Комментарии 160
НЛО прилетело и опубликовало эту надпись здесь
В чем же она сложная? Наоборот, многие вещи становятся гораздо проще. Долгие годы писали stateful на малых нагрузках, а тут то же самое, но есть возможность сделать масштабируемо без перехода к stateless.
Мне роднее концепция, когда состояние приложения хранится на клиентской стороне, а сервер рассматривается как набор сервисов/API. Это естественней, что-ли. Классический клиент-сервер.
Долго думал, что к этому все и придет. Особенно после выхода GWT. Но что-то эта тенденция сильно замедлилась. Хотя концепция single page приложений потихоньку набирает популярность.
Потребность в тяжелых single page приложениях есть. Но, ИМХО, пока не выйдет JavaScript с хорошей поддержкой классов или Google не добавит в Chrome поддежку Java, все еще долго будут топтаться на месте.
Долго думал, что к этому все и придет. Особенно после выхода GWT. Но что-то эта тенденция сильно замедлилась. Хотя концепция single page приложений потихоньку набирает популярность.
Потребность в тяжелых single page приложениях есть. Но, ИМХО, пока не выйдет JavaScript с хорошей поддержкой классов или Google не добавит в Chrome поддежку Java, все еще долго будут топтаться на месте.
НЛО прилетело и опубликовало эту надпись здесь
Меня уже долгое время интересует вопрос: когда нужно разделять сервер и клиент, когда действительно нужно делать клиента толстым и писать все эти REST API, RPC. Понятно что если помимо веб интерфейса планируется мобильное приложение, десктопное приложение или еще какая нибудь экзотика, то нужно API. Но если планируется только веб морда, действительное ли нужно все это воротить?
Что бы не быть голословным: работал над крупным проектом. Был сервер с REST API и толстый веб клиент. Проблем было море, вот те которые относятся к теме:
— бизнес логика дублировалась и на клиенте и на сервере. Это к стати общая проблема толстых клинтов.
— некоторые вещи не подходили под REST API, а скорее тяготели к RPC. Смотрелись они чужеродно.
Что бы добавить справочник нужно было сделать кучу рутины — к концу уже начинал во всю зевать. И самое обидное что не было особых причин делать обе стороны толстыми. Релтаймность можно было достигнуть и без этого. Тем более нужно она была всего в паре мест.
Что бы не быть голословным: работал над крупным проектом. Был сервер с REST API и толстый веб клиент. Проблем было море, вот те которые относятся к теме:
— бизнес логика дублировалась и на клиенте и на сервере. Это к стати общая проблема толстых клинтов.
— некоторые вещи не подходили под REST API, а скорее тяготели к RPC. Смотрелись они чужеродно.
Что бы добавить справочник нужно было сделать кучу рутины — к концу уже начинал во всю зевать. И самое обидное что не было особых причин делать обе стороны толстыми. Релтаймность можно было достигнуть и без этого. Тем более нужно она была всего в паре мест.
Разделение простое, если сайт — генерируйте все на сервере, если веб-приложение — разделяйте.
Бизнес логику в любом случае нужно будет продублировать, потому что пользователю нужен отзывчивый интерфейс, а не передёргивание страницы на каждый чих, вроде не заполнения обязательного поля. Для уменьшения трудозатрат можно сделать небольшую прослойку в виде node.js, который будет по сути являтся проксёй в «настоящий» бэкэнд и заниматься будет тем что валидирует то что ему пришло и отправляет данные на обработку либо заворачивает запрос.
По второму пункту — приведите пример, пожалуйста.
По второму пункту — приведите пример, пожалуйста.
Относительно node.js уже думал, можно повторно использовать код на сервере и клиенте. Но под него нужно уметь писать, framework'ов пока не шишь для него. Да и «в нем все работает быстро за исключением твоего кода» или как там оно звучало. Ну и ограничен ты JS и его производными.
По второму пункту. Например для уменьшения дублирования кода создал API для валидации данных, на JS это было бы громоздко. Но вот под концепцию REST оно не сильно подходит. Это скорее RPC.
По второму пункту. Например для уменьшения дублирования кода создал API для валидации данных, на JS это было бы громоздко. Но вот под концепцию REST оно не сильно подходит. Это скорее RPC.
Эм? Не понял. Никакого смысла создавать АПИ для валидации нет — им пользоваться никто не будет(как и те, кто пишет новое представление, так и кулхацкеры).
Как модуль-прослойка между бэкэндом и «основным» кодом — вполне. И этого будет не видно в REST, это чисто бэкэндовая фича(у меня например на стороне клиента есть одна глобальная функция которая посылает данные, она же — обрабатывает глобальные ошибки. Но можно написать свою спеку, и обрабатывать стандартизированные ошибки в этом методе). Запрос пойдёт по REST-правилам, просто провалидируется перед тем как выполниться.
Да и на JS правильно организованная валидация данных — не проблема(конечно, БЫВАЮТ граничные случаи, но зачастую это не существенно(ибо особенность языка) либо кривые руки). В случае структурированных данных это JSON-схема например.
PS по поводу node.js много не скажу, но очень привлекательно выглядит схема front->node->API, т.к серьёзно уменьшает затраты на написание API(правильная валидация и обработка ошибок это крайне важно для АПИ)
Как модуль-прослойка между бэкэндом и «основным» кодом — вполне. И этого будет не видно в REST, это чисто бэкэндовая фича(у меня например на стороне клиента есть одна глобальная функция которая посылает данные, она же — обрабатывает глобальные ошибки. Но можно написать свою спеку, и обрабатывать стандартизированные ошибки в этом методе). Запрос пойдёт по REST-правилам, просто провалидируется перед тем как выполниться.
Да и на JS правильно организованная валидация данных — не проблема(конечно, БЫВАЮТ граничные случаи, но зачастую это не существенно(ибо особенность языка) либо кривые руки). В случае структурированных данных это JSON-схема например.
PS по поводу node.js много не скажу, но очень привлекательно выглядит схема front->node->API, т.к серьёзно уменьшает затраты на написание API(правильная валидация и обработка ошибок это крайне важно для АПИ)
на сервере MVC может быть только если у нас пользовательский интерфейс полностью реализован на сервере, т.е. нет браузерного кода, интерфейс генерируется на сервере, а браузер просто показывает его.V будет, но мнимая. Должен же кто-то словари и массивы отрисовать в JSON ;)
Я много лет ждал этой статьи. Огромное спасибо. Все стало на свои места!
Состояние в БД гораздо надежнее и нагляднее в разработке. Если оно только там — жить проще и спать лучше.
Stateless в вебе нужно хотя бы чтобы работали ссылки. И как следствие — закладки, «открыть в новой вкладке», поисковики, возможность отправить ссылку по скайпу. Отказаться от всего этого можно только для какого-нибудь бекенд-приложения, и то неясно зачем.
И я бы зассал держать что-либо важное в памяти node.js.
Stateless в вебе нужно хотя бы чтобы работали ссылки. И как следствие — закладки, «открыть в новой вкладке», поисковики, возможность отправить ссылку по скайпу. Отказаться от всего этого можно только для какого-нибудь бекенд-приложения, и то неясно зачем.
И я бы зассал держать что-либо важное в памяти node.js.
А кто говорит, что нужно без базы работать, нужно исходить из того, что любой сервер может в любой момент сгореть, поэтому все состояния должны восстановиться в память других серверов, куда сессии будут раскиданы после падения.
Если с базой (в любом понимании — SQL/no-SQL) — то непонятно что значит «stateless».
У меня вот достается из БД и кладется в кэш весьма хитрая структура для каждого пользователя, с кучей всяких хешей и деревьев. Но ее в любой момент можно достать заново совершенно прозрачно. Это stateful или stateless?
У меня вот достается из БД и кладется в кэш весьма хитрая структура для каждого пользователя, с кучей всяких хешей и деревьев. Но ее в любой момент можно достать заново совершенно прозрачно. Это stateful или stateless?
Если кеш в отдельном процессе (например, memcached), а процесс обработки HTTP запроса создает и уничтожает структуры данных каждый раз при получении нового HTTP запроса, то это stateless. А если модель развертывается в нативных структурах языка и сохраняется между запросами в серверном процессе, то у вас stateful, мои искренние поздравления.
а если некоторое количество информации, требующейся с каждым запросом(авторизационные данные и некоторые не-касающиеся пользователя данные), необходимые для работы с апи находятся у клиента в куках — это stateful? А если в куках только идентификатор сессии будет находится, но данные будут получаться раз и до конца сессии лежать на сервере?
PS если чего, то сайт можно назвать «веб-приложением».
PS если чего, то сайт можно назвать «веб-приложением».
Не имеет значения, по-моему, в каком процессе разворачиваются данные. Главное являются ли они кэшем, сохраненных в хранилище данных, либо основной структурой, которая лишь дублируется в хранилище на случай рестарта.
Являются ли данные кешем адресуемых по URL ресурсов (файлов) или развернутой в структурах данных (моделью) — это важно, но в родном ли это процессе приложения или нужно каждый раз за состоянием обращаться в другой процесс и вынимать оттуда сериализованные объекты, а потом их туда сохранять — это важно не менее.
Похоже что с терминологией stateless/stateful точно такие же проблемы как с MVC и REST.
Я бы не лез в терминологию. Если прикладной код написан так, что:
— приложение не лажает на кнопах back и refresh
— оно нормально живет с несколькими параллельно открытыми одним юзером вкладками
— оно переживает открытие ссылки в новом окне
— таймаут сессии не имеет серьезных последствий для пользователя
— можно ссылку из адресной строки передать по скайпу коллеге, и он увидит примерно тоже что и ты. Можно на любую страницу поставить закладку
— нигде кэш не залипает
— то это годно написанный код. Одна из методик сделать чтобы оно так было — держать весь стейт максимально явно, в той же БД, а всякие кэши строить как-то так, чтобы прикладной код не видел разницы с чем он работает.
Я бы не лез в терминологию. Если прикладной код написан так, что:
— приложение не лажает на кнопах back и refresh
— оно нормально живет с несколькими параллельно открытыми одним юзером вкладками
— оно переживает открытие ссылки в новом окне
— таймаут сессии не имеет серьезных последствий для пользователя
— можно ссылку из адресной строки передать по скайпу коллеге, и он увидит примерно тоже что и ты. Можно на любую страницу поставить закладку
— нигде кэш не залипает
— то это годно написанный код. Одна из методик сделать чтобы оно так было — держать весь стейт максимально явно, в той же БД, а всякие кэши строить как-то так, чтобы прикладной код не видел разницы с чем он работает.
Чертовски с вами согласен. Данные — в базе (базах), сессии — в Redis, какая-то часть контента и данных — в кэше.
Вопрос, где тут граница между stateless и stateful — ведь все состояние во внешних процессах. В самом «веб-приложении» нет никакого состояния, и, возможно, и не нужно. Как минимум, не стоит говорить, что «stateful лучше stateless». Чем лучше то?
Вопрос, где тут граница между stateless и stateful — ведь все состояние во внешних процессах. В самом «веб-приложении» нет никакого состояния, и, возможно, и не нужно. Как минимум, не стоит говорить, что «stateful лучше stateless». Чем лучше то?
stateless означает, что не делается предположений о состоянии сессии, все изменения атомарны, нет каких-то сессионных переменных на сервере, помнящих результат предыдущего запроса. Обычный пример: «многоэкранные» формы — в stateless нужно либо заводить ресурсы типа /customer/:id/form_step1, либо на каждом шаге передавать (и возвращать) все введённые ранее данные (хидден полями например).
Да ну такая информация вполне может быть — просто сессионные данные обычно в базе или в Redis-е хранятся. Само веб-приложение то в этом случае stateless.
Нет, приложение становится statefull для клиента — чтобы восстановить состояние нужно сделать несколько запросов. Хранит данные сессии в базе, редисе, в файлах или в своей памяти — не суть. Самое частое нарушение stateless в вебе — аутентификация, когда аутентификационные данные не передаются при каждом запросе, а передаётся лишь идентификатор сессии, полученный в процессе аутентификации. По хорошему это должны быть заголовки http, поля с логином и паролем или зашифрованные куки. Именно зашифрованные логин/пароль, не хэши, полученные с сервера.
Аутентификация с токеном сессии в куки — это что-то типа кэширования. Вроде и стейт, но иначе непонятно как. Если оно правильно сделано — то все ок. Другое дело если ты пошел покушать, сессия отлетела, и тебя куда-то там выкидывает.
В принципе понятно — http authentication, — но неудобно, некрасиво, есть бреши в секурности, и т. п., в связи с чем начинают делать стэйт в сессии. А сделав его возникает соблазн ещё что-то в сессию занести. И ладно когда используется просто как кеш, чтобы, например, не дергать базу дабы вытащить юзернейм по юзерайди, но часто начинают использовать сессию именно как временное хранилище каких-то данных, в других местах несуществующее, вводят ещё больше стэйта кроме как юзерайди.
Когда уже мы перестанем говорить, что А лучше Б, доказывать, что это серебряная пуля, махать флагом и зазывать всех применять только это решение? В программировании нет универсального подхода. Паттерны, методики, фреймворки — это лишь сборники советов. Но как и где их применять — зависит от задачи. Имею опыт применения STATEful подхода. И были проекты, где такой подход был выбран неоправданно и доставил кучу проблем. Были и уместные случаи использования. Аналогичный опыт использования STATEless. Давайте все же более глубоко и широко анализировать задачу и на основании этого анализа принимать решение об используемом подходе.
Согласен с автором по поводу разночтений терминологии. Это касается не только REST'а и MVC, но и вообще многих определений и подходов. Это общая проблема.
Так же согласен насчет модели. Вообще, у меня при проектировании общий подход такой: при создании каждого слоя надо задавать вопросы — какая цель существования этого слоя? что он знает? что он умеет? кого он использует? кто его использует? И между этими вопросами не должно быть противоречий.
В целом, понимаю, что скорее всего, статья была призвана «поднять» авторитет STATEful подхода, но в итоге получилась слишком холиварной.
Согласен с автором по поводу разночтений терминологии. Это касается не только REST'а и MVC, но и вообще многих определений и подходов. Это общая проблема.
Так же согласен насчет модели. Вообще, у меня при проектировании общий подход такой: при создании каждого слоя надо задавать вопросы — какая цель существования этого слоя? что он знает? что он умеет? кого он использует? кто его использует? И между этими вопросами не должно быть противоречий.
В целом, понимаю, что скорее всего, статья была призвана «поднять» авторитет STATEful подхода, но в итоге получилась слишком холиварной.
Так что, уберите слово REST, вводящее в заблуждение, делайте API и все.
методы CRUD не могут быть частью модели объекта реального мира, потому, что ни один реальный объект не умеет себя создавать или удалять
Почему же вы по отношению к API допускаете широкое его применение, а у моделей не допускаете ничего лишнего? Ваш подход к моделям в таком случае мало чем отличается от подхода REST к API, разве нет?
Проводить аналогии с реальными объектами вселенной это хорошо — так проще для понимания, но почему вы не можете допустить, что модель (представляющая из себя реальную запись в БД) не может сама себя сохранять, удалять, изменять? Если это удобно и позволяет инкапсулировать процесс взаимодействия с БД, то почему этого не должно быть с вашей точки зрения?
почему вы не можете допустить, что модель (представляющая из себя реальную запись в БД) не может сама себя сохранять, удалять, изменять?
Ну так объяснили же — потому, что модель — это некий объект, сохраняющий интересующие свойства оригинала (и игнорирующий остальные). Про дополнительные свойства — по сравнению с оригиналом — в определении ничего не сказано. Если они есть — способность сохранять себя, например — это уже может быть не модель по определению слова «модель». Вопрос в терминах, о чём и говорится в статье.
Способность модели сохранять себя противоестественна. Если так хотите, способность сохранять что-то — это свойство контейнера. То есть, можно взять базу данных в качестве модели этого контейнера. Именно у этой модели, то есть, у базы данных должны быть по логике методы сохранения объектов.
Добавлю еще, что в сложном приложении логика сохранения данных может быть довольно сложной, чтобы полагаться только на сохранение каждой модели.
Если это удобно и позволяет инкапсулировать процесс взаимодействия с БД, то почему этого не должно быть с вашей точки зрения?
Это означает появлении у объектов моделей двух ответственностей: моделирование предметной области и управление персистентностью данных модели. Причём популярные библотеки/фреймворки/паттерны типа ActiveRecord как раз не инкапсулируют персистентность — методы типа save() вызываются извне. Если персистентность будет полностью инкапсулирована от клиентов (других объектов модели, контроллеров, вьюх) и разработчиков бизнес-логики самой модели (скажем, путем наследования или примесей), то ещё куда ни шло, но что-то такие реализации редко встречаются.
Причём популярные библотеки/фреймворки/паттерны типа ActiveRecord как раз не инкапсулируют персистентность — методы типа save() вызываются извне.
Простите, а откуда «извне» у AR?
@post = Post.new(title: 'whatever', text: 'whatever')
@post.save!
Это же действия из контроллера? Для модели они извне. Вот если бы ваша либа обеспечивала сохранение поста без save, в new и при каждом изменении, тогда бы она инкапсулировала персистентность. А так контроллер должен знать, что модель сохранится только если дернуть её метод save — персистентность не инкапсулирована.
Таким подходом нарушается принцип единственной обязанности. Помимо этого получаются очень грустные зависимости, например, «пользователь» зависит от базы данных. А что ещё хуже объект уже зависим от некоторого абстрактного хранилища («жадность» налицо), а ведь значительно лучше когда объект зависит только от того, что он использует, а за сохранение\загрузку\удаление из абстрактного хранилища отвечает само это хранилище.
весь смысл REST в том, что он оперирует файлами, каждый из которых имеет свой уникальный URL и над этим файлом можно производить только HTTP методы: GET, PUT, POST, DELETE
Откуда такое понимание? Для начала REST может быть вообще без HTTP, а если поверх HTTP, то действия не ограничены HTTP-методами.
А можно ваше определение REST, пожалуйста?
открытый сокет на котором висит RPC-сервер, читающий XML по своему какому-то протоколу.
Все же RPC является антиподом REST, что кстати отражено в вики.
Ага, слажал я с формулировкой. Не RPC, а неважно какой сервер, но тот, который просто читает из этого порта и работает с XML. Важно, что не знающий о HTTP.
все же чаще под REST в прикладном смысле понимается именно HTTP доступ по определенным правилам, обычно описываемым или отрабатываемым рутером вебовского приложения. С терминологиями действительно существует некоторый люфт. Из-за флюктуаций при реализации в «железе» теоретических обоснований. Поэтому автор прав — надо в команде четко определяться с терминологией. Вернее с ее однозначным пониманием разными членами команды.
Ну не определение, а понимание:
— данные существуют в виде ресурсов, однозначно идентифицируемых в запросах (в частности в идентификации могут участвовать куки и подобные механизмы)
— получение, изменение и т. п. данных осуществляется с помощью атомарных действий над ними, также передаваемых в запросе
— если не было изменений данных между двумя запросами на получение, то результаты одинаковых запросов строго одинаковы (что, в частности, позволяет использовать кэширование)
— данные существуют в виде ресурсов, однозначно идентифицируемых в запросах (в частности в идентификации могут участвовать куки и подобные механизмы)
— получение, изменение и т. п. данных осуществляется с помощью атомарных действий над ними, также передаваемых в запросе
— если не было изменений данных между двумя запросами на получение, то результаты одинаковых запросов строго одинаковы (что, в частности, позволяет использовать кэширование)
НЛО прилетело и опубликовало эту надпись здесь
Спасибо. Это же самое и в википедии написано. Из этого определения видно, что в первую очередь — всё-таки Web, т.е. HTTP. (Ещё одно ключевое слово — hypermedia — это «гипертекст со свистелками и перделками» — это тоже этой же оперы, хотя напрямую от HTTP не зависит, может быть и локальный гипермедиа html-файлик со включенными картинками.)
Поэтому, собственно, я и попросил определение, что «официальное» всё-таки завязывается на Web, а комментарий был «для начала, REST может быть без HTTP».
Поэтому, собственно, я и попросил определение, что «официальное» всё-таки завязывается на Web, а комментарий был «для начала, REST может быть без HTTP».
НЛО прилетело и опубликовало эту надпись здесь
Web привык рассматривать как синоним WWW, World Wide Web, и это — именно и только HTTP.
FTP, SMTP — никакой не Web. В них нет гиперссылок, которые формировали бы «паутину». (Не понимаю, как FTP в этом обсуждении вообще появился.)
Да, я в курсе про то, что можно сделать ссылку на IRC. Где это работает? В вебе. И mailto -тоже только в вебе.
FTP, SMTP — никакой не Web. В них нет гиперссылок, которые формировали бы «паутину». (Не понимаю, как FTP в этом обсуждении вообще появился.)
Да, я в курсе про то, что можно сделать ссылку на IRC. Где это работает? В вебе. И mailto -тоже только в вебе.
Если без HTTP, то можно сказать, что REST это ограниченный набор глаголов над большим набором объектов. Но в HTTP он мапится именно на методы, так написано во всех руководствах, но из-за того, что это бред, то разработчики, конечно же, делаю так, как удобно.
HTTP сам по сути является реализацией REST. Разработчик вправе использовать его напрямую, а может разработать свой REST-протокол, поверх HTTP, привязываясь к нему лишь поскольку постольку, скажем не различая HTTP-методы, а используя в качестве идентификатора действия GET-параметр method.
Это не бред. Просто такой стиль построения API не всегда подходит, что еще раз показывает что серебряной пули не бывает. Замечательная статья по теме есть у Steve Klabnik.
А это уже совсем не REST, например, Хабр выдает по адресу habrahabr.ru/tracker/ разный список для каждого из нас и такое повсеместно
Не понял примера, habrahabr.ru/tracker/ — это просто запрос страницы с сервера. Причем тут RPC или REST? Вы имели в виду, что идентификатор пользователя отсутствует в URI запросе? Строго говоря, он не обязан там быть, он может быть и в сессии и в параметрах.
STATEful — это великолепная возможность писать быстрые приложения, и даже не из-за того, что Event Loop фреймворки предполагают неблокирующий ввод/вывод, а из-за правильного использования памяти. Большинство операций ввода-вывода не нужно даже делать в во время обработки запросов, чтение можно делать упреждающими и параллельным, а запись ленивой (lazy). Разворачивайте данные в память приложения, стройте хеши, объекты, массивы, которые проживут долгую и счастливую жизнь в STATEful процессе.
Звучит замечательно, но возникают вопросы насчет согласованности данных между разными экземплярами приложения. Вы могли бы привезти пример? Не получится ли, что первый экземпляр должен предупреждать второй (через «ZeroMQ (и другие MQ), TCP, HTTP, IPC и еще что-угодно».) о необходимости перечитать таблицу Users?
1. URL /tracker не идентифицирует определенный ресурс, по одному урлу каждый получает совершенно разный ресурс.
2. Если нужно, например, удалить пользователя, то нужно удалить его из БД и разослать по ZMQ событие об удалении при помощи паттерна pub/sub, т.е. все подписанные на это событие процессы его поймают и удалят соответствующего пользователя из структур памяти.
2. Если нужно, например, удалить пользователя, то нужно удалить его из БД и разослать по ZMQ событие об удалении при помощи паттерна pub/sub, т.е. все подписанные на это событие процессы его поймают и удалят соответствующего пользователя из структур памяти.
Считайте запрос GET /tracker алиасом запроса GET /user/:id/tracker, где :id хранится в куках.
Это какой-то ужасающий REST. Для аутентификации пользователя есть специальный заголовок, к URL не имеет никакого отношения. Так у вас получается, что каждый пользователь обращается к РАЗНОМУ ресурсу. А это совершенно не правильно.
Почему неправильно, если так оно и есть? Утрируя, если я обращаюсь к /tracker, то происходит запрос типа SELECT * FROM tracker WHERE user = 'volch', а если вы, то SELECT * FROM tracker WHERE user = 'ivlis' — это разные ресурсы с точки зрения приложения, так же как, например, разные запросы /user/volch и /user/ivlis, просто id ресурса берётся не из URL.
Это реализация логики приложения уже она может быть абсолютно любой, SQL тут непричём. Смысл REST в абстракции, при реализации потокола приложение передаёт данные о пользователе единообразным образом, невависимо от сервиса. Как и данные о кеширвании, успешности операции и тп. Достаточно один раз это реализовать и использовать где угодно.
1. А «GET example.com/order/» идентифицирует (если у каждого пользователя свои заказы)?
Потому что не URLом единым. Ещё же есть заголовки, например Authorization, там так или иначе указан пользователь. И таких заголовков достаточно много. Один из смыслов REST в том, что формат запросов/ответов/ошибок унифицирован, не надо каждый раз изобретать велосипед.
Если сервер отвечает 403, значит текущему пользователю документ не доступен. Естественно для этого пользователя надо авторизовать и для разных пользователей будет выдаваться разный контент, кому-то 200 кому-то 403, что тут такого? И это некое состояние, но это состояние сервера, а не протокола. Никакой динамический контент не возможен бе сохранения какого-то состояния на сервере. Но это опять же не имеет никакого отношения к протоколу.
Вот тут посмотрите разбор REST запроса в одном из REST фрейморков. raw.github.com/wiki/basho/webmachine/images/http-headers-status-v3.png
Как уже организован бекэнд, как будет выделятся память и пр — детали реализации. Для одних REST подходит, для других нет. Например erlang'у совершенно ничего не стоит наплодить 100500 одинаковых процессов для обработки запросов, по процессу на пользователя с минимальными затратами. Абсолютно stateless.
Если сервер отвечает 403, значит текущему пользователю документ не доступен. Естественно для этого пользователя надо авторизовать и для разных пользователей будет выдаваться разный контент, кому-то 200 кому-то 403, что тут такого? И это некое состояние, но это состояние сервера, а не протокола. Никакой динамический контент не возможен бе сохранения какого-то состояния на сервере. Но это опять же не имеет никакого отношения к протоколу.
Вот тут посмотрите разбор REST запроса в одном из REST фрейморков. raw.github.com/wiki/basho/webmachine/images/http-headers-status-v3.png
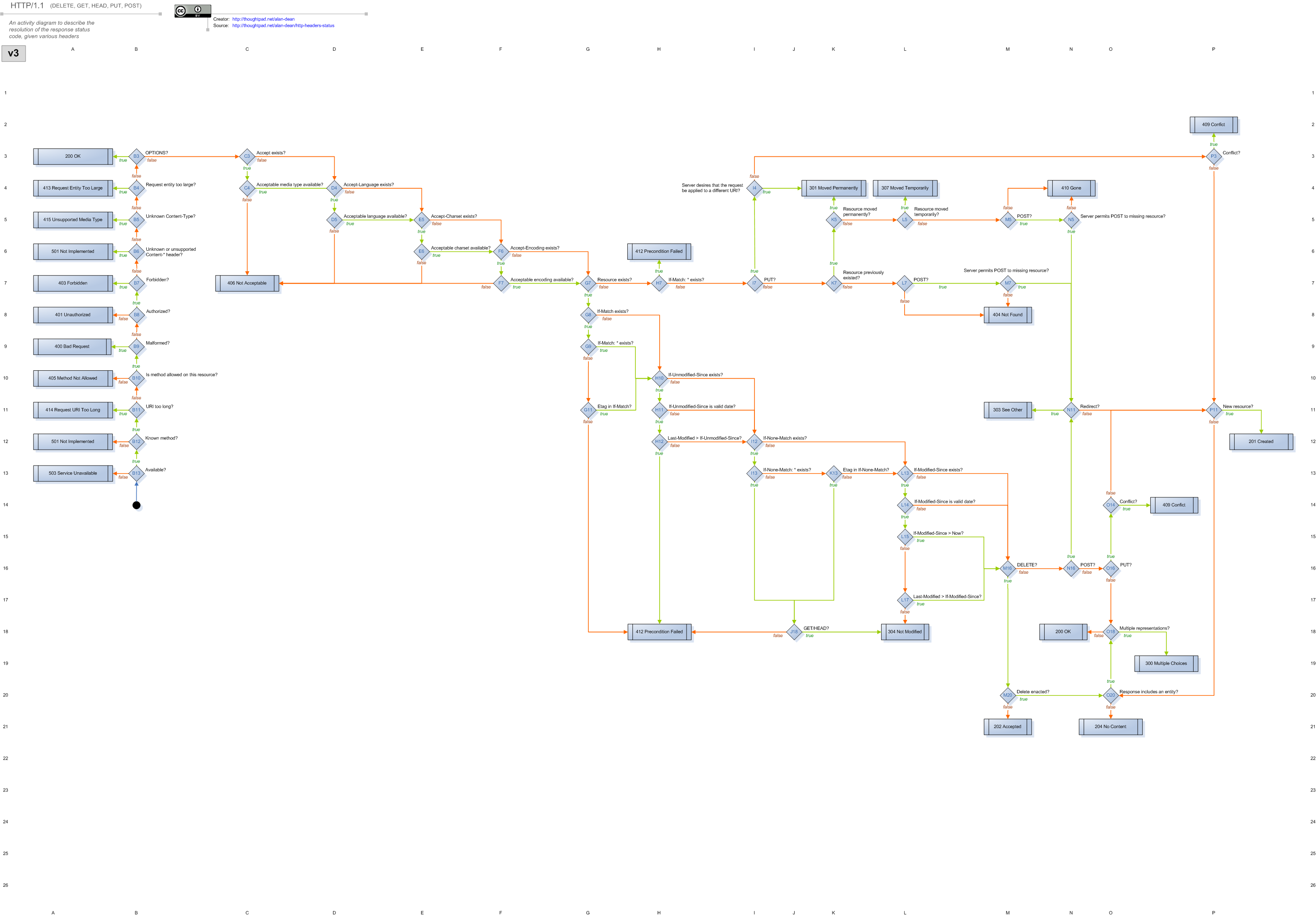{kind=link}
Как уже организован бекэнд, как будет выделятся память и пр — детали реализации. Для одних REST подходит, для других нет. Например erlang'у совершенно ничего не стоит наплодить 100500 одинаковых процессов для обработки запросов, по процессу на пользователя с минимальными затратами. Абсолютно stateless.
> только HTTP методы: GET, PUT, POST, DELETE
Не забывайте про метод PATCH. Вами описанная проблема с `setUserCity` не актуальна.
Не забывайте про метод PATCH. Вами описанная проблема с `setUserCity` не актуальна.
Stateful тяжело тестировать.
Stateless хорош тем, что для достаточно точного воспроизведения ситуации на сервере вам достаточно иметь бэкап базы и параметры запроса. В случае Stateful вам ещё дамп памяти надо будет иметь.
Представьте, что у вас приложение после 30 минут работы под нагрузкой у вас система начинает глючить. Вам надо будет всю развесистую систему логировать и т.п. Воспроизводить и вылавливать такие проблемы очень тяжело.
Stateless хорош тем, что для достаточно точного воспроизведения ситуации на сервере вам достаточно иметь бэкап базы и параметры запроса. В случае Stateful вам ещё дамп памяти надо будет иметь.
Представьте, что у вас приложение после 30 минут работы под нагрузкой у вас система начинает глючить. Вам надо будет всю развесистую систему логировать и т.п. Воспроизводить и вылавливать такие проблемы очень тяжело.
Stateful не значит, что нет базы, и все хранится только в памяти, просто модель в памяти память не разрушается между запросами, а сохранение ее в базу ленивое. Ни какого дампа иметь не нужно. Отладка Stateful такая же, как и Stateless, нужно вывести определенную часть данных в лог.
А я и не говорю, что нет базы. Я говорю, что кроме базы, вам нужно будет ещё бэкапить state.
Зачем? В жизни не бекапил стейт. Для критических операций можно делать транзакционный лог, но большинство данных, в памяти может быть утеряна и восстановлена из базы.
Зачем?
Чтобы воспроизвести проблему локально.
Продакшен начинает глючить:
Stateless way: берём бэкап базы, версию исходников, запрос из лога и смотрим что не так.
Stateful way: смотрим базу/логи/код пытаемся понять, что не так с нашим общим деревом объектов.
Зависимости рождают сложности в воспроизведении ошибок. Потому statelss, и за счёт снижения эффективности, старается сделать каждый запрос максимально независимым от других. Ну это как глобальную статическую переменную заводить: удобно всё под рукой, но через некоторое время вам уже не хватает 100 гигабайт в день, чтобы хранить логи состояния объектов.
Для каждого подхода мы должны представлять, чем придётся пожертвовать.
Скорее суть в том, что ошибка может воспроизводиться именно при определенном кеше, т.е. ошибка в формировании\поддержании состояния в памяти между запросами, а это значит, что для ее воспроизведения недостаточно знать только состояния базы и запущенного приложения — надо будет прогнать всю цепочку запросов, что бы понять какой из них привел к ошибке\нарушению состояния.
Хотя по факту, REST просто выглядит как stateless протокол для клиента. В реализации он может быть не менее statefull чем и остальные. Вообще если сравнивать stateless протокол и statefull протокол — то надо смотреть не на реализацию, а на то, как он выглядит для клиента, ведь это stateless\full именно для клиента, а не для реализации.
Хотя по факту, REST просто выглядит как stateless протокол для клиента. В реализации он может быть не менее statefull чем и остальные. Вообще если сравнивать stateless протокол и statefull протокол — то надо смотреть не на реализацию, а на то, как он выглядит для клиента, ведь это stateless\full именно для клиента, а не для реализации.
А какие плюсы дает ленивое сохранение в БД?
Как упреждающее чтение, так и ленивое сохранение позволяют исключить из времени исполнения запроса все операции ввода/вывода.
Непонятно что именно читать с упреждением, как при ленивом сохранении сказать пользователю что что-то не сохранилось из-за ошибки, и зачем сокращать время запроса.
1. Читать с упреждением: например, мы знаем, что нужно 5 раз в сутки перестроить статистический отчет, вот мы его по времени и перестраиваем, кладем в кеш, а при запросе не происходит расчетов, сразу отдается кеш из памяти.
2. Если что-то не сохранилось в ленивом режиме, то пользователь может получить об этом уведомление без рефреша страницы, для этого есть Server-Sent Event и WebSockets, на худой конец Long Pooling, которые подключились прямо в тот же процесс.
3. Время запроса сокращать нужно, чтобы пользователь не ждал.
2. Если что-то не сохранилось в ленивом режиме, то пользователь может получить об этом уведомление без рефреша страницы, для этого есть Server-Sent Event и WebSockets, на худой конец Long Pooling, которые подключились прямо в тот же процесс.
3. Время запроса сокращать нужно, чтобы пользователь не ждал.
1. Ну, раз в сутки перестроить отчет — это вполне себе классическая штука. В большинстве случаев параллельно веб-серверу крутится процесс, который всякое такое делает. Положить его сразу в кэш — тоже можно, и в каких-то специфических случаях может быть даже и нужно.
2. А если пользователь успеет закрыть приложение? И оправдана ли настолько более сложная инфраструктура — ведь мало того что нужно тащить server-side events, так надо еще как-то уметь открыть ту же форму чтобы что-то поправить, нужно как-то думать в какую вкладку посылать событие, нужно придумывать как сделать чтобы пользователю было понятно. А потом какая разница пользователю — через веб-сокет придет «ваш заказ принят», по ajax-у, или это будет ответ на обычный post-запрос?
3. Это оправдано если нет последствий для пользователя. Если от оптимизаций пользователь не видит что его заказ не сохранился, или получает не актуальные данные — я бы, как пользователь, лучше бы подождал.
2. А если пользователь успеет закрыть приложение? И оправдана ли настолько более сложная инфраструктура — ведь мало того что нужно тащить server-side events, так надо еще как-то уметь открыть ту же форму чтобы что-то поправить, нужно как-то думать в какую вкладку посылать событие, нужно придумывать как сделать чтобы пользователю было понятно. А потом какая разница пользователю — через веб-сокет придет «ваш заказ принят», по ajax-у, или это будет ответ на обычный post-запрос?
3. Это оправдано если нет последствий для пользователя. Если от оптимизаций пользователь не видит что его заказ не сохранился, или получает не актуальные данные — я бы, как пользователь, лучше бы подождал.
На закрытие окна браузера можно повесить предупреждение, но вообще, пользователь может и комп выключит, тут мы ему уже ни чем не поможем. А вот Server-Sent Events и WebSocket отличаются от AJAX тем, что по ним можно прислать событие с сервера на клиент по инициативе сервера, а не по запросу клиента.
За статью поставил плюс, хотя и не согласен с мнением автора.
Соглашусь, что хорошего программиста отличает ясность в понимании той терминологии, которую он использует, потому что за каждым словом скрывается множество нюансов.
Но Stateless подход гораздо более приемлем для нагруженных приложений, требующих масштабирования. Возможно его дольше воплощать (хотя это спорно), и отдельный компонент системы может работать немного медленнее за счет необходимости получения данных из внешнего источника (кэш, БД, другой компонент), но зато количество таких компонентов может расти линейно без потери производительности и, самое главное, надежности всей системы.
Опять же автоматизация тестирования Stateless системы гораздо тривиальнее.
Соглашусь, что хорошего программиста отличает ясность в понимании той терминологии, которую он использует, потому что за каждым словом скрывается множество нюансов.
Но Stateless подход гораздо более приемлем для нагруженных приложений, требующих масштабирования. Возможно его дольше воплощать (хотя это спорно), и отдельный компонент системы может работать немного медленнее за счет необходимости получения данных из внешнего источника (кэш, БД, другой компонент), но зато количество таких компонентов может расти линейно без потери производительности и, самое главное, надежности всей системы.
Опять же автоматизация тестирования Stateless системы гораздо тривиальнее.
А в чем преграда масштабирования Statefull системы?
Проблема привязки клиента к процессу/серверу, как минимум. Прилипание по куки или айпи это лишь часть решения. Пускай ситуация: есть 4 сервера, на каждом по сотне клиентов, работают, объём данных растёт, клиенты начинают жаловаться на тормоза. Ставим ещё один сервер, но клиенты прилипли к первым четверым — они загружены, а пятый стоит. Нужно или рвать сессию клиента (возможно с потерей данных), или предусматривать механизм миграции состояния с сервер на сервера хотя бы ручками.
Мигрировать клиентов очень просто, их сессии рвать не нужно, их можно просто перестикать к другому процессу, а их состояние на старом сервере просто убить, перемещать их на другой сервер дольше, чем восстановить состояние сессии из БД. Кстати, кроме состояний сессий, есть еще глобальное состояние и состояние хранимых объектов, доступ к которым есть у многих сессий, эти состояния синхронизируются через подписку на события (например, паттерн pub/sub из ZMQ).
Фигассе «просто» :-)
Это в случае Stateless просто, а здесь, пи#$$ц, извините.
Это надо писать балансер, который бы раскидывал нагрузку, ну или использовать готовый — по мне так это нифига не просто + куча подводных граблей.
Это в случае Stateless просто, а здесь, пи#$$ц, извините.
Это надо писать балансер, который бы раскидывал нагрузку, ну или использовать готовый — по мне так это нифига не просто + куча подводных граблей.
Т.е. есть у меня 3-х этапная огромная веб-форма. Я заполнил первый этап, второй этап, начал заполнять третий — последний, и тут… Админ решил, что неплохо бы нам отмасштабироваться, включил новый сервер и прибил мою сессию на сервере. И что мне теперь — заново форму заполнять? (В случае stateless промежуточные состояния сохраняются в hidden поле или в БД).
Если же промежуточные состояния формы не держатся в памяти а скидываются в БД то какой-же это statefull?
Если же промежуточные состояния формы не держатся в памяти а скидываются в БД то какой-же это statefull?
Можно передвигать сессии для неактивных пользователей, их всегда больше и этого админу хватит для удовлетворения.
Если у вас есть 3ех этапная форма, при заполнении которой нужно вызывать процедуры на сервере и при этом вы не закрепляете выполнение этих процедур за пользователем, а за сессией, у ваш протокол логически stateful. Естественно, если вы захотите его реализовать через stateless то у вас будут костыли.
Проверка на stateless/stateful очень проста. Если пользователь зашёл с другого компьютера, то ему надо будет форму всю заново заполнять? Если да — stateful, если нет — stateless. Ещё раз нельзя путать state протокола и state сервера, это существенные вещи.
Ещё стоит заметить, что сохранение состояния клиента это необязательно сохранение в базу данных, состояние можно хранится и памяти, например в memcached, процессе erlang'а и проч. К состоянию протокола это не имеет отношения.
Проверка на stateless/stateful очень проста. Если пользователь зашёл с другого компьютера, то ему надо будет форму всю заново заполнять? Если да — stateful, если нет — stateless. Ещё раз нельзя путать state протокола и state сервера, это существенные вещи.
Ещё стоит заметить, что сохранение состояния клиента это необязательно сохранение в базу данных, состояние можно хранится и памяти, например в memcached, процессе erlang'а и проч. К состоянию протокола это не имеет отношения.
hidden поля в случае get формы вполне себе попадают в URL. Если в первой форме будет пункт «Вам есть 18 лет», то у второй формы будет URL
Так что тут тоже как подойти…
/form/2?is_18=trueТак что тут тоже как подойти…
Если потом результат обратно возвращается пользователю и хранится у него, тогда не проще сразу всю форму ему отправить, пусть заполняет.
То что вы показали это очень плохой дизайн. Пользователю достаточно добавить в URL строчку, чтобы обойти проверку на сервере. А если оно так, то она зачем вообще.
То что вы показали это очень плохой дизайн. Пользователю достаточно добавить в URL строчку, чтобы обойти проверку на сервере. А если оно так, то она зачем вообще.
Сразу всю форму не разрешили маркетологи, т.к. «огромная форма отпугнет» например.
Второй аргумент как то неубедительно звучит.
Окончательно валидировать форму можно на последнем этапе. Не думаю, что вопрос безопасности тут уместен.
Второй аргумент как то неубедительно звучит.
Окончательно валидировать форму можно на последнем этапе. Не думаю, что вопрос безопасности тут уместен.
А js маркетологи отменили? Можно же вывести постранично форму как угодно прямо в браузере пользователя. То что вы описали, это очень-очень плохой дизайн, потому что в представление формы (от маркетологов) введено в логику протокола.
Идеальным вариантом является именно сохранения каждой части формы на сервере. Тогда и stateless и маркетологи счастливы.
Идеальным вариантом является именно сохранения каждой части формы на сервере. Тогда и stateless и маркетологи счастливы.
Совсем нет, если пользователь зашел с другого компа, то ему можно выдать тот же идентификатор сессии, и пристикать к тому же процессу, он продолжит с того же места.
А вот теперь представьте, что пользователь одновременно троллит ваш сервис с двух компов? Race condition обеспечено.
Почему?
Computer1:
Page 1 -> Page 2 -> Page 3 (нажал back)-> Page 2 (нажал submit)
Computer2:
Page 1 -> Page 2 -> Page 3 (нажал submit)-> Page?
И результат зависит от того какой запрос первый пришёл.
Потому что у вас фактически два параллельных процесса с одними и теме же переменными. То есть конечно, вы можете всё там предусмотреть, наделать кучу проверок, но зачем?
Page 1 -> Page 2 -> Page 3 (нажал back)-> Page 2 (нажал submit)
Computer2:
Page 1 -> Page 2 -> Page 3 (нажал submit)-> Page?
И результат зависит от того какой запрос первый пришёл.
Потому что у вас фактически два параллельных процесса с одними и теме же переменными. То есть конечно, вы можете всё там предусмотреть, наделать кучу проверок, но зачем?
В случаях, при открытии сессии на новом компьютере, на старый сваливается по SSE событие, закрывающее все недоделанное и выводящее сообщение о том, что сессия перешла к другому клиенту. Вот именно такой случай был при многостраничных опросах (голосованиях).
Интересно как вы обеспечите атомарность передачи сессии и отсыл этого события на компьютер пользователя?
То есть stateful не масштабируется и не атомарен. Если вас это устраивает, то почему бы и нет?
То есть stateful не масштабируется и не атомарен. Если вас это устраивает, то почему бы и нет?
Что вы подразумеваете под атомарностью передачи сессии?
Событие по SSE (понятия не имею что это такое не применительно к процессорам) пришло позже, чем пользователь нажал submit на первом компьютере.
Server-Sent Events это протокол, позволяющий передавать события с сервера на клиент по инициативе сервера, без AJAX опрашивания (пулинга), можно применять вебсокеты или лонг-пулинг. Но суть у них одна, события попадают с сервера на клиент за миллисекунды. Как только на новом компьютере пользователь вошел, то на старом он автоматически вышел (пришло событие), но даже если предположить, что за эти миллисекунды кто-то нажал сабмит, то сервер уже не признает сессию со старого компьютера, на сервере то она уже получила новый идентификатор и посты со старого будут 403 Forbidden.
Вот видите вам уже нужен двусторонний обмен данными, вместо одностороннего. Зачем усложнять, когда всё уже придумано? В REST предусмотрен ответ на такой случай 409-ый.
С оптимизацией без цифр не очень понятно, потому что вы несколько выиграли в нагрузке сервера, зато проиграли в нагрузке на сеть. Процессор то всегда можно ещё один поставить, а вот канал не всегда можно расширить.
С оптимизацией без цифр не очень понятно, потому что вы несколько выиграли в нагрузке сервера, зато проиграли в нагрузке на сеть. Процессор то всегда можно ещё один поставить, а вот канал не всегда можно расширить.
Прошу прощения, что влазию в дискуссию)
Long polling != long pooling. Второго термина вообще не существует, насколько я знаю. Long polling так называется, потому что клиент poll'ит (опрашивает) сервер на наличие эвентов, а long — потому что это длинное HTTP-соединение.
Long polling != long pooling. Второго термина вообще не существует, насколько я знаю. Long polling так называется, потому что клиент poll'ит (опрашивает) сервер на наличие эвентов, а long — потому что это длинное HTTP-соединение.
Ну и stateless rest спокойно выдаст 409 Conflict и всё.
Стоит добавить еще, что не надо путать state приложения в целом от конкретно state-а в процессе веб-сервера.
Это, как я понимаю, речь об имитации состояния протокола передачей всего «состояния» туда-сюда каждый этап? (по типу как ASP.NET WebForms делал с помощью ViewState). Если так — то да, концептуально тут stateful, но протокол от этого не перестает быть stateless, ровно как и приложение.
Если у вас есть 3ех этапная форма, при заполнении которой нужно вызывать процедуры на сервере и при этом вы не закрепляете выполнение этих процедур за пользователем, а за сессией, у ваш протокол логически stateful.
Это, как я понимаю, речь об имитации состояния протокола передачей всего «состояния» туда-сюда каждый этап? (по типу как ASP.NET WebForms делал с помощью ViewState). Если так — то да, концептуально тут stateful, но протокол от этого не перестает быть stateless, ровно как и приложение.
У вас в многопоточном многопроцессном окружении с разделённой памятью глобальные переменные? Мама-мия! Ради интереса, на чём вы пишите?
В рамках одного процесса Node.js однопоточный, а для многопоточных платформ можно делать локинг.
Но зачем делать локинг, когда его можно не делать?
В ноде его делать не нужно, и это очень удобно, не сессионное состояние, разделяемое между тысячами пользователей, например, статистика и агрегации, очень сокращают объем используемой памяти.
А чего будет, если это состояние поменяется в процесс обработки запроса? Для многопоточной системы это же катастрофа.
Для Node.js это не грозит, а на других платформах можно использовать модель акторов, событийный доступ к общем объектам или локинг.
Акторы это самый рафинированый stateless — родился, обработал, умер. Никакого состояния.
Совсем не обязательно, акторы — это модель параллельных вычислений с доступом к общим данным, но без блокирования. Связи с stateless нет ни какой, актор может жить хоть полгода.
У акторов нет общих данных. Это, в общем-то, ключевой момент этой парадигмы. Но связи со stateless действительно нет никакой — у самих акторов вполне себе может быть состояние.
Я имею в виду, что актор может держать глобальное состояние для системы в своих личных данных, к нему обращаются во время обработки HTTP-запросов из нескольких потоков, чтобы исключить параллельное изменение глобального состояния. Эту задачу же можно решить и с помощью локинга. А в Node.js ее вообще нет, потому, что там один поток, а в режиме кластера — много процессов, но у каждого своя отдельная память (как у акторов).
Нода однопоточная же. И суть поста же в том что PHP-шникам дали живущие дольше чем запрос переменные, и они вот рвут шаблоны отцам тут.
Это какие долгоживущие переменные? Сессии? Они на любом языке реализуются.
Нет, не сессии, а структуры данных, остающиеся постоянно в памяти, не разрушающиеся после обработки HTTP-запроса и доступные из каждого следующего потока обработки для новых и новых HTTP-запросов. Как я уже говорил, Node.js запускается в несколько процессов, у каждого своя отдельная копия этих данных в памяти. В рамках одного процесса приложение однопоточное, но без блокирующих операций, т.е. реализовано асинхронное программирование (можно обрабатывать тысячи запросов параллельно без многопоточности в одном процессе). На PHP тоже можно так написать, открыть серверный сокет, сделать event loop, но только нельзя использовать блокирующих операций (чтение диска и БД), ограничившись только работой с памятью. Будет тоже приложение с глобальным состоянием.
Думаю, следует различать внутреннее состояние приложения (не оказывающее влияния на результаты запросов — кэши, дескрипторы ресурсов, какие-то глобальные данные и т. п.) и внешнее (оказывающее влияние на результаты запросов, например, данные и/или результаты предыдущих запросов, но недоступное клиенту).
Это точно, я в статью апдейт сделал, потому, что уже три состояния насчитали: состояние процесса обработки HTTP-запросов, состояние всех серверных процессов (включая процессы специализированных серверов состояний, редис, мемкеш), состояние всей системы в целом (включая БД, а многие БД имеют кеш в памяти, не хуже, чем мемкеш). А состояние еще можно делить на состояние сессий, состояние объектов данных, глобальное состояние системы.
Такие что можно var x = 1005005 написать и менять в запросах. В любом языке такое всегда можно было. Но в PHP — нельзя. Потому что PHP — он вообще изначально процесс на запрос делал. Потому в посте за CGI даже есть ответвление. Хотя CGI никого кроме PHP и может быть перла не парит вообще.
И тут чуваку дали ноду, а в ноде — делай что хочешь. Заводи глобальный стейт и меняй в колбеках, в случае пожара ссы в молоко. Но люди ведь такого наелись еще 10 лет назад, и детей своих уже за такое бьют по рукам.
Кстати, публика на хабре на удивление культурная. Вот этот мой коммент — наверное даже предел того что можно тут писать без бана. Удивительно что пост антинаучен во второй части, и никто никого не линчевал еще.
И тут чуваку дали ноду, а в ноде — делай что хочешь. Заводи глобальный стейт и меняй в колбеках, в случае пожара ссы в молоко. Но люди ведь такого наелись еще 10 лет назад, и детей своих уже за такое бьют по рукам.
Кстати, публика на хабре на удивление культурная. Вот этот мой коммент — наверное даже предел того что можно тут писать без бана. Удивительно что пост антинаучен во второй части, и никто никого не линчевал еще.
Все языки, которые поддерживают stdin/stdout использовали CGI для подключения к веб-серверам (Apache, IIS и др) до появления FastCGI, не нужно обижать PHP-шников, и C# и Java и Python тоже использовали и кое-где еще используют CGI.
В любом языке такое всегда можно было.
Только если писать свой сервер. А по умолчанию для всех, тот самый процесс на запрос по CGI, хоть на ассемблере, лишь бы писал в stdout и читал из ENV.
Примерно в том же в чём преграда для портирования программы на C полной глобальных переменных на многопоточное окружение. Statefull означает, что у вас квант разделения как минимум несколько запросов. Если выполнение этих запросов намного быстрее выгрузки/сохранения в базу, то statefull имеет смысл. Иначе нет.
За последние пару лет я пришел к выводу, что указание в требованиях к вакансиях «понимание MVC» по большому счету — пустое место. Мало того, что каждый понимает его так, как вздумается, так еще и и далеко не факт что оно там вообще к месту.
Автору большое спасибо. Я сам планировал написать, что то подобное но всё руки не доходили. Именно эти вопросы так часто вызывали споры на работах и увы когда я, что то говорил не «по книге» или не словами «того крутого чувака» то смотрели аля «ты что дурак?».
Самое важное смотреть как лучше реализовать ту или иную задачу и не зацикливаться на терминах.
Самое важное смотреть как лучше реализовать ту или иную задачу и не зацикливаться на терминах.
stateLESS, statFUL… Полностью согласен с автором.
Уберите куки, сессии, хранилища, уберите из базы профили пользователей (чего ещё забыл?) — вот тогда у вас stateLESS. Во всех остальных случаях, если есть хоть один способ хранения состояния пользователя — у вас stateFUL. Жуткий, урезанный, ограниченный, эдакий stateHALF, но с хранением состояния. Так что не врите себе и другим, поддёргивая профиль пользователя из базы и читая его куку, что у вас stateLESS-подход. Просто используемая технология не поддерживает состояния и вам приходится хоть как-то (куки, хранилища, etc) этот недостаток восполнить. А если вы его пытаетесь восполнить — значит, вам нужен stateFUL-подход.
И не нужно говорить, что речь не о проекте в целом, а о его серверной (клиентской, БД, etc, да хоть M / V / C и иже с ымями) части. Разницы нет абсолютно. Вы храните состояние пользователя, так или иначе. Так просто делайте это полноценно, только и делов. И не врите. В первую очередь себе.
Уберите куки, сессии, хранилища, уберите из базы профили пользователей (чего ещё забыл?) — вот тогда у вас stateLESS. Во всех остальных случаях, если есть хоть один способ хранения состояния пользователя — у вас stateFUL. Жуткий, урезанный, ограниченный, эдакий stateHALF, но с хранением состояния. Так что не врите себе и другим, поддёргивая профиль пользователя из базы и читая его куку, что у вас stateLESS-подход. Просто используемая технология не поддерживает состояния и вам приходится хоть как-то (куки, хранилища, etc) этот недостаток восполнить. А если вы его пытаетесь восполнить — значит, вам нужен stateFUL-подход.
И не нужно говорить, что речь не о проекте в целом, а о его серверной (клиентской, БД, etc, да хоть M / V / C и иже с ымями) части. Разницы нет абсолютно. Вы храните состояние пользователя, так или иначе. Так просто делайте это полноценно, только и делов. И не врите. В первую очередь себе.
То есть любая система где есть логин/пароль может быть реализована только через stateful. Во, а мужики то не знают…
en.wikipedia.org/wiki/Stateless_protocol
en.wikipedia.org/wiki/Stateless_protocol
Гыгггыг. А если жить вегетарианцем, то только в каменном веке?
Я говорю не о том, что это должно быть stateFUL. Я говорю о том, что любой stateLESS с хранением состояния не есть stateLESS. Следовательно, зачем городить себе палки в колёса и стоически преодолевать проблемы технологии? А если там кроме логина/пароля и нет ничего, и оно не сильно-то и надо, то зачем оно нам вообще? Уберите и не парьтесь.
Я говорю не о том, что это должно быть stateFUL. Я говорю о том, что любой stateLESS с хранением состояния не есть stateLESS. Следовательно, зачем городить себе палки в колёса и стоически преодолевать проблемы технологии? А если там кроме логина/пароля и нет ничего, и оно не сильно-то и надо, то зачем оно нам вообще? Уберите и не парьтесь.
Состояние чего?
Представьте, что мы предоставляем сервис хранения целого числа. Протокол реализован следующим образом:
псевдо HTTP
запрос:
ответ:
запрос:
ответ:
Это что stateful по вашему да?
Представьте, что мы предоставляем сервис хранения целого числа. Протокол реализован следующим образом:
псевдо HTTP
запрос:
PUT /int
Authorization: haxk0r:super
1337
ответ:
204 No Content
запрос:
GET /int
ответ:
200 FOUND
Content-Length: 4
1337
Это что stateful по вашему да?
Состояние чего?
Пользователя. Аутентификация, история посещения/покупок, etc…
Это что stateful по вашему да?
Та я не о тоооомм… Веб за двадцать пять лет сильно изменился. Если тогда были тупо текстовые файлики, то сейчас у нас сплошь и рядом идентификация и интеграция. Если тогда было пофик, кто читает, то сейчас мы хотим знать точно, тот же это, который запросил, или уже сфальсифицированный, как минимум с позиции безопасности, не говоря уж об увеличении продаж методом «с этим обычно покупают...». И если на ненагруженных проектах состояние пользователя порою рациональнее хранить в каких-либо сессиях, либо не хранить вообще, то на высоких нагрузках имеет смысл как-то себе жизнь всё-таки упростить. Я за разумный подход.
А с этими терминологиями столько копий переломано впустую, какая нафик разница, как это называется? Важно лишь, что именно оно делает и как помогает. И помогает ли вообще. Ниже хорошо написали.
А с этими терминологиями столько копий переломано впустую, какая нафик разница, как это называется? Важно лишь, что именно оно делает и как помогает. И помогает ли вообще. Ниже хорошо написали.
Терминология не важна в рамках одного проекта. В смысле, достаточно договориться внутри для себя, какое слово что означает — и поехали.
Но как только понадобилось взаимодействовать, хотя бы в форме «использовать такой-то фреймворк» — сразу же нужно устанавливать соответствие между своими терминами и терминами в понимании разработчиков этого фреймворка. А ещё один задействуете — ещё одно соответствие. Просто чтобы говорить об одном и том же, а то окажется например, что у вас под слоем view понимается класс, который строит http-ответ, а у них — шаблон, который используется в таком классе. Сказали тебе название — а вот непонятно,
что именно оно делает и как помогает, и помогает ли вообще
Все эти соответствия напрягают, особенно, когда терминов и библиотек много. Возникает путаница. Чтобы её не было, наоборот, заранее договариваются о терминах все в целом, а не каждый в своём маленьком мирочке одного проекта. И тогда никаких соответствий не потребуется, view с вашей точки зрения будет view с точки зрения того парня. Вот только в этом случае, в случае чёткого соблюдения терминологии, и может быть понятно
что именно оно делает и как помогает. И помогает ли вообще
Это как выбор системы единиц. Есть система единиц «СИ», которую понимают все. Поживите с милями, футами, и температурой в градусах Фаренгейта — почуствуете, как это. Да, в отдельных случаях она неудобна и не используется, например, в физике высоких энергий — но это случай отдельный и в общем с повседневностью не пересекающийся. В программировании тоже термины в системной разработке и разработке драйверов отличаются от терминов в веб-дизайне. Но они опять же — общепризнанные.
А ниже написали вообще про другое — про то, что для каждой задачи свой инструмент, а не про то, что якобы неважно, как называется этот инструмент.
Ну вы хоть вики почитайте просто stateful потокол…
Ежу понятно, что в самом общем, любая система, где есть возможность изменения состояния — stateful-система, ведь состояние надо же где-то держать.
Но давайте не будем передергивать и ограничим контекст процессом веб-сервера, принимающего запросы пользователей (ну и сам протокол в придачу, который stateless by design). Вот тут речь о том и идет — хранить все в памяти или нет. Это напрямую влияет на то, к какому серверу наш пользователь должен обращаться «при последующем запросе».
Но давайте не будем передергивать и ограничим контекст процессом веб-сервера, принимающего запросы пользователей (ну и сам протокол в придачу, который stateless by design). Вот тут речь о том и идет — хранить все в памяти или нет. Это напрямую влияет на то, к какому серверу наш пользователь должен обращаться «при последующем запросе».
Чувак, правильная и годная часть заметки сверху — она про то что термины MVC и REST никуда не годны. Потому что если разные люди понимают термин по-разному, то термин нужно просто выбросить. Глупо под этой статьей устраивать срач за термины, даже если сам автор статьи этот срач затеял во второй части статьи.
Вся лента комментариев — лучшее доказательство терминологической катастрофы. В такой ситуации лучше выбрасывать старые, испачканные термины и договариваться про новые, но делая уже строгие словарные определения. Иначе, вообще не о чем говорить.
:facepalm: катастрофа в том, что вы не можете отличиать состояние протокола от состояния сервера. Если вы работаете через HTTP то у вас уже stateless протокол, какие бы вы костыли туда не вставили типа sessionid и прочие, от этого stateful он никогда не станет. Хотите stateful протокол? Возьмите любой ssh, telnet, вот там будет state-ов куча. Только не надо мучать HTTP.
Или даже свой протокол сделайте и через websocket его прокиньте. То что HTTP будет выступать транспортным уровнем вашего протокола не превратит его в statful.
Или даже свой протокол сделайте и через websocket его прокиньте. То что HTTP будет выступать транспортным уровнем вашего протокола не превратит его в statful.
о, наконец-то словами выразили мысль, которая постоянно вертелась в виде туманных ощущений «что-то тут не так»
Верно, ведь и ip — протокол без состояния, а вот tcp — уже с состоянием — но этот факт сам по себе не делает ip протоколом с состоянием. Просто ip лежит уровнем ниже, а tcp использует его и добавляет свои фокусы. Есть и собрат tcp по уровню поверх ip — udp — который не имеет состояния. То есть, всё возможно. Можно и наоборот поверх протокола с состоянием построить протокол без состояния, если возможность протокола держать состояние не использовать.
Сделать через HTTP что-то с состоянием можно, если передавать в каждом запросе контекст. В этом случае протокол сам по себе остаётся без состояния (ему же каждый раз приходится напоминать!) а вот приложение поверх него получается с состоянием. Если бы сам протокол был с состоянием, не нужны были бы например куки.
Верно, ведь и ip — протокол без состояния, а вот tcp — уже с состоянием — но этот факт сам по себе не делает ip протоколом с состоянием. Просто ip лежит уровнем ниже, а tcp использует его и добавляет свои фокусы. Есть и собрат tcp по уровню поверх ip — udp — который не имеет состояния. То есть, всё возможно. Можно и наоборот поверх протокола с состоянием построить протокол без состояния, если возможность протокола держать состояние не использовать.
Сделать через HTTP что-то с состоянием можно, если передавать в каждом запросе контекст. В этом случае протокол сам по себе остаётся без состояния (ему же каждый раз приходится напоминать!) а вот приложение поверх него получается с состоянием. Если бы сам протокол был с состоянием, не нужны были бы например куки.
К сожалению, веб развивается намного быстрее академической науки, точнее даже так, развивающие веб во многом не в курсе теоретических основ того, чем собственно они занимаются. «Быстро и на коленке» — вот фактически девиз веба конца 2000ых, так появился всякий ад типа <?php $a=get_from_sql(«SELECT a FROM $table_name»); ?><?$a+1?>. Только когда это стало совершенно нереально поддерживать и гонять под высокими нагрузками народ понял, что «что-то пошло не так». Пример конечно утрированный, но некоторые современные костыли ничем не лучше.
И тут выделелось два пути, интенсивный — ну что, php работает плохо, ну не переписывать же это дерьмо, давайте напишем транслятор в C или лучше сразу в машинный код и всё будет круто. Ну или сделаем всё на JS/C#/Java/%langname%, это же модно, значит будет быстро. И экстенсивный, где люди всё же вспомнили, что веб создавался как клиент-сервеное приложение, что можно вообще передать всю страницу клиенту статически и разущенная на клиенте JS программа будет общаться по REST протоколу с сервером и выводить уже нужную информацию пользователю.
Вот как-то так :)
И тут выделелось два пути, интенсивный — ну что, php работает плохо, ну не переписывать же это дерьмо, давайте напишем транслятор в C или лучше сразу в машинный код и всё будет круто. Ну или сделаем всё на JS/C#/Java/%langname%, это же модно, значит будет быстро. И экстенсивный, где люди всё же вспомнили, что веб создавался как клиент-сервеное приложение, что можно вообще передать всю страницу клиенту статически и разущенная на клиенте JS программа будет общаться по REST протоколу с сервером и выводить уже нужную информацию пользователю.
Вот как-то так :)
Одно дело состояние протокола, а другое дело состояние сервера. Через протокол без состояния можно работать с сервером, имеющим состояние.
Тогда и в этой статье стоит строго прописать, что и под чем подразумевается. А то вот так читаешь, думаешь об одном. А потом в комментариях оказывается, что говорят тут совсем о другом.
Мы говорим о безграмотности начинающих разработчиков, но при этом забываем, что матерые дядьки порой тоже договориться не могут.
Мы говорим о безграмотности начинающих разработчиков, но при этом забываем, что матерые дядьки порой тоже договориться не могут.
Вообще не могут ) Все читали разные книжки, варились в своих коллективах, привыкли к словам и все.
Ещё один источник непонимания: общей абстракцией называть конкретную её реализацию. Так, например, многие под «ActiveRecord» имеют в виду исключительно любимую библиотеку на любимом языке. Вплоть до статей «сравнение производительности AR и DAO» без упоминания фреймворка и вскользь упомянутым языком. Но это ещё нормально, называть частное общим. Некоторые, под DataMapper понимают исключительно одноименную библиотеку, реализующую паттерн ActiveRecord. А некоторые вообще не считают ORM неуниверсальный набор классов, схема БД в котором захардкожена, все запросы пишутся ручками, и при изменении схемы нужно менять код (на двух языках минимум), а не пару строчек в конфиге или вообще ничего (классы сами подтянут схему при коннекте).
Кука куке рознь в этом отношении. Если кука хранит ид временной сессии на сервере, где хранится ид пользователя, то это явно стэйтфулл. Если же она хранит зашифрованный ид пользователя, то это стэйтлесс.
Кука — просто механизм хранения и передачи состояния, сам процесс веб-приложения на сервере для работы с этой кукой не обязан хранить состояние в себе. Суть не в том, хранит ли кука какие-то данные или только ссылку на «состояние», а в том где это «состояние» находится фактически.
Суть как раз в том хранит кука (или ещё какой заголовок) данные, достаточные для полноценного запроса, или какие-то ссылки на какое-то объекты, хранящиеся на сервере, но явно клиенту недоступные. Одно дело, когда сервер даёт клиенту куку, о смысле которой он не знает ничего, кроме того, что должен каждый раз её серверу давать, а совсем другое, если клиент сам формирует куку с ид пользователя.
Также клиент сам формирует URL, по которому обращается. Но каким образом все это внезапно делает веб-приложение непременно завязаным на состоянии конкретного сервера?
Не непременно, а большей частью. Банальный пример — при первом запросе (аутентификации) получаешь куку сессии, в которой хранится, как минимум, признак аутентификации, и для нормальной работы клиентской части нужно посылать всегда эту куку, но даже тогда сервер может по каким-то причинам (истекло время сеанса, например) изменить своё состояние и потребовать аутентификации заново.
Как всегда склоняюсь к старому доброму «Right Tool For The Right Job».
Никто не заставляет использовать только один подход, тем более ни один не является единственно верным или в корне неверным.
Ну зачем мне stateful-подход там, где он не нужен или неудобен. И точно так же, зачем пытаться сделать непременно stateless там, где это будет хаком?
Stateless вполне себе годится для доброй (обычно бОльшей) части любого веб-приложения, где царит CRUD и иже с ним, а также прочие сценарии, где мы этот самый «state» где-то храним. Ну зачем помнить залогиненного пользователя в запущенном процессе и реализовывать sticky-sessions и продвинутую балансировку (и не говорите, что это не проблема при масштабировании), когда все можно держать в базе/Redis (сессии)/etc, а само веб-приложение держать «stateless».
С другой стороны — какой там «REST» или stateless, если у нас real-time-система или просто система с pub/sub и сокетами — тут как раз нужен запущенный процесс, держащий состояние всех участников в памяти сервера и управляющий общим состоянием и обработчиками событий в реальном времени.
P.S. Насчет REST — согласен полностью — черт пойми что под ним имеют в виду.
Никто не заставляет использовать только один подход, тем более ни один не является единственно верным или в корне неверным.
Ну зачем мне stateful-подход там, где он не нужен или неудобен. И точно так же, зачем пытаться сделать непременно stateless там, где это будет хаком?
Stateless вполне себе годится для доброй (обычно бОльшей) части любого веб-приложения, где царит CRUD и иже с ним, а также прочие сценарии, где мы этот самый «state» где-то храним. Ну зачем помнить залогиненного пользователя в запущенном процессе и реализовывать sticky-sessions и продвинутую балансировку (и не говорите, что это не проблема при масштабировании), когда все можно держать в базе/Redis (сессии)/etc, а само веб-приложение держать «stateless».
С другой стороны — какой там «REST» или stateless, если у нас real-time-система или просто система с pub/sub и сокетами — тут как раз нужен запущенный процесс, держащий состояние всех участников в памяти сервера и управляющий общим состоянием и обработчиками событий в реальном времени.
P.S. Насчет REST — согласен полностью — черт пойми что под ним имеют в виду.
Спасибо большое за эту статью. Как-то не задумывался сильно по этому поводу, но в некоторых вещах увидел себя и понял, какая неразбериха все это время была у меня в голове и, даже обрадовался, что не только у меня.
Я бы сказал, что вы пошатнули мой мир: уже некоторое время меня подташнивает от застарелой плесени, которая покрыла мой разум и не давала двигаться дальше и развиваться; теперь у меня есть новое видение и новый стимул!
Еще раз спасибо вам за это!
Я бы сказал, что вы пошатнули мой мир: уже некоторое время меня подташнивает от застарелой плесени, которая покрыла мой разум и не давала двигаться дальше и развиваться; теперь у меня есть новое видение и новый стимул!
Еще раз спасибо вам за это!
Понравилось про терминологию, действительно у многих с этим каша. НО:
Не забывайте, что главное не терминология, а удобство пользования системой (в данном случае API). Если у 99% разработчиков есть некоторое «понимание» термина, которое не совпадает с его научным определением, но использование этого термина позволяет им быстро вникнуть в смысл и донести до них информацию — почему бы и нет? API твиттера удобно пользоваться и плевать на то есть у него в названии RESTful или нет.
Не забывайте, что главное не терминология, а удобство пользования системой (в данном случае API). Если у 99% разработчиков есть некоторое «понимание» термина, которое не совпадает с его научным определением, но использование этого термина позволяет им быстро вникнуть в смысл и донести до них информацию — почему бы и нет? API твиттера удобно пользоваться и плевать на то есть у него в названии RESTful или нет.
Ладно, если бы не совпадало с научным определением, так это понимание еще и препятствует эффективной разработке, порождая лишние сущности, ничего не дающие ограничения и непонимание между специалистами. Если клубок ниток запутан, то его можно использовать только как смешной балабон для шапки, но чтобы связать саму шапку, все же придется распутать нитки.
Зарегистрируйтесь на Хабре , чтобы оставить комментарий
Назад, к технологиям верхнего палеолита, от любимых всеми REST, STATEless, CRUD, CGI, FastСGI и MVC