Комментарии 178
НЛО прилетело и опубликовало эту надпись здесь
Почему только Java? Там есть код и на Паскале с тем же эффектом. Ну и касается это наверное всех, кто работает с массивами. А уж «математика» в массиве или картинка роли не играет.
НЛО прилетело и опубликовало эту надпись здесь
Все зависит от проектов, с которыми Вы сталкиваетесь. Я конечно слышал о программистах, которые никогда не работали с массивами… Но мне, даже при работе с «готовой» библиотекой OpenCV, приходилось довольно много крутить большими массивами.
Это одна из таких «мелочей», которые относятся к «общей грамотности». Библиотеки могут и не спасти.
Многие, скажем, без всякой задней мысли составляют крупную строку, складывая отдельные строчки простым плюсом. Да, в стандартной библиотеке есть под такую задачу класс (в Java это StringBuilder), но если разработчик о нём не знает, его это не спасёт, и тормозить будет. А в обширном мире практического программирования наткнуться на подзадачу склеивания тонны строк недолго, как и на алгоритм с массивами.
Многие, скажем, без всякой задней мысли составляют крупную строку, складывая отдельные строчки простым плюсом. Да, в стандартной библиотеке есть под такую задачу класс (в Java это StringBuilder), но если разработчик о нём не знает, его это не спасёт, и тормозить будет. А в обширном мире практического программирования наткнуться на подзадачу склеивания тонны строк недолго, как и на алгоритм с массивами.
НЛО прилетело и опубликовало эту надпись здесь
Ну, это уже холивар. Выбор реализации структуры данных зависит от того, какие именно операции чаще всего с ним выполняются в программе. Ropes рассчитаны на быструю конкатенацию O(1), но индексирование в них проходит за O(h). habrahabr.ru/post/144736/
НЛО прилетело и опубликовало эту надпись здесь
Сейчас как раз пишу реализацию Ropes по этой статье. В ней я как раз писал про то что есть оптимизации индексирования, основанные на том что доступ к символам почти всегда последовательный — это значит что можно кэшировать листовой узел в котором в последний раз нашелся символ и диапазон индексов который он представляет. За счет того что в следующий раз обращение наверняка будет производиться к соседним символам индексация пройдет за О(1). Можно даже пойти дальше и вместо одного кэша поддерживать 2-3, чтобы оптимизировать даже те сценарии, когда символы поочередно выбираются с разных концов строки, однако на практике одного.
В общем, основная мысль в том что индексация в Ropes на практике происходит за амортизированное O(1). Главная же их фишка — вставка в середину строки за то же О(1), чего обычные строки и StringBuilder'ы не умеют.
В общем, основная мысль в том что индексация в Ropes на практике происходит за амортизированное O(1). Главная же их фишка — вставка в середину строки за то же О(1), чего обычные строки и StringBuilder'ы не умеют.
Просто не могу удержаться и не попроавить. Как раз в Java компилятор заменит простую конктенацию вызовом StringBuilder'а. И константы заранее все соединит.
Конечно если строка конкатенируется в цикле или в разных методах, то компилятор уже не спасёт.
Пример
$ javac Test.java && javap -c Test
public class Test {
public static void main(String[] args) {
String s = "Some " + "string " + 1 + " concatenated: " + 2L + ":" + (byte)3 + ":" + 1.0d;
System.out.println(s);
String s2 = "Another one " + args[0] + args[1] + args[2] + args[3];
System.out.println(s2);
}
}
$ javac Test.java && javap -c Test
public static void main(java.lang.String[]);
Code:
0: ldc #2 // String Some string 1 concatenated: 2:3:1.0
2: astore_1
3: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
6: aload_1
7: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
10: new #5 // class java/lang/StringBuilder
13: dup
14: invokespecial #6 // Method java/lang/StringBuilder."<init>":()V
17: ldc #7 // String Another one
19: invokevirtual #8 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
22: aload_0
23: iconst_0
24: aaload
25: invokevirtual #8 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
28: aload_0
29: iconst_1
30: aaload
31: invokevirtual #8 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
34: aload_0
35: iconst_2
36: aaload
37: invokevirtual #8 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
40: aload_0
41: iconst_3
42: aaload
43: invokevirtual #8 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
46: invokevirtual #9 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
49: astore_2
50: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
53: aload_2
54: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
57: return
}
Конечно если строка конкатенируется в цикле или в разных методах, то компилятор уже не спасёт.
вам не кажется, что в случае «без цикла» — один хрен: что с конкатенацией, что со СтрингБилдером?
Если надо сложить два десятка строк длиной по миллиону символов, то, может быть, StringBuilder тоже окажется выгодней. Хоть и без цикла.
У voronaam это в примере и показано. Если компилятор сможет вычислить строчку в compile-time, то поклеит. Если нет — создаст StringBuilder.
вопрос не в этом, а в том, всегда ли замена конкатенации на СтрингБилдер быстрее.
Что вы понимаете под конкатенацией? Оператор + или String#concat(String)?
Если первое — то оно с java 1.5 использовало StringBuilder внутри, а в java 1.4.2 (возможно, что и раньше — не проверял) использовало StringBuffer.
Если второе — то оно иногда может быть выгоднее за счет меньшего количества выделений памяти в худшем случае, но оно менее удобно (не приводит типы автоматически), может вызвать NPE (если первая строка — null).
Если первое — то оно с java 1.5 использовало StringBuilder внутри, а в java 1.4.2 (возможно, что и раньше — не проверял) использовало StringBuffer.
java se 1.4.2
The Java language provides special support for the string concatenation operator ( + ), and for conversion of other objects to strings. String concatenation is implemented through the StringBuffer class and its append method. String conversions are implemented through the method toString, defined by Object and inherited by all classes in Java. For additional information on string concatenation and conversion, see Gosling, Joy, and Steele, The Java Language Specification.
Если второе — то оно иногда может быть выгоднее за счет меньшего количества выделений памяти в худшем случае, но оно менее удобно (не приводит типы автоматически), может вызвать NPE (если первая строка — null).
Принципиальная разница в том, что результат String.concat() — полноценная строка. Уже само по себе плохо что это полноценный объект (который должен будет подчистить GC), так это ещё и строка — а значит она окажется в строковом кэше. Который (насколько я помню), до Full GC чистить никто не будет.
В StringBuilder'е же строка это просто char*, который Java-объектом не является.
Раз уж у нас тут ветка ликбеза получается…
В StringBuilder'е же строка это просто char*, который Java-объектом не является.
Раз уж у нас тут ветка ликбеза получается…
Судя по коду в java 7 ни то, ни другое не intern'ит строку. Т. е. в строковый пул не попадает. По умолчанию inter'ятся литералы (3.10.5 в jls7).
И то, и другое создает массив char'ов и String на его основе:
— в случае concat он создается в методе String#concat и переиспользуется в new String(char[], boolean);
— в случае StringBuilder#toString() он создается в new String(char[], int, int).
В StringBuilder'е — char[] — вполне себе java-объект.
И то, и другое создает массив char'ов и String на его основе:
— в случае concat он создается в методе String#concat и переиспользуется в new String(char[], boolean);
— в случае StringBuilder#toString() он создается в new String(char[], int, int).
В StringBuilder'е — char[] — вполне себе java-объект.
Заметьте, что из Java я упомянул только класс для сборки строк (чтобы было понятно, о чём речь), а сам пример совершенно абстрактный.
Я лично не очень рад доверять разницу между сложностью в О(N) и в O(N^2) компилятору без 100%-ной уверенности, что получится более быстрый вариант (а здесь, из синтаксиса, на вид не должен, если понимать операции). Здесь компилятор спасёт, но он (вы и сами отметили) спасёт не везде. Особенно если речь пойдёт о другой реализации компилятора или вообще не о Java.
Я лично не очень рад доверять разницу между сложностью в О(N) и в O(N^2) компилятору без 100%-ной уверенности, что получится более быстрый вариант (а здесь, из синтаксиса, на вид не должен, если понимать операции). Здесь компилятор спасёт, но он (вы и сами отметили) спасёт не везде. Особенно если речь пойдёт о другой реализации компилятора или вообще не о Java.
Со строками возможны и обратные грабли.
Если приходит большая строка, из которой выбирается лишь маленькая подстрока, то в памяти остаётся вся исходная строка. Когда таких строк много, память внезапно кончается. Ситуация, конечно, крайне редкая, но возможная.
Если приходит большая строка, из которой выбирается лишь маленькая подстрока, то в памяти остаётся вся исходная строка. Когда таких строк много, память внезапно кончается. Ситуация, конечно, крайне редкая, но возможная.
А при чем тут массивы? Можно аналогично подсчитывать любые операции с небольшими объемами данных (строки, математику, хеши т.д.) и результат будет неожиданным из-за работы кешей
Кэш?
Так что же происходит? Объясните кто-нибудь в подробностях, пожалуйста.
Я склонен дождаться версий читателей. Пока есть только одна — кэш.
Хм, «раздербанил» код теста с помощью javap. Код второго цикла гораздо больше и наличие имеется imul и dup_x2, в отличие от кода первого.
Есть предположение что массив хранится в «одну линию», и, поскольку во-втором массиве идет обращение к элементам массива не по-порядку, строка за строкой, а вразнобой, то появляется дополнительный код, вычисляющий смещение.
Есть предположение что массив хранится в «одну линию», и, поскольку во-втором массиве идет обращение к элементам массива не по-порядку, строка за строкой, а вразнобой, то появляется дополнительный код, вычисляющий смещение.
Помимо кэша есть еще JIT, который и срабатывает при больших N.
А почитать статью специально этому посвящённую — не судьба? То, что тут происходит описано в пятой части. И да, кеш имеет к этому отношение, но дело в том, что в современных процессорах вокруг кеша наверчено мнооого всего. Обращение по строкам быстрее обращений по столбцам, но это не вся правда. Там есть чудеса со строками кеша и прочим. Есть красивый манёвр с кривой Пеано. Вообще есть много чего и очень грустно наблюдать ситуацию, когда люди (с надеждой и замиранием сердца) говорят «кеш», как будто это слово в три буквы описывает всю ситуацию…
Для статьи по ссылке есть русский перевод: rus-linux.net/lib.php?name=/MyLDP/hard/memory/memory.html.
А точно пишут именно так?
Еще один повод поговорить.
g[i][i] = i << 2; Еще один повод поговорить.
Cache, конечно, тут и думать не надо. Вместо последовательного обращения к памяти получили обращения в разные места памяти.
Помимо кэша, ОС приходится обращаться не к соседним ячейкам памяти, а к далеко-лежащим, что сильно увеличивает скорость
Почитав про кеш и про пространственную локальность я бы написал так:
for ($i=0; $i < $n; $i++){
$mass[$i][$i] = 2*$i;
for ($j=0; $j < $i; $j++){
if($j==0){
$s = $n-$i;
$k = $i;
}
$mass[$i][$j] = $mass[$s][$k] = 2*$j;
$k++;
}
}
for ($i=0; $i < $n; $i++){
$mass[$i][$i] = 2*$i;
for ($j=0; $j < $i; $j++){
if($j==0){
$s = $n-$i;
$k = $i;
}
$mass[$i][$j] = $mass[$s][$k] = 2*$j;
$k++;
}
}
В пользу теории о кеше говорит то, что если n уменьшить до 64, то время выполнения будет приблизительно равным.
Для таких маленьких массивов скорость исполнения измеряется с большой погрешностью. Кстати, обратите внимание на нарушение закономерности при изменении размера всего на единицу 117 — 118. Причем работает на виртуальном сервере ideone.com/r4ZXu5. На локальной машине вы это вряд ли получите.
А то что при каждом обращении по индексу происходит проверка — не зашли ли вы за границы массива не учитывается (только в Java, во FreePascal ее нет)? Можно сохранить в одной верхней итерации ссылку на массив и использовать его, чтобы избежать лишних проверок.
А в java двумерный массив хранится точно также как и в си?
Кстати, на скорость инициализации еще будет влиять то, по столбцам мы его будем заполнять или по строчкам.
Кстати, на скорость инициализации еще будет влиять то, по столбцам мы его будем заполнять или по строчкам.
Я может быть чего-то не понимаю, но есть же вот такое:
http://docs.oracle.com/javase/7/docs/api/java/util/Arrays.html#fill(int[], int)
http://docs.oracle.com/javase/7/docs/api/java/util/Arrays.html#fill(int[], int)
fill() позволит заполнить линейный массив одинаковыми значениями. Мы обсуждаем вопрос почему так сильно различается скорость перебора элементов двумерного массива «по строкам» и «по столбцам». Относительная парадоксальность ситуации в том, что обычно декларируется (так оно и есть), что массив структура данных с эффективным произвольным доступом. Постепенно в обсуждении формируется идея, что при доступе по строкам производится O(n+m) обращений к элементам массива. А при доступе по столбцам — O(n*m).
Нет, это то все понятно, но ведь изначально была задача «Теперь просим инициализировать элементы массива чем-нибудь. Хоть единицами, хоть суммой индексов.».
И, кстати, интересно бы еще посмотреть на результаты чего-то такого:
будет ли значительное проседание?
И, кстати, интересно бы еще посмотреть на результаты чего-то такого:
for (int[] row : arr)
Arrays.fill(row, 1);
будет ли значительное проседание?
Мне очень понравилась версия про кэш процессора. Основная его идея — последовательный доступ быстрее случайного. Давайте поисследуем его чуть-чуть. Напишем простой код. Даже без двумерного массива. Просто, работаем с элементами массива подряд (вариант 1) и в случайном порядке (вариант 2). Вот он — ideone.com/tMaR2S. При таком размере массива (1200 целых чисел), случайный доступ чуть-чуть быстрее. Можно снова поиграть с размером массива и получить самые разные результаты.
Меняем one/two местами и получаем обратный результат, даже немного лучший для последовательно заполнения: ideone.com/T5rfeM
Тест не очень чистый, первый прогон влияет на второй.
«Краснеющих» хорошо только туда, где будут сплошные стрессы. «Бледнеющие» могут лучше себя показать в спокойной обстановке.
Процессорный кеш может и как то влияет, но скорее всего проблема в проверках границ массивов.
Код на Java
One time 17.966596 msc
Two time 23.864461 msc
Код на С
1st=14.017 msc
2nd=8.937 msc
Код на Java
One time 17.966596 msc
Two time 23.864461 msc
Код на С
1st=14.017 msc
2nd=8.937 msc
Мне кажется причина в том, что во втором варианте некоторые ключи массива перезаписываются повторно.
По моему кеш проца оказывает минимальное влияние в данном случае. Основное это доступ к элементам — в java массивы хранятся построчно, поэтому доступ по столбцам гораздо менее эффективен, что можно подтвердить следующим тестом:
у меня 70.225679 msc против 2943.409599 msc.
Если вопрос именно по симметричной матрице, то в java 2d массив — это именно массив массивов ( в отличие например от С), поэтому у каждого массива может быть свой размер — можно хранить и заполнять только нижний треугольник матрицы.
class A {
public static void main(String[] args) {
int n = 8000;
int g[][] = new int[n][n];
long st, en;
// one
st = System.nanoTime();
for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
g[i][j] = 1;
}
}
en = System.nanoTime();
System.out.println("\nTwo time " + (en - st)/1000000.d + " msc");
// two
st = System.nanoTime();
for(int j = 0; j < n; j++) {
for(int i = 0; i < n; i++) {
g[i][j] = 1;
}
}
en = System.nanoTime();
System.out.println("\nTwo time " + (en - st)/1000000.d + " msc");
}
}
у меня 70.225679 msc против 2943.409599 msc.
Если вопрос именно по симметричной матрице, то в java 2d массив — это именно массив массивов ( в отличие например от С), поэтому у каждого массива может быть свой размер — можно хранить и заполнять только нижний треугольник матрицы.
Вы абсолютно правы, что дело в порядке доступа. Но как быть с этим ideone.com/tMaR2S?
тут вы меряете скорость работы random, которая на порядок меньше скорости работы с массивом ideone.com/A50fQA
(ниже уже есть)
Да, все верно. Тормоза вызваны именно тем, что двумерный массив представлен как массив из массивов, в результате для получения определенного элемента надо сделать несколько дополнительных операций по получению вложенного массива, вместо прямого доступа к нужному элементу. Поэтому и получается, что случайный доступ медленнее последовательного. Так что кэш процессора тут вообще не при чем…
Пример:
ideone.com/crcmVU
Результат:
Ну и плюс, скорее всего, свою лепту обычно вносит оптимизатор — я не джавист, так что как оно там внутрях работает и что делает я не знаю.
Пример:
ideone.com/crcmVU
Код
class A {
public static void main(String[] args) {
int n = 5000;
int g[][] = new int[n][n];
long st, en;
// one
st = System.nanoTime();
for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
g[i][j] = 10;
}
}
en = System.nanoTime();
System.out.println("\nTwo time " + (en - st)/1000000.d + " msc");
// two
st = System.nanoTime();
for(int i = 0; i < n; i++) {
g[i][i] = 20;
for(int j = 0; j < i; j++) {
g[j][i] = g[i][j] = 20;
}
}
en = System.nanoTime();
System.out.println("\nTwo time " + (en - st)/1000000.d + " msc");
// 3 Обычный массив такого же размера, как и двухмерный, линейный проход по всем элементам
int arrLen = n*n;
int[] arr = new int[arrLen];
st = System.nanoTime();
for(int i : arr) {
arr[i] = 30;
}
en = System.nanoTime();
System.out.println("\n3 time " + (en - st)/1000000.d + " msc");
// 4 Тот же массив, но работаем как с двухменым массом
st = System.nanoTime();
int i, j;
for(i = 0; i < n; i++) {
for(j = 0; j < n; j++) {
arr[i*n+j] = 40;
}
}
en = System.nanoTime();
System.out.println("\n4 time " + (en - st)/1000000.d + " msc");
}
}
Результат:
Two time 71.998012 mscTwo time 551.664166 msc3 time 63.74851 msc4 time 57.215167 mscНу и плюс, скорее всего, свою лепту обычно вносит оптимизатор — я не джавист, так что как оно там внутрях работает и что делает я не знаю.
> что двумерный массив представлен как массив из массивов
Строго говоря в Java вообще нет двумерных массивов, поэтому автор всех здорово запутал своими параллелями с Си и Паскалем.
Видимо отсюда и весь налет мистики.
В Си и Паскале двумерные массивы есть (насколько я помню), и там размерность массива NxK будет означать непрерывный блок памяти размером NxK в котором с помощью pointer arithmetics можно вычислить адрес каждой конкретной ячейки — но в Java ничего такого нет. «Двумерный» массив в Java это одномерный массив ссылок на одномерные массивы, каждый из которых может быть разной длинны например, а то и просто отсутствовать (null ссылка).
Вроде такого:
int a[][] = new int[4][];
a[1]=new int[2];
a[2]=new int[3];
a[3]=new int[2];
В результате имеем:
a[0] — null
a[1] — массив 2-х интов, a[1][2] — ok, a[1][3] — out of bounds
a[2] — массив 3-х интов, a[2][3] — ok, a[2][4] — out of bounds
a[3] — опять массив 2-х интов.
Когда в Java надо завести именно двумерный массив, как в Си — заводим одномерный длинной NxK и делаем враппер который при доступе по i,j будет вычислять индекс как произведение i и j и доступаться к одномерному массиву уже по этому индексу.
Единственная новость о массивах в Java которую я вынес из статьи это то, что в Java есть такой convenience как int g[][] = new int[n][n]; который сразу еще и дочерние подмассивы создает. Хотя наверно лучше б его не было — ибо сбивает с толку (что автор статьи нам продемонстрировал на практике).
Строго говоря в Java вообще нет двумерных массивов, поэтому автор всех здорово запутал своими параллелями с Си и Паскалем.
Видимо отсюда и весь налет мистики.
В Си и Паскале двумерные массивы есть (насколько я помню), и там размерность массива NxK будет означать непрерывный блок памяти размером NxK в котором с помощью pointer arithmetics можно вычислить адрес каждой конкретной ячейки — но в Java ничего такого нет. «Двумерный» массив в Java это одномерный массив ссылок на одномерные массивы, каждый из которых может быть разной длинны например, а то и просто отсутствовать (null ссылка).
Вроде такого:
int a[][] = new int[4][];
a[1]=new int[2];
a[2]=new int[3];
a[3]=new int[2];
В результате имеем:
a[0] — null
a[1] — массив 2-х интов, a[1][2] — ok, a[1][3] — out of bounds
a[2] — массив 3-х интов, a[2][3] — ok, a[2][4] — out of bounds
a[3] — опять массив 2-х интов.
Когда в Java надо завести именно двумерный массив, как в Си — заводим одномерный длинной NxK и делаем враппер который при доступе по i,j будет вычислять индекс как произведение i и j и доступаться к одномерному массиву уже по этому индексу.
Единственная новость о массивах в Java которую я вынес из статьи это то, что в Java есть такой convenience как int g[][] = new int[n][n]; который сразу еще и дочерние подмассивы создает. Хотя наверно лучше б его не было — ибо сбивает с толку (что автор статьи нам продемонстрировал на практике).
Строго говоря в Java вообще нет двумерных массивов, поэтому автор всех здорово запутал своими параллелями с Си и Паскалем. Видимо отсюда и весь налет мистики.
Да, это если строго. А по факту получается, что int[][] генерирует вложенные массивы, а не перемножает i и j и делает массив соответствующего размера. Т.е.:
int a[][] = new int[N][K]
int b[] = new int[N*K];
a != b;
Кроме того, я так предполагаю, что в мануале по Java этот момент указан…
Так и есть, одна из первых ссылок в гугле ведет вот сюда: www.learn-java-tutorial.com/Arrays.cfm#Multidimensional-Arrays-in-Memory
int[][] nums = new int[3][6];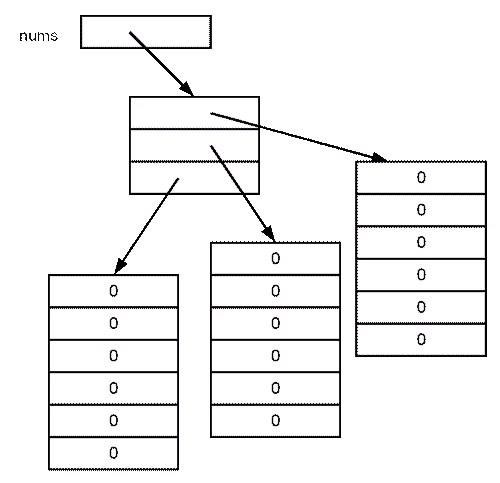
P.S.
> как произведение i и j
Oops, ошбочка, i*N+j (-:
> как произведение i и j
Oops, ошбочка, i*N+j (-:
Вы не правы. Виноват в первую очередь кеш. Чтобы в этом убедиться добавьте 5-ый тест, в котором в присвоении будет arr[j*n+i] = 40; и сравните с четвертым.
p.s. Надеюсь оптимизатор не поменяет местами циклы.
p.s. Надеюсь оптимизатор не поменяет местами циклы.
Это зависит от того, на каком языке написано.
Если мы говорим про C или Pascal, то можем почувствовать напрямую влияние кэша (при случайном доступе), ошибок предсказателя переходов и тому подобные низкоуровневые эффекты. Если мы говорим о Java с его массивами-объектами, кучей, GC и барьерами в Java Memory Model — то вмешиваются ещё куча эффектов, которые могут доминировать над тем, что определяет результат на C или C++.
Кроме того, подход к тестированию производительности кода на Java должен учитывать работу на конкретной JavaVM. В частности, работу JIT на HotSpot, коли мы тестируемся на ней. Т. е. измерение времени выполнения, как оно приведено в статье — абсолютно бесполезно. Как минимум, об этом здесь говорили leventov, gvsmirnov.
Если мы говорим про C или Pascal, то можем почувствовать напрямую влияние кэша (при случайном доступе), ошибок предсказателя переходов и тому подобные низкоуровневые эффекты. Если мы говорим о Java с его массивами-объектами, кучей, GC и барьерами в Java Memory Model — то вмешиваются ещё куча эффектов, которые могут доминировать над тем, что определяет результат на C или C++.
Кроме того, подход к тестированию производительности кода на Java должен учитывать работу на конкретной JavaVM. В частности, работу JIT на HotSpot, коли мы тестируемся на ней. Т. е. измерение времени выполнения, как оно приведено в статье — абсолютно бесполезно. Как минимум, об этом здесь говорили leventov, gvsmirnov.
То что на яве к результатам влияния кэша может добавиться куча других эффектов — само собой, но как вы уже заметили — влияние кэша будет в обоих случаях, а в конкретном синтетическом примере это десятки раз.
В общем подход должен учитывать не только виртуальную машину, но и железо, на котором код исполняется. Например у GPU есть текстурный кэш, который изначально двухмерный.
В общем подход должен учитывать не только виртуальную машину, но и железо, на котором код исполняется. Например у GPU есть текстурный кэш, который изначально двухмерный.
Проблема точно в кэше, в данном случае в расположении в памяти двумерных массивов. Если в первом цикле заменить g[i][j] на g[j][i], его скорость упадет в 20, поскольку в одном случае проход идет по строкам, элементы каждой строки в памяти близко, а в другом — по столбцам, элементы которых далеко. Я пока не знаю, как ее решить, ясно, что нельзя обращаться к элементам других строк в цикле.
Перепроверил на таком коде:
Байт код второго цикла больше. Может и не кэше дело, а в способах адресации.
public class Test2 {
public static void main(String[] args) {
int n = 8000;
int g = new int[n*n];
long st, en;
// one
st = System.nanoTime();
for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
g[i*n + j] = i + j;
}
}
en = System.nanoTime();
System.out.println("\nOne time " + (en - st)/1000000.d + " msc");
// two
st = System.nanoTime();
for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
g[j*n + i] = i + j;
}
}
en = System.nanoTime();
System.out.println("\nTwo time " + (en - st)/1000000.d + " msc");
}
}
Байт код второго цикла больше. Может и не кэше дело, а в способах адресации.
Замеры кода на Java в один прогон без прогрева и построение на этих результатах далеко идущих выводов — это тоже повод поговорить…
Хотя тут вы получили более-менее верные оценки, это чистое везение.
Причина замедления в том, что на каждой итерации идет дереференс массива
118 (скорее, 128) — это какой-то внутренний порог в HotSpot, когда он делает какой-то продвинутый анализ объектов (только массивов?) в методе, только если их меньше этого количества.
Кстати, я на Java 8 этот порог не нашел. Возможно, теперь они все равно анализируют первые 128(?) объектов в методе, поэтому производительность деградирует постепенно с ростом N.
Хотя тут вы получили более-менее верные оценки, это чистое везение.
Причина замедления в том, что на каждой итерации идет дереференс массива
g[j], чтение его длины, проверка на границы при записи i-го элемента, весь фарш. А когда во внутреннем цикле обращаются только к одному массиву g[i], это все JIT выносит за цикл.118 (скорее, 128) — это какой-то внутренний порог в HotSpot, когда он делает какой-то продвинутый анализ объектов (только массивов?) в методе, только если их меньше этого количества.
Кстати, я на Java 8 этот порог не нашел. Возможно, теперь они все равно анализируют первые 128(?) объектов в методе, поэтому производительность деградирует постепенно с ростом N.
import org.openjdk.jmh.annotations.*;
import java.util.concurrent.TimeUnit;
@State(Scope.Benchmark)
@BenchmarkMode(Mode.AverageTime)
@OperationsPerInvocation(ArrayFill.N * ArrayFill.N)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class ArrayFill {
public static final int N = 380;
public int[][] g;
@Setup
public void setup() {
g = new int[N][N];
}
@GenerateMicroBenchmark
public int simple(ArrayFill state) {
int[][] g = state.g;
for(int i = 0; i < g.length; i++) {
for(int j = 0; j < g[i].length; j++) {
g[i][j] = i + j;
}
}
return g[g.length - 1][g[g.length - 1].length - 1];
}
@GenerateMicroBenchmark
public int optimized(ArrayFill state) {
int[][] g = state.g;
for(int i = 0; i < g.length; i++) {
g[i][i] = 2* i;
for(int j = 0; j < i; j++) {
g[j][i] = g[i][j] = i + j;
}
}
return g[g.length - 1][g[g.length - 1].length - 1];
}
}
Не беспокойтесь — я проверял на многих прогонах. И с прогревом тоже поэкспериментировал. К слову, автоматический прогрев по участкам кода без многократного вызова функции обычно не производится.
Для демонстрации пишется короткий и прозрачный для понимания код, который демонстрирует проблему. Что я и сделал. Вы говорите везение? Чем больше работаешь, тем чаще везет.
Про спец обработку массива новой строки совершенно правильно уже писал MuLLtiQ, который воспользовался javap. Там действительно идет громоздкий дереференс. Но если уже раздерибанили байткод, то есть смысл досмотреть до конца? Что там еще? И кстати, можно ли все таки воспользоваться симметричностью и сделать все быстрее чем по строкам?
Для демонстрации пишется короткий и прозрачный для понимания код, который демонстрирует проблему. Что я и сделал. Вы говорите везение? Чем больше работаешь, тем чаще везет.
Про спец обработку массива новой строки совершенно правильно уже писал MuLLtiQ, который воспользовался javap. Там действительно идет громоздкий дереференс. Но если уже раздерибанили байткод, то есть смысл досмотреть до конца? Что там еще? И кстати, можно ли все таки воспользоваться симметричностью и сделать все быстрее чем по строкам?
Ну вот, проверяете один код, а публикуете другой. А народ его и запускает.
Я байткод и тем более ассемблер вообще не смотрел, это все предположения.
Как справедливо заметил voronaam, провальна любая попытка сэкономить на одном вшивом сложении. Если бы в цикле стояло целочисленное деление, и это был бы Си с плоскими массивами, вот тогда можно было бы.
Нет, самый простой вариант конкретно этой задачи на Java — он же и самый быстрый.
Я байткод и тем более ассемблер вообще не смотрел, это все предположения.
Как справедливо заметил voronaam, провальна любая попытка сэкономить на одном вшивом сложении. Если бы в цикле стояло целочисленное деление, и это был бы Си с плоскими массивами, вот тогда можно было бы.
Нет, самый простой вариант конкретно этой задачи на Java — он же и самый быстрый.
Что там еще?Разворачивание цикла, а в усложненном варианте — нет (предположение)
НЛО прилетело и опубликовало эту надпись здесь
Я видимо плохо объясняю. Я публикую код, который наилучшим образом демонстрирует проблему.
Если бы я публиковал код в котором у меня неожиданно просел fps после рефакторинга, это было бы бессмысленно. Я выделил проблему, проверил все возможные накладки и опубликовал короткий понятный код, демонстрирующий проблему. Если Вам почему-то хочется считать, что все хорошо получилось только по счастливой случайности, боюсь я не смогу Вас переубедить.
Если бы я публиковал код в котором у меня неожиданно просел fps после рефакторинга, это было бы бессмысленно. Я выделил проблему, проверил все возможные накладки и опубликовал короткий понятный код, демонстрирующий проблему. Если Вам почему-то хочется считать, что все хорошо получилось только по счастливой случайности, боюсь я не смогу Вас переубедить.
НЛО прилетело и опубликовало эту надпись здесь
или просто сказать таким интервьюируемым «спасибо, удачи» и пойти работать в другое место.
Вот поэтому сейчас «майндфаки» на собеседованиях не в почёте. Гугл тоже с год как от них отказался. Майндфак и его решение на собеседовании может свидетельствовать как о неадекватности проводящего собеседование, так и о себеседуемом :)
Гениально! До сегодняшнего дня не задумывался. Чтобы увидеть и понять эффект достаточно поменять местами i c j в вычислении индекса.
Кому интересно вот моя версия на С++
// test-time.cpp : main project file.
#include "stdafx.h"
#include <windows.h>
#include <iostream>
using namespace System;
__int64 GetTime()
{
__int64 value = 0;
QueryPerformanceCounter((LARGE_INTEGER *)&value);
return value;
}
int main(array<System::String ^> ^args)
{
int n = 8000;
int* g = new int[n*n];
__int64 st, en;
// one
st = GetTime();
for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
g[i*n +j] = i + j;
}
}
en = GetTime();
std::cout << "\n1 time ";
std::cout << (en - st);
// two
st = GetTime();
for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
g[j*n +i] = i + j; //j и i меняем местами
}
}
en = GetTime();
std::cout << "\n1 time ";
std::cout << (en - st);
Console::ReadKey();
return 0;
}
</spoiler>
Вы еще и результаты вычислений в элементах массива g не используете. Но HotSpot их не выкинул, почему-то. Поразительно, что замеры дали адекватные результаты
Совершенно верно. Но почему Вы считаете, что автор непременно глуп и невнимателен? Результаты вычислений суммировались, чтоб их не выкинул оптимизатор. Когда убедился, что ничего не выбрасывается, исключил лишнее из кода. Еще раз говорю, код демонстрирует проблему. И Вы это подтверждаете. Что Вас смущает?
НЛО прилетело и опубликовало эту надпись здесь
Интересная задача! Посмотрел код и вот что видно. В варианте два тело цикла
А в варианте один только
Мне кажется дело в лишнем aaload. В первом варианте компилятор работает с массивом как с одномерным. Во втором, он строго следуюет написанному коду и постоянно пихает в стек ссылку на очередной внутренний массив как на отдельный массив. Ему же надо найти g[j].
Ну и вообще получается, что раз количество операций записи у нас одинаково (мы же весь массив инициируем), то мы хотели сэкономить на вычилении каждого из элементов. Но вычисление элемента у нас один iadd, так что после «оптимизации» мы потратили больше операций вычисляя координаты в памяти куда писать.
35: aaload
36: iload_3
37: aload_1
38: iload_3
39: aaload
40: iload_2
41: iload_2
42: iload_3
43: iadd
44: dup_x2
45: iastore
46: iastore
А в варианте один только
27: aaload
28: iload_3
29: iload_2
30: iload_3
31: iadd
32: iastore
Мне кажется дело в лишнем aaload. В первом варианте компилятор работает с массивом как с одномерным. Во втором, он строго следуюет написанному коду и постоянно пихает в стек ссылку на очередной внутренний массив как на отдельный массив. Ему же надо найти g[j].
Ну и вообще получается, что раз количество операций записи у нас одинаково (мы же весь массив инициируем), то мы хотели сэкономить на вычилении каждого из элементов. Но вычисление элемента у нас один iadd, так что после «оптимизации» мы потратили больше операций вычисляя координаты в памяти куда писать.
Это супер близко к полному решению. Дальнейшие разборки потребуют вникнуть в полученный код. Только учтите, что просто число команд еще не делает погоду. Да, второй цикл в два раза короче (6 команд), но он и выполняется в два раза большее число раз.
Хм, вообще-то мой комментарий был совсем не о количестве команд в листинге. Для интереса я заменил функцию вычисления элемента с i + j на rand.nextInt(100) / (1 + rand.nextInt(100)) * rand.nextInt(100), оставив при этом весь остальной код тем же (то есть матрица по-прежнему получится диагональная). И вот результат:
То есть оптимизировать таким образом имеет смысл если операция вычисления Mij = Mji достаточно «дорогая».
One time 2072.3487 msc Two time 1246.582756 msc
То есть оптимизировать таким образом имеет смысл если операция вычисления Mij = Mji достаточно «дорогая».
Посмотрел и дизассемблер. Ещё интересно, что JVM вынесла проверку границ за пределы цикла в «неоптимизированном» варианте. В первом варианте есть только одно место с комментарием «implicit exception», в втором их три. Я не слишком часто читают дизассемблерный код из JVM, так что дальше разбираться пожалуй не буду.
Буду следить за обновлениями в топике. Спасибо за задачку!
P.S. Ничего себе у вас задачки для (pre)juniour'ов :)
Буду следить за обновлениями в топике. Спасибо за задачку!
P.S. Ничего себе у вас задачки для (pre)juniour'ов :)
Есть еще такая вещь, как cache contentions. Суть в том, что при некоторых обстоятельствах(«удачном» размере матрицы) g[i][j] и g[j][i] приходятся на одну линию кэша(см en.wikipedia.org/wiki/CPU_cache#Associativity). Получается что при обращение к первому адресу в L1 из L2 подтягивается одна область памяти. При обращении к второму — другая. И так _каждое_! обращение. Т.е. вместо кэширования области памяти и дальнейшего чтения последующих напрямую из L1 мы каждый раз ждем перечитывания из L2. Та же история может быть с L2, только обходится еще дороже — перечитывать из L3 или того хуже из памяти.
Подробно про такие вещи хорошо рассказывается в «Optimizing software in C++» by Agner Fog — www.agner.org/optimize/optimizing_cpp.pdf
Подробно про такие вещи хорошо рассказывается в «Optimizing software in C++» by Agner Fog — www.agner.org/optimize/optimizing_cpp.pdf
Я думаю, что это не задача для новичка, потому, что это архитектурно-зависимая проблема.
Также задача зависит от уровня оптимизации компилятора, который может «удачный» вариант развернуть в неудачный ассемблер. Был у меня такой опыт, когда мне нужно было оптимизировать кусок кода, но после компиляции, ассемблер на выходе был хуже, чем изначальный вариант. А все потому, что своими действиями я сбивал оптимизатор компилятора и тот принимал малопитательные решения.
Если уже говорить о кешах — тут вообще тоска — размер строки кэша может варьироваться от 16 байт до 256. Я думаю что даже эти рамки можно поставить под сомнение. Так что же, писать код который будет зависеть от процессора? А как быть с системами реального времени где кэш часто отсутствует в меру своей непредсказуемости? Да и не стоит забывать про то что есть системы без поддержки страниц памяти, или наоборот с поддержкой огромных страниц.
Ну а если конкретнее — Вы хотели инициализировать массив — мой ответ memset!
Также задача зависит от уровня оптимизации компилятора, который может «удачный» вариант развернуть в неудачный ассемблер. Был у меня такой опыт, когда мне нужно было оптимизировать кусок кода, но после компиляции, ассемблер на выходе был хуже, чем изначальный вариант. А все потому, что своими действиями я сбивал оптимизатор компилятора и тот принимал малопитательные решения.
Если уже говорить о кешах — тут вообще тоска — размер строки кэша может варьироваться от 16 байт до 256. Я думаю что даже эти рамки можно поставить под сомнение. Так что же, писать код который будет зависеть от процессора? А как быть с системами реального времени где кэш часто отсутствует в меру своей непредсказуемости? Да и не стоит забывать про то что есть системы без поддержки страниц памяти, или наоборот с поддержкой огромных страниц.
Ну а если конкретнее — Вы хотели инициализировать массив — мой ответ memset!
Задач для новичка не бывает. Есть просто задачи. Человек их решает, мыслит, выдвигает гипотезы. Ты наблюдаешь, общаешься. Вы видите, как коллективный разум на три счета здесь раскрутил ситуацию?
memset конечно форевер, но это подмена задачи. Вопрос именно в доступе, а не в том, что мы с ним делаем.
А согласитесь, забавная вышла задачка на ровном месте. Нет?
memset конечно форевер, но это подмена задачи. Вопрос именно в доступе, а не в том, что мы с ним делаем.
А согласитесь, забавная вышла задачка на ровном месте. Нет?
Странный подход с тем же успехом можно пытаться на вступительных экзаменах по математике не просить решать школьные задачи, а попросить из фундаментальных принципов придумать и обосновать, к примеру, интеграл. И посмотреть, как человек мыслит и выдвигает гипотезы. Но лично я знаю всего одного человека, который смог интеграл придумать самостоятельно, а подавляющее большинство людей приходит учиться, что бы учиться и проверять надо что они знаю, и есть ли смысл их учить. Или у вас в конторе все сплошь гении мирового масштаба, у в руководство берут по предъявлению нобелевского сертификата?
Когда мы последовательно записываем адреса, то вторая запись в границах одной кэш линейки застоллит процессор — он будет ждать окончания записи линейки в основную память. Когда доступы идут в разнобой (особенно в последнем примере с рандомным доступом к линейному массиву), то writeback происходит спекулятивно, без столла.
Согласен. А что writeback всегда происходит после изменения одного элемента массива?
Нет, пожалуй что writeback здесь будет происходить вообще только при выстеснении линейки из кэша…
Кстати, в примере с одномерным массивом, если тела циклов поменять местами, то второй цикл будет все равно работать быстрее. То есть второй цикл будет всегда быстрее, можно предположить что вступает в игру прогрев кэшей.
Кстати, в примере с одномерным массивом, если тела циклов поменять местами, то второй цикл будет все равно работать быстрее. То есть второй цикл будет всегда быстрее, можно предположить что вступает в игру прогрев кэшей.
> Когда мы последовательно записываем адреса, то вторая запись в границах одной кэш линейки застоллит процессор
совершенно неверно.
совершенно неверно.
К стати — вариант с кэшем не совсем уместен по отношению к первому примеру, поскольку второй индекс — это как раз строка, то есть во внутреннем цикле будет проход как раз по строке — последовательно в памяти. Прошу прощения — невнимательно читал. Ведь я же все знаю про массивы! ;)
Все-таки мало кому из начинающих разработчиков может прийти в голову думать о проблемах касательно способа доступа к памяти или особенностях реализации компилятора/виртуальной машины/интерпретатора.
Изначальный код, возможно, будет превосходно работать с каким-то компилятором в силу того, что он попадает под определенный шаблон оптимизации, точно так же, как и во многих случая i*2 === i<<1 для беззнаковых целых, если процессор поддерживает операцию сдвига.
Или например в с/с++ массивы вида int (a*)[n] и int **a неравноправны по отношению как к потреблению памяти так и доступа.
Я согласен, что задача интересна тем, чтоб посмотреть как человек будет пытаться анализировать ситуацию. И да, возникают вопросы =)
Все-таки мало кому из начинающих разработчиков может прийти в голову думать о проблемах касательно способа доступа к памяти или особенностях реализации компилятора/виртуальной машины/интерпретатора.
Изначальный код, возможно, будет превосходно работать с каким-то компилятором в силу того, что он попадает под определенный шаблон оптимизации, точно так же, как и во многих случая i*2 === i<<1 для беззнаковых целых, если процессор поддерживает операцию сдвига.
Или например в с/с++ массивы вида int (a*)[n] и int **a неравноправны по отношению как к потреблению памяти так и доступа.
Я согласен, что задача интересна тем, чтоб посмотреть как человек будет пытаться анализировать ситуацию. И да, возникают вопросы =)
Запостил провокационный вопрос на SO, пусть господа соревнуются в точности ответа ;)
Только — цыц!
stackoverflow.com/questions/21639405/java-2d-array-fill-innocent-optimization-caused-terrible-slowdown
Только — цыц!
stackoverflow.com/questions/21639405/java-2d-array-fill-innocent-optimization-caused-terrible-slowdown
… и правильный ответ там на него уже дали.
Правильный-то правильный, но довольно поверхностный, к сожалению. А вот Chen Gupta (думаю, что это IEMazurok) порадовал :)
Порадовал чем? Там же очередной лжебенчмарк, замеряющий время интерпретации + время JIT-компиляции. Небось, еще и на клиентской 32-битной JVM. Если измерять по-честному, разница получается мизерная, причем то в пользу одного, то в пользу другого варианта, в зависимости от опций JVM (UseCompressedOops).
[sarcasm]Чего уж там, давайте сразу на 10 итераций ручной loop unrolling сделаем — глядишь, будет еще эффективнее.[/sarcasm]
[sarcasm]Чего уж там, давайте сразу на 10 итераций ручной loop unrolling сделаем — глядишь, будет еще эффективнее.[/sarcasm]
Ничего загадочного. В «оптимизированном» варианте просто-напросто больше операций. Гораздо больше.
Если в простом примере на одной итерации внутреннего цикла, грубо говоря, делается один store (не зависящий от предыдущих), то во втором примере на каждой итерации делается:
1. load указателя на j-ю строку;
2. load длинны массива;
3. bounds check;
4. и два store.
причем эти операции не могут выполняться конвейерно, т.к. зависят от результатов предыдущих операций.
Добавим ко всему этому, что обращение к памяти сильно разнесено, а, значит, кеши и префетчи не работают, куча TLB промахов и всё такое.
Если в простом примере на одной итерации внутреннего цикла, грубо говоря, делается один store (не зависящий от предыдущих), то во втором примере на каждой итерации делается:
1. load указателя на j-ю строку;
2. load длинны массива;
3. bounds check;
4. и два store.
причем эти операции не могут выполняться конвейерно, т.к. зависят от результатов предыдущих операций.
Добавим ко всему этому, что обращение к памяти сильно разнесено, а, значит, кеши и префетчи не работают, куча TLB промахов и всё такое.
Интересно вот: а действительно ли в условиях нынешней сумасшедшей конкурентной гонки находится возможность заниматься вот такой оптимизацией?
Или же в данном примере проверяется навыки кандидата в оптимизации? Которые потом применяются не в улучшении производительности в работе с массивами, а в других, более серьезных ситуациях.
Расскажите, многоопытные товарищи
Или же в данном примере проверяется навыки кандидата в оптимизации? Которые потом применяются не в улучшении производительности в работе с массивами, а в других, более серьезных ситуациях.
Расскажите, многоопытные товарищи
Возможность и необходимость оптимизации, наверное, находится. Ведь не всегда есть возможность заставить пользователя удвоить число ядер или частоту — иногда надо выигрывать и за счёт более подходящего кода. Если рассматривать «оптимизацию» как улучшение существующего кода, то упражнение не о том — скорее, оно показывает, как писать надо, а как не надо. Чтобы при наличии выбора у человека было больше информации (пусть и для данного конкретного компилятора и процессора). А проверялось, насколько я понял, умение разбираться в не очень знакомой ситуации, а массивы и оптимизация тут, в общем, ни при чём — это всего лишь выбор игрового сценария.
Выбор, мягко говоря, неудачный. Это все равно что дать человеку решать шахматную задачу,
рассказать как ходят фигуры, но не сказать что пешка может стать ферзем.
Человек, на основании своих базовых знаний, просто не сможет логически вывести такой вариант.
рассказать как ходят фигуры, но не сказать что пешка может стать ферзем.
Человек, на основании своих базовых знаний, просто не сможет логически вывести такой вариант.
Думаю, что к его распоряжению все знания интернета. И главное, может быть, даже не то, что даст он правильный ответ или нет, а куда и как будет копать.
В случае java, за этими несколькими строчками кода, будет еще jit компилятор с profile optimization со своими правилами и багами. Что может сказать человек претендующий на junior позицию в этом случае?
Premature optimization is the root of all evil — Donald Ervin Knuth
In established engineering disciplines a 12% improvement, easily obtained, is never considered marginal and I believe the same viewpoint should prevail in software engineering — Donald Ervin Knuth
Ключевое слово здесь «premature». После того как выбраны алгоритмы, система написана и обладает необходимой функциональностью, есть тесты и измерена производительность на реальных данных и не хватает этих самых 12%, вот тогда можно приступать к такого рода оптимизации. Заниматься этим до — значит просто терять время и тормозить проект.
Premature optimization — это попытки экономии «на спичках», когда мы не понимаем — будет реальный выигрыш или нет. К сожалению под флагом борьбы с ними зачастую люди с легкостью вводят в систему прокладки и абстракции, каждая из которых вроде как и не сильно на что-то влияет, а в сумме — они дают ощутимое замедление и/или увеличение в размерах.
Потеря 12% десять раз — это замедление программы (или увеличение потребности в памяти или… нужное подчеркнуть) втрое. И если вы спохватитесь уже тогда, когда «система написана и обладает необходимой функциональностью», то в большинстве случаев вам придётся всё выкинуть к чёртовой бабушке и начать заново.
Простой пример: как вы будете бороться с тем, что ваша тормозит тупо из-за того, что у вас вместо конечного автомата обработка запросов осуществляется в виде сплошного участка кода, что требует отводить на каждый запрос свой поток? А с тем, что у вас борьба за православный DI привела к тому, что объекты, которые, в общем-то, не меняются во время запроса при этом преобразуются 100500 раз?
Из моего опыта: программисты на C/C++ иногда грешат этими самыми «premature optimizations», но по сравнению с программистами на Java, готовыми под развеваемыми вами знамёными выпускать монстров требующих гигабайт памяти и многоядерных процессоров для решения задач где, по хорошему, и 16-битного контроллера с парой мегабайт памяти должно хватать — они паиньки.
Потеря 12% десять раз — это замедление программы (или увеличение потребности в памяти или… нужное подчеркнуть) втрое. И если вы спохватитесь уже тогда, когда «система написана и обладает необходимой функциональностью», то в большинстве случаев вам придётся всё выкинуть к чёртовой бабушке и начать заново.
Простой пример: как вы будете бороться с тем, что ваша тормозит тупо из-за того, что у вас вместо конечного автомата обработка запросов осуществляется в виде сплошного участка кода, что требует отводить на каждый запрос свой поток? А с тем, что у вас борьба за православный DI привела к тому, что объекты, которые, в общем-то, не меняются во время запроса при этом преобразуются 100500 раз?
Из моего опыта: программисты на C/C++ иногда грешат этими самыми «premature optimizations», но по сравнению с программистами на Java, готовыми под развеваемыми вами знамёными выпускать монстров требующих гигабайт памяти и многоядерных процессоров для решения задач где, по хорошему, и 16-битного контроллера с парой мегабайт памяти должно хватать — они паиньки.
Тут мы вступаем на зыбкую почву «эффективности». По сути, даже код на ассемблере, в какой то мере абстракция. Ниже лежит процессор со спекулятивным исполнением команд, branch predictor, декодеры команд, scheduler микрокоманд, иерархическая модель памяти + NUMA и т.д. Чем выше уровень абстракций — тем быстрее можно получить работающий софт. Но вот вычислить этот максимально допустимый уровень и есть основная задача.
НЛО прилетело и опубликовало эту надпись здесь
Похожий пример досконально разобран в «What Every Programmer Should Know About Memory» by Ulrich Drepper.
Теперь намного раньше кончаются все кэши — L1D, L2, L3. Также не стоит забывать про Translation Look-Aside Buffer(TLB).
Добавлю интересный артефакт — подобный тест может быть своеобразным бенчмарком TLB внутри виртуальной машины, так как она там более многоуровневая.
Теперь намного раньше кончаются все кэши — L1D, L2, L3. Также не стоит забывать про Translation Look-Aside Buffer(TLB).
Добавлю интересный артефакт — подобный тест может быть своеобразным бенчмарком TLB внутри виртуальной машины, так как она там более многоуровневая.
Странно, а если использовать два массива, то второй вариант работает быстрее. Хотя, наверное, что-то похожее уже предлагали выше :) Что не так? Оптимизированный вариант быстрее, прямой доступ к ячейке памяти быстрее перебора… или я уже переседел в субботу на работе?
Не ясно следующее:
Самым быстрым является простой способ заполнения симметричного массива с помощью двух вложенных циклов? Так и отвечать работодателю на собеседовании, если он вдруг задаст такую задачку?
Или же существует лучшее решение?
Самым быстрым является простой способ заполнения симметричного массива с помощью двух вложенных циклов? Так и отвечать работодателю на собеседовании, если он вдруг задаст такую задачку?
Или же существует лучшее решение?
Существует лучшее решение. С помощью четырёх вложенных циклов. Есть и другие. В соответствующей статье об этом довольно много написано. Конкретно про работу с массивами — в пятой части.
P.S. Топикстартер — молодец: среди программистов на C/C++ обычно людей, понимающих что происходит, много, но программисты на Java в 90% почему-то пребывают в наивной убеждённости, что они-то уж работают на высокоуровневом языке и до них-то все эти кеши и префетчи никак добраться не могут. Что, разумеется, ни разу не так, но осознать это непросто, так как опыта «чистого» общения со всей этой машинерией у них (в отличие от программистов, работающих на C/C++) нету.
P.S. Топикстартер — молодец: среди программистов на C/C++ обычно людей, понимающих что происходит, много, но программисты на Java в 90% почему-то пребывают в наивной убеждённости, что они-то уж работают на высокоуровневом языке и до них-то все эти кеши и префетчи никак добраться не могут. Что, разумеется, ни разу не так, но осознать это непросто, так как опыта «чистого» общения со всей этой машинерией у них (в отличие от программистов, работающих на C/C++) нету.
По-моему все просто первый вариант векторизуется, второй — нет.
Что за чушь, бежать от таких работодателей сломя голову, вот оптимизировал:
int n = 8000;
int g[][] = new int[n][n];
int gTmp[] = new int[n];
long st, en;
// one
st = System.nanoTime();
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
g[i][j] = i + j;
}
}
en = System.nanoTime();
System.out.println("\nOne time " + (en — st) / 1000000.d + " msc");
// two
st = System.nanoTime();
for (int i = 0; i < n; i++) {
gTmp[i] = 1;
}
for (int j = 0; j < n; j++) {
g[j] = gTmp;
}
en = System.nanoTime();
System.out.println("\nTwo time " + (en — st) / 1000000.d + " msc");
One time 39.901124 msc
Two time 0.133835 msc
int n = 8000;
int g[][] = new int[n][n];
int gTmp[] = new int[n];
long st, en;
// one
st = System.nanoTime();
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
g[i][j] = i + j;
}
}
en = System.nanoTime();
System.out.println("\nOne time " + (en — st) / 1000000.d + " msc");
// two
st = System.nanoTime();
for (int i = 0; i < n; i++) {
gTmp[i] = 1;
}
for (int j = 0; j < n; j++) {
g[j] = gTmp;
}
en = System.nanoTime();
System.out.println("\nTwo time " + (en — st) / 1000000.d + " msc");
One time 39.901124 msc
Two time 0.133835 msc
я что-то не понимаю, или второй вариант заполняет не суммой индексов?
Ваш вариант подходит для заполнения неизменяемого массива — но не для инициализации изменяемого. А вообще, идея хорошая, особенно вариант ниже на плюсах…
а потом говорим:
И видим, что на самом деле у нас в двумерном массиве используется N ссылок на один и тот же массив gTmp, т, е. используется в N раз меньше памяти. И правильный вариант такой:
Один прогон которого даст примерно одинаковые времена:
One time 56.96192 msc
Two time 50.87872 msc
gTmp[0] = -999;
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
System.out.print(g[i][j] + " ");
}
System.out.println();
}
И видим, что на самом деле у нас в двумерном массиве используется N ссылок на один и тот же массив gTmp, т, е. используется в N раз меньше памяти. И правильный вариант такой:
st = System.nanoTime();
for (int i = 0; i < n; i++) {
gTmp[i] = 1;
}
for (int j = 0; j < n; j++) {
System.arraycopy(gTmp, 0, g[j], 0, n);
}
en = System.nanoTime();
Один прогон которого даст примерно одинаковые времена:
One time 56.96192 msc
Two time 50.87872 msc
НЛО прилетело и опубликовало эту надпись здесь
Ответ на вопрос, «почему так происходит» был дан lunserv в комментарии чуть выше: habrahabr.ru/post/211747/#comment_7289139
Я его чуть дополнил примером.
На самом деле, для разных задач бывают разные требования. Если данную ситуацию рассматривать с общей точки зрения (обычное программирование) — это не экономия на спичках и не оптимизация, а выбор правильного решения задачи. Применение массива с массивами имеет смысл только для данных, в которых строки или столбцы могут быть разной размерности и не критично по скорости. Все. Во всех остальных случаях, когда в массиве данных строки и столбцы одинаковые или важна скорость, то следует применять обычный линейный массив, чтобы исключить лишний код, который может быт вставлен «шибко умным» компилятором и/или оптимизатором. Сюда относятся, например изображения, матрицы, таблицы и т.п. Ибо в любом случае, память в ПК линейная, т.о. это самое естественное представление данных.
Я его чуть дополнил примером.
Но мне все-таки правда интересно, где и в каких проектах такая оптимизация может быть полезной? Ведь по сути это экономия на спичках, а если нет, и правда нужна каждая миллисекунда при обработке матриц больших размеренностей, то неужели для java нет jni библиотеки для таких типовых операций на матрицах?
На самом деле, для разных задач бывают разные требования. Если данную ситуацию рассматривать с общей точки зрения (обычное программирование) — это не экономия на спичках и не оптимизация, а выбор правильного решения задачи. Применение массива с массивами имеет смысл только для данных, в которых строки или столбцы могут быть разной размерности и не критично по скорости. Все. Во всех остальных случаях, когда в массиве данных строки и столбцы одинаковые или важна скорость, то следует применять обычный линейный массив, чтобы исключить лишний код, который может быт вставлен «шибко умным» компилятором и/или оптимизатором. Сюда относятся, например изображения, матрицы, таблицы и т.п. Ибо в любом случае, память в ПК линейная, т.о. это самое естественное представление данных.
А что быстрее — двойное обращение по индексу, или умножение на размер по одной из координат, который тоже надо брать из памяти? Кроме того, если машина 32-битная, а массив гигабайтный, то единым куском его могут и не дать. Там массив массивов может оказаться правильнее.
Если в целом — то монопенисуально, т.е. без разницы — будет там перемножение индексов или сложение смещений адресов в массиве. Это если смотреть с точки зрения конечных действий. Все зависит от конретной реализации в конкретной железке. Просто не забываем, что там еще может оказаться код проверки на попадание индекса в размер массива, какие-то еще процедуры инициализации и все такое прочее. А так я уже сказал — выбор конкретного решения зависит от конкретной задачи. В разных случаях один и тот же код может быть разной степени правильности. Как отрицательной, так и положительной.
Неудачная попытка сэкономить на спичках в ущерб понятности кода. Для собеседований годится только разве что для того, чтобы дать ответ на вопрос «знаком ли кандидат с эффектами падения производительности из-за случайного доступа к памяти». К применению джавы в реальном мире имеет очень слабое отношение, как и к квалификации кандидата. Если, конечно, работа по предлагаемой вакансии не состоит в тюнинге и пропатчивании джавского JIT-компилятора.
Ну так разобрались бы перед тем, как пост писать.
Вообще такой пример надо «оптимизировать» распараллеливанием по ядрам исходного алгоритма (сохранится эффективность последовательного доступа и будут задействованы все ядра).
Все проблемы в следующей фразе:
«По этому обращаем его внимание на тот факт, что значения расположены симметрично и просим сэкономить на итерациях циклов. Конечно, зачем пробегать все значения индексов, когда можно пройти только нижний треугольник?»
А дело в том, что экономить нужно не на итерациях, а на операциях. Всё же просто:
— В оригинальном коде у нас N^2 записей в память — и как ты тут не оптимизируй, именно столько и останется. тут не соптимизировать.
— Далее, а стоит ли что нибудь нам i+j? Да ничего оно не стоит. Эта сумма на самом деле индуктивная и заменять такие выражения на инкремент умели еще в 70-х. :) Да к тому же это и пофиг, как i+j так и v+1 вычислаются с латенси в 1 такт, причем на исполнение программы этот 1 такт вообще никак не влияет, пойдет в параллель.
— адресная арифметика? Так же индуктивность + целочисленная арифметика. Intel CPU уже давно содержат по 3 целочисленных сложителя, у AMD тоже не один.
— Обслуживание циклов? Цикл короткий, с вероятностью 99% попадает под LSD (Loop Stream Detector). Profit.
Итого, имеем, что у нас есть N квадрат записей в память. Остальные операции можно не считать. Так что тут оптимизировать? Тут любое прикосновение к коду будет не оптимизацией, а пессимизацией, что автор нам успешно и продемонстрировал.
Вот если бы вместо (i+j) мы считали (int)(sin((double)(i+j))) тогда можно было о чем-нибудь говорить.
«По этому обращаем его внимание на тот факт, что значения расположены симметрично и просим сэкономить на итерациях циклов. Конечно, зачем пробегать все значения индексов, когда можно пройти только нижний треугольник?»
А дело в том, что экономить нужно не на итерациях, а на операциях. Всё же просто:
— В оригинальном коде у нас N^2 записей в память — и как ты тут не оптимизируй, именно столько и останется. тут не соптимизировать.
— Далее, а стоит ли что нибудь нам i+j? Да ничего оно не стоит. Эта сумма на самом деле индуктивная и заменять такие выражения на инкремент умели еще в 70-х. :) Да к тому же это и пофиг, как i+j так и v+1 вычислаются с латенси в 1 такт, причем на исполнение программы этот 1 такт вообще никак не влияет, пойдет в параллель.
— адресная арифметика? Так же индуктивность + целочисленная арифметика. Intel CPU уже давно содержат по 3 целочисленных сложителя, у AMD тоже не один.
— Обслуживание циклов? Цикл короткий, с вероятностью 99% попадает под LSD (Loop Stream Detector). Profit.
Итого, имеем, что у нас есть N квадрат записей в память. Остальные операции можно не считать. Так что тут оптимизировать? Тут любое прикосновение к коду будет не оптимизацией, а пессимизацией, что автор нам успешно и продемонстрировал.
Вот если бы вместо (i+j) мы считали (int)(sin((double)(i+j))) тогда можно было о чем-нибудь говорить.
Хорошая статья, заинтриговала. Жду полного решения ;)
Как способ потроллить / проверить соискателя — годится, а как бенчмарка — не очень.
Максимальная скорость, если именно за максимумом гоняться, — достигнется на каком-то крайне неочевидном алгоритме.
Потому что в нём будут
— префетчи
— разворачивание внутреннего и/или внешнего циклов
— выравнивания по границам линеек
— использование SIMD-интринсиков
причём размеры префетчей и развёртываний будут зависеть от конкретной архитектуры, т.е. где-то рядом будет ещё и код, интересующийся версией процессора.
На сях-плюсях проще не трахать себе мозг всеми этими делами, а взять готовую матричную библиотеку наподобие Eigen или MKL.
На яве — не знаю, не играл.
MKL, кстати, сильно различается по скорости первого и последующих запусков, — прогревает свои кэши.
Максимальная скорость, если именно за максимумом гоняться, — достигнется на каком-то крайне неочевидном алгоритме.
Потому что в нём будут
— префетчи
— разворачивание внутреннего и/или внешнего циклов
— выравнивания по границам линеек
— использование SIMD-интринсиков
причём размеры префетчей и развёртываний будут зависеть от конкретной архитектуры, т.е. где-то рядом будет ещё и код, интересующийся версией процессора.
На сях-плюсях проще не трахать себе мозг всеми этими делами, а взять готовую матричную библиотеку наподобие Eigen или MKL.
На яве — не знаю, не играл.
MKL, кстати, сильно различается по скорости первого и последующих запусков, — прогревает свои кэши.
Прочитал стать и первое ощущение от прочитанного — уровень юниоров программистов упал примерно раз в пятьдесят. Это действительно при наборе программистов такие собеседования или все же каких-нибудь сисадминов? Теперь понимаю почему я не могу пройти собеседования, собеседующие просто не понимают о чем я говорю :)
Андрей Терещенко, любезно разрешил разместить здесь цитату из нашего с ним обсуждения этой же темы на фейсбуке. Возможно она покажется полезной.
Цитата
"… И вот интересная картинка к коду ideone.com/k8h9k0 (предыдущий комментарий). На ней видно, как в определенные моменты с ростом размера данных, время исполнения увеличивается. Так на желтой линии по сравнению с черной видно влияние кеша, а разница между желтой и оранжевой (или синей и черной) — влияние вложенных массивов."

"… И вот интересная картинка к коду ideone.com/k8h9k0 (предыдущий комментарий). На ней видно, как в определенные моменты с ростом размера данных, время исполнения увеличивается. Так на желтой линии по сравнению с черной видно влияние кеша, а разница между желтой и оранжевой (или синей и черной) — влияние вложенных массивов."
А что там разбираться то? Запускаем, компилируем, смотрим ассемблерный выхлоп:
Код практически не меняется за исключением кусочка с присвоением.
Для быстрого случая:
Для медленного случая:
В ecx у нас в обоих случаях счетчик внешнего цикла (i), а в eax — вложенного (j).
А поскольку ecx меняется в 10000 раз меньше, то инструкция mov esi,[esi+ecx*4] в первом случае будет закеширована на каждые 10000 операций. Если в первом случае кешмиссов будет 10000, то во втором 10000*10000.
Я не знаю как у кого, но у нас на численных методах в универе была даже задача: оптимизация умножения больших матриц, которая заключалась в транспонировании матрицы перед умножением. Выйгрыш в скорости в процентном соотношении был даже выше чем в вашем примере.
p.s. Я не понял, а где подсветка ASM для тега Source? Нету чтоль?
Осторожно, ASM
быстрый случай:
медленный случай:
Project3.dpr.16: for i:=1 to n-1 do
0040712F 8B1D98BB4000 mov ebx,[$0040bb98]
00407135 4B dec ebx
00407136 85DB test ebx,ebx
00407138 7E2C jle $00407166
0040713A B901000000 mov ecx,$00000001
Project3.dpr.17: for j:=1 to n-1 do
0040713F 8B1598BB4000 mov edx,[$0040bb98]
00407145 4A dec edx
00407146 85D2 test edx,edx
00407148 7E18 jle $00407162
0040714A B801000000 mov eax,$00000001
Project3.dpr.18: g[i,j] := i + j;
0040714F 8B359CBB4000 mov esi,[$0040bb9c]
00407155 8B348E mov esi,[esi+ecx*4]
00407158 8D3C08 lea edi,[eax+ecx]
0040715B 893C86 mov [esi+eax*4],edi
0040715E 40 inc eax
Project3.dpr.17: for j:=1 to n-1 do
0040715F 4A dec edx
00407160 75ED jnz $0040714f
Project3.dpr.18: g[i,j] := i + j;
00407162 41 inc ecx
Project3.dpr.16: for i:=1 to n-1 do
00407163 4B dec ebx
00407164 75D9 jnz $0040713f
медленный случай:
Project3.dpr.22: for i:=1 to n-1 do
004071E2 8B1D98BB4000 mov ebx,[$0040bb98]
004071E8 4B dec ebx
004071E9 85DB test ebx,ebx
004071EB 7E2C jle $00407219
004071ED B901000000 mov ecx,$00000001
Project3.dpr.23: for j:=1 to n-1 do
004071F2 8B1598BB4000 mov edx,[$0040bb98]
004071F8 4A dec edx
004071F9 85D2 test edx,edx
004071FB 7E18 jle $00407215
004071FD B801000000 mov eax,$00000001
Project3.dpr.24: g[j,i] := i + j;
00407202 8B359CBB4000 mov esi,[$0040bb9c]
00407208 8B3486 mov esi,[esi+eax*4]
0040720B 8D3C08 lea edi,[eax+ecx]
0040720E 893C8E mov [esi+ecx*4],edi
00407211 40 inc eax
Project3.dpr.23: for j:=1 to n-1 do
00407212 4A dec edx
00407213 75ED jnz $00407202
Project3.dpr.24: g[j,i] := i + j;
00407215 41 inc ecx
Project3.dpr.22: for i:=1 to n-1 do
00407216 4B dec ebx
00407217 75D9 jnz $004071f2
Код практически не меняется за исключением кусочка с присвоением.
Для быстрого случая:
00407155 8B348E mov esi,[esi+ecx*4]
00407158 8D3C08 lea edi,[eax+ecx]
0040715B 893C86 mov [esi+eax*4],edi
Для медленного случая:
00407208 8B3486 mov esi,[esi+eax*4]
0040720B 8D3C08 lea edi,[eax+ecx]
0040720E 893C8E mov [esi+ecx*4],edi
В ecx у нас в обоих случаях счетчик внешнего цикла (i), а в eax — вложенного (j).
А поскольку ecx меняется в 10000 раз меньше, то инструкция mov esi,[esi+ecx*4] в первом случае будет закеширована на каждые 10000 операций. Если в первом случае кешмиссов будет 10000, то во втором 10000*10000.
Я не знаю как у кого, но у нас на численных методах в универе была даже задача: оптимизация умножения больших матриц, которая заключалась в транспонировании матрицы перед умножением. Выйгрыш в скорости в процентном соотношении был даже выше чем в вашем примере.
p.s. Я не понял, а где подсветка ASM для тега Source? Нету чтоль?
Дополню свой комментарий.
Вообще массив массивов использовать — это может и удобно для чтения кода, но чревато более частыми кешмиссами, ибо это будет не один кусок данных в памяти, как менеджер памяти раскидает — так оно и будет. И для массивов размерности [10000, 1] — перерасход памяти, так как массивы в большинстве ЯП хранят по отрицательному смещению служебную информацию (счетчики ссылок, размер и т.п.), а поскольку память под массив выделяется менеджером памяти, то менеджер памяти под блок памяти тоже хранит служебную информацию ;)
Итого выделив массив в 4 байта мы реально можем выделить 12-16 байт памяти. Я уже молчу о том, что выделить 10000 раз память под массив в 4 байта — это на порядки медленнее чем выделить один раз 40000 байт.
В общем рекомендую использовать одномерные массивы, а индекс считать самому, чтобы не получить в пах от производительности. Ну и само собой не забывать про кеш.
Вообще массив массивов использовать — это может и удобно для чтения кода, но чревато более частыми кешмиссами, ибо это будет не один кусок данных в памяти, как менеджер памяти раскидает — так оно и будет. И для массивов размерности [10000, 1] — перерасход памяти, так как массивы в большинстве ЯП хранят по отрицательному смещению служебную информацию (счетчики ссылок, размер и т.п.), а поскольку память под массив выделяется менеджером памяти, то менеджер памяти под блок памяти тоже хранит служебную информацию ;)
Итого выделив массив в 4 байта мы реально можем выделить 12-16 байт памяти. Я уже молчу о том, что выделить 10000 раз память под массив в 4 байта — это на порядки медленнее чем выделить один раз 40000 байт.
В общем рекомендую использовать одномерные массивы, а индекс считать самому, чтобы не получить в пах от производительности. Ну и само собой не забывать про кеш.
И еще дополню:
И все таки виноват кэш процессора. Как это работает:
Представим, что в кэш у нас влезло 50К элементов. При случайном доступе к массиву в 100К элементов у нас вероятность попасть в кэш аж 50%. Для чистоты эксперимента давайте увеличим одномерный массив до 10000*10000 = 100КК элементов, и бегать будем по нему не случайным доступом, а двойным циклом по индексам g[i*10000+j] в одном случае, и g[j*10000+i] во втором. Вы сильно удивитесь, но разница будет не 10% как при случайном доступе.
Пока лидирует версия, что «виноват» кэш процессора.
Т.е. случайный доступ к элементам большого массива на ~10% медленнее чем последовательный. Возможно и в правду какую-то роль может сыграть кэш. Однако, в исходной ситуации производительность проседала в разы. Значит есть еще что-то.
И все таки виноват кэш процессора. Как это работает:
Представим, что в кэш у нас влезло 50К элементов. При случайном доступе к массиву в 100К элементов у нас вероятность попасть в кэш аж 50%. Для чистоты эксперимента давайте увеличим одномерный массив до 10000*10000 = 100КК элементов, и бегать будем по нему не случайным доступом, а двойным циклом по индексам g[i*10000+j] в одном случае, и g[j*10000+i] во втором. Вы сильно удивитесь, но разница будет не 10% как при случайном доступе.
Я не понял, а где подсветка ASM для тега Source? Нету чтоль?Учитывая количество различных ассемблеров даже в пределах x86_64, ожидаемо, что её нет.
У всех разных ассемблеров есть общая часть, каждая строка может быть представлена как:
<инструкция> [операдны] [; комментарий]
есть еще лейблы, просто строки с комментариями, макросы, но думаю распарсить и правильно выровнять код в общем случае — не большая проблема. Под подсветкой я имел ввиду не столько подсветку, сколько выравнивание.
<инструкция> [операдны] [; комментарий]
есть еще лейблы, просто строки с комментариями, макросы, но думаю распарсить и правильно выровнять код в общем случае — не большая проблема. Под подсветкой я имел ввиду не столько подсветку, сколько выравнивание.
Кроме собственно ассемблерного кода, который публикуется относительно редко, народ часто выкладывает листинг дизасемблера. Там может быть колонка с адресами, с командами as-is (до дизассемблирования), бывают разные варианты записи констант (навскидку 0, $0, #0), разное количество аргументов (в ARM команда push/pop может применяться к группе регистров, до 13 штук разом), разные способы обозначения косвенной адресации, постинкрементов и прочей нечисти. Так что не факт, что появятся в разумном будущем.
Делаю ставку на кэш и векторизацию / распараллеливание.
А как называется ваша контора?
НЛО прилетело и опубликовало эту надпись здесь
Статья, вне всякого сомнения, интересная и полезная. Но — не про массивы.
НЛО прилетело и опубликовало эту надпись здесь
44мс — это очень мало для цикла из миллиарда итераций. Даже если процессор с тактовой частотой 4ГГц делает по итерации за такт, выходит 250мс. Но реальное время должно быть еще больше — ведь на каждой итерации не менее четырех команд (++x, ++k, сравнение и условный переход).
По всей видимости, оптимизатор из первого цикла что-то вырезал. Кабы не сам цикл. Правда, в таком случае 44мс становится уже нереально много…
В любом случае, такое поведение оптимизатора заставляет по-новому взглянуть на бенчмарки автора и задать вопрос: а что они вообще измеряют?
По всей видимости, оптимизатор из первого цикла что-то вырезал. Кабы не сам цикл. Правда, в таком случае 44мс становится уже нереально много…
В любом случае, такое поведение оптимизатора заставляет по-новому взглянуть на бенчмарки автора и задать вопрос: а что они вообще измеряют?
Особенность profile optimization, похожий баг.
$ java -version
java version "1.7.0_45"
Java(TM) SE Runtime Environment (build 1.7.0_45-b18)
Java HotSpot(TM) 64-Bit Server VM (build 24.45-b08, mixed mode)
$ java App
0.039184857 2.360865017
0.038515955 1.953248084
0.033702157 1.955458985
0.033699063 1.953420415
0.03370587 1.952605481
0.033703395 1.956728721
0.033702775 1.954714283
0.033710201 1.954150574
0.033706178 1.95341268
0.033711439 1.952654055
$ java -XX:MaxTrivialSize=50 App
0.039914707 0.01686856
0.045489296 0.033697825
0.033701847 0.033747329
0.033702776 0.033704942
0.03370061 0.033698754
0.033699992 0.033697207
0.033698135 0.033700919
0.033698445 0.033698135
0.033698135 0.033699373
0.033708345 0.033699682
Возможно повторюсь, но ошибка здесь в частом ненужном обращении к индексам. Сразу надо заметить, что «оптимизация» треугольниками ложная, т.к. (i+j) — это ничего не стоящая операция, по сравнению с правильным обходом массива.
Надо понимать, что в Java двумерные массивы не являются матрицами, а массивами из массивов. Поэтому оптимальным способом представления матрицы является ее компактификация в одномерный массив. Но раз уж задание с двумерным массивом, попробуем оптимизировать…
g[i] дает указатель на одномерный массив строки, причем вычисляется при заполнении каждого столбца. При этом происходит вычисление смещения элемента, проверка выхода за границы и доступ к объекту по указателю. Это можно исключить:
Надо понимать, что в Java двумерные массивы не являются матрицами, а массивами из массивов. Поэтому оптимальным способом представления матрицы является ее компактификация в одномерный массив. Но раз уж задание с двумерным массивом, попробуем оптимизировать…
g[i] дает указатель на одномерный массив строки, причем вычисляется при заполнении каждого столбца. При этом происходит вычисление смещения элемента, проверка выхода за границы и доступ к объекту по указателю. Это можно исключить:
for(int i = 0; i < n; i++) {
int[] row = g[i];
for(int j = 0; j < n; j++) {
row[j] = i + j;
}
}
Воспользоваться симметрией, наверно, не получится — накладные расходы на доступ к произвольным элементам съедают все.
Вариант Throwable хорош, но до него додумался оптимизатор — работает он ровно так же, как первоначальный код.
Удивительно, но такой вариант работает немного быстрее:
Возможно, из-за первой строки?
Вариант Throwable хорош, но до него додумался оптимизатор — работает он ровно так же, как первоначальный код.
Удивительно, но такой вариант работает немного быстрее:
for(int i = 0; i < n; i++) {
g[0][i] = i;
}
for(int i = 1; i < n; i++) {
for(int j = 0; j < n; j++) {
g[i][j] = g[i-1][j]+1;
}
}
Возможно, из-за первой строки?
Для заполнения — Array.fill например.
Для Си и иже с ними — вообще memset(buf, X, sizeof(buf[0])*n*n);
Для Си и иже с ними — вообще memset(buf, X, sizeof(buf[0])*n*n);
g: Array of Array of Integer;
…
n := 10000;
SetLength(g, n, n);
…
for i:=1 to n-1 do
for j:=1 to n-1 do
g[i,j] := i + j;
Динамические массивы в паскале начинаются с нулевого индекса.
Проверял на двумерных массивах на Java и на С++, а также на одномерных, с искусственно реализованной двумерностью вида A[i*n+j].
C++
[][]One time 90 mcs
[][]Two time 710 mcs
[]One time 80 mcs
[]Two time 830 mcs
Во всех случаях, за исключение первого (массив массивов) имеем одну и ту же физическую модель — обычной линейной памяти (двумерный массив в Си «строгается» по строчкам). Вывод: разные скорости — эффект вытеснения из кэша хоть по LRU, хоть по FIFO. Если «прыгать» по адресам через n элементов (т.е. по столбцам), то независимо от размера подгружаемого в кэш блока периодически будет возникать ситуация, когда будет вытесняться тот блок, в которому будет СЛЕДУЮЩЕЕ обращение. Разница, похоже, соответствует отношению времени доступа к «оперативной памяти» и кэш.
C++
[][]One time 90 mcs
[][]Two time 710 mcs
[]One time 80 mcs
[]Two time 830 mcs
Во всех случаях, за исключение первого (массив массивов) имеем одну и ту же физическую модель — обычной линейной памяти (двумерный массив в Си «строгается» по строчкам). Вывод: разные скорости — эффект вытеснения из кэша хоть по LRU, хоть по FIFO. Если «прыгать» по адресам через n элементов (т.е. по столбцам), то независимо от размера подгружаемого в кэш блока периодически будет возникать ситуация, когда будет вытесняться тот блок, в которому будет СЛЕДУЮЩЕЕ обращение. Разница, похоже, соответствует отношению времени доступа к «оперативной памяти» и кэш.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Знаете ли Вы массивы?