Комментарии 173
Make-файлы действительно ужасны. Код на бейсике и тот лучше выглядит:)
Я вообще за декларативный подход к описаню проектов вместо императивного, т.е. это должен быть не скрипт типа make-файла, а иерархический файл на базе xml или чего-то подобного, внутри которого в определенных узлах дерева содержатся имена файлов проекта, зависимости, опции компиляции и т.п. Более того, я склоняюсь к мысли, что базовый формат файла проекта должен включаться в стандарт языка программирования, чтобы любой компилятор и любая среда разработки могли открыть и скомпилировать любой проект (созданный в другой IDE и для другого компилятора) целиком. Разумеется, каждая IDE может иметь свои «расширения» формата, не влияющие на суть проекта, но в том же xml можно спокойно это организовать.
Что касается сред разработки — в них главное действительно то, что они должны работать. Дебаггеры обязательно нужны — иногда проще один раз пройти по шагам в отладчике, чтобы понять что неправильно в алгоритме, чем что-то там компилировать в уме. Ну и конечно, среды разработки должны быть легкими. И в смысле простоты использования, и в смысле потребляемых ресурсов компьютера. Много функций не надо — но те что есть, должны работать безупречно, не тормозить и не глючить ни при каких обстоятельствах.
Писать же код в блокнотах, вимах и т.п. — если люди привыкли то почему-бы и нет, но приятнее все-же пользоваться специальными инструментами.
Я вообще за декларативный подход к описаню проектов вместо императивного, т.е. это должен быть не скрипт типа make-файла, а иерархический файл на базе xml или чего-то подобного, внутри которого в определенных узлах дерева содержатся имена файлов проекта, зависимости, опции компиляции и т.п. Более того, я склоняюсь к мысли, что базовый формат файла проекта должен включаться в стандарт языка программирования, чтобы любой компилятор и любая среда разработки могли открыть и скомпилировать любой проект (созданный в другой IDE и для другого компилятора) целиком. Разумеется, каждая IDE может иметь свои «расширения» формата, не влияющие на суть проекта, но в том же xml можно спокойно это организовать.
Что касается сред разработки — в них главное действительно то, что они должны работать. Дебаггеры обязательно нужны — иногда проще один раз пройти по шагам в отладчике, чтобы понять что неправильно в алгоритме, чем что-то там компилировать в уме. Ну и конечно, среды разработки должны быть легкими. И в смысле простоты использования, и в смысле потребляемых ресурсов компьютера. Много функций не надо — но те что есть, должны работать безупречно, не тормозить и не глючить ни при каких обстоятельствах.
Писать же код в блокнотах, вимах и т.п. — если люди привыкли то почему-бы и нет, но приятнее все-же пользоваться специальными инструментами.
Мейкфайлы, конечно, вполне себе ужасны. И тем не менее, язык мейкфайлов — вполне себе декларативный язык. Мейкфайлы описывают ациклический граф, в узлах которого — как раз ваши файлы в проекте. Иерархические файлы, зависимости, флаги компиляции — все это можно реализовать.
По поводу формата файла проекта в стандарте языка. Для больших мейнстримовых языков: 1) поздно уже, поезд ушел. Да и на разных платформах — разные исторические традиции. 2) комитеты типа С++ никогда не договорятся; 3) всегда будут те, кому встроенный формат не подойдет, потому что не решит некоторых задач; 4) вместо того, чтобы сосредоточиться на разработке 1 языка, надо будет разработать 2 языка.
По поводу формата файла проекта в стандарте языка. Для больших мейнстримовых языков: 1) поздно уже, поезд ушел. Да и на разных платформах — разные исторические традиции. 2) комитеты типа С++ никогда не договорятся; 3) всегда будут те, кому встроенный формат не подойдет, потому что не решит некоторых задач; 4) вместо того, чтобы сосредоточиться на разработке 1 языка, надо будет разработать 2 языка.
Открываем любой мейкфайл — и видим if, else, case и т.д. Это не декларативность.
Одна из причин, по которой мне нравится декларативность — как раз макимальная интеграция с IDE. Можно открыть опции в каком-нибудь редакторе свойств, список файлов доступен визуально и т.д.
Да, в сложных проектах вероятно действительно нужен именно язык сборки, и скорее всего чисто декларативным проектом не обойтись. Я это прекрасно понимаю. Скажу честно — я не знаю как разрешить это противоречие. Но вероятно, нужно идти в сторону некоего структурированного файла, в котором информация по максимуму представлена в декларативном виде (и полностью доступна из IDE), а императивные фрагменты изолированы и написаны на чем-то более современном, чем то на чем написаны makefiles. Я не знаю, может быть javascript подойдет на эту роль и Qt Build System?
Одна из причин, по которой мне нравится декларативность — как раз макимальная интеграция с IDE. Можно открыть опции в каком-нибудь редакторе свойств, список файлов доступен визуально и т.д.
Да, в сложных проектах вероятно действительно нужен именно язык сборки, и скорее всего чисто декларативным проектом не обойтись. Я это прекрасно понимаю. Скажу честно — я не знаю как разрешить это противоречие. Но вероятно, нужно идти в сторону некоего структурированного файла, в котором информация по максимуму представлена в декларативном виде (и полностью доступна из IDE), а императивные фрагменты изолированы и написаны на чем-то более современном, чем то на чем написаны makefiles. Я не знаю, может быть javascript подойдет на эту роль и Qt Build System?
Вы описываете Gradle.
Можете сравнить ваши идеи с тем, куда движется Chrome: code.google.com/p/chromium/wiki/GNLanguage
Все правильно сказал. Особенно последний абзац.
Разумеется, разработчик языка может позволить себе писать по 10 строк в день для программы, вычисляющей смысл существования вселенной. А остальным-то что делать, у кого ТЗ со 100500 различными и постоянно меняющимися бизнес-правилами, которые, как ни старайся, в 10 строк никак не запишешь. Тут и рефакторинг в IDE нужен, и средства для организации файлов в проекте.
> Я помню времена, когда программисты отлично понимали друг друга. Каждый, кто умел программировать — знал как написать Makefile и bash скрипт. Сейчас же, человек который ничего не видел кроме Java и Maven входит в ступор, когда ему присылают Rake-файл.
Джо Армстронг бурчит, как старушка у подъезда: "А вот при Сталине..." И c чего-бы вдруг Java-программист, использующий Maven, должен понимать Rake(!)-файлы.
Джо Армстронг бурчит, как старушка у подъезда: "А вот при Сталине..." И c чего-бы вдруг Java-программист, использующий Maven, должен понимать Rake(!)-файлы.
Тулы никогда не смогут заменить вам головы.
Тулы, которые у нас есть сейчас, ничем не лучше тех что были 40 лет назад.
Чистейшая демагогия.
Ага. Навязывается ложная дилемма. Удобные инструменты никак не отменяют наличие головы. Более того, зачастую они позволяют освободить мозг от запоминания бесполезной информации, которую компьютер может по первому требованию посчитать на раз-два-три.
И, к тому же, ложь. В современном IDE я могу сделать «find all references» на идентификатор и получить все его вхождения в программе. Я очень хорошо владею VIM, Emacs, ctags, grep и прочим легаси — так вот, с помощью них это сделать невозможно. Конечно, если речь идет о коммерческом проекте от мегабайта исходников и идентификаторе типа «name», а не о hello world в один файл, где уникальный идентификатор встречается три раза :).
Не нужно так спешить, реализовать функционал «Find All Refernces» в emacs вполне возможно, мне кажется это и в VIM возможно, не берусь судить, я его не использую. И это сделать не так уж сложно.
Я не спешу. Разработка программ — это то, чем я занимаюсь за деньги уже больше пятнадцати лет. Возможности VIM, Emacs и Visual Studio я знаю похуже авторов — но все равно очень, очень хорошо. Повторить в Vim или Emacs функциональность «Find All References» как она реализована в Visual Studio для C# или в JetBrains IDEA для Java имеющимися средствами невозможно.
Безусловно, можно с нуля написать анализ абстрактного синтаксического дерева нужного языка с учетом зависимостей, встроить расширением. И такие работы даже ведутся для связки emacs и clang, к прмеру. Но на данный момент указанное сделать невозможно. Я говорю про то, что сейчас есть, а не про то, что «теоретически можно написать». А «find all references» — это одна из самых простых задач, возникающих при работе с большой и сложной базой кода. Так что по моему скромному мнению, заслуженный разработчик эрланга лжет, когда утверждает что современные средства работы с исходным кодом «ничем не лучше тех, что были 40 лет назад».
Возможно, ему просто никто не показал как сейчас выглядит большой и сложный коммерческий проект, сколько в нем строчек кода, какие задачи каждодневно решаются и какие для этого используются инструменты?
P.S. С удовольствием использую и Vim, и Emacs, и мейкфайлы. Для работы с текстом и фрагментами. Но когда нужно работать с чем-то большим — потребны более сложные инструменты. И они есть. И они намного лучше тех, что были 40 лет назад.
Безусловно, можно с нуля написать анализ абстрактного синтаксического дерева нужного языка с учетом зависимостей, встроить расширением. И такие работы даже ведутся для связки emacs и clang, к прмеру. Но на данный момент указанное сделать невозможно. Я говорю про то, что сейчас есть, а не про то, что «теоретически можно написать». А «find all references» — это одна из самых простых задач, возникающих при работе с большой и сложной базой кода. Так что по моему скромному мнению, заслуженный разработчик эрланга лжет, когда утверждает что современные средства работы с исходным кодом «ничем не лучше тех, что были 40 лет назад».
Возможно, ему просто никто не показал как сейчас выглядит большой и сложный коммерческий проект, сколько в нем строчек кода, какие задачи каждодневно решаются и какие для этого используются инструменты?
P.S. С удовольствием использую и Vim, и Emacs, и мейкфайлы. Для работы с текстом и фрагментами. Но когда нужно работать с чем-то большим — потребны более сложные инструменты. И они есть. И они намного лучше тех, что были 40 лет назад.
> Я не спешу
Нет, вы спешите.
> Возможности VIM, Emacs и Visual Studio я знаю похуже авторов
Это уж точно, судя по вашим выдумкам из параллельной вселенной далее по тексту
> но все равно очень, очень хорошо
Нет, очевидно что очень-очень плохо, по крайней мере что касается vim.
> Повторить в Vim или Emacs функциональность «Find All References» как она реализована в Visual Studio для C# или в JetBrains IDEA для Java имеющимися средствами невозможно.
Нет, не просто возможно, а она уже есть например в cscope и я её использую каждый божий день.
> Безусловно, можно с нуля написать анализ абстрактного синтаксического дерева нужного языка с учетом зависимостей, встроить расширением.
Не только можно, но уже написано. cscope называется и плагин для вима одноименный. Уже лет как… надцать. Уже для PDP-11 было, но вы же всего 15 лет разрабатываете, тем более судя по всему только в виндовс и вижуал студии и только на c#, — откуда же вам про это знать.
> Но на данный момент указанное сделать невозможно.
Можно, cscope/ctags. Всех устраивает вроде, если уметь использовать.
> Так что по моему скромному мнению, заслуженный разработчик эрланга лжет, когда утверждает что современные средства работы с исходным кодом «ничем не лучше тех, что были 40 лет назад».
Лучше, но это дает настолько несущественный выигрыш в производительности, что им вообще можно пренебречь. Я могу побыть примером тут. Работаю с кодовой базой Linux. Использую для навигазии vim+cscope. Рядом работает парень, который использует Eclipse. То что я вижу — у меня уходит столько же времени на то чтобы раскрутить аналогичный код. Так что да, все эти монструозные навороченные IDE с претензией на удобство, на самом деле суть те же редакторы кода, и не дают абсолютно ничего по сравнению с vim. Единственное — это что у них порог вхождения ниже.
> Возможно, ему просто никто не показал как сейчас выглядит большой и сложный коммерческий проект, сколько в нем строчек кода, какие задачи каждодневно решаются и какие для этого используются инструменты?
Ох, вспомним про слона и Моську. Подозреваю что он поболее вас видел, и опыта у него явно поболее чем 15 лет в си-шарпике на венде, со «сложными большими коммерческими поделками».
> И они намного лучше тех, что были 40 лет назад.
Смотрел Eclipse — ни нашёл для себя ни одной возможности, которая была бы полезна и которой не было бы в vim в виде плагина или известной надстройки конфига.
Нет, вы спешите.
> Возможности VIM, Emacs и Visual Studio я знаю похуже авторов
Это уж точно, судя по вашим выдумкам из параллельной вселенной далее по тексту
> но все равно очень, очень хорошо
Нет, очевидно что очень-очень плохо, по крайней мере что касается vim.
> Повторить в Vim или Emacs функциональность «Find All References» как она реализована в Visual Studio для C# или в JetBrains IDEA для Java имеющимися средствами невозможно.
Нет, не просто возможно, а она уже есть например в cscope и я её использую каждый божий день.
> Безусловно, можно с нуля написать анализ абстрактного синтаксического дерева нужного языка с учетом зависимостей, встроить расширением.
Не только можно, но уже написано. cscope называется и плагин для вима одноименный. Уже лет как… надцать. Уже для PDP-11 было, но вы же всего 15 лет разрабатываете, тем более судя по всему только в виндовс и вижуал студии и только на c#, — откуда же вам про это знать.
> Но на данный момент указанное сделать невозможно.
Можно, cscope/ctags. Всех устраивает вроде, если уметь использовать.
> Так что по моему скромному мнению, заслуженный разработчик эрланга лжет, когда утверждает что современные средства работы с исходным кодом «ничем не лучше тех, что были 40 лет назад».
Лучше, но это дает настолько несущественный выигрыш в производительности, что им вообще можно пренебречь. Я могу побыть примером тут. Работаю с кодовой базой Linux. Использую для навигазии vim+cscope. Рядом работает парень, который использует Eclipse. То что я вижу — у меня уходит столько же времени на то чтобы раскрутить аналогичный код. Так что да, все эти монструозные навороченные IDE с претензией на удобство, на самом деле суть те же редакторы кода, и не дают абсолютно ничего по сравнению с vim. Единственное — это что у них порог вхождения ниже.
> Возможно, ему просто никто не показал как сейчас выглядит большой и сложный коммерческий проект, сколько в нем строчек кода, какие задачи каждодневно решаются и какие для этого используются инструменты?
Ох, вспомним про слона и Моську. Подозреваю что он поболее вас видел, и опыта у него явно поболее чем 15 лет в си-шарпике на венде, со «сложными большими коммерческими поделками».
> И они намного лучше тех, что были 40 лет назад.
Смотрел Eclipse — ни нашёл для себя ни одной возможности, которая была бы полезна и которой не было бы в vim в виде плагина или известной надстройки конфига.
Я могу побыть примером тут. Работаю с кодовой базой Linux. Использую для навигазии vim+cscope.
Что именно из кодовой базы, если не секрет? kernel?
да, linux это и есть kernel. если подробнее — то я индексирую только файлы, существенные для используемой архитектуры (arm64) и нужной мне платформы, но это детали — по .config файлу вообще можно оставить только файлы, которые собираются для заданной конфигурации, но кому-то нравится чтобы были проиндексированы все файлы, чтобы можно было искать в них примеры кода. Всё тоже самое нужно делать в Eclipse — выбирать, какие файлы индексировать.
Замечательно. Подскажите старику, каким заклинанием cscope/ctags можно посмотреть все обращения к полю «next» объектов структуры «socket»?
Никаким. В структуре socket нет члена next:
git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/linux/net.h?id=refs/tags/v3.13#n105
git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/linux/net.h?id=refs/tags/v3.13#n105
flags меня более чем устроит.
Для этого даже cscope не нужен:
$ find. -name '*.[ch]' -exec grep -H 'struct socket ' {} \; | sed 's/:.*//g' | sort -u >cscope.files
$ for i in $(cat cscope.files); do grep -PHn '\.flags\b|->flags\b' $i; done
Если вам не нравится, что не все flags здесь будут именно из структуры socket, желаю удачи в отладке ситуаций когда синтаксический анализатор не «словит» присвоение типа такого:
struct socket a = {
.flags = 0x8,
};
или другое хитроумное, коих полно в сложных проектах на Си (например с использованием void*, container_of() и т.д.).
С другой стороны, если у вас постоянно возникают такие ситуации (вот у меня за 2 года еще ни разу такого не нужно было, иначе бы я уже полазил и нашёл бы, как такое сделать, или сам дописал бы в тот же cscope), то никто не мешает в качестве синтаксического парсера (не IDE!) использовать парсер из Eclipse или clang, которые намного мощнее (но и намного дольше) чем cscope:
eclim.org/
lists.cs.uiuc.edu/pipermail/cfe-dev/2013-March/028452.html
$ find. -name '*.[ch]' -exec grep -H 'struct socket ' {} \; | sed 's/:.*//g' | sort -u >cscope.files
$ for i in $(cat cscope.files); do grep -PHn '\.flags\b|->flags\b' $i; done
Если вам не нравится, что не все flags здесь будут именно из структуры socket, желаю удачи в отладке ситуаций когда синтаксический анализатор не «словит» присвоение типа такого:
struct socket a = {
.flags = 0x8,
};
или другое хитроумное, коих полно в сложных проектах на Си (например с использованием void*, container_of() и т.д.).
С другой стороны, если у вас постоянно возникают такие ситуации (вот у меня за 2 года еще ни разу такого не нужно было, иначе бы я уже полазил и нашёл бы, как такое сделать, или сам дописал бы в тот же cscope), то никто не мешает в качестве синтаксического парсера (не IDE!) использовать парсер из Eclipse или clang, которые намного мощнее (но и намного дольше) чем cscope:
eclim.org/
lists.cs.uiuc.edu/pipermail/cfe-dev/2013-March/028452.html
Поймите, я не против IDE как таковых, мой месседж в другом:
1. vim настраивается до уровня IDE с помощью плагинов и настроек
2. мне не понравилась категоричность и нигилизм ваших высказываний:
— в сторону «дедушек» с 40-летним опытом разработки реально крутых проектов типа Джо Армстронга, польза одного проекта которых превосходит пользу от всех энтерпрайзных поделок на C#/Java вместе взятых. да и сложность я уверен тоже
— в сторону инструментов типа vim и make, которые ну никак не устарели. да, на них нельзя тягать кнопочки на формочки, но что касается работы с кодом — они с ней справляются на 100%. ПО не портится и не гниет само по себе. задачи программирования почти никак не изменились за последние 50 лет, и способы писать программы тоже.
3. IDE даже по сравнению с простым блокнотом + консольные тулзы (grep, find и т.д.) дают ВЕСЬМА малый выигрыш по времени, я имею ввиду суммарное время разработки проекта. я думаю это и был основной посыл Джо Армстронга, и я с ним согласен
1. vim настраивается до уровня IDE с помощью плагинов и настроек
2. мне не понравилась категоричность и нигилизм ваших высказываний:
— в сторону «дедушек» с 40-летним опытом разработки реально крутых проектов типа Джо Армстронга, польза одного проекта которых превосходит пользу от всех энтерпрайзных поделок на C#/Java вместе взятых. да и сложность я уверен тоже
— в сторону инструментов типа vim и make, которые ну никак не устарели. да, на них нельзя тягать кнопочки на формочки, но что касается работы с кодом — они с ней справляются на 100%. ПО не портится и не гниет само по себе. задачи программирования почти никак не изменились за последние 50 лет, и способы писать программы тоже.
3. IDE даже по сравнению с простым блокнотом + консольные тулзы (grep, find и т.д.) дают ВЕСЬМА малый выигрыш по времени, я имею ввиду суммарное время разработки проекта. я думаю это и был основной посыл Джо Армстронга, и я с ним согласен
$ find. -name '*.[ch]' -exec grep -H 'struct socket ' {} \; | sed 's/:.*//g' | sort -u >cscope.files
$ for i in $(cat cscope.files); do grep -PHn '\.flags\b|->flags\b' $i; done
Серьезно?
$ for i in $(cat cscope.files); do grep -PHn '\.flags\b|->flags\b' $i; done
Серьезно?
А есть готовые пакеты для такого счастья? Например vim со всеми настройками, плагинами и конфигами для нормального J2EE окружения (автодополнение, интеграция с maven/gradle, анализ стактрейса и т.д). Меня бы очень обрадовало не переучиваться назад на стрелочки с hjkl.
Про J2EE не знаю, пишу только на Си/Си++. Для того что я делаю, — да, есть. sudo aptitude install cscope vim, и всё по сути, в самом виме уже есть плагин для cscope, подсветка синтаксиса, автодополнение (omni-completion), браузер файлов (:Sex, хотя я использую NerdTree), поддержка make (:make). Дальнейшие настройки, плагины — каждый себе по вкусу ставит и настраивает. Наверняка нет визуальной поддержки gdb по-умолчанию (уверен, что есть плагин), но ядро не так дебажат, так что не задавался вопросом.
Если вам нужно только h/j/k/l — может проще в вашей IDE поискать Vim режим или Vim-плагин? Потому что если вам кнопочки тягать на формочки — наверняка такого в vim нет и не будет, это ж вообще чисто консольный редактор.
Если вам нужно только h/j/k/l — может проще в вашей IDE поискать Vim режим или Vim-плагин? Потому что если вам кнопочки тягать на формочки — наверняка такого в vim нет и не будет, это ж вообще чисто консольный редактор.
cscope/ctags умеет C. Язык с простой грамматикой. Что на счет C++ или Erlang? Ну и IDE тоже нужно уметь пользоваться, да
Не теряйте контекст разговора. Говорили именно про Си, вот изначальная цитата «eyeofhell», на которую я отвечал:
> Я очень хорошо владею VIM, Emacs, ctags, grep и прочим легаси — так вот, с помощью них это сделать невозможно
Раз был упомянут ctags — очевидно разговор шёл именно о Си.
Пользоваться IDE я умею — 3 года просидел за QtCreator и KDevelop. В QtCreator на тот момент знал 95% функционала, т.е. все менюшки и настройки, и почти все комбинации клавиш. Да, такого парсера C++ как в KDevelop для вима я не видел, хотя на офф. сайте cscope пишут что он и C++ тянет, но опять же, разговор шёл про Си.
> Я очень хорошо владею VIM, Emacs, ctags, grep и прочим легаси — так вот, с помощью них это сделать невозможно
Раз был упомянут ctags — очевидно разговор шёл именно о Си.
Пользоваться IDE я умею — 3 года просидел за QtCreator и KDevelop. В QtCreator на тот момент знал 95% функционала, т.е. все менюшки и настройки, и почти все комбинации клавиш. Да, такого парсера C++ как в KDevelop для вима я не видел, хотя на офф. сайте cscope пишут что он и C++ тянет, но опять же, разговор шёл про Си.
Ну а ниже он упоминал C# и Java, поэтому я думаю, что имелась в виду функция в принципе, а не применительно к какому-то отдельному языку.
Возможно, вы знали QtCreator и KDevelop, но когда открыли Eclipse на посмотреть, то, очень может быть, вы просто не смогли оценить все его возможности.
P.S. Лично я считаю, что Eclipse — неудобная и лагающая IDE, да и парсер QtCreator еще далек до идеала.
Возможно, вы знали QtCreator и KDevelop, но когда открыли Eclipse на посмотреть, то, очень может быть, вы просто не смогли оценить все его возможности.
P.S. Лично я считаю, что Eclipse — неудобная и лагающая IDE, да и парсер QtCreator еще далек до идеала.
cscope/ctags
Они отчасти неудобны тем, что приходится перестраивать теги при обновлении исходных файлов. Если редактор ещё может делать это автоматически для сохраняемых файлов, то при обновлённых при обновлении рабочей копии приходится не забывать это делать явно.
К слову, для C/C++ пользуюсь Emacs + GNU global + helm-gtag.
Никто не мешает намапить обновление DB cscope в виме на сохранение файла. cscope второй раз и далее не переделывает DB, а обновляет. Из мана:
cscope builds the symbol cross-reference the first time it is used on the source files for the program being browsed.
On a subsequent invocation, cscope rebuilds the cross-reference only if a source file has changed or the list of source
files is different. When the cross-reference is rebuilt, the data for the unchanged files are copied from the old
cross-reference, which makes rebuilding faster than the initial build.
cscope builds the symbol cross-reference the first time it is used on the source files for the program being browsed.
On a subsequent invocation, cscope rebuilds the cross-reference only if a source file has changed or the list of source
files is different. When the cross-reference is rebuilt, the data for the unchanged files are copied from the old
cross-reference, which makes rebuilding faster than the initial build.
Первое что нашлось:
> I can't rebuild a database automaticly.
If you really want to do that each time you save the changes to a file,
you can use an autocommand something like this:
au BufWritePost * call system(&csprg. " -R -b") | cs reset
That's untested but uses pieces of commands I'm using currently, so it
should work as is or with some minor tweaks.
See
:help 40.3 " Autocommands
:help BufWritePost
:help :call
:help system()
:help :bar
> I can't rebuild a database automaticly.
If you really want to do that each time you save the changes to a file,
you can use an autocommand something like this:
au BufWritePost * call system(&csprg. " -R -b") | cs reset
That's untested but uses pieces of commands I'm using currently, so it
should work as is or with some minor tweaks.
See
:help 40.3 " Autocommands
:help BufWritePost
:help :call
:help system()
:help :bar
А теперь ещё раз прочитайте мой комментарий. Я знаю, что можно обновлять теги из редактора при сохранении. Более того, helm-gtags делает это за меня из коробки. GNU global умеет делать инкрементальное обновления базы для отдельных файлов. Я говорю о том, что файлы могут измениться не только вашим редактором.
точно, не так понял. но и для такого случая можно что-то придумать. например как делает это Eclipse? по таймеру? ну так наверняка и в vim можно завести обновление базы по таймеру.
Вы знаете, я тоже не 1-й год в разработке и меня ваш комментарий удивляет. Ну что ж, невозможно, видимо мы в паралельных мирах живем, в моем возможно. Более того, пугает ваша категоричность, потому конструктивный разговор с вами строить, вижу, не получится. Peace.
А чего там строить — показываете работающий «Find All References» для сложного C++/C#/Java/Python/Ruby с использованием emacs + ctags — и все, я снимаю шляпу и всячески вам благодарен. Я так сделать не могу и даже не представляю как. Потому как внутрь *tags смотрел и знаю как они работают. Легаси и современные средства работы с кодом — это две большие разницы. AST — это сила. Еще со времен LISP.
показываете работающий «Find All References» для сложного C++/C#/Java/Python/RubyА можно пример для последних двух (python, ruby) где-либо? Есть стойкое впечатление, что это не реализуемо в принципе, ни в редакторе с плагинами, ни в IDE.
Например, имя вызываемого метода может строиться на основе входных данных программы, такой вызов в отрыве от конкретных данных не отслеживаем в принципе (т. е. его эвристически можно указать, как потенциальный вызов, но количество false-positive и false-negative слабо прогнозируемо). На конкретных данных — только при исполнении кода.
Я вполне продуктивно работал с исходниками Хромиума как раз в виме. Более того, для проектов такого объема vim+ctags зачастую достаточно удобны и уж точно быстрее, чем современные навороченные ide.
+typo
+typo
Если не секрет, над какой именно частью работали и в чем заключалась работа?
Фиксил разнообразные баги, что как правило требовало немного врубиться в работу проблемного куска и некоторых окрестностей :) Много UI, но не только.
Глубоко копал загрузку ресурсов, сетевые оптимизации (преконнект, префетч, пререндер) и особенности взаимодействия процессов в Хромиуме, сделал автоматическую перезагрузку «пофейлившихся» страниц при появлении соединения с интернетом a-la safari.
Ранее использовал тот же инструментарий для копания в кодовой базе FreeBSD, делал подключаемую политику безопасности через Mac framework и для этого разбирался с работой некоторых механизмов ядра в части работы процессов и файловой системы. Также чинил некоторые юзерспейсные утилиты.
Справедливости ради надо признать, что все это очень качественно написанный код с разумной структурой. Если бы вместо этого была бы макаронная портянка, могло и не получиться.
Глубоко копал загрузку ресурсов, сетевые оптимизации (преконнект, префетч, пререндер) и особенности взаимодействия процессов в Хромиуме, сделал автоматическую перезагрузку «пофейлившихся» страниц при появлении соединения с интернетом a-la safari.
Ранее использовал тот же инструментарий для копания в кодовой базе FreeBSD, делал подключаемую политику безопасности через Mac framework и для этого разбирался с работой некоторых механизмов ядра в части работы процессов и файловой системы. Также чинил некоторые юзерспейсные утилиты.
Справедливости ради надо признать, что все это очень качественно написанный код с разумной структурой. Если бы вместо этого была бы макаронная портянка, могло и не получиться.
Специфические кейсы. Багфикс, если не большой архитектурный баг, требует как раз изучения конкретных кусков без всей остальной туши кода. А вот расширение функциональности уже треует изучать не только как это реализовано здесь — но и как оно используется.
Линукс кернел — это C. Для него и cscope нормально работает, там же кроме макросов ничего неприятного нету, если напрямую память не кастить.
Согласитесь, от задачи зависит. Find All Reference — вполне себе хороший, годный, часто встречающийся кейс которого 40 лет назад нифига не было.
Линукс кернел — это C. Для него и cscope нормально работает, там же кроме макросов ничего неприятного нету, если напрямую память не кастить.
Согласитесь, от задачи зависит. Find All Reference — вполне себе хороший, годный, часто встречающийся кейс которого 40 лет назад нифига не было.
Специфические кейсы.
ИМХО довольно типичные. Что исправление багов, что расширение функционала требует понимания интимных взаимоотеношений различных сущностей, определенных в разных местах кода. Вы не поверите, часто даже тупой grep оказывается годным решением для find all references (или я вас не понимаю).
А вот глобального рефакторинга мне делать не приходилось, заочно признаю превосходство современных IDE на этой задаче.
Вы не поверите, часто даже тупой grep оказывается годным решением для find all references (или я вас не понимаю).
Охотно поверю. Сам много над чем работал и ack люблю. Я больше про большие проекты, когда нужно найти name у во-о-о-он того класса, а разработчики как обычно любят генереки, шаблоны и абстрактные фабрики. В таких, частых в энтерпрайзе и автоматизации, раскладах, IDE творят чудеса и позволяют не срывать сроки. По крайней мере сильно :).
Сейчас постоянно использую Makefile при работе с ndk в Android. Не скажу, что они прям настолько ужасны. Они могут показаться страшными только при первом знакомстве.
Понятно, что Make-файлы лишь как один из примеров, но всё же.
«Проблема не в самих тулах, а в том, что когда они сломаны, все время уходит на то чтобы их починить.»
Проблемы не в тулах, а в самих программистах )
Понятно, что Make-файлы лишь как один из примеров, но всё же.
«Проблема не в самих тулах, а в том, что когда они сломаны, все время уходит на то чтобы их починить.»
Проблемы не в тулах, а в самих программистах )
Ну и что, в Java есть еще Ant, как альтернатива декларативности Maven, и чем-то напоминающий make. А еще есть Gradle со смесью того и другого. Печально, что автор языка не желает признавать того, что инфраструктура Erlang неразвита.
Ответ просто удивителен. Зачем вам перфоратор, если можно взять ручную дрель, и неторопливо, по миллиметру в час двигаться к цели? Зачем вам бензопила, если тот же результат можно получить, используя ножовку?
Я тоже помню времена, когда нужно было знать тьму математики. А сегодня можно запрограммировать игру с трёхмерной графикой, даже понятия не имея, что такое кватернионы и матрицы. И больше людей сможет сосредоточиться на разработке самого продукта, а не на технических деталях. Какая досада, правда...?
Я тоже помню времена, когда нужно было знать тьму математики. А сегодня можно запрограммировать игру с трёхмерной графикой, даже понятия не имея, что такое кватернионы и матрицы. И больше людей сможет сосредоточиться на разработке самого продукта, а не на технических деталях. Какая досада, правда...?
Блин. А я думаю почему современным программистам гигагерц нескольких процессоров и десятка гигабайт памяти не хватает на то, что раньше на мегагерцах и мегабайтах работало очень хорошо?
Ан вон оно что, не надо «знать тьму математики», не надо сосредотачиваться на «технических деталях», а надо «на разработке самого продукта». То есть разработка продукта не ради продукта, а ради разработки.
P.S.: Извините, наболело.
Ан вон оно что, не надо «знать тьму математики», не надо сосредотачиваться на «технических деталях», а надо «на разработке самого продукта». То есть разработка продукта не ради продукта, а ради разработки.
P.S.: Извините, наболело.
Может, это не программисту не хватает, а пользователю?
Попробуйте ради интереса включить графический режим 320x240 и представьте, что вам в таком работать целый дель.
Зато на мегабайтах и мегагерцах.
Ну и информационные возможности на мегабайтах скудные. Никаких больших словарей, предиктивного ввода, даже подсказок.
А, ну о чём я. Пользователь же с перфокарты задание введёт и ответ получит в пакетном режиме, зачем интерактив.
Попробуйте ради интереса включить графический режим 320x240 и представьте, что вам в таком работать целый дель.
Зато на мегабайтах и мегагерцах.
Ну и информационные возможности на мегабайтах скудные. Никаких больших словарей, предиктивного ввода, даже подсказок.
А, ну о чём я. Пользователь же с перфокарты задание введёт и ответ получит в пакетном режиме, зачем интерактив.
То есть вы утверждаете, что с ростом разрешения графического режима можно не заморачиваться математикой, сконцентрироваться на разработке и это нужно пользователю?
Какие информационные возможности нужны, например для notepad? Размер 193536 байт
Или, например, mspaint.exe 6,676,480 байт. И это только .exe код, без dll-ей.
Давайте будем честными с самими собой и скажем, что да, сейчас мы пишем программы в угоду скорости разработки. Плюс сейчас средний программист не так умен, как было когда-то. Плюс к этому современная аппаратная база позволяет.
Какие информационные возможности нужны, например для notepad? Размер 193536 байт
Или, например, mspaint.exe 6,676,480 байт. И это только .exe код, без dll-ей.
Давайте будем честными с самими собой и скажем, что да, сейчас мы пишем программы в угоду скорости разработки. Плюс сейчас средний программист не так умен, как было когда-то. Плюс к этому современная аппаратная база позволяет.
Блокнот — 86 килобайт кода. Остальное ресурсы.
Пейнт — 600 килобайт код + ресурсы.
Собственно размер ресурсов (которые значки, курсоры, картинки) напрямую зависит от разрешения экрана.
Пейнт — 600 килобайт код + ресурсы.
Собственно размер ресурсов (которые значки, курсоры, картинки) напрямую зависит от разрешения экрана.
Ок. Не будем рассуждать много это или мало — 86 килобайт кода для блокнота, в котором используется только стандартные элементы управления и логики на чуток.
Мне больше интересно Ваше мнение на первый вопрос. Вы тоже считаете что из-за высокого разрешение экрана не стоит заморачиваться на математике и разработке?
Мне больше интересно Ваше мнение на первый вопрос. Вы тоже считаете что из-за высокого разрешение экрана не стоит заморачиваться на математике и разработке?
при средней длине инструкции в 4 байта, это 20 тысяч строк ассемблерного кода. Что весьма не много (не забываем, что у 16тиразрядных процессоров инструкции короче были).
Если применяется оптимизация по скорости, то размер кода возрастает: более эффективные алгоритмы почти всегда требуют больше кода+разворачивание циклов, встраивание функций.
Дополнительно, требования к портируемости приложений в последнее время сильно возросли. Если 30 лет назад ваша программа должна была корректно работать на одном компьютере — на котором вы ее написали, то теперь у нас есть 2 семейства операционных систем х 3 семейства архитектур процессоров. Поэтому грязные хаки уже канают.
Программное окружение, в котором работает ваша программа, также заметно изменилась. Теперь ваша программа не может распоряжаться всем оборудованием (и безнаказанно стащить все ваши пароли и удалить систему), ей приходится соблюдать правила, и это тоже доп. код.
Конечно, все не должны заниматься математикой! Если вместо того, чтобы дело делать, каждый будет свой графический движок велосипедить, то качество продуктов упадёт, и на много.
Если применяется оптимизация по скорости, то размер кода возрастает: более эффективные алгоритмы почти всегда требуют больше кода+разворачивание циклов, встраивание функций.
Дополнительно, требования к портируемости приложений в последнее время сильно возросли. Если 30 лет назад ваша программа должна была корректно работать на одном компьютере — на котором вы ее написали, то теперь у нас есть 2 семейства операционных систем х 3 семейства архитектур процессоров. Поэтому грязные хаки уже канают.
Программное окружение, в котором работает ваша программа, также заметно изменилась. Теперь ваша программа не может распоряжаться всем оборудованием (и безнаказанно стащить все ваши пароли и удалить систему), ей приходится соблюдать правила, и это тоже доп. код.
Конечно, все не должны заниматься математикой! Если вместо того, чтобы дело делать, каждый будет свой графический движок велосипедить, то качество продуктов упадёт, и на много.
Все, что Вы выше написали про грязные хаки и оптимизации по скорости, это все про notepad?
Про «недолжны заниматься математикой».
Лично у меня «заниматься математикой» не означает «велосипедить графический движок», как и вообще что-то велосипедить. Для меня это, в первую очередь, означает хотя бы знать, что время произвольного доступа к элементу односвязного списка будет зависеть от длины этого списка. Вот даже такая мелочь современным программистам неведома порой. см.http://habrahabr.ru/post/206338/
И вот из-за таких мелочей возникают те проблемы, о которых я писал в своем первом комментарии.
Всё то, что Вы написали
Про «недолжны заниматься математикой».
Лично у меня «заниматься математикой» не означает «велосипедить графический движок», как и вообще что-то велосипедить. Для меня это, в первую очередь, означает хотя бы знать, что время произвольного доступа к элементу односвязного списка будет зависеть от длины этого списка. Вот даже такая мелочь современным программистам неведома порой. см.http://habrahabr.ru/post/206338/
И вот из-за таких мелочей возникают те проблемы, о которых я писал в своем первом комментарии.
Всё то, что Вы написали
Грязные хаки, и оптимизации компилятора, конечно, и к блокноту относится!
у меня «заниматься математикой»… означает хотя бы знать, что время произвольного доступа к элементу односвязного списка будет зависеть от длины этого списка.А вам писали про кватернионы и матрицы.
вот из-за таких мелочей возникают те проблемы, о которых я писал в своем первом комментарииТак где они возникают-то? Примеров-то вы так и не предоставили.
Ок. Ради чего нужны грязные хаки и оптимизации компилятора для блокнота?
Во-первых про квартерионы и матрицы писали не мне. Посмотрите, пожалуйста, наверх. Автор никому конкретно не адресовал свое послание. Во-вторых, причем тут квартерионы и матрицы? Я автору тому комментария писал про нужность хотя бы основ математики для программирования. Вы хотите поспорить с тем, что программисту математика не нужна?
По поводу примеров, пожалуйста, будьте терпеливы. Как только у меня будет достаточно свободного времени я постараюсь для вас найти хороший пример.
Во-первых про квартерионы и матрицы писали не мне. Посмотрите, пожалуйста, наверх. Автор никому конкретно не адресовал свое послание. Во-вторых, причем тут квартерионы и матрицы? Я автору тому комментария писал про нужность хотя бы основ математики для программирования. Вы хотите поспорить с тем, что программисту математика не нужна?
По поводу примеров, пожалуйста, будьте терпеливы. Как только у меня будет достаточно свободного времени я постараюсь для вас найти хороший пример.
Хаки применялись в DOS повсеместно, например. А оптимизации обычно одинаковы для всего продукта — не будете же вы блокнот собирать с оптимизацией по размеру специально? Зачем это вообще может быть нужно?
А кто с вами спорил по поводу того, что основы алгоритмов программист должен знать? Речь шла про весьма специфическую и более сложную математику. А то, что вы по-своему поняли…
А кто с вами спорил по поводу того, что основы алгоритмов программист должен знать? Речь шла про весьма специфическую и более сложную математику. А то, что вы по-своему поняли…
То есть вы утверждаете, что с ростом разрешения графического режима можно не заморачиваться математикой, сконцентрироваться на разработке и это нужно пользователю?
Вы зря привязываете математику к размеру кода. Например, сложные, но быстрые структуры данных, которые реализуются в STL, занимают десятки килобайт на каждый контейнер. А если тупо написать всё циклами большой вложенности, получится пара килобайт, но работать будет на порядки медленнее.
Какие информационные возможности нужны, например для notepad?
Одно слово — юникод. Редактор с возможностями блокнота малореален на старых ЭВМ, потому как только карты типа символа (цифра, буква и т.п.), таблицы соответствия строчной и заглавной, всё это занимает мегабайты.
:) Я все никак в толк взять не могу, каким образом у Вас из утверждения:
«То есть вы утверждаете, что с ростом разрешения графического режима можно не заморачиваться математикой, сконцентрироваться на разработке и это нужно пользователю?» получилось утверждение «привязываете математику к размеру кода»?
Получается что мы с вами упорно говорим о разных вещах. Я говорю о том, что существующее софтостроение так сильно нацелено на _дешево_ написать код что получаются монстры. Вот лично вы удовлетворены существующим положением вещей в софте? Вас не удивляют операционные системы, которые тормозят на последнем железе или маленькие (по функциональности) программы, которые требуют для запуска самолет?
Это слово Unicode — поддерживается в OS (Операционной системе) для всех программ и не занимает ничего (или почти ничего) в коде программы. Вы в самом деле верите, что notepad имеет личные таблицы локалей? Да даже если и так, они бы были в ресурсах, как мне кажется.
P.S.: А если уж из-за чего кодовая секция блокнота распухла, так от прилинкованной к нему стандартной библиотеки. Будет время, посмотрю IDA.
«То есть вы утверждаете, что с ростом разрешения графического режима можно не заморачиваться математикой, сконцентрироваться на разработке и это нужно пользователю?» получилось утверждение «привязываете математику к размеру кода»?
Получается что мы с вами упорно говорим о разных вещах. Я говорю о том, что существующее софтостроение так сильно нацелено на _дешево_ написать код что получаются монстры. Вот лично вы удовлетворены существующим положением вещей в софте? Вас не удивляют операционные системы, которые тормозят на последнем железе или маленькие (по функциональности) программы, которые требуют для запуска самолет?
Это слово Unicode — поддерживается в OS (Операционной системе) для всех программ и не занимает ничего (или почти ничего) в коде программы. Вы в самом деле верите, что notepad имеет личные таблицы локалей? Да даже если и так, они бы были в ресурсах, как мне кажется.
P.S.: А если уж из-за чего кодовая секция блокнота распухла, так от прилинкованной к нему стандартной библиотеки. Будет время, посмотрю IDA.
Вас не удивляют операционные системы, которые тормозят на последнем железе или маленькие (по функциональности) программы, которые требуют для запуска самолет?
Факты говорят о другом. Когда-то я пользовался Windows 2000, Windows 2003, эти системы загружались по 3-4 минуты.
Сейчас Windows 8 загружается 10 секунд. Быстрее специализированного linux-роутера.
Это слово Unicode — поддерживается в OS (Операционной системе) для всех программ и не занимает ничего (или почти ничего) в коде программы. Вы в самом деле верите, что notepad имеет личные таблицы локалей?
Нет, я просто хотел показать, что решаемые задачи несравнимы. То, что сейчас легко делает блокнот, с большим скрипом можно было провернуть на железе эпохи мегабайт/мегагерц. Поэтому кажущаяся простота современных программ — лишь кажущаяся.
Вы не подумайте, я ещё на ZX-Spectrum кодил, и задача впихать в часть видеопамяти дебагер+дизассемблер мне знакома. Но сейчас такие задачи смешные. Да, они решаются тупо в лоб менее оптимально, чем в те времена. Но это потому, что впереди намного более сложные и интересные задачи, которыми нужно заниматься, а не сидеть в песочнице, перекладывая килобайты.
:) А как вы часто системы грузите? Вот вам сильно помогает что Windows грузится по 10 секунд? Мне лично надо чтобы система нормально работала.
А вот когда система только что стартовавшая уже сьела 3.6 Gb памяти, и при это еще что-то жующая — это вас не удивляет? Припарка в виде SSD проблему частично решила, до тех пор, пока не загрузил PyCharm + еще что-то написанное на Java и вот уже 8Gb RAM кончились :)
То что сейчас легко делает блокнот, можно было легко сделать в редакторах эпохи 90-x.
Хм. А интересно зачем впихивать в часть видеопамяти дизассемблер + дебаггер? ;)
Или так STS работал? (уже не помню)
Был же и Scorpion с теневым монитором и много чего еще :)
А вот когда система только что стартовавшая уже сьела 3.6 Gb памяти, и при это еще что-то жующая — это вас не удивляет? Припарка в виде SSD проблему частично решила, до тех пор, пока не загрузил PyCharm + еще что-то написанное на Java и вот уже 8Gb RAM кончились :)
То что сейчас легко делает блокнот, можно было легко сделать в редакторах эпохи 90-x.
Хм. А интересно зачем впихивать в часть видеопамяти дизассемблер + дебаггер? ;)
Или так STS работал? (уже не помню)
Был же и Scorpion с теневым монитором и много чего еще :)
пока не загрузил PyCharm + еще что-то написанное на Java и вот уже 8Gb RAM кончились :)
Ну и пусть кончилась. Я точно скажу, что производительнось работы в VS2013+R# выше, чем в любом редакторе из 90-х (несмотря на минутное ожидание загрузки большого проекта, но ведь «А как вы часто xxx грузите?»). Да, иногда я Delphi запускаю, но счастья в виде реактивно быстрой IDE что-то и не хочется, когда там даже goto definition работает далеко не на всех символах.
Хм. А интересно зачем впихивать в часть видеопамяти дизассемблер + дебаггер? ;)
Защиты часто всю память съедали, только на экран не покушались. Да и игры тоже на всю память претендовали. Перед запуском, чтобы покопаться нормально, только в экран грузить код.
Или так STS работал?Это другая история, 128K :)
Был же и Scorpion с теневым монитором и много чего еще :)Скорпион дорог и малораспространён. Рулят свои ROM-ы c выходом в отладчик по NMI
Я не более недели назад на своей шкуре ощутил, что никакой редактор не заменит vim, к которому привык. В vim при должном умении и знании что писать, все пишется просто очень быстро! Как нибудь посмотрите как мастера пишут на vim-е, _насколько_ быстро получается.
Понятно. У меня последним спектрумом был Scorpion. Мне были неведомы эти проблемы.
У нас кроме Scorpion-а ничего больше не было. Ну, или как вариант, брали Ленинград-2 48к, напаивали на него AY8912, РУ-ки (уже не помню 5-ые наверное), ВГ93 и получали свои 128к.
Понятно. У меня последним спектрумом был Scorpion. Мне были неведомы эти проблемы.
У нас кроме Scorpion-а ничего больше не было. Ну, или как вариант, брали Ленинград-2 48к, напаивали на него AY8912, РУ-ки (уже не помню 5-ые наверное), ВГ93 и получали свои 128к.
Вы хотя бы разберитесь что ли, как работают менеджеры памяти Windows и Java. Уже сколько раз это обсуждалось! И на хабре было!
:) А зачем? Вы можете мне обьяснить чем знание того, как работает программа изнутри поможет мне решить мои пользовательские проблемы?
Затем, что для того, чтобы делать выводы из высоты столбика занятой памяти, вы должны представлять, что же этот столбик на самом деле показывает, как его показания нужно интерпретировать и как система себя будет вести при изменении этой самой высоты столбика.
Ок. Ну интерпретировал я, что некому жава софту нужно 2 гига памяти чтобы мне рисовать 6 графиков и показывать кусок лога на экране. Что дальше? Вгрызаться в него декомпилятором чтобы выяснить, какого там происходит?
а зачем Джаве собирать мусор и тратить на это ваше время, если памяти все равно хватает?
: Э… 7.6 Гб занятой из 8 Гб.
При этом чувствуется что система стала замирать и тормозить. Это хватает? Как у жава устроено внутри проверять что памяти хватает?
При этом чувствуется что система стала замирать и тормозить. Это хватает? Как у жава устроено внутри проверять что памяти хватает?
да хоть пусть все 8 будут заняты — от пустующей памяти толку тоже нет никакого.
Как у жава устроено внутри проверять что памяти хватает?ну так вот и предлагается это выяснить) и, возможно, помочь ей. Я на счет джавы не могу сказать, а вот видна будет держать память до последнего, чтоб по возможности ее переиспользовать.
Ну чтобы хотя бы знать что можно задать IDE -Xmx, что ли…
Если знать, что под капотом, можно эффективнее пользоваться.
Например, с 5-й скорости автомобиль не разгонять ))
Например, с 5-й скорости автомобиль не разгонять ))
Да, я согласен. Мы размениваем мегабайты на быстроту и удобство кодирования.
Но это оправдано — без такого размена мы бы не достигли тех высот, на которых мы сейчас.
Не согласны? Напишите свою ось на ассемблере и попробуйте поконкурировать с разжиревшими мейнстримными.
Но это оправдано — без такого размена мы бы не достигли тех высот, на которых мы сейчас.
Не согласны? Напишите свою ось на ассемблере и попробуйте поконкурировать с разжиревшими мейнстримными.
Опять Вы не про то. Я одно, мне в ответ список мемов «ось на ассемблере», «оптимизация всего и вся», «велосипедостроение». Я про это не говорил!
Берите пример с раннего IPhone-а, которому удавалось на относительно скромном железе показывать офигительные результаты. Что мешает это делать на обычных ОС? Тем что «батарейки» не ограниченные и память докупить просто?
Берите пример с раннего IPhone-а, которому удавалось на относительно скромном железе показывать офигительные результаты. Что мешает это делать на обычных ОС? Тем что «батарейки» не ограниченные и память докупить просто?
Возьмём HTC Sense, который только ленивый не ругает за жир и тормознутость.
Но в состоянии «с завода» он работает ровно как первый айфон, ничего не тормозит, и звонит прекрасно. А вот стоит поставить анимированные обои, улучшалки интерфейса, google maps (и кучу других «социальных» сервисов, которые в автозагрузку прописываются) — и уже тормоза начинаются.
Аналогично, я думаю, с «обычными» ОС.
Хочешь R# на MSVS — проекты начнут тормозить при загрузке, но это окупится многократно.
Но в состоянии «с завода» он работает ровно как первый айфон, ничего не тормозит, и звонит прекрасно. А вот стоит поставить анимированные обои, улучшалки интерфейса, google maps (и кучу других «социальных» сервисов, которые в автозагрузку прописываются) — и уже тормоза начинаются.
Аналогично, я думаю, с «обычными» ОС.
Хочешь R# на MSVS — проекты начнут тормозить при загрузке, но это окупится многократно.
Я же приводил в пример IPhone. Про Андроид то я в курсе.
IPhone был стоящим, да тоже стал портиться потихоньку.
IPhone был стоящим, да тоже стал портиться потихоньку.
Вы можете привести пример того, что раньше работало на мегагерцах и мегабайтах, а теперь требует гигагерцы и гигабайты? При равных возможностях.
Драйвер мыши. Раньше это был килобайт, ну два кода. Ну памяти сколько там могла отьесть резидентная программа для своей работы? Килобайт 16?
А вот сейчас висит у меня ipoint.exe (Microsoft IntelliPoint)
Сам весит 2328944 байт. Памяти жрет 24 мегабайта. На что? :)
При том что все функции для поддержки мыши уже есть в OS. Загадка.
А вот сейчас висит у меня ipoint.exe (Microsoft IntelliPoint)
Сам весит 2328944 байт. Памяти жрет 24 мегабайта. На что? :)
При том что все функции для поддержки мыши уже есть в OS. Загадка.
Ну там же не драйвер, а всякие свистелки место занимают. Я так полагаю, что можно просто воткнуть мышь и вообще ничего не делать. Будет работать нормально же все. Опять же, если посмотреть, что там внутри в пакете, то сами драйвера занимают порядка 50 КБ (30КБ кода для x64). Можно только их и поставить. Только конфигурить придется, видимо, как в старые добрые времена, через regedit :)
В общем, не подходит под пункт о равных возможностях.
В общем, не подходит под пункт о равных возможностях.
Нет никаких свистелок — есть иконка в трее в котором есть только один пункт «Exit».
И драйвера я сам не ставил. Воткнул мышь, она определились как мышь от MS. Win7 полезла в интернет, сдернула драйвера, после чего в системе появился процесс ipoint.exe.
Для чего он нужен — мне неведомо. Как пользователь буду ли я забавляться с регедит-ом? Да даже как непользователь не буду, быстрее другую мышку найти.
И драйвера я сам не ставил. Воткнул мышь, она определились как мышь от MS. Win7 полезла в интернет, сдернула драйвера, после чего в системе появился процесс ipoint.exe.
Для чего он нужен — мне неведомо. Как пользователь буду ли я забавляться с регедит-ом? Да даже как непользователь не буду, быстрее другую мышку найти.
сейчас 2014-ый, а мы все еще используем VimС таким программистом дальше разговаривать просто не о чем.
«Сейчас 2014, а мы все еще составляем слова из букв.»
Простите, а вы вообще работали с IDE типа JetBrains IDEA?
Прощаю, работал. И что?
Я еще на пхп когда-то писал, чего уж там.
Кто без греха, пусть кинет камень.
Я еще на пхп когда-то писал, чего уж там.
Кто без греха, пусть кинет камень.
Простите, я вот работаю в IDEA, но без IdeaVim-плагина работы не представляю. На коллег, постоянно в той же Idea пользующихся мышкой, больно смотреть.
Функционал редактора и функционал среды разработки ортогональны. Программа может быть никаким редактором, но предоставлять кучу функций по работе с кодом. Также может быть так, что редактировать текст в ней потрясающе удобно, а вот фич для упрощения разработки — кот наплакал. Вим — это как раз второй случай. Я тоже пишу в идее исключительно с помощью IdeaVim, и без вимоподобной раскладки не представляю себе удобного редактирования текста. Но сам вим, как бы крут он не был для редактирования, не заменит полноценную среду. Вышеприведённый пример с «Find all usages» очень показателен. А ведь это только одна из функций. Другой типичный пример, характерный для Java — перемещение класса в другой пакет. В среде это пара кликов мышкой (или пара горячих клавиш, если настроено). А в случае вима это перемещение файлов вручную и изменение целой кучи других файлов, которые использовали перемещаемый класс. В проекте, где число классов близко к тысяче, это просто невозможно сделать без ошибок. И опять же, это только один из множества примеров.
Разумеется, ортогональны. Причем подойти к вопросу можно и с другой стороны: есть, например, такой проект, как eclim, интегрирующий headless eclipse в vim.
Я, большой любитель Vim считаю IDEA «близким» к нему по подходу хоткиз, ибо 95% действий в Идее можно сделать с помощью клавиатуры (конечно с возможностями редактирования не сравнить, но скажем ctrl+w вполне неплохо заменяет, а иногда и лучше, чем v+i+w)
Да, в IDEA все хорошо с хоткеями, мышка вообще не нужна. Но редактирование кода (а подавляющую часть времени в IDE мы пишем код) с vim-плагином намного эргономичнее — невозможно все возможности вима уместить на хоткеях с модификаторами, без введения режима команд (либо получатся такие хоткеи, что за пару месяцев работы заработаешь туннельный синдром).
Некорректное сравнение.
Сейчас 2014 год, но часто ли мы используем пергамент и чернила, пишем пером? Вообще пишем вручную, а не клавиатуре? Используем почтовых голубей? Буквы — да, буквы остались. Способ записи и передачи букв изменился.
Сейчас 2014 год, но часто ли мы используем пергамент и чернила, пишем пером? Вообще пишем вручную, а не клавиатуре? Используем почтовых голубей? Буквы — да, буквы остались. Способ записи и передачи букв изменился.
Вот это действительно некорректное сравнение. Клавиатура обычно быстрее и эффективнее каллиграфии. Vim обычно быстрее и эффективнее IDE.
И да, безусловно, есть определенный шарм в том, чтобы писать пером, или отправлять всякие вещипочтой России почтовыми голубями, или ждать пока запустится IntelliJ. Отлично, когда есть выбор, не правда ли?
И да, безусловно, есть определенный шарм в том, чтобы писать пером, или отправлять всякие вещи
Я сам долгое время разрабатывал сайты на PHP из Notepad++, даже аргументировал похоже, мол, пока эта IDE загрузится, я пол класса напишу))
Но когда дошел до крупных, даже КРУПНЫХ проектов, осознал, как круто иметь возможность видеть автоматические подсказки по методам и аннотации вслпывающие, подсказки по методам и классам, как удобно рефакторить в IDE-шке… Ух. Это не мешает мне иногда использовать тот же блокнот для быстрого редактирования какого-то файла, но IDE помогает мне не держать в голове то, что она может быстро показать или подставить сама.
Я сейчас разрабатываю под android, в той же, и она меня IntelliJ IDEA 13 дико радует. Например, редактор XML-ек с версткой экранов. Можно даже не пользоваться визуальным редактором и писать XML-ку руками — но всё равно тут же видеть превьюшку. IDE мне настучит по рукам, если я попробую использовать параметр доступной только с API Level 19, когда я сейчас пишу под 11 и т.п. Не нужность держать это в голове, отдать рутину машинке, освободить больше процессорного времени мозга для разработки бизнес-логики — разве это не оптимальный подход?
Но когда дошел до крупных, даже КРУПНЫХ проектов, осознал, как круто иметь возможность видеть автоматические подсказки по методам и аннотации вслпывающие, подсказки по методам и классам, как удобно рефакторить в IDE-шке… Ух. Это не мешает мне иногда использовать тот же блокнот для быстрого редактирования какого-то файла, но IDE помогает мне не держать в голове то, что она может быстро показать или подставить сама.
Я сейчас разрабатываю под android, в той же, и она меня IntelliJ IDEA 13 дико радует. Например, редактор XML-ек с версткой экранов. Можно даже не пользоваться визуальным редактором и писать XML-ку руками — но всё равно тут же видеть превьюшку. IDE мне настучит по рукам, если я попробую использовать параметр доступной только с API Level 19, когда я сейчас пишу под 11 и т.п. Не нужность держать это в голове, отдать рутину машинке, освободить больше процессорного времени мозга для разработки бизнес-логики — разве это не оптимальный подход?
НЛО прилетело и опубликовало эту надпись здесь
Я просто не работал с vim, но работал с редакторами с подсветкой синтаксиса, типа Notepad++.
Vim умеет по команде перейти в реализацию нужного метода? (сам найти и открыть требуемый файл)? Показать все реализации, если мы находимся в интерфейсе, например? Показать все «перекрытия метода вверх и вниз»? (перейти к наследнику, в котором метод заново реализован/предку в длинной иерархии классов) Я правда просто не знаю, есть ли там все эти пользительные возможности.
Vim умеет по команде перейти в реализацию нужного метода? (сам найти и открыть требуемый файл)? Показать все реализации, если мы находимся в интерфейсе, например? Показать все «перекрытия метода вверх и вниз»? (перейти к наследнику, в котором метод заново реализован/предку в длинной иерархии классов) Я правда просто не знаю, есть ли там все эти пользительные возможности.
Сам — нет. Для этого он использует т.н. «tag files», которые сооружаются сторонними утиитами: ctags, cscope, clang tags итд. К сожалению, делают они это небыстро, в общем случае по команде и при работе в фоновом режиме проблемы. А сама функциональность прыгания по файлам и отображения completion/search result списокв есть конечно :).
НЛО прилетело и опубликовало эту надпись здесь
1. cscope строит базу ядра по времени намного быстрее Eclipse
2. cscope делает быстрое перестроение при уже построенной базе
2. cscope делает быстрое перестроение при уже построенной базе
У него есть некоторые проблемы с фоновым режимом работы, потому как VIM немного однопоточный. Приходится извращаться с порождением фоновых процессов и взаимодействием через пайпы, что негативно влияется на все. Там же Visual Studio почти все делает в фоновом режиме. Особенно с Visual Assist и Resharper.
Vim обычно быстрее и эффективнее IDE.
При редактировании текста — да. Когда нужно работать именно с исходным кодом и проводить сложные операции над AST вида «переименовать вот это поле для всех экземпляров вот этого класса во всех двадцати мегабайтах нашего проекта» — нет.
НЛО прилетело и опубликовало эту надпись здесь
Конечно я допускаю, что вы можете поддерживать некую огромную ERP систему написанную индусами и удачно взлетевшую, из-за чего ваша команда все время занимается вялотекущим рефакторингом, но таких случаев на моей памяти исчезающе мало.
Расскажу. Так как я кроме основных команд еще часто консультирую другие компании, то есть наблюдения. Типичная начальная ситуация — когда 1-2-3 разработчика пилят проект. Они знают базу кода, код боллше пишется чем меняется, все хоршо. Через три года, когда двое из них уже уволились, оставшийс стал тим лидом и наняли еще три команды по 10 бойцов начинается ротация кадров. И вот тут-то, как бы хороша не была архитектура, новым разработчикам приходится ее изучать. Для этого нужно как минимум «Find all references». А также раотающий «go to definition» (который, между прочим, в реальной жизни даже в Visual Studio не работает, приходится сверху Visual Assist докупать) и прочие радости раоты с кодом как с кодом, а не с текстом.
Рефакторинг же часто требуется для устранения технического долга между релизами и поддержки более сильными разраотчиками менее сильных. В ряде случаев это дешеле и эффективнее, чем pre-commit code review. Но это, в целом, не критично. А вот find all references, go to definition и прочее — критично.
НЛО прилетело и опубликовало эту надпись здесь
Для языков поддерживающих ctags и gtags.
Интересно, эти xtags помогут текстовому редактору отличить в контексте выражения глобальную переменную от локальной, просканировать только те неймспейсы, которые подключены в using, чтобы перейти к правильному definition, а не к первому похожему?
В общем случае, нужно применить препроцессор и построить синтаксическое дерево по всем правилам языка, иначе ложные срабатывания обеспечены.
Нет. Там очень тривиальный анализатор, который от грепа отличается только понимаем что такое область видимости и простейшим набором трюков, которые можно применить на plain text без разбирания ast и зависимостей.
по-моему зря этот Джо сюда Java прилепил, она совсем из другой оперы, и отсюда холивар весь.
кто-то может привести пример инструментария для языков с _динамической_ типизацией где всякие go to definition и find all references, дают сколь-нибудь существенное отличие в надежности результата, по сравнению с «тупым грепом»?
мне вот не попадались еще. поэтому да, на первый план, так или иначе, выходит удобство редактирования и «vim» — наше всё. остальные трюки приходится делать лапками и внимательно проверять глазками.
кто-то может привести пример инструментария для языков с _динамической_ типизацией где всякие go to definition и find all references, дают сколь-нибудь существенное отличие в надежности результата, по сравнению с «тупым грепом»?
мне вот не попадались еще. поэтому да, на первый план, так или иначе, выходит удобство редактирования и «vim» — наше всё. остальные трюки приходится делать лапками и внимательно проверять глазками.
Python, Visual Studio 2013, «find all references» на определение «a» в конструкторе Foo. Сложнее можете сами поиграться, все бесплатно и доступно для скачивания с офсайтов:
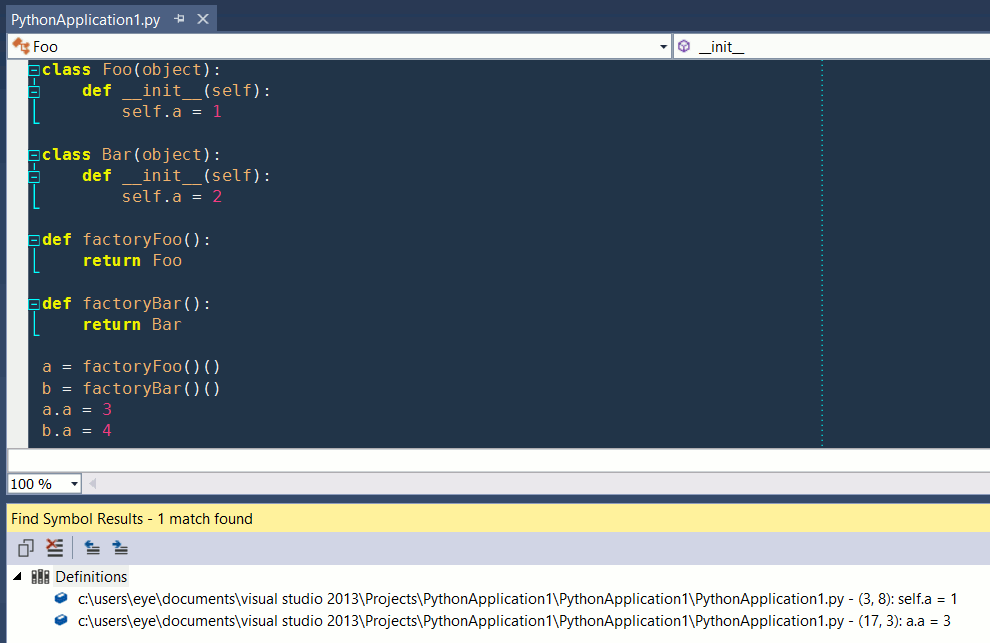

мм. а если так? :)
def factoryMad():
return random.choice([Foo, Bar])
Так, конечно, не найдет. Потому что random C-шный код, и никто не знает что он возвращает. А вот так — найдет:
def factoryMad():
if 1:
return Foo
else:
return Bar
я хотел сказать, что в реальных проектах, возможности языка используются на полную катушку — со всяким мета-программированием, и прочей ерундой, которая делает язык именно таким, за что мы его и выбираем, а статический анализ — лишь приятной примочкой (типа на PEP8 чекать). автоматический рефакторинг в каких-то частных случаях тоже возможен, но поменять мегабайт индуистического кода неглядя, как для Java — это фантастика (или безумие).
Еси какакая-то тулза автоматически решает задачу в 95% случаев, а в 5% за ней нужно немного подправить руками — то меня такая тулза вполне устраивает, пока альтернатива — править руками все с шансом на ошибку большим, чем у автоматики тулзы.
А вот VIM с ctags такого не может в принципе, как ни крути.
А вот VIM с ctags такого не может в принципе, как ни крути.
Да и на java тоже. Как только выходим на уровень интеграционного функционала или метапрограммирования (то же aspect-oriented programming) — только с подробным тестированием, как дедушка Фаулер завещал ,)
Банальный пример: использование IoC-контейнера дает позднее связывание (часто в рантайме) и при рефакторинге от IDE требуется «понимание», как работает конкретный контейнер, чтобы не нарушить его работу.
Банальный пример: использование IoC-контейнера дает позднее связывание (часто в рантайме) и при рефакторинге от IDE требуется «понимание», как работает конкретный контейнер, чтобы не нарушить его работу.
Аналогичные эвристические алгоритмы работают и в семействе IntelliJ. Но как доходит до простого метапрограммирования (на ruby, python, js — не суть), начинаются проблемы.
Редактор питона в Visual studio, кстати, действительно хорошо сделан и его постоянно улучшают.
Для питона сейчас активно развивается проект github.com/davidhalter/jedi (я использую в комплекте с Emacs github.com/tkf/emacs-jedi ). Работает прекрасно, не тормозит.
Features тут jedi.jedidjah.ch/en/latest/docs/features.html
Features тут jedi.jedidjah.ch/en/latest/docs/features.html
НЛО прилетело и опубликовало эту надпись здесь
А для части языков и ast недостаточно. Начиная с метапрограммирования на всяких ruby, python, javascript; AOP на java (хотя, там есть плагины типа ajdt для eclispe и aspectj support для idea). Конечно, делают плагины для конкретных языков и фреймворков, но сейчас часто итоговая структура собирается только в рантайме.
Э… Как? Вот взяли нового человека в команду… Ну пусть какую-нить внутреннюю CMS крупной компании допиливать. Java, десять мегабайт кода (очень много GUI и три вагона логики, отчетов всяких, аналитики, интеграции с другими программами). Вот он ползает по коду и видит Странный Класс. Со Странным Методом. И нужно ему для понимания процесса выполнить запрос «все фрагменты кода, где выывается этот метод». Как это сделать с примитивным инструментом?
НЛО прилетело и опубликовало эту надпись здесь
Да пожалуйста. Человеку нужно поменять функцинальность модуля. Он его видит первый раз в жизни. Смотрит на методы — это понятно, это понятно. А вот это — непонятно. И с комментарием тоже не понятно. Простейший и самый б быстрый способ разобраться — «find all references» и посмотреть как и где ЭТО используется в коде.
Сверху вниз на 10-мегабайтной CMS — это как и откуда? O_O
Если мне нужно разобраться как что-то работает, то я обычно ищу сверху вниз, погружаясь в реализацию.
Сверху вниз на 10-мегабайтной CMS — это как и откуда? O_O
НЛО прилетело и опубликовало эту надпись здесь
Типичная задача — «вот тебе модуль, имплементирующий таск в JIRA такой-то и дополнительные задачи такие-то и такие-то» (это видно по blame). Вот следующая задача в JIRA — нужно что-то поменять, к примеру модуль оперирует одной бизнес-сущностью, а нужно модифицировать его и систему так, чтобы оперировал еще и другой. Типичная, рядовая задача. Требует рефакторинга всего модуля по диагонали и скорее всего ряда мест, где он используется. Вперед, и главный критерий — скорость выполнения задачи, потому что каждый день отсутствия этой функции — это недополученая прибыль у клиента.
Я предвижу, что вы скажете про то, что расширяемую архитектуру надо заранее делать. Нет, во времени путешетвовать я не умею и кто умеет не знаю. Деньги обычно платят за решение конкретных задач, здесь и сейчас :).
Я предвижу, что вы скажете про то, что расширяемую архитектуру надо заранее делать. Нет, во времени путешетвовать я не умею и кто умеет не знаю. Деньги обычно платят за решение конкретных задач, здесь и сейчас :).
Ну вот вы сверху вниз добрались до странного метода, и понимаете, что вам его неплохо бы конкретно так поменять. Для того использования, по которому вы пришли, это решит вашу проблему. Вопрос: не поломает ли это изменение что-то еще, завязанное на этот метод?
НЛО прилетело и опубликовало эту надпись здесь
Если мне нужно будет рефакторить метод с названием типа toString, то понятное дело у меня будут боооольшие проблемы. Но неужели вы правда думаете, что если бы мне приходилось сталкиваться с такими проблемами, я бы не поменял окружение на более подходящее?
Ну вот, видите, даже вы согласились что ряд задач требует IDE, которые могут что-то, чего не может ack. А вот один из авторов erlang, заявление которого мы тут обсуждаем, утверждает что все тулзы за 40 лет не улучшились.
НЛО прилетело и опубликовало эту надпись здесь
Не вижу как он может быть прав, если он говорит «не улучшилось», а в топовых средах разработки «появился intellisense для языков со статической типизацией». Которые энтерпрайз мейнстрим C++/C#/Java и которых 40 лет назад не было. Ни языков, ни IDE.
А что до динамических, см. выше мой скриншот от Visual Studio 2013 для Python. Все уже работает.
А что до динамических, см. выше мой скриншот от Visual Studio 2013 для Python. Все уже работает.
Во-первых я буду смотреть по ситуации, во-вторых тот факт, что IDEA поменяет везде в коде сигнатуры метода не будет означать, что ничего нигде не сломано. Тут вас спасут только тесты.
Я имею ввиду, что в подобной ситуации для начала неплохо бы посмотреть, где еще в проекте «вызывается конкретно этот метод».
угу. только при чем тут Java, если статья конкретно про Erlang?
в этом цирке «Станый Метод» может быть запросто результатом чего-то в роде string:concat(X, Y), или того хуже. это совсем другой мир, где от AST толку чуть. распоследние тулзы пытаются даже код выполнять, но у и этого подхода есть принципиальные ограничения.
в этом цирке «Станый Метод» может быть запросто результатом чего-то в роде string:concat(X, Y), или того хуже. это совсем другой мир, где от AST толку чуть. распоследние тулзы пытаются даже код выполнять, но у и этого подхода есть принципиальные ограничения.
К слову go to definition и find all references могут быть настроены в vim и emacs. Для языков поддерживающих ctags и gtags
Для чего-то сложнее hello world — не могут. Потому что с точки зрения ast языка, строчка «auto a = foo.create(); a.name = „bar“;» имеет в виду поле 'name' объекта, который создает «foo.create()». О том, что это за объект знает компилятор и, возможно, статический анализатор. ctags об этом знать не может. И, соответственно, «find all references» в режиме ctags мало отличается от grep, что на сложный проектах от мегабайта исходников чуть менее чем бесполезно.
А какая группа языков используется? И насколько плохи «менее сильные» разработчики? Каков объем проектов?
Я в основном на enterprise экзотике специализируюсь: C++, C#, Java. Что с рефакторингом у мейнстримовых php, python, ruby и js для веб страничек я не знаю, увы. Обычно проблем вызывают проекты от мегабайта исходников. Я еше ни разу не видел, чтобы команда запуталась в тысяче строк кода :). Менее сильные разработчики обычно плохи на уровне 50-60к белыми на руки по Москве. То есть действующий/недавний студент который прочел пару книжек, написал велосипед и, возможно, год работал единственным разработчиком в неайтишной компании. Такова суровая правда жизни — специалистов по 150к нанимать долго, дорого, сложно и плохо масштабируемо. Работаем с тем что есть.
НЛО прилетело и опубликовало эту надпись здесь
Ну сил на «преведение в порядок» у тимлидов в реальности не остается :). Скорее, стараются держать технический долг на уровне, потребном бизнесу. Чтобы продукт целиком не сгнил раньше, чем это предусмотрено. И чтобы расширение в ожидаемые стороны не всегда требовало переписывать с нуля. Где-то так.
Так что тулзы для работы с кодом очень потребны, да. Конкуренция, одним вимом и мейкфайлами уже обходиться тяжеловато.
Так что тулзы для работы с кодом очень потребны, да. Конкуренция, одним вимом и мейкфайлами уже обходиться тяжеловато.
НЛО прилетело и опубликовало эту надпись здесь
Батенька, ну где же я вам enterprise код найду, который был бы публичный? На публичные меня никто не приглашает :(. Все за что мне деньги платят во внутренних репозиториях лежит. И цитировать я оттуда не могу — потому что NDA.
Вот из последнего пример. Не самый крупный, но и немаленький джава-проект с кривой системой авторизации, которую нужно привести в порядок. В глубине этой системы лежит реализованный строками идентификатор доступа, который генерируется из имени класса, дергается по всей программе и так строками и пишется в базу постоянно. Работать сложно, потому что в программе тысячи методов, которые на вход принимают строку, и поди разберись, что это за строка. Для упрощения дальнейшей работы неплохо бы выпилить это безобразие и заменить нормальным классом, а в методы передавать не непонятную строку, а экземпляр класса с несколькими полями. Тут без толковой поддержки рефакторинга как без рук.
Другое дело, что такая задача весьма специфична, и занимает примерно 1% времени от работы среднего программиста
Может, я страдаю перфекционизмом, но часто в процессе написания до меня доходит, что имя переменной, метода или класса изначально выбрано неудачно или в процессе развития кода перестало соответствовать. Я не заморачиваясь переименовываю идентификатор в одном месте и нажимаю хоткей — среда запомнила, что было переименовано в последний раз и распространяет изменения на весь проект.
А что вы в такой ситуации делаете: миритесь с тем, что название уже не соответствует, или делаете глобальный find/replace с ручным контролем, какие места переименовать, а какие пропустить?
Хочу кстати спросить у автора перевода. spiff, как сами то относитесь к сказанному к статье? Согласны по каким-то пунктам, по всем, статья опубликована ради дискуссии?
Я согласен с тем, что никакие тулы не отменяют необходимости думать головой и понимать, что именно ты делаешь. Я как человек из мира системного программирования (в данный момент разработка компиляторов) пишу как раз 10-20 строк в день и вполне обхожусь Vim, Makefile и grep. В этом плане я Джо поддерживаю. С другой стороны у меня есть Java OSS проект c которым без супер-соврменной IDE работать почти невозможно. Я конечно, знаю там каждую строку и даже могу на коленке (в Notepad) написать какой-нибудь патч, но я предпочитаю использовать Intellij IDEA для этого.
Мне в словах Джо вот, что приглянулось. Последний абзац. У нас действительно проблема. Мы все говорим на разных языках. Да, 40 лет назад любой программист понимал любого другого с полуслова. Но сейчас — у нас уже куча специализаций, кланов если хотите. Я не говорю, что это плохо. Это прогресс, скорее всего. Но я за то, чтобы хоть как-то сохранить связи и иметь в наличии язык на котором мы сможем говорить. И я зык этот дожен быть не тулом а чем-то более глобальным. Я глубоко надеюсь, что то что называется Computer Science и есть этот самый универсальный язык. И его нужно стараться сохранять и учить независимо от того в какой области вы работаете — веб или системного программирования.
Мне в словах Джо вот, что приглянулось. Последний абзац. У нас действительно проблема. Мы все говорим на разных языках. Да, 40 лет назад любой программист понимал любого другого с полуслова. Но сейчас — у нас уже куча специализаций, кланов если хотите. Я не говорю, что это плохо. Это прогресс, скорее всего. Но я за то, чтобы хоть как-то сохранить связи и иметь в наличии язык на котором мы сможем говорить. И я зык этот дожен быть не тулом а чем-то более глобальным. Я глубоко надеюсь, что то что называется Computer Science и есть этот самый универсальный язык. И его нужно стараться сохранять и учить независимо от того в какой области вы работаете — веб или системного программирования.
А это действительно проблема? Т.е., если встретятся два инженера, один из которых всю жизнь проектировал тракторы с отсутствием электроники, а второй — мобильные телефоны, как быстро и просто они смогут найти общий язык? Номинально все чертежи и схемы пишутся по стандартам, но реально, если окунуться в чужую область — сколько времени понадобится, что бы понять всю специфику, что бы начать говорить на одном язык? Ситуация такая сложилась наверняка не только у программистов.
Ну или как вариант, что ни вас, ни Джо верно не понял.
Ну или как вариант, что ни вас, ни Джо верно не понял.
Ну ваш пример слегка вычурный. Это действительно два разных инженера (Electrical Engineering и Машиностроение?). Эти ребята разве что на языке математики и физики будут договариваться. Мой поинт в том, что формально мы все люди из одной сферы и занимаемся одним и тем-же — «при помощи текстовых файлов говорим компьютерам что делать ».
Одни пишут 10 строк в день и уверенно двигаются к конечному продуктуБла-бла-бла. 10 строк — одни лишь импорты, инклюды, дефайны и прочая нужная фигня. Пусть сам их руками пишет.
Я помню времена, когда программисты отлично понимали друг другаБла-бла-бла. Это он про те времена, когда не было стандартов языков, стандартов железа, на каждой машине стоял полностью свой вендорный набор софта, а индустрия ныла о том, как фигово готовить специалистов, когда это «специалист по XYZ-1020 фирмы ABC», ага.
Большую часть времени провожу в IDEA от JetBrains, тем не менее, я очень люблю vim, bash, make, awk, sed и пр. и слазить с этих инструментов пока желания нет.
НЛО прилетело и опубликовало эту надпись здесь
Сейчас же, человек который ничего не видел кроме Java и Maven входит в ступор, когда ему присылают Rake-файл.
Интересно, что происходит с человеком, который ничего не видел кроме Rake-файлов, когда ему присылают Maven-файл.
НЛО прилетело и опубликовало эту надпись здесь
Кажется, товарищ Армстронг забыл, что тулы нужны не только для того, чтобы решать задачи, но и чтобы легко делиться плодами своего труда с другими. Ну и опять же, почему бы умному человеку не писать тулы, чтобы автоматизировать рутинные задачи и не повторять рутинные действия снова и снова?
Зачем? Так же можно похвастатся, какой ты офигенный, что неделями программил на перфокарты, а нынче «молодеж» вообще разбалованная.
Хотя учить стоит имхо с консоли в том числе, потому что встречаю повсеместно например Android девов, которые не могут сбилдить программу с консоли и не знают, что такое maven/ant/gradle. В большинстве случаев мб это и не надо, ведь IDE автоматизирует процедуру построения, но бывают случаи, когда бы это знать не помешало бы.
Хотя учить стоит имхо с консоли в том числе, потому что встречаю повсеместно например Android девов, которые не могут сбилдить программу с консоли и не знают, что такое maven/ant/gradle. В большинстве случаев мб это и не надо, ведь IDE автоматизирует процедуру построения, но бывают случаи, когда бы это знать не помешало бы.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Джо Армстронг об инструментах разработчика