Комментарии 26
Интересная штука, думаю можно использовать в различных «играх» на сайтах или интерактиве!
очень интересно описано, с этой темой до этого знаком не был. Но пример и демка выбраны таким образом, что стало ясно как это работает. Только пока не очень понятно, где бы можно было использовать эту штуку.
В общем случае, деревья принятия решений находят применение в качестве нелинейных классификаторов (из примеров, на ум приходит — оценка кредитоспособности клиентов в банке). Также, в сравнении с другими видами классификаторов, результаты классификации деревьев принятия решений легче интерпретировать — можно взглянуть внутрь дерева и проследить цепочку условий (правда, с практической точки зрения — здесь тоже имеются свои нюансы).
В конце статьи я описал идею, о поисковике, который мог бы ранжировать результаты поиска на стороне клиента, с использованием локально построенного классификатора принятия решений (заинтересует пользователя сниппет или нет?). Хотя, думаю, что несмотря на то, что идея звучит довольно просто — при её реализации могут возникнуть различные подводные камни (например, какие именно статические/динамические атрибуты использовать?).
Также, думаю что было бы интересно использовать данную библиотеку для создания игровой логики, которая бы могла обучаться в процессе игры (прогнозировать следующий ход игрока — и, соответственно, как-то противодействовать).
В конце статьи я описал идею, о поисковике, который мог бы ранжировать результаты поиска на стороне клиента, с использованием локально построенного классификатора принятия решений (заинтересует пользователя сниппет или нет?). Хотя, думаю, что несмотря на то, что идея звучит довольно просто — при её реализации могут возникнуть различные подводные камни (например, какие именно статические/динамические атрибуты использовать?).
Также, думаю что было бы интересно использовать данную библиотеку для создания игровой логики, которая бы могла обучаться в процессе игры (прогнозировать следующий ход игрока — и, соответственно, как-то противодействовать).
А ID3 деревья могут строить регрессии?
В качестве довольно грубого приближения — можно разбить ряд непрерывных значений на несколько классов (например, «очень маленькие значения», «маленькие значения», «большие значения» и т.д.). Затем, имея ограниченное число классов — можно использовать ID3 дерево. Правда, такую технику получится использовать лишь для прогнозирования трендов.
А вообще, для регрессии, лучше посмотреть в сторону CART. На Хабре была статья, в которой упоминался данный метод: habrahabr.ru/post/116385/
А вообще, для регрессии, лучше посмотреть в сторону CART. На Хабре была статья, в которой упоминался данный метод: habrahabr.ru/post/116385/
Для работы с непрерывными значениями Куинлан (создатель ID3) предложил алгоритм C4.5. Дальше другие авторы еще развивали эту тему.
Вообще, ID3 — это алгоритм построения дерева классификации. Для регресии, как сказали выше, лучше смотреть другие вещи.
Вообще, ID3 — это алгоритм построения дерева классификации. Для регресии, как сказали выше, лучше смотреть другие вещи.
Чет т в хроме и IE 10 не пашет. FF и опера работает. Напишите, пожалуйста, поддерживаемые сейчас браузеры. А так весьма любопытно.
Проверял в Safari 6.0 и 7.0, Firefox 8.0 и 26.0, Google Chrome 31.0
А что именно не пашет?
Если честно, то в хроме и FF наблюдал проблемы с отображением очень больших деревьев.
CSS для рисования дерева на основе вложенных списков — взят отсюда: thecodeplayer.com/walkthrough/css3-family-tree
Но, поскольку с вёрсткой я фактически не работал раньше — то пофиксить стили для определённых браузеров у меня не получилось (
А что именно не пашет?
Если честно, то в хроме и FF наблюдал проблемы с отображением очень больших деревьев.
CSS для рисования дерева на основе вложенных списков — взят отсюда: thecodeplayer.com/walkthrough/css3-family-tree
Но, поскольку с вёрсткой я фактически не работал раньше — то пофиксить стили для определённых браузеров у меня не получилось (
Пофиксил.
Теперь демки должны работать и в Яндекс Браузере и в Хроме (надеюсь, что и в IE тоже).
Причина была в том, что к jsfiddle подключал JS код, который хостится на гитхабе (более подробное описание здесь: stackoverflow.com/questions/17341122/link-and-execute-external-javascript-file-hosted-on-github)
Ссылки на демки обновил.
Теперь демки должны работать и в Яндекс Браузере и в Хроме (надеюсь, что и в IE тоже).
Причина была в том, что к jsfiddle подключал JS код, который хостится на гитхабе (более подробное описание здесь: stackoverflow.com/questions/17341122/link-and-execute-external-javascript-file-hosted-on-github)
Ссылки на демки обновил.
А насколько однозначным получается решение при обучающей выборке, не охватывающей весь диапазон десятка параметров, но охватывающей все возможные ветви (в некоторых ветвях некоторые значения не важны)? Есть ли вероятность, что набор, имеющий признаки как одной («синий»), так и другой («круглый») ветви, уйдёт не ту ветвь, которая в обучающей выборке была первой(ну или последней) — в общем можно ли как-то задавать приоритет одного набора параметров перед другим?
Вообще суть задачи: иметь человекочитаемые и машинообрабатываемые правила вычисления некоей дискретной функции, заданной десятком правил на естественном языке, но с чётким приоритетом одних над другими (срабатывает первое). Сейчас используется по сути полная таблица принятия решений (чуть уменьшенная за счет отсекания хвостовых параметров в некоторых случаях), обрабатываемая за один проход. Но читать или править её дюже неудобно. Идея обучающей выборки понравилась, но вот ложные срабатывания недопустимы, должен быть чёткий приоритет примеров.
Вообще суть задачи: иметь человекочитаемые и машинообрабатываемые правила вычисления некоей дискретной функции, заданной десятком правил на естественном языке, но с чётким приоритетом одних над другими (срабатывает первое). Сейчас используется по сути полная таблица принятия решений (чуть уменьшенная за счет отсекания хвостовых параметров в некоторых случаях), обрабатываемая за один проход. Но читать или править её дюже неудобно. Идея обучающей выборки понравилась, но вот ложные срабатывания недопустимы, должен быть чёткий приоритет примеров.
Советую почитать предыдущую статью автора.
Если кратко, то приоритет одного параметра перед другим четко определяется самой моделью через понятие энтропии. И порядок атрибутов обучающей выборки неважен. В этом, собственно, и состоит весь изюм этой модели: она сама определяет, какой атрибут наиболее важен на данной стадии, и разбивает обучающую выборку на подмножества по значениям этого атрибута. На следующем шаге анализ «важности» происходит снова, и каждое подмножество в свою очередь разбивается. И так до тех пор, пока в очередном подмножестве не окажутся только те объекты, которые принадлежат одному и тому же классу. В этот момент дальнейшее разбиение по этой ветке больше не нужно, потому что мы получили путь, эффективно классифицирующий эту часть изначальной выборки.
Если ваш вопрос касался того, что делать с ситуацией, когда в обучающей выборке могут оказаться противоречивые данные, то ответ прост: представленный алгоритм ID3 не обрабатывает такие ситуации. Дерево он, конечно, построит, но часть объектов из самой же обучающей выборке потом будут классифицироваться им с ошибкой, что естественно. Разумеется, существуют методы предварительной проверки данных на противоречивость, оценка достоверности и так далее. В реальных системах все это должно применяться в комплексе.
Если кратко, то приоритет одного параметра перед другим четко определяется самой моделью через понятие энтропии. И порядок атрибутов обучающей выборки неважен. В этом, собственно, и состоит весь изюм этой модели: она сама определяет, какой атрибут наиболее важен на данной стадии, и разбивает обучающую выборку на подмножества по значениям этого атрибута. На следующем шаге анализ «важности» происходит снова, и каждое подмножество в свою очередь разбивается. И так до тех пор, пока в очередном подмножестве не окажутся только те объекты, которые принадлежат одному и тому же классу. В этот момент дальнейшее разбиение по этой ветке больше не нужно, потому что мы получили путь, эффективно классифицирующий эту часть изначальной выборки.
Если ваш вопрос касался того, что делать с ситуацией, когда в обучающей выборке могут оказаться противоречивые данные, то ответ прост: представленный алгоритм ID3 не обрабатывает такие ситуации. Дерево он, конечно, построит, но часть объектов из самой же обучающей выборке потом будут классифицироваться им с ошибкой, что естественно. Разумеется, существуют методы предварительной проверки данных на противоречивость, оценка достоверности и так далее. В реальных системах все это должно применяться в комплексе.
Нет, мой вопрос касался ситуации когда в обучающей выборке ровно один случай попадания под каждую категорию. Скажем, есть 5 булевых параметров, и есть таблица результатов типа
(1 1 1 0 0) => 1
(0 0 0 1 1) => 2
(0 0 0 1 0) => 3
(0 0 0 0 1) => 4
(0 0 0 0 0) => 5
При этом система должна «понять», что первые три параметра значимы только если все три установлены, и тогда игнорируются последние два, а иначе игнорируются первые три и значимы только последние два.
(1 1 1 0 0) => 1
(0 0 0 1 1) => 2
(0 0 0 1 0) => 3
(0 0 0 0 1) => 4
(0 0 0 0 0) => 5
При этом система должна «понять», что первые три параметра значимы только если все три установлены, и тогда игнорируются последние два, а иначе игнорируются первые три и значимы только последние два.
Построил дерево решений для Вашего примера.
Судя по структуре дерева, значимыми являются только три параметра из пяти: x1, x4 и x5
Ссылка на демку: jsfiddle.net/H4jpA/
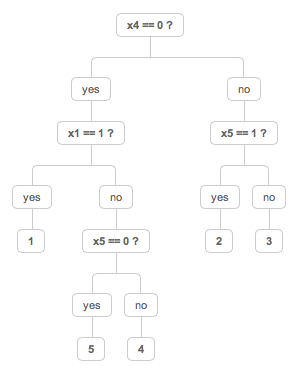
Таким образом, чтобы понять что объект принадлежит к классу «1» — достаточно всего двух параметров x1 и x4.
Судя по структуре дерева, значимыми являются только три параметра из пяти: x1, x4 и x5
Ссылка на демку: jsfiddle.net/H4jpA/

Таким образом, чтобы понять что объект принадлежит к классу «1» — достаточно всего двух параметров x1 и x4.
Опять проблема с подключением либы из гитхаба на jsfiddle (
Вот эта ссылка на демку, которая должна работать во всех браузерах: jsfiddle.net/ug4Hs/
Вот эта ссылка на демку, которая должна работать во всех браузерах: jsfiddle.net/ug4Hs/
Вообще полная таблица выглядит примерно так:
(1 1 1 * *) = 1
(* * * 1 1) => 2
(* * * 1 0) => 3
(* * * 0 1) => 4
(* * * 0 0) => 5
И первая запись имеет явный приоритет.
на псевдокоде это выглядит примерно так:
и (вроде) не допускает неоднозначных решений либо отсутствия решения (при условии, что параметры 0 или 1).
(1 1 1 * *) = 1
(* * * 1 1) => 2
(* * * 1 0) => 3
(* * * 0 1) => 4
(* * * 0 0) => 5
И первая запись имеет явный приоритет.
на псевдокоде это выглядит примерно так:
if (x1 == 1 && x2 == 1 && x3 == 1)
result = 1
else
if (x4 == 1)
if (x5 == 1)
result = 2
else
result = 3
else
if (x5 == 1)
result = 4
else
result = 5
и (вроде) не допускает неоднозначных решений либо отсутствия решения (при условии, что параметры 0 или 1).
Прекрасный пример!
По поводу дерева, которое представил stemm. У меня тоже получилось такое дерево(ура, наши модели написаны без ошибок! :). Но стоит заметить, что атрибуты Х2 и Х3 не то чтобы не имеют значения, они равнозначны (что очевидно) атрибуту Х1. В данном дереве везде вместо Х1 можно смело подставить, например Х2. Алгоритм просто выбрал первый по счету атрибут из равнозначных. Атрибуты Х4 и Х5 тоже равнозначны между собой (это тоже понятно уже по исходному виду таблицы), поэтому корнем дерева вполне мог бы быть и Х5.
Теперь по поводу полной таблицы:
(1 1 1 * *) => 1
(* * * 1 1) => 2
(* * * 1 0) => 3
(* * * 0 1) => 4
(* * * 0 0) => 5
Полная таблица как раз не совпадает с кодом :)
Строка (1 1 1 1 1) будет удовлетворять сразу классам 1 и 2. Псевдокод, конечно, распределит как надо, но обучаемая модель не поймет. В общем-то, никто не поймет, куда распределить строку из всех единиц, если не смотреть псевдокод.
Что интересно, если пройти по предложенному выше дереву, то мы попадем в нужный класс 2, но это будет почти что совпадение.
Если к таблице добавить строку (1 1 1 1 1)=2, то вид дерева не изменится.
Если к таблице добавить строку (1 1 1 1 1)=1, то дерево станет таким:

Вывод: чем больше размер обучающего множества, чем больше в нём «нахлестов», тем точнее будет модель.
По поводу дерева, которое представил stemm. У меня тоже получилось такое дерево
Теперь по поводу полной таблицы:
(1 1 1 * *) => 1
(* * * 1 1) => 2
(* * * 1 0) => 3
(* * * 0 1) => 4
(* * * 0 0) => 5
Полная таблица как раз не совпадает с кодом :)
Строка (1 1 1 1 1) будет удовлетворять сразу классам 1 и 2. Псевдокод, конечно, распределит как надо, но обучаемая модель не поймет. В общем-то, никто не поймет, куда распределить строку из всех единиц, если не смотреть псевдокод.
Что интересно, если пройти по предложенному выше дереву, то мы попадем в нужный класс 2, но это будет почти что совпадение.
Если к таблице добавить строку (1 1 1 1 1)=2, то вид дерева не изменится.
Если к таблице добавить строку (1 1 1 1 1)=1, то дерево станет таким:

Вывод: чем больше размер обучающего множества, чем больше в нём «нахлестов», тем точнее будет модель.
Небольшая поправка. Я написал:
Потом я посмотрел еще раз псевдокод и обнаружил, что как раз-таки первоначальное дерево не соответствует вашему псевдокоду. Дерево, которое представил я, псевдокоду соответствовать будет, как раз из-за дополнительной строки в обучающем множестве: (1 1 1 1 1)=1.
Что интересно, если пройти по предложенному выше дереву, то мы попадем в нужный класс 2, но это будет почти что совпадение.
Потом я посмотрел еще раз псевдокод и обнаружил, что как раз-таки первоначальное дерево не соответствует вашему псевдокоду. Дерево, которое представил я, псевдокоду соответствовать будет, как раз из-за дополнительной строки в обучающем множестве: (1 1 1 1 1)=1.
Полная таблица как раз не совпадает с кодом :) Строка (1 1 1 1 1) будет удовлетворять сразу классам 1 и 2.
Вроде совпадает, если учитывать замечание, что работа происходит сначала до первого совпадения.
Первые три атрибута не то чтобы синонимы, просто их логическое сложение является по сути одним атрибутом и таблицу можно свести к виду:
(1 * *) => 1
(0 1 1) => 2
(0 1 0) => 3
(0 0 1) => 4
(0 0 0) => 5
То есть установка сложного атрибута является однозначным признаком соответствия первому классу.
Но это просто пример, а реальная задача несколько сложнее, просто хотел показать, что есть комбинации параметров, задающие ту или иную «глобальную» (первого уровня ветвь), в которых часть параметров должны игнорироваться, даже если попадают под другую ветвь.
Такой вопрос концептуально не совсем корректен для задачи использования деревьев решений. Я бы не стал применять дерево решений при такой выборке (ну или как минимум хорошо бы обдумал сначала задачу).
Сама модель дерева решений относится к моделям прогнозного анализа, то есть на основе статистических данных (истории) строится дерево, задачей которого является создание прогноза о том, к какому классу будет отнесен новый объект.
В свою очередь прогнозный анализ основывается на главном предположении о сохранении тренда: если какая-то закономерность имела место в прошлом, то она будет иметь место и в будущем.
Деревья решений, впрочем, лишь модель. Применять ее можно как угодно, если это получается эффективно.
В общем случае модель для этого и предназначена. Но это не значит, что модель определит так же, как предполагаете вы. Для модели могут оказаться важными не первые три параметра, а, например, первый и четвертый.
Сама модель дерева решений относится к моделям прогнозного анализа, то есть на основе статистических данных (истории) строится дерево, задачей которого является создание прогноза о том, к какому классу будет отнесен новый объект.
В свою очередь прогнозный анализ основывается на главном предположении о сохранении тренда: если какая-то закономерность имела место в прошлом, то она будет иметь место и в будущем.
Деревья решений, впрочем, лишь модель. Применять ее можно как угодно, если это получается эффективно.
При этом система должна «понять», что первые три параметра значимы только если все три установлены, и тогда игнорируются последние два, а иначе игнорируются первые три и значимы только последние два.
В общем случае модель для этого и предназначена. Но это не значит, что модель определит так же, как предполагаете вы. Для модели могут оказаться важными не первые три параметра, а, например, первый и четвертый.
Отто же дрыщ, откуда в нём 180 фунтов? Там от силы 160.
//Я понимаю, что так дерево компактнее выходит, но всё же…
//Я понимаю, что так дерево компактнее выходит, но всё же…
Спасибо, весьма интересная статья (а предыдущая — вообще блеск!). В своей диссертации я использовал деревья решений как основную модель для классификации. Тоже писал на javascript построение деревьев, вижу в представленной в статье библиотеке частично свой же по сути код, только лучше оформленный :) Приятно, что деревья решений удерживают определенный интерес. И, на мой взгляд, очень заслуженно.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Деревья принятия решений на JavaScript