больше.
Хотя SATA-полка из 24 дисков по 1 ТБ даёт 16 ТБ полезной ёмкости. SAS полки мы использовали по 300 ГБ и точную полезную ёмкость их я забыл.
У «классической» СХД дополнительная полка в 24 диска по терабайту даст от 12 до 20 ТБ, в зависимости от типа RAID и конфигурации spare.
Не то чтобы прям критическая разница, но иметь ввиду стоит.
1) Полагаю вы про Cluster-Mode говорите. Так как рекомендаций по root addr для 7-Mode нет.
2) Хочу обратить ваше внимание на то, что здесь конкретно идёт речь про тест 3240 на 7-Mode.
3) И да, если вы хотите функционал переключения агрегатов на «ходу» в C-Mode, то нужно отдать 3 диска под root aggr на контроллер. По поводу специфики, пардон, но я высчитывать «обратно» из процентов не стану.
4) Сверху привёл вполне понятный и простой пример, ваш коммент получился сумбурный и не внятный.
5) На высоконагруженных продакшн сиcтемах выбор между типом RAID не стоит, так что «до» заканчивается на «от» ;)
ЗЫ: Вы толком не написали какие у вас в расчёте диски см п. 4.
2) Хочу обратить ваше внимание на то, что здесь конкретно идёт речь про тест 3240 на 7-Mode.
3) И да, если вы хотите функционал переключения агрегатов на «ходу» в C-Mode, то нужно отдать 3 диска под root aggr на контроллер. По поводу специфики, пардон, но я высчитывать «обратно» из процентов не стану.
4) Сверху привёл вполне понятный и простой пример, ваш коммент получился сумбурный и не внятный.
5) На высоконагруженных продакшн сиcтемах выбор между типом RAID не стоит, так что «до» заканчивается на «от» ;)
ЗЫ: Вы толком не написали какие у вас в расчёте диски см п. 4.
3,4) Забыл указать, в расчётах использовал диски 600 ГБ.
5) Ну в продакшене бывают не только высоконагруженные системы. Обычно больше объёма занимают архивы, бэкапы, файлопомойки и куча нетребовательных к дисковой производительности приложений и систем.
В сильно высоконагруженные системы я бы, кстати, дважды подумал, прежде чем ставить Netapp. Преимущество Netapp в гибкости. А в продуктивности он демонстрирует не самые высокие показатели.
Не хочу устраивать холивар, можно считать это моим частным мнением. Всё равно при расчёте мощностей под такие задачи учитывается сильно больше факторов, чем мы сможем тут обсудить.
5) Ну в продакшене бывают не только высоконагруженные системы. Обычно больше объёма занимают архивы, бэкапы, файлопомойки и куча нетребовательных к дисковой производительности приложений и систем.
В сильно высоконагруженные системы я бы, кстати, дважды подумал, прежде чем ставить Netapp. Преимущество Netapp в гибкости. А в продуктивности он демонстрирует не самые высокие показатели.
Не хочу устраивать холивар, можно считать это моим частным мнением. Всё равно при расчёте мощностей под такие задачи учитывается сильно больше факторов, чем мы сможем тут обсудить.
Ну не знаю на счёт «сильно подумал». Это очень субъективное мнение без какой-либо конкретики, так заявлять. В то время как у меня есть именно конкретика к примеру здесь и я заявляю, что высоконагруженные системы со случайным характером чтения/записи и NetApp «это самое оно», в не зависимости SAN/NAS.
Основные заказчики NetApp это крупные банки с высоконагруженными БД и виртуализацией.
Есть один крупный красный круглый банк который поставил V6200, очень довольны. Недавно докупили ещё полок, положили туда ещё и серверную виртуализацию.
«архивы, бэкапы, файлопомойки и куча нетребовательных к дисковой производительности приложений» явно не относятся к выражению «На высоконагруженных продакшн сиcтемах выбор между типом RAID не стоит». Вот теперь возьмите и посчитайте сколько будет полезного пространства с рекомендацией бестпрактис в 8 дисков RAID-6 и сравните с RAID-DP в 20.
Основные заказчики NetApp это крупные банки с высоконагруженными БД и виртуализацией.
Есть один крупный красный круглый банк который поставил V6200, очень довольны. Недавно докупили ещё полок, положили туда ещё и серверную виртуализацию.
«архивы, бэкапы, файлопомойки и куча нетребовательных к дисковой производительности приложений» явно не относятся к выражению «На высоконагруженных продакшн сиcтемах выбор между типом RAID не стоит». Вот теперь возьмите и посчитайте сколько будет полезного пространства с рекомендацией бестпрактис в 8 дисков RAID-6 и сравните с RAID-DP в 20.
>А в продуктивности он демонстрирует не самые высокие показатели.
Это ж где такое написано?
Вот к примеру разбор полётов по производительности и (что наиболее важно для БД) задержкам по тому же Cluster Mode и SAN с случайным характером чтения/записи.
Это ж где такое написано?
Вот к примеру разбор полётов по производительности и (что наиболее важно для БД) задержкам по тому же Cluster Mode и SAN с случайным характером чтения/записи.
Ну конечно субъективное мнение, я так и написал.
Забавно, хотя, в своё время (года три назад) спорили с Романом (romx) на тему производительности Netapp на примере младшей модели. Тогда iometer показал мне почти линейное снижение производительности по мере заполнения свободного пространства, с переходом в экспоненциальное в конце. На что Роман заявил, что синтетические тесты — чушь. А раз Netapp используют Cisco и Facebook, значит я чего-то не понимаю.
После изучения документов, на которые он ссылался, выяснилось, что Facebook использовал Netapp для хранения медиа-контента, а Cisco — под test/dev.
А сейчас вы мне приводите в доказательство как раз синтетические тесты. Ну и очередную порцию success story.
Есть один облачный сервис провайдер, у него MSA стоят, очень доволен. Значит ли это, что MSA лучше подходит под высоконагруженные мультитенантные системы с круглосуточной активностью? Или просто MSA в данном случае используется для хранения бэкапов и тестового стенда.
Я не заинтересован в споре, я представитель заказчика и ничего не продаю. И мне одинаково нравится работать и с EMC и c Netapp.
Забавно, хотя, в своё время (года три назад) спорили с Романом (romx) на тему производительности Netapp на примере младшей модели. Тогда iometer показал мне почти линейное снижение производительности по мере заполнения свободного пространства, с переходом в экспоненциальное в конце. На что Роман заявил, что синтетические тесты — чушь. А раз Netapp используют Cisco и Facebook, значит я чего-то не понимаю.
После изучения документов, на которые он ссылался, выяснилось, что Facebook использовал Netapp для хранения медиа-контента, а Cisco — под test/dev.
А сейчас вы мне приводите в доказательство как раз синтетические тесты. Ну и очередную порцию success story.
Есть один крупный красный круглый банк который поставил V6200, очень довольны.
Есть один облачный сервис провайдер, у него MSA стоят, очень доволен. Значит ли это, что MSA лучше подходит под высоконагруженные мультитенантные системы с круглосуточной активностью? Или просто MSA в данном случае используется для хранения бэкапов и тестового стенда.
Я не заинтересован в споре, я представитель заказчика и ничего не продаю. И мне одинаково нравится работать и с EMC и c Netapp.
Если вы спуститесь к зазделу этой статьи «Oncommand Core + Perfomance Adviser», то увидите картинку с перфоменсом. Это реальный случай теста одного (уже другого, тоже крупного) банка и базы данных Oracle содержащая всех своих карточных клиентов. СХД 2240, подключение FC4.
По поводу падения производительности нужно разбирать ваш конкретный случай. В большинстве случаев все «проблемы нетапа» сводятся к этому случаю. Но это не всегда так, к примеру у банка который я только что упомянул проблема заключалась в файловой системе (или её конкретной реализации) UFS, которая почему-то генерировала чтение на 100% операциях записи и при этом жутко тупила по не известной причине. На СХД было видно, что она совершенно не нагружена в эти моменты. Разбираться с реализацией файловой системы было не интересно, сменили на ZFS и «оно попёрло» :)
>Есть один облачный сервис провайдер, у него MSA стоят.
Если заказчика устраивает именно эта модель, ну так чтож. Пускай пользуются и радуются :)
Я привожу всего лишь новые «переменные», на которые стоит начать обращать внимание и возможно пересматривать свои «сделанные выводы» с их учётом.
По поводу падения производительности нужно разбирать ваш конкретный случай. В большинстве случаев все «проблемы нетапа» сводятся к этому случаю. Но это не всегда так, к примеру у банка который я только что упомянул проблема заключалась в файловой системе (или её конкретной реализации) UFS, которая почему-то генерировала чтение на 100% операциях записи и при этом жутко тупила по не известной причине. На СХД было видно, что она совершенно не нагружена в эти моменты. Разбираться с реализацией файловой системы было не интересно, сменили на ZFS и «оно попёрло» :)
>Есть один облачный сервис провайдер, у него MSA стоят.
Если заказчика устраивает именно эта модель, ну так чтож. Пускай пользуются и радуются :)
Я привожу всего лишь новые «переменные», на которые стоит начать обращать внимание и возможно пересматривать свои «сделанные выводы» с их учётом.
Я не приверженец жёстких убеждений и всегда рассматриваю «новые переменные». Я ведь сказал, что «дважды подумал бы», а не «я категорически против».
Просто я скептически воспринимаю попытки вендоров представить свой продукт панацеей. И понимаю разницу между фантастическим результатом теста в много миллионов попугаев и длительной и вдумчивой эксплуатацией нагруженной системы. Хотя тесты важны, конечно, тоже.
И как вы точно заметили, всё равно в каждом случае надо индивидуально разбираться.
Просто я скептически воспринимаю попытки вендоров представить свой продукт панацеей. И понимаю разницу между фантастическим результатом теста в много миллионов попугаев и длительной и вдумчивой эксплуатацией нагруженной системы. Хотя тесты важны, конечно, тоже.
И как вы точно заметили, всё равно в каждом случае надо индивидуально разбираться.
Не сказал бы, что прям
Как не понятны люди, установившие утеплённую и укреплённую железную дверь в квартиру и оставляющие открывающуюся внутрь слабую деревянную («на всякий случай»), также не могу представить, зачем вводить iSCSI-сущность для «надёжности», в дополнение к нормальной отказоустойчивой конфигурации FC. Если, конечно, она отказоустойчиво спроектирована. А если нет, то я бы добавил вторую FC-фабрику, чем городить винегрет, который вдобавок вводит ограничения и снижает производительность.
Если что, я не утверждаю, что FC — железная дверь, а iSCSI — деревянная, может быть и наоборот, всё зависит от конфигурации.
Очень часто используется параллельно.За 4 года взаимодействия с SAN я с таким не столкнулся ни разу.
Как не понятны люди, установившие утеплённую и укреплённую железную дверь в квартиру и оставляющие открывающуюся внутрь слабую деревянную («на всякий случай»), также не могу представить, зачем вводить iSCSI-сущность для «надёжности», в дополнение к нормальной отказоустойчивой конфигурации FC. Если, конечно, она отказоустойчиво спроектирована. А если нет, то я бы добавил вторую FC-фабрику, чем городить винегрет, который вдобавок вводит ограничения и снижает производительность.
Если что, я не утверждаю, что FC — железная дверь, а iSCSI — деревянная, может быть и наоборот, всё зависит от конфигурации.
зачем вводить iSCSI-сущность для «надёжности», в дополнение к нормальной отказоустойчивой конфигурации FC.
ISCSI дешевле, так-как обычно IP инфраструктура уже существует. FC всё-таки на много дороже и должен строится параллельно.
На счёт «Если, конечно, она отказоустойчиво спроектирована.» Был у нас забавный случай: FC как полагается — два свича, два адаптера, два контроллера, по два блока питания во всех устройствах, Даже две линии электричества от разных фирм. Да вот только есть проблема с софтом свича — как оказалось позже, перезагружается каждые 48 дней. Вроде не беда, ведь всё дублировано. Да только свичи мы включили одновременно и перезагружались они одновременно тоже. Долго мы искали дефект…
Как-то однобоко, сейчас очёнь силён тренд перехода СХД с FC на Ethernet. Кстати сам термин FC не раскрыт. Ещё, если уж цеплять базовые понятия, не хватает multipathing
НЛО прилетело и опубликовало эту надпись здесь
Я имел в виду более глобальный тренд ухода от FC не только на канальном но и на логическом уровне, повальное увлечение iSCSI и размазывание границ SAN-LAN за счёт гомогенной IP-over-Ethernet сети. А классическое FC железо становится всё менее популярным, практически исчезли некогда популярные FC-HDD, FC на канальном уровне заменяет 10GE и Infiniband итд.
НЛО прилетело и опубликовало эту надпись здесь
> А вот Infiniband всё меньше и меньше, его вытесняют DAS решения на базе более популярного SAS. Да что там, я не знаю ни одной компании в СНГ, которая бы использовала Infiniband с коммутаторами.
А как связан рост популярности DAS, подключаемых по SAS, и падение популярности СХД на основе IB-фабрик, состоящих из тех же самых DAS?
Или же имелось в виду использование IB без коммутаторов?
А как связан рост популярности DAS, подключаемых по SAS, и падение популярности СХД на основе IB-фабрик, состоящих из тех же самых DAS?
Или же имелось в виду использование IB без коммутаторов?
>> я не знаю ни одной компании в СНГ, которая бы использовала Infiniband с коммутаторами
Начиная с запуска Скалакси насколько я помню Оверсан свои SAN переводил на InfiniBand, при чём якобы оказалось существенно дешевле чем 40G. На хабре был обзор их коммутаторов и вообще архитектуры. В Европе тоже частенько видел IB-interconnected кластеры.
Начиная с запуска Скалакси насколько я помню Оверсан свои SAN переводил на InfiniBand, при чём якобы оказалось существенно дешевле чем 40G. На хабре был обзор их коммутаторов и вообще архитектуры. В Европе тоже частенько видел IB-interconnected кластеры.
НЛО прилетело и опубликовало эту надпись здесь
> При этом они заявляют, что используют HP MSA2312sa
Эти полки цеплялись по SAS к серверам, которые раздавали диски инициаторам по SRP. Впоследствии от отдельных полок отказались и перешли на 36-дисковые супермикровские серверы.
Эти полки цеплялись по SAS к серверам, которые раздавали диски инициаторам по SRP. Впоследствии от отдельных полок отказались и перешли на 36-дисковые супермикровские серверы.
НЛО прилетело и опубликовало эту надпись здесь
Диски по SRP экспортировались на проксирующие узлы, где они собирались в массивы, нарезались на тома, а затем массивы по SRP отдавались непосредственно хостам виртуализации, где уже по dm-картам заново восстанавливались тома.
Резервировались контроллеры на нодах с дисками (multipath), сами ноды (на проксях собирались RAID1+0 из пар нод, причем так, что зеркала собирались из дисков разных нод пары) и проксирующие узлы (multipath).
НЛО прилетело и опубликовало эту надпись здесь
> почти что Network RAID (если этот термин применим для IB RDMA)
RDMA — транспорт для SRP, network raid — архитектура над SRP. Как одно другому мешает?
> TCO насколько меньше получилось?
TCO я не считал, и тем более не сравнивал (с чем?). Эксплуатацией этого добра я начал заниматься уже после разработки и внедрения.
Если вас интересуют именно затраты на эксплуатацию, то они сильно зависит от результатов разработки. Точно сказать заранее, какие они будут для подобного сферического хранилища в вакууме, нельзя.
> Ведь этот подход претит малым и средним инсталляциям.
Почему?
RDMA — транспорт для SRP, network raid — архитектура над SRP. Как одно другому мешает?
> TCO насколько меньше получилось?
TCO я не считал, и тем более не сравнивал (с чем?). Эксплуатацией этого добра я начал заниматься уже после разработки и внедрения.
Если вас интересуют именно затраты на эксплуатацию, то они сильно зависит от результатов разработки. Точно сказать заранее, какие они будут для подобного сферического хранилища в вакууме, нельзя.
> Ведь этот подход претит малым и средним инсталляциям.
Почему?
НЛО прилетело и опубликовало эту надпись здесь
> Малые инсталляции обычно не ориентированны на большую производительность ввиду скромных запросов к I/O.
В энтерпрайзе может быть и так, но не в облачном хостинге. И итоге упирались именно в IOPS-ы из-за малого количества шпенделей, и это на 15k SAS дисках и сотнях гигабайт кэша.
> Это элементарно невыгодно, так как решения вендоров могут окупиться гораздо быстрее и включают в себя саппорт.
Это утверждение еще нуждается в проверке, если нужна большая производительность. Особенно насчет саппорта. Ни разу не видел достаточно сложных вещей, которые бы при использовании под интенсивной нагрузкой «просто работали», а саппорт, однако, имеет свои пределы.
В энтерпрайзе может быть и так, но не в облачном хостинге. И итоге упирались именно в IOPS-ы из-за малого количества шпенделей, и это на 15k SAS дисках и сотнях гигабайт кэша.
> Это элементарно невыгодно, так как решения вендоров могут окупиться гораздо быстрее и включают в себя саппорт.
Это утверждение еще нуждается в проверке, если нужна большая производительность. Особенно насчет саппорта. Ни разу не видел достаточно сложных вещей, которые бы при использовании под интенсивной нагрузкой «просто работали», а саппорт, однако, имеет свои пределы.
Этот тренд силён уже пару лет минимум. Однако на FC всё ещё достаточное количество сетей. Однобоко, поскольку не планировал охватить вообще все аспекты, а, как говорил по тексту, осветил то (и так) чего в своё время не хватало мне.
НЛО прилетело и опубликовало эту надпись здесь
Относительно книг Вы как-то совсем грустную картину описали.
Ну в плане бумажных книг, столь мной любимых, действительно совсем грустно. Разве что с амазона заказывать. На русском языке ещё хуже — кроме переводов Netapp ничего толкового и не видел даже в электронном варианте, а у них сильный перекос в сторону маркетинга (я просто устал от выражений «совершенно бесплатно», «оптимальные решения» и иже с ними).
Отличные книги у EMC и Brocade, да. Причём если у первого, несмотря на жуткую навигацию сайта в целом, их можно найти через powerlink, то у второго я всю литературу вытаскивал через гугл запросом "*.pdf /site:brocade.com". То ли у меня с интуитивностью худо, то ли у брокейда с юзабилити.
Fibre исправил, спасибо. Дурацкая ошибка :)
Про совокупность, и один коммутатор не стал конкретизировать, ибо ещё из школьной математики закрепилось, что множество может состоять из единственного элемента (и даже из их отсутствия вообще). Косвенно, кстати, упомянуто:
И EMC и Brocade напирают на то, чтобы в зоне был единственный инициатор, допуская несколько таргетов. Если существенно, могу точную цитату привести, как на работу вернусь. Есть опять же рекомендация (уже не помню откуда), что таргеты не должны быть разных производителей. Но это уже детали, на мой взгляд, выходящие за пределы формата «на пальцах».
Про совокупность, и один коммутатор не стал конкретизировать, ибо ещё из школьной математики закрепилось, что множество может состоять из единственного элемента (и даже из их отсутствия вообще). Косвенно, кстати, упомянуто:
Например одна фабрика может состоять из четырёх коммутаторов, а другая — из одного
И EMC и Brocade напирают на то, чтобы в зоне был единственный инициатор, допуская несколько таргетов. Если существенно, могу точную цитату привести, как на работу вернусь. Есть опять же рекомендация (уже не помню откуда), что таргеты не должны быть разных производителей. Но это уже детали, на мой взгляд, выходящие за пределы формата «на пальцах».
НЛО прилетело и опубликовало эту надпись здесь
Идеал, да. Как и прочие идеалы, в реальных условиях встречается мало. Ну может в конфигурации из трёх серверов и одного стораджа можно себе позволить, но если у нас 5 дисковых массивов о 8 портах каждый и пол сотни серверов, то идеал заставляет делать 4000 зон (50 серверов * 2 порта HBA * 5 СХД * 8 портов SP). В более приемлемом варианте (одна зона — один инициатор) — всего 100 зон.
Приходится жертвовать идеалами в пользу управляемости и удобства.
EMC: “FC SAN Topologies”:
Use single initiator zoning
For Open Systems environments, ideally each initiator will be in a zone with single target. However, due to the significant management overhead that this can impose, single initiator zones can contain multiple target ports but should never contain more than 16 target ports.
“SAN Технологии и решения Brocade 2012”:
Зонирование с одним инициатором (single initiator zoning)
В очень больших сетях применение зон point-to-point не всегда удобно, поскольку оно означает создание большого числа зон и необходимость многочисленных изменений в конфигурации фабрики при добавлении и перемещении устройств. Более популярный метод – это зоны с одним инициатором, при котором достигается баланс между необходимостью ограничить число зон и упрощением управления. Для каждого инициатора в фабрике создается отдельная зона, которая также содержит все порты систем хранения для этого инициатора.
Приходится жертвовать идеалами в пользу управляемости и удобства.
EMC: “FC SAN Topologies”:
Use single initiator zoning
For Open Systems environments, ideally each initiator will be in a zone with single target. However, due to the significant management overhead that this can impose, single initiator zones can contain multiple target ports but should never contain more than 16 target ports.
“SAN Технологии и решения Brocade 2012”:
Зонирование с одним инициатором (single initiator zoning)
В очень больших сетях применение зон point-to-point не всегда удобно, поскольку оно означает создание большого числа зон и необходимость многочисленных изменений в конфигурации фабрики при добавлении и перемещении устройств. Более популярный метод – это зоны с одним инициатором, при котором достигается баланс между необходимостью ограничить число зон и упрощением управления. Для каждого инициатора в фабрике создается отдельная зона, которая также содержит все порты систем хранения для этого инициатора.
> А если на это же время отвалится жёсткий диск с базой или с ОС, эффект будет куда более серьёзным.
Если диск в базой отвалится на пару секунд, то эффект будет не намного серьезнее, чем от пропажи сети. Кратковременная заморозка IO не смертельна, если аккумулированная нагрузка после разморозки не кладет сервер (но в таком случае и пропадание сети тоже становится весьма серьезным и, опять же, разница не настолько велика).
В случае же с ОС эффект практически отсутствует, потому что ввода-вывода практически нет, и попадание запросов в кэши VFS велико.
Если диск в базой отвалится на пару секунд, то эффект будет не намного серьезнее, чем от пропажи сети. Кратковременная заморозка IO не смертельна, если аккумулированная нагрузка после разморозки не кладет сервер (но в таком случае и пропадание сети тоже становится весьма серьезным и, опять же, разница не настолько велика).
В случае же с ОС эффект практически отсутствует, потому что ввода-вывода практически нет, и попадание запросов в кэши VFS велико.
Книга Джоша Джадда «Основы проектирования SAN» на русском языке лежит в свободном доступе:
www.brocade.com/international/russian/san.page
www.brocade.com/international/russian/san.page
Чем-то мне эта книга напомнила стиль технической библиотеки NetApp. Активная маркетинговая пропаганда (особенно там, где сравнение с продуктами MDS «другого известного вендора») под эгидой технического просвещения. Тем не менее, прочесть, конечно, полезно, хотя КПД книги по соотношению польза / объём (время чтения) далеко не 100%. И стоит иметь ввиду, что книга написана в 2005 г., то есть содержит устаревшие сведения.
После такого количества комментов про нетап можно и тег статье поставить соответствующий :)
А о какой книге о VMware и даже на русском идет речь? Подскажите название, пожалуйста.
НЛО прилетело и опубликовало эту надпись здесь
Именно. «Администрирование VMware vSphere 5». На данный момент третье издание, по-моему. По результатам трёх десятков собеседований на должность инженера виртуализации, каждый второй читал, либо хотя бы пролистывал именно эту книгу и знает только этого автора.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
О SAN (Storage Area Network) на пальцах